













El advenimiento del Sistema de Archivos Distribuido Apache Hadoop (HDFS) revolucionó el almacenamiento, procesamiento y análisis de datos para las empresas, acelerando el crecimiento de los big data y provocando cambios transformadores en la industria.
Inicialmente, Hadoop integró el almacenamiento y el cómputo, pero la aparición de la computación en la nube llevó a una separación de estos componentes. El almacenamiento de objetos surgió como una alternativa al HDFS pero tenía limitaciones. Para complementar estas limitaciones, JuiceFS, un sistema de archivos distribuido de alto rendimiento y de código abierto, ofrece soluciones rentables para escenarios de datos intensivos como cómputo, análisis y entrenamiento. La decisión de adoptar la separación de almacenamiento y cómputo depende de factores como escalabilidad, rendimiento, costo y compatibilidad.
En este artículo, revisaremos la arquitectura de Hadoop, discutiremos la importancia y viabilidad del desacoplamiento de almacenamiento y cómputo, y exploraremos las soluciones disponibles en el mercado, destacando sus respectivas ventajas y desventajas. Nuestro objetivo es proporcionar información e inspiración a las empresas que están experimentando una transformación de la arquitectura de separación de almacenamiento y cómputo.
Características de Diseño de la Arquitectura de Hadoop
Hadoop como Marco Integral
En 2006, Hadoop fue lanzado como un marco integral que consistía en tres componentes:
- MapReduce para cómputo
- YARN para planificación de recursos
- HDFS para almacenamiento de archivos distribuidos
 Core components of Hadoop
Core components of HadoopComponentes de Cómputo Diversos
Entre estos tres componentes, la capa de cómputo ha experimentado un rápido desarrollo. Inicialmente, solo existía MapReduce, pero pronto la industria presenció la aparición de diversos frameworks como Tez y Spark para el cómputo, Hive para el almacenamiento de datos, y motores de consulta como Presto e Impala. En conjunto con estos componentes, hay numerosos herramientas de transferencia de datos como Sqoop.

HDFS Dominó el Sistema de Almacenamiento
Durante aproximadamente diez años, HDFS, el sistema de archivos distribuido, se mantuvo como el sistema de almacenamiento dominante. Era la opción predeterminada para casi todos los componentes de cómputo. Todos los componentes mencionados anteriormente dentro del ecosistema de big data fueron diseñados para la API de HDFS. Algunos componentes aprovechan profundamente las capacidades específicas de HDFS. Por ejemplo:
- HBase utiliza las capacidades de escritura de baja latencia de HDFS para sus registros de escritura anticipada.
- MapReduce y Spark proporcionaron características de localidad de datos.
Las opciones de diseño de estos componentes de big data, basadas en la API de HDFS, trajeron desafíos potenciales para implementar plataformas de datos en la nube.
Arquitectura Acoplada de Almacenamiento y Cómputo
El siguiente diagrama muestra una parte de la arquitectura simplificada de HDFS, que combina el cálculo con el almacenamiento.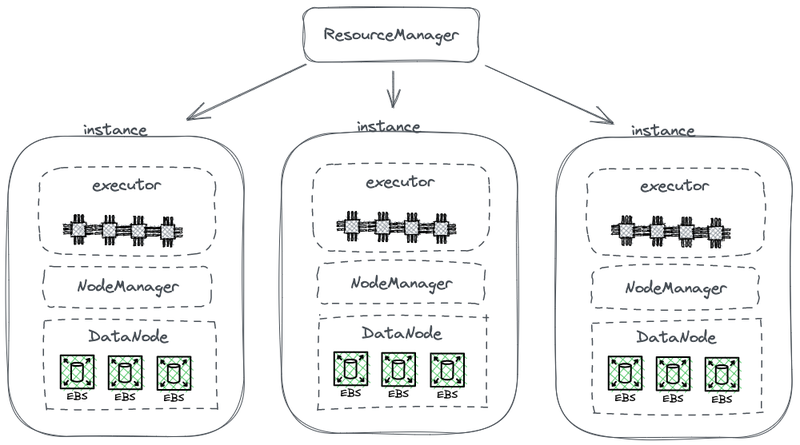
Arquitectura de almacenamiento-cálculo acoplada de Hadoop
En este diagrama, cada nodo actúa como un HDFS DataNode para almacenar datos. Además, YARN despliega un proceso de Node Manager en cada nodo. Esto permite que YARN reconozca el nodo como parte de sus recursos gestionados para tareas de cálculo. Esta arquitectura permite que el almacenamiento y el cálculo coexistan en la misma máquina, y los datos se pueden leer desde el disco durante el cálculo.
