













Introducción
El modelo de datos relacional, que organiza datos en tablas de filas y columnas, predomina en herramientas de gestión de bases de datos. Hoy en día existen otros modelos de datos, incluyendo NoSQL y NewSQL, pero los sistemas de gestión de bases de datos relacionales (RDBMSs) siguen siendo dominantes para almacenar y administrar datos a nivel mundial.
Este artículo compara y contrasta tres de los RDBMSs de código abierto más ampliamente implementados: SQLite, MySQL y PostgreSQL. Específicamente, explorará los tipos de datos que utiliza cada RDBMS, sus ventajas y desventajas, y las situaciones en las que están mejor optimizados.
A Bit About Database Management Systems
Las bases de datos son agrupaciones lógicamente modeladas de información o datos. Por otro lado, un sistema de gestión de bases de datos (DBMS) es un programa informático que interactúa con una base de datos. Un DBMS te permite controlar el acceso a una base de datos, escribir datos, ejecutar consultas y realizar cualquier otra tarea relacionada con la gestión de bases de datos.
Aunque los sistemas de gestión de bases de datos a menudo se denominan “bases de datos”, los dos términos no son intercambiables. Una base de datos puede ser cualquier colección de datos, no solo una almacenada en una computadora. En contraste, un DBMS se refiere específicamente al software que te permite interactuar con una base de datos.
Todos los sistemas de gestión de bases de datos tienen un modelo subyacente que estructura cómo se almacenan y acceden los datos. Un sistema de gestión de bases de datos relacionales es un DBMS que emplea el modelo de datos relacional. En este modelo relacional, los datos se organizan en tablas. Las tablas, en el contexto de los RDBMS, se conocen más formalmente como relaciones. Una relación es un conjunto de tuplas, que son las filas en una tabla, y cada tupla comparte un conjunto de atributos, que son las columnas en una tabla:
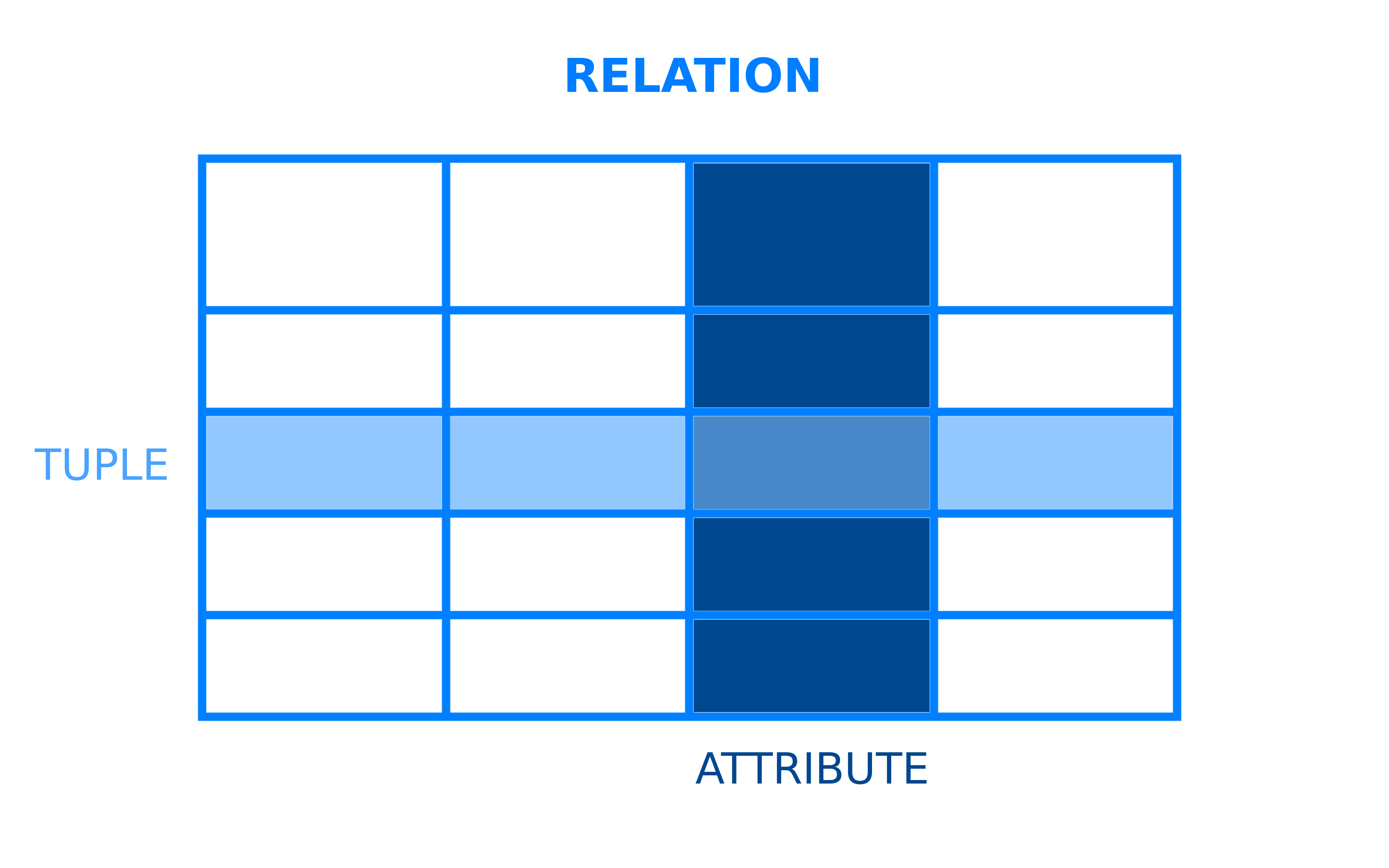
La mayoría de las bases de datos relacionales utilizan el lenguaje estructurado de consultas (SQL) para gestionar y consultar datos. Sin embargo, muchos RDBMS utilizan su propio dialecto particular de SQL, que puede tener ciertas limitaciones o extensiones. Estas extensiones suelen incluir características adicionales que permiten a los usuarios realizar operaciones más complejas de lo que podrían hacer con SQL estándar.
Nota: El término “SQL estándar” aparece varias veces a lo largo de esta guía. Los estándares de SQL son mantenidos conjuntamente por el Instituto Nacional Estadounidense de Estándares (ANSI), la Organización Internacional de Normalización (ISO) y la Comisión Electrotécnica Internacional (IEC). Cuando este artículo menciona “SQL estándar” o “el estándar SQL”, se refiere a la versión actual del estándar SQL publicado por estos organismos.
