













Aprender Linux es una de las habilidades más valiosas en la industria tecnológica. Puede ayudarle a hacer las cosas más rápido y eficientemente. Muchos de los servidores y supercomputadores más poderosos del mundo funcionan con Linux.
Mientras que le brinda poder en su papel actual, aprender Linux también le puede ayudar a transitionar a otras carreras tecnológicas como DevOps, Ciberseguridad y Computación en la Nube.
En este manual, aprenderá los conceptos básicos de la línea de comandos de Linux, y luego pasará a temas avanzados como scripting de shell y administración del sistema. Tanto si es nuevo en Linux como si lo ha estado usando durante años, este libro tiene algo para usted.
Nota importante: todos los ejemplos en este libro se demostraron en Ubuntu 22.04.2 LTS (Jammy Jellyfish). La mayoría de las herramientas de línea de comandos son más o menos las mismas en otras distribuciones. Sin embargo, algunas aplicaciones de GUI y comandos pueden ser diferentes si está trabajando en otra distribución de Linux.
Tabla de contenidos
-
Parte 2: Introducción a la Shell Bash y las Órdenes del Sistema
-
Parte 5: Los conceptos básicos de la edición de texto en Linux
Parte 1: Introducción a Linux
1.1. Empezar con Linux
¿Qué es Linux?
Linux es un sistema operativo de código abierto basado en el sistema operativo Unix. Fue creado por Linus Torvalds en 1991.
La definición de software libre o de código abierto significa que el código fuente del sistema operativo está disponible para el público. Esto permite que cualquier persona modifique el código original, lo personalice y distribuya el nuevo sistema operativo a los usuarios potenciales.
¿Por qué deberías aprender sobre Linux?
En el paisaje actual de los centros de datos, Linux y Microsoft Windows se destacan como los principales contendientes, con Linux teniendo una gran parte de mercado.
Hay varias razones convincentes para aprender Linux:
-
Dada la prevalencia de los servidores hospedados en Linux, hay una gran probabilidad de que su aplicación se hospedará en Linux. Así que aprender Linux como desarrollador se hace cada vez más valioso.
-
Con la computación en la nube que se está haciendo la norma, las probabilidades son altas que sus instancias en la nube se basen en Linux.
-
Linux sirve de base para muchos sistemas operativos de la Internet de las cosas (IoT) y aplicaciones móviles.
-
En TI, hay muchas oportunidades para aquellos que están capacitados en Linux.
¿Qué significa que Linux es un sistema operativo de código abierto?
Primero, ¿qué es software de código abierto? Software de código abierto es software cuyo código fuente está libremente accesible, permitiendo a cualquier persona utilizarlo, modificarlo y distribuirlo.
Cada vez que se crea un código fuente, automáticamente se considera protegido por derechos de autor, y su distribución está gobernada por el titular de los derechos de autor a través de licencias de software.
En contraste con el software de código abierto, el software propietario o cerrado restringe el acceso a su código fuente. Sólo los creadores pueden ver, modificar o distribuirlo.
Linux es principalmente de código abierto, lo que significa que su código fuente está libremente disponible. Cualquiera puede ver, modificar y distribuirlo. Los desarrolladores de todo el mundo pueden contribuir a su mejora. Esto pone las bases de la colaboración, que es un aspecto importante del software de código abierto.
Este enfoque colaborativo ha llevado a la adopción generalizada de Linux en servidores, computadoras de escritorio, sistemas embebidos y dispositivos móviles.
El aspecto más interesante de que Linux sea de código abierto es que cualquiera puede personalizar el sistema operativo a sus necesidades específicas sin ser limitado por restricciones propias.
Chrome OS, utilizado por los Chromebooks, se basa en Linux. Android, que impulsa muchos smartphones en todo el mundo, también se basa en Linux.
¿Qué es un Núcleo de Linux?
El núcleo es el componente central de un sistema operativo que gestiona las operaciones de la computadora y su hardware. administra las operaciones de memoria y el tiempo de CPU.
El núcleo actúa como un puente entre las aplicaciones y las operaciones de procesamiento de datos a nivel hardware, utilizando la comunicación entre procesos y llamadas al sistema.
El kernel se carga en la memoria primero cuando se inicia un sistema operativo y permanece allí hasta que el sistema se apaga. Es responsable de tareas como la gestión de discos, la gestión de tareas y la gestión de memoria.
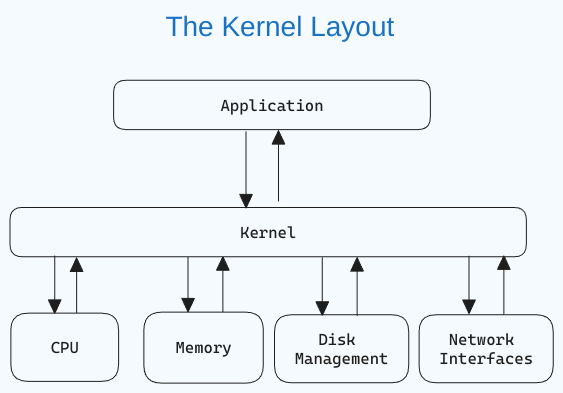
Si tiene curiosidad sobre cómo se parece el núcleo de Linux, aquí tienes el enlace de GitHub.
¿Qué es una distribución de Linux?
En este punto, sabes que puedes reutilizar el código del núcleo de Linux, modificarlo y crear un nuevo núcleo. Puedes combinar además diferentes utilidades y software para crear un sistema operativo completamente nuevo.
Una distribución de Linux o distro es una versión del sistema operativo Linux que incluye el núcleo de Linux, utilidades del sistema y otro software. Siendo de código abierto, una distribución de Linux es un esfuerzo colaborativo que involucra a múltiples comunidades de desarrollo de código abierto independientes.
¿Qué significa que una distribución se deriva de otra? Cuando dices que una distribución “se deriva” de otra, la distribución más nueva se construye sobre la base o el fundamento de la distribución original. Esta derivación puede incluir el uso del mismo sistema de gestión de paquetes (más sobre esto más adelante), la misma versión del núcleo y, a veces, las mismas herramientas de configuración.
Hoy en día, hay miles de distribuciones de Linux entre las que elegir, ofreciendo diferentes objetivos y criterios para seleccionar y apoyar el software proporcionado por su distribución.
Las distribuciones varían una de otra, pero generalmente tienen varias características comunes:
-
Una distribución consiste en un núcleo de Linux.
-
Ella admite programas de espacio de usuario.
-
Una distribución puede ser pequeña y de propósito único o incluir miles de programas de código abierto.
-
Debe proporcionarse algún medio para instalar y actualizar la distribución y sus componentes.
Si usted ve la Linea de Tiempo de las Distribuciones de Linux, verá dos distribuciones mayores: Slackware y Debian. varias distribuciones se derivan de ellas. Por ejemplo, Ubuntu y Kali se derivan de Debian.
¿Cuales son las ventajas de la derivación? Hay varias ventajas de la derivación. Las distribuciones derivadas pueden aprovechar la estabilidad, seguridad y los grandes repositorios de software de la distribución padre.
Cuando se construye sobre una base existente, los desarrolladores pueden enfocar y dedicar toda su atención y esfuerzo a las características especializadas de la nueva distribución. Los usuarios de las distribuciones derivadas pueden beneficiarse de la documentación, soporte de comunidad y recursos ya disponibles para la distribución padre.
Algunas distribuciones de Linux populares son:
-
Ubuntu: Una de las distribuciones de Linux más ampliamente utilizadas y populares. Es amigable con el usuario y recomendada para principiantes. Más información sobre Ubuntu aquí.
-
Linux Mint: Basada en Ubuntu, Linux Mint ofrece una experiencia amigable con el usuario con un enfoque en la multimedia. Más información sobre Linux Mint aquí.
-
Arch Linux: Populare entre usuarios experimentados, Arch es una distribución ligera y flexible dirigida a usuarios que prefieren un enfoque de DIY. Más información sobre Arch Linux aquí.
-
Manjaro: Basado en Arch Linux, Manjaro ofrece una experiencia amigable con software preinstalado y herramientas de gestión del sistema fáciles de usar. Más información sobre Manjaro aquí.
-
Kali Linux: Kali Linux ofrece una suite completa de herramientas de seguridad y se centra principalmente en ciberseguridad y hackeo. Más información sobre Kali Linux aquí.
Cómo instalar y acceder a Linux
La mejor manera de aprender es aplicando los conceptos mientras avanzas. En esta sección, aprenderás cómo instalar Linux en tu máquina para que puedas seguir con nosotros. También aprenderás cómo acceder a Linux en una máquina con Windows.
Recomiendo que sigas cualquiera de los métodos mencionados en esta sección para tener acceso a Linux y poder seguir con nosotros.
Instalar Linux como SO principal
Instalar Linux como SO principal es la manera más eficiente de usar Linux, ya que puedes utilizar toda la potencia de tu máquina.
En esta sección, aprenderá cómo instalar Ubuntu, que es una de las distribuciones de Linux más populares. Dejo fuera otras distribuciones por ahora, ya que quiero mantener las cosas simples. Siempre puede explorar otras distribuciones una vez que esté cómodo con Ubuntu.
-
Paso 1 – Descargar el iso de Ubuntu: Vaya al sitio web oficial web y descargue el archivo iso. Asegúrese de seleccionar una versión estable que esté etiquetada como “LTS”. LTS significa Soporte de largo plazo, lo que significa que puede obtener actualizaciones de seguridad y mantenimiento gratuitas por un largo tiempo (normalmente 5 años).
-
Paso 2 – Crear un pendrive bootable: Existen varias herramientas que pueden crear un pendrive bootable. Recomiendo utilizar Rufus, ya que es bastante fácil de usar. Puede descargarlo de aquí.
-
Paso 3 – Arrancar desde el pendrive: Una vez que su pendrive arrancable esté listo, insertuelo y arrancue desde el pendrive. El menú de arranque depende de su portátil. Puede buscar el menú de arranque para su modelo de portátil en Google.
-
Paso 4 – Siga con las instrucciones. Una vez que comience el proceso de arranque, seleccione
prueba o instala Ubuntu.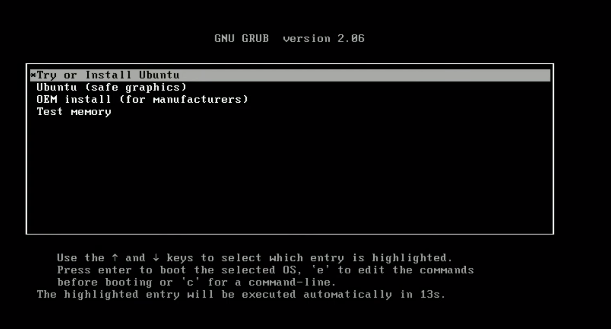
El proceso tardará un tiempo. Una vez que aparezca la interfaz gráfica, puede seleccionar el idioma y el layout del teclado y continuar. Ingresar su nombre de usuario y su nombre. Recuerde las credenciales, ya que necesitarálas para iniciar sesión en su sistema y tener acceso a los privilegios completos. Esperar a que finalice la instalación.
-
Paso 5 – Reiniciar: Haga clic en reiniciar ahora y elimine el pendrive.
- Paso 6 – Iniciar sesión: Inicie sesión con las credenciales que ingresó anteriormente.
¡Y listo! Ahora puede instalar aplicaciones y personalizar su escritorio.

Para una instalación avanzada, puede explorar los siguientes temas:
-
Particionamiento de disco.
-
Configuración de memoria de intercambio para habilitar la hibernación.
Acceder al terminal
Una parte importante de este manual es aprender acerca del terminal donde ejecutará todas las órdenes y verá la magia suceder. Puede buscar el terminal presionando la tecla “windows” y escribiendo “terminal”. Puede anclar el Terminal en el dock donde se encuentran otras aplicaciones para tener un acceso fácil.
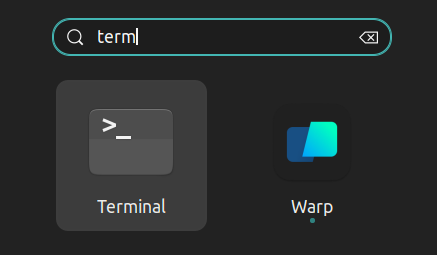
💡 La tecla de acceso directo para abrir el terminal es
ctrl+alt+t
También puede abrir el terminal desde dentro de una carpeta. Haga clic derecho donde se encuentra y haga clic en “Abrir en Terminal”. Esto abrirá el terminal en la misma ruta.
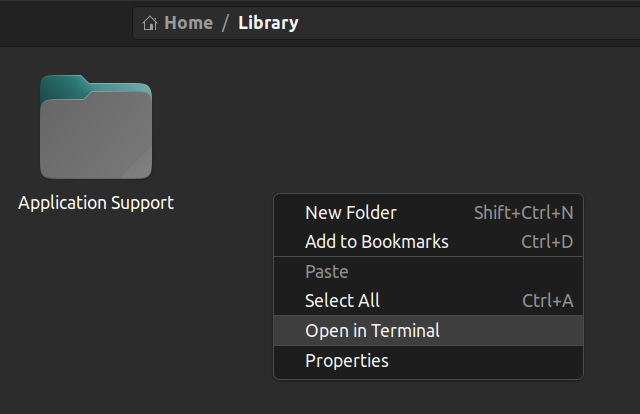
Cómo usar Linux en una máquina de Windows
Algunas veces podría necesitar ejecutar Linux y Windows lado a lado. Por suerte, hay algunas formas de obtener lo mejor de ambos mundos sin obtener diferentes computadoras para cada sistema operativo.
En esta sección, explorará algunas formas de usar Linux en una máquina de Windows. Algunos de ellos son basados en navegador o en la nube y no necesitan ninguna instalación de SO antes de usarlos.
Opción 1: “Arranque doble” Linux + Windows Con el arranque doble, puede instalar Linux junto a Windows en su computadora, lo que le permite elegir qué sistema operativo utilizar al iniciar.
Esto requiere particionar su disco duro y instalar Linux en una partición separada. Con este enfoque, solo puede usar un sistema operativo a la vez.
Opción 2: Utilizar el Sistema Subyacente de Windows para Linux (WSL) El Sistema Subyacente de Windows para Linux proporciona una capa de compatibilidad que permite ejecutar archivos ejecutables de Linux nativamente en Windows.
Utilizar WSL tiene algunas ventajas. La configuración de WSL es simple y no consume mucho tiempo. Es ligero en comparación con las VM en las que tienes que asignar recursos de la máquina anfitriona. No necesita instalar ninguna imagen ISO o disco virtual para las máquinas Linux, que suelen ser archivos pesados. Puede usar Windows y Linux juntos.
Cómo instalar WSL2
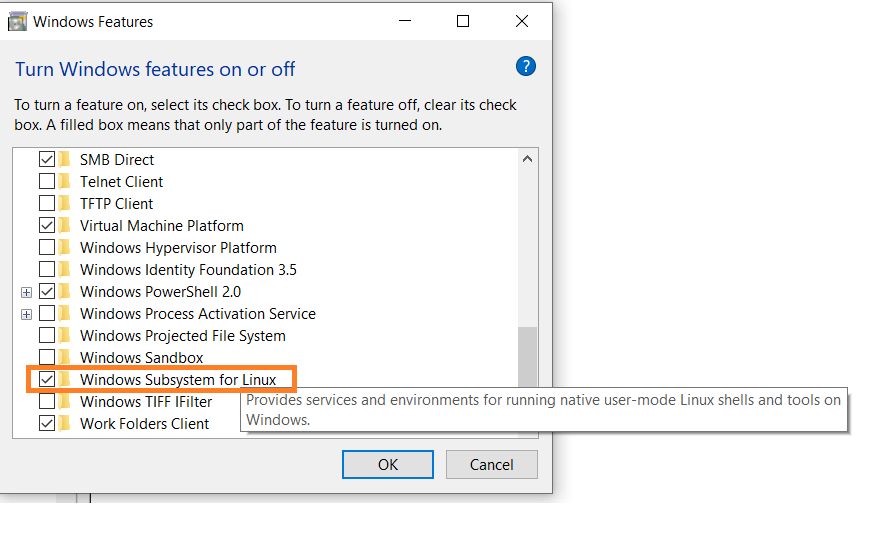
Primero, habilite la opción de Sistema Subyacente de Windows para Linux en las configuraciones.
-
Vaya a Inicio. Busque “Activar o desactivar funciones de Windows.”
-
Marque la opción “Sistema Subyacente de Windows para Linux” si no está marcada ya.
-
A continuación, abra su cuaderno de comandos y proporcione los comandos de instalación.
-
Abrir Terminal de Comandos como administrador:

-
Ejecute el siguiente comando:
wsl --install
Esto es la salida:
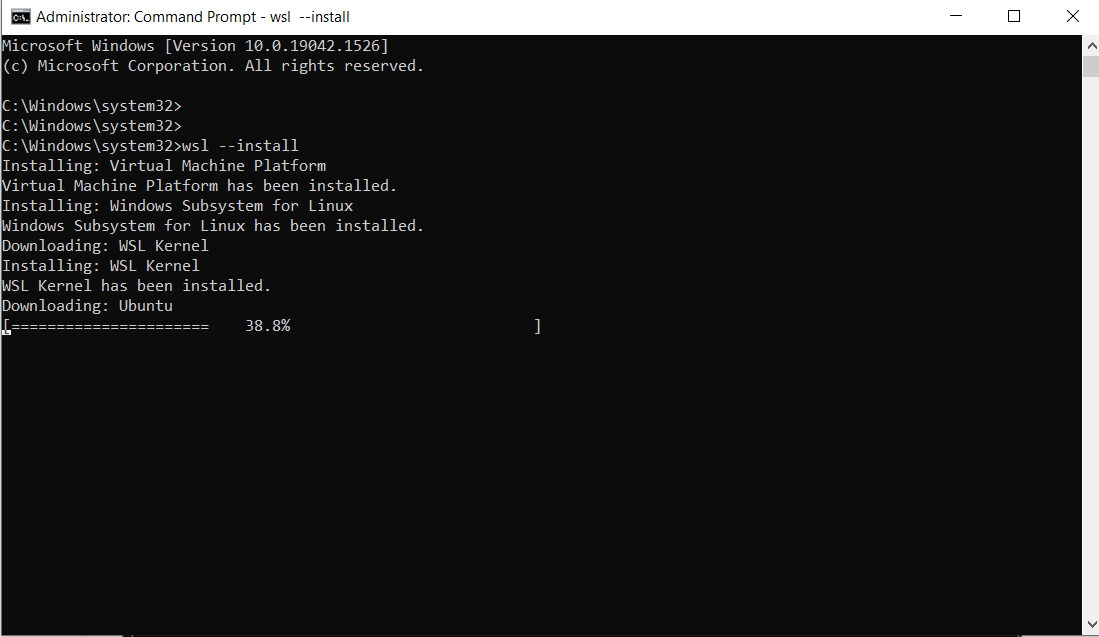
Nota: Por defecto, se instalará Ubuntu.
- Una vez que la instalación haya finalizado, tendrá que reiniciar su equipo Windows. Así que, reinicie su equipo Windows.
Después de reiniciar, podría ver una ventana como esta:
Una vez que la instalación de Ubuntu haya finalizado, se le pedirá que ingrese su nombre de usuario y contraseña.

Y, listo! Está listo para usar Ubuntu.
Inicie Ubuntu buscando en el menú Inicio.
Y aquí tienemos su instancia de Ubuntu iniciada.

Opción 3: Usar una Máquina Virtual (VM)
Una máquina virtual (VM) es una emulación de software de un sistema de computación físico. Permite ejecutar múltiples sistemas operativos y aplicaciones simultáneamente en una sola máquina física.
Puede utilizar software de virtualización como Oracle VirtualBox o VMware para crear una máquina virtual que ejecute Linux en su entorno Windows. Esto le permite ejecutar Linux como un sistema operativo invitado junto con Windows.
El software de VM proporciona opciones para allocar y administrar recursos de hardware para cada VM, incluyendo núcleos de CPU, memoria, espacio en disco y ancho de banda de red. Puedes ajustar estas asignaciones según los requerimientos de los sistemas operativos invitados y aplicaciones.
Aquí están algunas de las opciones comunes disponibles para la virtualización:
Opción 4: Utilizar una Solución Basada en Navegador
Las soluciones basadas en navegador son particularmente útiles para pruebas rápidas, aprendizaje o acceso a entornos Linux desde dispositivos que no tienen Linux instalado.
Puedes utilizar editores de código en línea o terminales web basados en la web para acceder a Linux. Tenga en cuenta que generalmente en estos casos no tienesprivilegios de administración completos.
Editores de código en línea
Los editores de código en línea ofrecen terminales de Linux integrados. Aunque su propósito principal es codificar, también puede utilizar el terminal de Linux para ejecutar comandos y realizar tareas.
Replit es un ejemplo de un editor de código en línea, donde puede escribir su código y acceder a la shell de Linux al mismo tiempo.