¿Por qué Hadoop acopla el almacenamiento y el cálculo?
Hadoop acopló el almacenamiento y el cálculo debido a las limitaciones de la comunicación por red y el hardware durante su fase de diseño.
En 2006, la informática en la nube aún estaba en sus primeras etapas, y Amazon acababa de lanzar su primer servicio. En los centros de datos, las tarjetas de red predominantes operaban principalmente a 100 Mbps. Los discos de datos utilizados para cargas de trabajo de big data alcanzaban un rendimiento de aproximadamente 50 MB/s, equivalente a 400 Mbps en términos de ancho de banda de red.
Considerando un nodo con ocho discos que funcionan a plena capacidad, se necesitaban varios gigabits por segundo de ancho de banda de red para una transmisión de datos eficiente. Desafortunadamente, la capacidad máxima de las tarjetas de red se limitaba a 1 Gbps. Como resultado, el ancho de banda de red por nodo no era suficiente para aprovechar al máximo las capacidades de todos los discos dentro del nodo. En consecuencia, si las tareas de cómputo se encontraban en un extremo de la red y los datos residían en nodos de datos en el otro extremo, el ancho de banda de red era un cuello de botella significativo.
Por qué es necesario desacoplar almacenamiento y cómputo
Desde 2006 hasta alrededor de 2016, las empresas enfrentaron los siguientes problemas:
- La demanda de potencia de cómputo y almacenamiento en las aplicaciones estaba desequilibrada, y sus tasas de crecimiento diferían. Mientras que los datos de las empresas crecían rápidamente, la necesidad de potencia de cómputo no aumentaba tan rápido. Estas tareas, desarrolladas por humanos, no se multiplicaban exponencialmente en un corto período. Sin embargo, los datos generados a partir de estas tareas se acumulaban rápidamente, posiblemente de manera exponencial. Además, algunos datos podrían no ser inmediatamente útiles para la empresa, pero tendrían valor en el futuro. Por lo tanto, las empresas almacenaron los datos de manera integral para explorar su potencial valor.
- Durante la escalabilidad, las empresas tuvieron que expandir tanto la computación como el almacenamiento simultáneamente, lo que a menudo llevó a un desperdicio de recursos computacionales. La topología de hardware de la arquitectura almacenamiento-computación acoplada afectó la expansión de capacidad. Cuando la capacidad de almacenamiento no alcanzaba, no solo necesitábamos agregar máquinas sino también actualizar CPUs y memoria, ya que los nodos de datos en la arquitectura acoplada eran responsables de la computación. Por lo tanto, las máquinas generalmente estaban equipadas con una configuración equilibrada de potencia computacional y almacenamiento, proporcionando una capacidad de almacenamiento suficiente junto con una potencia computacional comparable. Sin embargo, la demanda real de potencia computacional no aumentó como se anticipaba. Como resultado, la potencia computacional expandida causó un gran desperdicio para las empresas.
- El equilibrio entre la computación y el almacenamiento y la selección de máquinas adecuadas se volvió complicado. La utilización de recursos del clúster en términos de almacenamiento e I/O podría estar muy desequilibrada, y este desequilibrio empeoraba a medida que el clúster se hacía más grande. Además, adquirir máquinas apropiadas era difícil, ya que las máquinas debían encontrar un equilibrio entre las necesidades de computación y almacenamiento.
- Debido a que los datos podían distribuirse de manera desigual, era difícil programar de manera efectiva las tareas computacionales en las instancias donde residían los datos. La estrategia de programación de localidad de datos puede no abordar de manera efectiva los escenarios del mundo real debido a la posibilidad de distribución de datos desequilibrada. Por ejemplo, ciertos nodos podrían convertirse en puntos calientes locales, requiriendo más potencia computacional. En consecuencia, incluso si las tareas en la plataforma de big data se programaban en estos nodos de puntos calientes, el rendimiento de E/S podría seguir siendo un factor limitante.
