













La Recuperación Aumentada de Generación (RAG) representa una avanzación transformadora en los modelos de lenguaje large (LLMs). Combina la habilidad generativa de las arquitecturas de transformador con la búsqueda de información dinámica.
Esta integración permite que los LLMs accedan y incorporen conocimiento externo relevante durante la generación de texto, resultando en salidas que son más precisas, contextuales y consistentes en datos de hecho.
La evolución de los sistemas basados en reglas tempranos a modelos sofisticados de red neuronal como BERT y GPT-3 ha abierto la puerta para RAG, resolviendo las limitaciones de la memoria paramétrica estática. Además, el advenimiento de RAG Multimodal extiende estas capacidades al incorporar diferentes tipos de datos, como imágenes, audio y video. Esto mejora la riqueza y la relevancia del contenido generado.
Este cambio de paradigma no solo mejora la precisión e interpretabilidad de las salidas de LLM sino que también apoya aplicaciones innovadoras en varios campos.
Aquí es lo que cubriremos:
- Capítulo 1. Introducción a RAG
– 1.1 ¿Qué es RAG? Una Visión General
– 1.2 Cómo RAG Resuelve Problemas Complejos - Capítulo 2. fundamentos técnicos
– 2.1 Transición de LM neurales a RAG
– 2.2 Comprensión de la memoria de RAG: paramétrico vs. no paramétrico
– 2.3 RAG multi-modal: integración de varios tipos de datos - Capítulo 3. mecanismos centrales
– 3.1 La potencia de la combinación de información de búsqueda y generación en RAG
– 3.2 Estrategias de integración para recuperadores y generadores - Capítulo 4. Aplicaciones y casos de uso
– 4.1 RAG en acción: Desde Preguntas y respuestas hasta redacción creativa
– 4.2 RAG para lenguas de bajos recursos: Extendiendo la alcance y las capacidades - Capítulo 5. Técnicas de Optimización
– 5.1 Técnicas avanzadas de búsqueda para optimizar los sistemas RAG - Capítulo 6. Retos e Innovaciones
– 6.1 Retos actuales y direcciones futuras para RAG
– 6.2 Aceleración hardware y eficiente implementación de sistemas RAG - Capítulo 7. Reflexiones Concluyentes
– 7.1 El futuro de RAG: Conclusiones y Reflexiones
Pre-requisites
Para interactuar con contenido centrado en modelos de lenguaje grande (LLMs) como Retrieval-Augmented Generation (RAG), dos prerequisitos esenciales son:
- Fundamentos de Machine Learning: Es crucial comprender conceptos básicos de machine learning y algoritmos, especialmente como se aplican a arquitecturas de redes neuronales.
- Procesamiento del Lenguaje Natural (NLP): El conocimiento de técnicas de NLP, incluyendo la preprocesamiento de texto, la tokenización y el uso de embeddings, es vital para trabajar con modelos de lenguaje.
Capítulo 1: Introducción a RAG
La Generación Aumentada con Recuperación (RAG) revoluciona el procesamiento del lenguaje natural al combinar la información de recuperación y los modelos generativos. Los sistemas RAG acceden dinámicamente a los conocimientos externos, mejorando la precisión y la relevancia del texto generado.
Este capítulo explora los mecanismos de RAG, sus ventajas y desafíos. Nos adentramos en las técnicas de recuperación, la integración con modelos generativos y el impacto en varias aplicaciones.
RAG reduce las alucinaciones, Incorpora información actualizada y aborda problemas complejos. También discutimos desafíos como la recuperación eficiente y las consideraciones éticas. Este capítulo proporciona una comprensión completa del potencial transformador de RAG en el procesamiento del lenguaje natural.
1.1 ¿Qué es RAG? Una Visión General
La Generación Aumentada con Recuperación (RAG) representa un cambio de paradigma en el procesamiento del lenguaje natural, integrando sin problemas las fortalezas de la información de recuperación y los modelos de lenguaje generativos. Los sistemas RAG aprovechan las fuentes de conocimiento externas para mejorar la precisión, relevancia y coherencia del texto generado, abordando las limitaciones de la memoria paramétrica pura en los modelos de lenguaje tradicionales. (Lewis et al., 2020)
Al retirar y Incorporar información relevante dinámicamente durante el proceso de generación, RAG permite salidas más arraigadas en el contexto y consistentes en los hechos en una amplia gama de aplicaciones, desde las respuestas a preguntas y sistemas de diálogo hasta la resumisión y la escritura creativa. (Petroni et al., 2021)
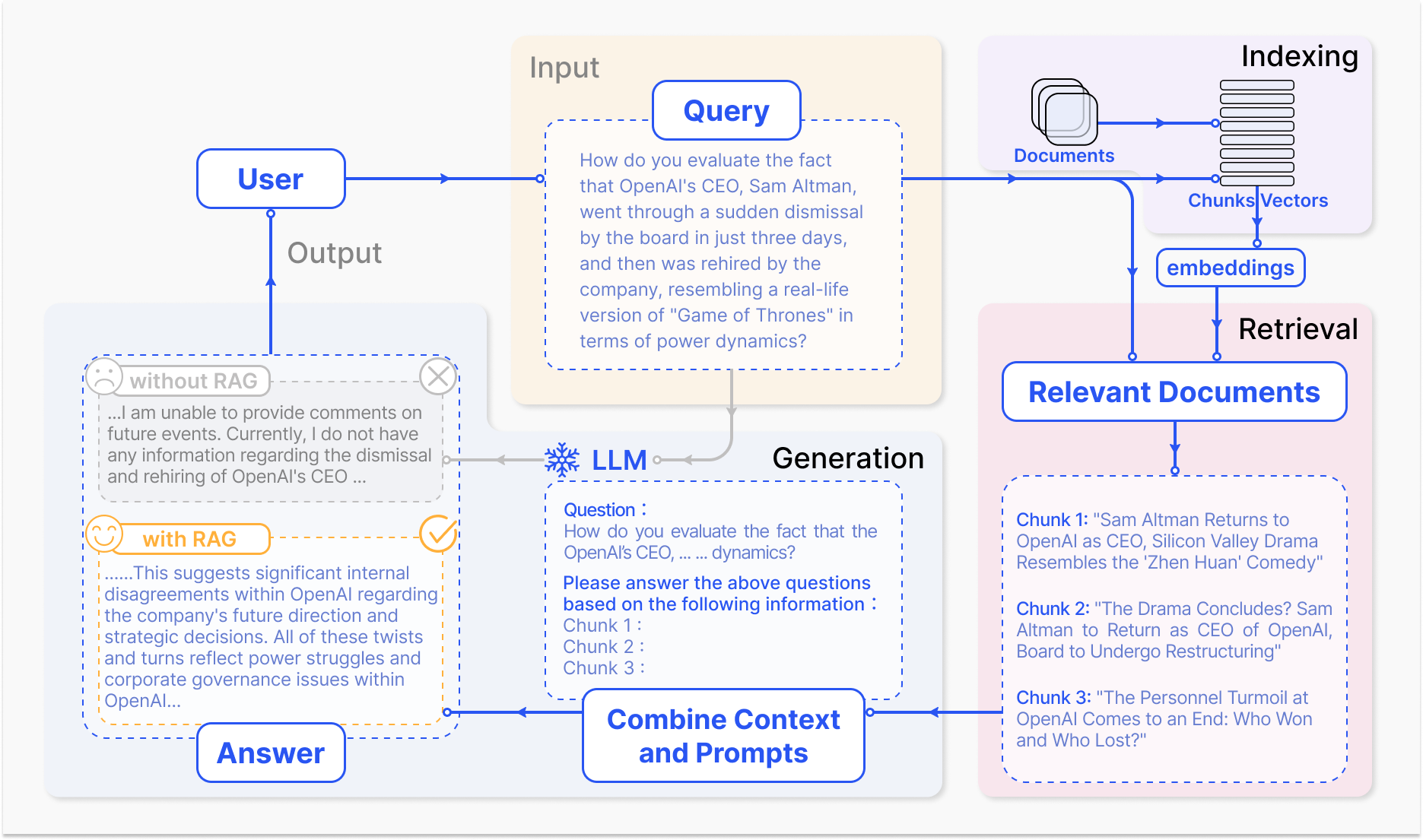
Cómo opera un Sistema RAG – arxiv.org
El mecanismo central de RAG implica dos componentes primarios: búsqueda y generación.
El componente de búsqueda busca eficientemente a través de bases de conocimiento amplios para identificar la información más pertinente basada en la consulta de entrada o contexto. Se emplean técnicas como la búsqueda dispersa, que utiliza índices invertidos y coincidencias basadas en términos, y la búsqueda densa, que emplea representaciones de vectores densos y semejanza semántica, para optimizar el proceso de búsqueda. (Karpukhin et al., 2020)
La información recuperada luego se integra en el modelo generativo, normalmente un gran modelo de lenguaje como GPT o T5, que sintetiza el contenido relevante en una respuesta coherente y fluida. (Izacard & Grave, 2021)
La integración de recuperación y generación en RAG ofrece varias ventajas sobre los modelos de lenguaje tradicionales. Al fundamentar el texto generado en conocimientos externos, RAG reduce significativamente la incidencia de alucinaciones o salidas factualmente incorrectas. (Shuster et al., 2021)
RAG también permite incorporar información actualizada, garantizando que las respuestas generadas reflejan los últimos conocimientos y desarrollos en un determinado campo. (Lewis et al., 2020) Esta adaptabilidad es particularmente crucial en campos como la atención médica, las finanzas y la investigación científica, donde la exactitud y la actualidad de la información son de suma importancia. (Petroni et al., 2021)
Pero el desarrollo y la implementación de sistemas RAG también presentan desafíos significativos. La recuperación eficiente de bases de conocimiento a gran escala, la mitigación de las alucinaciones y la integración de diversas modalidades de datos son entre los obstáculos técnicos que deben ser abordados. (Izacard & Grave, 2021)
También, consideraciones éticas, como asegurar un procesamiento imparcial y justo de la información de búsqueda y generación, son cruciales para el despliegue responsable de sistemas RAG. (Bender et al., 2021) El desarrollo de métricas de evaluación comprensivas y marcos que capturar la interacción entre la precisión de recuperación y la calidad generativa es fundamental para evaluar la eficacia de los sistemas RAG. (Lewis et al., 2020)
Con el campo de RAG en constante evolución, futuras direcciones de investigación se enfocan en optimizar procesos de recuperación, expandiendo capacidades multimodales, desarrollando arquitecturas modulares y estableciendo marcos de evaluación robustos. (Izacard & Grave, 2021) Estos avances mejorarán la eficiencia, precisión y adaptabilidad de los sistemas RAG, abriendo camino a aplicaciones más inteligentes y versátiles en procesamiento de lenguaje natural.