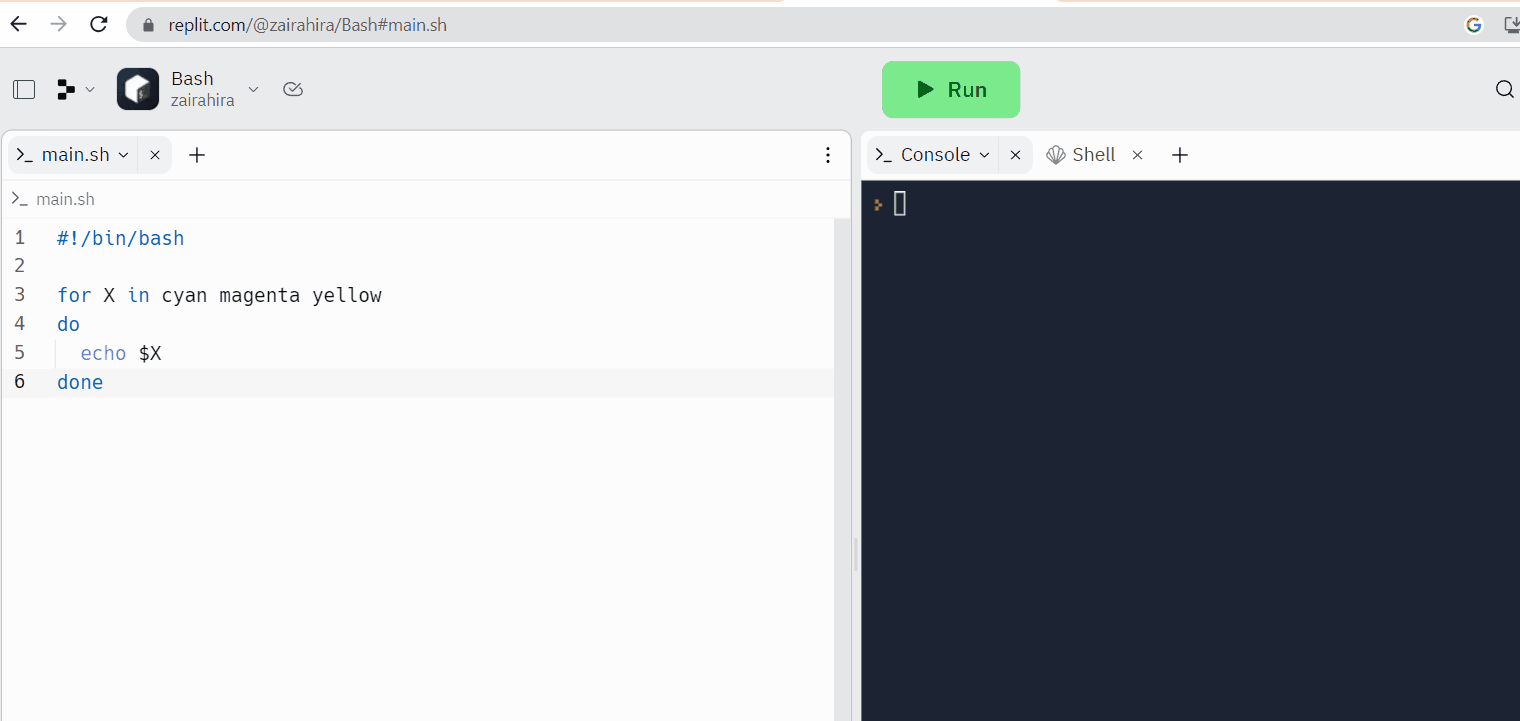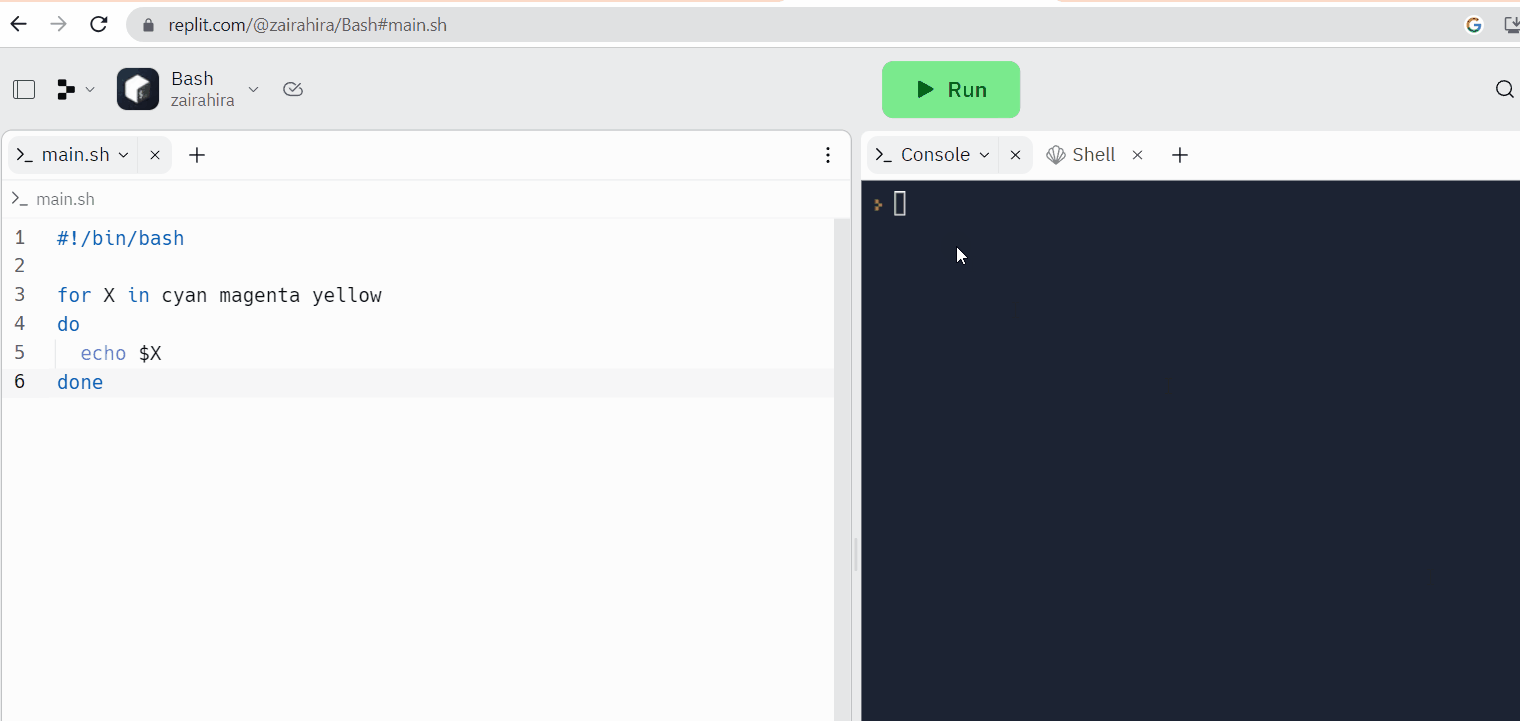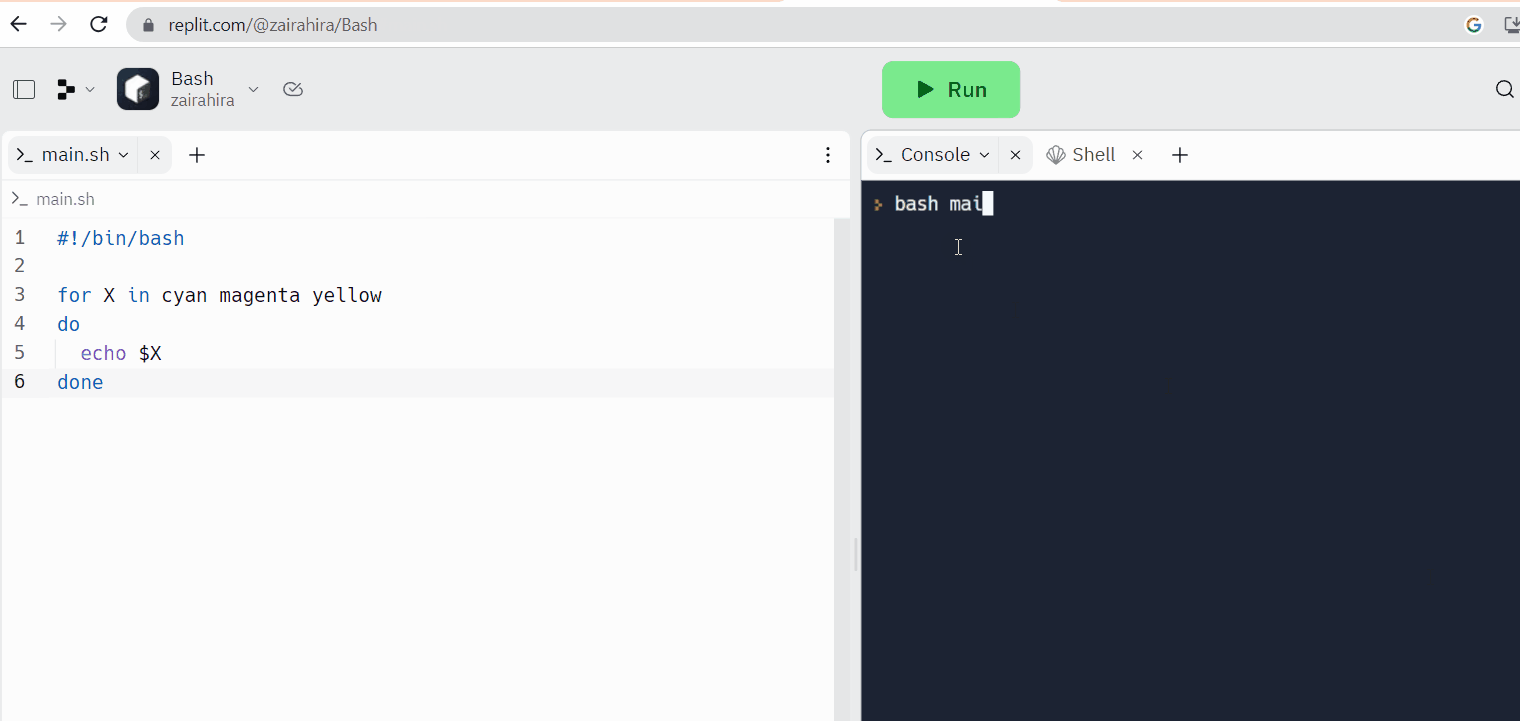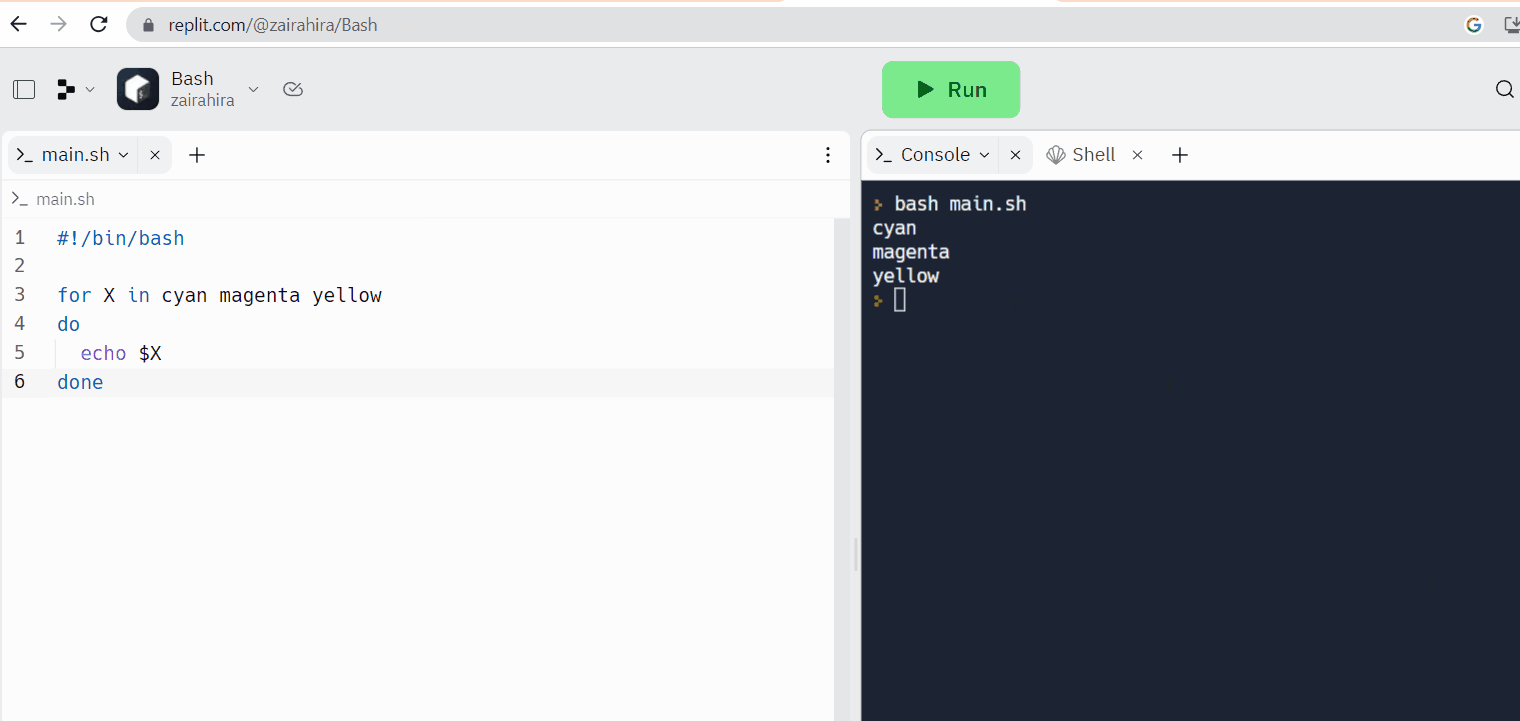
Terminales de Linux en línea:
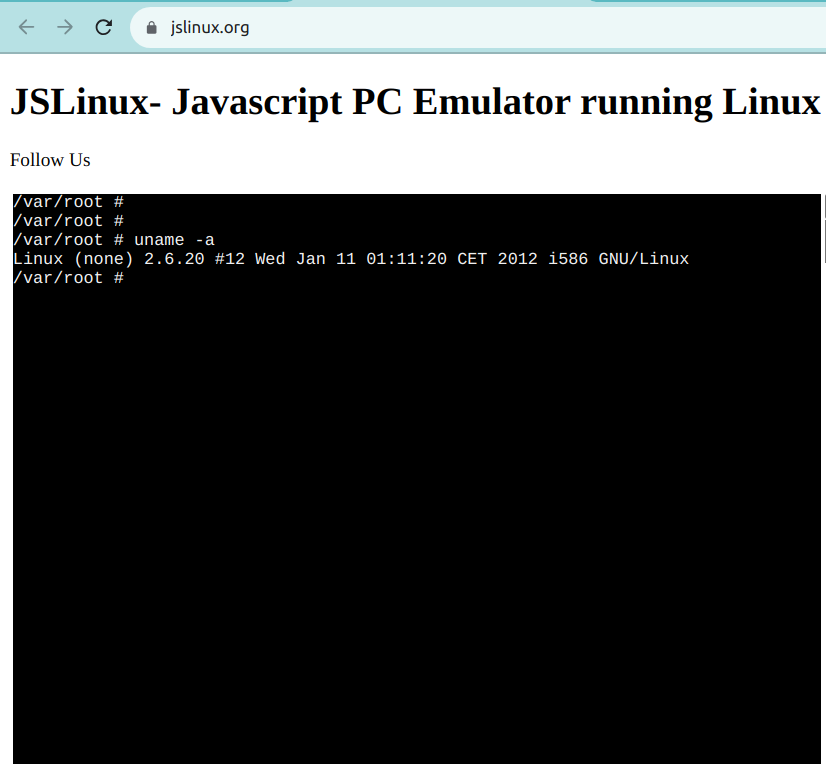
Los terminales de Linux en línea le permiten acceder a una interfaz de línea de comandos de Linux directamente desde su navegador web. Estos terminales proporcionan una interfaz basada en web a una shell de Linux, lo que le permite ejecutar comandos y trabajar con utilidades de Linux.
Un ejemplo de este tipo es JSLinux. La captura de pantalla de abajo muestra un entorno de Linux listo para usar:
Opción 5: Usar una Solución en la Nube
En lugar de ejecutar Linux directamente en su equipo Windows, puede considerar el uso de entornos de Linux en la nube o servidores virtuales privados (VPS) para acceder y trabajar con Linux de forma remota.
Servicios como Amazon EC2, Microsoft Azure o DigitalOcean proporcionan instancias de Linux que puede conectar a su equipo Windows. Tenga en cuenta que algunos de estos servicios ofrecen niveles gratuitos, pero normalmente no son gratuitos a largo plazo.
Parte 2: Introducción a la Shell Bash y los Comandos del Sistema
2.1. Iniciando con la Shell Bash
Introducción a la shell bash
La línea de comandos de Linux es proporcionada por un programa llamado shell. A lo largo de los años, el programa shell ha evolucionado para adaptarse a varias opciones.
Diferentes usuarios pueden configurarse para usar diferentes shell. Sin embargo, la mayoría de los usuarios prefiere mantenerse con el shell predeterminado actual. El shell predeterminado para muchas distribuciones de Linux es el GNU Bourne-Again Shell (bash). Bash sucede al shell Bourne (sh).
Para descubrir su shell actual, abra su terminal y ingrese el siguiente comando:
echo $SHELL
Resumen del comando:
-
El comando
echose utiliza para imprimir en el terminal. -
La variable especial
$SHELLcontiene el nombre del shell actual.
En mi configuración, la salida es /bin/bash. Esto significa que estoy usando el shell bash.
# salida
echo $SHELL
/bin/bash
Bash es muy poderoso ya que puede simplificar ciertas operaciones que son difíciles de realizar eficientemente con una interfaz gráfica (o interfaz de usuario gráfico). Recuerde que la mayoría de los servidores no tienen una interfaz gráfica, y es mejor aprender a usar los poderes de una interfaz de línea de comandos (CLI).
Terminal vs Shell
Los términos “terminal” y “shell” se utilizan a menudo intercambiados, pero se refieren a partes diferentes de la interfaz de línea de comandos.
El terminal es la interfaz que utilizas para interactuar con la shell. La shell es el intérprete de comandos que procesa y ejecuta tus órdenes. Aprenderás más sobre las shell en la Parte 6 del manual.
¿Qué es un prompt?
Cuando se utiliza una shell de forma interactiva, muestra un $ cuando está esperando un comando del usuario. Este se conoce como el prompt de la shell.
[username@host ~]$
Si la shell se está ejecutando como root (más adelante aprenderás sobre el usuario root), el prompt cambia a #.
[root@host ~]#
2.2. Estructura de los Comandos
Un comando es un programa que realiza una operación específica. Una vez que tengas acceso a la shell, puedes ingresar cualquier comando después de la signatura $ y verás la salida en el terminal.
Generalmente, los comandos de Linux siguen esta sintaxis:
command [options] [arguments]
Aquí tienes el desglose de la sintaxis anterior:
-
comando: Este es el nombre del comando que deseas ejecutar.ls(list),cp(copy), yrm(remove) son comandos comunes de Linux. -
[opciones]: Las opciones, o banderas, usualmente precedidas de un guión (-) o un doble guión (–), modifican el comportamiento de la orden. Pueden cambiar cómo opera la orden. Por ejemplo,
ls -autiliza la opción-apara mostrar los archivos ocultos en el directorio actual. -
[argumentos]: Los argumentos son los datos de entrada para las órdenes que lo requieren. Estos podrían ser nombres de archivo, nombres de usuario u otra información que la orden actuará sobre. Por ejemplo, en la ordencat access.log,cates la orden yaccess.loges la entrada. Como resultado, la ordencatmuestra el contenido del archivoaccess.log.
Las opciones y los argumentos no son requeridos para todas las órdenes. Algunas órdenes se pueden ejecutar sin ninguna opción o argumento, mientras que otras pueden requerir uno o ambos para funcionar correctamente. Siempre puedes consultar el manual de la orden para ver qué opciones y argumentos admite.
💡Consejo: Puede consultar el manual de un comando usando el comando man.
Puede acceder a la página del manual para ls con man ls, y se verá así:

Las páginas del manual son una gran y rápida forma de acceder a la documentación. Recomiendo encarecidamente que revise las páginas del manual para los comandos que use más a menudo.
2.3. Comandos Bash y Atajos de Teclado
Cuando esté en el terminal, puede acelerar sus tareas usando atajos.
Aquí tienen algunos de los atajos de terminal más comunes:
| Operación | Atajo |
| Buscar el comando anterior | Arrow Up |
| Ir al principio de la palabra anterior | Ctrl+Arrow Izquierdo |
| Borrar caracteres desde el cursor hasta el final de la línea de comando | Ctrl+K |
| Completar comandos, nombres de archivo y opciones | Pulsar Tab |
| Ir al principio de la línea de comando | Ctrl+A |
| Mostrar la lista de comandos anteriores | history |
2.4. Identificándote: El Comando whoami
Puede obtener el nombre de usuario con el que inicio sesión usando el comando whoami. Este comando es útil cuando estás cambiando entre diferentes usuarios y quieres confirmar el usuario actual.
Sólo después de la signo de dólar $, escribe whoami y presiona Enter.
whoami
Este es el resultado que obtuve.
zaira@zaira-ThinkPad:~$ whoami
zaira
Parte 3: Entendiendo su Sistema Linux
3.1. Descubriendo su SO y especificaciones
Imprimir información del sistema usando el comando uname
Puede obtener información detallada del sistema mediante el comando uname.
Cuando proporciona la opción -a, imprime toda la información del sistema.
uname -a
# output
Linux zaira 6.5.0-21-generic #21~22.04.1-Ubuntu SMP PREEMPT_DYNAMIC Fri Feb 9 13:32:52 UTC 2 x86_64 x86_64 x86_64 GNU/Linux
En la salida anterior,
-
Linux: Indica el sistema operativo. -
zaira: Representa el nombre de host de la máquina. -
6.5.0-21-generic #21~22.04.1-Ubuntu SMP PREEMPT_DYNAMIC Fri Feb 9 13:32:52 UTC 2: Proporciona información sobre la versión del kernel, la fecha de construcción y algunos detalles adicionales. -
x86_64 x86_64 x86_64: Indica la arquitectura del sistema. -
GNU/Linux: Representa el tipo de sistema operativo.
Consulte detalles de la arquitectura del CPU utilizando el comando lscpu
El comando lscpu en Linux se utiliza para mostrar información sobre la arquitectura del CPU. Cuando ejecuta lscpu en el terminal, proporciona detalles tales como:
-
La arquitectura del CPU (por ejemplo, x86_64)
-
Modos de operación del CPU (por ejemplo, 32-bit, 64-bit)
-
Orden de bytes (por ejemplo, Little Endian)
-
Número de CPU(s), y así sucesivamente
Vamos a probarlo:
lscpu
# output
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Address sizes: 48 bits physical, 48 bits virtual
Byte Order: Little Endian
CPU(s): 12
On-line CPU(s) list: 0-11
Vendor ID: AuthenticAMD
Model name: AMD Ryzen 5 5500U with Radeon Graphics
Thread(s) per core: 2
Core(s) per socket: 6
Socket(s): 1
Stepping: 1
CPU max MHz: 4056.0000
CPU min MHz: 400.0000
Fue una gran cantidad de información, pero también útil! Recuerde que siempre puede consultar información relevante utilizando banderas específicas. Vea el manual del comando con man lscpu.
Parte 4: Gestionar archivos desde la línea de comandos
4.1. La Jerarquía del Sistema de Archivos de Linux
Todos los archivos en Linux se almacenan en un sistema de archivos. Es una estructura en forma de árbol invertido porque la raíz se encuentra en la parte superior.
El carácter / es la carpeta raíz y el punto de partida del sistema de archivos. La carpeta raíz contiene todas las otras carpetas y archivos del sistema. El carácter / también sirve como separador de carpetas en las rutas. Por ejemplo, /home/alice forma una ruta completa.
A continuación se muestra la jerarquía completa del sistema de archivos. Cada directorio sirve a un propósito específico.
Tenga en cuenta que esta no es una lista exhaustiva y diferentes distribuciones pueden tener configuraciones diferentes.
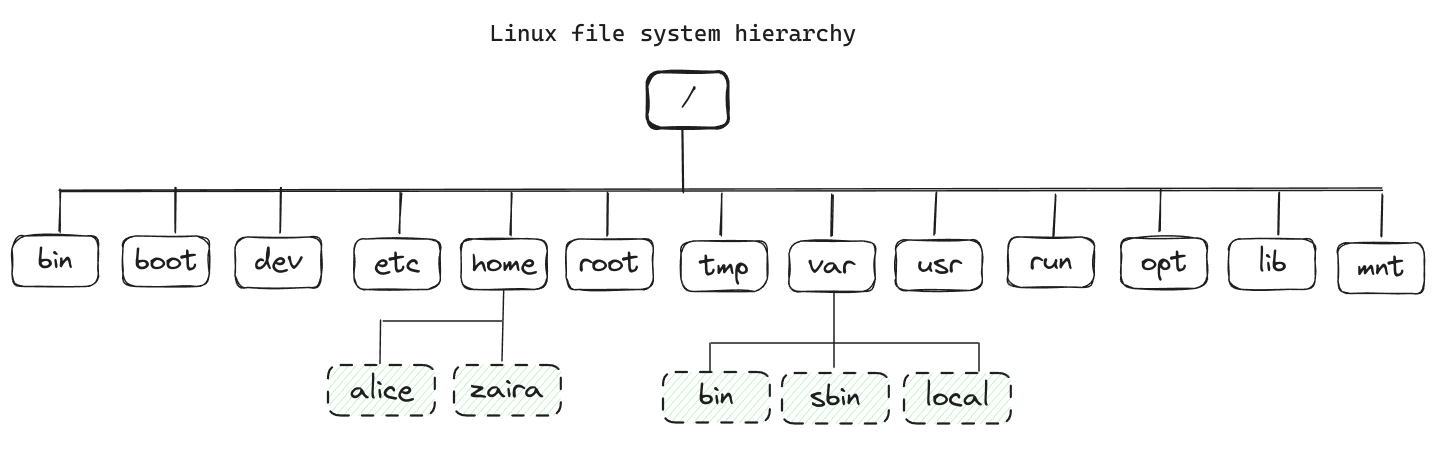
Aquí se muestra una tabla que muestra el propósito de cada directorio:
| Ubicación | Propósito |
| /bin | Binarios de órdenes esenciales |
| /boot | Archivos estáticos del cargador de arranque, necesarios para iniciar el proceso de arranque. |
| /etc | Configuración específica del sistema del equipo |
| /home | Directorios personales de los usuarios |
| /root | Directorio personal de la cuenta de administración root |
| /lib | Bibliotecas compartidas esenciales y módulos del kernel |
| /mnt | Punto de montaje para montar un sistema de archivos temporalmente |
| /opt | Paquetes de software aplicativo complementarios |
| /usr | Software instalado y bibliotecas compartidas |
| /var | Datos variables que persisten entre reinicios |
| /tmp | Archivos temporales accesibles a todos los usuarios |
💡 Consejo: Puede aprender más sobre el sistema de archivos usando la orden man hier.
Puede ver su sistema de archivos usando la orden tree -d -L 1. Puede modificar la opción -L para cambiar la profundidad del árbol.
tree -d -L 1
# output
.
├── bin -> usr/bin
├── boot
├── cdrom
├── data
├── dev
├── etc
├── home
├── lib -> usr/lib
├── lib32 -> usr/lib32
├── lib64 -> usr/lib64
├── libx32 -> usr/libx32
├── lost+found
├── media
├── mnt
├── opt
├── proc
├── root
├── run
├── sbin -> usr/sbin
├── snap
├── srv
├── sys
├── tmp
├── usr
└── var
25 directories
Esta lista no es exhaustiva y diferentes distribuciones y sistemas pueden estar configuradas de manera diferente.
4.2. Navegar por el Sistema de Archivos de Linux
Ruta absoluta vs ruta relativa
La ruta absoluta es la ruta completa desde la carpeta raíz hasta el archivo o carpeta. Siempre empieza con un /. Por ejemplo, /home/john/documents.
La ruta relativa, por otra parte, es la ruta desde la carpeta actual hasta el archivo o carpeta de destino. No empieza con un /. Por ejemplo, documents/work/project.
Localizar su carpeta actual usando el comando pwd
Es fácil perderse en el sistema de archivos de Linux, especialmente si es nuevo en la línea de comandos. Puede localizar su carpeta actual usando el comando pwd.
Aquí hay un ejemplo:
pwd
# output
/home/zaira/scripts/python/free-mem.py
Cambiar carpetas usando el comando cd
El comando para cambiar carpetas es cd y significa “cambiar carpeta”. Puede usar el comando cd para navegar a una carpeta diferente.
Puede usar una ruta relativa o una ruta absoluta.
Por ejemplo, si desea navegar por la estructura de archivos de abajo (seguir las líneas rojas):
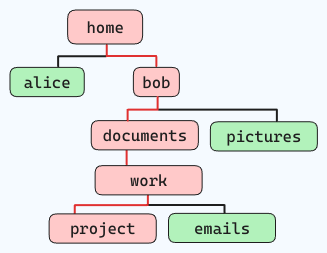
y se encuentra en “home”, el comando sería algo así:
cd home/bob/documents/work/project
Algunos otros atajos de cd comúnmente usados son:
| Comando | Descripción |
cd .. |
Atrás una carpeta |
cd ../.. |
Atrás dos carpetas |
cd o cd ~ |
Ir al directorio de inicio |
cd - |
Ir a la ruta anterior |
4.3. Gestionar Archivos y Directorios
Al trabajar con archivos y directorios, podría querer copiar, mover, eliminar y crear nuevos archivos y directorios. Aquí están algunos comandos que le pueden ayudar con eso.
💡Consejo: Puede diferenciar entre un archivo y una carpeta mirando la primera letra en la salida de ls -l. Un '-' representa un archivo y un 'd' representa una carpeta.
