













Los usuarios tienden a notar una disminución en el rendimiento de baja concurrencia con mayor facilidad, mientras que las mejoras en el rendimiento de alta concurrencia son a menudo más difíciles de percibir. Por lo tanto, mantener un rendimiento de baja concurrencia es crucial, ya que afecta directamente la experiencia del usuario y la disposición a actualizar [1].
Según una amplia retroalimentación de los usuarios, después de actualizar a MySQL 8.0, los usuarios han percibido generalmente una disminución en el rendimiento, particularmente en operaciones de inserción por lotes y uniones. Esta tendencia a la baja se ha vuelto más evidente en versiones superiores de MySQL. Además, algunos entusiastas y evaluadores de MySQL han informado sobre una degradación del rendimiento en múltiples pruebas de sysbench después de la actualización.
¿Pueden evitarse estos problemas de rendimiento? O, más específicamente, ¿cómo deberíamos evaluar científicamente la tendencia continua de disminución del rendimiento? Estas son preguntas importantes a considerar.
Aunque el equipo oficial continúa optimizando, la deterioración gradual del rendimiento no puede ser pasada por alto. En ciertos escenarios, puede parecer que hay mejoras, pero esto no significa que el rendimiento en todos los escenarios esté igualmente optimizado. Además, también es fácil optimizar el rendimiento para escenarios específicos a costa de degradar el rendimiento en otras áreas.
Las Causas Raíz de la Disminución del Rendimiento de MySQL
En general, a medida que se añaden más características, la base de código crece, y con la expansión continua de la funcionalidad, el rendimiento se vuelve cada vez más difícil de controlar.
Los desarrolladores de MySQL a menudo no notan la disminución en el rendimiento, ya que cada adición al código solo resulta en una pequeña disminución en el rendimiento. Sin embargo, con el tiempo, estas pequeñas disminuciones se acumulan, lo que lleva a un efecto acumulativo significativo, causando que los usuarios perciban una degradación notable en el rendimiento en las nuevas versiones de MySQL.
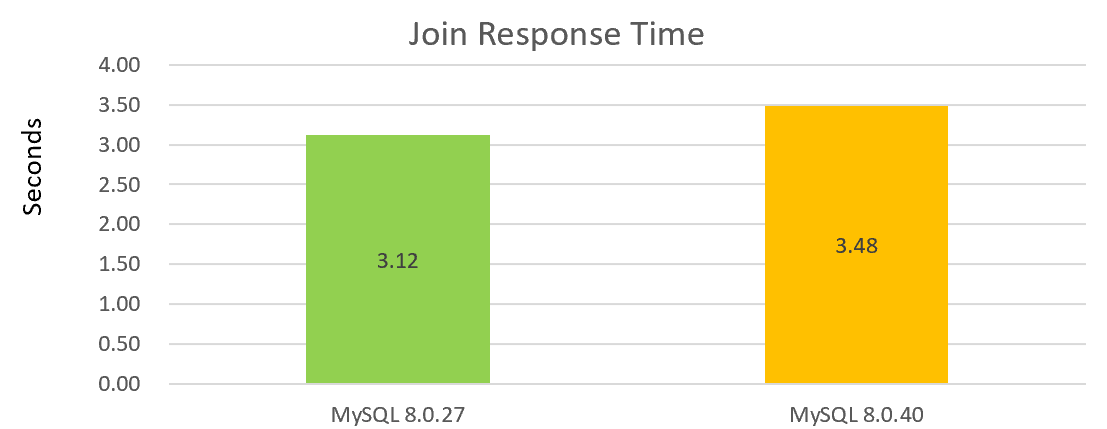
Por ejemplo, la siguiente figura muestra el rendimiento de una simple operación de unión, con MySQL 8.0.40 mostrando una disminución en el rendimiento en comparación con MySQL 8.0.27:
La siguiente figura muestra la prueba de rendimiento de inserción por lotes bajo una concurrencia única, con la disminución de rendimiento de MySQL 8.0.40 en comparación con la versión 5.7.44:
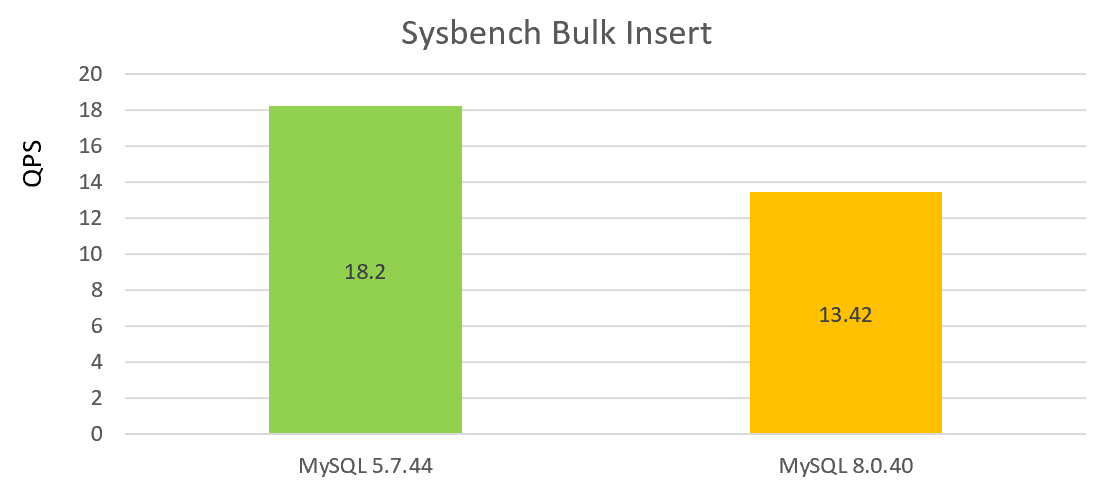
De las dos gráficas anteriores, se puede ver que el rendimiento de la versión 8.0.40 no es bueno.
A continuación, analicemos la causa raíz de la degradación del rendimiento en MySQL desde el nivel del código. A continuación se muestra la función PT_insert_values_list::contextualize en MySQL 8.0:
La función correspondiente PT_insert_values_list::contextualize en MySQL 5.7 es la siguiente:
De la comparación de código, MySQL 8.0 parece tener un código más elegante, aparentemente progresando.
Desafortunadamente, muchas veces, son precisamente las motivaciones detrás de estas mejoras de código las que llevan a la degradación del rendimiento. El equipo oficial de MySQL reemplazó la estructura de datos List anterior con un deque, que se ha convertido en una de las causas fundamentales de la degradación gradual del rendimiento. Echemos un vistazo a la documentación de deque:
std::deque (double-ended queue) is an indexed sequence container that allows fast insertion and deletion at both its
beginning and its end. In addition, insertion and deletion at either end of a deque never invalidates pointers or
references to the rest of the elements.
As opposed to std::vector, the elements of a deque are not stored contiguously: typical implementations use a sequence
of individually allocated fixed-size arrays, with additional bookkeeping, which means indexed access to deque must
perform two pointer dereferences, compared to vector's indexed access which performs only one.
The storage of a deque is automatically expanded and contracted as needed. Expansion of a deque is cheaper than the
expansion of a std::vector because it does not involve copying of the existing elements to a new memory location. On
the other hand, deques typically have large minimal memory cost; a deque holding just one element has to allocate its
full internal array (e.g. 8 times the object size on 64-bit libstdc++; 16 times the object size or 4096 bytes,
whichever is larger, on 64-bit libc++).
The complexity (efficiency) of common operations on deques is as follows:
Random access - constant O(1).
Insertion or removal of elements at the end or beginning - constant O(1).
Insertion or removal of elements - linear O(n).
Como se muestra en la descripción anterior, en casos extremos, retener un solo elemento requiere asignar la matriz completa, lo que resulta en una eficiencia de memoria muy baja. Por ejemplo, en inserciones masivas, donde se necesita insertar un gran número de registros, la implementación oficial almacena cada registro en un deque separado. Incluso si el contenido del registro es mínimo, todavía se debe asignar un deque. La implementación de deque de MySQL asigna 1KB de memoria para cada deque para admitir búsquedas rápidas.
The implementation is the same as classic std::deque: Elements are held in blocks of about 1 kB each.
La implementación oficial utiliza 1KB de memoria para almacenar información de índice, y aunque la longitud del registro no sea grande pero hay muchos registros, las direcciones de acceso a memoria pueden volverse no contiguas, lo que lleva a una baja amistosidad con la caché. Este diseño tenía la intención de mejorar la amistosidad con la caché, pero no ha sido completamente efectivo.