Aquí hay un ejemplo básico de código Python que demuestra un ajuste de generación aumentada por recuperación (RAG) utilizando las populares bibliotecas LangChain y FAISS:
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import FAISS
from langchain.document_loaders import TextLoader
from langchain.chains import RetrievalQA
from langchain.llms import OpenAI
# 1. Cargar y Embedear Documentos
loader = TextLoader('your_documents.txt') # Reemplaza con tu fuente de documentos
documents = loader.load()
embeddings = OpenAIEmbeddings()
vectorstore = FAISS.from_documents(documents, embeddings)
# 2. Recuperar Documentos Relevantes
def retrieve_docs(query):
return vectorstore.similarity_search(query)
# 3. Configurar Cadena RAG
llm = OpenAI(temperature=0.1) # Ajustar la temperatura para la creatividad de la respuesta
chain = RetrievalQA.from_chain_type(llm=llm, chain_type="stuff", retriever=vectorstore.as_retriever())
# 4. Usar el Modelo RAG
def get_answer(query):
return chain.run(query)
# Ejemplo de uso
query = "What are the key features of Company X's latest product?"
answer = get_answer(query)
print(answer)
# Ejemplo de uso Historia de la empresa
query = "When was Company X founded and who were the founders?"
answer = get_answer(query)
print(answer)
# Ejemplo de uso Rendimiento financiero
query = "What were Company X's revenue and profit figures for the last quarter?"
answer = get_answer(query)
print(answer)
# Ejemplo de uso Perspectiva futura
query = "What are Company X's plans for expansion or new product development?"
answer = get_answer(query)
print(answer)
Al aprovechar el poder de la recuperación y la generación, RAG muestra un gran potencial para transformar cómo interactuamos con la información y la generación, revolucionando diversos campos y moldeando el futuro de la interacción humano-máquina.
1.2 Cómo RAG Resuelve problemas complejos
La Generación Aumentada por Recuperación (RAG) ofrece una solución poderosa para los problemas complejos que los modelos de lenguaje grande (LLMs) tradicionales tienen dificultades para resolver, particularmente en situaciones que involucren grandes cantidades de datos no estructurados.
Un such problem is the ability to engage in meaningful conversations about specific documents or multimedia content, such as YouTube videos, without prior fine-tuning or explicit training on the target material.
Las MLL tradicionales, a pesar de sus impresionantes capacidades generativas, están limitadas por su memoria paramétrica, que se fija en el momento de la entrenación. (Lewis et al., 2020) Esto significa que no pueden acceder directamente o incorporar información nueva más allá de sus datos de entrenamiento, lo que hace difícil participar en discusiones informadas sobre documentos o videos no vistos.
En consecuencia, las MLL pueden generar respuestas que son inconsistentes, irrelevantes o incorrectas de hecho cuando se les pide que respondan a consultas relacionadas con contenidos específicos. (Petroni et al., 2021)
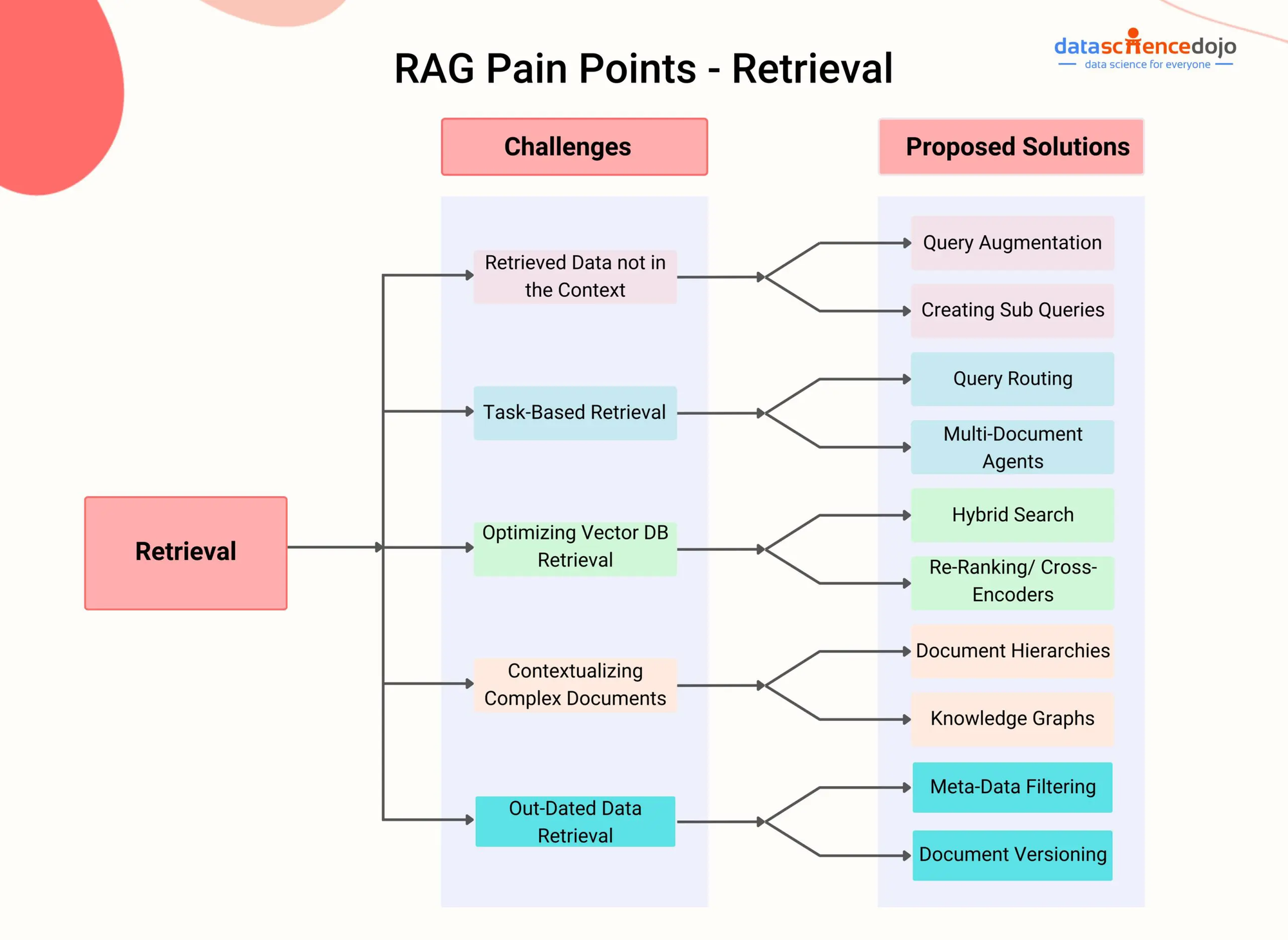
Puntos de dolor de RAG – DataScienceDojo
RAG aborda esta limitación integrando un componente de búsqueda que permite que el modelo acceda dinámicamente e incorporate información relevante de fuentes de conocimiento externos durante el proceso de generación.
Mediante la utilización de técnicas de búsqueda avanzadas, como la búsqueda de pasajes densos (Karpukhin et al., 2020) o la búsqueda híbrida (Izacard & Grave, 2021), los sistemas RAG pueden identificar eficientemente los pasajes o segmentos más pertinentes de un documento o video dado en función del contexto conversacional.
Por ejemplo, considere un escenario en el que un usuario desea participar en una conversación sobre un video de YouTube específico sobre un tema científico. Un sistema RAG puede primero transcribir el contenido de audio del video y luego indexar el texto resultante utilizando representaciones de vectores densos.
Luego, cuando el usuario hace una pregunta relacionada con el video, el componente de búsqueda del sistema RAG puede rápidamente identificar las pasajes más relevantes de la transcripción basándose en la semejanza semántica entre la consulta y el contenido indexado.
Los pasajes recuperados luego se suministran al modelo generativo, que sintetiza una respuesta coherente e informativa que atiende directamente a la pregunta del usuario y fija la respuesta en el contenido del video. (Shuster et al., 2021)
Este enfoque permite que los sistemas RAG se involucren en conversaciones científicamente sólidas sobre un amplio abanico de documentos y contenido multimedia sin la necesidad de ajustes finales explícitos. Mediante la recuperación dinámica e integración de información relevante, RAG puede generar respuestas que son más precisas, relevantes en contexto y consistentes en datos comparadas con los LMM tradicionales. (Lewis et al., 2020)
También, la capacidad de RAG para manejar datos no estructurados de varias modalidades, como texto, imágenes y audio, lo hace una solución versátil para problemas complejos que involucran fuentes de información heterogéneas. (Izacard & Grave, 2021) Conforme los sistemas RAG continúan evolucionando, su potencial para abordar problemas complejos en diversos dominios aumenta.
Mediante la utilización de técnicas de búsqueda avanzadas y de integración multimodal, RAG puede facilitar agentes conversacionales más inteligentes y alertas al contexto, sistemas de recomendación personalizados y aplicaciones basadas en conocimiento.
Con el avance de la investigación en áreas como el índice eficiente, la alineación cruzada de modalidades y la integración de búsqueda-generación, RAG sin duda desempeñará un papel crucial en avanzar los límites de lo posible con los modelos de lenguaje y la inteligencia artificial.
Capítulo 2: fundamentos técnicos
Este capítulo se adentra en el fascinante mundo de la Generación Auxiliada por Búsqueda Multimodal (RAG), una innovadora aproximación que supera las limitaciones de los modelos basados en texto tradicionales.
Mediante la integración fluida de modalidades de datos diversos como imágenes, audio y video con Modelos de Lenguaje Largos (LLMs), la Multimodal RAG capta el poder de los sistemas AI para razonar a través de un paisaje informacional más rico.
Exploraremos los mecanismos detrás de esta integración, como el aprendizaje por contraste y la atención cruzada de modalidades, y cómo estos permiten a los LLMs generar respuestas más elaboradas y relevantes contextualmente.
Mientras que RAG Multimodal ofrece beneficios prometedores como mejor precisión y la capacidad de respaldar casos de uso novedosos como la respuesta a preguntas visuales, también presenta desafíos únicos. Estos desafíos incluyen la necesidad de conjuntos de datos multimodales a gran escala, una complejidad computacional aumentada y el potencial para la sesgo en la información recuperada.
Mientras que emprendemos este viaje, no solo descubriremos el potencial transformador de RAG Multimodal sino que también examinaremos críticamente los obstáculos que se presentan, pavimentando el camino para un mayor entendimiento de este campo en rápido desarrollo.
2.1 Modelos Neuronales LM a RAG
La evolución de los modelos de lenguaje ha sido marcada por una progresión constante de los sistemas basados en reglas tempranas a modelos cada vez más sofisticados basados en estadísticas y redes neuronales.