Por qué separar el almacenamiento y el cálculo es factible
La viabilidad de separar el almacenamiento y el cálculo se hizo posible gracias a los avances en hardware y software entre 2006 y 2016. Estos avances incluyen:
Tarjetas de Red
La adopción de tarjetas de red de 10 Gb se ha generalizado, con una creciente disponibilidad de capacidades más altas como 20 Gb, 40 Gb e incluso 50 Gb en centros de datos y entornos en la nube. En escenarios de IA, también se utilizan tarjetas de red con una capacidad de 100 GB. Esto representa un aumento significativo en el ancho de banda de la red de más de 100 veces.
Discos
Muchas empresas todavía confían en soluciones basadas en discos para el almacenamiento en grandes clústeres de datos. La tasa de transferencia de los discos se ha duplicado, aumentando de 50 MB/s a 100 MB/s. Una instancia equipada con una tarjeta de red de 10 GB puede soportar una tasa de transferencia máxima de aproximadamente 12 discos. Esto es suficiente para la mayoría de las empresas, y por lo tanto, la transmisión por red ya no es un cuello de botella.
Software
El uso de algoritmos de compresión eficientes como Snappy, LZ4 y Zstandard y formatos de almacenamiento de columnas como Avro, Parquet y Orc ha aliviado aún más la presión de E/S. El cuello de botella en el procesamiento de big data ha cambiado de la E/S al rendimiento de la CPU.
Cómo implementar la separación de almacenamiento y cálculo
Intento inicial: Implementación independiente de HDFS en la nube
Implementación independiente de HDFS
Desde 2013, ha habido intentos dentro de la industria para separar el almacenamiento y el cómputo. El enfoque inicial es bastante sencillo, involucrando el despliegue independiente de HDFS sin integrarlo con los trabajadores de cómputo. Esta solución no introdujo ningún componente nuevo al ecosistema de Hadoop.
Como se muestra en el diagrama a continuación, el NodeManager ya no se desplegaba en los DataNodes. Esto indicaba que las tareas de cómputo ya no se enviaban a los DataNodes. El almacenamiento se convirtió en un clúster separado, y los datos necesarios para los cálculos se transmitían a través de la red, soportados por tarjetas de red de extremo a extremo de 10 Gb. (Tenga en cuenta que las líneas de transmisión de red no están marcadas en el diagrama.)

Aunque esta solución abandonó la localidad de datos, el diseño más ingenioso de HDFS, la velocidad mejorada de la comunicación de red facilitó significativamente la configuración del clúster. Esto fue demostrado a través de experimentos realizados por Davies, el Co-fundador de Juicedata, y sus compañeros de equipo durante su tiempo en Facebook en 2013. Los resultados confirmaron la viabilidad del despliegue e independiente y la gestión de nodos de cómputo.
Sin embargo, este intento no avanzó más. La razón principal es los desafíos de desplegar HDFS en la nube.
Desafíos de Desplegar HDFS en la Nube
Desplegar HDFS en la nube enfrenta los siguientes problemas:
- El mecanismo de múltiples réplicas de HDFS puede aumentar el costo de las empresas en la nube: En el pasado, las empresas utilizaban discos duros sin formato para construir un sistema HDFS en sus centros de datos. Para mitigar el riesgo de daño en los discos, HDFS implementó un mecanismo de múltiples réplicas para garantizar la seguridad y disponibilidad de los datos. Sin embargo, al migrar datos a la nube, los proveedores de nube ofrecen discos en la nube que ya están protegidos por el mecanismo de múltiples réplicas. Como resultado, las empresas necesitan replicar los datos tres veces dentro de la nube, lo que resulta en un aumento significativo de costos.
- Opciones limitadas para implementar en discos duros sin formato: Aunque los proveedores de nube ofrecen algunos tipos de máquinas con discos duros sin formato, las opciones disponibles son limitadas. Por ejemplo, de los 100 tipos de máquinas virtuales disponibles en la nube, solo 5-10 tipos de máquinas soportan discos duros sin formato. Esta selección limitada puede no cumplir con los requisitos específicos de los clústeres empresariales.
- Incapacidad de aprovechar las ventajas únicas de la nube: Implementar HDFS en la nube requiere la creación manual de máquinas, implementación, mantenimiento, monitoreo y operaciones sin la conveniencia de escalamiento elástico y el modelo de pago por uso. Estas son las principales ventajas de la computación en la nube. Por lo tanto, implementar HDFS en la nube al mismo tiempo que se logra la separación de almacenamiento y cómputo no es fácil.
