













Estado actual de MySQL 5.7
MySQL 5.7 no es ideal en términos de escalabilidad. La siguiente figura ilustra la relación entre el throughput TPC-C y la concurrencia en MySQL 5.7.39 bajo una configuración específica. Esto incluye establecer el nivel de aislamiento de transacción en Read Committed y ajustar el parámetro innodb_spin_wait_delay para mitigar la degradación del throughput.
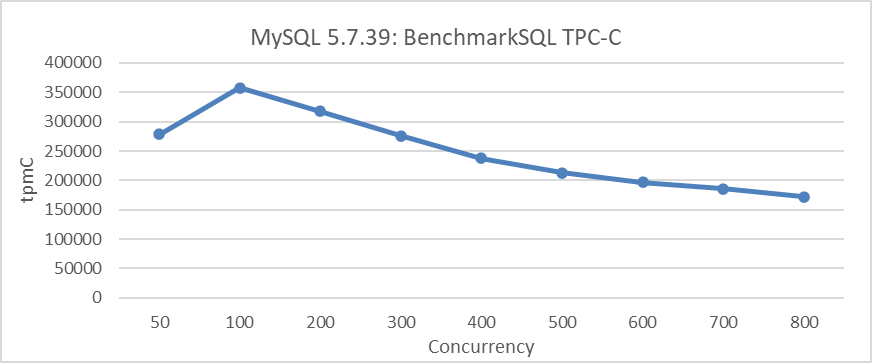
Figura 1: Problemas de escalabilidad en MySQL 5.7.39 durante las pruebas BenchmarkSQL
A partir de la figura, es evidente que los problemas de escalabilidad limitan significativamente el aumento en el throughput de MySQL. Por ejemplo, tras 100 concurrencias, el throughput comienza a declinar.
Para addressed el issue anterior mencionado del colapso de rendimiento, se empleó el pool de hilos de Percona. La siguiente figura ilustra la relación entre el throughput TPC-C y la concurrencia después de configurar el pool de hilos de Percona.
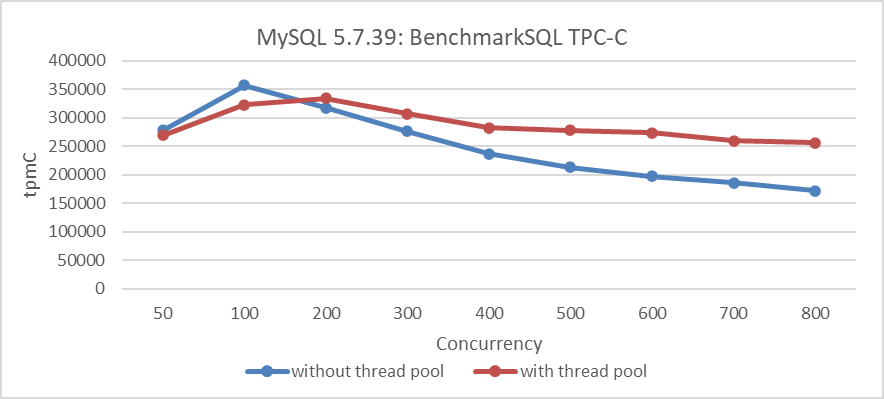
Figura 2: El pool de hilos de Percona mitiga los problemas de escalabilidad en MySQL 5.7.39
Aunque el pool de hilos introduce un poco de overhead y ha disminuido el rendimiento máximo, ha mitigado el issue del colapso de rendimiento bajo altas concurrencias.
Estado actual de MySQL 8.0
Veamos los esfuerzos que MySQL 8.0 ha realizado en torno a la escalabilidad.
Optimización del registro de reescritura
La primera mejora importante es la optimización del registro de reescritura [3].
commit 6be2fa0bdbbadc52cc8478b52b69db02b0eaff40
Author: Paweł Olchawa <[email protected]>
Date: Wed Feb 14 09:33:42 2018 +0100
WL#10310 Redo log optimization: dedicated threads and concurrent log buffer.
