













VAR-As-A-Service es un enfoque MLOps para la unificación y reutilización de modelos estadísticos y de aprendizaje automático en las canalizaciones de despliegue. Es el segundo de una serie de artículos construidos sobre ese proyecto, que representan experimentos con diversos modelos estadísticos y de aprendizaje automático, canalizaciones de datos implementadas utilizando herramientas DAG existentes, y servicios de almacenamiento, tanto basados en la nube como alternativas locales. Este artículo se centra en el almacenamiento de archivos de modelos utilizando un enfoque también aplicable y utilizado para modelos de aprendizaje automático. El almacenamiento implementado se basa en MinIO como servicio de almacenamiento de objetos compatible con AWS S3. Además, el artículo ofrece una visión general de soluciones de almacenamiento alternativas y destaca los beneficios del almacenamiento basado en objetos.
El primer artículo de la serie (Análisis de Series de Tiempo: VARMAX-As-A-Service) compara modelos estadísticos y de aprendizaje automático como modelos matemáticos y proporciona una implementación completa de un modelo estadístico basado en VARMAX para la predicción macroeconómica utilizando una biblioteca de Python llamada statsmodels. El modelo se despliega como un servicio REST utilizando Python Flask y servidor web Apache, empaquetado en un contenedor docker. La arquitectura de alto nivel de la aplicación se muestra en la siguiente imagen:
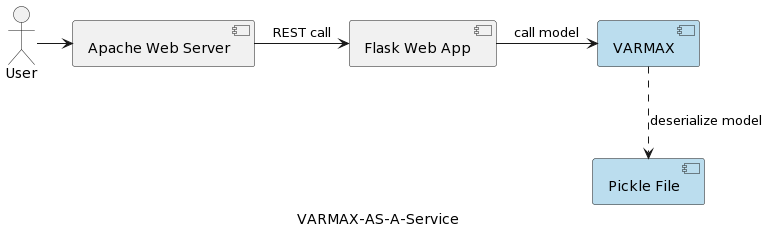
El modelo se serializa como un archivo pickle y se implementa en el servidor web como parte del paquete de servicio REST. Sin embargo, en proyectos reales, los modelos se versionan, acompañados de información de metadatos y se aseguran, y los experimentos de entrenamiento deben registrarse y mantenerse reproducibles. Además, desde una perspectiva arquitectónica, almacenar el modelo en el sistema de archivos junto al aplicación contradice el principio de responsabilidad única. Un buen ejemplo es una arquitectura basada en microservicios. Escalar el servicio del modelo de manera horizontal significa que cada instancia de microservicio tendrá su propia versión del archivo físico pickle replicado en todas las instancias del servicio. Eso también significa que el soporte de múltiples versiones de los modelos requerirá una nueva versión y reexpedición del servicio REST y su infraestructura. El objetivo de este artículo es desacoplar los modelos de la infraestructura del servicio web y permitir la reutilización de la lógica del servicio web con diferentes versiones de modelos.
Antes de sumergirnos en la implementación, digamos unas palabras sobre los modelos estadísticos y el modelo VAR utilizado en ese proyecto. Modelos estadísticos son modelos matemáticos, al igual que los modelos de aprendizaje automático. Más información sobre la diferencia entre los dos se puede encontrar en el primer artículo de la serie. Un modelo estadístico generalmente se especifica como una relación matemática entre una o más variables aleatorias y otras variables no aleatorias. Autoregresión vectorial (VAR) es un modelo estadístico utilizado para capturar la relación entre múltiples cantidades a medida que cambian en el tiempo. Los modelos VAR generalizan el modelo autoregresivo de variable única (AR) al permitir series de tiempo multivariadas. En el proyecto presentado, el modelo se entrena para hacer pronósticos para dos variables. Los modelos VAR se utilizan a menudo en economía y ciencias naturales. En general, el modelo se representa mediante un sistema de ecuaciones, que en el proyecto están ocultas detrás de la biblioteca Python statsmodels.