Debe tenerse en cuenta que el estándar completo de SQL es grande y complejo: el cumplimiento completo de SQL:2011 requiere 179 características. Debido a esto, la mayoría de los sistemas de gestión de bases de datos relacionales (RDBMS) no admiten todo el estándar, aunque algunos se acercan más al cumplimiento total que otros.
Tipos de datos y restricciones
A cada columna se le asigna un tipo de dato que dicta qué tipo de entradas se permiten en esa columna. Los diferentes RDBMS implementan diferentes tipos de datos, que no siempre son directamente intercambiables. Algunos tipos de datos comunes incluyen fechas, cadenas, enteros y valores booleanos.
Almacenar enteros en una base de datos es más matizado que poner números en una tabla. Los tipos de datos numéricos pueden ser con signo, lo que significa que pueden representar números positivos y negativos, o sin signo, lo que significa que solo pueden representar números positivos. Por ejemplo, el tipo de dato tinyint de MySQL puede contener 8 bits de datos, lo que equivale a 256 valores posibles. El rango con signo de este tipo de datos es de -128 a 127, mientras que el rango sin signo es de 0 a 255.
Poder controlar qué datos se permiten en una base de datos es importante. A veces, un administrador de bases de datos impondrá una restricción en una tabla para limitar qué valores se pueden ingresar en ella. Una restricción típicamente se aplica a una columna en particular, pero algunas restricciones también pueden aplicarse a toda una tabla. Aquí hay algunas restricciones que se utilizan comúnmente en SQL:
ÚNICO: Aplicar esta restricción a una columna asegura que no haya dos entradas idénticas en esa columna.NO NULO: Esta restricción asegura que una columna no tenga ninguna entradaNULL.CLAVE PRIMARIA: Una combinación deÚNICOyNO NULO, la restricción deCLAVE PRIMARIAasegura que ninguna entrada en la columna seaNULLy que cada entrada sea distinta.CLAVE FORÁNEA: UnaCLAVE FORÁNEAes una columna en una tabla que se refiere a laCLAVE PRIMARIAde otra tabla. Esta restricción se utiliza para vincular dos tablas. Las entradas en la columna deCLAVE FORÁNEAdeben existir previamente en la columna deCLAVE PRIMARIAprincipal para que el proceso de escritura tenga éxito.CHEQUEO: Esta restricción limita el rango de valores que pueden ingresarse en una columna. Por ejemplo, si tu aplicación está destinada solo para residentes de Alaska, podrías agregar una restricción deCHEQUEOen una columna de código postal para permitir solo entradas entre 99501 y 99950.