Cabe destacar que la implementación original utilizaba una estructura de datos List, donde la memoria se asignaba a través de un grupo de memoria, proporcionando un cierto nivel de amistosidad con la caché. Aunque el acceso aleatorio es menos eficiente, optimizar el acceso secuencial a los elementos de la List mejora significativamente el rendimiento.
Durante la actualización a MySQL 8.0, los usuarios observaron una disminución significativa en el rendimiento de la inserción por lotes, y una de las principales causas fue el cambio sustancial en las estructuras de datos subyacentes.
Además, aunque el equipo oficial mejoró el mecanismo de registro de rehacer, esto también llevó a una disminución en la eficiencia de la operación de confirmación MTR. En comparación con MySQL 5.7, el código añadido reduce significativamente el rendimiento de las confirmaciones individuales, aunque se ha mejorado considerablemente el rendimiento general de escritura.
Examinemos la operación central execute de la confirmación MTR en MySQL 5.7.44:
Veamos la operación principal execute del commit MTR en MySQL 8.0.40:
En comparación, es claro que en MySQL 8.0.40, la operación execute en el commit MTR se ha vuelto mucho más compleja, con más pasos involucrados. Esta complejidad es una de las principales causas de la disminución en el rendimiento de escritura de baja concurrencia.
En particular, las operaciones m_impl->m_log.for_each_block(write_log) y log_wait_for_space_in_log_recent_closed(*log_sys, handle.start_lsn) tienen una sobrecarga significativa. Estos cambios se hicieron para mejorar el rendimiento de alta concurrencia, pero vinieron a costa del rendimiento de baja concurrencia.
La priorización del modo de alta concurrencia del registro de rehacer resulta en un rendimiento pobre para cargas de trabajo de baja concurrencia. Aunque la introducción de innodb_log_writer_threads se pretendía mitigar los problemas de rendimiento de baja concurrencia, no afecta la ejecución de las funciones mencionadas anteriormente. Dado que estas operaciones se han vuelto más complejas y requieren commits de MTR frecuentes, el rendimiento ha disminuido significativamente.
Veamos el impacto de la característica de agregar/eliminar instantáneamente en el rendimiento. A continuación se muestra la función rec_init_offsets_comp_ordinary en MySQL 5.7:
La función rec_init_offsets_comp_ordinary en MySQL 8.0.40 es la siguiente:
A partir del código anterior, queda claro que con la introducción de la función de agregar/eliminar columnas de forma instantánea, la función rec_init_offsets_comp_ordinary se ha vuelto notablemente más compleja, introduciendo más llamadas a funciones y añadiendo una declaración switch que afecta gravemente a la optimización de caché. Dado que esta función se llama con frecuencia, impacta directamente en el rendimiento del índice de actualización, las inserciones por lotes y las uniones, resultando en una gran caída del rendimiento.
Además, la disminución del rendimiento en MySQL 8.0 no se limita a lo anterior; hay muchas otras áreas que contribuyen a la degradación general del rendimiento, especialmente el impacto en la expansión de funciones en línea. Por ejemplo, el siguiente código afecta la expansión de funciones en línea:
Según nuestras pruebas, la declaración ib::fatal interfiere gravemente con la optimización en línea. Para funciones a las que se accede con frecuencia, es aconsejable evitar declaraciones que interfieran con la optimización en línea.
A continuación, veamos un problema similar. La función row_sel_store_mysql_field se llama con frecuencia, siendo row_sel_field_store_in_mysql_format una función de punto caliente dentro de ella. El código específico es el siguiente:
La función row_sel_field_store_in_mysql_format finalmente llama a row_sel_field_store_in_mysql_format_func.
La función row_sel_field_store_in_mysql_format_func no se puede insertar en línea debido a la presencia del código ib::fatal.
Funciones ineficientes llamadas con frecuencia, que se ejecutan decenas de millones de veces por segundo, pueden afectar gravemente el rendimiento de las uniones.
Continuemos explorando las razones de la disminución del rendimiento. La siguiente optimización oficial del rendimiento es, de hecho, una de las causas fundamentales de la disminución en el rendimiento de las operaciones de unión. Aunque ciertas consultas pueden mejorarse, siguen siendo algunas de las razones de la degradación del rendimiento de las operaciones de unión ordinarias.