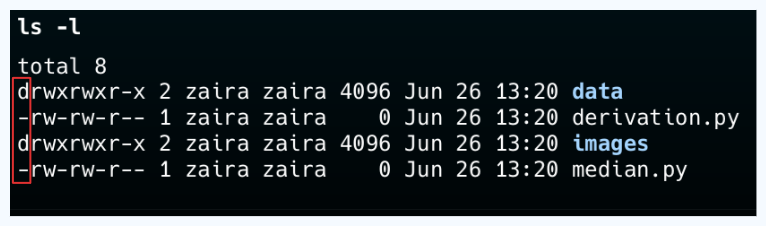
Crear carpetas nuevas usando el comando mkdir
Puede crear una carpeta vacía usando el comando mkdir.
# crea una carpeta vacía llamada "foo" en el directorio actual
mkdir foo
También puede crear carpetas recursivamente usando la opción -p.
mkdir -p tools/index/helper-scripts
# salida de tree
.
└── tools
└── index
└── helper-scripts
3 directories, 0 files
Crear archivos nuevos usando el comando touch
El comando touch crea un archivo vacío. Puede usarlo así:
# crea el archivo vacío "file.txt" en el directorio actual
touch file.txt
Los nombres de los archivos pueden enlazarse si quiere crear varios archivos en un solo comando.
# crea archivos vacíos "file1.txt", "file2.txt" y "file3.txt" en la carpeta actual
touch file1.txt file2.txt file3.txt
Eliminando archivos y directorios usando el comando rm y rmdir
Puedes usar el comando rm para eliminar tanto archivos como directorios no vacíos.
| Comando | Descripción |
rm file.txt |
Elimina el archivo file.txt |
rm -r directory |
Elimina el directorio directory y su contenido |
rm -f file.txt |
Elimina el archivo file.txt sin pedir confirmación |
rmdir directory |
Elimina un directorio vacío |
🛑 Tenga en cuenta que debe usar la bandera -f con cautela ya que no se le pedirá confirmación antes de eliminar un archivo. Además, tenga cuidado al ejecutar comandos rm en la carpeta root ya que podría resultar en la eliminación de importantes archivos del sistema.
Copiando archivos usando el comando cp
Para copiar archivos en Linux, use el comando cp.
- Sintaxis para copiar archivos:
cp source_file destination_of_file
Este comando copia un archivo llamado file1.txt a una nueva ubicación de archivo /home/adam/logs.
cp file1.txt /home/adam/logs
El comando cp también crea una copia de un archivo con el nombre proporcionado.
Este comando copia un archivo llamado file1.txt a otro archivo llamado file2.txt en la misma carpeta.
cp file1.txt file2.txt
Mover y renombrar archivos y carpetas usando el comando mv
El comando mv se utiliza para mover archivos y carpetas de un directorio a otro.
Sintaxis para mover archivos:mv archivo_origen directorio_destino
Ejemplo: Mover un archivo llamado file1.txt a un directorio llamado backup:
mv file1.txt backup/
Para mover un directorio y su contenido:
mv dir1/ backup/
El renombrar de archivos y carpetas en Linux se realiza también con el comando mv.
Sintaxis para renombrar archivos:mv nombre_viejo nombre_nuevo
Ejemplo: Renombrar un archivo de file1.txt a file2.txt:
mv file1.txt file2.txt
Renombrar un directorio de dir1 a dir2:
mv dir1 dir2
4.4. Encontrar Archivos y carpetas Usando el Comando find
El comando find le permite buscar eficientemente archivos, carpetas y dispositivos de caracteres y bloques.
A continuación se muestra la sintaxis básica del comando find:
find /path/ -type f -name file-to-search
Donde,
-
/pathes la ruta donde se espera que se encuentre el archivo. Esto es el punto de partida para buscar archivos. La ruta también puede ser/o., que representan respectivamente la raíz y el directorio actual. -
-typerepresenta los descriptores de archivo. Pueden ser cualquiera de los siguientes:
f– Archivo regular como archivos de texto, imágenes y archivos ocultos.
d– Directorio. Estos son los carpetas que se están considerando.
l– Enlace simbólico. Los enlaces simbólicos apuntan a archivos y son similares a los accesorios.
c– Dispositivos de caracteres. Los archivos que se utilizan para acceder a dispositivos de caracteres se llaman archivos de dispositivo de caracteres. Los controladores se comunican con los dispositivos de caracteres enviando y recibiendo caracteres individuales (bytes, octetos). Ejemplos incluyen las computadoras de escritorio, tarjetas de sonido y el mouse.
b– Dispositivos de bloque. Los archivos que se utilizan para acceder a dispositivos de bloque se llaman archivos de dispositivo de bloque. Los controladores se comunican con los dispositivos de bloque enviando y recibiendo bloques completos de datos. Ejemplos incluyen USB y CD-ROM. -
-namees el nombre del tipo de archivo que desea buscar.
Cómo buscar archivos por nombre o extensión
Supongamos que necesitamos encontrar archivos que contengan “style” en su nombre. Utilizaremos este comando:
find . -type f -name "style*"
#output
./style.css
./styles.css
Ahora digamos que queremos encontrar archivos con una extensión particular como .html. Modificaremos el comando de esta manera:
find . -type f -name "*.html"
# output
./services.html
./blob.html
./index.html
Cómo buscar archivos ocultos
Un punto al inicio del nombre de archivo representa archivos ocultos. Normalmente están ocultos, pero pueden ser visualizados con ls -a en el directorio actual.
Podemos modificar la orden find como se muestra a continuación para buscar archivos ocultos:
find . -type f -name ".*"
Listar y encontrar archivos ocultos
ls -la
# contenido de la carpeta
total 5
drwxrwxr-x 2 zaira zaira 4096 Mar 26 14:17 .
drwxr-x--- 61 zaira zaira 4096 Mar 26 14:12 ..
-rw-rw-r-- 1 zaira zaira 0 Mar 26 14:17 .bash_history
-rw-rw-r-- 1 zaira zaira 0 Mar 26 14:17 .bash_logout
-rw-rw-r-- 1 zaira zaira 0 Mar 26 14:17 .bashrc
find . -type f -name ".*"
# salida de find
./.bash_logout
./.bashrc
./.bash_history
Aquí puede ver una lista de archivos ocultos en mi directorio personal.
Cómo buscar archivos de registro y archivos de configuración
Los archivos de registro usualmente tienen la extensión .log y los podemos encontrar de este modo:
find . -type f -name "*.log"
Del mismo modo, podemos buscar archivos de configuración de este modo:
find . -type f -name "*.conf"
Cómo buscar otros archivos por tipo
Podemos buscar archivos de bloques de caracteres proporcionando c a -type:
find / -type c
Del mismo modo, podemos encontrar archivos de bloques de dispositivo usando b:
find / -type b
Cómo buscar directorios
En el ejemplo de abajo, estamos encontrando las carpetas usando la bandera -type d.
ls -l
# listar contenido de la carpeta
drwxrwxr-x 2 zaira zaira 4096 Mar 26 14:22 hosts
-rw-rw-r-- 1 zaira zaira 0 Mar 26 14:23 hosts.txt
drwxrwxr-x 2 zaira zaira 4096 Mar 26 14:22 images
drwxrwxr-x 2 zaira zaira 4096 Mar 26 14:23 style
drwxrwxr-x 2 zaira zaira 4096 Mar 26 14:22 webp
find . -type d
# salida de buscar directorio
.
./webp
./images
./style
./hosts
Cómo buscar archivos por tamaño
Un uso increíblemente útil de la orden find es listade archivos en base a un tamaño particular.
find / -size +250M
Aquí, estamos listade archivos cuyo tamaño excede los 250MB.
Otras unidades incluyen:
-
G: GigaBytes. -
M: MegaBytes. -
K: KiloBytes -
c: bytes.
Sustituya con la unidad relevante.
find <directory> -type f -size +N<Unit Type>
Cómo buscar archivos por fecha de modificación
Usando la opción -mtime, puede filtrar archivos y carpetas según la fecha de modificación.
find /path -name "*.txt" -mtime -10
Por ejemplo,
-
-mtime +10 significa que busca un archivo modificado hace 10 días.
-
-mtime -10 significa menos de 10 días.
-
-mtime 10 Si omite + o – significa exactamente 10 días.
4.5. Órdenes básicas para ver archivos
Concatenar y mostrar archivos usando el comando cat
El comando cat en Linux se utiliza para mostrar el contenido de un archivo. También puede usarse para concatenar archivos y crear archivos nuevos.
Aquí está la sintaxis básica del comando cat:
cat [options] [file]
La forma más simple de usar cat es sin opciones ni argumentos. Esto mostrará el contenido del archivo en la terminal.
Por ejemplo, si desea ver el contenido de un archivo llamado file.txt, puede usar el siguiente comando:
cat file.txt
Esto mostrará todo el contenido del archivo en la terminal de una sola vez.
Para ver archivos de texto de forma interactiva usando less y more
Mientras que cat muestra todo el archivo de una sola vez, less y more le permiten ver el contenido de un archivo de forma interactiva. Esto es útil cuando desea desplazarse por un archivo grande o buscar contenido específico.
La sintaxis del comando less es:
less [options] [file]
El comando more es similar a less pero con menos características. Se utiliza para mostrar el contenido de un archivo por pantalla completa.
La sintaxis del comando more es:
more [options] [file]
Para ambos comandos, puede usar la barra espaciadora para desplazarse una página hacia abajo, la tecla Enter para desplazarse una línea hacia abajo y la tecla q para salir del visor.
Para moverse hacia atrás, puede usar la tecla b, y para moverse hacia adelante, puede usar la tecla f.
Visualización de la última parte de los archivos usando tail
A veces puede que necesite ver solo las últimas líneas de un archivo en lugar de todo el archivo. El comando tail en Linux se utiliza para mostrar la última parte de un archivo.
Por ejemplo, tail file.txt mostrará por defecto las últimas 10 líneas del archivo file.txt.
Si desea mostrar un número distinto de líneas, puede usar la opción -n seguida del número de líneas que desea mostrar.
# Muestra las últimas 50 líneas del archivo file.txt
tail -n 50 file.txt
💡Consejo: Otra utilidad del tail es su opción de seguimiento (-f). Esta opción le permite ver el contenido de un archivo mientras se escriben. Es una herramienta útil para ver y monitorear los archivos de registro en tiempo real.
Muestra de principios de archivos usando head
Al igual que tail muestra la última parte de un archivo, puede usar el comando head en Linux para mostrar el principio de un archivo.
Por ejemplo, head file.txt mostrará por defecto las primeras 10 líneas del archivo file.txt.
Para cambiar el número de líneas mostradas, puede usar la opción -n seguida del número de líneas que desea mostrar.
Contando palabras, líneas y caracteres usando wc
Puede contar palabras, líneas y caracteres en un archivo usando el comando wc.
Por ejemplo, ejecutando wc syslog.log me dio la siguiente salida:
1669 9623 64367 syslog.log
En la salida anterior,
-
1669representa el número de líneas en el archivosyslog.log. -
9623representa el número de palabras en el archivosyslog.log. -
64367representa el número de caracteres en el archivosyslog.log.
Así, la orden wc syslog.log contó 1669 líneas, 9623 palabras y 64367 caracteres en el archivo syslog.log.
Comparando archivos linea por linea usando diff
Comparar y encontrar diferencias entre dos archivos es una tarea común en Linux. Puede comparar dos archivos directamente en la línea de comandos usando la orden diff.
La sintaxis básica de la orden diff es:
diff [options] file1 file2
Aquí hay dos archivos, hello.py y also-hello.py, que vamos a comparar usando la orden diff:
# contenido de hello.py
def greet(name):
return f"Hello, {name}!"
user = input("Enter your name: ")
print(greet(user))
# contenido de also-hello.py
more also-hello.py
def greet(name):
return fHello, {name}!
user = input(Enter your name: )
print(greet(user))
print("Nice to meet you")
- Compruebe si los archivos son iguales o no
diff -q hello.py also-hello.py
# Salida
Files hello.py and also-hello.py differ
- Vea cómo los archivos difieren. Para eso, puede usar la opción
-upara ver una salida unificada:
diff -u hello.py also-hello.py
--- hello.py 2024-05-24 18:31:29.891690478 +0500
+++ also-hello.py 2024-05-24 18:32:17.207921795 +0500
@@ -3,4 +3,5 @@
user = input(Enter your name: )
print(greet(user))
+print("Nice to meet you")
— hello.py 2024-05-24 18:31:29.891690478 +0500
- En la salida anterior:
--- hello.py 2024-05-24 18:31:29.891690478 +0500indica el archivo que se está comparando y su marca de tiempo.+++ also-hello.py 2024-05-24 18:32:17.207921795 +0500indica el otro archivo que se está comparando y su marca de tiempo.@@ -3,4 +3,5 @@muestra los números de línea donde ocurren los cambios. En este caso, indica que las líneas 3 a 4 en el archivo original han cambiado a las líneas 3 a 5 en el archivo modificado.user = input(Enter your name: )es una línea del archivo original.print(greet(user))es otra línea del archivo original.
+print("Nice to meet you")es la línea adicional en el archivo modificado.
diff -y hello.py also-hello.py
Para ver la diferencia en un formato lado a lado, puedes usar la opción -y:
def greet(name): def greet(name):
return fHello, {name}! return fHello, {name}!
user = input(Enter your name: ) user = input(Enter your name: )
print(greet(user)) print(greet(user))
> print("Nice to meet you")
# Salida
- En la salida:
- Las líneas que son iguales en ambos archivos se muestran lado a lado.
Las líneas que son diferentes se muestran con un símbolo > que indica que la línea solo está presente en uno de los archivos.
Parte 5: Los fundamentos de la edición de texto en Linux
Las habilidades de edición de texto usando la línea de comandos son una de las habilidades más cruciales en Linux. En esta sección, aprenderás a usar dos editores de texto populares en Linux: Vim y Nano.
Te sugiero que domines cualquier editor de texto de tu elección y que te atas a él. Te ahorrará tiempo y te hará más productivo. Vim y nano son opciones seguras ya que están presentes en la mayoría de las distribuciones de Linux.
5.1. Dominando Vim: La guía completa
Introducción a Vim
- Vim es una herramienta popular de edición de texto para la línea de comandos. Vim cuenta con sus ventajas: es potente, personalizable y rápido. He aquí algunas razones por las que deberías considerar aprender Vim:
- La mayoría de los servidores se acceden a través de una CLI, por lo que en la administración de sistemas, no siempre tienes el lujo de una GUI. Pero Vim te respalda – siempre estará allí.
- Vim utiliza un enfoque centrado en el teclado, ya que está diseñado para ser usado sin ratón, lo cual puede incrementar sustancialmente la velocidad de las tareas de edición una vez que haya aprendido los atajos de teclado. Esto también lo hace más rápido que las herramientas de interfaz gráfica.
- Algunas utilidades de Linux, por ejemplo, la edición de trabajos cron, funcionan en el mismo formato de edición que Vim.
Vim es adecuado para todos – tanto para principiantes como para usuarios avanzados. Vim admite búsquedas de cadenas complejas, resaltado de búsquedas y mucho más. A través de plugins, Vim proporciona funcionalidades extendidas a desarrolladores y administradores de sistemas que incluyen compleción de código, resaltado de sintaxis, gestión de archivos, control de versiones y más.
Vim tiene dos variantes: Vim (vim) y Vim tiny (vi). Vim tiny es una versión más pequeña de Vim que carece de algunas características de Vim.
Cómo empezar a usar vim
vim your-file.txt
Comience a usar Vim con este comando:
your-file.txt puede ser un archivo nuevo o un archivo existente que desea editar.
Navegando en Vim: Dominando los movimientos y los modos de comando
En los primeros días de la CLI, los teclados no tenían teclas de flecha. Por lo tanto, la navegación se realizaba usando el conjunto de teclas disponibles, hjkl siendo uno de ellos.
Al ser centrado en el teclado, el uso de las teclas hjkl puede acelerar considerablemente las tareas de edición de texto.
Nota: Aunque las teclas de flecha funcionarían totalmente bien, aún puedes experimentar con las teclas hjkl para navegar. Algunas personas encuentran esta forma de navegación eficiente.

💡Consejo: Para recordar la secuencia hjkl, usa esto: hang back, jump down, kick up, leap forward.
Los tres modos de Vim
- Necesitas saber los 3 modos de operación de Vim y cómo cambiar entre ellos. Los golpes de teclas se comportan de forma diferente en cada modo de comando. Los tres modos son los siguientes:
- Modo de comando.
- Modo de edición.
Modo visual.
Modo de Comando. Cuando inicias Vim, apareces en el modo de comando de forma predeterminada. Este modo te permite acceder a otros modos.
⚠ Para cambiar a otros modos, primero debes estar en el modo de comando
Modo de Edición
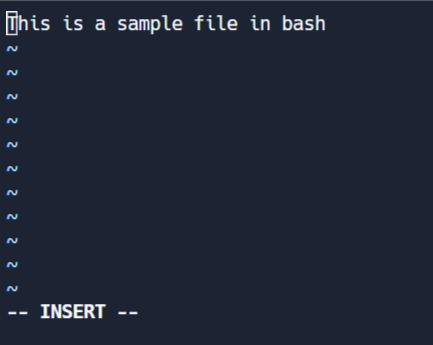
Este modo te permite realizar cambios en el archivo. Para entrar en el modo de edición, presiona I mientras estás en el modo de comando. Observa la opción '-- INSERT' en la parte inferior de la pantalla.
Modo visual
- Este modo le permite trabajar en un solo carácter, un bloque de texto o líneas de texto. Vamos a desglosar esto en pasos simples. Recuerde, use las combinaciones siguientes cuando esté en modo de comando.
Mayús + V→ Selecciona varias líneas.Ctrl + V→ Modo de bloque
V → Modo de carácter
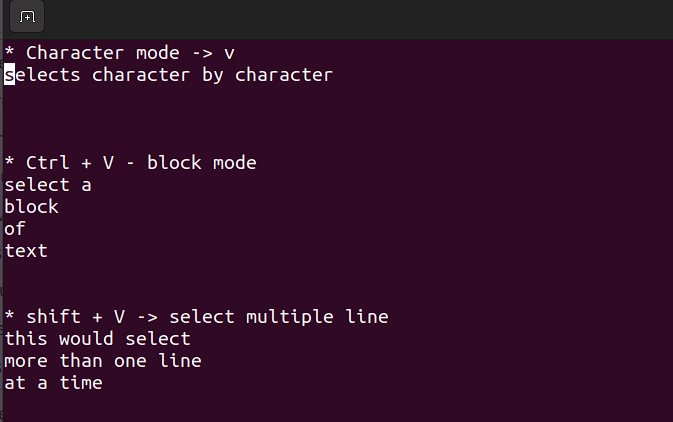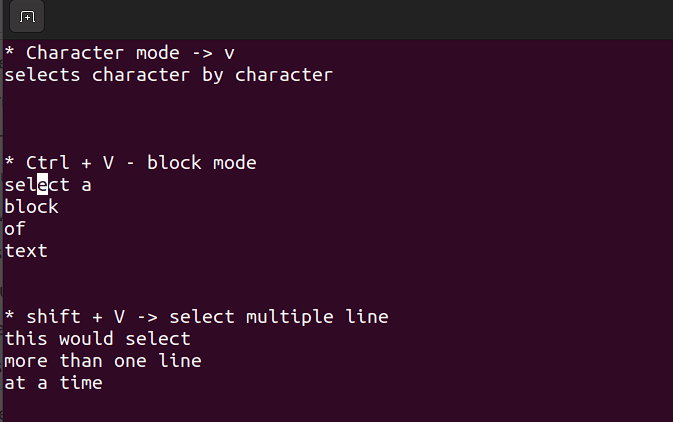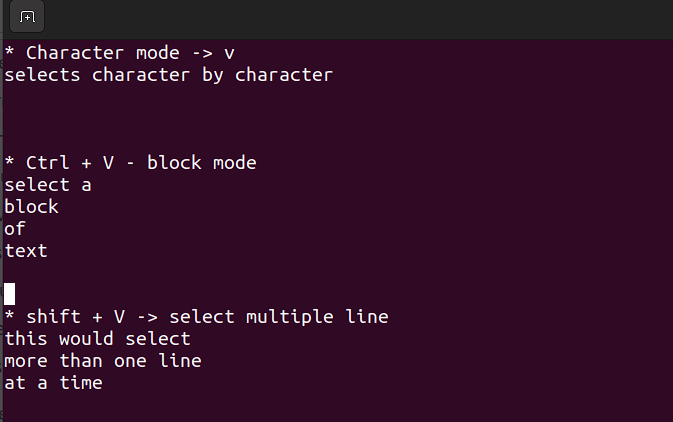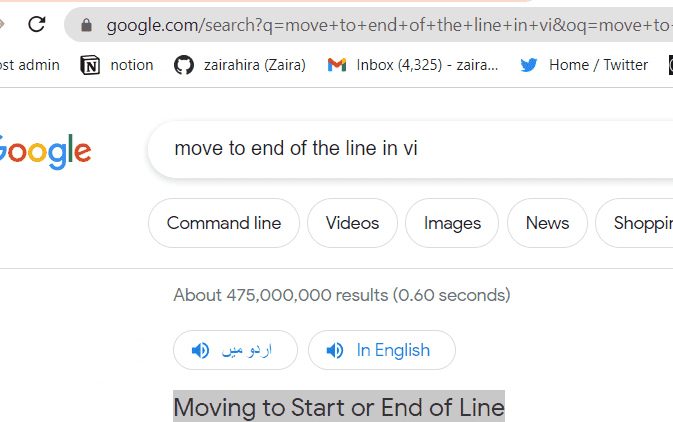
El modo visual es útil cuando necesita copiar y pegar o editar líneas en lotes.
Modo de comando extendido.
El modo de comando extendido le permite realizar operaciones avanzadas como buscar, configurar números de línea y resaltar texto. Vamos a cubrir el modo extendido en la sección siguiente.
¿Cómo mantenerse en el rumbo? Si olvida su modo actual, solo presione ESC dos veces y volverá al Modo de Comando.
Edición eficiente en Vim: Copiar/pegar y buscar
1. Cómo copiar y pegar en Vim
- La copiar/pegar se conoce como ‘sacar’ y ‘poner’ en términos de Linux. Para copiar/pegar, siga estos pasos:
- Seleccione texto en modo visual.
- Pulse
'y'para copiar/sacar.
Mueve tu cursor a la posición requerida y presiona 'p'.
2. Cómo buscar texto en Vim
Cualquier serie de cadenas puede buscarse en Vim usando el / en modo de comando. Para buscar, usa /cadena-a-coincidir.
En modo de comando, tipea :set hls y presiona enter. Busca usando /cadena-a-coincidir. Esto destacará las búsquedas.
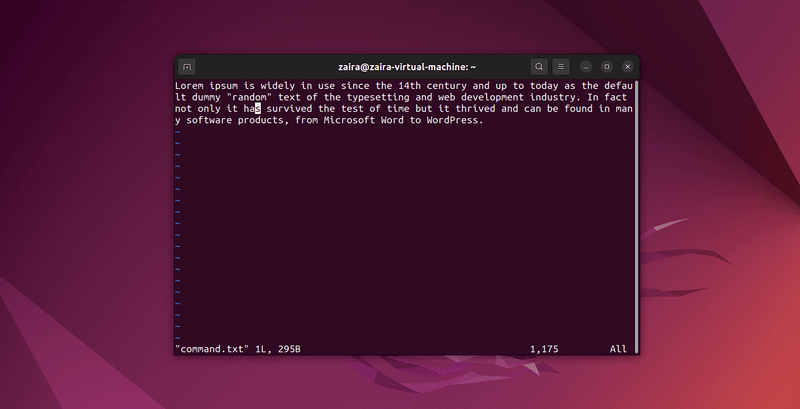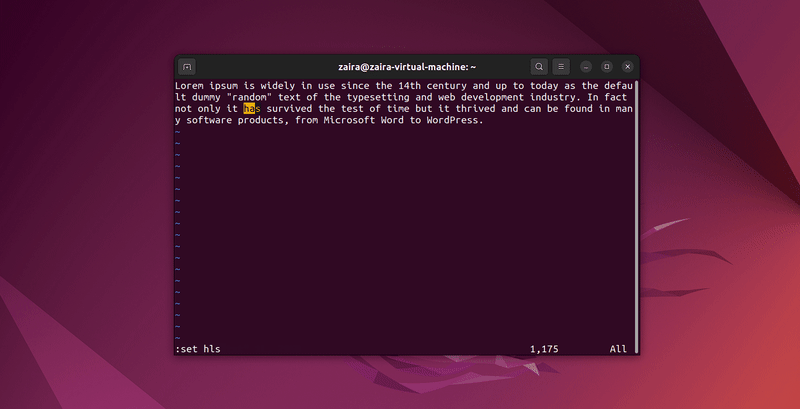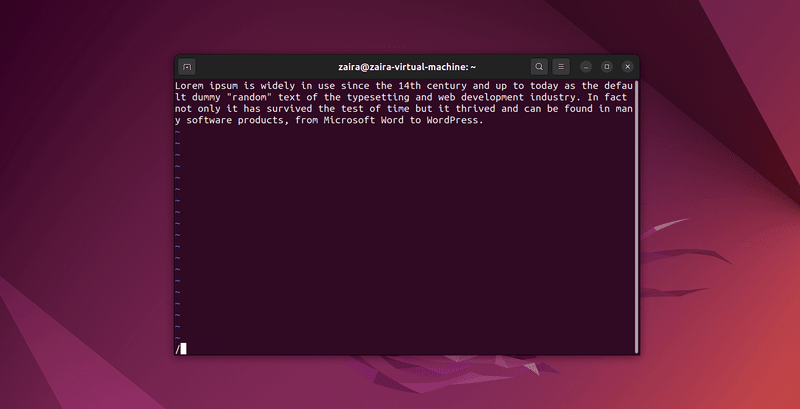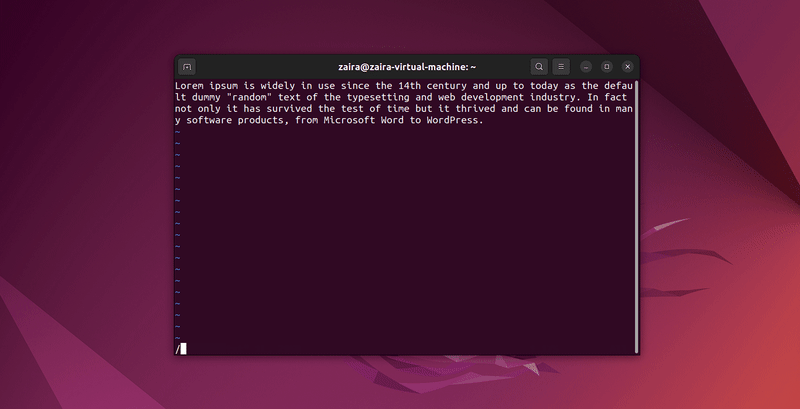
Vamos a buscar unas cuantas cadenas:
3. Cómo salir de Vim
- Primero, mueve al modo de comando (presionando escape dos veces) y luego utiliza estas opciones:
- Salir sin guardar →
:q!