Si deseas obtener más información sobre sistemas de gestión de bases de datos, consulta nuestro artículo sobre Una Comparación de Sistemas y Modelos de Gestión de Bases de Datos NoSQL.
Ahora que hemos cubierto los sistemas de gestión de bases de datos relacionales en general, pasemos al primero de los tres sistemas de bases de datos relacionales de código abierto que cubriremos en este artículo: SQLite.
SQLite
SQLite es un sistema de gestión de bases de datos relacionales (RDBMS) autocontenido, basado en archivos y totalmente de código abierto, conocido por su portabilidad, confiabilidad y sólido rendimiento incluso en entornos de memoria limitada. Sus transacciones cumplen con las propiedades ACID, incluso en casos de fallo del sistema o cortes de energía.
El sitio web del proyecto SQLite lo describe como una base de datos “sin servidor”. La mayoría de los motores de bases de datos relacionales se implementan como un proceso de servidor en el cual los programas se comunican con el servidor host a través de una comunicación entre procesos que relaya las solicitudes. En contraste, SQLite permite que cualquier proceso que acceda a la base de datos lea y escriba directamente en el archivo de disco de la base de datos. Esto simplifica el proceso de configuración de SQLite, ya que elimina la necesidad de configurar un proceso de servidor. De igual manera, no se necesita configuración para los programas que utilizarán la base de datos SQLite: todo lo que necesitan es acceso al disco.
SQLite es software gratuito y de código abierto, y no se requiere una licencia especial para usarlo. Sin embargo, el proyecto ofrece varias extensiones, cada una por un pago único, que ayudan con la compresión y el cifrado. Además, el proyecto ofrece varios paquetes de soporte comercial, cada uno por una tarifa anual.
Tipos de datos admitidos por SQLite
SQLite permite una variedad de tipos de datos, organizados en las siguientes clases de almacenamiento:
| Data Type | Explanation |
|---|---|
null |
Includes any NULL values. |
integer |
Signed integers, stored in 1, 2, 3, 4, 6, or 8 bytes depending on the magnitude of the value. |
real |
Real numbers, or floating point values, stored as 8-byte floating point numbers. |
text |
Text strings stored using the database encoding, which can either be UTF-8, UTF-16BE or UTF-16LE. |
blob |
Any blob of data, with every blob stored exactly as it was input. |
En el contexto de SQLite, los términos “clase de almacenamiento” y “tipo de datos” se consideran intercambiables. Si deseas obtener más información sobre los tipos de datos de SQLite y la afinidad de tipos de SQLite, consulta la documentación oficial de SQLite sobre el tema.
Ventajas de SQLite
- Pequeña huella: Como su nombre indica, la biblioteca SQLite es muy ligera. Aunque el espacio que utiliza varía dependiendo del sistema donde está instalado, puede ocupar menos de 600 KiB de espacio. Además, es completamente autónomo, lo que significa que no hay dependencias externas que debas instalar en tu sistema para que SQLite funcione.
- Amigable para el usuario: SQLite a veces se describe como una base de datos “sin configuración” que está lista para usar de inmediato. SQLite no se ejecuta como un proceso de servidor, lo que significa que nunca necesita detenerse, iniciarse o reiniciarse y no viene con ningún archivo de configuración que necesite administrarse. Estas características ayudan a simplificar el proceso desde la instalación de SQLite hasta la integración con una aplicación.
- Portable: A diferencia de otros sistemas de gestión de bases de datos, que típicamente almacenan datos como un gran lote de archivos separados, toda la base de datos de SQLite se almacena en un solo archivo. Este archivo puede ubicarse en cualquier lugar en una jerarquía de directorios, y se puede compartir a través de medios extraíbles o protocolo de transferencia de archivos.