La arquitectura de la aplicación de servicio del modelo VAR se muestra en la siguiente imagen:
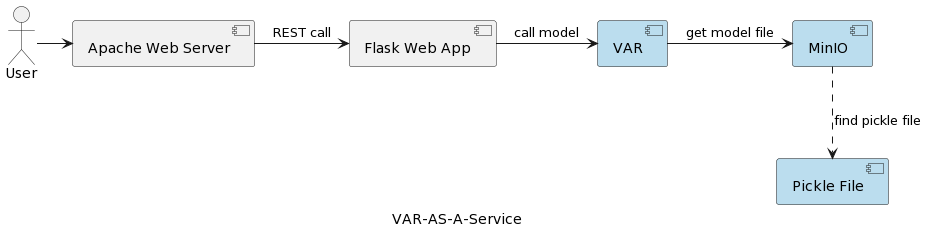
El componente de tiempo de ejecución VAR representa la ejecución real del modelo basada en los parámetros enviados por el usuario. Se conecta a un servicio MinIO a través de una interfaz REST, carga el modelo y ejecuta la predicción. En comparación con la solución en el primer artículo, donde el modelo VARMAX se carga y deserializa al inicio de la aplicación, el modelo VAR se lee desde el servidor MinIO cada vez que se desencadena una predicción. Esto conlleva el costo de un tiempo adicional de carga y deserialización, pero también con la ventaja de tener la versión más reciente del modelo desplegada en cada ejecución. Además, permite la versión dinámica de los modelos, haciéndolos automáticamente accesibles para sistemas externos y usuarios finales, como se mostrará más adelante en el artículo. Tenga en cuenta que debido a esa sobrecarga de carga, el rendimiento del servicio de almacenamiento seleccionado es de gran importancia.
Pero, ¿por qué MinIO y el almacenamiento basado en objetos en general?
MinIO es una solución de almacenamiento de objetos de alto rendimiento con soporte nativo para despliegues en Kubernetes que ofrece una API compatible con Amazon Web Services S3 y soporta todas las características principales de S3. En el proyecto presentado, MinIO está en Modo Standalone, que consta de un solo servidor MinIO y una sola unidad o volumen de almacenamiento en Linux utilizando Docker Compose. Para entornos de desarrollo extendidos o de producción, existe la opción de un modo distribuido, descrito en el artículo Desplegar MinIO en Modo Distribuido.
Echemos un vistazo rápido a algunas alternativas de almacenamiento, mientras que una descripción detallada se puede encontrar aquí y aquí:
- Almacenamiento de archivos local/distribuido: El almacenamiento de archivos local es la solución implementada en el primer artículo, ya que es la opción más sencilla. La computación y el almacenamiento están en el mismo sistema. Es aceptable durante la fase de PoC o para modelos muy simples que soporten una sola versión del modelo. Los sistemas de archivos locales tienen una capacidad de almacenamiento limitada y no son adecuados para conjuntos de datos más grandes en caso de que queramos almacenar metadatos adicionales como el conjunto de datos de entrenamiento utilizado. Dado que no hay replicación ni escalado automático, un sistema de archivos local no puede operar de manera disponible, confiable y escalable. Cada servicio desplegado para escalar horizontalmente se despliega con su propia copia del modelo. Además, el almacenamiento local es tan seguro como lo es el sistema anfitrión. Las alternativas al almacenamiento de archivos local son NAS (almacenamiento conectado a la red), SAN (red de área de almacenamiento), sistemas de archivos distribuidos (Sistema de Archivos Distribuido de Hadoop (HDFS), Sistema de Archivos de Google (GFS), Amazon Elastic File System (EFS) y Azure Files). En comparación con el sistema de archivos local, estas soluciones se caracterizan por disponibilidad, escalabilidad y resiliencia, pero vienen con el costo de una complejidad aumentada.
- Bases de datos relacionales: Debido a la serialización binaria de modelos, las bases de datos relacionales ofrecen la opción de almacenar modelos en columnas de tablas como blobs o datos binarios. Los desarrolladores de software y muchos científicos de datos están familiarizados con las bases de datos relacionales, lo que hace que esta solución sea directa. Las versiones del modelo se pueden almacenar como filas separadas en la tabla con metadatos adicionales, lo cual también es fácil de leer desde la base de datos. Un inconveniente es que la base de datos requerirá más espacio de almacenamiento, y esto afectará las copias de seguridad. Tener grandes cantidades de datos binarios en una base de datos también puede afectar el rendimiento. Además, las bases de datos relacionales imponen algunas restricciones en las estructuras de datos, lo que podría complicar el almacenamiento de datos heterogéneos como archivos CSV, imágenes y archivos JSON como metadatos del modelo.