En los primeros días, los modelos de lenguaje dependían de reglas hechas a mano y conocimientos lingüísticos para generar texto, resultando en salidas rígidas y limitadas. La aparición de modelos estadísticos, como los modelos de n-gramas, introdujo un enfoque basado en datos que aprendió patrones de grandes corporas, permitiendo la generación de lenguaje más natural y coherente. (Redis)
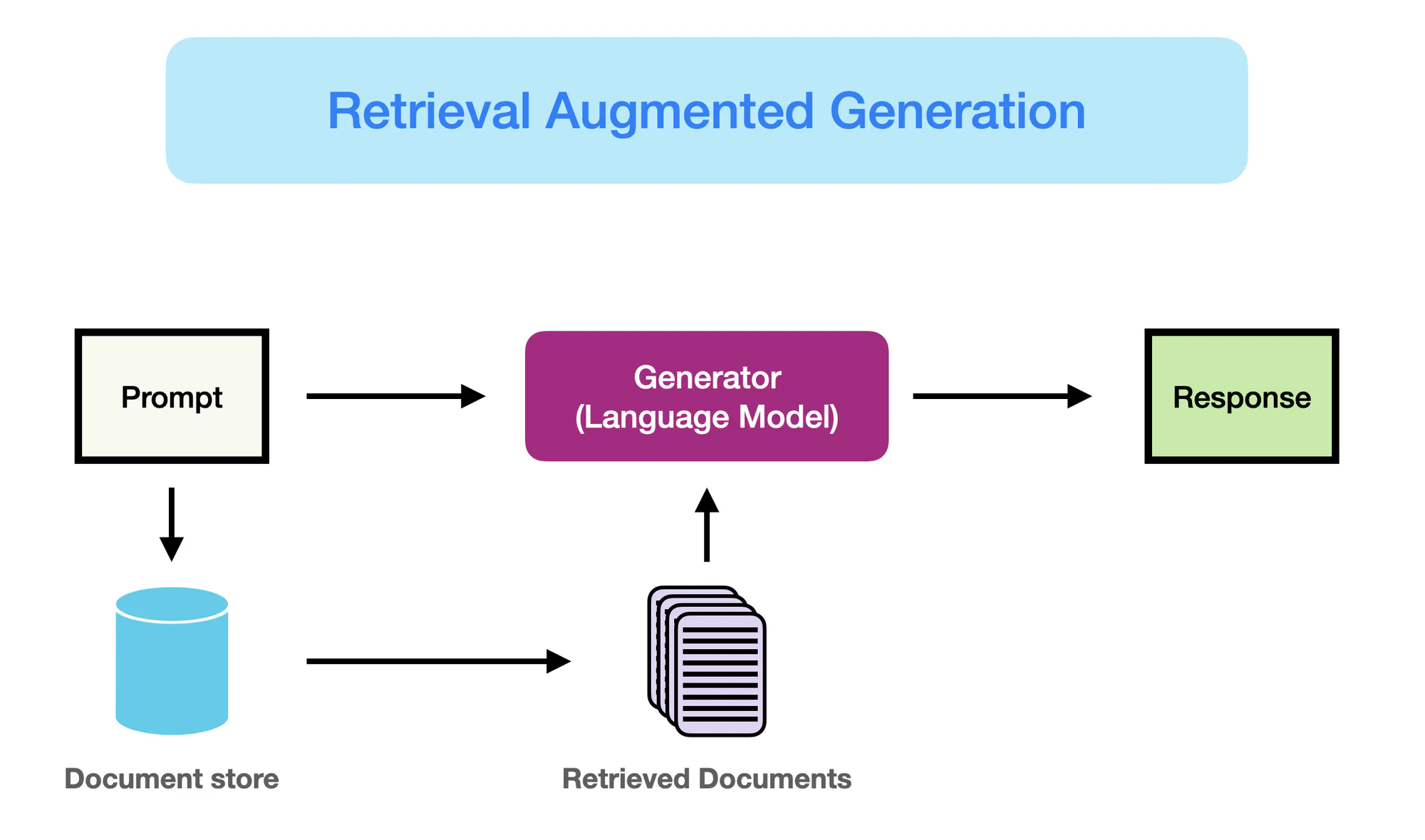
Cómo funciona RAG – promptingguide.ai
Sin embargo, fue la emergencia de modelos basados en redes neuronales, particularmente arquitecturas de transformador como BERT y GPT-3, lo que revolucionó el campo de procesamiento de lenguaje natural (NLP).
Estos modelos, conocidos como grandes modelos de lenguaje (LLMs), aprovechan el poder del aprendizaje profundo para capturar patrones lingüísticos complejos y generar texto humanoide con fluidez y coherencia sin precedentes. (Yarnit) La creciente complejidad y escala de los LLMs, con modelos como GPT-3 que cuentan con más de 175 mil millones de parámetros, han dado lugar a capacidades destacadas en tareas como la traducción de lenguaje, la respuesta a preguntas y la creación de contenido.
A pesar de su impresionante rendimiento, los modelos tradicionales de LLM sufren limitaciones debido a su dependencia de una memoria puramente paramétrica. (StackOverflow) El conocimiento codificado en estos modelos es estático, limitado por la fecha de corte de sus datos de entrenamiento.
Como resultado, los LLMs pueden generar salidas que son factualmente incorrectas o inconsistentes con la información más reciente. Además, la falta de acceso explícito a fuentes de conocimiento externos impide su capacidad para proporcionar respuestas precisas y contextualmente relevantes a consultas de alto contenido de conocimiento.
La Retrieval Augmented Generation (RAG) emerge como una solución innovadora que cambia el paradigma para abordar estas limitaciones. Al integrar sin problemas las capacidades de información de retiro con el poder generativo de los LLMs, RAG permite que los modelos accedan y incorporen dinámicamente el conocimiento relevante de fuentes externas durante el proceso de generación.
Esta fusión de memoria paramétrica y no paramétrica permite que los LSM dotados con RAG produzcan salidas que no solo son fluentes y coherentes sino también precisas en cuanto a hechos y informadas contextualmente.
RAG representa un avance importante en la generación de lenguaje, fusionando las ventajas de los LSM con el vasto conocimiento disponible en repositorios externos. Al aprovechar lo mejor de ambos mundos, RAG capacita a los modelos para generar texto que es más fiable, informativo y alineado con el conocimiento del mundo real.
Este cambio de paradigma abre nuevas posibilidades para las aplicaciones de NLP, desde la respuesta a preguntas y la creación de contenido hasta tareas de dominios como la atención médica, las finanzas y la investigación científica que requieren conocimientos intensivos.
2.2 Memoria Paramétrica vs No Paramétrica
La memoria paramétrica se refiere al conocimiento almacenado dentro de los parámetros de los modelos de lenguaje pre-entrenados, como BERT y GPT-4. Estos modelos aprenden a capturar patrones lingüísticos y relaciones de vastos montos de datos de texto durante el proceso de entrenamiento, codificando este conocimiento en sus millones o miles de millones de parámetros.
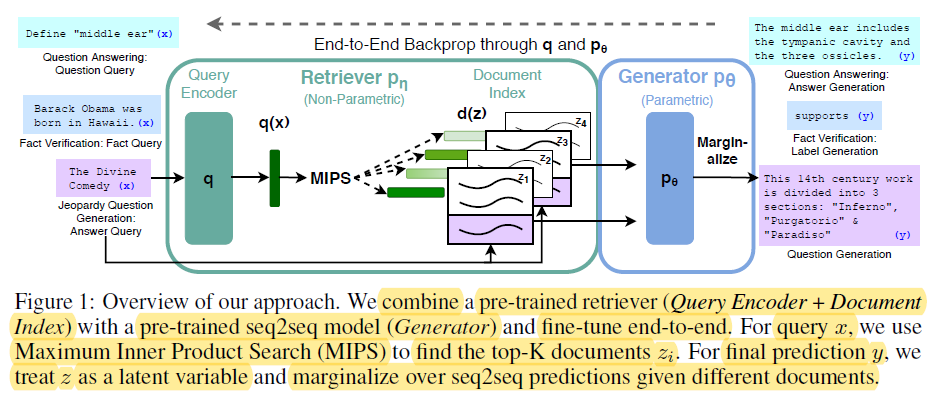
End-t-End Backprop through q and p0 – miro.medium.com
Las ventajas de la memoria paramétrica incluyen:
- Fluidez: Los modelos de lenguaje pre-entrenados generan texto humanoide con una fluidez y coherencia destacables, capturando las nuances y estilo del lenguaje natural. (Redis y Lewis et al.)
- Generalización: El conocimiento codificado en los parámetros del modelo le permite generalizar a nuevas tareas y dominios, permitiendo capacidades de aprendizaje de transferencia y aprendizaje con muy pocos ejemplos. (Redis y Lewis et al.)
Sin embargo, la memoria paramétrica también tiene limitaciones significativas:
- Errores de hecho: Los modelos de lenguaje pueden generar salidas que no son consistentes con los hechos del mundo real, ya que su conocimiento se limita a los datos en los que fueron entrenados.
- Conocimiento anticuado: El conocimiento codificado en los parámetros del modelo se hace vago con el tiempo, ya que se fija en el momento del entrenamiento y no refleja actualizaciones o cambios en el mundo real.
- Costo computacional alto: El entrenamiento de modelos de lenguaje grandes requiere cantidades masivas de recursos computacionales y energía, haciendo que sea caro y tiempo consumido actualizar su conocimiento.
- Conocimiento general: El conocimiento capturado por los modelos de lenguaje es amplio y general, y carece de la profundidad y especificidad requerida para muchas aplicaciones específicas de dominio.
En comparación, la memoria no paramétrica se refiere al uso de fuentes de conocimiento explícitas, como bases de datos, documentos y grafos de conocimiento, para proporcionar información actualizada y precisa a los modelos de lenguaje. Estas fuentes externas sirven como una forma complementaria de memoria, permitiendo que los modelos accedan y recuperen información relevante en demanda durante el proceso de generación.
Los beneficios de la memoria no paramétrica incluyen:
- Información actualizada: Las fuentes de conocimiento externas pueden actualizarse y mantenerse fácilmente, garantizando que el modelo tenga acceso a la información más reciente y precisa.
- Reducción de ilusiones: “Al recuperar información relevante de fuentes externas, RAG reduce significativamente la incidencia de ilusiones o salidas generativas factualmente incorrectas.” (Lewis et al. y Guu et al.)
- Conocimiento específico del dominio: La memoria no paramétrica permite a los modelos aprovechar el conocimiento especializado de fuentes específicas del dominio, lo que permite generar salidas más precisas y relevantes en contexto para aplicaciones específicas. (Lewis et al. y Guu et al.)
Las limitaciones de la memoria paramétrica subrayan la necesidad de un cambio de paradigma en la generación de lenguaje.
RAG representa un avance significativo en la procesamiento del lenguaje natural al mejorar el rendimiento de los modelos generativos mediante la integración de técnicas de búsqueda de información. (Redis)
Aquí está el código de Python para demostrar la distinción entre memoria paramétrica y no paramétrica en el contexto de RAG, junto con un claro resaltado de salida:
from sentence_transformers import SentenceTransformer
from langchain.embeddings import HuggingFaceEmbeddings
from langchain.vectorstores import FAISS
from langchain.chains import RetrievalQAWithSourcesChain
from langchain.llms import OpenAI
# Colección de documentos de muestra (supongamos que en un escenario real hay documentos más extensos)
documents = [
"The Large Hadron Collider (LHC) is the world's largest and most powerful particle accelerator.",
"The LHC is located at CERN, near Geneva, Switzerland.",
"The LHC is used to study the fundamental particles of matter.",
"In 2012, the LHC discovered the Higgs boson, a particle that gives mass to other particles.",
]
# 1. Memoria No Paramétrica (Búsqueda con Embedidos)
model_name = "sentence-transformers/all-mpnet-base-v2"
embeddings = HuggingFaceEmbeddings(model_name=model_name)
vectorstore = FAISS.from_documents(documents, embeddings)
# 2. Memoria Paramétrica (Modelo de Lenguaje con Búsqueda)
llm = OpenAI(temperature=0.1) # Ajustar la temperatura para la creatividad de la respuesta
chain = RetrievalQAWithSourcesChain.from_chain_type(llm=llm, chain_type="stuff", retriever=vectorstore.as_retriever())
# --- Consultas y Respuestas ---
query = "What was discovered at the LHC in 2012?"
answer = chain.run(query)
print("Parametric (w/ Retrieval): ", answer["answer"])
query = "Where is the LHC located?"
docs = vectorstore.similarity_search(query)
print("Non-Parametric: ", docs[0].page_content)
Salida:
Parametric (w/ Retrieval): The Higgs boson, a particle that gives mass to other particles, was discovered at the LHC in 2012.