Salir y guardar → :wq!
Atajos en Vim: Haciendo la Edición Más Rápida
- Nota: Todos estos atajos funcionan solo en modo de comando.
Ctrl+u: Mover mitad de página arribaP: Pegar encima del cursor:%s/old/new/g: Reemplazar todas las ocurrencias deoldconnewen el archivo- :q!: Salir sin guardar
Ctrl+w seguido de h/j/k/l: Navegar entre ventanas divididas
5.2. Dominar Nano
Iniciándose con Nano: El editor de texto amigable con el usuario
Nano es un editor de texto amigable con el usuario que es fácil de usar y perfecto para principiantes. Está preinstalado en la mayoría de las distribuciones de Linux.
nano
Para crear un archivo nuevo usando Nano, use el siguiente comando:
nano filename
Para empezar a editar un archivo existente con Nano, use el siguiente comando:
Lista de atajos de teclado en Nano
Vamos a estudiar los atajos de teclado más importantes en Nano. Usará los atajos de teclado para realizar varias operaciones como guardar, salir, copiar, pegar y más.
Escribir en un archivo y guardar
Una vez que abres Nano usando el comando nano, puedes empezar a escribir texto. Para guardar el archivo, presiona Ctrl+O. Se le pedirá que ingrese el nombre del archivo. Presione Enter para guardar el archivo.
Salir de Nano
Puede salir de Nano presionando Ctrl+X. Si tiene cambios sin guardar, Nano le pedirá que guarde los cambios antes de salir.
Copiar y pegar
Para seleccionar una región, use ALT+A. Aparecerá un marcador. Use las flechas para seleccionar el texto. Una vez seleccionado, salga del marcador con ALT+^.
Para copiar el texto seleccionado, presione Ctrl+K. Para pegar el texto copiado, presione Ctrl+U.
Cortar y pegar
Seleccione la región con ALT+A. Una vez seleccionado, corte el texto con Ctrl+K. Para pegar el texto cortado, presione Ctrl+U.
Navegación
Use Alt \ para moverse al inicio del archivo.
Use Alt / para moverse al final del archivo.
Visualización de números de línea
Cuando abre un archivo con nano -l nombre_archivo, puede ver los números de línea en el lado izquierdo del archivo.
Búsqueda
Puede buscar una línea específica con ALt + G. Ingrese el número de línea a la solicitud y presione Enter.
Puedes también iniciar la búsqueda de una cadena con CTRL + W y presionar Enter. Si quieres buscar hacia atrás, puedes presionar Alt+W después de iniciar la búsqueda con Ctrl+W.
- Resumen de atajos de teclado en Nano
Ctrl+G: Mostrar el texto de ayudaCtrl+J: Justificar el párrafo actualCtrl+V: Desplazarse una página hacia abajoCtrl+\: Buscar y reemplazar
Alt+E: Volver a hacer la última operación deshecha
Parte 6: Escritura de scripts Bash
6.1. Definición de la escritura de scripts Bash
Un script Bash es un archivo que contiene una secuencia de órdenes que es ejecutada por el programa Bash línea por línea. Permite realizar una serie de acciones, como navegar a un directorio específico, crear una carpeta y lanzar un proceso usando la línea de comandos.
Al guardar comandos en un script, puedes repetir la misma secuencia de pasos varias veces y ejecutarlos ejecutando el script.
6.2. Ventajas del Scripting Bash
El scripting Bash es una herramienta poderosa y versátil para automatizar tareas de administración de sistema, manejar recursos del sistema y realizar otras tareas rutinarias en sistemas Unix/Linux.
- Algunas ventajas del scripting de shell son:
- Automatización: Los scripts de shell permiten automatizar tareas y procesos repetitivos, economizando tiempo y reduciendo el riesgo de errores que pueden ocurrir con la ejecución manual.
- Portabilidad: Los scripts de shell pueden ejecutarse en varias plataformas y sistemas operativos, incluyendo Unix, Linux, macOS, e incluso Windows mediante el uso de emuladores o máquinas virtuales.
- Flexibilidad: Las shell scripts son altamente personalizables y pueden modificarse fácilmente para adaptarse a requerimientos específicos. También pueden combinarse con otras lenguajes de programación o utilidades para crear scripts más potentes.
- Accesibilidad: Las shell scripts son fáciles de escribir y no requieren herramientas o software especiales. Pueden editarse usando cualquier editor de texto, y la mayoría de los sistemas operativos tienen un intérprete de shell integrado.
- Integración: Las shell scripts pueden integrarse con otras herramientas y aplicaciones, como bases de datos, servidores web y servicios en la nube, permitiendo tareas de automatización y gestión de sistemas más complejas.
Depuración: Las shell scripts son fáciles de depurar, y la mayoría de las shell tienen herramientas de depuración y de reporte de errores integradas que pueden ayudar a identificar y corregir problemas rápidamente.
6.3. Visión general del shell Bash y de la interfaz de línea de comandos
Los términos “shell” y “bash” se utilizan a menudo indistintamente. Pero hay una diferencia sutil entre ambos.
El término “shell” se refiere a un programa que proporciona una interfaz de línea de comandos para interactuar con un sistema operativo. Bash (Bourne-Again SHell) es una de las shell más utilizadas de Unix/Linux y es la shell predeterminada en muchas distribuciones de Linux.
Hasta ahora, los comandos que has estado introduciendo eran básicamente introducidos en una “shell”.
Aunque Bash es un tipo de shell, también hay otras shell disponibles, como shell de Korn (ksh), shell de C (csh) y shell Z (zsh). Cada shell tiene su propia sintaxis y conjunto de características, pero comparten la misma finalidad de proporcionar una interfaz de línea de comandos para interactuar con el sistema operativo.
ps
# output:
PID TTY TIME CMD
20506 pts/0 00:00:00 bash <--- the shell type
20931 pts/0 00:00:00 ps
Puedes determinar el tipo de shell que utilizas utilizando el comando ps:
En resumen, mientras que “shell” es un término amplio que se refiere a cualquier programa que proporciona una interfaz de línea de comandos, “Bash” es un tipo específico de shell que se utiliza ampliamente en sistemas Unix/Linux.
Nota: En esta sección, utilizaremos la “shell bash”.
6.4. Cómo crear y ejecutar scripts Bash
Convenciones de nomenclatura de scripts
Por convención, los scripts bash terminan con .sh. Sin embargo, los scripts bash pueden ejecutarse perfectamente sin la extensión sh.
Agregar el Shebang
Los scripts Bash empiezan con un shebang. Shebang es una combinación de bash # y bang ! seguido de la ruta de la shell Bash. Esta es la primera línea del script. Shebang indica a la shell que ejecute mediante la shell Bash. Shebang es simplemente una ruta absoluta hacia el intérprete Bash.
#!/bin/bash
A continuación se muestra un ejemplo de la declaración shebang.
which bash
Puede encontrar su ruta de shell Bash (que puede variar de la arriba) utilizando el comando:
Creando tu primera script Bash
Nuestro primer script le pide al usuario que introduzca una ruta. A cambio, se listarán sus contenidos.
vim run_all.sh
Cree un archivo llamado run_all.sh usando cualquier editor de su preferencia.
#!/bin/bash
echo "Today is " `date`
echo -e "\nenter the path to directory"
read the_path
echo -e "\n you path has the following files and folders: "
ls $the_path
Agregue los siguientes comandos en su archivo y guárdelo:
1 Veamos más profundamente el script línea por línea. Estoy mostrando el mismo script de nuevo, pero esta vez con números de línea.
2 echo "Today is " `date`
3
4 echo -e "\nenter the path to directory"
5 read the_path
6
7 echo -e "\n you path has the following files and folders: "
8 ls $the_path
- #!/bin/bash
- Línea #1: El shebang (
#!/bin/bash) apunta hacia la ruta de la shell Bash. - Línea #2: El comando
echomuestra la fecha y hora actual en la terminal. Note quedateestá entre comillas invertidas. - Línea #4: Queremos que el usuario introduzca una ruta válida.
- Linea #5: El comando
readlee la entrada y la almacena en la variablethe_path.
linea #8: El comando ls toma la variable con el path almacenado y muestra los archivos y carpetas actuales.
Ejecutando el script de Bash
chmod u+x run_all.sh
Para hacer que el script sea ejecutable, asigna derechos de ejecución a tu usuario empleando este comando:
- Aquí,
chmodmodifica la propiedad de un archivo para el usuario actual :u.+xagrega los derechos de ejecución al usuario actual. Esto significa que el usuario dueño puede ejecutar ahora el script.
run_all.sh es el archivo que queremos ejecutar.
- Puedes ejecutar el script usando cualquiera de los métodos mencionados:
sh run_all.shbash run_all.sh
./run_all.sh
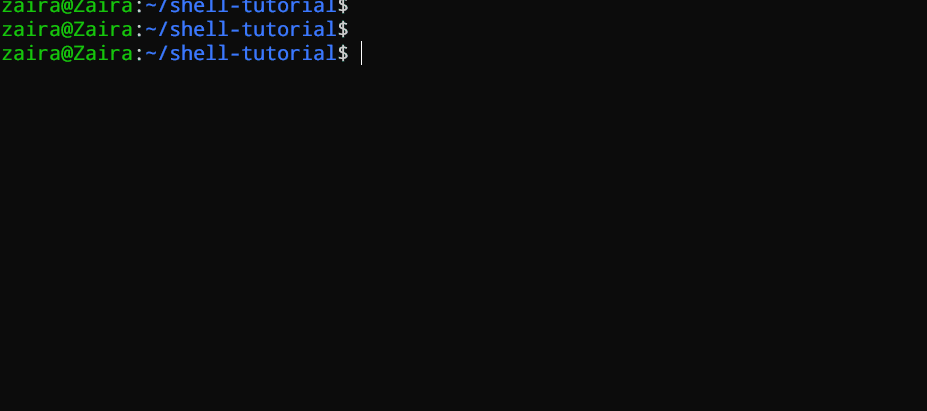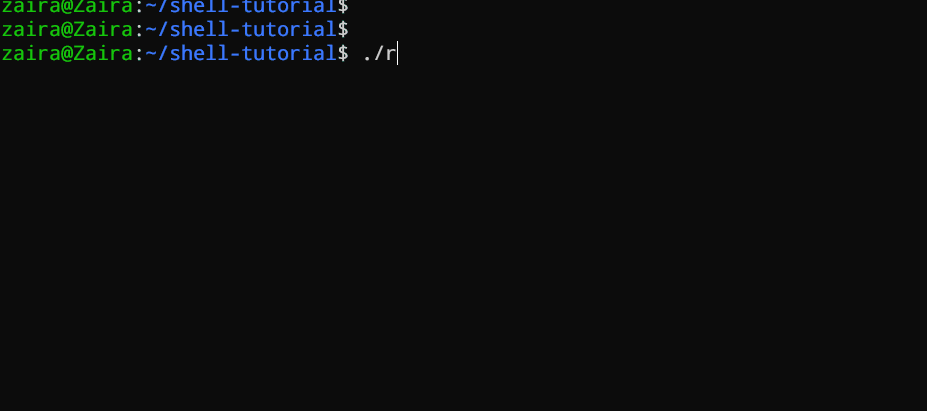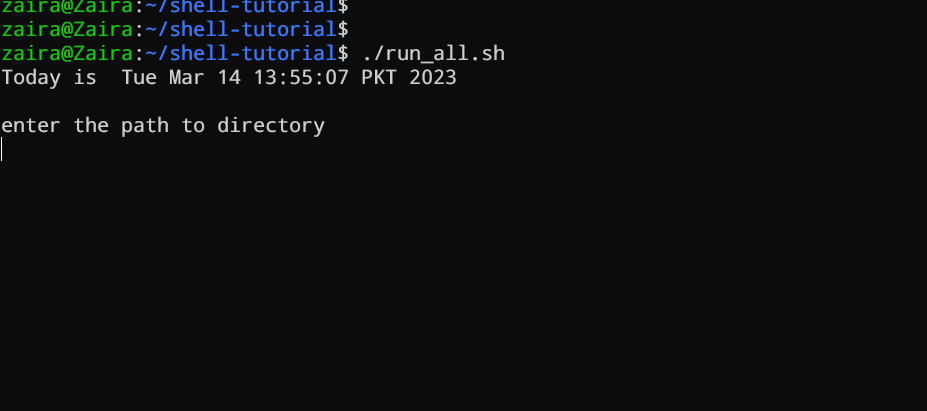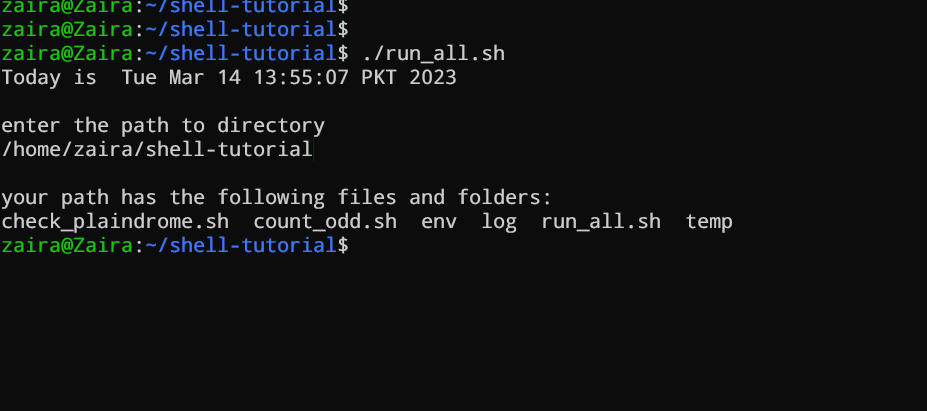
Vamos a verlo en acción 🚀
6.5. Basicos de Escritura de Scripts en Bash
Comentarios en la escritura de scripts Bash
Los comentarios en la escritura de scripts Bash comienzan con un #. Esto significa que cualquier línea que comience con un # es un comentario y será ignorado por el intérprete.
Los comentarios son muy útiles para documentar el código, y es una buena práctica agregarlos para ayudar a otros a entender el código.
Estos son ejemplos de comentarios:
# Este es un comentario de ejemplo
# Ambas líneas serán ignoradas por el intérprete
Variables y tipos de datos en Bash
Las variables te permiten almacenar datos. Puedes usar variables para leer, acceder y manipular datos a lo largo de tu script.
No hay tipos de datos en Bash. En Bash, una variable es capaz de almacenar valores numéricos, caracteres individuales o cadenas de caracteres.
- En Bash, puedes usar y establecer los valores de las variables de la siguiente manera:
country=Netherlands
Asignar el valor directamente:
same_country=$country
2. Asignar el valor basado en la salida obtenida de un programa o comando, utilizando sustitución de comando. Note que $ es necesario para acceder al valor de una variable existente.
Esto asigna el valor de country a la nueva variable same_country.
country=Netherlands
echo $country
Para acceder al valor de la variable, añade $ al nombre de la variable.
Netherlands
new_country=$country
echo $new_country
# output
Netherlands
# output
Arriba, puede ver un ejemplo de asignación y impresión de valores de variables.
Convenciones de nombres de variables
- En la scripting Bash, las siguientes son las convenciones de nombres de variables:
- Los nombres de variables deben comenzar con una letra o un guión bajo (
_). - Los nombres de variables pueden contener letras, números y guiones bajos (
_). - Los nombres de variables son sensibles a mayúsculas y minúsculas.
- Los nombres de variables no deben contener espacios o caracteres especiales.
- Use nombres descriptivos que reflejen el propósito de la variable.
Evite usar palabras clave reservadas, como if, then, else, fi, y demás como nombres de variables.
name
count
_var
myVar
MY_VAR
Aquí hay algunos ejemplos de nombres de variables válidas en Bash:
Y aquí hay algunos ejemplos de nombres de variables no válidos:
2ndvar (variable name starts with a number)
my var (variable name contains a space)
my-var (variable name contains a hyphen)
# nombres de variables inválidos
Siguiendo estas convenciones de nombres ayuda a que los scripts de Bash sean más legibles y más fáciles de mantener.
Entrada y salida en los scripts de Bash
Recolección de entrada
- En esta sección, vamos a discutir algunos métodos para proporcionar entrada a nuestros scripts.
Leer la entrada del usuario y almacenarla en una variable
#!/bin/bash
echo "What's your name?"
read entered_name
echo -e "\nWelcome to bash tutorial" $entered_name
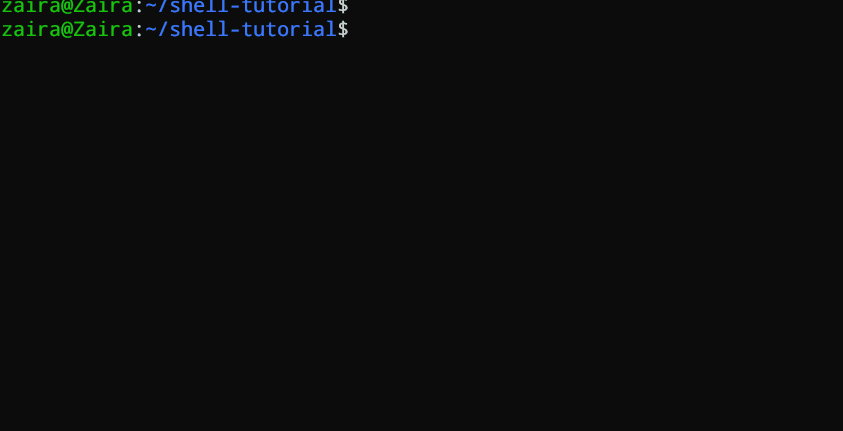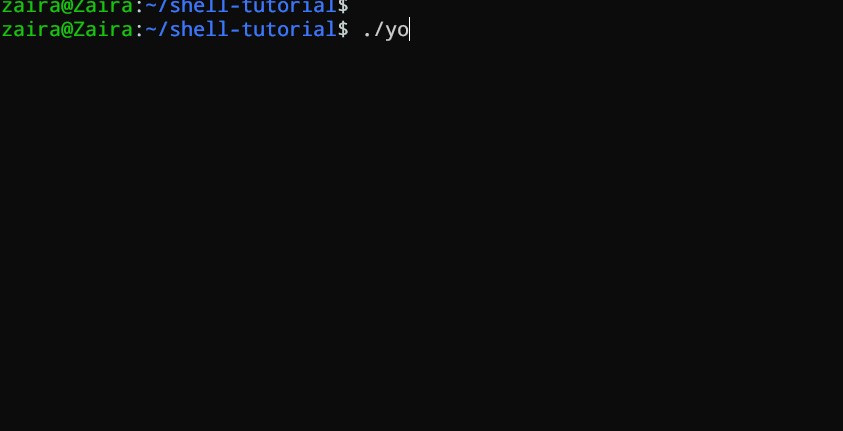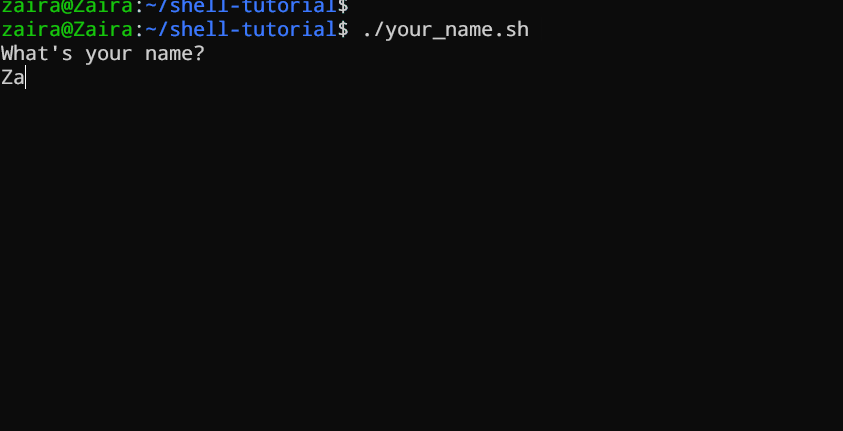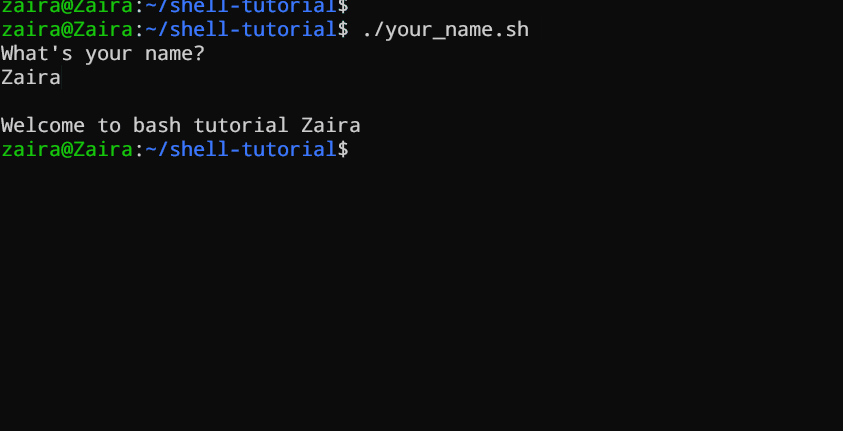
Podemos leer la entrada del usuario utilizando el comando read.
2. Leer de un archivo
while read line
do
echo $line
done < input.txt
Este código lee cada línea de un archivo llamado input.txt y la imprime en la terminal. Más adelante en esta sección estudiaremos los bucles while.
3. Argumentos de la línea de comandos
En un script de Bash o función, $1 denota el argumento inicial pasado, $2 denota el segundo argumento pasado, y así sucesivamente.
#!/bin/bash
echo "Hello, $1!"
Este script toma un nombre como argumento de la línea de comandos y imprime un saludo personalizado.
Hemos proporcionado Zaira como nuestro argumento al script.
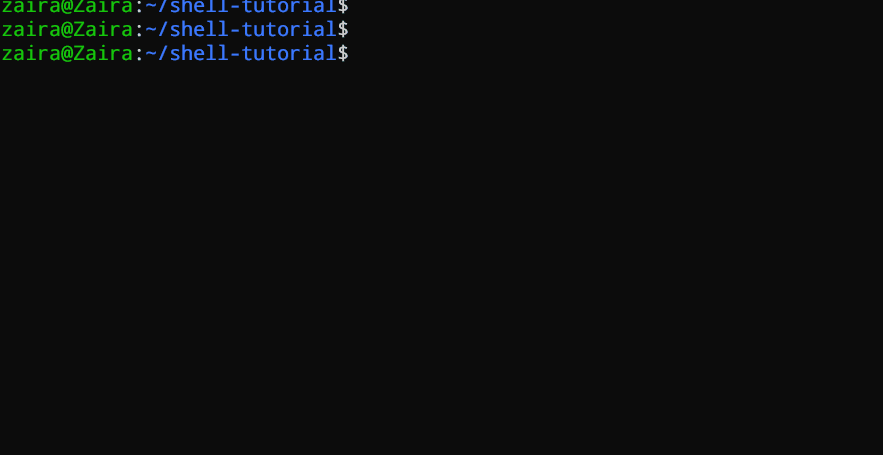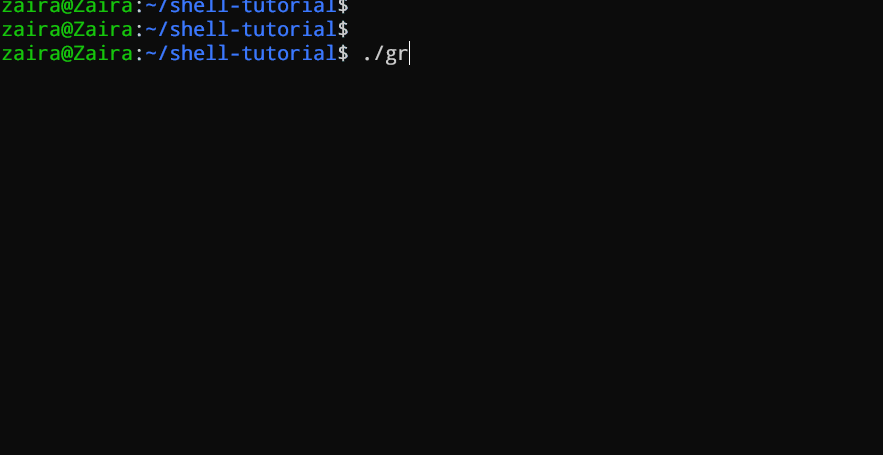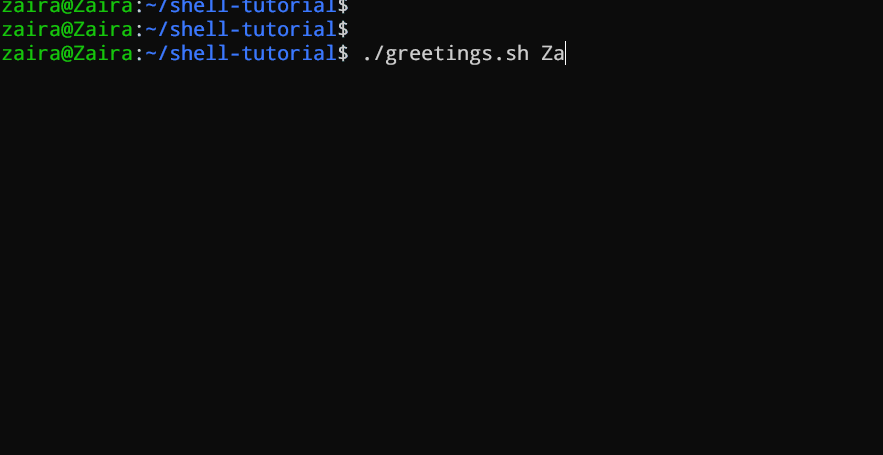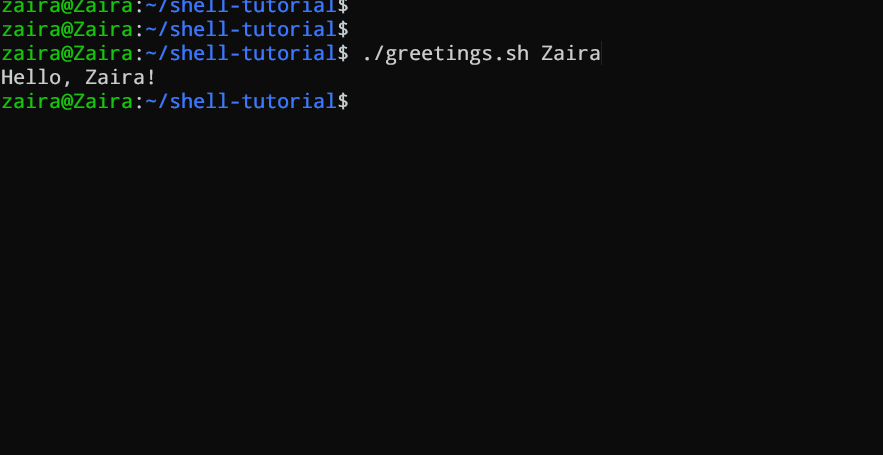
Salida:
Presentación de la salida
- Aquí vamos a discutir algunos métodos para recibir la salida de los scripts.
echo "Hello, World!"