Los problemas de MySQL van más allá de esto. Como se muestra en los análisis anteriores, la disminución del rendimiento en MySQL no ocurre sin motivo. Una serie de problemas pequeños, cuando se acumulan, pueden llevar a una degradación del rendimiento notable que experimentan los usuarios. Sin embargo, estos problemas a menudo son difíciles de identificar, lo que los hace aún más difíciles de resolver.
La llamada ‘optimización prematura’ es la raíz de todo mal, y no se aplica en el desarrollo de MySQL. El desarrollo de bases de datos es un proceso complejo, y descuidar el rendimiento con el tiempo hace que las mejoras posteriores en el rendimiento sean significativamente más desafiantes.
Soluciones para mitigar la disminución del rendimiento de MySQL
Las principales razones de la disminución del rendimiento de escritura están relacionadas con problemas de confirmación MTR, adición/desestimación instantánea de columnas y varios otros factores. Estos son difíciles de optimizar de formas tradicionales. Sin embargo, los usuarios pueden compensar la caída del rendimiento a través de optimización PGO. Con una estrategia adecuada, el rendimiento generalmente puede mantenerse estable.
Para la degradación del rendimiento en inserciones en batch, nuestra versión de código abierto [2] reemplaza la deque oficial con una implementación de lista mejorada. Esto aborda principalmente problemas de eficiencia de memoria y puede aliviar parcialmente la disminución del rendimiento. Al combinar la optimización PGO con nuestra versión de código abierto, el rendimiento de inserciones en batch puede acercarse al de MySQL 5.7.

Los usuarios también pueden aprovechar múltiples hilos para el procesamiento concurrente en batch, utilizando completamente la mejorada concurrencia del registro de redo, lo que puede aumentar significativamente el rendimiento de inserciones en batch.
En cuanto a los problemas de actualización de índices, debido a la inevitable adición de nuevo código, la optimización PGO puede ayudar a mitigar este problema. Nuestra versión PGO [2] puede aliviar significativamente este problema.
Para el rendimiento de lectura, especialmente el rendimiento de joins, hemos realizado mejoras sustanciales, incluyendo la corrección de problemas en línea y otras optimizaciones. Con la adición de PGO, el rendimiento de joins puede incrementarse en más del 30% en comparación con la versión oficial.
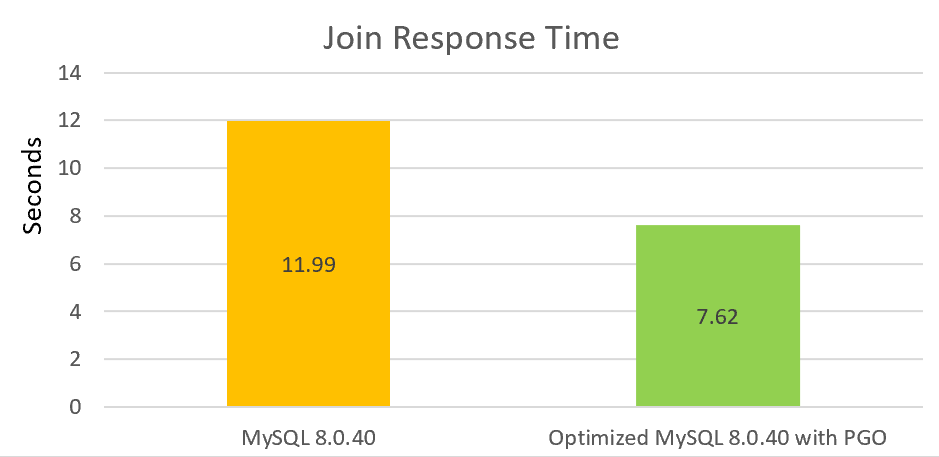
Continuaremos invirtiendo tiempo en optimizar el rendimiento de baja concurrencia. Este proceso es largo pero abarca numerosas áreas que necesitan mejora.
La versión de código abierto está disponible para pruebas, y los esfuerzos persistirán para mejorar el rendimiento de MySQL.
Referencias
[1] Bin Wang (2024). El Arte de Resolver Problemas en Ingeniería de Software: Cómo Mejorar MySQL.
Source:
https://dzone.com/articles/mysql-80-performance-degradation-analysis