













Shift-izquierda es un enfoque en el desarrollo y la operación de software que enfatiza la prueba, el monitoreo y la automatización desde etapas tempranas del ciclo de vida del software. El objetivo del enfoque shift-izquierda es prevenir problemas antes de que surjan, detectándolos temprano y abordándolos rápidamente.
Cuando identificas un problema de escalabilidad o un error temprano, es más rápido y económico solucionarlo. Mover código ineficiente a contenedores en la nube puede ser costoso, ya que puede activar el escalado automático y aumentar tu factura mensual. Además, estarás en una situación de emergencia hasta que puedas identificar, aislar y solucionar el problema.
Declaración del Problema
I would like to demonstrate to you a case where we managed to avert a potential issue with an application that could have caused a major issue in a production environment.
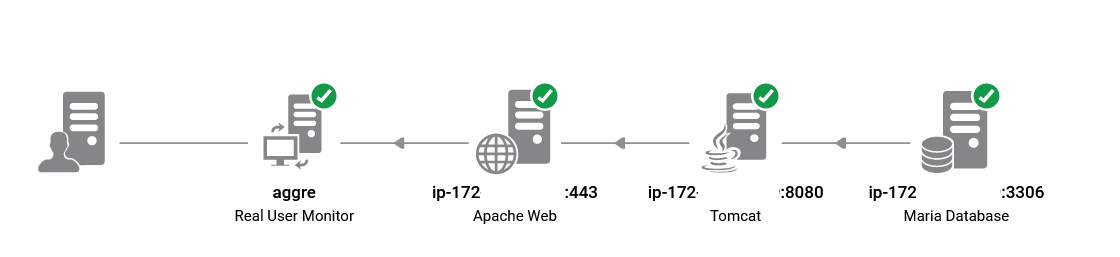
