













Whisper AI es un modelo avanzado de reconocimiento automático de voz (ASR) desarrollado por OpenAI que puede transcribir audio a texto con una precisión impresionante y admite múltiples idiomas. Aunque Whisper AI está diseñado principalmente para procesamiento por lotes, se puede configurar para transcripción de voz a texto en tiempo real en Linux.
En esta guía, pasaremos por el proceso paso a paso de instalar, configurar y ejecutar Whisper AI para transcripción en vivo en un sistema Linux.
¿Qué es Whisper AI?
Whisper AI es un modelo de reconocimiento de voz de código abierto entrenado en un vasto conjunto de datos de grabaciones de audio y se basa en una arquitectura de aprendizaje profundo que le permite:
- Transcribir voz en múltiples idiomas.
- Manejar acentos y ruido de fondo de manera eficiente.
- Realizar traducción de lenguaje hablado al inglés.
Dado que está diseñado para transcripciones de alta precisión, se utiliza ampliamente en:
- Servicios de transcripción en vivo (por ejemplo, para accesibilidad).
- Asistentes de voz y automatización.
- Transcripción de archivos de audio grabados.
Por defecto, Whisper AI no está optimizado para procesamiento en tiempo real. Sin embargo, con algunas herramientas adicionales, puede procesar flujos de audio en vivo para una transcripción inmediata.
Requisitos del sistema de Whisper AI
Antes de ejecutar Whisper AI en Linux, asegúrese de que su sistema cumpla con los siguientes requisitos:
Requisitos de hardware:
- CPU: Procesador multinúcleo (Intel/AMD).
- RAM: Al menos 8GB (se recomiendan 16GB o más).
- GPU: GPU NVIDIA con CUDA (opcional pero acelera significativamente el procesamiento).
- Almacenamiento: Mínimo 10GB de espacio libre en disco para modelos y dependencias.
Requisitos de software:
- Una distribución de Linux como Ubuntu, Debian, Arch, Fedora, etc.
- Python versión 3.8 o posterior.
- Gestor de paquetes Pip para instalar paquetes de Python.
- FFmpeg para manejar archivos y flujos de audio.
Paso 1: Instalar dependencias requeridas
Antes de instalar Whisper AI, actualice su lista de paquetes y actualice los paquetes existentes.
sudo apt update [On Ubuntu] sudo dnf update -y [On Fedora] sudo pacman -Syu [On Arch]
A continuación, debe instalar Python 3.8 o superior y el gestor de paquetes Pip como se muestra.
sudo apt install python3 python3-pip python3-venv -y [On Ubuntu] sudo dnf install python3 python3-pip python3-virtualenv -y [On Fedora] sudo pacman -S python python-pip python-virtualenv [On Arch]
Por último, debe instalar FFmpeg, que es un marco multimedia utilizado para procesar archivos de audio y video.
sudo apt install ffmpeg [On Ubuntu] sudo dnf install ffmpeg [On Fedora] sudo pacman -S ffmpeg [On Arch]
Paso 2: Instalar Whisper AI en Linux
Una vez que se hayan instalado las dependencias requeridas, puedes proceder a instalar Whisper AI en un entorno virtual que te permita instalar paquetes de Python sin afectar los paquetes del sistema.
python3 -m venv whisper_env source whisper_env/bin/activate pip install openai-whisper
Una vez que la instalación esté completa, verifica si Whisper AI se instaló correctamente ejecutando.
whisper --help
Esto debería mostrar un menú de ayuda con comandos y opciones disponibles, lo que significa que Whisper AI está instalado y listo para usarse.
Paso 3: Ejecutar Whisper AI en Linux
Una vez que Whisper AI esté instalado, puedes comenzar a transcribir archivos de audio usando diferentes comandos.
Transcribir un archivo de audio
Para transcribir un archivo de audio (audio.mp3), ejecuta:
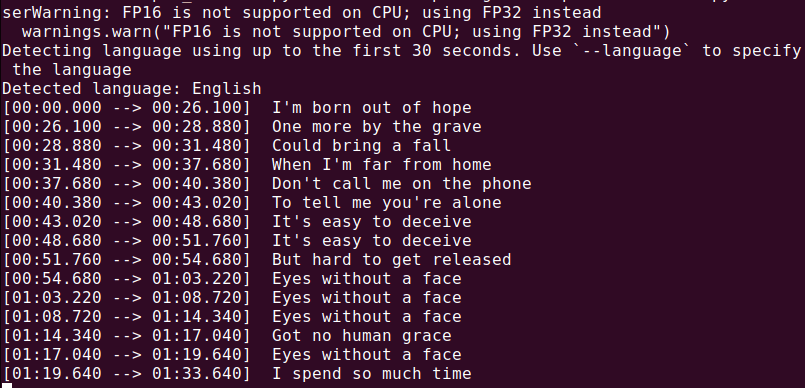
whisper audio.mp3
Whisper procesará el archivo y generará una transcripción en formato de texto.
Ahora que todo está instalado, creemos un script de Python para capturar audio desde tu micrófono y transcribirlo en tiempo real.
nano real_time_transcription.py
Copia y pega el siguiente código en el archivo.
import sounddevice as sd
import numpy as np
import whisper
import queue
import threading
# Load the Whisper model
model = whisper.load_model("base")
# Audio parameters
SAMPLE_RATE = 16000
BUFFER_SIZE = 1024
audio_queue = queue.Queue()
def audio_callback(indata, frames, time, status):
"""Callback function to capture audio data."""
if status:
print(status)
audio_queue.put(indata.copy())
def transcribe_audio():
"""Thread to transcribe audio in real time."""
while True:
audio_data = audio_queue.get()
audio_data = np.concatenate(list(audio_queue.queue)) # Combine buffered audio
audio_queue.queue.clear()
# Transcribe the audio
result = model.transcribe(audio_data.flatten(), language="en")
print(f"Transcription: {result['text']}")
# Start the transcription thread
transcription_thread = threading.Thread(target=transcribe_audio, daemon=True)
transcription_thread.start()
# Start capturing audio from the microphone
with sd.InputStream(callback=audio_callback, channels=1, samplerate=SAMPLE_RATE, blocksize=BUFFER_SIZE):
print("Listening... Press Ctrl+C to stop.")
try:
while True:
pass
except KeyboardInterrupt:
print("\nStopping...")
Ejecuta el script usando Python, el cual comenzará a escuchar la entrada de tu micrófono y mostrará el texto transcribido en tiempo real. Habla claramente en tu micrófono y deberías ver los resultados impresos en la terminal.
python3 real_time_transcription.py
Conclusión
Whisper AI es una poderosa herramienta de conversión de voz a texto que puede adaptarse para la transcripción en tiempo real en Linux. Para obtener mejores resultados, utiliza una GPU y optimiza tu sistema para el procesamiento en tiempo real.
Source:
https://www.tecmint.com/whisper-ai-audio-transcription-on-linux/