













Amazon Simple Storage Service (S3) es un servicio de almacenamiento de objetos altamente escalable, duradero y seguro ofrecido por Amazon Web Services (AWS). S3 permite a las empresas almacenar y recuperar cualquier cantidad de datos desde cualquier lugar en la web mediante el uso de sus servicios de nivel empresarial. S3 está diseñado para ser altamente interoperable e integra de manera fluida con otros servicios de Amazon Web Services (AWS) y herramientas y tecnologías de terceros para procesar datos almacenados en Amazon S3. Uno de ellos es Amazon EMR (Elastic MapReduce), que te permite procesar grandes cantidades de datos utilizando herramientas de código abierto como Spark.
Apache Spark es un sistema de computación distribuida de código abierto utilizado para el procesamiento de datos a gran escala. Spark está construido para permitir velocidad y soporta varios orígenes de datos, incluyendo Amazon S3. Spark proporciona una forma eficiente de procesar grandes cantidades de datos y realizar cálculos complejos en poco tiempo.
Memphis.dev es una alternativa de próxima generación a los brokers de mensajes tradicionales. Un broker de mensajes nativo en la nube simple, robusto y duradero, envuelto con un ecosistema completo que permite el desarrollo rápido, económico y confiable de casos de uso modernos basados en colas.
El patrón común de los brokers de mensajes es eliminar los mensajes después de pasar la directiva de retención definida, como tiempo/tamaño/número de mensajes. Memphis ofrece una segunda capa de almacenamiento para una retención más larga, posiblemente infinita, de los mensajes almacenados. Cada mensaje que expulsa de la estación migrará automáticamente a la segunda capa de almacenamiento, que en ese caso es AWS S3.
En este tutorial, te guiaré a través del proceso de configurar una estación de Memphis con una segunda clase de almacenamiento conectada a AWS S3. Un entorno en AWS. Seguido de la creación de un bucket de S3, configuración de un clúster de EMR, instalación y configuración de Apache Spark en el clúster, preparación de datos en S3 para procesamiento, procesamiento de datos con Apache Spark, mejores prácticas y ajuste de rendimiento.
Configurar el Entorno
Memphis
- Para comenzar, primero instala Memphis.
- Habilita la integración de AWS S3 a través del centro de integración de Memphis.
