













Cuando trabajes con Amazon S3 (Simple Storage Service), probablemente estés utilizando el consola web de S3 para descargar, copiar o subir archivos a los buckets de S3. Usar la consola es perfectamente válido, para eso fue diseñada, en primer lugar.
Especialmente para los administradores que están acostumbrados a más clics de ratón que comandos de teclado, la consola web probablemente sea la más fácil. Sin embargo, los administradores eventualmente necesitarán realizar operaciones de archivos a granel con Amazon S3, como una carga de archivos no supervisada. La GUI no es la mejor herramienta para eso.
Para tales requisitos de automatización con Amazon Web Services, incluido Amazon S3, la herramienta AWS CLI proporciona a los administradores opciones de línea de comandos para administrar buckets y objetos de Amazon S3.
En este artículo, aprenderás cómo utilizar la herramienta AWS CLI de línea de comandos para cargar, copiar, descargar y sincronizar archivos con Amazon S3. También aprenderás los conceptos básicos de cómo proporcionar acceso a tu bucket de S3 y configurar ese perfil de acceso para que funcione con la herramienta AWS CLI.
Prerrequisitos
Dado que este es un artículo práctico, habrá ejemplos y demostraciones en las secciones siguientes. Para que puedas seguir correctamente, necesitarás cumplir con varios requisitos.
- Una cuenta de AWS. Si no tienes una suscripción AWS existente, puedes registrarte para una Tier Gratuita de AWS.
- Un cubo AWS S3. Puedes usar un cubo existente si lo prefieres. Sin embargo, se recomienda crear un cubo vacío en su lugar. Consulta Cómo crear un cubo.
- A Windows 10 computer with at least Windows PowerShell 5.1. In this article, PowerShell 7.0.2 will be used.
- La herramienta AWS CLI versión 2 debe estar instalada en tu computadora.
- Carpetas y archivos locales que cargarás o sincronizarás con Amazon S3
Preparación de tu acceso a AWS S3
Supongamos que ya tienes los requisitos en su lugar. Pensarías que ya puedes ir y comenzar a operar AWS CLI con tu cubo S3. Quiero decir, ¿no sería genial si fuera tan simple?
Para aquellos que están empezando a trabajar con Amazon S3 o AWS en general, esta sección tiene como objetivo ayudarte a configurar el acceso a S3 y configurar un perfil AWS CLI.
Puedes encontrar la documentación completa para crear un usuario IAM en AWS en este enlace a continuación. Cómo crear un usuario IAM en tu cuenta de AWS
Creación de un usuario IAM con permisos de acceso a S3
Cuando accedes a AWS mediante la CLI, deberás crear uno o más usuarios IAM con suficiente acceso a los recursos con los que planeas trabajar. En esta sección, crearás un usuario IAM con acceso a Amazon S3.
Para crear un usuario IAM con acceso a Amazon S3, primero debes iniciar sesión en tu consola de AWS IAM. Bajo el grupo de gestión de acceso, haz clic en Usuarios. Luego, haz clic en Añadir usuario.
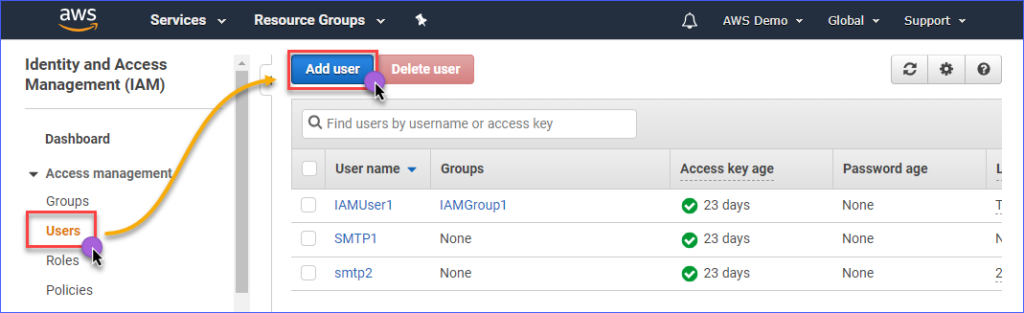
Escribe el nombre del usuario IAM que estás creando dentro del cuadro de texto Nombre de usuario, como por ejemplo s3Admin. En la selección de Tipo de acceso, marca la opción Acceso programático. Después, haz clic en el botón Siguiente: Permisos.