0. Log buffer became a ring buffer, data inside is no longer shifted.
1. User threads are able to write concurrently to log buffer.
2. Relaxed order of dirty pages in flush lists - no need to synchronize
the order in which dirty pages are added to flush lists.
3. Concurrent MTR commits can interleave on different stages of commits.
4. Introduced dedicated log threads which keep writing log buffer:
* log_writer: writes log buffer to system buffers,
* log_flusher: flushes system buffers to disk.
As soon as they finished writing (flushing) and there is new data to
write (flush), they start next write (flush).
5. User threads no longer write / flush log buffer to disk, they only
wait by spinning or on event for notification. They do not have to
compete for the responsibility of writing / flushing.
6. Introduced a ring buffer of events (one per log-block) which are used
by user threads to wait for written/flushed redo log to avoid:
* contention on single event
* false wake-ups of all waiting threads whenever some write/flush
has finished (we can wake-up only those waiting in related blocks)
7. Introduced dedicated notifier threads not to delay next writes/fsyncs:
* log_write_notifier: notifies user threads about written redo,
* log_flush_notifier: notifies user threads about flushed redo.
8. Master thread no longer has to flush log buffer.
...
30. Mysql test runner received a new feature (thanks to Marcin):
--exec_in_background.
Review: RB#15134
Reviewers:
- Marcin Babij <[email protected]>,
- Debarun Banerjee <[email protected]>.
Performance tests:
- Dimitri Kravtchuk <[email protected]>,
- Daniel Blanchard <[email protected]>,
- Amrendra Kumar <[email protected]>.
QA and MTR tests:
- Vinay Fisrekar <[email protected]>.Se realizó una prueba que compara el throughput TPC-C con diferentes niveles de concurrencia antes y después de la optimización. Los detalles específicos se muestran en la siguiente figura:
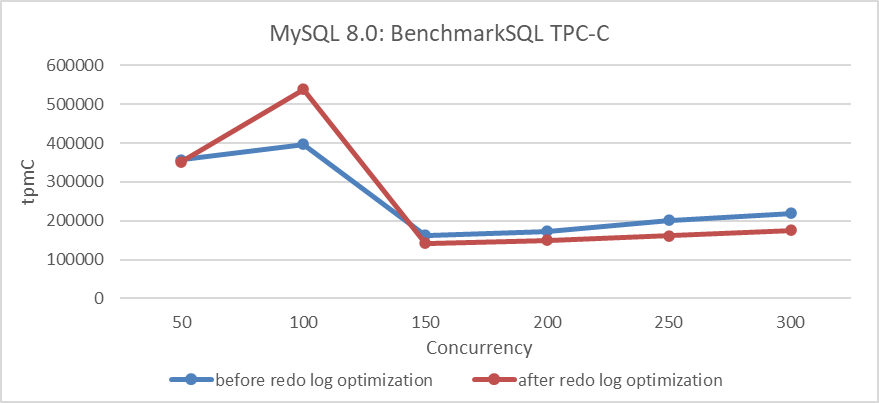
Figura 3: Impacto de la optimización del log de redo en diferentes niveles de concurrencia
Los resultados de la figura muestran una mejora significativa en la throughput a niveles bajos de concurrencia.
Optimización de Lock-Sys a través de la partición de latches
La segunda mejora importante es la optimización de Lock-Sys [5].
commit 1d259b87a63defa814e19a7534380cb43ee23c48
Author: Jakub Łopuszański <[email protected]>
Date: Wed Feb 5 14:12:22 2020 +0100
WL#10314 - InnoDB: Lock-sys optimization: sharded lock_sys mutex
The Lock-sys orchestrates access to tables and rows. Each table, and each row,
can be thought of as a resource, and a transaction may request access right for
a resource. As two transactions operating on a single resource can lead to
problems if the two operations conflict with each other, Lock-sys remembers
lists of already GRANTED lock requests and checks new requests for conflicts in
which case they have to start WAITING for their turn.