Non-Parametric: The LHC is located at CERN, near Geneva, Switzerland.
Y esto es lo que ocurre en este código:
Memoria Paramétrica:
- Aprovecha el vasto conocimiento de la LLM para generar una respuesta completa, incluyendo el hecho crucial de que el bosón Higgs da masa a otras partículas. La LLM está “parametrizada” por su amplio entrenamiento en datos.
Memoria No-Paramétrica:
- Realiza una búsqueda de similitud en el espacio vectorial, encontrando el documento más relevante que responde directamente a la pregunta sobre la ubicación del LHC. No sintetiza nueva información, simplemente recupera el hecho relevante.
Diferencias Clave:
| Feature | Parametric Memory | Non-Parametric Memory |
|---|---|---|
| Almacenamiento de Conocimiento | Incorporado en los parámetros del modelo (ponderaciones) como representaciones aprendidas. | Almacenado directamente como texto en bruto o otros formatos (por ejemplo, embeddings). |
| Recuperación | Utiliza las capacidades generativas del modelo para producir texto relevante a la consulta basado en su conocimiento aprendido. | Incluye la búsqueda de documentos que se asemejan closamente a la consulta (por ejemplo, mediante similaridad o coincidencia de palabras clave). |
| Flexibilidad | Muy flexible y puede generar respuestas novedosas, pero también puede ilusionar (generar información incorrecta). | Menos flexible, pero menos propenso a ilusiones ya que se basa en datos existentes. |
| Estilo de Respuesta | Puede producir respuestas más elaboradas y subtanciosas, pero potencialmente con más información irrelevante. | Proporciona respuestas directas y concisas, pero puede faltar contexto o elaboración. |
| Coste Computacional | El proceso de generación de respuestas puede ser computacionalmente intensivo, especialmente para modelos grandes. | La búsqueda puede ser más rápida, especialmente con algoritmos de índice e búsqueda eficientes. |
Al combinar las ventajas de la memoria paramétrica y no paramétrica, RAG aborda las limitaciones de los modelos de lenguaje tradicionales y permite la generación de salidas más precisas, actualizadas y relevantes contextualmente. (Redis, Lewis et al., y Guu et al.)
2.3 RAG multimodal: integración de texto
RAG multimodal extende el paradigma tradicional basado en texto de RAG al integrar múltiples modalidades de datos, como imágenes, audio y video, para mejorar las capacidades de recuperación y generación de los grandes modelos de lenguaje (LLMs).
Al aprovechar técnicas de aprendizaje contrastivo, los sistemas RAG multimodales aprenden a integrar tipos de datos heterogéneos en un espacio vectorial compartido, permitiendo una búsqueda cruzada de modalidades sin problemas. Esto permite que los LLMs razonen sobre un contexto más rico, combinando información textual con señales visuales y auditivas para generar salidas más sutiles y relevantes contextualmente. (Shen et al.)
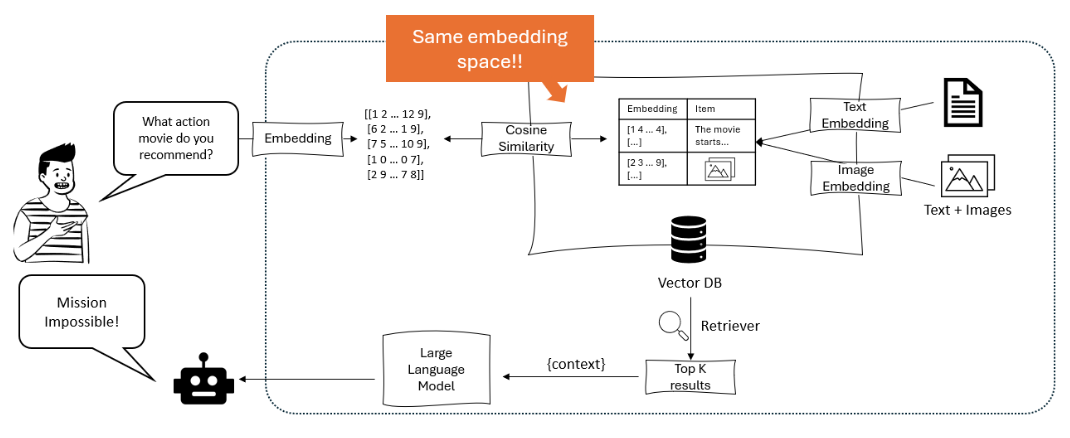
El diagrama ilustra un sistema de recomendación en el que un gran modelo de lenguaje procesa una consulta del usuario en representaciones embebidas, que luego se matchean utilizando similaridad coseno dentro de una base de vectores que contiene tanto representaciones embebidas de texto como de imágenes, para recuperar y recomendar los elementos más relevantes. – opendatascience.com
Una de las principales aproximaciones en RAG multimodal es el uso de modelos basados en transformer, como ViLBERT y LXMERT, que emplean mecanismos de atención cruzada multimodal. Estos modelos pueden prestar atención a regiones relevantes en imágenes o segmentos específicos en audio/vídeo mientras generan texto, capturando interacciones finas entre modalidades. Esto permite respuestas más visualmente y contextualmente ajustadas. (Protecto.ai)
La integración de texto con otras modalidades en las pipeline de RAG presenta desafíos como el alineamiento de representaciones semánticas entre diferentes tipos de datos y la manejo de las características únicas de cada modalidad durante el proceso de embeddings. Se utilizan técnicas como la codificación específica de modalidad y atención cruzada para abordar estos desafíos. (Zhu et al.)
Pero los potenciales beneficios de RAG multimodal son significativos, incluyendo mejores precisiones, controlabilidad e interpretabilidad del contenido generado, así como la capacidad de apoyar casos de uso novedosos como la respuesta visual de preguntas y la creación de contenido multimodal.
Por ejemplo, Li et al. (2020) propusieron un marco multimodal RAG para la respuesta a preguntas visuales que recupera imágenes relevantes y información textual para generar respuestas precisas, superando a las previas técnicas de referencia en benchmark como VQA v2.0 y CLEVR. (MyScale)
A pesar de los resultados prometedores, el multimodal RAG también introduce nuevos desafíos, como la complejidad computacional aumentada, la necesidad de grandes conjuntos de datos multimodales y el potencial para sesgos y ruido en la información recuperada.
Los investigadores están explorando activamente técnicas para mitigar estos problemas, como estructuras de índice eficientes, estrategias de data augmentation y métodos de entrenamiento adversarial. (Sohoni et al.)
Capítulo 3: Mecánicas Centrales de RAG
Este capítulo explora la compleja interacción entre los recuperadores y los modelos generativos en los sistemas de Retrieval-Augmented Generation (RAG), destacando sus roles cruciales en la indexación, recuperación y síntesis de información para producir respuestas precisas y relevantes contextualmente.
Nos adentramos en las nuestras de la técnica esparcida y densa de recuperación, comparando sus fortalezas y debilidades en diferentes situaciones. Además, examinamos varias estrategias para integrar la información recuperada en los modelos generativos, como la concatenación y la atención cruzada, y discutimos su impacto en la eficacia general de los sistemas RAG.
Al entender estrategias de integración, conseguirá valiosas perspectivas sobre cómo optimizar sistemas RAG para tareas y dominios específicos, abriendo camino a un uso más informado y efectivo de este poderoso paradigma.
3.1 El poder de combinar Información de Retiro y Generación en RAG
Retrieval-Augmented Generation (RAG) representa un poderoso paradigma que integra sin problemas la información de retiro con modelos generativos de lenguaje. RAG se compone de dos componentes principales, como puede deducir por su nombre: Retiro y Generación.
El componente de retiro es responsable de indexar y buscar a través de un inmenso repositorio de conocimiento, mientras que el componente de generación aprovecha la información retirada para producir respuestas contextualmente relevantes y facturalmente precisas. (Redis y Lewis et al.)
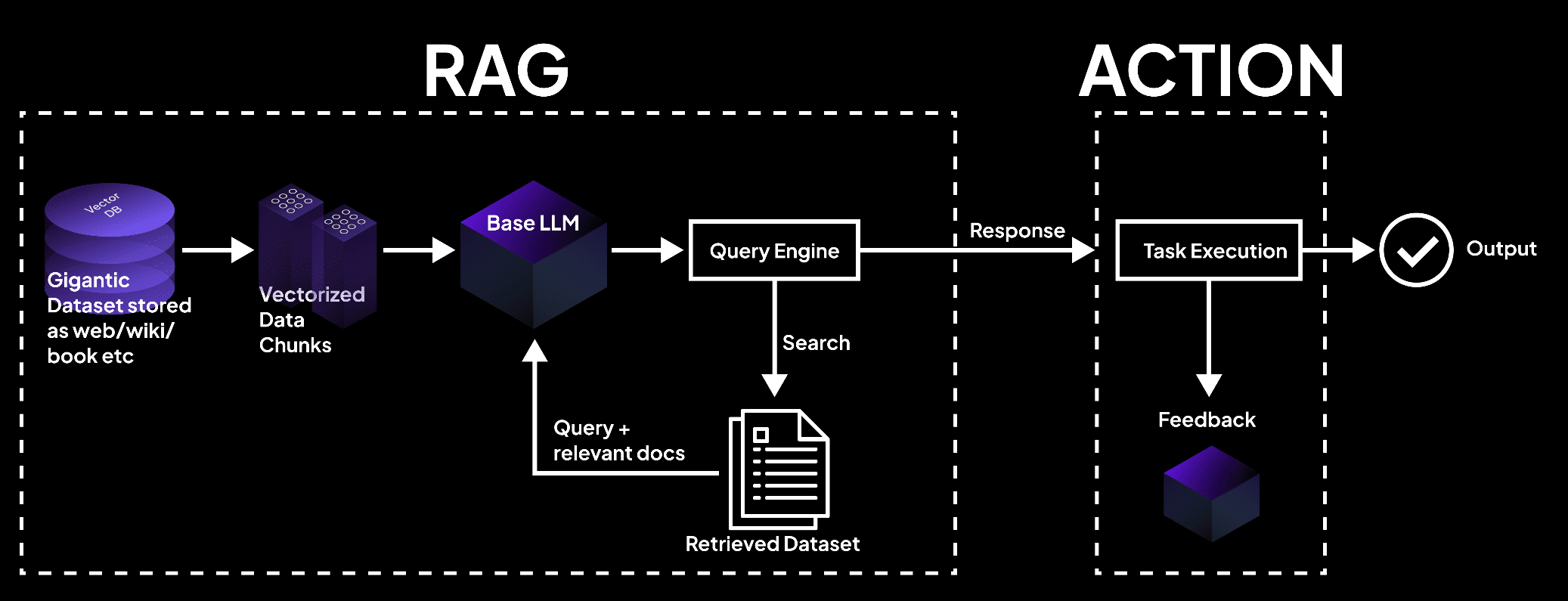
La imagen muestra un sistema RAG en el que una base de vectores procesa datos en bloques, consultados por un modelo de lenguaje para retornar documentos para la ejecución de tareas y salidas precisas. – superagi.com
El proceso de recuperación comienza con la indexación de fuentes de conocimiento externos, como bases de datos, documentos y páginas web. (Redis y Lewis et al.) Los recuperadores e indexadores desempeñan un papel crucial en este proceso, organizando y almacenando la información de manera eficiente en un formato que facilita la búsqueda rápida y la recuperación.