Luego, haz clic en Adjuntar directamente políticas existentes. A continuación, busca el nombre de la política AmazonS3FullAccess y marca la casilla correspondiente. Cuando hayas terminado, haz clic en Siguiente: Etiquetas.

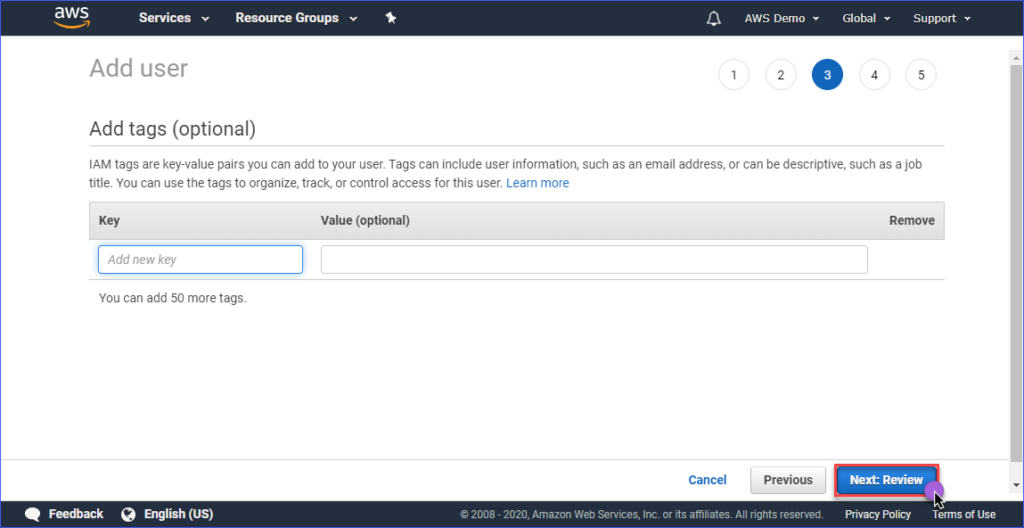
Crear etiquetas es opcional en la página Agregar etiquetas, puedes omitir este paso y hacer clic en el botón Siguiente: Revisar.
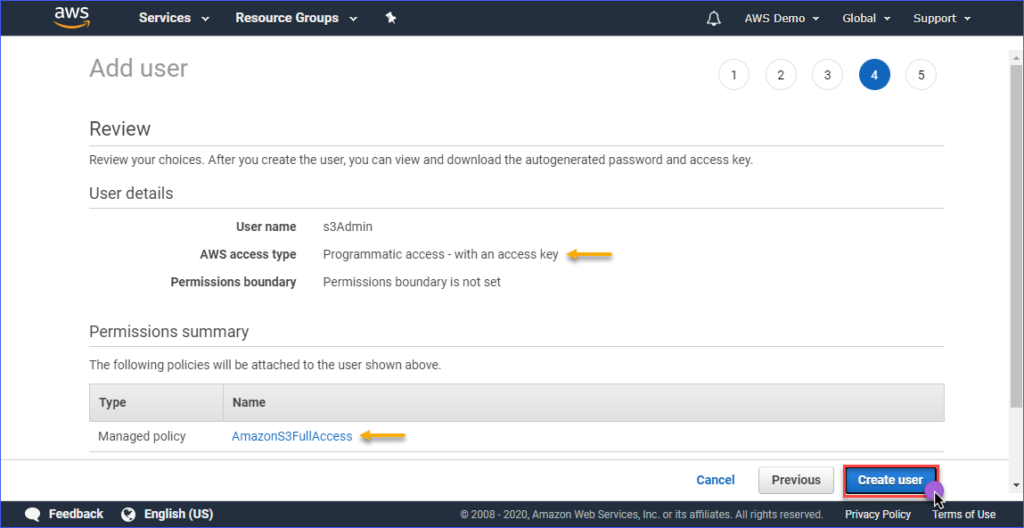
En la página de Revisión, se te mostrará un resumen de la nueva cuenta que se está creando. Haz clic en Crear usuario.
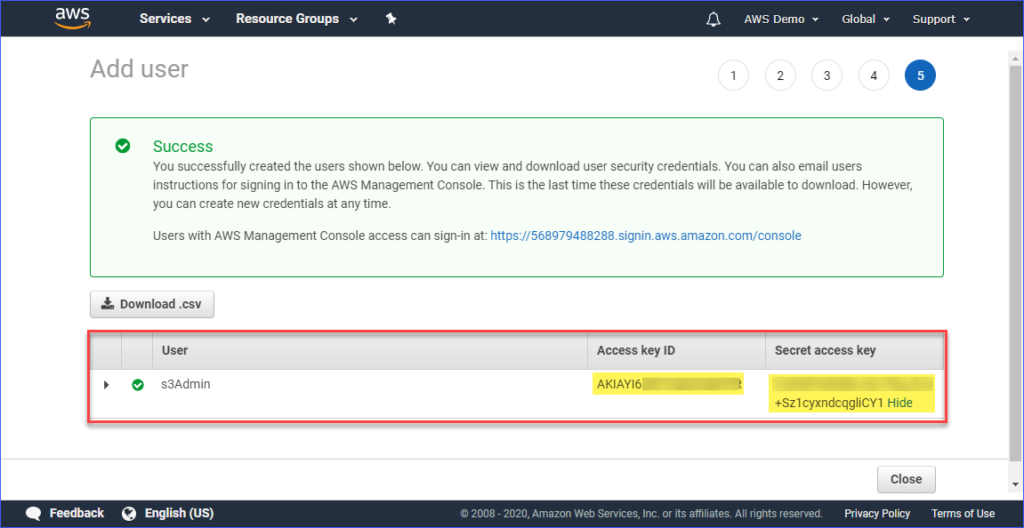
Finalmente, una vez que se haya creado el usuario, debes copiar los valores de la Clave de acceso y la Clave de acceso secreta y guardarlos para su uso posterior. Ten en cuenta que esta es la única vez que podrás ver estos valores.
Configuración de un perfil de AWS en tu ordenador
Ahora que has creado el usuario IAM con el acceso adecuado a Amazon S3, el siguiente paso es configurar el perfil de AWS CLI en tu ordenador.
Esta sección asume que ya has instalado la herramienta AWS CLI versión 2 según lo requerido. Para la creación del perfil, necesitarás la siguiente información:
- El Identificador de clave de acceso (Access key ID) del usuario IAM.
- La Clave de acceso secreta (Secret access key) asociada con el usuario IAM.
- El Nombre de región predeterminada corresponde a la ubicación de tu depósito AWS S3. Puedes consultar la lista de puntos finales utilizando este enlace. En este artículo, el depósito AWS S3 se encuentra en la región Asia Pacífico (Sídney), y el punto final correspondiente es ap-southeast-2.
- El formato de salida predeterminado. Utiliza JSON para esto.
Para crear el perfil, abre PowerShell y escribe el siguiente comando, luego sigue las indicaciones.
Ingresa el Identificador de clave de acceso, Clave de acceso secreta, Nombre de región predeterminada, y nombre de salida predeterminado. Consulta la demostración a continuación.

Prueba de acceso a AWS CLI
Después de configurar el perfil de AWS CLI, puedes confirmar que el perfil funciona ejecutando el siguiente comando en PowerShell.
El comando anterior debería listar los depósitos de Amazon S3 que tienes en tu cuenta. La demostración a continuación muestra el comando en acción. El resultado indica que la configuración del perfil fue exitosa.