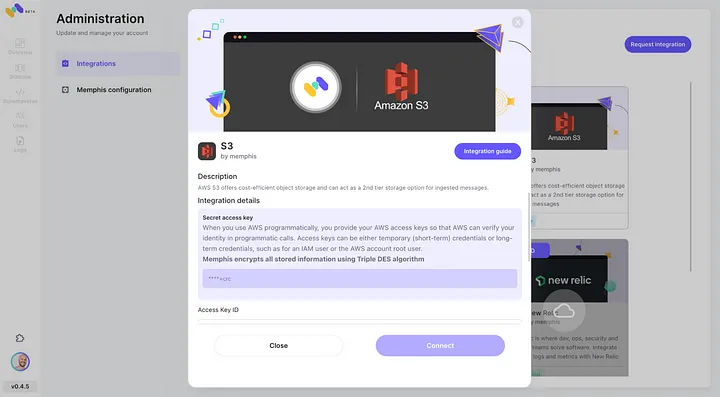
3. Crea una estación (tema) y elige una política de retención.
4. Cada mensaje que pase la política de retención configurada se descargará a un bucket de S3.
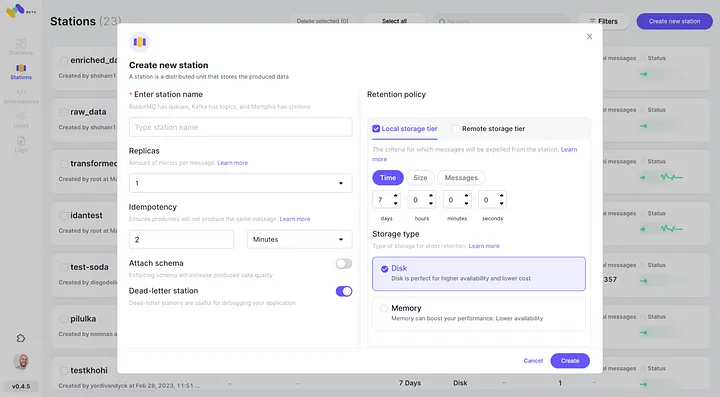
5. Verifica la nueva integración de AWS S3 configurada como segunda clase de almacenamiento al hacer clic en “Conectar”.
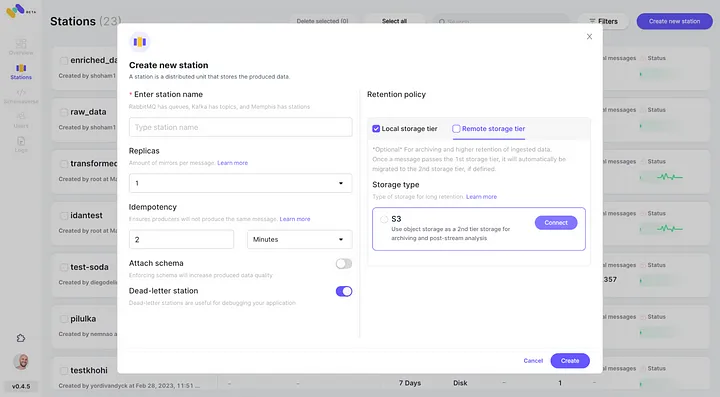
6. Comienza a producir eventos para tu nueva estación de Memphis creada.
Crear un Bucket de AWS S3
Si aún no lo has hecho, primero, necesitas crear una cuenta de AWS account. Luego, crea un bucket de S3 donde almacenarás tus datos. Puedes utilizar el AWS Management Console, la CLI de AWS o un SDK para crear un bucket. Para este tutorial, usarás el console de administración de AWS.
Haz clic en “Crear bucket”.
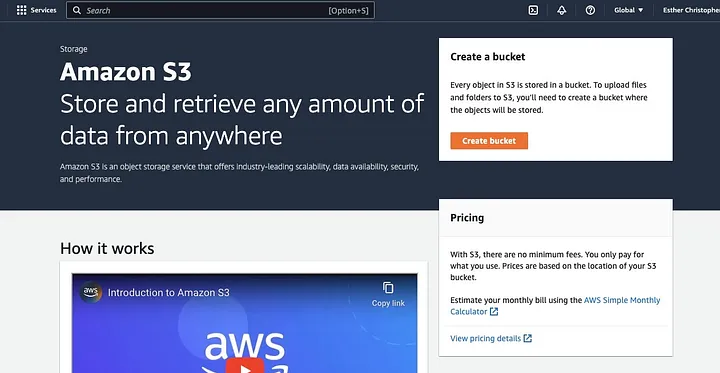
Luego, procede a crear un nombre de bucket que cumpla con la convención de nomenclatura y elige la región donde deseas que se encuentre el bucket. Configura la “Propiedad de objetos” y “Bloquear todo acceso público” según tu caso de uso.
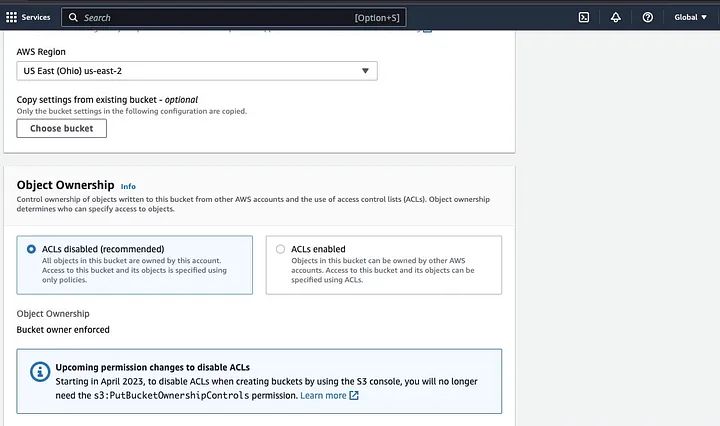
Asegúrate de configurar otras permisos del bucket para permitir que tu aplicación de Spark acceda a los datos. Finalmente, haz clic en el botón “Crear bucket” para crear el bucket.