I was reviewing the performance report of the UAT infrastructure following the recent application change. It was a Spring Boot microservice with MariaDB as the backend, running behind Apache reverse proxy and AWS application load balancer. The new feature was successfully integrated, and all UAT test cases are passed. However, I noticed the performance charts in the MariaDB performance dashboard deviated from pre-deployment patterns.
Esta es la línea de tiempo de los eventos.
El 6 de agosto a las 14:13, la aplicación fue reiniciada con un nuevo archivo jar de Spring Boot que contiene un Tomcat embebido.
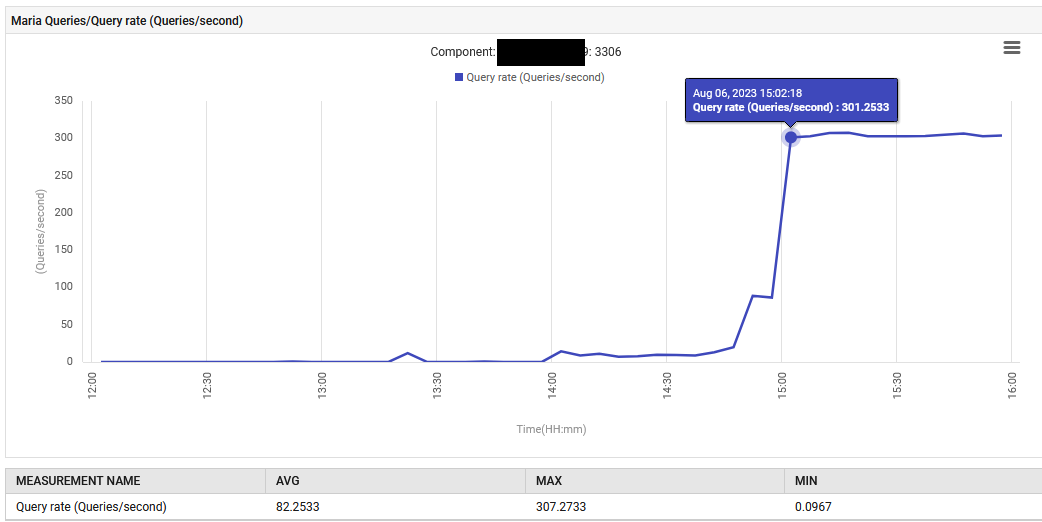
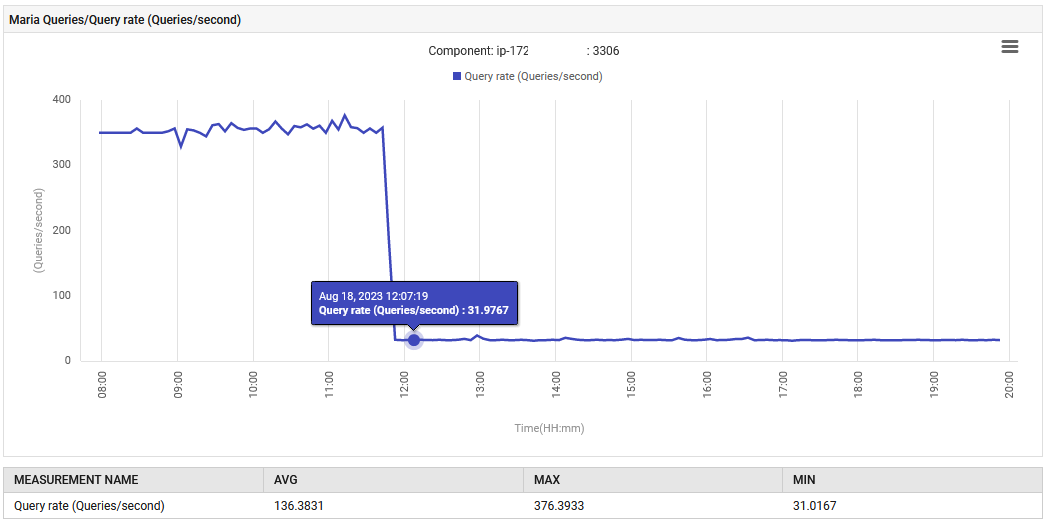
A las 14:52, la tasa de procesamiento de consultas para MariaDB aumentó de 0.1 a 88 consultas por segundo y luego a 301 consultas por segundo.
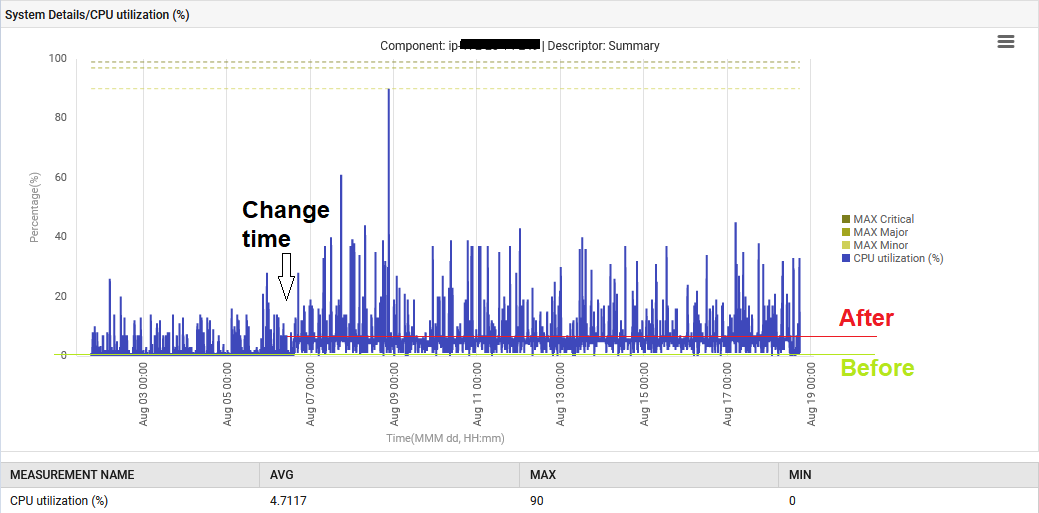
Además, la CPU del sistema se elevó del 1% al 6%.
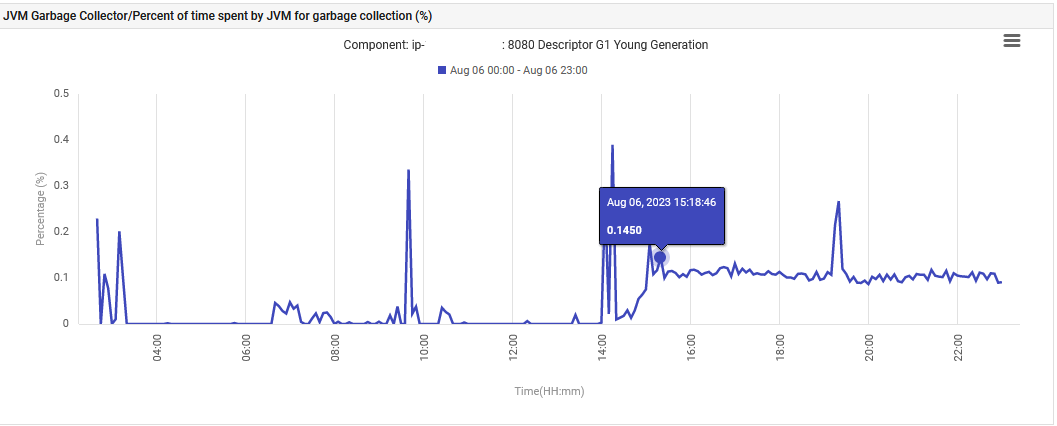
Finalmente, el tiempo que el JVM dedicó a la Colección de Basura de la Generación Joven G1 aumentó de 0% a 0.1% y se mantuvo en ese nivel.