Para aprender acerca de los comandos AWS CLI específicos para Amazon S3, puedes visitar la página de Referencia de Comandos AWS CLI S3.
Manejo de Archivos en S3
Con AWS CLI, las operaciones típicas de gestión de archivos se pueden realizar, como cargar archivos en S3, descargar archivos de S3, eliminar objetos en S3 y copiar objetos de S3 a otra ubicación de S3. Todo depende de conocer el comando correcto, la sintaxis, los parámetros y las opciones adecuadas.
En las siguientes secciones, el entorno utilizado consiste en lo siguiente.
- Dos buckets de S3, llamados atasync1 y atasync2. La captura de pantalla a continuación muestra los buckets de S3 existentes en la consola de Amazon S3.
- Directorio local y archivos ubicados en c:\sync.

Cargando Archivos Individuales en S3
Cuando cargas archivos en S3, puedes subir un archivo a la vez o cargar varios archivos y carpetas de forma recursiva. Según tus requisitos, puedes elegir uno u otro que consideres apropiado.
Para cargar un archivo en S3, deberás proporcionar dos argumentos (origen y destino) al comando aws s3 cp.
Por ejemplo, para cargar el archivo c:\sync\logs\log1.xml en la raíz del bucket atasync1, puedes usar el siguiente comando.
Nota: Los nombres de los buckets de S3 siempre tienen el prefijo S3:// cuando se utilizan con AWS CLI
Ejecuta el comando anterior en PowerShell, pero cambia el origen y el destino que se ajusten a tu entorno primero. La salida debería lucir similar a la demostración a continuación.

La demostración anterior muestra que el archivo llamado c:\sync\logs\log1.xml se cargó sin errores en el destino S3 s3://atasync1/.
Utiliza el comando a continuación para listar los objetos en la raíz del cubo S3.
Ejecutar el comando anterior en PowerShell daría como resultado una salida similar, como se muestra en la demostración a continuación. Como puedes ver en la salida a continuación, el archivo log1.xml está presente en la raíz de la ubicación S3.

Cargando Múltiples Archivos y Carpetas en S3 de Forma Recursiva
La sección anterior te mostró cómo copiar un solo archivo a una ubicación S3. ¿Qué pasa si necesitas cargar múltiples archivos desde una carpeta y subcarpetas? Seguramente no querrías ejecutar el mismo comando varias veces para diferentes nombres de archivo, ¿verdad?
El comando aws s3 cp tiene una opción para procesar archivos y carpetas de forma recursiva, y esta es la opción --recursive.
Como ejemplo, el directorio c:\sync contiene 166 objetos (archivos y subcarpetas).
Usando la opción --recursive, todo el contenido de la carpeta c:\sync se cargará en S3 manteniendo también la estructura de carpetas. Para probar, utiliza el código de ejemplo a continuación, pero asegúrate de cambiar el origen y el destino apropiadamente según tu entorno.
Observarás en el código a continuación que la fuente es c:\sync, y el destino es s3://atasync1/sync. La clave /sync que sigue al nombre del cubo S3 indica al AWS CLI que cargue los archivos en la carpeta /sync en S3. Si la carpeta /sync no existe en S3, se creará automáticamente.
El código anterior dará como resultado la salida, como se muestra en la demostración a continuación.

Cargando Múltiples Archivos y Carpetas en S3 Selectivamente
En algunos casos, subir TODOS los tipos de archivos no es la mejor opción. Por ejemplo, cuando solo necesitas cargar archivos con extensiones de archivo específicas (por ejemplo, *.ps1). Otras dos opciones disponibles para el comando cp son --include y --exclude.
Mientras que el uso del comando en la sección anterior incluye todos los archivos en la carga recursiva, el comando a continuación solo incluirá los archivos que coincidan con la extensión de archivo *.ps1 y excluirá cualquier otro archivo de la carga.
La demostración a continuación muestra cómo funciona el código anterior al ejecutarse.

Otro ejemplo es si deseas incluir varias extensiones de archivo diferentes, deberás especificar la opción --include varias veces.
El comando de ejemplo a continuación solo incluirá los archivos *.csv y *.png en el comando de copia.
Ejecutar el código anterior en PowerShell te presentaría un resultado similar, como se muestra a continuación.