Desventajas de SQLite
- Concurrencia limitada: Aunque varios procesos pueden acceder y consultar una base de datos de SQLite al mismo tiempo, solo un proceso puede realizar cambios en la base de datos en un momento dado. Esto significa que aunque SQLite admite una mayor concurrencia que la mayoría de otros sistemas de gestión de bases de datos integrados, no puede admitir tanto como los sistemas de gestión de bases de datos cliente/servidor como MySQL o PostgreSQL.
- Sin gestión de usuarios: Los sistemas de bases de datos a menudo vienen con soporte para usuarios, o conexiones gestionadas con privilegios de acceso predefinidos a la base de datos y tablas. Debido a que SQLite lee y escribe directamente en un archivo de disco ordinario, los únicos permisos de acceso aplicables son los permisos de acceso típicos del sistema operativo subyacente. Esto hace que SQLite sea una opción deficiente para aplicaciones que requieren múltiples usuarios con permisos de acceso especiales.
- Seguridad: Un motor de base de datos que utiliza un servidor puede, en algunos casos, proporcionar una mejor protección contra errores en la aplicación cliente que una base de datos sin servidor como SQLite. Por ejemplo, los punteros perdidos en un cliente no pueden corromper la memoria en el servidor. Además, debido a que un servidor es un único proceso persistente, una base de datos cliente-servidor puede controlar el acceso a los datos con más precisión que una base de datos sin servidor. Esto permite un bloqueo más detallado y una mejor concurrencia.
Cuándo usar SQLite
- Aplicaciones integradas: SQLite es una excelente opción de base de datos para aplicaciones que necesitan portabilidad y no requieren expansión futura. Ejemplos incluyen aplicaciones locales de un solo usuario, aplicaciones móviles o juegos.
- Reemplazo de acceso a disco: En casos donde una aplicación necesita leer y escribir archivos directamente en disco, puede ser beneficioso usar SQLite por la funcionalidad adicional y la simplicidad que ofrece el uso de SQL.
- Pruebas: Para muchas aplicaciones puede ser excesivo probar su funcionalidad con un DBMS que utiliza un proceso de servidor adicional. SQLite tiene un modo en memoria que se puede utilizar para ejecutar pruebas rápidamente sin la sobrecarga de operaciones de base de datos reales, lo que lo convierte en una opción ideal para las pruebas.
Cuándo no utilizar SQLite
- Trabajar con grandes cantidades de datos: SQLite puede técnicamente admitir una base de datos de hasta 140TB de tamaño, siempre que el disco duro y el sistema de archivos también cumplan con los requisitos de tamaño de la base de datos. Sin embargo, el sitio web de SQLite recomienda que cualquier base de datos que se aproxime a 1TB se aloje en una base de datos cliente-servidor centralizada, ya que una base de datos SQLite de ese tamaño o más grande sería difícil de gestionar.
- Volúmenes altos de escritura: SQLite permite que solo se realice una operación de escritura a la vez, lo que limita significativamente su rendimiento. Si su aplicación requiere muchas operaciones de escritura o escritores concurrentes múltiples, SQLite puede no ser adecuado para sus necesidades.
- Se requiere acceso a la red: Debido a que SQLite es una base de datos sin servidor, no proporciona acceso directo a la red a sus datos. Este acceso está incorporado en la aplicación. Si los datos en SQLite están ubicados en una máquina separada de la aplicación, se requerirá un enlace de alta velocidad entre el motor y el disco a través de la red. Esta es una solución costosa e ineficiente, y en tales casos puede ser una mejor opción un sistema de gestión de bases de datos cliente-servidor.
MySQL
Según el Ranking de DB-Engines, MySQL ha sido el sistema de gestión de bases de datos relacional de código abierto más popular desde que el sitio comenzó a rastrear la popularidad de las bases de datos en 2012. Es un producto rico en características que impulsa muchos de los sitios web y aplicaciones más grandes del mundo, incluidos Twitter, Facebook, Netflix y Spotify. Empezar con MySQL es relativamente sencillo, en gran parte gracias a su documentación exhaustiva y a su amplia comunidad de desarrolladores, así como a la abundancia de recursos relacionados con MySQL en línea.