- Almacenamiento de objetos: El almacenamiento de objetos lleva existiendo desde hace bastante tiempo, pero fue revolucionado cuando Amazon lo convirtió en el primer servicio de AWS en 2006 con Simple Storage Service (S3). El almacenamiento de objetos moderno es nativo en la nube, y pronto otras nubes también ofrecieron sus propias soluciones. Microsoft ofrece Azure Blob Storage, y Google tiene su servicio Google Cloud Storage. La API de S3 es el estándar de facto para que los desarrolladores interactúen con el almacenamiento en la nube, y hay varias compañías que ofrecen almacenamiento compatible con S3 para la nube pública, privada y soluciones on-premises privadas. Independientemente de dónde se encuentre una tienda de objetos, se accede a través de una interfaz RESTful. Aunque el almacenamiento de objetos elimina la necesidad de directorios, carpetas y otras organizaciones jerárquicas complejas, no es una buena solución para datos dinámicos que cambian constantemente, ya que es necesario reescribir todo el objeto para modificarlo, pero es una buena opción para almacenar modelos serializados y los metadatos del modelo.
A summary of the main benefits of object storage are:
- Escalabilidad masiva: El tamaño del almacenamiento de objetos es prácticamente ilimitado, por lo que los datos pueden escalar a exabytes simplemente agregando nuevos dispositivos. Las soluciones de almacenamiento de objetos también funcionan mejor cuando se ejecutan como un clúster distribuido.
- Reducción de complejidad: Los datos se almacenan en una estructura plana. La falta de árboles complejos o particiones (sin carpetas o directorios) reduce la complejidad de recuperar archivos, ya que no es necesario conocer la ubicación exacta.
- Buscabilidad: El metadato es parte de los objetos, lo que facilita la búsqueda y navegación sin necesidad de una aplicación separada. Se pueden etiquetar objetos con atributos e información, como consumo, costo y políticas para la eliminación automática, retención y escalonamiento. Debido a la estructura de espacio de direcciones plana del almacenamiento subyacente (cada objeto en un solo bucket y sin buckets dentro de buckets), los almacenes de objetos pueden encontrar un objeto entre potencialmente miles de millones de objetos rápidamente.
- Resiliencia: El almacenamiento de objetos puede replicar automáticamente los datos y almacenarlos en múltiples dispositivos y ubicaciones geográficas. Esto puede ayudar a protegerse contra interrupciones, salvaguardar contra la pérdida de datos y ayudar a respaldar las estrategias de recuperación ante desastres.
- Simplicidad: El uso de una API REST para almacenar y recuperar modelos implica casi ninguna curva de aprendizaje y hace que las integraciones en arquitecturas basadas en microservicios sean una opción natural.
Es hora de analizar la implementación del modelo VAR como servicio y la integración con MinIO. El despliegue de la solución presentada se simplifica utilizando Docker y Docker Compose. La organización de todo el proyecto es la siguiente:

Tal como en el primer artículo, la preparación del modelo consiste en varios pasos que están escritos en un script de Python llamado var_model.py ubicado en un repositorio dedicado GitHub:
- Cargar datos
- Dividir los datos en conjuntos de entrenamiento y prueba
- Preparar variables endógenas
- Encontrar el parámetro óptimo del modelo p (primeros p rezagos de cada variable utilizados como predictores de regresión)
- Instanciar el modelo con los parámetros óptimos identificados
- Serializar el modelo instanciado en un archivo pickle
- Almacenar el archivo pickle como un objeto versionado en un bucket de MinIO
Estos pasos también pueden implementarse como tareas en un motor de flujo de trabajo (por ejemplo, Apache Airflow) desencadenado por la necesidad de entrenar una nueva versión del modelo con datos más recientes. DAGs y sus aplicaciones en MLOps serán el foco de otro artículo.