Limitaciones de HDFS
HDFS en sí tiene estas limitaciones:
- Los NameNodes tienen una escalabilidad limitada: Los NameNodes en HDFS solo pueden escalar verticalmente y no pueden escalarse de manera distribuida. Esta limitación impone una restricción en el número de archivos que pueden ser administrados dentro de un solo clúster HDFS.
- Almacenar más de 500 millones de archivos conlleva altos costos operativos: Según nuestra experiencia, generalmente es fácil operar y mantener HDFS con menos de 300 millones de archivos. Cuando el número de archivos supera los 500 millones, se necesita implementar el mecanismo de HDFS Federation. Sin embargo, esto introduce altos costos operativos y de gestión.
- Alto uso de recursos y carga pesada en el NameNode impacta la disponibilidad del clúster HDFS: Cuando un NameNode ocupa demasiados recursos con una alta carga, puede desencadenarse una recolección completa de basura (GC). Esto afecta la disponibilidad de todo el clúster HDFS. El almacenamiento del sistema puede experimentar tiempo de inactividad, incapaz de leer datos, y no hay forma de intervenir en el proceso de GC. La duración del congelamiento del sistema no puede determinarse. Este ha sido un problema persistente en clústeres HDFS de alta carga.
Cloud Público + Almacenamiento de Objetos
Con el avance de la computación en la nube, las empresas ahora tienen la opción de usar el almacenamiento de objetos como alternativa a HDFS. El almacenamiento de objetos está específicamente diseñado para almacenar datos no estructurados a gran escala, ofreciendo una arquitectura para facilitar la carga y descarga de datos. Proporciona una capacidad de almacenamiento altamente escalable, asegurando la efectividad en costos.
Ventajas del Almacenamiento de Objetos como Reemplazo de HDFS
El almacenamiento de objetos ha ganado impulso, comenzando con AWS y posteriormente siendo adoptado por otros proveedores de nube como reemplazo de HDFS. Las siguientes ventajas son notables:
- Orientado a servicios y listo para usar: El almacenamiento de objetos no requiere tareas de implementación, monitoreo o mantenimiento, proporcionando una experiencia conveniente y amigable para el usuario.
- Escalado elástico y pago por uso: Las empresas pagan por el almacenamiento de objetos en función de su uso real, eliminando la necesidad de planificar la capacidad. Pueden crear un bucket de almacenamiento de objetos y almacenar la cantidad de datos necesaria sin preocupaciones por las limitaciones de capacidad de almacenamiento.
Desventajas del Almacenamiento de Objetos
Sin embargo, al utilizar el almacenamiento de objetos para respaldar sistemas de datos complejos como Hadoop, surgen los siguientes desafíos:
Desventaja #1: Pobre Rendimiento de Listado de Archivos
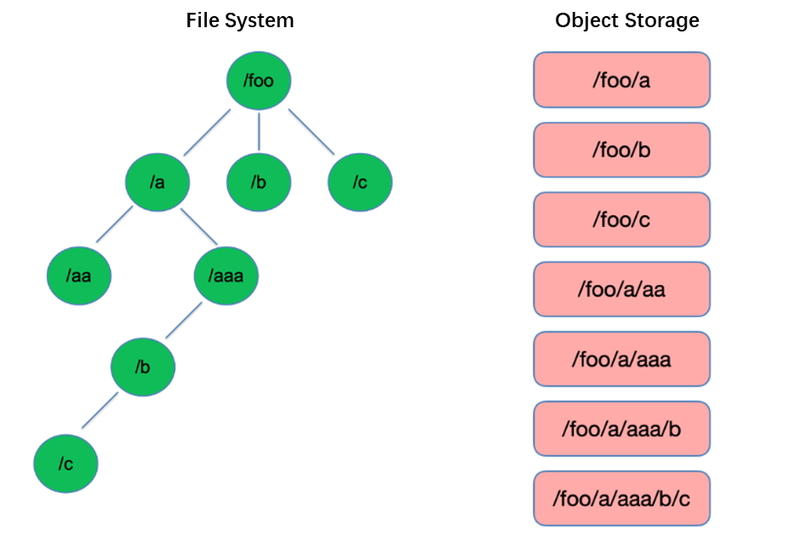
El listado es una de las operaciones más básicas en el sistema de archivos. Es ligero y rápido en estructuras en forma de árbol como HDFS.