Lock-sys stores both GRANTED and WAITING lock requests in lists known as queues.
To allow concurrent operations on these queues, we need a mechanism to latch
these queues in safe and quick fashion.
In the past a single latch protected access to all of these queues.
This scaled poorly, and the managment of queues become a bottleneck.
In this WL, we introduce a more granular approach to latching.
Reviewed-by: Pawel Olchawa <[email protected]>
Reviewed-by: Debarun Banerjee <[email protected]>
RB:23836Basándonos en el programa antes y después de optimizar con Lock-Sys, utilizando BenchmarkSQL para comparar la throughput de TPC-C con la concurrencia, los resultados específicos se muestran en la siguiente figura:
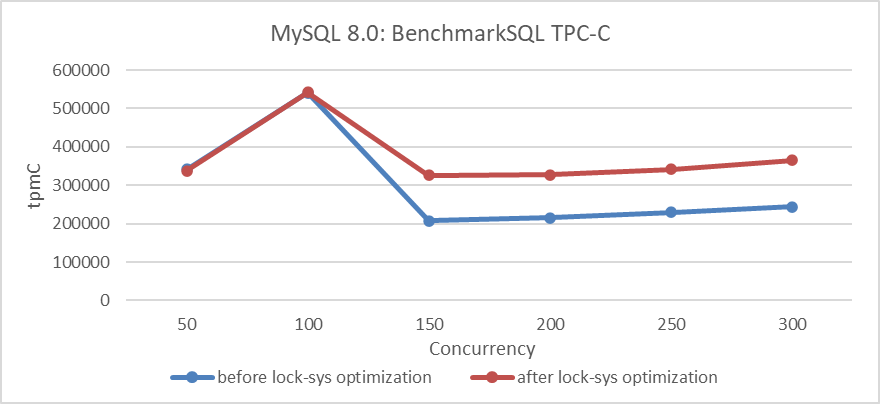
Figura 4: Impacto de la optimización de Lock-Sys en diferentes niveles de concurrencia
Desde la figura, se puede observar que la optimización de Lock-Sys mejora significativamente la throughput bajo altos niveles de concurrencia, mientras que el efecto es menos pronunciado a niveles bajos de concurrencia debido a menos conflictos.
Partición de latches para trx-sys
La tercera mejora importante es la partición de latches para trx-sys.
commit bc95476c0156070fd5cedcfd354fa68ce3c95bdb
Author: Paweł Olchawa <[email protected]>
Date: Tue May 25 18:12:20 2021 +0200
BUG#32832196 SINGLE RW_TRX_SET LEADS TO CONTENTION ON TRX_SYS MUTEX
1. Introduced shards, each with rw_trx_set and dedicated mutex.
2. Extracted modifications to rw_trx_set outside its original critical sections
(removal had to be extracted outside trx_erase_lists).
3. Eliminated allocation on heap inside TrxUndoRsegs.
4. [BUG-FIX] The trx->state and trx->start_time became converted to std::atomic<>
fields to avoid risk of torn reads on egzotic platforms.
5. Added assertions which ensure that thread operating on transaction has rights
to do so (to show there is no possible race condition).