El último paso implementado en var_model.py es almacenar el modelo serializado como un archivo pickle en un bucket de S3. Debido a la estructura plana del almacenamiento de objetos, el formato seleccionado es:
<nombre del bucket>/<nombre del archivo>
Sin embargo, para los nombres de archivo, se permite usar una barra inclinada (/) para imitar una estructura jerárquica, manteniendo la ventaja de una búsqueda lineal rápida. La convención para almacenar modelos VAR es la siguiente:
models/var/0_0_1/model.pkl
Donde el nombre del bucket es models, y el nombre del archivo es var/0_0_1/model.pkl y en la interfaz de MinIO, se ve de la siguiente manera:

Esta es una forma muy conveniente de estructurar varios tipos de modelos y versiones de modelos, manteniendo aún el rendimiento y la simplicidad del almacenamiento de archivos planos.
Tenga en cuenta que la versión del modelo se implementa como parte del nombre del modelo. MinIO también proporciona la versión de archivos, pero el enfoque seleccionado aquí tiene algunas ventajas:
- Soporte de versiones de instantáneas y anulación
- Uso de la versión semántica (puntos reemplazados por ‘_’ debido a restricciones)
- Mayor control de la estrategia de versión
- Desacoplamiento del mecanismo de almacenamiento subyacente en términos de características específicas de versión
Una vez que el modelo se despliega, es hora de exponerlo como un servicio REST utilizando Flask y desplegarlo utilizando docker-compose que ejecuta MinIO y un servidor web Apache. La imagen de Docker, así como el código del modelo, se pueden encontrar en un repositorio dedicado GitHub.
Y finalmente, los pasos necesarios para ejecutar la aplicación son:
- Desplegar aplicación:
docker-compose up -d - Ejecutar algoritmo de preparación del modelo:
python var_model.py(requiere un servicio MinIO en ejecución) - Comprobar si el modelo ha sido desplegado: http://127.0.0.1:9101/browser
- Probar el modelo:
http://127.0.0.1:80/apidocs
Después de desplegar el proyecto, la API de Swagger es accesible a través de <host>:<port>/apidocs (por ejemplo, 127.0.0.1:80/apidocs). Hay un punto final para el modelo VAR que se muestra junto a los otros dos que exponen un modelo VARMAX:
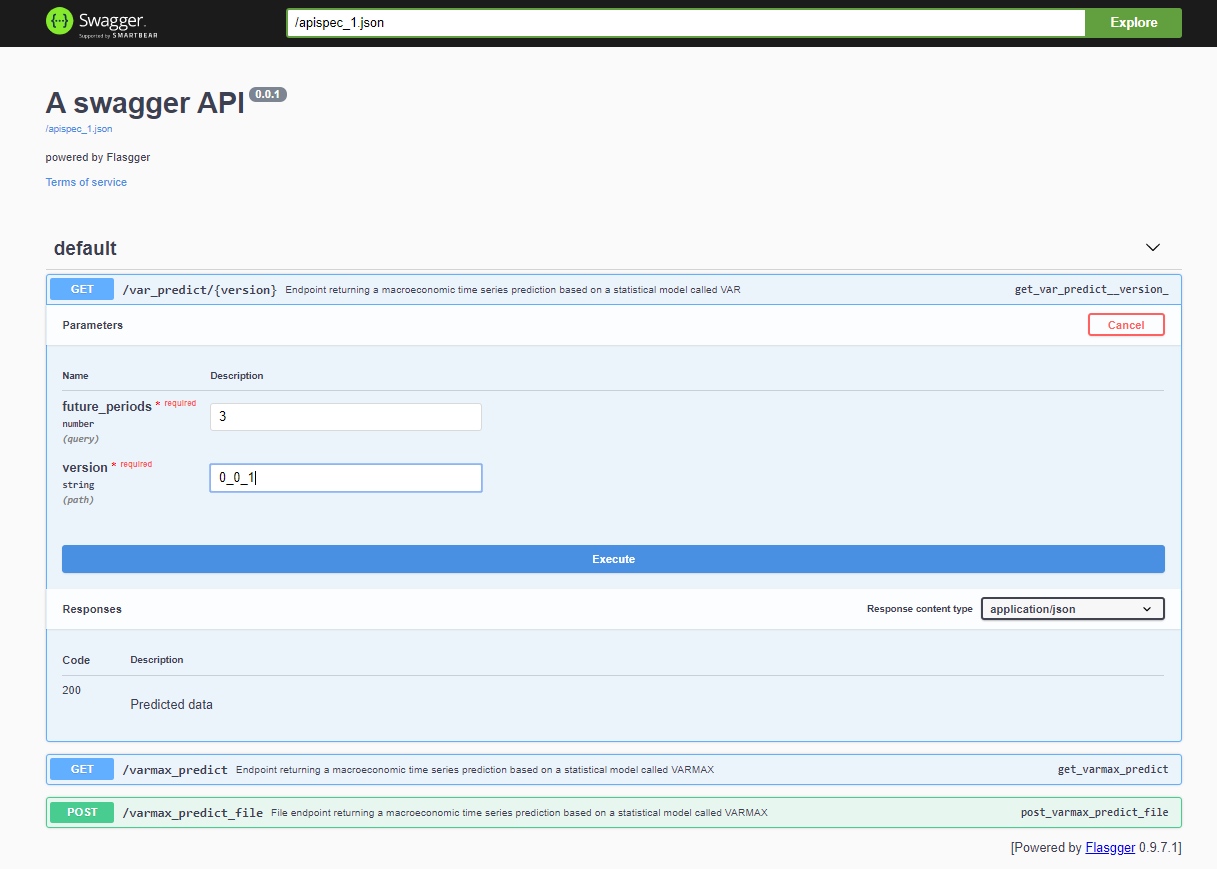
Internamente, el servicio utiliza el archivo pickle del modelo deserializado cargado desde un servicio MinIO:
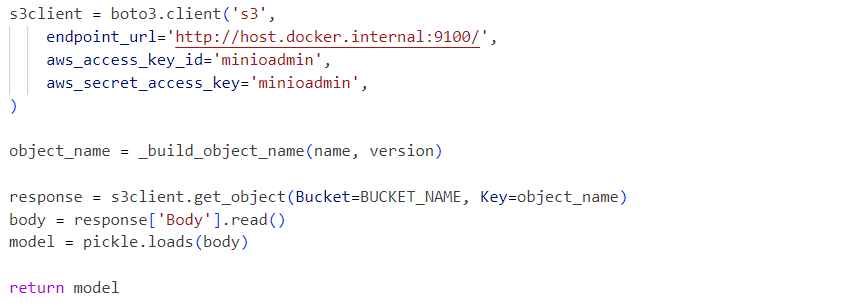
Las solicitudes se envían al modelo inicializado de la siguiente manera:

El proyecto presentado es un flujo de trabajo simplificado del modelo VAR que puede ser extendido paso a paso con funcionalidades adicionales como:
- Explorar formatos de serialización estándar y reemplazar el pickle con una solución alternativa
- Integrar herramientas de visualización de datos de series temporales como Kibana o Apache Superset
- Almacenar datos de series temporales en una base de datos de series temporales como Prometheus, TimescaleDB, InfluxDB, o un Almacenamiento de Objetos como S3
- Ampliar el pipeline con pasos de carga de datos y preprocesamiento de datos
- Incorporar informes de métricas como parte de los pipelines
- Implementar pipelines utilizando herramientas específicas como Apache Airflow o AWS Step Functions o herramientas más estándar como Gitlab o GitHub
- Comparar el rendimiento y la precisión de los modelos estadísticos con los modelos de aprendizaje automático
- Implementar soluciones integradas en la nube de extremo a extremo, incluyendo Infraestructura como Código
- Exponer otros modelos estadísticos y de ML como servicios
- Implementar una API de Almacenamiento de Modelos que abstraiga el mecanismo de almacenamiento real y la versión del modelo, almacene metadatos del modelo y datos de entrenamiento
Estas mejoras futuras serán el enfoque de artículos y proyectos venideros. El objetivo de este artículo es integrar una API de almacenamiento compatible con S3 y permitir el almacenamiento de modelos con versión. Esa funcionalidad se extraerá en una biblioteca separada pronto. La solución de infraestructura de extremo a extremo presentada puede implementarse en producción y mejorarse como parte de un proceso de CI/CD con el tiempo, también utilizando las opciones de implementación distribuida de MinIO o reemplazándolo con AWS S3.
Source:
https://dzone.com/articles/time-series-analysis-var-model-as-a-service