Imprimir en la terminal:
Esto imprime el texto “¡Hola, Mundo!” en la terminal.
echo "This is some text." > output.txt
2. Escribir en un archivo:
Esto escribe el texto “Este es algo de texto.” en un archivo llamado output.txt. Tenga en cuenta que el operador > sobreescribe un archivo si ya tiene contenido.
echo "More text." >> output.txt
3. Añadir a un archivo:
Este añade el texto “Más texto.” al final del archivo output.txt.
ls > files.txt
4. Redirección de salida:
Este lista los archivos del directorio actual y escribe la salida en un archivo llamado files.txt. Puede redirigir la salida de cualquier comando a un archivo de esta manera.
Aprenderá sobre la redirección de salida en detalle en la sección 8.5.
Decisiones condicionales (if/else)
Las expresiones que producen un resultado booleano, ya sea verdadero o falso, se llaman condiciones. Hay varias maneras de evaluar condiciones, incluyendo if, if-else, if-elif-else, y condicionales anidados.
if [[ condition ]];
then
statement
elif [[ condition ]]; then
statement
else
do this by default
fi
Sintaxis:
Sintaxis de las declaraciones condicionales de bash
if [ $a -gt 60 -a $b -lt 100 ]
Puede usar operadores lógicos como Y -a y O -o para hacer comparaciones que tienen más significado.
Esta sentencia verifica si ambas condiciones son true: a es mayor que 60 Y b es menor que 100.
#!/bin/bash
Veamos un ejemplo de un script Bash que utiliza las declaraciones if, if-else, y if-elif-else para determinar si un número ingresado por el usuario es positivo, negativo o cero:
echo "Please enter a number: "
read num
if [ $num -gt 0 ]; then
echo "$num is positive"
elif [ $num -lt 0 ]; then
echo "$num is negative"
else
echo "$num is zero"
fi
# Script para determinar si un número es positivo, negativo o cero
El script primero pide al usuario que introduzca un número. A continuación, utiliza una estructura if para verificar si el número es mayor que 0. Si lo es, el script muestra que el número es positivo. Si el número no es mayor que 0, el script pasa a la siguiente declaración, que es una estructura if-elif.
Aquí, el script comprueba si el número es menor que 0. Si lo es, el script muestra que el número es negativo.
Finalmente, si el número no es ni mayor que 0 ni menor que 0, el script utiliza una estructura else para mostrar que el número es cero.
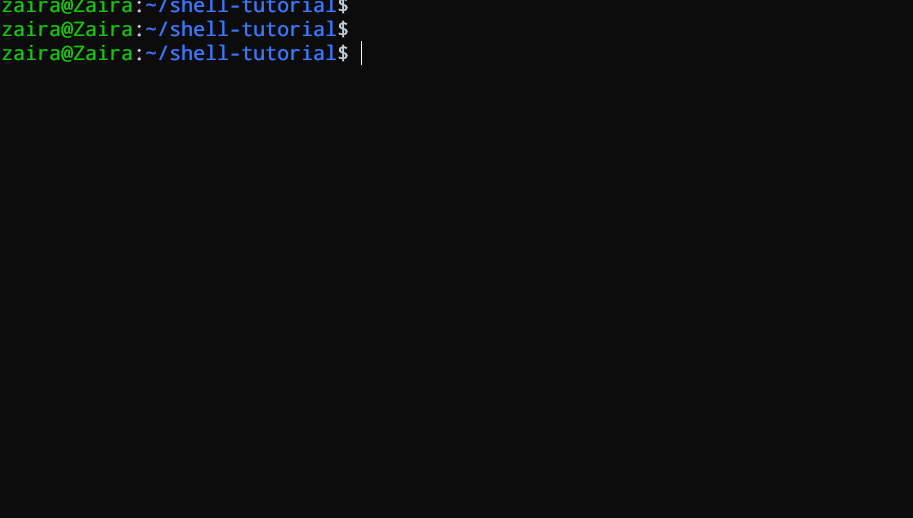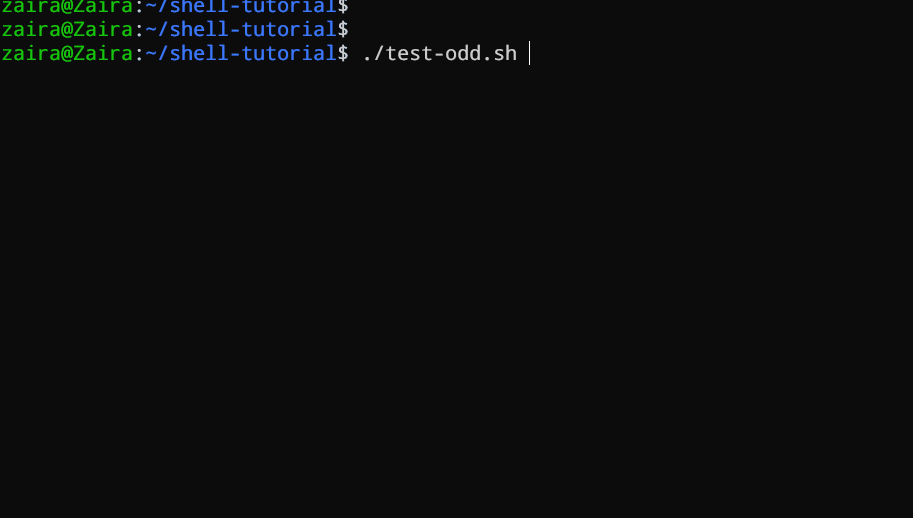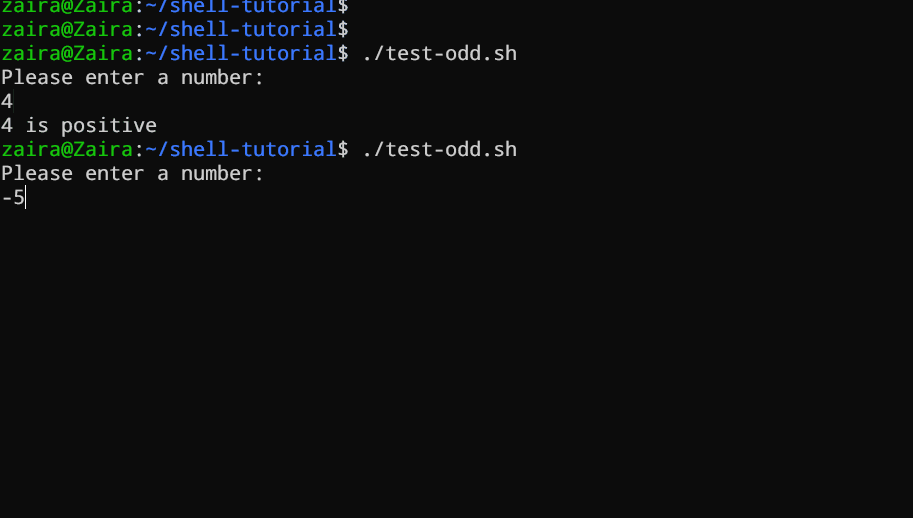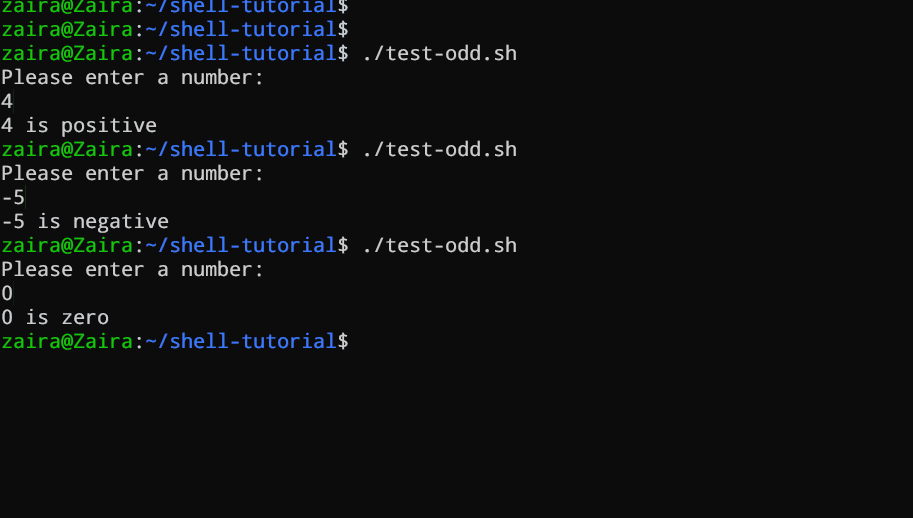
Veándolo en acción 🚀
Bucle y ramificación en Bash
Bucle while
Los bucles while revisan una condición y se repiten hasta que la condición sigue siendo true. Necesitamos proporcionar una declaración de contador que incrementa el contador para controlar la ejecución del bucle.
#!/bin/bash
i=1
while [[ $i -le 10 ]] ; do
echo "$i"
(( i += 1 ))
done
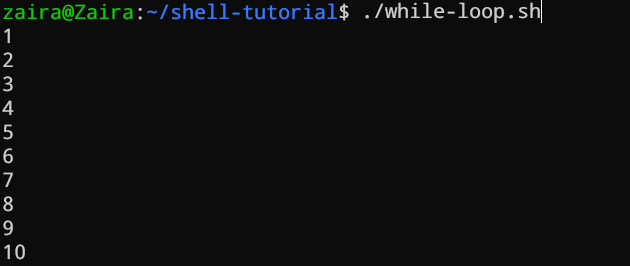
En el ejemplo de abajo, (( i += 1 )) es la declaración de contador que incrementa el valor de i. El bucle se ejecutará exactamente 10 veces.
Bucle for
El bucle for, al igual que el bucle while, le permite ejecutar declaraciones un determinado número de veces. Cada bucle difiere en su sintaxis y uso.
#!/bin/bash
for i in {1..5}
do
echo $i
done

En el ejemplo de abajo, el bucle iterará 5 veces.
Declaraciones case
case expression in
pattern1)
En Bash, las estructuras switch (o casos) se utilizan para comparar un valor dado contra una lista de patrones y ejecutar un bloque de código basado en el primer patrón que se ajuste. La sintaxis para una estructura switch en Bash es la siguiente:
;;
pattern2)
# ejecutar código si la expresión coincide con pattern1
;;
pattern3)
# ejecutar código si la expresión coincide con pattern2
;;
*)
# ejecutar código si la expresión coincide con pattern3
;;
esac
# ejecutar código si ninguno de los patrones anteriores coincide con la expresión
Aquí, “expresión” es el valor que queremos comparar, y “pattern1”, “pattern2”, “pattern3” y demás son los patrones con los que queremos compararlo.
El doble signo de punto y coma “;;” separa cada bloque de código que se debe ejecutar para cada patrón. El asterisco “*” representa el caso por defecto, que se ejecuta si ninguno de los patrones especificados coincide con la expresión.
fruit="apple"
case $fruit in
"apple")
echo "This is a red fruit."
;;
"banana")
echo "This is a yellow fruit."
;;
"orange")
echo "This is an orange fruit."
;;
*)
echo "Unknown fruit."
;;
esac
Veamos un ejemplo:
En este ejemplo, ya que el valor de fruit es apple, el primer patrón coincide, y se ejecuta el bloque de código que imprime This is a red fruit.. Si el valor de fruit hubiera sido en su lugar banana, el segundo patrón habría coincidido y se habría ejecutado el bloque de código que imprime This is a yellow fruit., y así sucesivamente.
Si el valor de fruit no coincide con ninguno de los patrones especificados, se ejecuta el caso por defecto, que imprime Unknown fruit.
Parte 7: Gestionar paquetes de software en Linux.
Linux viene con varios programas integrados. Sin embargo, puede que necesite instalar nuevos programas según sus necesidades. También podría necesitar actualizar las aplicaciones existentes.
7.1. Paquetes y Gestión de Paquetes
¿Qué es un paquete?
Un paquete es una colección de archivos que se envuelven juntos. Estos archivos son esenciales para que un programa pueda ejecutarse. Estos archivos contienen los archivos ejecutables del programa, bibliotecas y otras recursos.
Además de los archivos necesarios para que el programa ejecute, los paquetes también contienen scripts de instalación, que copian los archivos donde son necesarios. Un programa puede contener muchos archivos y dependencias. Con los paquetes, es más fácil manejar todos los archivos y dependencias al mismo tiempo.
¿Qué diferencia hay entre fuente y binario?
Los programadores escriben el código fuente en un lenguaje de programación. Este código fuente luego se compila en código máquina que el ordenador puede entender. El código compilado se denomina código binario.
Cuando descargas un paquete, puedes obtener la código fuente o el código binario. El código fuente es el código legible por humanos que se puede compilar en código binario. El código binario es el código compilado que el ordenador puede entender.
Los paquetes de fuente se pueden usar con cualquier tipo de máquina si el código fuente se compila correctamente. Por otro lado, el binario es el código compilado específico para un tipo particular de máquina o arquitectura.
uname -m
Puede encontrar la arquitectura de su máquina utilizando el comando uname -m.
x86_64
# output
Dependencias del paquete
Los programas a menudo comparten archivos. En lugar de incluir estos archivos en cada paquete, un paquete separado puede proporcionarlos para todos los programas.
Para instalar un programa que necesita estos archivos, debes también instalar el paquete que los contiene. Esto se denomina una dependencia de paquete. Especificar dependencias hace que los paquetes sean más pequeños y más simples reduciendo las duplicidades.
Cuando instales un programa, sus dependencias también deben instalarse. La mayoría de las dependencias requeridas usualmente ya están instaladas, pero quizás se necesiten unas pocas extra. Así que, no te sorprenda si varios otros paquetes se instalan junto con tu paquete elegido. Estos son las dependencias necesarias.
Gestores de paquetes
Linux ofrece un sistema integral de gestión de paquetes para instalar, actualizar, configurar y eliminar software.
Con la gestión de paquetes, puedes tener acceso a una base organizada de miles de paquetes de software junto con la capacidad para resolver dependencias y buscar actualizaciones de software.
Los paquetes se pueden administrar utilizando utilidades de línea de comandos que pueden ser fácilmente automatizadas por administradores de sistemas o a través de una interfaz gráfica.
Canales de software/repositorios
⚠️ La gestión de paquetes es diferente para diferentes distribuciones. Aquí, utilizamos Ubuntu.
La instalación de software es un poco diferente en Linux en comparación con Windows y Mac.
Linux utiliza repositorios para almacenar paquetes de software. Un repositorio es una colección de paquetes de software disponibles para la instalación a través de un gestor de paquetes.
Un gestor de paquetes también almacena un índice de todos los paquetes disponibles en un repositorio. A veces se reconstruye el índice para asegurarse de que esté actualizado y para saber qué paquetes se han actualizado o añadido al canal desde la última vez que se comprobó.
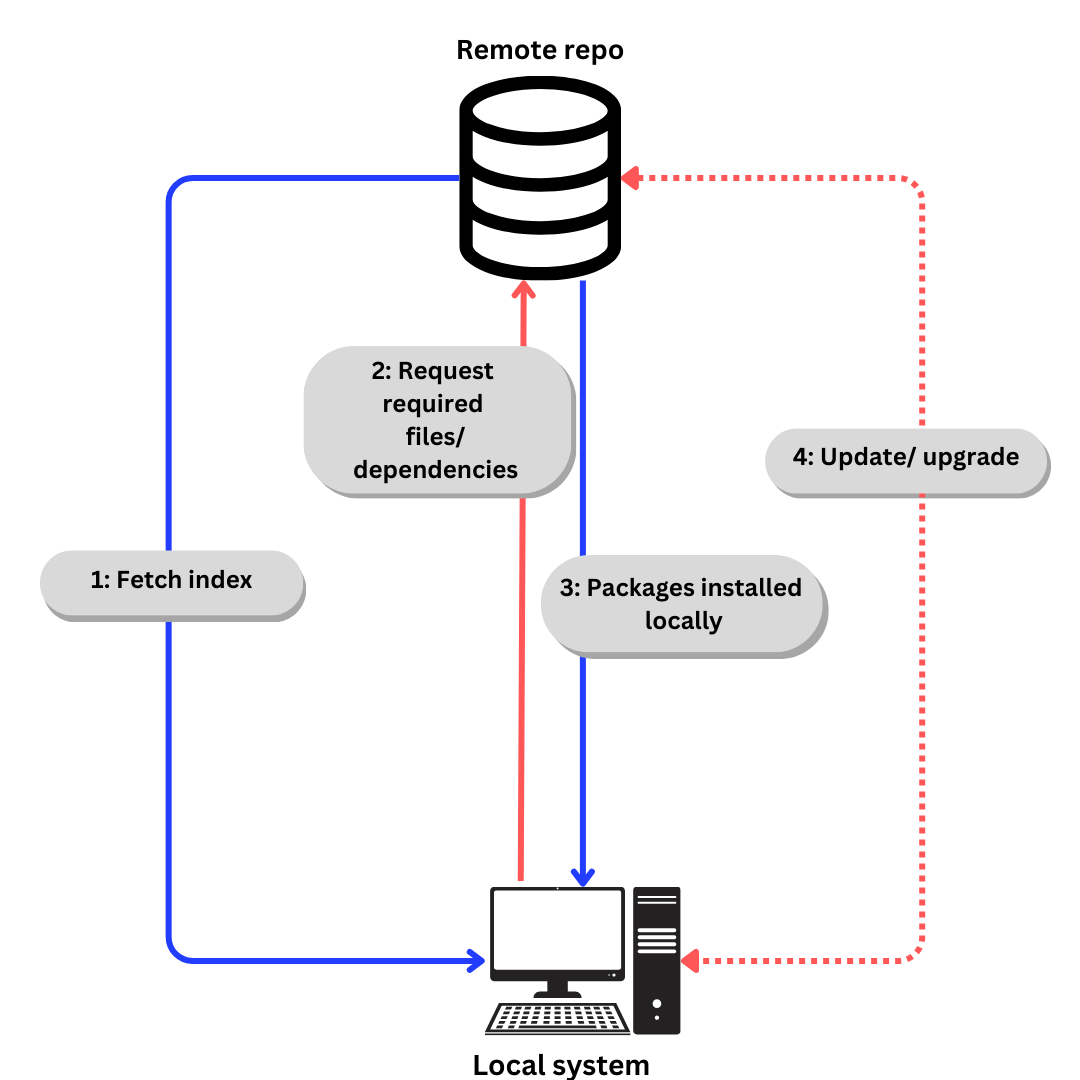
El proceso genérico de descargar software de un repositorio se parece a esto:
- Si hablamos específicamente de Ubuntu,
- Se recupera el índice utilizando
apt update.(aptse explica en la sección siguiente). - Se solicitan los archivos/dependencias necesarias según el índice utilizando
apt install - Paquetes y dependencias instalados localmente.
Actualizar dependencias y paquetes cuando sea necesario utilizando apt update y apt upgrade
En las distros basadas en Debian, puede archivar la lista de repositorios (repositorios) en /etc/apt/sources.list.
7.2. Instalar un Paquete mediante la Línea de Comandos
La orden apt es una herramienta de línea de comandos potente, que trabaja con la herramienta de empaques avanzados de Ubuntu (APT).
apt, junto con los comandos incluidos con él, proporciona las herramientas para instalar nuevos paquetes de software, actualizar paquetes de software existentes, actualizar el índice de lista de paquetes y incluso actualizar todo el sistema Ubuntu.
Para ver los registros de la instalación utilizando apt, se puede ver el archivo /var/log/dpkg.log.
A continuación están los usos del comando apt:
Instalar paquetes
sudo apt install htop
Por ejemplo, para instalar el paquete htop, se puede usar el siguiente comando:
Actualizar el índice de lista de paquetes
sudo apt update
El índice de lista de paquetes es una lista de todos los paquetes disponibles en los repositorios. Para actualizar el índice de lista de paquetes local, se puede usar el siguiente comando:
Actualizar los paquetes
Los paquetes instalados en su sistema pueden obtener actualizaciones que contienen correcciones de errores, parches de seguridad y nuevas características.
sudo apt upgrade
Para actualizar los paquetes, se puede usar el siguiente comando:
Eliminar paquetes
sudo apt remove htop
Para eliminar un paquete, como htop, se puede usar el siguiente comando:
7.3. Instalar un Paquete mediante un Método Avanzado Gráfico – Synaptic
Si no está cómodo con la línea de comandos, puede usar una aplicación GUI para instalar paquetes. Puede obtener los mismos resultados que la línea de comandos, pero con una interfaz gráfica.
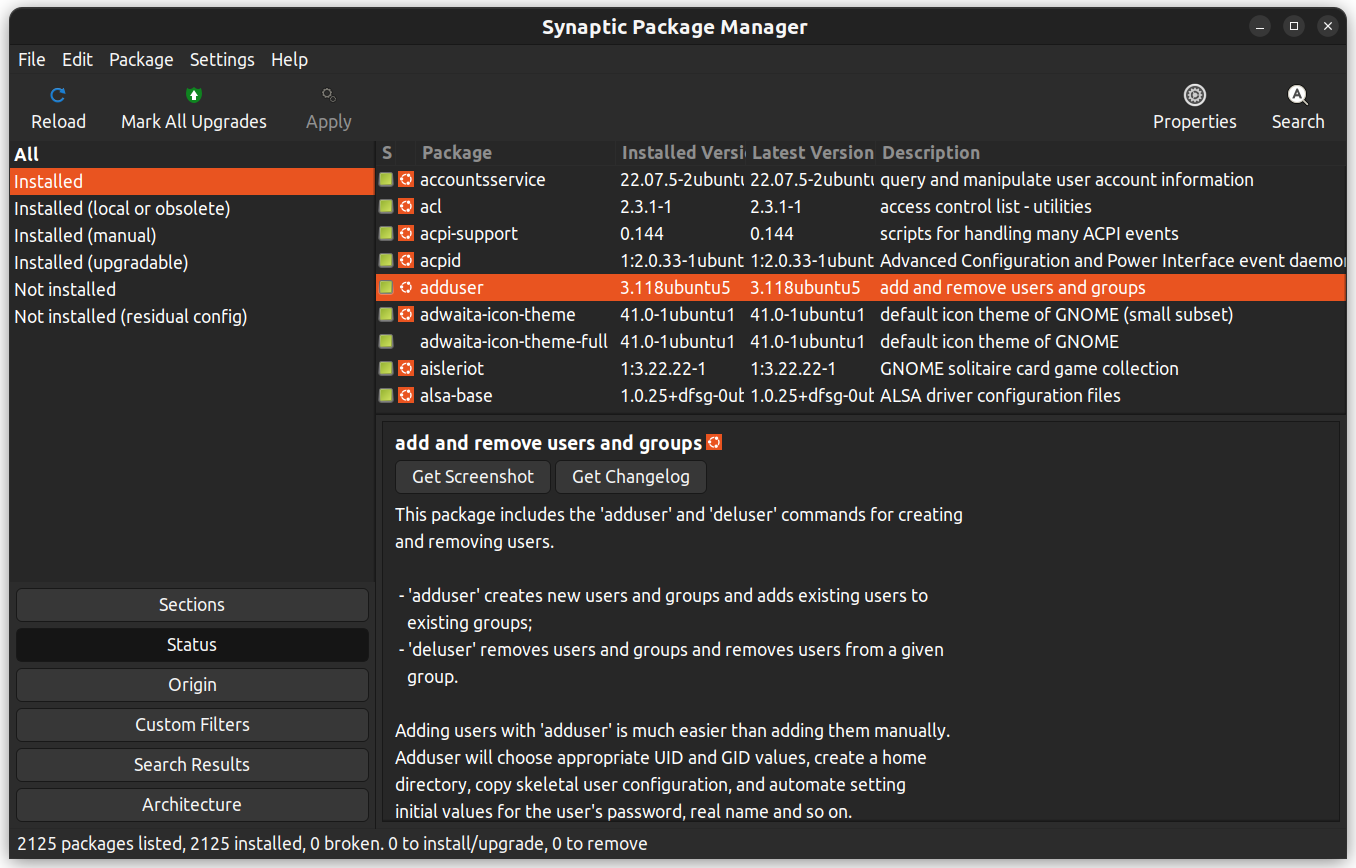
Synaptic es una aplicación de gestión de paquetes GUI que ayuda en la lista de paquetes instalados, su estado, actualizaciones pendientes y demás. Ofrece filtros personalizados para ayudar a reducir los resultados de la búsqueda.