Por el contrario, el almacenamiento de objetos adopta una estructura plana y requiere la indexación con claves (identificadores únicos) para almacenar y recuperar miles o incluso miles de millones de objetos. Como resultado, al realizar una operación de Listado, el almacenamiento de objetos solo puede buscar dentro de este índice, lo que lleva a un rendimiento significativamente inferior en comparación con las estructuras en forma de árbol.
Desventaja #2: Falta de Capacidad de Cambio de Nombre Atómico, Afectando el Rendimiento y Estabilidad de las Tareas
En modelos de cómputo de extracción, transformación y carga (ETL), cada subtarea escribe sus resultados en un directorio temporal. Cuando se completa toda la tarea, el directorio temporal puede renombrarse al nombre del directorio final.
Estas operaciones de renombramiento son atómicas y rápidas en sistemas de archivos como HDFS, y garantizan transacciones. Sin embargo, debido a que el almacenamiento de objetos no tiene una estructura de directorio nativa, manejar una operación de renombramiento es un proceso simulado que implica una cantidad considerable de copia interna de datos. Este proceso puede ser lento y no proporciona garantías transaccionales.
Cuando los usuarios emplean almacenamiento de objetos, suelen utilizar el formato de ruta de los sistemas de archivos tradicionales como clave para los objetos, como “/order/2-22/8/10/detail”. Durante una operación de renombramiento, es necesario buscar todos los objetos cuyas claves contengan el nombre del directorio y copiar todos los objetos utilizando el nuevo nombre del directorio como clave. Este proceso implica copiar datos, lo que resulta en un rendimiento significativamente menor en comparación con los sistemas de archivos, potencialmente más lento en una o dos órdenes de magnitud.
Además, debido a la ausencia de garantías transaccionales, existe un riesgo de fallo durante el proceso, lo que puede resultar en datos incorrectos. Estas diferencias aparentemente menores tienen implicaciones para el rendimiento y la estabilidad de toda la tubería de tareas.
Desventaja #3: El Mecanismo de Consistencia Eventual Afecta la Corrección de Datos y la Estabilidad de las Tareas
Por ejemplo, cuando varios clientes crean archivos concurrentemente bajo una ruta, la lista de archivos obtenida a través de la API de Listado puede no incluir inmediatamente todos los archivos creados. Lleva tiempo para que los sistemas internos del almacenamiento de objetos logren la consistencia de datos. Este patrón de acceso se usa comúnmente en el procesamiento de datos ETL, y la consistencia eventual puede afectar la corrección de los datos y la estabilidad de las tareas.
Para abordar la incapacidad de los sistemas de almacenamiento de objetos para mantener una fuerte consistencia de datos, AWS lanzó un producto llamado EMRFS. Su enfoque consiste en emplear una base de datos adicional de DynamoDB. Por ejemplo, cuando Spark escribe un archivo, también escribe simultáneamente una copia de la lista del archivo en DynamoDB. Se establece un mecanismo para llamar de forma continua a la API List del almacenamiento de objetos y comparar los resultados obtenidos con los resultados almacenados en la base de datos hasta que sean iguales, momento en el cual se devuelven los resultados. Sin embargo, la estabilidad de este mecanismo no es suficientemente buena, ya que puede verse influenciada por la carga en la región donde se encuentra el almacenamiento de objetos, lo que resulta en un rendimiento variable. Por lo tanto, no es una solución ideal.
Desventaja #4: Compatibilidad limitada con componentes de Hadoop
HDFS fue la opción de almacenamiento principal en las primeras etapas del ecosistema de Hadoop, y varios componentes se desarrollaron basándose en la API de HDFS. La introducción del almacenamiento de objetos ha llevado a cambios en la estructura de almacenamiento de datos y en las API.
Los proveedores de nube necesitan modificar los conectores entre componentes y el almacenamiento de objetos en la nube, así como aplicar parches a los componentes de nivel superior para garantizar la compatibilidad. Esta tarea supone una carga de trabajo significativa para los proveedores de nube pública.
En consecuencia, el número de componentes de cálculo compatibles en las plataformas de big data ofrecidas por los proveedores de nube pública es limitado, típicamente incluyendo solo algunas versiones de Spark, Hive y Presto. Esta limitación plantea desafíos para migrar plataformas de big data a la nube o para usuarios con requisitos específicos para su propia distribución y componentes.