RB: 26314
Reviewed-by: Jakub Łopuszański [email protected]Basándonos en estas optimizaciones antes y después, utilizando BenchmarkSQL para comparar la throughput de TPC-C con la concurrencia, los resultados específicos se muestran en la siguiente figura:
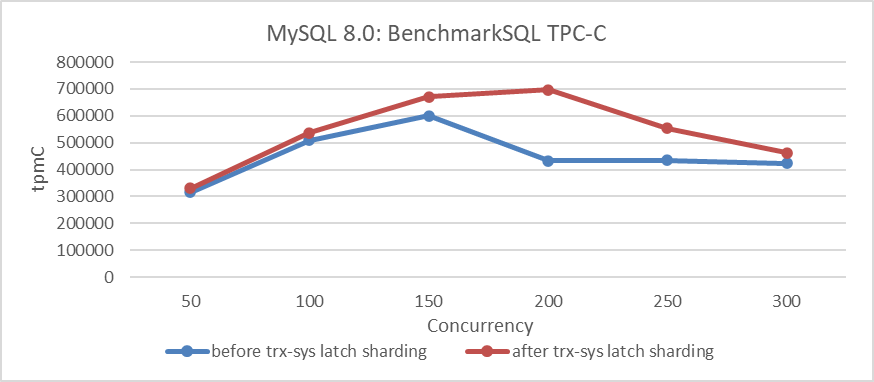
Figura 5: Impacto de la partición de latches en trx-sys en diferentes niveles de concurrencia
Desde la figura, se puede ver que esta mejora aumenta significativamente la throughput de TPC-C, alcanzando su punto máximo a 200 de concurrencia. Es importante notar que el impacto disminuye a 300 de concurrencia, principalmente debido a problemas de escalabilidad en el subsistema trx-sys relacionados con el MVCC ReadView.
Refinamiento de MySQL 8.0
Las mejoras restantes son nuestras mejoras independientes.
Mejoras en la estructura de MVCC ReadView
La primera mejora importante es la mejora de la estructura de datos MVCC ReadView [1].
Se realizaron pruebas de comparación de rendimiento para evaluar la eficacia de la optimización de MVCC ReadView. La figura siguiente muestra una comparación de throughput TPC-C con diferentes niveles de concurrencia, antes y después de modificar la estructura de datos MVCC ReadView.
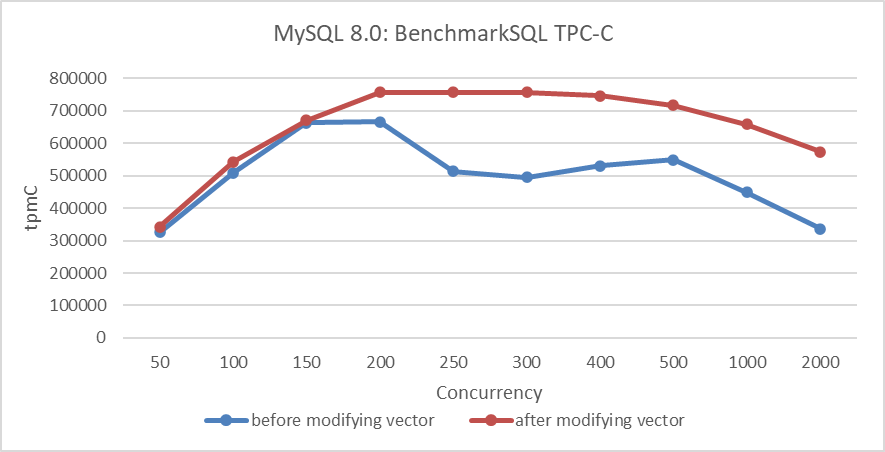
Figura 6: Comparación de rendimiento antes y después de adoptar la nueva estructura de datos híbrida en NUMA
Desde la figura, resulta evidente que esta transformación ha optimizado principalmente la escalabilidad y ha mejorado el throughput máximo de MySQL en entornos NUMA.
Evitar problemas de doble bloqueo
La segunda mejora importante que hemos realizado se refiere al problema de doble bloqueo, donde “doble bloqueo” se refiere a la necesidad del bloqueo global trx-sys por ambos view_open y view_close [1].