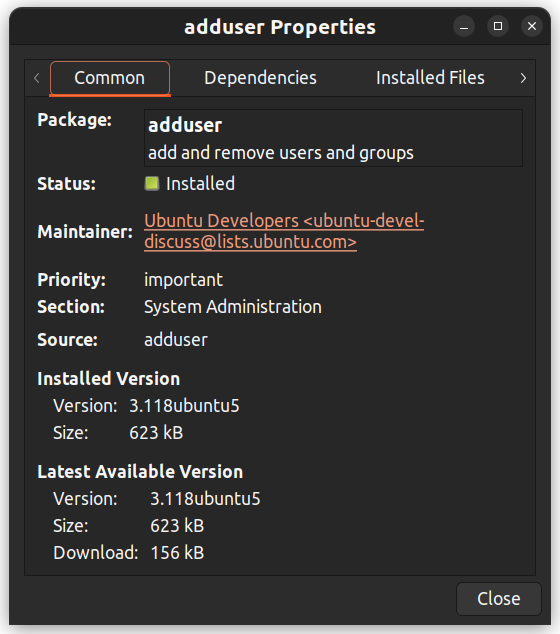
También puede hacer clic derecho en un paquete y ver detalles adicionales, como las dependencias, el mantenedor, el tamaño y los archivos instalados.
7.4. Instalar paquetes descargados de un sitio web
Puede que desee instalar un paquete que ha descargado de un sitio web, en lugar de de un repositorio de software. Estos paquetes se llaman archivos .deb.
cd directory
sudo dpkg -i package_name.deb
Usandodpkgpara instalar paquetes:dpkg es una herramienta de línea de comandos que se utiliza para instalar paquetes. Para instalar un paquete con dpkg, abra el Terminal y escriba lo siguiente:
Nota: Reemplace “directorio” con el directorio donde se almacena el paquete y “nombre_paquete” con el nombre de archivo del paquete.
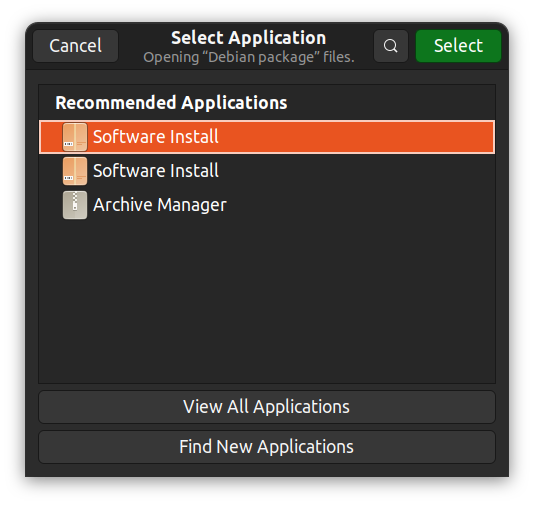
Alternativamente, puede hacer clic derecho, seleccionar “Abrir con Otra Aplicación” y elegir una aplicación de interfaz gráfica de su elección.
💡 Consejo: En Ubuntu, puede ver una lista de paquetes instalados con dpkg --list.
Parte 8: Temas Avanzados de Linux
8.1. Gestión de Usuarios
Pueden haber varios usuarios con diferentes niveles de acceso en un sistema. En Linux, el usuario root tiene el nivel más alto de acceso y puede realizar cualquier operación en el sistema. Los usuarios regulares tienen acceso limitado y solo pueden realizar operaciones para las que han sido concedida la permiso.
¿Qué es un usuario?
una cuenta de usuario proporciona separación entre diferentes personas y programas que pueden ejecutar comandos.
Los seres humanos identifican a los usuarios por un nombre, ya que los nombres son fáciles de trabajar con. Pero el sistema identifica a los usuarios mediante un número único llamado el ID de usuario (UID).
Cuando los usuarios humanos inician sesión usando el nombre de usuario proporcionado, deben utilizar una contraseña para autorizarse.
Las cuentas de usuario forman las bases de la seguridad del sistema. La propiedad de los archivos también se asocia con las cuentas de usuario y esto impone controles de acceso a los archivos. Cada proceso tiene una cuenta de usuario asociada que proporciona un nivel de control para los administradores.
- Hay tres tipos de cuentas de usuario principales:
- Superusuario: El superusuario tiene acceso completo al sistema. El nombre del superusuario es
root. Tiene unUIDde 0. - Usuario del sistema: El usuario del sistema tiene cuentas de usuario que se utilizan para ejecutar servicios del sistema. Estas cuentas se utilizan para ejecutar servicios del sistema y no están destinadas a la interacción humana.
Usuario regular: Los usuarios regulares son usuarios humanos que tienen acceso al sistema.
id
uid=1000(john) gid=1000(john) groups=1000(john),4(adm),24(cdrom),27(sudo),30(dip)... output truncated
La orden id muestra la identificación del usuario y el identificador de grupo del usuario actual.
id username
Para ver la información básica de otro usuario, pasar el nombre de usuario como argumento a la orden id.
ps -u
Para ver información relacionada con los usuarios de los procesos, use el comando ps con la bandera -u.
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
root 1 0.0 0.1 16968 3920 ? Ss 18:45 0:00 /sbin/init splash
root 2 0.0 0.0 0 0 ? S 18:45 0:00 [kthreadd]
# Salida
Por defecto, los sistemas utilizan el archivo /etc/passwd para almacenar información de los usuarios.
root:x:0:0:root:/root:/bin/bash
Aquí hay una línea del archivo /etc/passwd:
- El archivo
/etc/passwdcontiene la siguiente información sobre cada usuario: - Nombre de usuario:
root– El nombre de usuario de la cuenta de usuario. - Contraseña:
x– La contraseña del usuario en formato cifrado que se almacena en el archivo/etc/shadowpor motivos de seguridad. - ID de usuario (UID):
0– El identificador numérico único para la cuenta de usuario. - ID de grupo (GID):
0– El identificador primario del grupo para la cuenta de usuario. - Información del usuario:
root– El nombre real de la cuenta de usuario. - Directorio de inicio:
/root– El directorio de inicio de la cuenta de usuario.
Shell: /bin/bash – La shell predeterminada para la cuenta de usuario. Un usuario del sistema podría utilizar /sbin/nologin si no se permite el inicio interactivo para ese usuario.
¿Qué es un grupo?
Un grupo es una colección de cuentas de usuario que comparten acceso y recursos. Los grupos tienen nombres de grupo para identificarlos. El sistema identifica los grupos con un número único llamado el ID de grupo (GID).
Por defecto, la información sobre los grupos se almacena en el archivo /etc/group.
adm:x:4:syslog,john
Aquí está una entrada del archivo /etc/group:
- Aquí está la descomposición de los campos en la entrada dada:
- Nombre de grupo:
adm– El nombre del grupo. - Contraseña:
x– La contraseña del grupo se almacena en el archivo/etc/gshadowpor motivos de seguridad. La contraseña es opcional y aparece vacía si no se establece. - ID de grupo (GID):
4– Identificador numérico único para el grupo.
Miembros del grupo: syslog,john – Lista de nombres de usuario que son miembros del grupo. En este caso, el grupo adm tiene dos miembros: syslog y john.
En esta entrada específica, el nombre del grupo es adm, el ID de grupo es 4, y el grupo tiene dos miembros: syslog y john. El campo de contraseña se configura generalmente a x para indicar que la contraseña del grupo se almacena en el archivo /etc/gshadow.
- Los grupos se dividen además en ‘grupos primarios‘ y ‘grupos complementarios‘.
- Grupo primario: Cada usuario se asigna automáticamente un grupo primario. Este grupo generalmente tiene el mismo nombre que el usuario y se crea cuando se crea la cuenta de usuario. Los archivos y directorios creados por el usuario normalmente pertenecen a este grupo primario.
Grupos complementarios: Estos son grupos adicionales a los que un usuario puede pertenecer además de su grupo principal. Los usuarios pueden ser miembros de varios grupos complementarios. Estos grupos permiten a un usuario tener permisos para recursos compartidos entre esos grupos. Ayudan a proporcionar acceso a recursos compartidos sin afectar las permisos de archivo del sistema y manteniendo la seguridad intacta. Si bien un usuario debe pertenecer a un solo grupo principal, pertenecer a grupos complementarios es opcional.
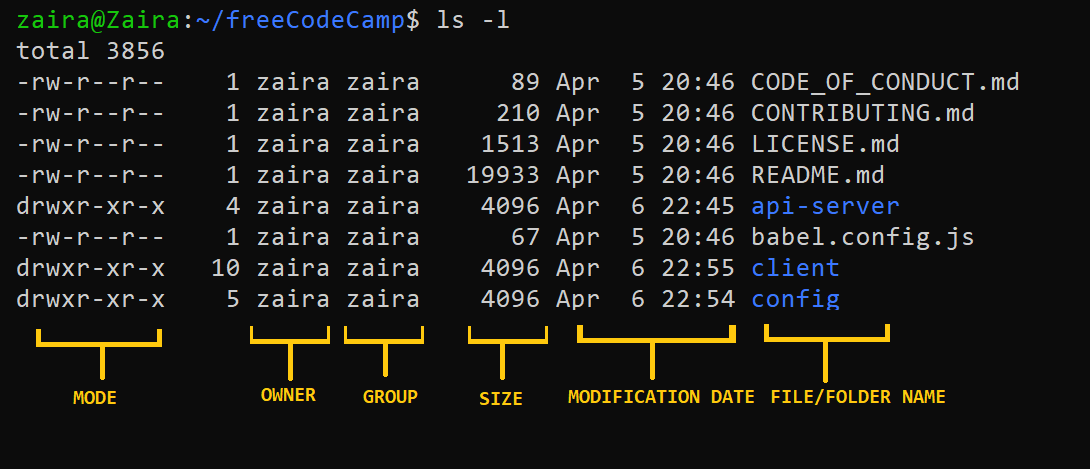
Control de acceso: encontrar y entender permisos de archivo
La propiedad de los archivos se puede ver usando la orden ls -l. La primera columna en la salida de la orden ls -l muestra los permisos del archivo. Otras columnas muestran el propietario del archivo y el grupo al que pertenece el archivo.

Vamos a echar un vistazo más de cerca a la columna mode:
- Modo define dos cosas:
- Tipo de archivo: El tipo de archivo define el tipo del archivo. Para archivos normales que contienen datos sencillos está en blanco
-. Para otros tipos de archivos especiales el símbolo es diferente. Para un directorio, que es un archivo especial, esd. Los archivos especiales son tratados de forma diferente por el SO.
Clases de permisos: El conjunto de caracteres siguiente define los permisos para usuario, grupo y otros respectivamente.
– Usuario: Este es el dueño de un archivo y el dueño del archivo pertenece a esta clase.
– Grupo: Los miembros del grupo del archivo pertenecen a esta clase
– Otros: Cualquier usuario que no pertenezca a las clases de usuario o grupo pertenece a esta clase.
💡Consejo: La propiedad del directorio puede verse usando el comando ls -ld.
Cómo leer permisos simbólicos o los permisos rwx
- La representación
rwxse conoce como la representación simbólica de permisos. En el conjunto de permisos, - lectura. Se indica en el primer carácter de la tríada.
wrepresenta escritura. Se indica en el segundo carácter de la tríada.
x代表ejecución。它在三位数的第三个字符中指示。
Lectura:
Para archivos regulares, los permisos de lectura permiten abrir y leer solo el archivo. Los usuarios no pueden modificar el archivo.
De forma similar, para directorios, los permisos de lectura permiten enumerar el contenido del directorio sin modificar el directorio.
Escritura:
Cuando los archivos tienen permisos de escritura, el usuario puede modificar (editar, eliminar) el archivo y guardarlo.
Para carpetas, los permisos de escritura permiten a un usuario modificar su contenido (crear, eliminar y renombrar los archivos dentro de ella), y modificar el contenido de los archivos en los que el usuario tenga permisos de escritura.
Ejemplos de permisos en Linux
- Ahora que sabemos cómo leer permisos, vamos a ver algunos ejemplos.
-
-rw-rw-r--: Un archivo que puede ser modificado por su propietario y el grupo, pero no por otros.
drwxrwx---: Un directorio que puede ser modificado por su propietario y el grupo.
Ejecutar:
Para archivos, las permisos de ejecución permiten a los usuarios ejecutar un script ejecutable. Para directorios, el usuario puede acceder y ver detalles sobre los archivos en el directorio.
Cómo cambiar permisos y propietario de archivos en Linux usando chmod y chown
Ahora que sabemos los conceptos básicos de propietarios y permisos, vamos a ver cómo podemos modificar los permisos usando el comando chmod.
chmod permissions filename
Sintaxis dechmod:
- Donde,
permisospueden ser de lectura, escritura, ejecución o una combinación de ellos.
nombre_archivo es el nombre del archivo para el cual se necesitan cambiar los permisos. Este parámetro también puede ser una lista de archivos si se van a cambiar permisos en lote.
- Podemos cambiar los permisos usando dos modos:
- Modo simbólico: Este método utiliza símbolos como
u,g,opara representar al usuario, grupo y otros. Los permisos se representan conr, w, xpara leer, escribir y ejecutar, respectivamente. Puedes modificar los permisos usando +, – y =.
Modo absoluto: Este método representa los permisos como números octales de tres dígitos que van de 0-7.
Ahora, veamoslos en detalle.
Cómo cambiar permisos usando el modo simbólico
| La siguiente tabla resume la representación del usuario: | REPRESENTACIÓN DE USUARIO |
| u | DESCRIPCIÓN |
| g | usuario/propietario |
| o | grupo |
otros
| Podemos usar operadores matemáticos para agregar, quitar y asignar permisos. La siguiente tabla muestra el resumen: | OPERADOR |
| DESCRIPCIÓN | + |
| Agrega un permiso a un archivo o directorio | – |
| Quita el permiso | \= |
Establece el permiso si no está presente antes. También sobrescribe los permisos si se establecieron anteriormente.
Ejemplo:
Supongamos que tengo un script y quiero hacerlo ejecutable para el propietario del archivo zaira.

Los permisos actuales del archivo son los siguientes:
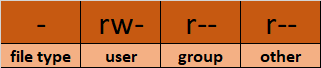
Dividamos los permisos de esta manera:
chmod u+x mymotd.sh
Para agregar derechos de ejecución (x) al propietario (u) usando el modo simbólico, podemos usar el siguiente comando:
Salida:
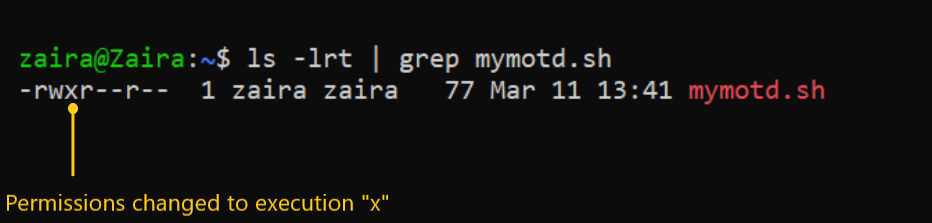
Ahora, podemos ver que los permisos de ejecución se han agregado para el propietario zaira.
- Ejemplos adicionales para cambiar permisos mediante el método simbólico:
- Eliminar permiso de
lecturayescrituraparagrupoyotros:chmod go-rw. - Eliminar permisos de
lecturaparaotros:chmod o-r.
Asignar permiso de escritura a grupo y sobrescribir el permiso existente: chmod g=w.
Cómo cambiar permisos usando el modo absoluto
El modo absoluto utiliza números para representar permisos y operadores matemáticos para modificarlos.
| La tabla de abajo muestra cómo podemos asignar permisos relevantes: | PERMISO |
| PROPORCIONAR PERMISO | lectura |
| sumar 4 | escritura |
| sumar 2 | ejecución |
sumar 1
| Los permisos se pueden revocar mediante la resta. La tabla de abajo muestra cómo se pueden quitar permisos relevantes. | PERMISO |
| REVOCAR PERMISO | lectura |
| restar 4 | escritura |
| restar 2 | ejecución |
restar 1
- Ejemplo:
Establecer lectura (sumar 4) para usuario, lectura (sumar 4) y ejecución (sumar 1) para el grupo, y solo ejecución (sumar 1) para otros.
chmod 451 archivo-nombre
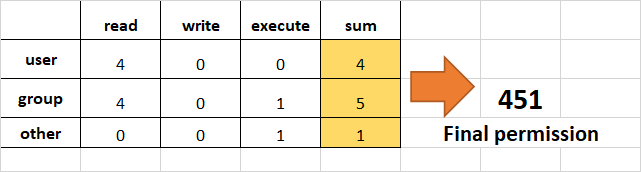
Así es cómo realizamos la calculadora:
- Nota que esto es lo mismo que
r--r-x--x.
Quitar derechos de ejecución a otros y grupo.
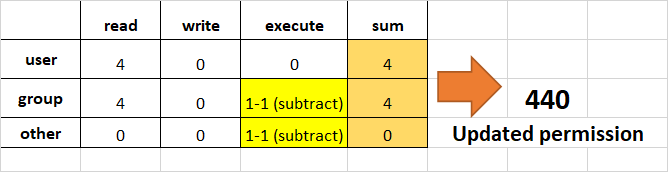
- Para quitar la ejecución de
otrosygrupo, reste 1 del apartado deejecuciónde los últimos dos bytes.
Asigne lectura, escritura y ejecución a usuario, lectura y ejecución a grupo y solo lectura a los demás.

Esto sería lo mismo que rwxr-xr--.
Cómo cambiar la propiedad del archivo usando el comando chown
Después, aprenderemos cómo cambiar la propiedad de un archivo. Puedes cambiar la propiedad de un archivo o carpeta usando el comando chown. En algunos casos, cambiar la propiedad debe tener permisos de sudo.
chown user filename
Sintaxis de chown:
Cómo cambiar la propiedad de usuario con chown
Vamos a transferir la propiedad del usuario zaira al usuario news.

chown news mymotd.sh
Comando para cambiar la propiedad: sudo chown news mymotd.sh.

Salida:
Cómo cambiar la propiedad de usuario y grupo simultáneamente
chown user:group filename
También podemos usar chown para cambiar el usuario y el grupo simultáneamente.
Cómo cambiar la propiedad de un directorio
chown -R admin /opt/script
Puedes cambiar la propiedad de forma recursiva para los contenidos en un directorio. El ejemplo de abajo cambia la propiedad del directorio /opt/script para permitir al usuario admin.
Cómo cambiar la propiedad de un grupo
chown :admins /opt/script
En caso de que solo necesitemos cambiar el dueño del grupo, podemos usar chown precediendo el nombre del grupo por un signo de dos puntos :
Cómo cambiar de usuario
[user01@host ~]$ su user02
Password:
[user02@host ~]$
Puedes cambiar de usuario usando el comando su.
Cómo obtener acceso de superusuario
El superusuario o el usuario root tiene el nivel máximo de acceso en un sistema Linux. El usuario root puede realizar cualquier operación en el sistema. El usuario root puede acceder a todos los archivos y directorios, instalar y eliminar software, y modificar o anular configuraciones del sistema.
Con gran poder viene gran responsabilidad. Si el usuario root es comprometido, alguien puede obtener control completo sobre el sistema. Se recomienda usar la cuenta de usuario root solo cuando sea necesario.
[user01@host ~]$ su
Password:
[root@host ~]Si omites el nombre de usuario, el comando su cambia por defecto a la cuenta de usuario root.
#
Otra variación del comando su es su -. El comando su cambia a la cuenta de usuario root pero no cambia las variables de entorno. El comando su - cambia a la cuenta de usuario root y cambia las variables de entorno a las del usuario de destino.
Ejecutar comandos con sudo
Para ejecutar comandos como el usuario root sin cambiar a la cuenta de usuario root, puedes usar el comando sudo. El comando sudo te permite ejecutar comandos con privilegios elevados.
Ejecutar comandos con sudo es una opción más segura que ejecutar comandos como el usuario root. Esto es así porque solo un conjunto específico de usuarios puede tener permiso para ejecutar comandos con sudo. Esto está definido en el archivo /etc/sudoers.
También, sudo registra todas las órdenes que se ejecutan con él, proporcionando una traza de auditoría de quién ejecutó qué órdenes y cuándo.
cat /var/log/auth.log | grep sudo
En Ubuntu, puede encontrar los registros de auditoría aquí:
user01 is not in the sudoers file. This incident will be reported.
Para un usuario que no tiene acceso a sudo, se marca en los registros y muestra un mensaje como este:
Gestionar cuentas de usuario locales
Crear usuarios desde la línea de comandos
sudo useradd username
La orden utilizada para agregar un nuevo usuario es:
Esta orden configura la carpeta personal del usuario y crea un grupo privado designado por el nombre de usuario del usuario. Actualmente, la cuenta carece de una contraseña válida, impidiendo que el usuario inicie sesión hasta que se cree una contraseña.
Modificar usuarios existentes
La orden usermod se utiliza para modificar usuarios existentes. Aquí están algunas de las opciones comunes utilizadas con la orden usermod:
- Aquí están algunos ejemplos de la orden
usermoden Linux: - Cambiar el nombre de inicio de un usuario:
- Cambiar el directorio de inicio de un usuario:
- Agregar un usuario a un grupo auxiliar:
- Cambiar la shell de un usuario:
- Bloquear la cuenta de un usuario:
- Desbloquear una cuenta de usuario:
- Establecer una fecha de expiración para una cuenta de usuario:
- Cambiar el ID de usuario (UID) de un usuario:
- Cambiar el grupo primario de un usuario:
Eliminar un usuario de un grupo secundario:
Eliminación de usuarios
- El comando
userdelse utiliza para eliminar una cuenta de usuario y archivos relacionados del sistema. sudo userdel username: elimina los detalles del usuario de/etc/passwdpero mantiene la carpeta personal del usuario.
El comando sudo userdel -r username elimina los detalles del usuario de /etc/passwd y además elimina la carpeta personal del usuario.
Cambio de contraseñas de usuario
- El comando
passwdse utiliza para cambiar la contraseña de un usuario.
sudo passwd username: establece la contraseña inicial o cambia la contraseña existente de username. También se utiliza para cambiar la contraseña del usuario actualmente conectado.
8.2 Conectando a Servidores remotos mediante SSH
Acceder a servidores remotos es una de las tareas esenciales para los administradores de sistemas. Puede conectarse a diferentes servidores o acceder a bases de datos a través de su máquina local y ejecutar comandos, todo usando SSH.
¿Qué es el protocolo SSH?
SSH es la sigla de Secure Shell. Es un protocolo de red criptográfico que permite la comunicación segura entre dos sistemas.
El puerto predeterminado para SSH es 22.
- Los dos participantes al comunicarse a través de SSH son:
- El servidor: la máquina a la que desea acceder.
El cliente: El sistema desde el que accede al servidor.
- La conexión a un servidor sigue estos pasos:
- Iniciar Conexión: El cliente envía una solicitud de conexión al servidor.
- Intercambio de Claves: El servidor envía su clave pública al cliente. Ambos acuerdan los métodos de encriptación a utilizar.
- Generación de Clave de Sesión: El cliente y el servidor utilizan el intercambio de claves Diffie-Hellman para crear una clave de sesión compartida.
- Autenticación del cliente: El cliente inicia sesión en el servidor mediante una contraseña, clave privada o otro método.
Comunicación segura: Después de la autenticación, el cliente y el servidor se comunican de forma segura mediante cifrado.
¿Cómo conectarse a un servidor remoto usando SSH?
El comando ssh es una utilidad integrada en Linux y también el predeterminado. Facilita el acceso a los servidores y es seguro.
Aquí estamos hablando de cómo el cliente establece una conexión con el servidor.
- Antes de conectarte a un servidor, necesitas tener la siguiente información:
- La dirección IP o el nombre de dominio del servidor.
- El nombre de usuario y la contraseña del servidor.