La aplicación, en su fase de UAT, está emitiendo anormalmente 300 consultas/seg, lo cual está muy por encima de lo que estaba diseñada para hacer. La nueva función ha provocado un aumento en la conexión a la base de datos, razón por la cual el incremento en las consultas es tan drástico. Sin embargo, el panel de monitoreo mostró que las medidas problemáticas eran normales antes de que se desplegara la nueva versión.
La Resolución
Se trata de una aplicación Spring Boot que utiliza JPA para consultar una MariaDB. La aplicación está diseñada para ejecutarse en dos contenedores para una carga mínima, pero se espera que pueda escalar hasta diez.
Si un solo contenedor puede generar 300 consultas por segundo, ¿puede manejar 3000 consultas por segundo si todos los diez contenedores están operativos? ¿Puede la base de datos tener suficientes conexiones para satisfacer las necesidades del resto de la aplicación?
No nos quedó más remedio que regresar a la mesa del desarrollador para inspeccionar los cambios en Git.
El nuevo cambio tomará algunas registros de una tabla y los procesará. Esto es lo que observamos en la clase de servicio.
List<X> findAll = this.xRepository.findAll();
No, utilizar el método findAll() sin paginación en CrudRepository de Spring no es eficiente. La paginación ayuda a reducir el tiempo que lleva recuperar datos de la base de datos limitando la cantidad de datos recuperados. Esto es lo que nos enseñó nuestra educación primaria en RDBMS. Además, la paginación ayuda a mantener baja la utilización de memoria para evitar que la aplicación se cierre debido a una sobrecarga de datos, así como reducir el esfuerzo de la recolección de basura de la Máquina Virtual Java, lo cual se mencionó en el enunciado del problema anterior.
Este test se realizó utilizando solo 2,000 registros en un contenedor. Si este código se hubiera trasladado a producción, donde hay alrededor de 200,000 registros en hasta 10 contenedores, podría haber causado mucho estrés y preocupación al equipo ese día.
La aplicación fue reconstruida con la adición de una cláusula WHERE al método.
List<X> findAll = this.xRepository.findAllByY(Y);
La función normal fue restaurada. El número de consultas por segundo disminuyó de 300 a 30, y el esfuerzo invertido en la recolección de basura volvió a su nivel original. Además, la utilización de CPU del sistema disminuyó.
Aprendizaje y Resumen
Cualquier persona que trabaje en Ingeniería de Confiabilidad de Sitios (SRE) apreciará la importancia de este descubrimiento. Pudimos actuar sin tener que levantar una bandera de Severidad 1. Si este paquete defectuoso hubiera sido desplegado en producción, podría haber activado el umbral de escalado automático del cliente, resultando en el lanzamiento de nuevos contenedores incluso sin una carga de usuario adicional.
Hay tres conclusiones principales de esta historia.
En primer lugar, es una buena práctica activar una solución de observabilidad desde el principio, ya que puede proporcionar un historial de eventos que se puede utilizar para identificar posibles problemas. Sin este historial, es posible que no hubiera tomado en serio un porcentaje de Recolección de Basura del 0,1% y un consumo de CPU del 6%, y el código podría haber sido lanzado en producción con consecuencias desastrosas. Ampliar el alcance de la solución de monitoreo a servidores de UAT ayudó al equipo a identificar posibles causas raíz y prevenir problemas antes de que ocurran.
En segundo lugar, las pruebas relacionadas con el rendimiento deben existir en el proceso de prueba, y estas deben ser revisadas por alguien con experiencia en observabilidad. Esto garantizará que la funcionalidad del código sea probada, así como su rendimiento.
En tercer lugar, las técnicas de seguimiento de rendimiento nativas de la nube son buenas para recibir alertas sobre alta utilización, disponibilidad, etc. Para lograr la observabilidad, es posible que necesites tener las herramientas y la experiencia adecuadas en su lugar. ¡Feliz codificación!
Source:
https://dzone.com/articles/shift-left-monitoring-approach-for-cloud-apps-in-c