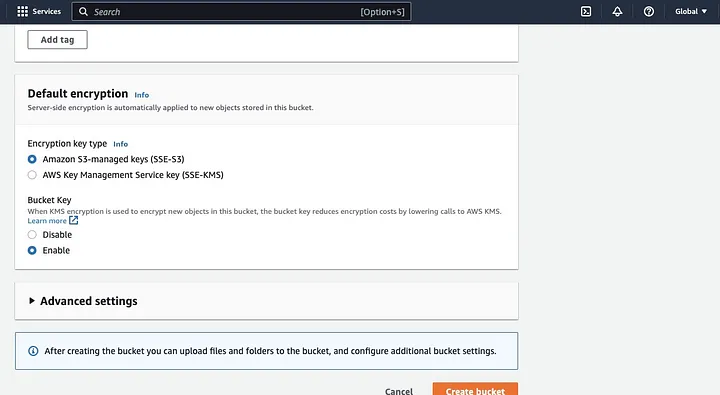
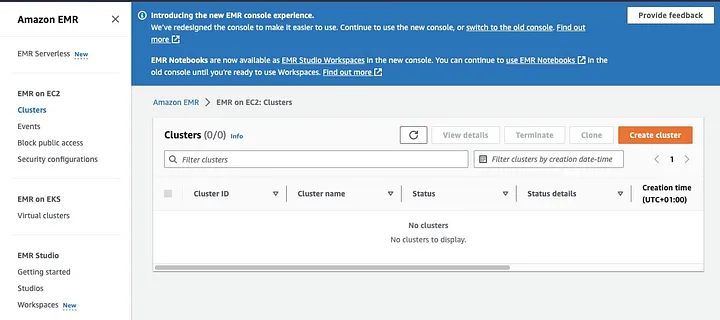
Configurar un Cluster EMR con Spark Instalado
Amazon Elastic MapReduce (EMR) es un servicio web basado en Apache Hadoop que permite a los usuarios procesar de manera rentable grandes cantidades de datos utilizando tecnologías de big data, incluyendo Apache Spark. Para crear un cluster EMR con Spark instalado, abre el consola de EMR y selecciona “Clusters” debajo de “EMR on EC2” en el lado izquierdo de la página.
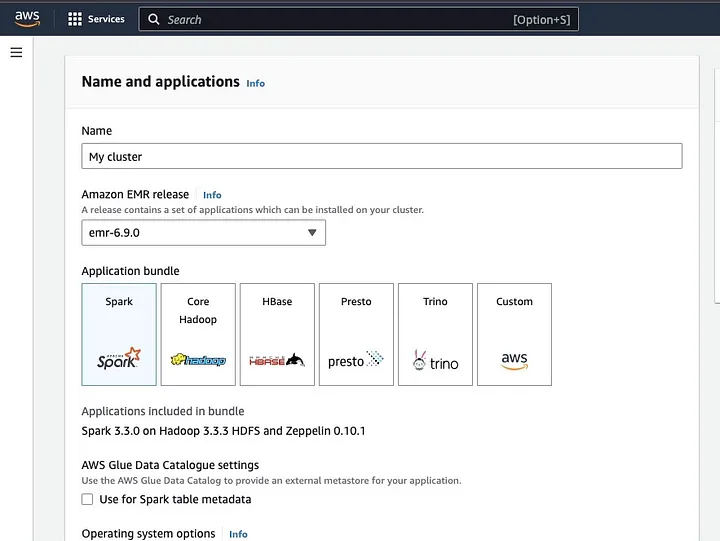
Haz clic en “Crear cluster” y dale un nombre descriptivo al cluster. Bajo “Application bundle”, selecciona Spark para instalarlo en tu cluster.