Para aprovechar el potente rendimiento de los almacenamientos de objetos y al mismo tiempo preservar la fiabilidad de los sistemas de archivos, las empresas pueden utilizar el almacenamiento de objetos + JuiceFS.
Almacenamiento de Objetos + JuiceFS
Cuando los usuarios deseen realizar cálculos de datos complejos, análisis y entrenamiento en almacenamiento de objetos, este último por sí solo puede no satisfacer adecuadamente las necesidades de las empresas. Esta es una motivación clave detrás del desarrollo de JuiceFS por parte de Juicedata, que busca complementar las limitaciones del almacenamiento de objetos.
JuiceFS es un sistema de archivos distribuido de alto rendimiento, de código abierto, diseñado para la nube. Junto con el almacenamiento de objetos, JuiceFS ofrece soluciones rentables para escenarios intensivos en datos como cálculo, análisis y entrenamiento.
Cómo Funciona JuiceFS + Almacenamiento de Objetos
El diagrama a continuación muestra la implementación de JuiceFS en un clúster Hadoop.
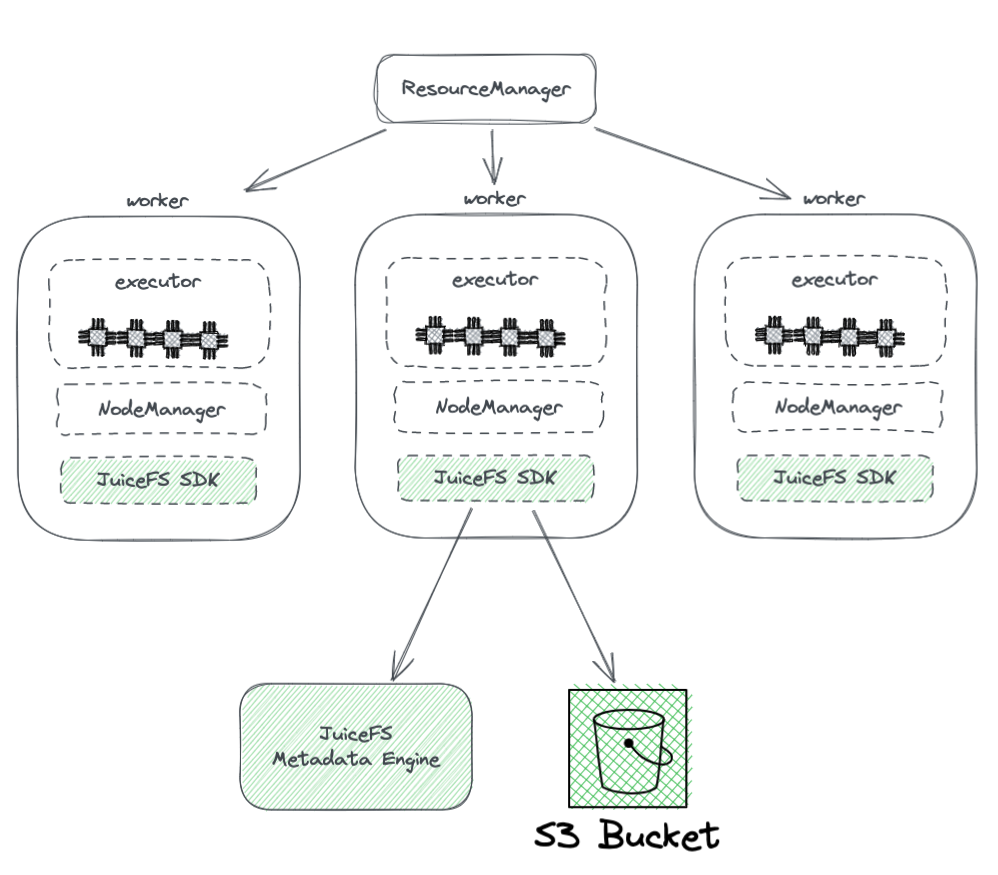
A partir del diagrama, podemos observar lo siguiente:
- Todos los nodos de trabajo gestionados por YARN llevan un SDK de Hadoop de JuiceFS, que puede garantizar la plena compatibilidad con HDFS.