MySQL fue diseñado para ser rápido y confiable, a expensas de cumplir totalmente con el estándar SQL. Los desarrolladores de MySQL trabajan continuamente para cumplir más de cerca con el estándar SQL, pero aún está por detrás de otras implementaciones de SQL. Sin embargo, viene con varios modos y extensiones de SQL que lo acercan más al cumplimiento.
A diferencia de las aplicaciones que utilizan SQLite, las aplicaciones que usan una base de datos MySQL acceden a ella a través de un proceso de demonio separado. Debido a que el proceso del servidor se encuentra entre la base de datos y otras aplicaciones, permite un mayor control sobre quién tiene acceso a la base de datos.
MySQL ha inspirado una gran cantidad de aplicaciones de terceros, herramientas y bibliotecas integradas que extienden su funcionalidad y ayudan a facilitar su uso. Algunas de las herramientas de terceros más utilizadas son phpMyAdmin, DBeaver y HeidiSQL.
Tipos de Datos Soportados por MySQL
Los tipos de datos de MySQL pueden organizarse en tres categorías principales: tipos numéricos, tipos de fecha y hora, y tipos de cadena.
Tipos numéricos:
| Data Type | Explanation |
|---|---|
tinyint |
A very small integer. The signed range for this numeric data type is -128 to 127, while the unsigned range is 0 to 255. |
smallint |
A small integer. The signed range for this numeric type is -32768 to 32767, while the unsigned range is 0 to 65535. |
mediumint |
A medium-sized integer. The signed range for this numeric data type is -8388608 to 8388607, while the unsigned range is 0 to 16777215. |
int or integer |
A normal-sized integer. The signed range for this numeric data type is -2147483648 to 2147483647, while the unsigned range is 0 to 4294967295. |
bigint |
A large integer. The signed range for this numeric data type is -9223372036854775808 to 9223372036854775807, while the unsigned range is 0 to 18446744073709551615. |
float |
A small (single-precision) floating-point number. |
double, double precision, or real |
A normal sized (double-precision) floating-point number. |
dec, decimal, fixed, or numeric |
A packed fixed-point number. The display length of entries for this data type is defined when the column is created, and every entry adheres to that length. |
bool or boolean |
A Boolean is a data type that only has two possible values, usually either true or false. |
bit |
A bit value type for which you can specify the number of bits per value, from 1 to 64. |
Tipos de fecha y hora:
| Data Type | Explanation |
|---|---|
date |
A date, represented as YYYY-MM-DD. |
datetime |
A timestamp showing the date and time, displayed as YYYY-MM-DD HH:MM:SS. |
timestamp |
A timestamp indicating the amount of time since the Unix epoch (00:00:00 on January 1, 1970). |
time |
A time of day, displayed as HH:MM:SS. |
year |
A year expressed in either a 2 or 4 digit format, with 4 digits being the default. |
Tipos de cadena:
| Data Type | Explanation |
|---|---|
char |
A fixed-length string; entries of this type are padded on the right with spaces to meet the specified length when stored. |
varchar |
A string of variable length. |
binary |
Similar to the char type, but a binary byte string of a specified length rather than a nonbinary character string. |
varbinary |
Similar to the varchar type, but a binary byte string of a variable length rather than a nonbinary character string. |
blob |
A binary string with a maximum length of 65535 (2^16 – 1) bytes of data. |
tinyblob |
A blob column with a maximum length of 255 (2^8 – 1) bytes of data. |
mediumblob |
A blob column with a maximum length of 16777215 (2^24 – 1) bytes of data. |
longblob |
A blob column with a maximum length of 4294967295 (2^32 – 1) bytes of data. |
text |
A string with a maximum length of 65535 (2^16 – 1) characters. |
tinytext |
A text column with a maximum length of 255 (2^8 – 1) characters. |
mediumtext |
A text column with a maximum length of 16777215 (2^24 – 1) characters. |
longtext |
A text column with a maximum length of 4294967295 (2^32 – 1) characters. |
enum |
An enumeration, which is a string object that takes a single value from a list of values that are declared when the table is created. |
set |
Similar to an enumeration, a string object that can have zero or more values, each of which must be chosen from a list of allowed values that are specified when the table is created. |
Ventajas de MySQL
- Popularidad y facilidad de uso: Como uno de los sistemas de bases de datos más populares del mundo, no hay escasez de administradores de bases de datos que tengan experiencia trabajando con MySQL. Del mismo modo, abunda la documentación impresa y en línea sobre cómo instalar y administrar una base de datos MySQL. Esto incluye una serie de herramientas de terceros, como phpMyAdmin, que tienen como objetivo simplificar el proceso de inicio con la base de datos.