Desplácese hacia abajo hasta la sección “Logs del clúster” y seleccione la casilla de Publicar logs específicos del clúster en Amazon S3.
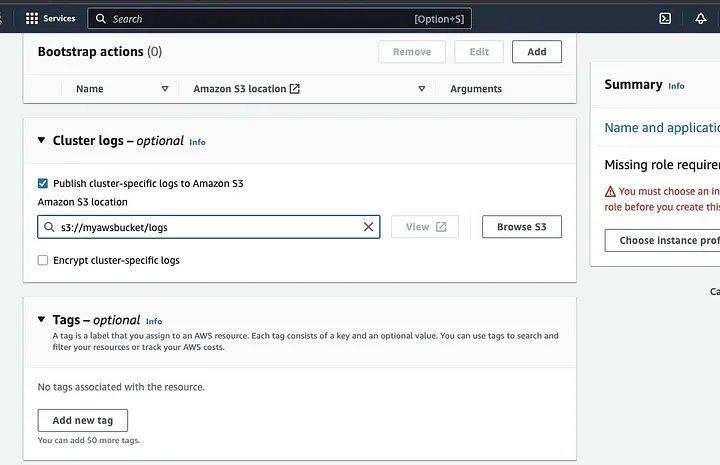
Esto generará un aviso para ingresar la ubicación de Amazon S3 utilizando el nombre del bucket S3 que creó en el paso anterior, seguido de /logs, es decir, s3://myawsbucket/logs. /logs son requeridos por Amazon para crear una nueva carpeta en su bucket donde Amazon EMR puede copiar los archivos de log de su clúster.
Vaya a la sección “Configuración de seguridad y permisos” e introduzca su par de claves EC2 o vaya con la opción de crear uno.
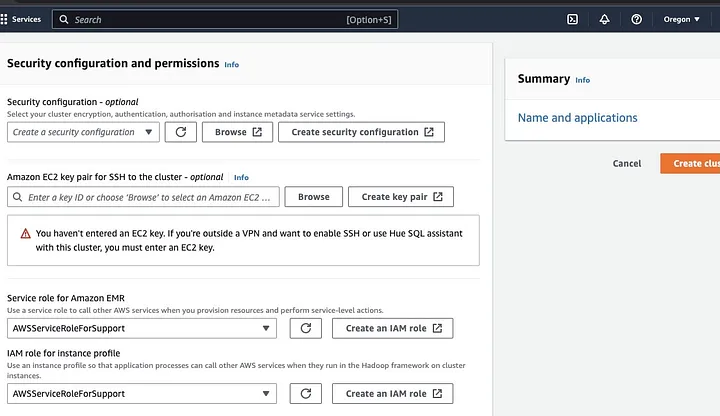
Luego haga clic en las opciones desplegables para “Rol de servicio para Amazon EMR” y elija AWSServiceRoleForSupport. Elija la misma opción desplegable para “Rol de IAM para perfil de instancia”. Actualice el icono si es necesario para obtener estas opciones desplegables.
Finalmente, haga clic en el botón “Crear clúster” para lanzar el clúster y monitorear el estado del clúster para validar que se ha creado.
Instalación y Configuración de Apache Spark en el Clúster EMR
Después de crear con éxito un clúster EMR, el siguiente paso será configurar Apache Spark en el Clúster EMR. Los clústeres EMR proporcionan un entorno administrado para ejecutar aplicaciones Spark en la infraestructura de AWS, lo que facilita el lanzamiento y la gestión de clústeres Spark en la nube. Configura Spark para que funcione con sus datos y necesidades de procesamiento y luego envía trabajos Spark al clúster para procesar sus datos.
Puedes configurar Apache Spark en el clúster mediante el protocolo Secure Shell (SSH). Pero primero, necesitas autorizar las conexiones seguras de SSH a tu clúster, que se configuraron por defecto cuando creaste el clúster de EMR. Puedes encontrar una guía sobre cómo autorizar conexiones SSH aquí.
