













Caso Clásico 1
Muchos profesionales del software carecen de un conocimiento profundo del razonamiento lógico de TCP/IP, lo que a menudo lleva a identificar erróneamente problemas como problemas misteriosos. Algunos se desaniman por la complejidad de la literatura de redes TCP/IP, mientras que otros son engañados por detalles confusos en Wireshark. Por ejemplo, un DBA que enfrenta problemas de rendimiento podría interpretar erróneamente los datos de captura de paquetes en Wireshark, concluyendo erróneamente que las retransmisiones TCP son la causa.

Dado que se sospecha una retransmisión, es esencial comprender su naturaleza. La retransmisión implica fundamentalmente una retransmisión por timeout. Para confirmar si la retransmisión es de hecho la causa, se necesita información relacionada con el tiempo, la cual no se proporciona en la captura de pantalla anterior. Después de solicitar una nueva captura de pantalla al DBA, se incluyó la información de marca de tiempo.

Al analizar paquetes de red, la información de marca de tiempo es crucial para un razonamiento lógico preciso. Una diferencia de tiempo en el rango de microsegundos entre dos paquetes duplicados sugiere ya sea una retransmisión por timeout o una captura de paquete duplicado. En un entorno LAN típico con un Tiempo de ida y vuelta (RTT) de alrededor de 100 microsegundos, donde las retransmisiones TCP requieren al menos un RTT, una retransmisión que ocurra en solo 1/100 del RTT probablemente indique una captura de paquete duplicado en lugar de una retransmisión real por timeout.
Caso Clásico 2
Otro caso clásico ilustra la importancia del razonamiento lógico en el análisis de problemas de red.
Un día, un desarrollador de negocios llegó corriendo, diciendo que un script programado que utilizaba el middleware de base de datos MySQL había fallado en las primeras horas de la mañana sin respuesta. Al escuchar sobre el problema, revisé los registros de errores del middleware de la base de datos MySQL, pero no encontré pistas valiosas. Así que pregunté a los desarrolladores si podían reproducir el problema, sabiendo que una vez que algo es reproducible, se vuelve más fácil de resolver.
Los desarrolladores intentaron múltiples veces reproducir el problema, pero no tuvieron éxito. Sin embargo, hicieron un nuevo descubrimiento: encontraron que ejecutar las mismas consultas SQL durante el día resultaba en tiempos de respuesta diferentes en comparación con las primeras horas de la mañana. Sospecharon que cuando la respuesta SQL era lenta, el middleware de la base de datos MySQL estaba bloqueando la sesión y no devolviendo resultados al cliente.
Con base en esta información, se pidió al equipo de operaciones de la base de datos que modificara el SQL del script para simular una respuesta SQL lenta. Como resultado, el middleware de la base de datos MySQL devolvió los resultados sin encontrar el problema de bloqueo que se observó en las primeras horas de la mañana.
Durante un tiempo, no se pudo identificar la causa raíz, y los desarrolladores descubrieron un problema funcional con el middleware de la base de datos MySQL. Por lo tanto, los desarrolladores y las operaciones de DBA se convencieron más de que el middleware de la base de datos MySQL estaba retrasando las respuestas. En realidad, estos problemas no estaban relacionados con los tiempos de respuesta del middleware de la base de datos MySQL.
A partir de los eventos del primer día, el problema efectivamente ocurrió. Todos los involucrados intentaron identificar la causa, haciendo varias conjeturas, pero la verdadera razón seguía siendo esquiva.
Al día siguiente, los desarrolladores informaron que el problema del script volvió a ocurrir por la mañana temprano, pero no pudieron reproducirlo durante el día. Los desarrolladores, sintiéndose presionados ya que el script pronto se utilizaría en línea, se quejaron de la situación. Mi única sugerencia fue que utilizaran el script durante el día para evitar problemas por la mañana temprano. Con todas las sospechas centradas en el middleware de la base de datos MySQL, fue difícil analizar el problema desde otras perspectivas.
Como desarrollador responsable del middleware de la base de datos MySQL, no se pueden pasar por alto fácilmente problemas tan misteriosos. Ignorarlos podría afectar el uso posterior del middleware de la base de datos MySQL, y también hay presión por parte de la dirección para resolver el problema rápidamente. Finalmente, se decidió implementar una solución de análisis de captura de paquetes de bajo costo: durante la ejecución del script por la mañana temprano, se realizarían capturas de paquetes en el servidor para analizar lo que estaba sucediendo en ese momento. El objetivo era determinar si el middleware de la base de datos MySQL no lograba enviar una respuesta en absoluto o si enviaba una respuesta que el script del cliente no recibía. Una vez que se pudiera confirmar que el middleware de la base de datos MySQL enviaba una respuesta, el problema no se atribuiría a los desarrolladores del middleware de la base de datos MySQL.