Cuando se plantea una consulta al sistema RAG, el recuperador busca en la base de conocimiento indexada para identificar las piezas de información más relevantes basándose en la similitud semántica y otras métricas de relevancia.
Una vez que se ha recuperado la información relevante, la componente de generación se hace cargo. El contenido recuperado se utiliza para estímular y guiar al modelo generativo de lenguaje, proporcionándole el contexto y el apoyo factual necesarios para generar respuestas precisas e informativas.
El modelo de lenguaje emplea técnicas avanzadas de inferencia, como mecanismos de atención y arquitecturas de transformador, para sintetizar la información recuperada con su conocimiento preexistente y generar texto coherente y fluido.
El flujo de información dentro de un sistema RAG puede ilustrarse de la siguiente manera:
graph LR
A[Query] --> B[Retriever]
B --> C[Indexed Knowledge Base]
C --> D[Relevant Information]
D --> E[Generator]
E --> F[Response]
Las ventajas de RAG son múltiples:
Esta fusión de capacidades de recuperación y generación permite la creación de respuestas que no solo son apropiadas contextualmente sino también informadas por la información más actual y precisa disponible. (Guu et al.)
Al aprovechar fuentes de conocimiento externas, RAG reduce significativamente la incidencia de alucinaciones o salidas incorrectas en términos de hechos, pitfalls comunes en modelos generativos puramente.
Además, RAG permite la integración de información actualizada, garantizando que las respuestas generadas reflejan el último conocimiento y los desarrollos en un determinado campo. Esto es particularmente crucial en campos como la atención médica, las finanzas y la investigación científica, donde la precisión y la actualidad de la información son de suma importancia. (Guu et al. y NVIDIA)
RAG también muestra una adaptabilidad destacable, permitiendo a los modelos de lenguaje manejar una amplia variedad de tareas con mejor rendimiento. Al recuperar información relevante dinámicamente según la consulta o el contexto específico, RAG capacita a los modelos para generar respuestas que se ajustan a las características particulares de cada tarea, ya sean responder a preguntas, generar contenido o aplicaciones específicas de dominio.
Numerosos estudios han demostrado la eficacia de RAG en la mejora de la precisión factual, la relevancia y la adaptabilidad de los modelos generativos de lenguaje.
Por ejemplo, Lewis et al. (2020) demostraron que RAG superó a los modelos generativos puros en una gama de tareas de respuesta a preguntas, alcanzando los mejores resultados del estado del arte en benchmarks como Natural Questions y TriviaQA. (Lewis et al.)
De manera similar, Izacard y Grave (2021) demostraron la superioridad de RAG frente a los modelos de lenguaje tradicionales en la generación de texto de largo formato coherente y consistente factualmente.
La Generación Aumentada con Recuperación representa un enfoque transformador para la generación de lenguaje, utilizando el poder de la recuperación de información para mejorar la exactitud, relevancia y adaptabilidad de los modelos generativos.
Al integrar sin problemas el conocimiento externo con las capacidades lingüísticas preexistentes, RAG abre nuevas posibilidades para la procesación del lenguaje natural y pavila el camino para sistemas de generación de lenguaje más inteligentes y confiables.
3.2 Estrategias de Integración Retriever-Generador
Los sistemas de Generación Aumentada con Recuperación (RAG) dependen de dos componentes clave: retrievers y modelos generativos. Los retrievers son responsables de buscar y recuperar información relevante de bases de conocimiento a gran escala de manera eficiente.
“Incluye dos fases principales: indexación y búsqueda. La indexación organiza los documentos para facilitar una recuperación eficiente, utilizando ya sea índices invertidos para recuperación dispersa o codificación de vectores densos para recuperación densa.” (Redis)
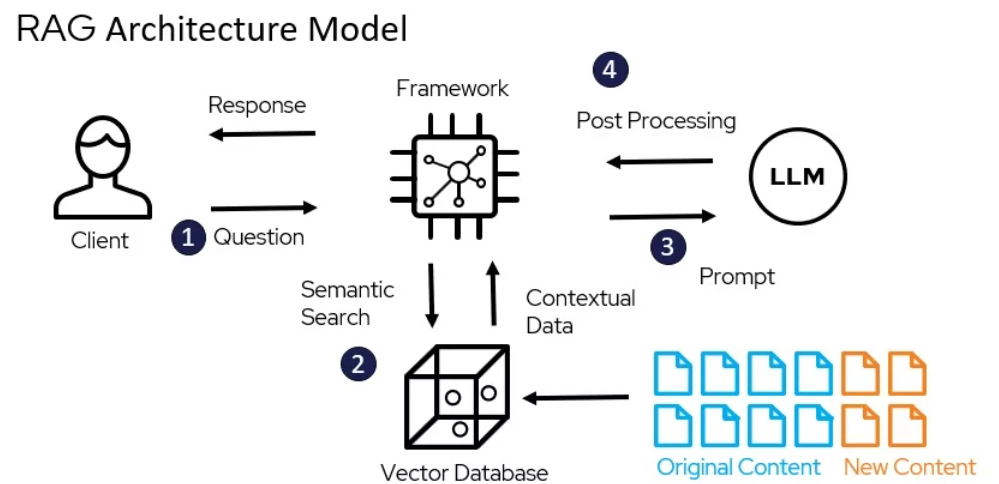
Modelo de Arquitectura de RAG – miro.medium.com
Técnicas de búsqueda dispersa, como TF-IDF y BM25, representan documentos como vectores dispersos de alta dimensión, donde cada dimensión corresponde a una palabra única en el vocabulario. La relevancia de un documento a una consulta se determine por la superposición de términos, ponderados por su importancia.
Por ejemplo, utilizando la popular biblioteca Elasticsearch, un recuperador basado en TF-IDF puede implementarse de la siguiente manera:
from elasticsearch import Elasticsearch
es = Elasticsearch()
es.index(index="documents", doc_type="_doc", body={"text": "This is a sample document."})
query = "sample"
results = es.search(index="documents", body={"query": {"match": {"text": query}}})
Técnicas de búsqueda densa, como la búsqueda de pasajes densos (DPR) y modelos basados en BERT, representan documentos y consultas como vectores densos en un espacio de embeddings continuo. La relevancia se determina por la similitud coseno entre los vectores de consulta y documento.
DPR se puede implementar utilizando la biblioteca Hugging Face Transformers:
from transformers import DPRContextEncoder, DPRQuestionEncoder
context_encoder = DPRContextEncoder.from_pretrained("facebook/dpr-ctx_encoder-single-nq-base")
question_encoder = DPRQuestionEncoder.from_pretrained("facebook/dpr-question_encoder-single-nq-base")
context_embeddings = context_encoder(documents)
query_embedding = question_encoder(query)
scores = torch.matmul(query_embedding, context_embeddings.transpose(0, 1))
Los modelos generativos, como GPT y T5, se utilizan en RAG para generar respuestas coherentes y relevantes contextualmente basadas en la información recuperada. Ajustar estos modelos en datos específicos del dominio y emplear técnicas de ingeniería de prompt puede mejorar significativamente su rendimiento en los sistemas RAG. (Comunidad DEV)
Estrategias de integración determinan cómo se Incorpora el contenido recuperado en los modelos generativos.
El componente de generación utiliza el contenido recuperado para formular respuestas coherentes y relevantes contextualmente con las fases de iniciación y deducción. (Redis)
Dos enfoques comunes son la concatenación y la atención cruzada.
La concatenación implica anexar las pasajes recuperados a la consulta de entrada, permitiendo al modelo generativo prestar atención a la información relevante durante el proceso de decodificación.
Aunque simple de implementar, este enfoque puede luchar con secuencias largas e información irrelevante. (Comunidad DEV) Las mecanismos de atención cruzada, como RAG-Token y RAG-Sequence, permiten que el modelo generativo seleccione atención selectiva a las pasajes recuperados en cada paso de decodificación.
Esto permite un mejor control fino sobre el proceso de integración, pero viene con una complejidad computacional mayor.
Por ejemplo, RAG-Token se puede implementar usando la biblioteca Hugging Face Transformers:
from transformers import RagTokenizer, RagRetriever, RagSequenceForGeneration
tokenizer = RagTokenizer.from_pretrained("facebook/rag-token-nq")
retriever = RagRetriever.from_pretrained("facebook/rag-token-nq", index_name="exact", use_dummy_dataset=True)
model = RagSequenceForGeneration.from_pretrained("facebook/rag-token-nq")
input_ids = tokenizer(query, return_tensors="pt").input_ids
retrieved_docs = retriever(input_ids)
generated_output = model.generate(input_ids, retrieved_docs=retrieved_docs)
La elección del recuperador, modelo generativo y estrategia de integración depende de los requisitos específicos del sistema RAG, como el tamaño y la naturaleza de la base de conocimiento, el equilibrio deseado entre eficiencia y efectividad, y el dominio de aplicación objetivo.
Capítulo 4: Aplicaciones y casos de uso.
Este capítulo explora el potencial transformador de la Generación Aumentada con Recuperación (RAG) en la revolución de las aplicaciones de lenguajes de recursos bajos y multilingües. Nos adentramos en estrategias como la traducción de documentos de origen a lenguajes ricos en recursos, el uso de embeddings multilingües y la aplicación de aprendizaje federado para superar limitaciones de datos y diferencias lingüísticas.
Además, abordamos el desafío crítico de mitigar las alucinaciones en sistemas RAG multilingües para asegurar una generación de contenido precisa y fiable. Al explorar estos enfoques innovadores, este capítulo ofrece una guía completa para aprovechar el poder de RAG para la inclusividad y la diversidad en el procesamiento de lenguaje.
4.1 Aplicaciones de RAG: QA a Escritura Creativa
La Generación Aumentada con Recuperación (RAG) ha encontrado numerosas aplicaciones prácticas en diversos dominios, mostrando su potencial para revolucionar nuestra interacción y generación de información. Al aprovechar el poder de la recuperación y la generación, los sistemas RAG han demostrado mejoras significativas en precisión, relevancia y compromiso del usuario.