- Seguridad: MySQL viene instalado con un script que te ayuda a mejorar la seguridad de tu base de datos al establecer el nivel de seguridad de la contraseña de la instalación, definir una contraseña para el usuario root, eliminar cuentas anónimas y eliminar bases de datos de prueba que, por defecto, son accesibles para todos los usuarios. Además, a diferencia de SQLite, MySQL admite la gestión de usuarios y te permite otorgar privilegios de acceso de manera individual a cada usuario.
- Velocidad: Al optar por no implementar ciertas características de SQL, los desarrolladores de MySQL pudieron priorizar la velocidad. Aunque pruebas de referencia más recientes muestran que otros sistemas de gestión de bases de datos relacionales como PostgreSQL pueden igualar o al menos acercarse a MySQL en términos de velocidad, MySQL aún conserva una reputación como una solución de base de datos excepcionalmente rápida.
- Replicación: MySQL admite varios tipos de replicación, que es la práctica de compartir información entre dos o más hosts para ayudar a mejorar la confiabilidad, disponibilidad y tolerancia a fallos. Esto es útil para configurar una solución de respaldo de base de datos o escalar horizontalmente una base de datos.
Desventajas de MySQL
- Limitaciones conocidas: Debido a que MySQL fue diseñado para velocidad y facilidad de uso en lugar de cumplir completamente con SQL, viene con ciertas limitaciones funcionales. Por ejemplo, carece de soporte para cláusulas
FULL JOIN. - Licencias y características propietarias: MySQL es software de doble licencia, con una edición comunitaria gratuita y de código abierto con licencia bajo GPLv2 y varias ediciones comerciales pagas lanzadas bajo licencias propietarias. Debido a esto, algunas características y complementos solo están disponibles para las ediciones propietarias.
- Desarrollo ralentizado: Desde que el proyecto MySQL fue adquirido por Sun Microsystems en 2008, y luego por Oracle Corporation en 2009, ha habido quejas de los usuarios de que el proceso de desarrollo para el DBMS se ha ralentizado significativamente, ya que la comunidad ya no tiene la capacidad de reaccionar rápidamente a los problemas e implementar cambios.
Cuándo usar MySQL
- Operaciones distribuidas: El soporte de replicación de MySQL lo convierte en una excelente opción para configuraciones de bases de datos distribuidas como arquitecturas primario-secundario o primario-primario.
- Sitios web y aplicaciones web: MySQL alimenta muchos sitios web y aplicaciones en Internet. Esto se debe en gran parte a lo fácil que es instalar y configurar una base de datos MySQL, así como a su velocidad general y escalabilidad a largo plazo.
- Crecimiento futuro esperado: El soporte de replicación de MySQL puede ayudar a facilitar la escalabilidad horizontal. Además, es un proceso relativamente sencillo actualizar a un producto MySQL comercial, como MySQL Cluster, que admite fragmentación automática, otro proceso de escalabilidad horizontal.
Cuándo no usar MySQL
- La conformidad con SQL es necesaria: Dado que MySQL no intenta implementar completamente el estándar SQL, esta herramienta no es completamente compatible con SQL. Si la conformidad completa o casi completa con SQL es imprescindible para su caso de uso, es posible que desee utilizar un sistema de gestión de bases de datos (DBMS) más compatible.
- Concurrencia y grandes volúmenes de datos: Aunque MySQL generalmente funciona bien con operaciones de lectura intensiva, las lecturas-escrituras concurrentes pueden ser problemáticas. Si su aplicación tendrá muchos usuarios escribiendo datos en ella al mismo tiempo, otro RDBMS como PostgreSQL podría ser una mejor elección de base de datos.
PostgreSQL
PostgreSQL, también conocido como Postgres, se presenta como “la base de datos relacional de código abierto más avanzada del mundo”. Fue creado con el objetivo de ser altamente extensible y compatible con los estándares. PostgreSQL es una base de datos relacional-objeto, lo que significa que aunque es principalmente una base de datos relacional, también incluye características, como la herencia de tablas y la sobrecarga de funciones, que están más asociadas con bases de datos de objetos.