Para crear una conexión SSH, debes especificar la pareja de claves EC2 que seleccionaste al crear el clúster. Luego, conecta al clúster de EMR utilizando la shell de Spark, primero conectando al nodo principal. Primero necesitas obtener el DNS público del nodo principal navegando a la izquierda de la consola de AWS, bajo EMR en EC2, elige Clústeres y luego selecciona el clúster del nombre de DNS público que deseas obtener.
En tu terminal de OS, introduce el siguiente comando.
ssh hadoop@ec2-###-##-##-###.compute-1.amazonaws.com -i ~/mykeypair.pemReemplaza el ec2-###-##-##-###.compute-1.amazonaws.com con el nombre de tu DNS público maestro y el ~/mykeypair.pem con el nombre de archivo y la ruta de tu archivo .pem (Sigue esta guía para obtener el archivo .pem aquí). Aparecerá un mensaje de aviso al que tu respuesta debería ser sí; escribe exit para cerrar el comando SSH.
Preparando Datos para Procesamiento con Spark y Subiéndolos al Bucket de S3
El procesamiento de datos requiere preparación antes de subirlos para presentarlos en un formato que Spark pueda procesar fácilmente. El formato utilizado está influenciado por el tipo de datos que tienes y el análisis que planeas realizar. Algunos formatos utilizados incluyen CSV, JSON y Parquet.
Crea una nueva sesión de Spark y carga tus datos en Spark utilizando la API relevante. Por ejemplo, utiliza el método spark.read.csv() para leer archivos CSV en un DataFrame de Spark.
Amazon EMR, un servicio administrado para clústeres del ecosistema de Hadoop, puede usarse para procesar datos. Reduce la necesidad de configurar, ajustar y mantener clústeres. También cuenta con otras integraciones con Amazon SageMaker, por ejemplo, para iniciar un trabajo de entrenamiento de modelos de SageMaker desde una canalización de Spark en Amazon EMR.
Una vez que tus datos estén listos, utilizando el método DataFrame.write.format("s3"), puedes leer un archivo CSV desde el bucket de Amazon S3 en un DataFrame de Spark. Deberías haber configurado tus credenciales de AWS y tener permisos de escritura para acceder al bucket de S3.
Indica el bucket y la ruta de S3 donde deseas guardar los datos. Por ejemplo, puedes utilizar el método df.write.format("s3").save("s3://mi-bucket/ruta/a/datos") para guardar los datos en el bucket de S3 especificado.
Una vez que los datos se guardan en el bucket de S3, puedes acceder a ellos desde otras aplicaciones de Spark o herramientas, o puedes descargarlo para realizar un análisis o procesamiento adicional. Para cargar el bucket, crea una carpeta y elige el bucket que inicialmente creaste. Selecciona el botón de Acciones y haz clic en “Crear Carpeta” en los elementos desplegables. Ahora puedes nombrar la nueva carpeta.
Para cargar los archivos de datos en el bucket, seleccione el nombre de la carpeta de datos.
En la sección de Cargar — Seleccione “Asistente de archivos” y elija Agregar Archivos.
Siga las indicaciones en la consola de Amazon S3 para cargar los archivos y seleccione “Iniciar Carga”.
Es crucial considerar y asegurar las mejores prácticas para proteger sus datos antes de cargarlos en el bucket de S3.
Comprensión de Formatos y Esquemas de Datos
Los formatos y esquemas de datos son dos conceptos relacionados pero completamente diferentes e importantes en la gestión de datos. El formato de datos se refiere a la organización y estructura de los datos dentro de la base de datos. Existen varios formatos para almacenar datos, como CSV, JSON, XML, YAML, etc. Estos formatos definen cómo se debe estructurar los datos junto con los diferentes tipos de datos y aplicaciones aplicables a ellos. Mientras que los esquemas de datos son la estructura de la base de datos en sí. Define el diseño de la base de datos y asegura que los datos se almacenen adecuadamente. Un esquema de base de datos especifica las vistas, tablas, índices, tipos y otros elementos. Estos conceptos son importantes en el análisis y la visualización de la base de datos.