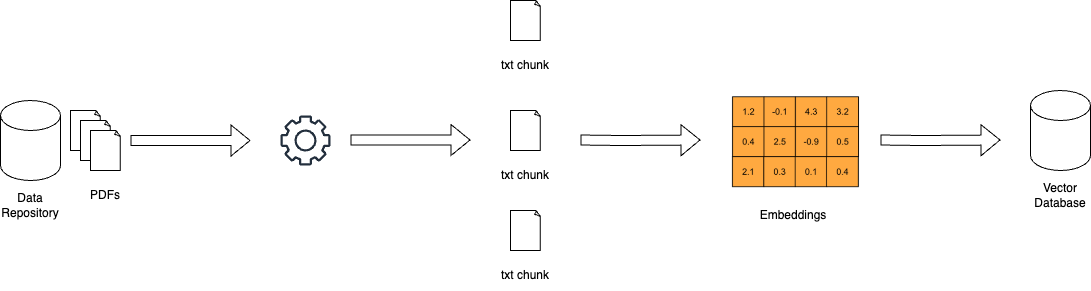
Cómo funciona RAG – miro.medium.com
Respuesta a Preguntas
RAG ha demostrado ser un cambio de juego en el campo de la respuesta a preguntas. Al recuperar información relevante de fuentes de conocimiento externos e integrándola en el proceso de generación, los sistemas RAG pueden proporcionar respuestas más precisas y contextualmente relevantes a las consultas de los usuarios. (LangChain y Django Stars)
Por ejemplo, Izacard y Grave (2021) propusieron un modelo basado en RAG llamado Fusion-in-Decoder (FiD), que alcanzó un rendimiento de punto de referencia en varias plataformas de evaluación de respuesta a preguntas, incluidas Natural Questions y TriviaQA. (Izacard and Grave)
FiD aprovecha un recuperador denso para obtener pasajes relevantes y un modelo generativo para sintetizar la información recuperada en una respuesta coherente, superando a los modelos generativos puros con una diferencia significativa. (Izacard and Grave)
Sistemas de diálogo
RAG también ha encontrado aplicaciones en la creación de agentes conversacionales más atractivos e informativos. Mediante la incorporación de conocimiento externo a través de la recuperación, los sistemas de dialogo basados en RAG pueden generar respuestas que no solo son apropiadas contextualmente sino también basadas en hechos. (LlamaIndex y MyScale)
Shuster et al. (2021) presentaron un sistema de dialogo basado en RAG llamado BlenderBot 2.0, que demostró mejores habilidades conversacionales que su predecesor. (Shuster et al.)
BlenderBot 2.0 recupera información relevante de un conjunto diverso de fuentes de conocimiento, incluyendo Wikipedia, artículos de noticias y medios sociales, lo que le permite participar en conversaciones más informadas y coherentes sobre un amplio abanico de temas. (Shuster et al.)
Resumen
RAG ha mostrado promesa en mejorar la calidad de los resúmenes generados al incorporar información relevante de varias fuentes. (Hyperight) Pasunuru et al. (2021) propusieron un modelo de resumen basado en RAG llamado PEGASUS-X, que recupera y integra pasajes relevantes de documentos externos para generar resúmenes más informativos y coherentes.
PEGASUS-X superó a los modelos generativos puramente en varios benchmarks de resumen, demostrando la eficacia de la recuperación en la mejora de la precisión factual y la relevancia de los resúmenes generados.
Escritura creativa
El potencial de RAG supera los límites de los dominios factuales y entra en el ámbito de la escritura creativa. Al recuperar pasajes relevantes de un corpus diverso de obras literarias, los sistemas RAG pueden generar historias o artículos noveles y atractivos.
Rashkin et al. (2020) presentaron un modelo de escritura creativa basado en RAG llamado CTRL-RAG, que recupera pasajes relevantes de un gran conjunto de datos de ficción a gran escala y los integra en el proceso de generación. CTRL-RAG demostró la capacidad para generar historias coherentes y estilísticamente consistentes, mostrando el potencial de RAG en aplicaciones creativas.
Estudios de caso
Varios documentos de investigación y proyectos han demostrado la eficacia de RAG en varios dominios.
Por ejemplo, Lewis et al. (2020) presentaron el marco RAG y lo aplicaron a la respuesta a preguntas de dominio abierto, alcanzando un rendimiento de punta en el benchmark Natural Questions. (Lewis et al.) Destacaron los retos de la recuperación eficiente y la importancia de ajustar el modelo generativo en pasajes recuperados.
En otro caso de estudio, Petroni et al. (2021) aplicaron RAG a la tarea de verificación de hechos, demostrando su capacidad para recuperar pruebas relevantes y generar veredictos precisos. Mostraron el potencial de RAG en la lucha contra la desinformación y la mejora de la confiabilidad de los sistemas de información.
El impacto de RAG en la experiencia del usuario y las métricas de negocio ha sido significativo. Proporcionando respuestas más precisas e informativas, los sistemas basados en RAG han mejorado la satisfacción del usuario y la participación. (LlamaIndex y MyScale)
En el caso de los agentes conversacionales, RAG ha permitido interacciones más naturales y coherentes, lo que ha llevado a un aumento en la retención de usuarios y la lealtad. (LlamaIndex y MyScale) En el ámbito de la creación creativa, RAG tiene el potencial para agilizar los procesos de creación de contenido y generar ideas novedosas, economizando tiempo y recursos para las empresas.
Así que, como pueden ver, las aplicaciones prácticas de RAG abarcan una amplia gama de dominios, desde la respuesta a preguntas y los sistemas de diálogo hasta la resumición y la creación creativa. Al aprovechar el poder de la recuperación y la generación, RAG ha demostrado mejoras significativas en la precisión, la relevancia y la participación del usuario.
Mientras el campo continúa evolucionando, podemos esperar ver más aplicaciones innovadoras de RAG, transformando la forma en que interactuamos y generamos información en varios contextos.
4.2 RAG para Lenguajes de Bajo Recurso y Entornos Multilingües
Aplicar el poder de la Generación Augmentada con Recuperación (RAG) para lenguajes de bajo recurso y entornos multilingües no es solo una oportunidad, es una necesidad. Con más de 7,000 lenguajes hablados en todo el mundo, muchos de los cuales carecen de recursos digitales sustanciales, el desafío es claro: ¿cómo aseguramos que estos lenguajes no se queden atrás en la era digital?
La Traducción como un Puente
Una estrategia efectiva es traducir los documentos fuente a un lenguaje con más recursos antes de indexar. Este enfoque aprovecha los extensos corpus disponibles en lenguajes como el inglés, mejorando significativamente la precisión y la relevancia de la recuperación.
Al traducir documentos al inglés, se puede acceder a los vastos recursos y técnicas de recuperación avanzadas ya desarrolladas para lenguajes de alto recurso, mejorando así el rendimiento de los sistemas RAG en contextos de bajo recurso.
Incorporación de Embeddings Multilingües
Los recientes avances en embeddings multilingües ofrecen otra solución prometedora. Al crear espacios de embeddings compartidos para varios lenguajes, se puede mejorar el desempeño cross-lingual incluso para lenguajes muy de bajo recurso.
Investigaciones han demostrado que la incorporación de lenguajes intermedios con embeddings de alta calidad puede llenar el hueco entre pares de lenguajes distantes, mejorando la calidad general de los embeddings multilingües.
Este método no solo mejora la precisión de búsqueda sino que además garantiza que el contenido generado sea relevante contextualmente y coherente lingüísticamente.
Aprendizaje Federado
El aprendizaje federado presenta una nueva aproximación para superar las limitaciones de compartición de datos y las diferencias lingüísticas. Mediante la afinización de modelos en fuentes de datos descentralizadas, se puede preservar la privacidad del usuario al mismo tiempo que se mejora el rendimiento del modelo en varios idiomas.
Este método ha demostrado una precisión superior en un 6,9% y una reducción en los parámetros de entrenamiento en un 99% en comparación con los métodos tradicionales, lo que lo convierte en una solución altamente eficiente y efectiva para los sistemas RAG multilingües.
Mitigación de las Alucinaciones
Un desafío crítico en la implementación de sistemas RAG en entornos multilingües es la mitigación de las alucinaciones, que son instancias en las que el modelo genera información factiblemente incorrecta o irrelevante.
Técnicas avanzadas de RAG, como RAG Modular, introducen nuevos módulos y estrategias de afinizado para abordar este problema. Al actualizar continuamente la base de conocimiento y emplear metríticas de evaluación rigurosas, se puede reducir significativamente la incidencia de las alucinaciones y garantizar que el contenido generado sea tanto preciso como fiable.
Implementación Práctica
Para implementar estas estrategias de manera efectiva, considere los siguientes pasos prácticos:
- Aprovechar la Traducción: Traduzca documentos de lenguajes con recursos bajos en un idioma con recursos altos como el inglés antes de indexarlos.
- Utilizar Embedimientos Multilingües: Incorporar lenguajes intermedios con alt calidad de embedimientos para mejorar el desempeño cross-lingüístico.
- Adoptar Aprendizaje Federado: Ajustar modelos en fuentes de datos descentralizadas para mejorar el desempeño mientras preserva la privacidad.
- Mitigar Hallucinaciones: Emplear técnicas avanzadas de RAG y actualizaciones continuas de base de conocimiento para asegurar precisión factual.
Al adoptar estas estrategias, puede mejorar significativamente el desempeño de los sistemas RAG en entornos de bajas recursos y multilingües, asegurando que ningún idioma quede atrás en la revolución digital.
Capítulo 5: Técnicas de Optimización
Este capítulo se adentra en las técnicas avanzadas de búsqueda que subyacen a la eficacia de los sistemas Retrieval-Augmented Generation (RAG). Exploramos cómo la optimización de bloques, la integración de metadatos, la indexación basada en grafos, las técnicas de alineación, la búsqueda híbrida y la reordenación mejoran la precisión, relevancia y comprensión de la información de retorno.
Al entender estas metodologías de vanguardia, adquirirá insights sobre cómo los sistemas RAG están evolucionando de simples motores de búsqueda a proveedores inteligentes de información capaces de entender consultas complejas y entregar respuestas precisas y relevantes en contexto.
5.1 Técnicas Avanzadas de Retorno para Optimizar Sistemas RAG
Los sistemas Retrieval Augmented Generation (RAG) están revolucionando la manera en que accedemos y utilizamos información. El corazón de estos sistemas radica en su habilidad para recuperar información relevante efectivamente.
Vamos a profundizar en las técnicas de búsqueda avanzadas que empodernan a los sistemas RAG para entregar respuestas precisas, relevantes contextualmente y completas.
Optimización de Chunks: Maximizar la Relevancia Mediante la Retracción Granular
En el mundo de los sistemas RAG, los documentos grandes pueden ser abrumadores. La optimización de chunks aborda este reto dividiendo textos extensos en unidades más manejables llamadas chunks. Esta granularidad permite que los sistemas de retracción sean capaces de identificar secciones específicas de texto que se alinean con los términos de la consulta, mejorando la precisión y la eficiencia.
El arte de la optimización de chunks radica en determinar el tamaño de chunk ideal y la superposición. Un chunk demasiado pequeño podría carecer de contexto, mientras que un chunk demasiado grande podría diluir la relevancia. La segmentación dinámica, una técnica que adapta el tamaño del chunk según la estructura y semántica del contenido, asegura que cada chunk sea coherente y significativo contextualmente.