Postgres es capaz de manejar eficientemente múltiples tareas al mismo tiempo, una característica conocida como concurrencia. Logra esto sin bloqueos de lectura gracias a su implementación de Control de Concurrencia Multiversión (MVCC), que asegura la atomicidad, consistencia, aislamiento y durabilidad de sus transacciones, también conocido como cumplimiento ACID.
PostgreSQL no es tan ampliamente utilizado como MySQL, pero aún existen varios herramientas y bibliotecas de terceros diseñadas para simplificar el trabajo con PostgreSQL, incluyendo pgAdmin y Postbird.
Tipos de Datos Soportados por PostgreSQL
PostgreSQL soporta tipos de datos numéricos, de cadena, de fecha y hora, al igual que MySQL. Además, soporta tipos de datos para formas geométricas, direcciones de red, cadenas de bits, búsquedas de texto y entradas JSON, así como varios tipos de datos idiosincrásicos.
Tipos numéricos:
| Data Type | Explanation |
|---|---|
bigint |
A signed 8 byte integer. |
bigserial |
An auto-incrementing 8 byte integer. |
double precision |
An 8 byte double precision floating-point number. |
integer |
A signed 4 byte integer. |
numeric or decimal |
A number of selectable precision, recommended for use in cases where exactness is crucial, such as monetary amounts. |
real |
A 4 byte single precision floating-point number. |
smallint |
A signed 2 byte integer. |
smallserial |
An auto-incrementing 2 byte integer. |
serial |
An auto-incrementing 4 byte integer. |
Tipos de caracteres:
| Data Type | Explanation |
|---|---|
character |
A character string with a specified fixed length. |
character varying or varchar |
A character string with a variable but limited length. |
text |
A character string of a variable, unlimited length. |
Tipos de fecha y hora:
| Data Type | Explanation |
|---|---|
date |
A calendar date consisting of the day, month, and year. |
interval |
A time span. |
time or time without time zone |
A time of day, not including the time zone. |
time with time zone |
A time of day, including the time zone. |
timestamp or timestamp without time zone |
A date and time, not including the time zone. |
timestamp with time zone |
A date and time, including the time zone. |
Tipos geométricos:
| Data Type | Explanation |
|---|---|
box |
A rectangular box on a plane. |
circle |
A circle on a plane. |
line |
An infinite line on a plane. |
lseg |
A line segment on a plane. |
path |
A geometric path on a plane. |
point |
A geometric point on a plane. |
polygon |
A closed geometric path on a plane. |
Tipos de dirección de red:
| Data Type | Explanation |
|---|---|
cidr |
An IPv4 or IPv6 network address. |
inet |
An IPv4 or IPv6 host address. |
macaddr |
A Media Access Control (MAC) address. |
Tipos de cadena de bits:
| Data Type | Explanation |
|---|---|
bit |
A fixed-length bit string. |
bit varying |
A variable-length bit string. |
Tipos de búsqueda de texto:
| Data Type | Explanation |
|---|---|
tsquery |
A text search query. |
tsvector |
A text search document. |
Tipos JSON:
| Data Type | Explanation |
|---|---|
json |
Textual JSON data. |
jsonb |
Decomposed binary JSON data. |
Otros tipos de datos:
| Data Type | Explanation |
|---|---|
boolean |
A logical Boolean, representing either true or false. |
bytea |
Short for “byte array”, this type is used for binary data. |
money |
An amount of currency. |
pg_lsn |
A PostgreSQL Log Sequence Number. |
txid_snapshot |
A user-level transaction ID snapshot. |
uuid |
A universally unique identifier. |
xml |
XML data. |
Ventajas de PostgreSQL
- Compatibilidad con SQL: Más que SQLite o MySQL, PostgreSQL tiene como objetivo adherirse estrechamente a los estándares SQL. Según la documentación oficial de PostgreSQL, PostgreSQL admite 160 de los 179 elementos necesarios para cumplir con la plena compatibilidad con SQL:2011, además de una larga lista de funciones opcionales.
- De código abierto y dirigido por la comunidad: Como proyecto totalmente de código abierto, el código fuente de PostgreSQL es desarrollado por una gran y dedicada comunidad. Del mismo modo, la comunidad de Postgres mantiene y contribuye a numerosos recursos en línea que describen cómo trabajar con el sistema de gestión de bases de datos, incluyendo la documentación oficial, el wiki de PostgreSQL, y varios foros en línea.