El número de puerto al que tienes acceso en el servidor.
ssh username@server_ip
La sintaxis básica del comando ssh es:
ssh [email protected]
Por ejemplo, si tu nombre de usuario es john y la IP del servidor es 192.168.1.10, el comando sería:
[email protected]'s password:
Welcome to Ubuntu 20.04.2 LTS (GNU/Linux 5.4.0-70-generic x86_64)
* Documentation: https://help.ubuntu.com
* Management: https://landscape.canonical.com
* Support: https://ubuntu.com/advantage
System information as of Fri Jun 5 10:17:32 UTC 2024
System load: 0.08 Processes: 122
Usage of /: 12.3% of 19.56GB Users logged in: 1
Memory usage: 53% IP address for eth0: 192.168.1.10
Swap usage: 0%
Last login: Fri Jun 5 09:34:56 2024 from 192.168.1.2
john@hostname:~$ Después de eso, se te pedirá que ingreses la contraseña secreta. Tu pantalla se verá similar a esto:
# inicio de entrada de comandos
Ahora puedes ejecutar los comandos relevantes en el servidor 192.168.1.10.
ssh -p port_number username@server_ip
⚠️ El puerto predeterminado para ssh es 22 pero también es vulnerable, ya que es probable que los hackers intenten aquí primero. Tu servidor puede exponer otro puerto y compartir el acceso contigo. Para conectarte a un puerto diferente, utiliza la bandera -p.
8.3. Análisis y análisis avanzados de registros
Los archivos de registro, cuando se configuran, son generados por tu sistema por una variedad de razones útiles. Pueden ser utilizados para rastrear eventos del sistema, monitorear el rendimiento del sistema y solucionar problemas. Son específicamente útiles para los administradores del sistema donde pueden rastrear errores de aplicación, eventos de red y actividad del usuario.
Este es un ejemplo de un archivo de registro:
2024-04-25 09:00:00 INFO Startup: Application starting
2024-04-25 09:01:00 INFO Config: Configuration loaded successfully
2024-04-25 09:02:00 DEBUG Database: Database connection established
2024-04-25 09:03:00 INFO User: New user registered (UserID: 1001)
2024-04-25 09:04:00 WARN Security: Attempted login with incorrect credentials (UserID: 1001)
2024-04-25 09:05:00 ERROR Network: Network timeout on request (ReqID: 456)
2024-04-25 09:06:00 INFO Email: Notification email sent (UserID: 1001)
2024-04-25 09:07:00 DEBUG API: API call with response time over threshold (Duration: 350ms)
2024-04-25 09:08:00 INFO Session: User session ended (UserID: 1001)
2024-04-25 09:09:00 INFO Shutdown: Application shutdown initiated
# archivo de registro de muestra
- Un archivo de registro usualmente contiene las siguientes columnas:
- Marca de tiempo: La fecha y hora en que ocurrió el evento.
- Nivel de registro: La gravedad del evento (INFO, DEBUG, WARN, ERROR).
- Componente: El componente del sistema que generó el evento (Inicio, Configuración, Base de datos, Usuario, Seguridad, Red, Correo electrónico, API, Sesión, Apagado).
- Mensaje: Una descripción del evento que ocurrió.
Información adicional: Información adicional relacionada con el evento.
En sistemas en tiempo real, los archivos de registro suelen ser miles de líneas de largo y se generan cada segundo. Pueden ser muy verbosos dependiendo de la configuración. Cada columna en un archivo de registro es una pieza de información que se puede usar para rastrear problemas. Esto hace que los archivos de registro sean difíciles de leer y comprender manualmente.
Este es donde entran las operaciones de parseo de registros. El parseo de registros es el proceso de extraer información útil de los archivos de registro. Involucra desglosar los archivos de registro en partes más pequeñas y manejables, y extraer la información relevante.
La información filtrada también puede ser útil para crear alertas, informes y paneles.
En esta sección, explorará algunas técnicas para el parseo de archivos de registro en Linux.
Extracción de texto usando grep
Grep es una utilidad integrada de bash. Significa “global regular expression print” (impresión de expresión regular global). Grep se utiliza para buscar cadenas en archivos.
- Aquí están algunos usos comunes de
grep: - Este comando busca “search_string” en el archivo nombrado
filename. - Este comando busca “
search_string” en todos los archivos dentro del directorio especificado y sus subdirectorios. - Este comando realiza una búsqueda no distingue mayúsculas de minúsculas para “search_string” en el archivo nombrado
filename. - Esta orden muestra los números de línea junto con las líneas coincidentes en el archivo llamado
filename. - Esta orden cuenta el número de líneas que contienen “search_string” en el archivo llamado
filename. - Este comando muestra todas las líneas que no contienen “search_string” en el archivo llamado
filename. - Este comando busca la palabra entera “word” en el archivo llamado
filename.
Este comando permite el uso de expresiones regulares extendidas para un mayor apoyo en la coincidencia de patrones complejos en el archivo llamado filename.
💡 Cualquier cosa: Si hay varios archivos en una carpeta, se puede usar el siguiente comando para encontrar la lista de archivos que contienen las cadenas deseadas.
grep -l "String to Match" /path/to/directory
# encontrar la lista de archivos que contienen las cadenas deseadas
Extracción de texto usando sed
sed se refiere a “editor de flujo”. Procesa los datos de manera fluida, lo que significa que lee una línea a la vez. sed te permite buscar patrones y realizar acciones en las líneas que concuerdan con esos patrones.
Sintaxis básica desed:
sed [options] 'command' file_name
La sintaxis básica de sed es la siguiente:
En este caso, comando se utiliza para realizar operaciones como sustitución, eliminación, inserción, entre otras, en los datos de texto. El nombre de archivo es el nombre del archivo que deseas procesar.
seduso:
1. Sustitución:
sed 's/old-text/new-text/' filename
La bandera s se utiliza para reemplazar texto. El texto-viejo se reemplaza con texto-nuevo:
sed 's/error/warning/' system.log
Por ejemplo, para cambiar todas las instancias de “error” a “aviso” en el archivo de registro system.log:
2. Impresión de líneas que contienen un patrón específico:
sed -n '/pattern/p' filename
Usando sed para filtrar y mostrar líneas que concuerdan con un patrón específico:
sed -n '/ERROR/p' system.log
Por ejemplo, para encontrar todas las líneas que contienen “ERROR”:
3. Eliminación de líneas que contienen un patrón específico:
sed '/pattern/d' filename
Puedes eliminar líneas de la salida que concuerdan con un patrón específico:
sed '/DEBUG/d' system.log
Por ejemplo, para eliminar todas las líneas que contienen “DEBUG”:
4. Extracción de campos específicos de una línea de registro:
sed -n 's/^\([0-9]\{4\}-[0-9]\{2\}-[0-9]\{2\}\).*/\1/p' system.log
Puedes usar expresiones regulares para extraer partes de las líneas. Suponiendo que cada línea de registro comienza con una fecha en el formato “AAAA-MM-DD”, podrías extraer solo la fecha de cada línea:
Parsing de texto con awk
awk tiene la capacidad de dividir cada línea en campos fácilmente. Es bien adaptado para procesar texto estructurado como archivos de registro.
Sintaxis básica deawk
awk 'pattern { action }' file_name
La sintaxis básica de awk es:
Aquí, patrón es una condición que debe ser satisfactoria para que la acción sea ejecutada. Si el patrón es omitido, la acción se realiza en cada línea.
2024-04-25 09:00:00 INFO Startup: Application starting
2024-04-25 09:01:00 INFO Config: Configuration loaded successfully
2024-04-25 09:02:00 INFO Database: Database connection established
2024-04-25 09:03:00 INFO User: New user registered (UserID: 1001)
2024-04-25 09:04:00 INFO Security: Attempted login with incorrect credentials (UserID: 1001)
2024-04-25 09:05:00 INFO Network: Network timeout on request (ReqID: 456)
2024-04-25 09:06:00 INFO Email: Notification email sent (UserID: 1001)
2024-04-25 09:07:00 INFO API: API call with response time over threshold (Duration: 350ms)
2024-04-25 09:08:00 INFO Session: User session ended (UserID: 1001)
2024-04-25 09:09:00 INFO Shutdown: Application shutdown initiated
INFO
- En los siguientes ejemplos, usarás este archivo de registro como ejemplo:
Acceder a columnas usandoawk
zaira@zaira-ThinkPad:~$ awk '{ print $1 }' sample.log
Los campos en awk (separados por espacios por defecto) se pueden acceder usando $1, $2, $3, y así sucesivamente.
2024-04-25
2024-04-25
2024-04-25
2024-04-25
2024-04-25
2024-04-25
2024-04-25
2024-04-25
2024-04-25
2024-04-25
zaira@zaira-ThinkPad:~$ awk '{ print $2 }' sample.log
# salida
09:00:00
09:01:00
09:02:00
09:03:00
09:04:00
09:05:00
09:06:00
09:07:00
09:08:00
09:09:00
- # salida
awk '/ERROR/ { print $0 }' logfile.log
Imprimir líneas que contienen un patrón específico (por ejemplo, ERROR)
2024-04-25 09:05:00 ERROR Network: Network timeout on request (ReqID: 456)
# salida
- Esto imprimirá todas las líneas que contienen “ERROR”.
awk '{ print $1, $2 }' logfile.log
Extraer el primer campo (Fecha y Hora)
2024-04-25 09:00:00
2024-04-25 09:01:00
2024-04-25 09:02:00
2024-04-25 09:03:00
2024-04-25 09:04:00
2024-04-25 09:05:00
2024-04-25 09:06:00
2024-04-25 09:07:00
2024-04-25 09:08:007
2024-04-25 09:09:00
# salida
- Esto extraerá los dos primeros campos de cada línea, que en este caso serían la fecha y la hora.
awk '{ count[$3]++ } END { for (level in count) print level, count[level] }' logfile.log
Resumir las apariciones de cada nivel de registro
1
WARN 1
ERROR 1
DEBUG 2
INFO 6
# output
- La salida será un resumen de la cantidad de apariciones de cada nivel de registro.
awk '{ $3="INFO"; print }' sample.log
Filtrar campos específicos (por ejemplo, donde el tercer campo es INFO)
2024-04-25 09:00:00 INFO Startup: Application starting
2024-04-25 09:01:00 INFO Config: Configuration loaded successfully
2024-04-25 09:02:00 INFO Database: Database connection established
2024-04-25 09:03:00 INFO User: New user registered (UserID: 1001)
2024-04-25 09:04:00 INFO Security: Attempted login with incorrect credentials (UserID: 1001)
2024-04-25 09:05:00 INFO Network: Network timeout on request (ReqID: 456)
2024-04-25 09:06:00 INFO Email: Notification email sent (UserID: 1001)
2024-04-25 09:07:00 INFO API: API call with response time over threshold (Duration: 350ms)
2024-04-25 09:08:00 INFO Session: User session ended (UserID: 1001)
2024-04-25 09:09:00 INFO Shutdown: Application shutdown initiated
INFO
# output
Este comando extraerá todas las líneas donde el tercer campo es “INFO”.
💡 Consejo: El separador predeterminado en awk es un espacio. Si su archivo de registros utiliza un separador diferente, puede especificarlo utilizando la opción -F. Por ejemplo, si su archivo de registros utiliza una coma como separador, puede usar awk -F: '{ print $1 }' logfile.log para extraer el primer campo.
Análisis de archivos de registros con cut
El comando cut es un comando simple y potente utilizado para extraer secciones de texto de cada línea de entrada. Como los archivos de registros están estructurados y cada campo está delimitado por un carácter específico, como un espacio, tabulador o un delimitador personalizado, cut hace un buen trabajo extraendo esos campos específicos.
cut [options] [file]
La sintaxis básica del comando cut es:
- Algunas opciones comunes utilizadas para el comando cut:
-d: Especifica un delimitador utilizado como separador de campos.-f: Selecciona los campos que deben mostrarse.
-c : Especifica posiciones de caracteres.
cut -d ' ' -f 1 logfile.log
Por ejemplo, el comando a continuación extraería el primer campo (separado por un espacio) de cada línea del archivo de registro:
Ejemplos de usocutpara análisis de registros
2024-04-25 08:23:01 INFO 192.168.1.10 User logged in successfully.
2024-04-25 08:24:15 WARNING 192.168.1.10 Disk usage exceeds 90%.
2024-04-25 08:25:02 ERROR 10.0.0.5 Connection timed out.
...
Supongamos que tienes un archivo de registros estructurado de la siguiente manera, donde los campos están separados por espacios:
cutse puede utilizar de las siguientes maneras:
cut -d ' ' -f 2 system.log
Extracción de la hora de cada entrada de registro:
08:23:01
08:24:15
08:25:02
...
# Salida
- Este comando utiliza el espacio como delimitador y selecciona el segundo campo, que es el componente de tiempo de cada entrada de registro.
cut -d ' ' -f 4 system.log
Extracción de las direcciones IP de los registros:
192.168.1.10
192.168.1.10
10.0.0.5
# Salida
- Este comando extrae el cuarto campo, que es la dirección IP de cada entrada de registro.
cut -d ' ' -f 3 system.log
Extracción de los niveles de registro (INFO, WARNING, ERROR):
INFO
WARNING
ERROR
# Salida
- Esto extrae el tercer campo que contiene el nivel de registro.
Combinacióncutcon otras órdenes:
grep "ERROR" system.log | cut -d ' ' -f 1,2
La salida de otras órdenes puede ser enviada a la orden cut. Digamos que quieres filtrar los registros antes de cortar. Puedes usar grep para extraer las líneas que contienen "ERROR" y luego usar cut para obtener información específica de esas líneas:
2024-04-25 08:25:02
# Salida
- Este comando primero filtra las líneas que incluyen “ERROR”, luego extrae la fecha y hora de estas líneas.
Extracción de múltiples campos:
cut -d ' ' -f 1,2,3 system.log`
Es posible extraer múltiples campos a la vez especificando un rango o una lista de campos separados por comas:
2024-04-25 08:23:01 INFO
2024-04-25 08:24:15 WARNING
2024-04-25 08:25:02 ERROR
...
# Salida
El comando anterior extrae los primeros tres campos de cada entrada de registro, que son fecha, hora y nivel de registro.
Análisis de archivos de registro con sort y uniq
Ordenar y eliminar duplicados son operaciones comunes al trabajar con archivos de registro. Los comandos sort y uniq son potentes para ordenar y eliminar líneas duplicadas del input, respectivamente.
Sintaxis básica de sort
sort [options] [file]
El comando sort organiza las líneas de texto alfabeticamente o numéricamente.
- Algunas opciones clave para el comando sort:
-n: Ordena el archivo suponiendo que el contenido es numérico.-r: Inverte el orden de ordenación.-k: Especifica una clave o número de columna para ordenar.
-u: Ordena y elimina líneas duplicadas.
La orden uniq se utiliza para filtrar o contar y reportar líneas repetidas en un archivo.
uniq [options] [input_file] [output_file]
La sintaxis de uniq es:
- Algunas opciones clave para la orden
uniqson: -c: Antepone al número de apariciones a las líneas.-d: Solo imprime líneas duplicadas.
-u: Solo imprime líneas únicas.
Ejemplos de uso de sort y uniq juntos para la interpretación de logs
2024-04-25 INFO User logged in successfully.
2024-04-25 WARNING Disk usage exceeds 90%.
2024-04-26 ERROR Connection timed out.
2024-04-25 INFO User logged in successfully.
2024-04-26 INFO Scheduled maintenance.
2024-04-26 ERROR Connection timed out.
- Supongamos las siguientes entradas de registro de ejemplo para estas demostraciones:
sort system.log
Ordenando entradas de registro por fecha:
2024-04-25 INFO User logged in successfully.
2024-04-25 INFO User logged in successfully.
2024-04-25 WARNING Disk usage exceeds 90%.
2024-04-26 ERROR Connection timed out.
2024-04-26 ERROR Connection timed out.
2024-04-26 INFO Scheduled maintenance.
# Salida
- Este comando ordena las entradas de registro alfabéticamente, lo que efectivamente las ordena por fecha si la fecha es el primer campo.
sort system.log | uniq
Ordenando y eliminando duplicados:
2024-04-25 INFO User logged in successfully.
2024-04-25 WARNING Disk usage exceeds 90%.
2024-04-26 ERROR Connection timed out.
2024-04-26 INFO Scheduled maintenance.
# Salida
- Este comando ordena el archivo de registro y lo canaliza a
uniq, eliminando las líneas duplicadas.
sort system.log | uniq -c
Contando las apariciones de cada línea:
2 2024-04-25 INFO User logged in successfully.
1 2024-04-25 WARNING Disk usage exceeds 90%.
2 2024-04-26 ERROR Connection timed out.
1 2024-04-26 INFO Scheduled maintenance.
# Salida
- Ordena las entradas de registro y luego cuenta cada línea única. Según la salida, la línea
'2024-04-25 INFO Usuario ha iniciado sesión correctamente.'apareció 2 veces en el archivo.
sort system.log | uniq -u
Identificación de entradas de registro únicas:
2024-04-25 WARNING Disk usage exceeds 90%.
2024-04-26 INFO Scheduled maintenance.
# Salida
- Este comando muestra las líneas que son únicas.
sort -k2 system.log
Clasificar por nivel de registro:
2024-04-26 ERROR Connection timed out.
2024-04-26 ERROR Connection timed out.
2024-04-25 INFO User logged in successfully.
2024-04-25 INFO User logged in successfully.
2024-04-26 INFO Scheduled maintenance.
2024-04-25 WARNING Disk usage exceeds 90%.
# Salida
Clasifica las entradas según el segundo campo, que es el nivel de registro.
8.4. Gestionar procesos de Linux mediante la línea de comandos
- Un proceso es una instancia en ejecución de un programa. Un proceso consta de:
- Un espacio de direcciones de memoria asignado.
- Estados del proceso.
Propiedades como la propiedad, atributos de seguridad y el uso de recursos.
- Un proceso también tiene un entorno que consta de:
- Variables locales y globales
- El contexto de planificación actual
Recursos del sistema asignados, como puertos de red o descriptores de archivo.
Cuando ejecutas el comando ls -l, el sistema operativo crea un nuevo proceso para ejecutar el comando. El proceso tiene una ID, un estado y ejecuta hasta que el comando se complete.
Comprender la creación de procesos y el ciclo de vida.
En Ubuntu, todos los procesos tienen su origen en el proceso inicial del sistema llamado systemd, que es el primer proceso iniciado por el núcleo durante el arranque.
El proceso systemd tiene un identificador de proceso (PID) de 1 y es responsable de iniciar y manejar los servicios del sistema, así como de iniciar y administrar otros procesos. Todos los demás procesos del sistema son descendientes de systemd.
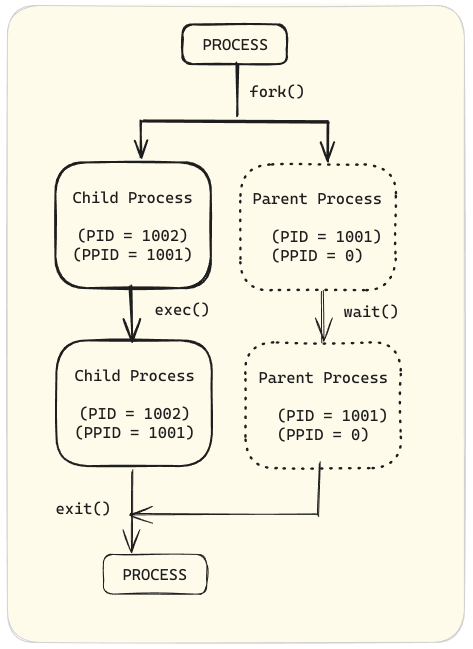
Un proceso padre duplica su propio espacio de direcciones (fork) para crear una nueva estructura de proceso (hijo). Cada nuevo proceso se asigna un identificador de proceso (PID) único para su seguimiento y fines de seguridad. El PID y el identificador de proceso del padre (PPID) forman parte del entorno del nuevo proceso. Cualquier proceso puede crear un proceso hijo.
A través de la rutina de fork, un proceso hijo hereda identidades de seguridad, descriptores de archivo anteriores y actuales, privilegios de puerto y recursos, variables de entorno y código de programa. El proceso hijo puede ejecutar entonces su propio código de programa.
Típicamente, un proceso padre duerme mientras el proceso hijo se ejecuta, estableciendo una solicitud (wait) para que se le avise cuando el hijo se complete.
Al salir, el proceso hijo ya ha cerrado o descartado sus recursos y entorno. El único recurso que queda, conocido como un zombie, es una entrada en la tabla de procesos. El padre, que se activa cuando el hijo sale, limpia la tabla de procesos de la entrada del hijo, liberando así el último recurso del proceso hijo. El proceso padre entonces continúa ejecutando su propio código de programa.
Entender los estados de los procesos.

Los procesos en Linux asumen diferentes estados a lo largo de su ciclo de vida. El estado de un proceso indica qué está haciendo actualmente el proceso y cómo está interactuando con el sistema. Los procesos transicionan entre estados basado en su estado de ejecución y el algoritmo de planificación del sistema.
| Los procesos en un sistema Linux pueden estar en uno de los siguientes estados: | Estado |
| Descripción | (new) |
| Estado inicial cuando un proceso es creado mediante una llamada de sistema fork. | Ejecutable (listo) (R) |
| El proceso está listo para ejecutarse y esperando ser programado en un CPU. | Ejecutando (usuario) (R) |
| El proceso está ejecutándose en modo usuario, ejecutando aplicaciones de usuario. | Ejecutando (kernel) (R) |
| El proceso está ejecutándose en modo kernel, manejando llamadas de sistema o interrupciones de hardware. | Durmiendo (S) |
| El proceso está esperando que un evento (por ejemplo, operación de E/S) se complete y puede despertarse fácilmente. | Durmiendo (no interrumpible) (D) |
| El proceso se encuentra en un estado de durmiendo no interrumpible, esperando que una condición específica (normalmente una E/S) se complete y no puede ser interrumpido por señales. | Durmiendo (disco durmiente) (K) |
| El proceso está esperando que las operaciones de E/S del disco se complete. | Durmiendo (inactivo) (I) |
| El proceso está inactivo, no realiza ninguna tarea, y espera que ocurra un evento. | Detenido (T) |
| La ejecución del proceso ha sido detenida, normalmente por una señal, y puede ser reanudada posteriormente. | Zombi (Z) |
El proceso ha finalizado su ejecución pero aún tiene una entrada en la tabla de procesos, esperando que su padre lea su estado de salida.
| Los procesos transicionan entre estos estados de la siguiente manera: | Transición |
| Descripción | Fork |
| Crea un nuevo proceso a partir de un proceso padre, transicionando de (nuevo) a Ejecutable (listo) (R). | Planificar |
| El planificador selecciona un proceso ejecutable, lo transiciona al estado En Ejecución (usuario) o En Ejecución (kernel). | Ejecutar |
| El proceso transiciona de Ejecutable (listo) (R) a En Ejecución (kernel) (R) cuando se programa para su ejecución. | Preempt o Reschedule |
| El proceso puede ser presionado o reprogramado, moviéndolo de vuelta al estado Ejecutable (listo) (R). | Syscall |
| El proceso realiza una llamada de sistema, transicionando de En Ejecución (usuario) (R) a En Ejecución (kernel) (R). | Retorno |
| El proceso finaliza una llamada de sistema y regresa a En Ejecución (usuario) (R). | Esperar |
| El proceso espera un evento, transicionando de En Ejecución (kernel) (R) a uno de los estados de sueño (S, D, K o I). | Evento o Señal |
| El proceso se despierta por un evento o señal, lo que lo mueve de un estado de sueño de vuelta a Ejecutable (listo) (R). | Suspender |
| El proceso se suspende, cambiando de Ejecutando (kernel) o Ejecutable (listo) a Detenido (T). | Reanudar |
| El proceso se reanuda, cambiando de Detenido (T) de vuelta a Ejecutable (listo) (R). | Salir |
| El proceso termina, cambiando de Ejecutando (usuario) o Ejecutando (kernel) a Zombi (Z). | Recoger |
El proceso padre lee el estado de salida del proceso zombi, quitándolo de la tabla de procesos.
Cómo ver procesos
zaira@zaira:~$ ps aux
Puede utilizar el comando ps junto con una combinación de opciones para ver procesos en un sistema Linux. El comando ps se utiliza para mostrar información sobre una selección de procesos activos. Por ejemplo, ps aux muestra todos los procesos en ejecución en el sistema.
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
root 1 0.0 0.0 168140 11352 ? Ss May21 0:18 /sbin/init splash
root 2 0.0 0.0 0 0 ? S May21 0:00 [kthreadd]
root 3 0.0 0.0 0 0 ? I< May21 0:00 [rcu_gp]
root 4 0.0 0.0 0 0 ? I< May21 0:00 [rcu_par_gp]
root 5 0.0 0.0 0 0 ? I< May21 0:00 [slub_flushwq]
root 6 0.0 0.0 0 0 ? I< May21 0:00 [netns]
root 11 0.0 0.0 0 0 ? I< May21 0:00 [mm_percpu_wq]
root 12 0.0 0.0 0 0 ? I May21 0:00 [rcu_tasks_kthread]
root 13 0.0 0.0 0 0 ? I May21 0:00 [rcu_tasks_rude_kthread]
*... output truncated ....*
# Salida
- La salida superior muestra una instantánea de los procesos en ejecución actualmente en el sistema. Cada fila representa un proceso con las columnas siguientes:
USUARIO: El usuario que posee el proceso.PID: La ID del proceso.%CPU: El uso de CPU del proceso.%MEM: El uso de memoria del proceso.VSZ: La tamaño de memoria virtual del proceso.RSS: El tamaño del conjunto residente, es decir, la memoria física no intercambiada que ha utilizado una tarea.TTY: La terminal controladora del proceso. Un?indica que no hay terminal controladora.Ss: Líder de sesión. Este es un proceso que ha iniciado una sesión, y es líder de un grupo de procesos y puede controlar señales de terminal. El primeroSindica el estado de reposo, y el segundosindica que es un líder de sesión.INICIO: La hora o fecha de inicio del proceso.TIEMPO: El tiempo de CPU acumulado.
COMANDO: El comando que inició el proceso.
Procesos en segundo plano y en primero
En esta sección, aprenderá cómo puede controlar tareas ejecutándolas en segundo plano o en primero.
Una tarea es un proceso iniciado por una shell. Cuando ejecuta un comando en la terminal, se considera una tarea. Una tarea puede ejecutarse en el frente o en el fondo.