Limpieza y Preprocesamiento de Datos en S3
Es esencial verificar dos veces por errores en sus datos antes de procesarlo. Para comenzar, acceda a la carpeta de datos en la que guardó el archivo de datos en su bucket de S3 y descárguelo en su máquina local. A continuación, cargará los datos en la herramienta de procesamiento de datos, que se utilizará para limpiar y preprocesar los datos. Para este tutorial, la herramienta de preprocesamiento utilizada es Amazon Athena, que ayuda a analizar datos estructurados y no estructurados almacenados en Amazon S3.
Ve a Amazon Athena en la consola de AWS.
Haz clic en “Crear” para crear una nueva tabla y luego en “CREAR TABLA”.
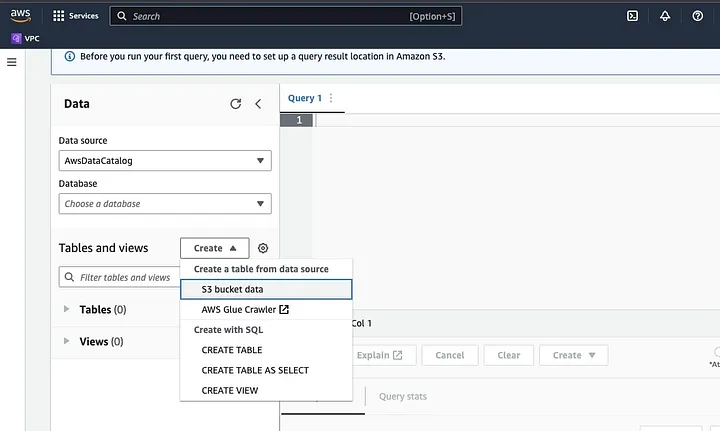
Escribe la ruta de tu archivo de datos en la parte resaltada como UBICACIÓN.
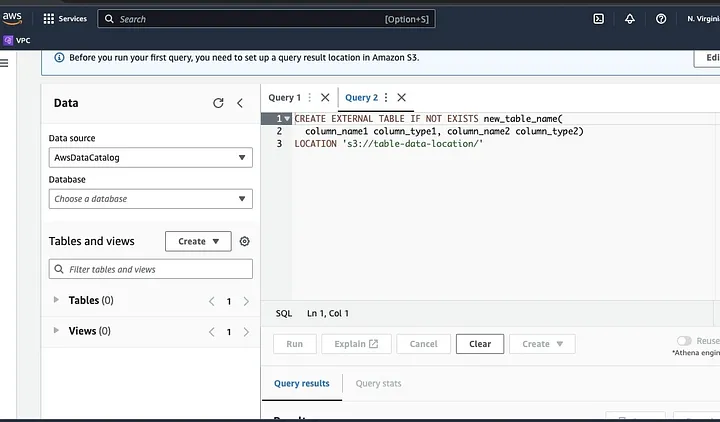
Continúa con las indicaciones para definir el esquema para los datos y guarda la tabla. Ahora, puedes ejecutar una consulta para validar que los datos se cargaron correctamente y luego limpiar y preprocesar los datos
Un ejemplo:
Esta consulta identifica los duplicados presentes en los datos.
SELECT row1, row2, COUNT(*)
FROM table
GROUP row, row2
HAVING COUNT(*) > 1;Este ejemplo crea una nueva tabla sin los duplicados:
CREATE TABLE new_table AS
SELECT DISTINCT *
FROM table;Finalmente, exporta los datos limpios de vuelta a S3 navegando al bucket de S3 y la carpeta para subir el archivo.
Entendiendo el Marco de Trabajo Spark
El marco de trabajo Spark es un sistema de cómputo de clústeres abierto, sencillo y expresivo que fue creado para el desarrollo rápido. Está basado en el lenguaje de programación Java y sirve como alternativa a otros marcos de Java. La característica principal de Spark es su capacidad de cómputo de datos en memoria que acelera el procesamiento de grandes conjuntos de datos.