Usando la versión optimizada de MVCC ReadView, comparar el throughput TPC-C antes y después de las modificaciones. Los detalles se muestran en la siguiente figura:
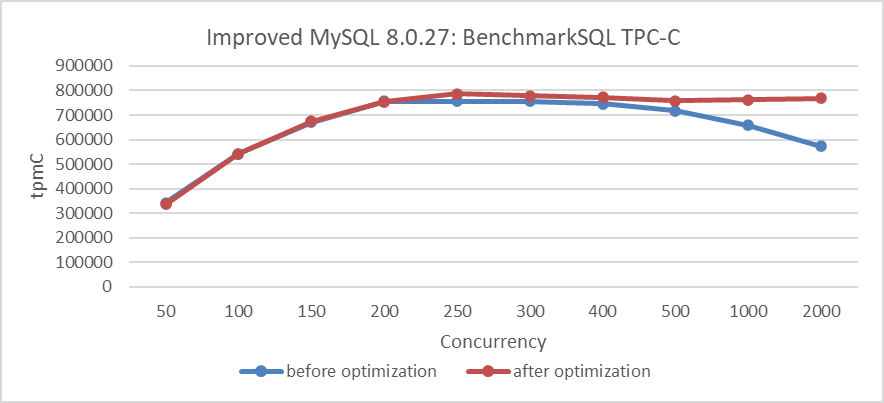
Figura 7: Mejora del rendimiento después de eliminar el cuello de botella del doble bloqueo
Desde la figura, resulta evidente que las modificaciones han mejorado significativamente la escalabilidad bajo condiciones de alta concurrencia.
Mechanismo de throttling de transacciones
La mejora final es la implementación de un mecanismo de throttling de transacciones para proteger contra la caída de rendimiento bajo una concurrencia extrema [1] [2] [4].
La siguiente figura representa la prueba de carga de escalabilidad TPC-C realizada después de implementar los mecanismos de limitación de transacciones. La prueba se realizó en un escenario con NUMA BIOS deshabilitado, limitando la entrada de hasta 512 hilos de usuario en el sistema de transacciones.
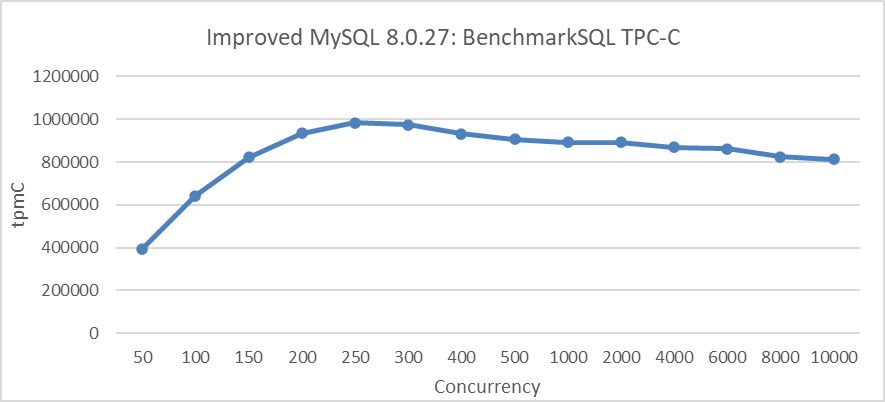
Figura 8: Máxima throughput TPC-C en BenchmarkSQL con mecanismos de limitación de transacciones
A partir de la figura, resulta evidente que la implementación de los mecanismos de limitación de transacciones mejora significativamente la escalabilidad de MySQL.
Resumen
En general, es perfectamente viable que MySQL mantenga un rendimiento estable sin colapso en decenas de miles de conexiones concurrentes en escenarios de bajo conflicto de pruebas TPC-C de BenchmarkSQL.
Referencias
- Bin Wang (2024). El arte de resolver problemas en ingeniería de software: Cómo hacer mejorar a MySQL.
- El Nuevo Nivel de Señalización de MySQL
- Paweł Olchawa. 2018. MySQL 8.0: Nuevo diseño escalable sin bloqueos en WAL. Archivo del Blog de MySQL.
- Xiangyao Yu. Una evaluación del control de concurrencia con mil núcleos. Tesis de doctorado, Instituto Tecnológico de Massachusetts, 2015.
- Manual de Referencia de MySQL 8.0
Source:
https://dzone.com/articles/mysql-scalability-improvement-for-benchmarksql