Descargando Objetos desde S3
Basado en los ejemplos que has aprendido en esta sección, también puedes realizar las operaciones de copia en reversa. Es decir, puedes descargar objetos desde la ubicación del bucket de S3 a la máquina local.
Copiar de S3 a local requeriría que cambies las posiciones de la fuente y el destino. La fuente siendo la ubicación de S3, y el destino es la ruta local, como la que se muestra a continuación.
Nota que las mismas opciones utilizadas al subir archivos a S3 también son aplicables al descargar objetos de S3 a local. Por ejemplo, descargar todos los objetos usando el comando a continuación con la opción --recursive.
Copiando Objetos Entre Ubicaciones de S3
Aparte de subir y descargar archivos y carpetas, usando AWS CLI, también puedes copiar o mover archivos entre dos ubicaciones de buckets de S3.
Notarás el comando a continuación usando una ubicación de S3 como la fuente, y otra ubicación de S3 como el destino.
La demostración a continuación te muestra el archivo fuente siendo copiado a otra ubicación de S3 usando el comando anterior.

Sincronizando Archivos y Carpetas con S3
Has aprendido cómo subir, descargar y copiar archivos en S3 usando los comandos de AWS CLI hasta ahora. En esta sección, aprenderás sobre un comando de operación de archivos más disponible en AWS CLI para S3, que es el comando sync. El comando sync solo procesa los archivos actualizados, nuevos y eliminados.
Hay algunos casos en los que necesitas mantener actualizados y sincronizados los contenidos de un bucket S3 con un directorio local en un servidor. Por ejemplo, puede que tengas el requisito de mantener sincronizados los registros de transacciones en un servidor con S3 a intervalos regulares.
Usando el comando a continuación, los archivos de registro *.XML ubicados en la carpeta c:\sync en el servidor local se sincronizarán con la ubicación S3 en s3://atasync1.
La demostración a continuación muestra que después de ejecutar el comando anterior en PowerShell, todos los archivos *.XML fueron cargados en el destino S3 s3://atasync1/.

Sincronización de Nuevos Archivos y Archivos Actualizados con S3
En este próximo ejemplo, se asume que el contenido del archivo de registro Log1.xml ha sido modificado. El comando sync debería detectar esa modificación y cargar los cambios realizados en el archivo local en S3, como se muestra en la demostración a continuación.
El comando a utilizar sigue siendo el mismo que en el ejemplo anterior.

Como puedes ver en la salida anterior, dado que solo se modificó el archivo Log1.xml localmente, también fue el único archivo sincronizado con S3.
Sincronización de Eliminaciones con S3
Por defecto, el comando sync no procesa las eliminaciones. Cualquier archivo eliminado de la ubicación de origen no se elimina en el destino. Bueno, a menos que uses la opción --delete.
En este próximo ejemplo, el archivo llamado Log5.xml ha sido eliminado de la fuente. El comando para sincronizar los archivos se añadirá con la opción --delete, como se muestra en el código a continuación.
Cuando ejecutas el comando anterior en PowerShell, el archivo eliminado llamado Log5.xml también debería ser eliminado en la ubicación S3 de destino. El resultado de muestra se muestra a continuación.

Resumen
Amazon S3 es un excelente recurso para almacenar archivos en la nube. Con el uso de la herramienta AWS CLI, la forma en que utilizas Amazon S3 se amplía aún más y abre la oportunidad de automatizar tus procesos.
En este artículo, has aprendido cómo usar la herramienta AWS CLI para cargar, descargar y sincronizar archivos y carpetas entre ubicaciones locales y buckets de S3. También has aprendido que el contenido de los buckets de S3 también se puede copiar o mover a otras ubicaciones de S3.
Puede haber muchos más escenarios de uso para utilizar la herramienta AWS CLI para automatizar la gestión de archivos con Amazon S3. Incluso puedes intentar combinarlo con scripts de PowerShell y crear tus propias herramientas o módulos que sean reutilizables. Depende de ti encontrar esas oportunidades y mostrar tus habilidades.