Integración de Metadatos: Aprovechar el Poder de las Etiquetas de Información
Los metadatos, la información a menudo ignorada que acompaña a los documentos, puede ser una mina de oro para los sistemas de retracción. Al integrar metadatos como el tipo de documento, el autor, la fecha de publicación y las etiquetas de tema, los sistemas RAG pueden realizar búsquedas más dirigidas.
La búsqueda autoconsulta, una técnica permitida por la integración de metadatos, permite que el sistema genere consultas adicionales basadas en los resultados iniciales. Este proceso iterativo refina la búsqueda, asegurando que los documentos retenidos no solo se ajusten a la consulta sino que también cumplan con los requerimientos específicos y las necesidades contextuales del usuario.
Estructuras de Indexación Avanzadas: Redes Baseadas en Grafos para Consultas Complejas
Los métodos de indexación tradicionales, como los índices invertidos y las codificaciones de vectores densos, presentan limitaciones al tratar con consultas complejas que implican varias entidades y sus relaciones. Los índices basados en grafos ofrecen una solución al organizar los documentos y sus conexiones en una estructura de grafo.
Esta organización en grafo permite una exploración y recuperación eficientes de documentos relacionados, incluso en escenarios intrincados. La indexación jerárquica y la búsqueda de vecinos más cercanos aproximada refuerzan además la escalabilidad y la velocidad de los sistemas de recuperación basados en grafos.
Técnicas de Alineación: Garantizar Precisión y Reducir Alucinaciones
La credibilidad de los sistemas RAG depende de su capacidad para proporcionar información precisa. Las técnicas de alineación, como el entrenamiento contrafactual, abordan este tema. Exigiendo al modelo que se exponga a escenarios hipotéticos, el entrenamiento contrafactual le enseña a distinguir entre hechos del mundo real y información generada, reduciendo así las alucinaciones.
En los sistemas RAG multimodales, que integran información de varias fuentes como texto e imágenes, el aprendizaje contrastivo juega un papel crucial. Esta técnica alinea las representaciones semánticas de diferentes modalidades de datos, garantizando que la información recuperada sea coherente e integrada contextualmente.
Búsqueda Híbrida: Mezclar Precisión de Palabras Clave con Comprensión Semántica
La búsqueda híbrida combina lo mejor de ambos mundos: la velocidad y la precisión de la búsqueda por palabras clave con el entendimiento semántico de la búsqueda por vector. Inicialmente, una búsqueda por palabras clave reduce rápidamente el conjunto de documentos potenciales.
Posteriormente, una búsqueda basada en vectores refina los resultados según la similitud semántica. Este enfoque es particularmente efectivo cuando las coincidencias de palabras clave exactas son esenciales, pero también es necesario un entendimiento más profundo de la intención de la consulta para una recuperación precisa.
Re-ranking: Refiniendo la Relevancia para la Respuesta Óptima
En la fase final de recuperación, el re-ranking entra en juego para ajustar finamente los resultados. Los modelos de aprendizaje automático, como los cross-encoders, revaloran las puntuaciones de relevancia de los documentos recuperados. Procesando la consulta y los documentos juntos, estos modelos adquieren un entendimiento más profundo de su relación.
Esta comparación tanctica garantiza que los documentos de mayor ranking realmente se alinean con la consulta del usuario y el contexto, proporcionando una experiencia de búsqueda más satisfactoria e informativa.
El poder de los sistemas RAG radica en su capacidad para retirar y presentar información de manera fluida. Empleando estas técnicas de recuperación avanzadas – optimización de bloques, integración de metadatos, índice basado en grafos, técnicas de alineación, búsqueda híbrida y re-ranking – los sistemas RAG se transforman en mucho más que motores de búsqueda. Evolucionan en proveedores inteligentes de información, capaces de comprender consultas complejas, descubrir matices y proporcionar respuestas precisas, relevantes y confiables.
Capítulo 6: Retos y Innovaciones
Este capítulo se adentra en los desafíos críticos y las direcciones futuras en el desarrollo y la implementación de los sistemas RAG (Retrieval-Augmented Generation).
Exploramos las complejidades de la evaluación de los sistemas RAG, incluyendo la necesidad de metrices comprensivas y frameworks adaptativos para evaluar con precisión su desempeño. También abordamos consideraciones éticas como la mitigación de sesgos y la equidad en la búsqueda de información y la generación.
También examinamos la importancia de la aceleración hardware y estrategias de implementación eficientes, destacando el uso de hardware especializado y herramientas de optimización como Optimum para mejorar el rendimiento y la escalabilidad.
Comprendiendo estos desafíos y explorando soluciones potenciales, este capítulo proporciona un mapa de carretera integral para el progreso continuo y la implementación responsable de la tecnología RAG.
6.1 Desafíos y Directores Futuros
Los sistemas Retrieval-Augmented Generation (RAG) han demostrado un potencial excepcional en mejorar la precisión, relevancia y coherencia del texto generado. Sin embargo, el desarrollo y la implementación de los sistemas RAG también presentan desafíos significativos que deben ser abordados para realizar plenamente su potencial.
“La evaluación de los sistemas RAG, de esta manera, implica considerar varios componentes específicos y la complejidad de la evaluación del sistema completo.” (Salemi et al.)
Desafíos en la Evaluación de Sistemas RAG
Las principales desafíos técnicos en RAG consisten en garantizar la recuperación eficiente de información relevante desde bases de conocimiento a gran escala. (Salemi et al. y Yu et al.)
Conforme el tamaño y la diversidad de las fuentes de conocimiento continúan creciendo, desarrollar mecanismos de recuperación escalables y robustos se vuelve cada vez más crítico. Técnicas tales como indexación jerárquica, búsqueda de vecinos aproximados y estrategias de recuperación adaptativas deben ser exploradas para optimizar el proceso de recuperación.
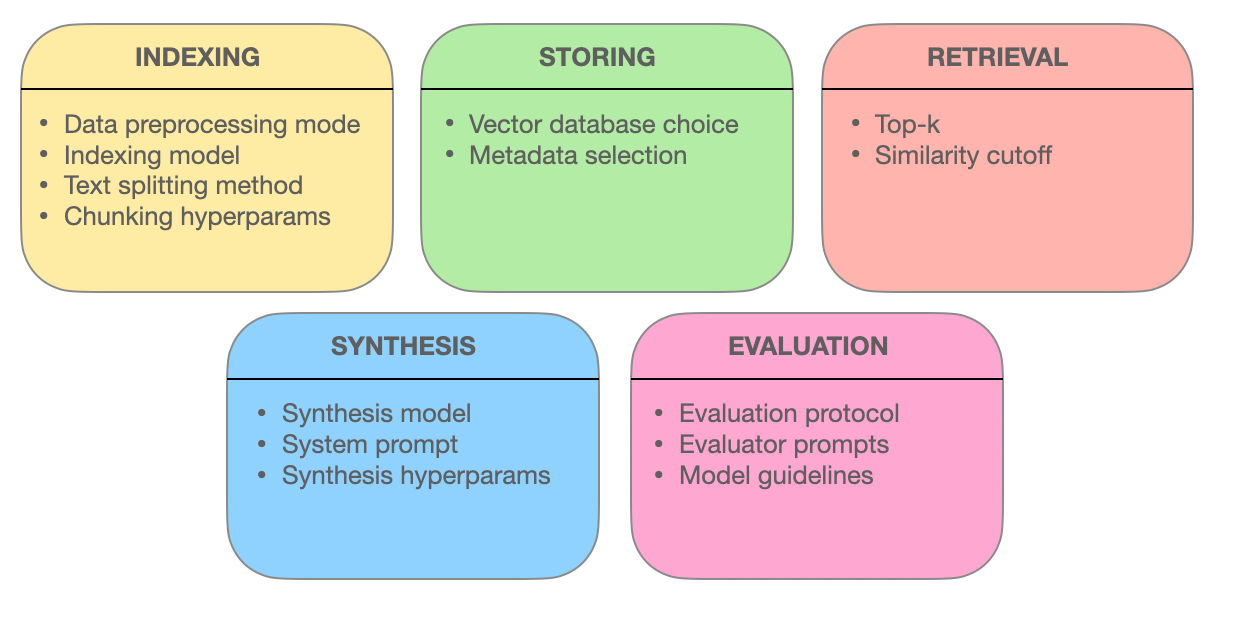
Algunos de los elementos involucrados en un sistema RAG – miro.medium.com
Otro desafío significativo es mitigar el problema de la alucinación, donde el modelo generativo produce información factualmente incorrecta o inconsistente.
Por ejemplo, un sistema RAG podría generar un evento histórico que nunca ocurrió o atribuir incorrectamente un descubrimiento científico. Aunque la recuperación ayuda a basar el texto generado en conocimientos factuales, asegurar la fidelidad y la coherencia de la salida generada sigue siendo un problema complejo.
Por ejemplo, un sistema RAG puede recuperar información precisa sobre un descubrimiento científico de una fuente fiable como Wikipedia, pero el modelo generativo podría aún alucinar al combinar esta información incorrectamente o agregar detalles no-existentes.
El desarrollo de mecanismos eficaces para detectar y prevenir alucinaciones es un área de investigación activa. Se están explorando técnicas como la verificación de hechos utilizando bases de datos externas y la comprobación de consistencia a través de la referenciación cruzada de múltiples fuentes. Estos métodos buscan asegurar que el contenido generado permanezca preciso y fiable, a pesar de los desafíos inherentes a la alineación de los procesos de búsqueda y generación.
La integración de diversas fuentes de conocimiento, como bases de datos estructuradas, texto no estructurado y datos multimodales, plantea desafíos adicionales en los sistemas RAG. (Yu et al. y Zilliz) La alineación de las representaciones y semánticas entre diferentes modalidades de datos y formatos de conocimiento requiere técnicas sofisticadas, como la atención cruzada y la inserción de grafos de conocimiento. Asegurar la compatibilidad e interoperabilidad de diversas fuentes de conocimiento es crucial para el funcionamiento efectivo de los sistemas RAG. (Zilliz)
Más allá de los desafíos técnicos, los sistemas RAG también plantean consideraciones éticas importantes. Asegurar un proceso de búsqueda e generación de información imparcial y justo es una consideración crítica. Los sistemas RAG pueden amplificar inadvertidamente los sesgos presentes en los datos de entrenamiento o en las fuentes de conocimiento, lo que puede llevar a resultados discriminativos o engañosos. (Salemi et al. y Banafa)
El desarrollo de técnicas para detectar y mitigar los sesgos, como el entrenamiento adversario y la recuperación equitativa, es una dirección de investigación importante. (Banafa)
Direcciones de Investigación Futuras
Para enfrentar los desafíos en la evaluación de los sistemas RAG, se pueden explorar varias soluciones potenciales y direcciones de investigación.
El desarrollo de métricas de evaluación comprensivas que capturar la interacción entre la precisión de recuperación y la calidad generativa es crucial. (Salemi et al.)
Las métricas que evalúan la relevancia, coherencia y exactitud factual del texto generado, considerando al mismo tiempo la eficacia del componente de recuperación, deben ser establecidas. (Salemi et al.) Esto requiere un enfoque holístico que supera las métricas tradicionales como BLEU y ROUGE y incorpora evaluaciones humanas y medidas específicas de tarea.