Configurando Spark Para Trabajar Con S3
Para configurar Spark para que trabaje con S3, comienza agregando la dependencia de Hadoop AWS a tu aplicación de Spark. Haz esto agregando la siguiente línea a tu archivo de compilación (por ejemplo, build.sbt para Scala o pom.xml para Java):
libraryDependencies += "org.apache.hadoop" % "hadoop-aws" % "3.3.1"Ingresa la clave de acceso de AWS y la clave de acceso secreta en tu aplicación de Spark configurando las siguientes propiedades:
spark.hadoop.fs.s3a.access.key <ACCESS_KEY_ID>
spark.hadoop.fs.s3a.secret.key <SECRET_ACCESS_KEY>Establece las siguientes propiedades usando el objeto SparkConf en tu código:
val conf = new SparkConf()
.set("spark.hadoop.fs.s3a.access.key", "<ACCESS_KEY_ID>")
.set("spark.hadoop.fs.s3a.secret.key", "<SECRET_ACCESS_KEY>")Establece la URL del punto de acceso de S3 en tu aplicación Spark configurando la siguiente propiedad de configuración:
spark.hadoop.fs.s3a.endpoint s3.<REGION>.amazonaws.com Reemplaza <REGION> con la región de AWS donde se encuentra tu bucket de S3 (por ejemplo, us-east-1).
Se requiere un nombre de bucket compatible con DNS para otorgar al cliente de S3 en Hadoop acceso a las solicitudes de S3. Si tu nombre de bucket contiene puntos o guiones bajos, es posible que debas habilitar el acceso de estilo de ruta para el cliente de S3 en Hadoop, que utiliza un estilo de host virtual. Establece la siguiente propiedad de configuración para habilitar el acceso de estilo de ruta:
spark.hadoop.fs.s3a.path.style.access true Por último, crea una sesión de Spark con la configuración de S3 estableciendo el prefijo spark.hadoop en la configuración de Spark:
val spark = SparkSession.builder()
.appName("MyApp")
.config("spark.hadoop.fs.s3a.access.key", "<ACCESS_KEY_ID>")
.config("spark.hadoop.fs.s3a.secret.key", "<SECRET_ACCESS_KEY>")
.config("spark.hadoop.fs.s3a.endpoint", "s3.<REGION>.amazonaws.com")
.getOrCreate() Reemplaza los campos de <ACCESS_KEY_ID>, <SECRET_ACCESS_KEY>, y <REGION> con tus credenciales de AWS y la región de S3.
Para leer los datos de S3 en Spark, se utilizará el método spark.read, y luego se especificará la ruta de S3 a tus datos como fuente de entrada.
Un ejemplo de código que demuestra cómo leer un archivo CSV de S3 en un DataFrame en Spark:
val spark = SparkSession.builder()
.appName("ReadDataFromS3")
.getOrCreate()
val df = spark.read
.option("header", "true") // Specify whether the first line is the header or not
.option("inferSchema", "true") // Infer the schema automatically
.csv("s3a://<BUCKET_NAME>/<FILE_PATH>") En este ejemplo, reemplaza <BUCKET_NAME> con el nombre de tu bucket de S3 y <FILE_PATH> con la ruta a tu archivo CSV dentro del bucket.
Transformando Datos con Spark
Transformar datos con Spark generalmente se refiere a operaciones en datos para limpiar, filtrar, agrupar y unir datos. Spark ofrece un conjunto rico de APIs para la transformación de datos. Incluyen las API de DataFrame, Dataset y RDD. Algunas de las operaciones comunes de transformación de datos en Spark incluyen filtrar, seleccionar columnas, agrupar datos, unir datos y ordenar datos.