En el tercer día, los desarrolladores informaron que el problema de la madrugada no se repitió, y el análisis de captura de paquetes confirmó que el problema no ocurrió. Tras una cuidadosa consideración, parecía poco probable que el problema estuviera únicamente en el middleware de la base de datos MySQL: las ocurrencias frecuentes en la madrugada y las raras durante el día eran desconcertantes. La única opción era esperar a que el problema ocurriera nuevamente y analizarlo en base a las capturas de paquetes.
En el cuarto día, el problema no volvió a aparecer.
Sin embargo, en el quinto día, el problema finalmente reapareció, trayendo esperanza de resolución.
Los archivos de captura de paquetes son numerosos. Primero, pida a los desarrolladores que proporcionen la marca de tiempo cuando ocurrió el problema, luego busque entre los extensos datos de captura de paquetes para identificar la consulta SQL que causó el problema. El resultado final es el siguiente:
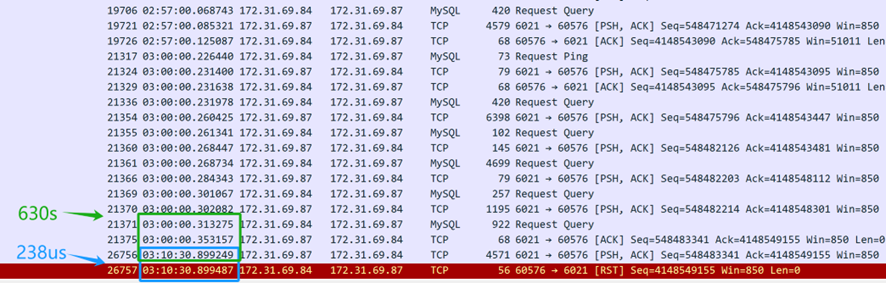
A partir del contenido de la captura de paquetes anterior (capturado desde el servidor), parece que la consulta SQL fue enviada a las 3 AM. El middleware de la base de datos MySQL tardó 630 segundos (03:10:30.899249-03:00:00.353157) en devolver la respuesta SQL al cliente, lo que indica que el middleware de la base de datos MySQL efectivamente respondió a la consulta SQL. Sin embargo, solo 238 microsegundos después (03:10:30.899487-03:10:30.899249), la capa TCP del servidor recibió un paquete de reinicio, lo cual fue sospechosamente rápido. Es importante destacar que este paquete de reinicio no puede asumirse de inmediato que provenga del cliente.
En primer lugar, es necesario confirmar quién envió el paquete de reinicio: si fue enviado por el cliente o por un dispositivo intermedio en el camino. Dado que la captura de paquetes se realizó solo en el lado del servidor, no se dispone de información sobre la situación del paquete del cliente. Al analizar los archivos de captura de paquetes desde el lado del servidor y aplicar razonamiento lógico, el objetivo es identificar la causa raíz del problema.
Si se asume que el cliente envió un reinicio, implicaría que la capa TCP del cliente ya no reconoce el estado TCP de esta conexión, pasando de un estado establecido a uno inexistente. Este cambio en el estado TCP notificaría a la aplicación del cliente sobre un problema de conexión, haciendo que el script del cliente falle inmediatamente. Sin embargo, en realidad, el script del cliente aún está esperando que llegue la respuesta. Por lo tanto, la suposición de que el cliente envió un reinicio no es válida: el cliente no envió un reinicio. La conexión del cliente sigue activa, pero del lado del servidor, la conexión correspondiente ha sido terminada por el reinicio.
¿Quién envió el reinicio, entonces? El principal sospechoso es el entorno de nube de Amazon. Basado en este análisis de captura de paquetes, las operaciones de DBA consultaron al servicio al cliente de Amazon y recibieron la siguiente información:
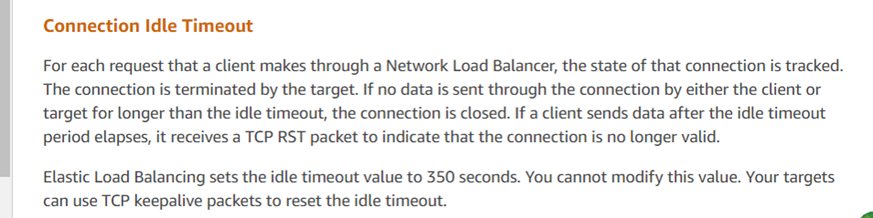
La respuesta del servicio al cliente coincide con los resultados del análisis, indicando que el ELB de Amazon (Balanceador de Carga Elástico, similar a LVS) terminó la sesión TCP de manera forzada. Según sus comentarios, si una respuesta excede el umbral de 350 segundos (como se observó en la captura de paquetes en 630 segundos), el dispositivo ELB de Amazon envía un reset a la parte que responde (en este caso, el servidor). Los scripts de cliente desplegados por los desarrolladores no recibieron el reset y asumieron erróneamente que la conexión con el servidor seguía activa. Las recomendaciones oficiales para problemas de este tipo incluyen el uso de mecanismos de mantenimiento de conexión TCP para mitigar estos problemas.
Con la respuesta oficial obtenida, se consideró que el problema estaba completamente resuelto.
Este caso específico ilustra cómo los problemas en línea pueden ser altamente complejos, requiriendo la captura de información crítica — en este caso, datos de captura de paquetes — para entender la situación tal como ocurrió. A través del razonamiento lógico y la aplicación de la reducción al absurdo, se identificó la causa raíz.
Source:
https://dzone.com/articles/logical-reasoning-in-network-problems