- Extensible: Los usuarios pueden extender PostgreSQL de forma programática y sobre la marcha a través de su operación impulsada por catálogos y su uso de carga dinámica. Se puede designar un archivo de código de objeto, como una biblioteca compartida, y PostgreSQL lo cargará según sea necesario.
Desventajas de PostgreSQL
- Rendimiento de memoria: Por cada nueva conexión de cliente, PostgreSQL crea un nuevo proceso. A cada nuevo proceso se le asignan aproximadamente 10 MB de memoria, lo que puede acumularse rápidamente para bases de datos con muchas conexiones. En consecuencia, para operaciones simples con muchas lecturas, PostgreSQL suele ser menos eficiente en comparación con otros sistemas de gestión de bases de datos relacionales, como MySQL.
- Popularidad: Aunque se ha utilizado más ampliamente en los últimos años, PostgreSQL históricamente ha quedado rezagado detrás de MySQL en términos de popularidad. Una consecuencia de esto es que todavía hay menos herramientas de terceros que pueden ayudar a gestionar una base de datos PostgreSQL. Del mismo modo, no hay tantos administradores de bases de datos con experiencia en la gestión de una base de datos Postgres en comparación con aquellos con experiencia en MySQL.
Cuándo usar PostgreSQL
- La integridad de los datos es importante: PostgreSQL ha sido completamente compatible con ACID desde 2001 e implementa control de concurrencia de múltiples versiones para garantizar que los datos permanezcan consistentes, lo que lo convierte en una opción sólida de sistema de gestión de bases de datos relacionales cuando la integridad de los datos es crítica.
- Integración con otras herramientas: PostgreSQL es compatible con una amplia variedad de lenguajes de programación y plataformas. Esto significa que si alguna vez necesitas migrar tu base de datos a otro sistema operativo o integrarla con una herramienta específica, probablemente será más fácil con una base de datos PostgreSQL que con otro sistema de gestión de bases de datos.
- Operaciones complejas: Postgres admite planes de consulta que pueden aprovechar múltiples CPUs para responder consultas con mayor rapidez. Esto, junto con su sólido soporte para múltiples escritores concurrentes, lo convierte en una excelente opción para operaciones complejas como el almacenamiento de datos y el procesamiento de transacciones en línea.
Cuándo no usar PostgreSQL
- La velocidad es imperativa: A expensas de la velocidad, PostgreSQL fue diseñado con la extensibilidad y la compatibilidad en mente. Si tu proyecto requiere las operaciones de lectura más rápidas posibles, PostgreSQL puede no ser la mejor opción de SGBD.
- Configuraciones simples: Debido a su amplio conjunto de características y su sólido cumplimiento de SQL estándar, Postgres puede ser excesivo para configuraciones de bases de datos simples. Para operaciones con una alta carga de lectura donde se requiere velocidad, MySQL suele ser una opción más práctica.
- Replicación compleja: Aunque PostgreSQL ofrece un sólido soporte para la replicación, sigue siendo una característica relativamente nueva. Algunas configuraciones, como la arquitectura primaria-primaria, solo son posibles con extensiones. La replicación es una característica más madura en MySQL y muchos usuarios consideran que la replicación de MySQL es más fácil de implementar, especialmente para aquellos que carecen de la experiencia necesaria en administración de bases de datos y sistemas.
Conclusión
Hoy en día, SQLite, MySQL y PostgreSQL son los tres sistemas de gestión de bases de datos relacionales de código abierto más populares en el mundo. Cada uno tiene sus propias características y limitaciones únicas, y sobresale en escenarios particulares. Hay bastantes variables en juego al decidir sobre un RDBMS, y la elección rara vez es tan simple como elegir el más rápido o el que tiene más funciones. La próxima vez que necesites una solución de base de datos relacional, asegúrate de investigar a fondo estas y otras herramientas para encontrar la que mejor se adapte a tus necesidades.
Si deseas aprender más sobre SQL y cómo usarlo para gestionar una base de datos relacional, te animamos a consultar nuestra hoja de trucos Cómo gestionar una base de datos SQL. Por otro lado, si deseas aprender sobre bases de datos no relacionales (o NoSQL), echa un vistazo a nuestra Comparación de sistemas de gestión de bases de datos NoSQL.