Explorar frameworks de evaluación adaptativos y en tiempo real es otra dirección prometedora.
Los sistemas RAG operan en entornos dinámicos donde las fuentes de conocimiento y los requisitos del usuario pueden evolucionar con el tiempo. (Yu et al.) Desarrollar frameworks de evaluación que se puedan adaptar a estos cambios y proporcionar retroalimentación en tiempo real sobre el rendimiento del sistema es fundamental para el mejoramiento continuo y el monitoreo.
Esto puede implicar técnicas como el aprendizaje en línea, el aprendizaje activo y el aprendizaje por reforzamiento para actualizar las métricas de evaluación y los modelos basándonos en la retroalimentación del usuario y el comportamiento del sistema. (Yu et al.)
Los esfuerzos colaborativos entre investigadores, profesionales de la industria y expertos en el dominio son necesarios para avanzar en la evaluación de los Sistemas de AI RAG. La establecimiento de benchmarks estándares, conjuntos de datos y protocolos de evaluación puede facilitar la comparación y la reproductividad de los sistemas de RAG entre diferentes dominios y aplicaciones. (Salemi et al. y Banafa)
Participar con los interesados directos, incluyendo a los usuarios finales y los responsables políticos, es fundamental para asegurar que el desarrollo y la implementación de los sistemas de RAG se alineen con los valores de la sociedad y los principios éticos. (Banafa)
Así, mientras que los sistemas de RAG han demostrado un gran potencial, abordar los retos en su evaluación es crucial para su amplia adopción y la confianza. Mediante el desarrollo de metrificos de evaluación comprensivos, la exploración de frameworks de evaluación adaptativos y en tiempo real, y la fomentación de esfuerzos colaborativos, podemos pavimentar el camino para sistemas de RAG más confiables, imparciales y efectivos.
Conforme el campo continúa evolucionando, es essential priorizar esfuerzos de investigación que no solo avancen las capacidades técnicas de los Sistemas de AI RAG sino que también aseguran su implementación responsable y ética en aplicaciones del mundo real.
6.2 Aceleración Hardware y Eficiente Implementación de Sistemas de RAG
La utilización de aceleración de hardware es clave para el despliegue eficiente de los sistemas de Generación Aumentada por Recuperación (RAG). Al desviar tareas computacionalmente intensivas a hardware especializado, puede mejorar sustancialmente el rendimiento y la escalabilidad de sus modelos RAG.
Aprovechar la Hardware Especializada
Las herramientas de optimización específicas para hardware de Optimum ofrecen ventajas sustanciales. Por ejemplo, la implementación de sistemas RAG en procesadores Habana Gaudi puede reducir notablemente la latencia de inferción, mientras que las optimizaciones de Intel Neural Compressor pueden mejorar más metricas de latencia. El hardware AWS Inferentia, optimizado a través de Optimum Neuron, puede mejorar las capacidades de throughput, haciendo que su sistema RAG sea más responsivo y eficiente.
Optimizar el Utilización de Recursos
La utilización eficiente de recursos es crucial. Las optimizaciones de Optimum ONNX Runtime pueden llevar a un uso más eficiente de la memoria, mientras que la API BetterTransformer puede mejorar la utilización del CPU y el GPU. Estas optimizaciones aseguran que su sistema RAG opera con la máxima eficiencia, reduciendo costos operativos y mejorando el rendimiento.
Escalabilidad y Flexibilidad
Optimum brinda una transición sin problemas entre diferentes aceleradores de hardware, permitiendo escalabilidad dinámica. Esta compatibilidad multi-hardware le permite adaptarse a demandas computacionales variables sin reconfiguración significante. Además, las características de cuantificación y recortado de modelos en Optimum pueden facilitar tamaños de modelo más eficientes, haciendo que el despliegue sea más fácil y económico.
Estudios de Casos y Aplicaciones Reales
Considere la aplicación de Optimum en la búsqueda de información de la salud. Al aprovechar optimizaciones específicas para hardware, los sistemas RAG pueden manejar eficientemente grandes conjuntos de datos, proporcionando búsquedas de información precisas y oportunas. Esto no solo mejora la calidad del suministro de atención médica sino que también mejora la experiencia del usuario global.
Pasos prácticos para la implementación
- Seleccione hardware adecuado: Elija aceleradores de hardware como Habana Gaudi o AWS Inferentia según sus requisitos de rendimiento específicos.
- Utilice herramientas de optimización: Implemente las herramientas de optimización de Optimum para mejorar la latencia, la throughput y el uso de recursos.
- Asegúrese de la escalabilidad: Utilice la compatibilidad con varios hardware para escalar dinámicamente su sistema RAG según sea necesario.
- Optimice el tamaño del modelo: Use la cuantización y el recorte del modelo para reducir el sobrecarga computacional y facilitar una implementación más fácil.
Al integrar estas estrategias, puede mejorar significativamente el rendimiento, la escalabilidad y la eficiencia de sus sistemas RAG, asegurándose que estén bien equipados para manejar aplicaciones complejas y reales.
Conclusión: El potencial transformador de RAG
La Generación Aumentada por Búsqueda (RAG) representa un paradigma transformador en la procesamiento del lenguaje natural, integrando sin problemas el poder de la búsqueda de información con las capacidades generativas de los grandes modelos de lenguaje.
Aprovechando fuentes de conocimiento externos, los sistemas RAG han demostrado mejorías notables en la precisión, relevancia y coherencia del texto generado a través de una amplia gama de aplicaciones, desde la respuesta a preguntas y los sistemas de diálogo hasta la resumición y la creación literaria.
La evolución de los modelos de lenguaje, desde los sistemas basados en reglas tempranos hasta las arquitecturas neuronales de punto de referencia como BERT y GPT-3, ha abierto la puerta al surgimiento de RAG. Los límites de la memoria puramente paramétrica en los modelos de lenguaje tradicionales, como los límites de fecha del conocimiento y las inconsistencias factuales, han sido efectivamente abordados mediante la incorporación de una memoria no paramétrica a través de mecanismos de búsqueda.
Los componentes centrales de los sistemas RAG, es decir, los retractores y los modelos generativos, trabajan en sinergia para producir salidas contextualmente relevantes y basadas en hechos.
Los retractores, que emplean técnicas como la búsqueda dispersa y densa, buscan eficientemente a través de bases de conocimiento vastas para identificar la información más pertinente. Los modelos generativos, que emplean arquitecturas como GPT y T5, sintetizan el contenido recuperado en texto coherente y fluido.
Las estrategias de integración, como la concatenación y la atención cruzada, determinan cómo se Incorpora la información recuperada al proceso de generación.
Las aplicaciones prácticas de RAG van desde diversos campos, mostrando su potencial para revolucionar varias industrias.
En la respuesta a preguntas, RAG ha mejorado significativamente la precisión y relevancia de las respuestas, permitiendo un mejor recuperación de información informativa y confiable. Los sistemas de diálogo han beneficiado de RAG,resultando en conversaciones más atractivas y coherentes. Las tareas de resumen han visto una calidad y coherencia mejoradas a través de la integración de información relevante de múltiples fuentes. Incluso la creación literaria ha sido explorada, con los sistemas RAG generando historias noveles y estilísticamente consistentes.
Sin embargo, el desarrollo y la evaluación de los sistemas RAG también presentan desafíos importantes. La recuperación eficiente de bases de conocimiento a gran escala, la mitigación de la ilusión y la integración de diversas modalidades de datos son entre los obstáculos técnicos que deben ser abordados. Las consideraciones éticas, como asegurar una recuperación y generación de información imparcial y justas, son cruciales para la aplicación responsable de los sistemas RAG.
Para aprovechar plenamente el potencial de RAG, futuras direcciones de investigación deben enfocarse en desarrollar métricas de evaluación comprensivas que capturen la interacción entre la precisión de recuperación y la calidad generativa.
Frameworks de evaluación adaptativos y en tiempo real que puedan manejar la naturaleza dinámica de los sistemas RAG son imprescindibles para la mejora continua y el monitoreo. Es necesario el esfuerzo colaborativo entre investigadores, profesionales de la industria y expertos en los dominios para establecer pautas estándares, conjuntos de datos y protocolos de evaluación.
Al evolucionar el campo de RAG, éste muestra un inmenso potencial para transformar la manera en que interactuamos y generamos información. Al aprovechar el poder de la recuperación y la generación, los sistemas RAG tienen el potencial para revolucionar varios campos, desde la recuperación de información y los agentes conversacionales hasta la creación de contenido y la descubierta de conocimiento.
La Recuperación-Aumentada Generación representa un hito significativo en el camino hacia una generación de lenguaje más inteligente, precisa y relevante contextualmente.
Al unir el espacio entre la memoria paramétrica y no paramétrica, los sistemas RAG han abierto nuevas posibilidades para la procesamiento del lenguaje natural y sus aplicaciones.
Con la evolución de la investigación y la resolución de los desafíos, podemos esperar que RAG juegue un papel cada vez más central en la formación del futuro de la interacción hombre-máquina y de la generación de conocimiento.
Acerca del Autor
Vahe Aslanyan aquí, en el núcleo de la informática, las ciencias de datos y la inteligencia artificial. Visita vaheaslanyan.com para ver un portafolio que es testimonio de la precisión y el progreso. Mi experiencia cruza el abismo entre el desarrollo full-stack y la optimización de productos de inteligencia artificial, impulsado por la resolución de problemas de nuevas maneras.
Con un historial que incluye la creación de un líder en bootcamps de ciencia de datos y trabajar con especialistas de la industria más destacados, mi enfoque sigue centrado en elevar la educación tecnológica a estándares universales.
¿Cómo Puedes Invertirte Más Profundamente?
Después de estudiar esta guía, si estás interesado en invertirte aún más y el aprendizaje estructurado es tu estilo, considera unirte con nosotros en LunarTech, ofrecemos cursos individuales y Bootcamp en Ciencia de Datos, Aprendizaje Automático y AI.
Proveemos un programa completo que ofrece una comprensión detallada de la teoría, implementación práctica en mano, material de práctica extensivo y preparación de entrevistas personalizada para situarte para el éxito en tu propio paso.
Puede echar un vistazo a nuestro Bootcamp de Ciencia de Datos Ultimate y unirse a una prueba gratuita para probar el contenido de primera mano. Esto ha obtenido el reconocimiento de ser uno de los Mejores Bootcamps de Ciencia de Datos de 2023 y ha sido destacado en publicaciones respetadas como Forbes, Yahoo, Entrepreneur y más. Esta es su oportunidad de formar parte de una comunidad que prospera en innovación y conocimiento. ¡Aquí está el mensaje de bienvenida!
Conecte conmigo.

LunarTech Newsletter
- Sígueme en LinkedIn y obtén un montón de Recursos Gratuitos en CS, ML y AI
- Visita mi Sitio Web Personal
- Suscríbete a mi The Data Science and AI Newsletter
Si quieres saber más sobre una carrera en Data Science, Machine Learning y AI, y aprender cómo obtener un trabajo de Data Science, puedes descargar este manual gratuito de Carrera en Data Science y AI.
Source:
https://www.freecodecamp.org/news/retrieval-augmented-generation-rag-handbook/