Aquí hay un ejemplo de operaciones de transformación de datos:
Ordenar datos: Esta operación implica ordenar datos en función de una o más columnas. El método orderBy o sort en un DataFrame o Dataset se utiliza para ordenar datos en función de una o más columnas. Por ejemplo:
val sortedData = df.orderBy(col("age").desc)Finalmente, es posible que necesites escribir el resultado de vuelta a S3 para almacenar los resultados.
Spark proporciona varias API para escribir datos en S3, como DataFrameWriter, DatasetWriter y RDD.saveAsTextFile.
El siguiente es un ejemplo de código que demuestra cómo escribir un DataFrame en S3 en formato Parquet:
val outputS3Path = "s3a://<BUCKET_NAME>/<OUTPUT_DIRECTORY>"
df.write
.mode(SaveMode.Overwrite)
.option("compression", "snappy")
.parquet(outputS3Path)Reemplaza el campo de entrada del <BUCKET_NAME> con el nombre de tu bucket de S3 y <OUTPUT_DIRECTORY> con la ruta al directorio de salida en el bucket.
El método mode especifica el modo de escritura, que puede ser Overwrite, Append, Ignore o ErrorIfExists. El método option se puede utilizar para especificar varias opciones para el formato de salida, como el codec de compresión.
También puedes escribir datos en S3 en otros formatos, como CSV, JSON y Avro, cambiando el formato de salida y especificando las opciones apropiadas.
Entendiendo la Particionamiento de Datos en Spark
En términos sencillos, el particionamiento de datos en Spark se refiere a la división del conjunto de datos en porciones más pequeñas y manejables a lo largo del clúster. El propósito de esto es optimizar el rendimiento, reducir la escalabilidad y, en última instancia, mejorar la administración de la base de datos. En Spark, los datos se procesan en paralelo en varios clústeres. Esto es posible gracias a los Conjuntos de Datos Distribuidos Resilientes (RDD), que son una colección de datos enormes y complejos. Por defecto, el RDD se particiona en varios nodos debido a su tamaño.
Para funcionar de manera óptima, hay formas de configurar Spark para asegurarse de que las tareas se ejecuten de manera oportuna y que los recursos se gestionen de manera efectiva. Algunas de estas incluyen el almacenamiento en caché, la gestión de memoria, la serialización de datos y el uso de mapPartitions() sobre map().
Spark UI es una interfaz gráfica basada en web que proporciona información detallada sobre el rendimiento y el uso de recursos de una aplicación Spark. Incluye varias páginas, como Visión general, Ejecutores, Fases y Tareas, que brindan información sobre diversos aspectos de un trabajo Spark. Spark UI es una herramienta esencial para monitorear y depurar aplicaciones Spark, ya que ayuda a identificar cuellos de botella de rendimiento y restricciones de recursos, y a solucionar errores. Al examinar métricas como el número de tareas completadas, la duración del trabajo, el uso de CPU y memoria, y los datos de shuffle escritos y leídos, los usuarios pueden optimizar sus trabajos Spark y asegurarse de que se ejecuten de manera eficiente.
Conclusión
En resumen, procesar tus datos en AWS S3 utilizando Apache Spark es una manera efectiva y escalable de analizar conjuntos de datos enormes. Al aprovechar los recursos de almacenamiento y cómputo basados en la nube de AWS S3 y Apache Spark, los usuarios pueden procesar sus datos de manera rápida y eficiente sin tener que preocuparse por la gestión de la arquitectura.
En este tutorial, revisamos la configuración de un bucket de S3 y un clúster de Apache Spark en AWS EMR, configurando Spark para que funcione con AWS S3, y escribiendo y ejecutando aplicaciones de Spark para procesar datos. También cubrimos la partición de datos en Spark, la interfaz de usuario de Spark y la optimización del rendimiento en Spark.
Referencia
Para un mayor detalle en la configuración de Spark para un rendimiento óptimo, consultaaquí.
https://docs.aws.amazon.com/emr/latest/ManagementGuide/emr-connect-master-node-ssh.html
Source:
https://dzone.com/articles/stateful-stream-processing-with-memphis-and-apache-spark