- El SDK accede a dos componentes:
-
Motor de Metadatos de JuiceFS: El motor de metadatos actúa como el contraparte del NameNode de HDFS. Almacena la información de metadatos del sistema de archivos completo, incluyendo conteos de directorios, nombres de archivos, permisos y marcas de tiempo, y resuelve los desafíos de escalabilidad y GC enfrentados por el NameNode de HDFS.
-
Bucket de S3: Los datos se almacenan dentro del bucket de S3, que puede verse como análogo al DataNode de HDFS. Puede ser utilizado como una gran cantidad de discos, gestionando tareas de almacenamiento y replicación de datos.
-
-
JuiceFS se compone de tres componentes:
- SDK de JuiceFS para Hadoop
- Motor de Metadatos
- Bucket de S3
Ventajas de JuiceFS sobre el uso directo de almacenamiento de objetos
JuiceFS ofrece varias ventajas en comparación con el uso directo de almacenamiento de objetos:
- Compatibilidad total con HDFS: Esto se logra gracias al diseño inicial de JuiceFS para soportar completamente POSIX. La API POSIX tiene una mayor cobertura y complejidad que HDFS.
- Capacidad de uso con HDFS y almacenamiento de objetos existentes: Gracias al diseño del sistema Hadoop, JuiceFS puede utilizarse junto con los sistemas de HDFS y almacenamiento de objetos existentes sin necesidad de una sustitución completa. En un clúster Hadoop, se pueden configurar múltiples sistemas de archivos, permitiendo que JuiceFS y HDFS coexistan y colaboren. Esta arquitectura elimina la necesidad de una sustitución completa de los clústeres HDFS existentes, lo que implicaría un esfuerzo y riesgos significativos. Los usuarios pueden integrar gradualmente JuiceFS según las necesidades de sus aplicaciones y situaciones del clúster.
- Potente rendimiento de metadatos: JuiceFS separa el motor de metadatos del S3 y ya no depende del rendimiento de metadatos de S3. Esto garantiza un rendimiento óptimo de metadatos. Al usar JuiceFS, las interacciones con el almacenamiento de objetos subyacente se simplifican a operaciones básicas como Get, Put y Delete. Esta arquitectura supera las limitaciones de rendimiento de los metadatos de almacenamiento de objetos y elimina los problemas relacionados con la consistencia eventual.
- Soporte para Rename atómico: JuiceFS admite operaciones de Rename atómico gracias a su motor de metadatos independiente. La caché mejora el rendimiento de acceso a los datos calientes y proporciona la característica de localidad de datos: Con la caché, los datos calientes ya no necesitan ser recuperados de la almacenamiento en objeto a través de la red cada vez. Además, JuiceFS implementa la API específica de HDFS para localidad de datos, de modo que todos los componentes de nivel superior que admiten localidad de datos pueden recuperar la conciencia de afinidad de datos. Esto permite que YARN priorice la planificación de tareas en nodos donde se ha establecido la caché, lo que resulta en un rendimiento general comparable al de HDFS con almacenamiento y cómputo acoplados.
- JuiceFS es compatible con POSIX, lo que facilita la integración con aplicaciones relacionadas con el aprendizaje automático y la IA.
Conclusión
Con la evolución de las necesidades empresariales y los avances en tecnologías, la arquitectura de almacenamiento y cómputo ha experimentado cambios, pasando de estar acoplada a estar separada.
Existen diversas formas de lograr la separación de almacenamiento y cómputo, cada una con sus propias ventajas y desventajas. Estas van desde implementar HDFS en la nube hasta utilizar soluciones de nube pública que sean compatibles con Hadoop e incluso adoptar soluciones como almacenamiento de objetos + JuiceFS, que son adecuadas para la compleja computación y almacenamiento de big data en la nube.
Para las empresas, no hay una solución mágica, y el enfoque clave radica en seleccionar la arquitectura en función de sus necesidades específicas. Sin embargo, independientemente de la elección, la simplicidad siempre es una apuesta segura.
Acerca del Autor
Rui Su, socio de Juicedata, ha sido miembro fundador involucrado en el desarrollo completo del producto JuiceFS, el mercado y la comunidad de código abierto desde 2017. Con 16 años de experiencia en la industria, ha desempeñado roles como R&D, gerente de producto y fundador en software, internet y organizaciones no gubernamentales.
Source:
https://dzone.com/articles/from-hadoop-to-cloud-why-and-how-to-decouple-stora