- Para demostrar el control, primero creará 3 procesos y luego los ejecutará en segundo plano. Después, listará los procesos y alternará entre el frente y el fondo. Verá cómo ponerlos a dormir o salir completamente.
Crear Tres Procesos
Abre una terminal y inicia tres procesos de larga ejecución. Utiliza el comando sleep, que mantiene el proceso en ejecución durante un número especificado de segundos.
sleep 300 &
sleep 400 &
sleep 500 &
# Ejecutar el comando sleep por 300, 400 y 500 segundos
- El carácter
&al final de cada comando mueve el proceso al segundo plano.
Mostrar las Tareas en Segundo Plano
jobs
Usa el comando jobs para mostrar la lista de tareas en segundo plano.
jobs
[1] Running sleep 300 &
[2]- Running sleep 400 &
[3]+ Running sleep 500 &
- La salida debería parecerse a esto:
Traer una Tarea en Segundo Plano al Frente
fg %1
Para traer una tarea en segundo plano al frente, use el comando fg seguido del número de la tarea. Por ejemplo, para traer la primera tarea (sleep 300) al frente:
- Esto traerá la tarea
1al frente.
Mover la Tarea en Frente de Nuevo al Segundo Plano
Mientras el trabajo se ejecuta en el frente, puede suspendirlo y devolverlo al fondo presionando Ctrl+Z para suspender el trabajo.
zaira@zaira:~$ fg %1
sleep 300
^Z
[1]+ Stopped sleep 300
zaira@zaira:~$ jobs
Un trabajo suspendido se verá así:
[1]+ Stopped sleep 300
[2] Running sleep 400 &
[3]- Running sleep 500 &
# trabajo suspendido
Ahora use el comando bg para reanudar el trabajo con ID 1 en el fondo.
# Presione Ctrl+Z para suspendir el trabajo del frente
bg %1
- # A continuación, reanúdalo en el fondo
jobs
[1] Running sleep 300 &
[2]- Running sleep 400 &
[3]+ Running sleep 500 &
Vuelva a mostrar los trabajos
- En este ejercicio, ha:
- Inició tres procesos en segundo plano usando comandos sleep.
- Usó el comando jobs para mostrar la lista de trabajos en segundo plano.
- Trajo un trabajo al frente con
fg %job_number. - Suspendió el trabajo con
Ctrl+Zy lo devolvió al fondo conbg %job_number.
Volvió a usar jobs para verificar el estado de los trabajos en segundo plano.
Ahora sabes cómo controlar los trabajos.
Matar procesos
Puede finalizar un proceso inactivo o no deseado usando el comando kill. El comando kill envía una señal a un ID de proceso, pidiéndole que finalice.
Hay varias opciones disponibles con el comando kill.
kill -l
1) SIGHUP 2) SIGINT 3) SIGQUIT 4) SIGILL 5) SIGTRAP
6) SIGABRT 7) SIGBUS 8) SIGFPE 9) SIGKILL 10) SIGUSR1
11) SIGSEGV 12) SIGUSR2 13) SIGPIPE 14) SIGALRM 15) SIGTERM
16) SIGSTKFLT 17) SIGCHLD 18) SIGCONT 19) SIGSTOP 20) SIGTSTP
21) SIGTTIN 22) SIGTTOU 23) SIGURG 24)
...terminated
# Opciones disponibles con kill
- Aquí están algunos ejemplos del comando
killen Linux: - Este comando envía la señal predeterminada
SIGTERMal proceso con PID 1234, pidiéndole que finalice. - Este comando envía la señal predeterminada
SIGTERMa todos los procesos con el nombre especificado. - Esta orden envía la señal
SIGKILLal proceso con el PID 1234, matándolo forzadamente. - Esta orden envía la señal
SIGSTOPal proceso con el PID 1234, deteniéndolo.
Esta orden envía la señal predeterminada SIGTERM a todos los procesos propiedad del usuario especificado.
Estos ejemplos demuestran diferentes maneras de usar el comando kill para gestionar procesos en un entorno Linux.
Aquí está la información sobre las opciones y señales del comando kill en forma tabular: esta tabla resume las opciones y señales de kill más comunes utilizadas en Linux para gestionar procesos. |
Comando / Opción | Señal |
| Descripción | kill |
SIGTERM |
| Solicita que el proceso finalice con gracia (señal predeterminada). | kill -9 |
SIGKILL |
| Fuerza la finalización inmediata del proceso sin limpieza. | kill -SIGKILL |
SIGKILL |
| Fuerza la finalización inmediata del proceso sin limpieza. | kill -15 |
SIGTERM |
Envía explícitamente la señal SIGTERM para solicitar una finalización con gracia. |
kill -SIGTERM |
SIGTERM |
Envía explícitamente la señal SIGTERM para solicitar una finalización con gracia. |
kill -1 |
SIGHUP |
| Tradicionalmente significa “colgar”; puede usarse para recargar los archivos de configuración. | kill -SIGHUP |
SIGHUP |
| Tradicionalmente significa “colgar”; se puede utilizar para recargar los archivos de configuración. | kill -2 <pid> |
SIGINT |
Pide que el proceso termine (igual que presionar Ctrl+C en la terminal). |
kill -SIGINT <pid> |
SIGINT |
Pide que el proceso termine (igual que presionar Ctrl+C en la terminal). |
kill -3 <pid> |
SIGQUIT |
| Causa que el proceso termine y genere un volcado de núcleo para depurar. | kill -SIGQUIT <pid> |
SIGQUIT |
| Causa que el proceso termine y genere un volcado de núcleo para depurar. | kill -19 <pid> |
SIGSTOP |
| Pausa el proceso. | kill -SIGSTOP <pid> |
SIGSTOP |
| Pausa el proceso. | kill -18 <pid> |
SIGCONT |
| Reanuda un proceso en pausa. | kill -SIGCONT <pid> |
SIGCONT |
| Reanuda un proceso en pausa. | killall <name> |
Varies |
| Envía una señal a todos los procesos con el nombre dado. | killall -9 <name> |
SIGKILL |
| Forza la muerte de todos los procesos con el nombre dado. | pkill |
Varias |
| Envía una señal a los procesos basándose en una coincidencia de patrón. | pkill -9 |
SIGKILL |
| Forza la muerte de todos los procesos que coinciden con el patrón. | xkill |
SIGKILL |
Utilidad gráfica que permite hacer clic en una ventana para matar el proceso correspondiente.
8.5. Flujos de Entrada y Salida Estándar en Linux
- Leer una entrada y escribir una salida es una parte fundamental para comprender la línea de comandos y la programación de shell. En Linux, cada proceso tiene tres flujos predeterminados por defecto:
- El descriptor de archivo para
stdines0. - Salida estándar (
stdout): Esta es la corriente de salida predeterminada donde un proceso escribe su salida. Por defecto, la salida estándar es el terminal. La salida también puede ser redirigida a un archivo o a otro programa. El descriptor de archivo parastdoutes1.
Error estándar (stderr): Esta es la corriente de error predeterminada donde un proceso escribe sus mensajes de error. Por defecto, el error estándar es el terminal, permitiendo que los mensajes de error se vean incluso si stdout ha sido redirigida. El descriptor de archivo para stderr es 2.
Redirección y tuberías
Redirección: Puede redirigir las corrientes de error y salida a archivos o a otros comandos. Por ejemplo:
ls > output.txt
# Redirigiendo stdout a un archivo
ls non_existent_directory 2> error.txt
# Redirigiendo stderr a un archivo
ls non_existent_directory > all_output.txt 2>&1
# Redirigiendo ambas stdout y stderr a un archivo
- En el último comando,
ls non_existent_directory: muestra el contenido de un directorio llamado non_existent_directory. Dado que este directorio no existe, `ls` generará un mensaje de error.> all_output.txt: El operador>redirecciona la salida estándar (stdout) del comando `ls` al archivoall_output.txt. Si el archivo no existe, se creará. Si ya existe, su contenido será sobrescrito.
2>&1: En este caso, 2 representa el descriptor de archivo para el error estándar (stderr). &1 representa el descriptor de archivo para la salida estándar (stdout). El carácter & se utiliza para indicar que 1 no es el nombre de archivo sino un descriptor de archivo.
Así, 2>&1 significa “redirigir stderr (2) a donde está actualmente stdout (1)”, que en este caso es el archivo all_output.txt. Por lo tanto, tanto la salida (si hubiera alguna) como el mensaje de error de ls serán escritos en all_output.txt.
Pipeline:
ls | grep image
Puede utilizar las tuberías (|) para pasar la salida de una orden como entrada para otra:
image-10.png
image-11.png
image-12.png
image-13.png
... Output truncated ...
# Salida
8.6 Automatización en Linux – Automatizar tareas con trabajos de Cron
Cron es una herramienta poderosa para la programación de tareas que está disponible en los sistemas operativos Unix-like. Configurando cron, puede establecer tareas automatizadas que ejecutarán en unidades de tiempo específicas como diariamente, semanales, mensuales u otras. Las capacidades de automatización proporcionadas por cron desempeñan un papel crucial en la administración de sistemas Linux.
El demonio crond (un tipo de programa que se ejecuta en segundo plano) permite la funcionalidad de cron. Cron lee las crontab (tablas de cron) para ejecutar scripts predefinidos.
Usando una sintaxis específica, puede configurar un trabajo de cron para programar scripts u otras órdenes automáticamente.
¿Qué son los trabajos de cron en Linux?
Cualquier tarea que se programa a través de crons se conoce como un trabajo de cron.
Ahora, veamos cómo funcionan los trabajos de cron.
Cómo controlar el acceso a los crons
Para utilizar los trabajos de cron, un administrador necesita permitir agregar trabajos de cron para los usuarios en el archivo /etc/cron.allow.
Si recibe un aviso como este, significa que no tiene permiso para utilizar cron.
![]()
Para permitir que Juan use crons, incluya su nombre en /etc/cron.allow. Cree el archivo si no existe. Esto permitirá a Juan crear y editar trabajos cron.
Los usuarios también pueden negar el acceso a los trabajos cron agregando sus nombres de usuario en el archivo /etc/cron.d/cron.deny.
Cómo agregar trabajos cron en Linux
Primero, para utilizar trabajos cron, necesitará verificar el estado del servicio cron. Si cron no está instalado, puede descargarlo fácilmente mediante el gestor de paquetes. Solo use esto para verificar:
sudo systemctl status cron.service
# Verificar servicio cron en sistema Linux
Sintaxis de trabajo cron
- Las crontabs utilizan las siguientes banderas para agregar y listar trabajos cron:
crontab -e: edita entradas de crontab para agregar, eliminar o editar trabajos cron.crontab -l: lista todos los trabajos cron para el usuario actual.crontab -u username -l: lista los crons de otro usuario.
crontab -u username -e: edita los crons de otro usuario.
Cuando lista crons y existen, verá algo así:
* * * * * sh /path/to/script.sh
# Ejemplo de tarea cron
- En el ejemplo anterior,
* representa minuto(s) hora(s) día(s) mes(es) día de la semana, respectivamente. Ver detalles de estos valores debajo: |
VALOR | |
| DESCRIPCIÓN | Minutos | 0-59 |
| El comando se ejecutará en el minuto específico. | Horas | 0-23 |
| El comando se ejecutará en la hora específica. | Días | 1-31 |
| Los comandos se ejecutarán en estos días del mes. | Meses | 1-12 |
| El mes en el que deben ejecutarse las tareas. | Días de la semana | 0-6 |
- Los días de la semana en los que se ejecutarán los comandos. Aquí, 0 es domingo.
shindica que el script es un script bash y debe ejecutarse desde/bin/bash.
/path/to/script.sh especifica la ruta al script.
* * * * * sh /path/to/script/script.sh
| | | | | |
| | | | | Command or Script to Execute
| | | | |
| | | | |
| | | | |
| | | | Day of the Week(0-6)
| | | |
| | | Month of the Year(1-12)
| | |
| | Day of the Month(1-31)
| |
| Hour(0-23)
|
Min(0-59)
A continuación se muestra una sinopsis de la sintaxis de las tareas cron:
Ejemplos de tareas cron
| A continuación se presentan algunos ejemplos de programación de tareas cron. | PLANIFICACIÓN |
| VALOR PROGRAMADO | 5 0 * 8 * |
| El 00:05 de agosto. | 5 4 * * 6 |
| A las 04:05 del sábado. | 0 22 * * 1-5 |
A las 22:00 todos los días de la semana de lunes a viernes.
No hay problema si no puedes comprender esto de una sola vez. Puedes practicar y generar programas de cron con el sitio web crontab guru.
Cómo configurar una tarea cron
- En esta sección, veremos un ejemplo de cómo programar una simple secuencia de comandos con una tarea cron.
#!/bin/bash
echo `date` >> date-out.txt
Crea un script llamado date-script.sh que imprima la fecha y hora del sistema y anexe el archivo. El script se muestra a continuación:
chmod 775 date-script.sh
2. Da permisos de ejecución al script.
3. Agrega el script a la crontab usando crontab -e.
*/1 * * * * /bin/sh /root/date-script.sh
Aquí, lo hemos programado para ejecutarse cada minuto.
cat date-out.txt
4. Revise el archivo de salida date-out.txt. Según el script, la fecha del sistema debería imprimirse en este archivo cada minuto.
Wed 26 Jun 16:59:33 PKT 2024
Wed 26 Jun 17:00:01 PKT 2024
Wed 26 Jun 17:01:01 PKT 2024
Wed 26 Jun 17:02:01 PKT 2024
Wed 26 Jun 17:03:01 PKT 2024
Wed 26 Jun 17:04:01 PKT 2024
Wed 26 Jun 17:05:01 PKT 2024
Wed 26 Jun 17:06:01 PKT 2024
Wed 26 Jun 17:07:01 PKT 2024
# output
Cómo solucionar problemas con crons
Los crons son realmente útiles, pero pueden no funcionar siempre como se espera. Afortunadamente, hay algunos métodos efectivos que puede usar para solucionarlos.
1. Verifique el programa.
Primero, puede intentar verificar el programa que se ha establecido para el cron. Puede hacerlo con la sintaxis que viste en las secciones anteriores.
2. Revisar logs de cron.
Antes de nada, necesitas revisar si el cron se ha ejecutado en el momento previsto o no. En Ubuntu, puedes verificar esto mediante los registros de cron ubicados en /var/log/syslog.
Si hay una entrada en estos registros en el momento correcto, significa que el cron se ha ejecutado según el horario que has establecido.
1 Jun 26 17:02:01 zaira-ThinkPad CRON[27834]: (zaira) CMD (/bin/sh /home/zaira/date-script.sh)
2 Jun 26 17:02:02 zaira-ThinkPad systemd[2094]: Started Tracker metadata extractor.
3 Jun 26 17:03:01 zaira-ThinkPad CRON[28255]: (zaira) CMD (/bin/sh /home/zaira/date-script.sh)
4 Jun 26 17:03:02 zaira-ThinkPad systemd[2094]: Started Tracker metadata extractor.
5 Jun 26 17:04:01 zaira-ThinkPad CRON[28538]: (zaira) CMD (/bin/sh /home/zaira/date-script.sh)
A continuación están los registros del trabajo de cron de nuestro ejemplo. Tenga en cuenta la primera columna que muestra la marca de tiempo. También se menciona el path del script al final de la línea. Las líneas #1, 3 y 5 muestran que el script se ha ejecutado según lo previsto.
3. Redirigir la salida del cron a un archivo.
Puedes redirigir la salida del cron a un archivo y verificar el archivo para cualquier posible error.
* * * * * sh /path/to/script.sh &> log_file.log
# Redirigir la salida del cron a un archivo
8.7. bases de red de Linux
Linux ofrece una serie de comandos para ver información relacionada con la red. En esta sección brevemente discutiremos algunos de los comandos.
Ver interfaces de red con ifconfig
ifconfig
El comando ifconfig proporciona información sobre las interfaces de red. Aquí tienes un ejemplo de salida:
eth0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 192.168.1.100 netmask 255.255.255.0 broadcast 192.168.1.255
inet6 fe80::a00:27ff:fe4e:66a1 prefixlen 64 scopeid 0x20<link>
ether 08:00:27:4e:66:a1 txqueuelen 1000 (Ethernet)
RX packets 1024 bytes 654321 (654.3 KB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 512 bytes 123456 (123.4 KB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
lo: flags=73<UP,LOOPBACK,RUNNING> mtu 65536
inet 127.0.0.1 netmask 255.0.0.0
inet6 ::1 prefixlen 128 scopeid 0x10<host>
loop txqueuelen 1000 (Local Loopback)
RX packets 256 bytes 20480 (20.4 KB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 256 bytes 20480 (20.4 KB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
# Salida
La salida del comando ifconfig muestra las interfaces de red configuradas en el sistema, junto con detalles como direcciones IP, direcciones MAC, estadísticas de paquetes y más.
Estas interfaces pueden ser dispositivos físicos o virtuales.
Para extraer direcciones IP versión 4 y 6, puedes usar ip -4 addr y ip -6 addr, respectivamente.
Ver actividad de red connetstat
El comando netstat muestra la actividad y estadísticas de la red proporcionando la información siguiente:
- Aquí están algunos ejemplos de cómo utilizar el comando
netstaten la línea de comandos: - Mostrar todos los sockets escuchando y no escuchando:
- Mostrar solo los puertos que están escuchando:
- Mostrar estadísticas de red:
- Mostrar tabla de enrutamiento:
- Mostrar conexiones TCP:
- Mostrar conexiones UDP:
- Mostrar interfaces de red:
- Mostrar PID y nombres de programa para conexiones:
- Mostrar estadísticas para un protocolo específico (por ejemplo, TCP):
Mostrar información extendida:
Comprobar la conectividad de red entre dos dispositivos usando ping
ping google.com
ping se utiliza para probar la conectividad de red entre dos dispositivos. Envía paquetes ICMP al dispositivo de destino y espera por una respuesta.
ping google.com
PING google.com (142.250.181.46) 56(84) bytes of data.
64 bytes from fjr04s06-in-f14.1e100.net (142.250.181.46): icmp_seq=1 ttl=60 time=78.3 ms
64 bytes from fjr04s06-in-f14.1e100.net (142.250.181.46): icmp_seq=2 ttl=60 time=141 ms
64 bytes from fjr04s06-in-f14.1e100.net (142.250.181.46): icmp_seq=3 ttl=60 time=205 ms
64 bytes from fjr04s06-in-f14.1e100.net (142.250.181.46): icmp_seq=4 ttl=60 time=100 ms
^C
--- google.com ping statistics ---
4 packets transmitted, 4 received, 0% packet loss, time 3001ms
rtt min/avg/max/mdev = 78.308/131.053/204.783/48.152 ms
ping prueba si consigue una respuesta sin obtener un timeout.
— google.com ping estadísticas —
Puede detener la respuesta con Ctrl + C.
Probando puntos finales con el comando curl
- El comando
curlsignifica “cliente URL”. Se utiliza para transferir datos a o desde un servidor. También se puede utilizar para probar puntos finales de API que ayudan en la resolución de problemas de sistemas y errores de aplicaciones.
curl http://www.official-joke-api.appspot.com/random_joke
{"type":"general",
"setup":"What did the fish say when it hit the wall?","punchline":"Dam.","id":1}
- Por ejemplo, puede usar
http://www.official-joke-api.appspot.com/para experimentar con el comandocurl.
curl -o random_joke.json http://www.official-joke-api.appspot.com/random_joke
El comando curl sin ninguna opción utiliza el método GET por defecto.
curl -oguarda la salida en el archivo mencionado.
curl -I http://www.official-joke-api.appspot.com/random_joke
HTTP/1.1 200 OK
Content-Type: application/json; charset=utf-8
Vary: Accept-Encoding
X-Powered-By: Express
Access-Control-Allow-Origin: *
ETag: W/"71-NaOSpKuq8ChoxdHD24M0lrA+JXA"
X-Cloud-Trace-Context: 2653a86b36b8b131df37716f8b2dd44f
Content-Length: 113
Date: Thu, 06 Jun 2024 10:11:50 GMT
Server: Google Frontend
# guarda la salida en random_joke.json
curl -I solo recupera las cabeceras.
8.8. Solución de problemas en Linux: herramientas y técnicas
Informe de actividad del sistema con sar
El comando sar en Linux es una herramienta poderosa para recopilar, informar y guardar información de actividad del sistema. Forma parte del paquete sysstat y es ampliamente utilizado para monitorear la actividad de desempeño del sistema en el tiempo.
Para utilizar sar necesitas primero instalar sysstat mediante sudo apt install sysstat.
Una vez instalado, inicia el servicio con sudo systemctl start sysstat.
Verifica el estado con sudo systemctl status sysstat.
sar [options] [interval] [count]
Una vez que el estado sea activo, el sistema comenzará a recolectar varias estadísticas que puedes usar para acceder y analizar datos históricos. Veremos esto en detalle pronto.
sar -u 1 3
La sintaxis del comando sar es la siguiente:
Linux 6.5.0-28-generic (zaira-ThinkPad) 04/06/24 _x86_64_ (12 CPU)
19:09:26 CPU %user %nice %system %iowait %steal %idle
19:09:27 all 3.78 0.00 2.18 0.08 0.00 93.96
19:09:28 all 4.02 0.00 2.01 0.08 0.00 93.89
19:09:29 all 6.89 0.00 2.10 0.00 0.00 91.01
Average: all 4.89 0.00 2.10 0.06 0.00 92.95
Por ejemplo, sar -u 1 3 mostrará estadísticas de utilización de CPU cada segundo tres veces.
# Salida
Aquí están algunos casos de uso comunes y ejemplos de cómo utilizar el comando sar.
El sar se puede utilizar para diversos propósitos:
sar -r 1 3
Linux 6.5.0-28-generic (zaira-ThinkPad) 04/06/24 _x86_64_ (12 CPU)
19:10:46 kbmemfree kbavail kbmemused %memused kbbuffers kbcached kbcommit %commit kbactive kbinact kbdirty
19:10:47 4600104 8934352 5502124 36.32 375844 4158352 15532012 65.99 6830564 2481260 264
19:10:48 4644668 8978940 5450252 35.98 375852 4165648 15549184 66.06 6776388 2481284 36
19:10:49 4646548 8980860 5448328 35.97 375860 4165648 15549224 66.06 6774368 2481292 116
Average: 4630440 8964717 5466901 36.09 375852 4163216 15543473 66.04 6793773 2481279 139
1. Utilización de memoria
Para verificar la utilización de memoria (libre y usada), utiliza:
Este comando muestra estadísticas de memoria cada segundo tres veces.
sar -S 1 3
sar -S 1 3
Linux 6.5.0-28-generic (zaira-ThinkPad) 04/06/24 _x86_64_ (12 CPU)
19:11:20 kbswpfree kbswpused %swpused kbswpcad %swpcad
19:11:21 8388604 0 0.00 0 0.00
19:11:22 8388604 0 0.00 0 0.00
19:11:23 8388604 0 0.00 0 0.00
Average: 8388604 0 0.00 0 0.00
2. Utilización del espacio de swap
Para ver estadísticas de utilización del espacio de swap, utiliza:
Este comando ayuda a monitorear el uso de swap, lo cual es crucial para sistemas que se están agotando del memoria física.
sar -d 1 3
3. Carga de dispositivos de E/S
Para informar la actividad de los dispositivos de bloques y las particiones de dispositivos de bloques:
Este comando proporciona estadísticas detalladas sobre las transferencias de datos hacia y desde los dispositivos de bloques, y es útil para diagnosticar las válvulas de E/S.
sar -n DEV 1 3
5. Estadísticas de red
sar -n DEV 1 3
Linux 6.5.0-28-generic (zaira-ThinkPad) 04/06/24 _x86_64_ (12 CPU)
19:12:47 IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s %ifutil
19:12:48 lo 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
19:12:48 enp2s0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
19:12:48 wlp3s0 10.00 3.00 1.83 0.37 0.00 0.00 0.00 0.00
19:12:48 br-5129d04f972f 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
.
.
.
Average: IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s %ifutil
Average: lo 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
Average: enp2s0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
...output truncated...
Para ver estadísticas de red, como el número de paquetes recibidos (transmitidos) por la interfaz de red:
# -n DEV indica a sar que informe las interfaces de dispositivos de red
Esto muestra estadísticas de red cada segundo durante tres segundos, ayudando en el monitoreo del tráfico de red.
- 6. Datos históricos
- # son “true” y “false”. No ponga otros valores, serán
- Configurar el intervalo de recopilación de datos: Edite la configuración de la tarea cron para establecer el intervalo de recopilación de datos.
sar -u -f /var/log/sysstat/sa04
Linux 6.5.0-28-generic (zaira-ThinkPad) 04/06/24 _x86_64_ (12 CPU)
15:20:49 LINUX RESTART (12 CPU)
16:13:30 LINUX RESTART (12 CPU)
18:16:00 CPU %user %nice %system %iowait %steal %idle
18:16:01 all 0.25 0.00 0.67 0.08 0.00 99.00
Average: all 0.25 0.00 0.67 0.08 0.00 99.00
Reemplace <DD> con el día del mes para el que desea ver los datos.
En el comando de abajo, /var/log/sysstat/sa04 proporciona estadísticas para el cuarto día del mes actual.
sar -I SUM 1 3
7. Interrupciones de CPU en tiempo real
Linux 6.5.0-28-generic (zaira-ThinkPad) 04/06/24 _x86_64_ (12 CPU)
19:14:22 INTR intr/s
19:14:23 sum 5784.00
19:14:24 sum 5694.00
19:14:25 sum 5795.00
Average: sum 5757.67
Para observar las interrupciones por segundo atendidas por la CPU, use este comando:
# Salida
Este comando ayuda en el monitoreo de la frecuencia con la que la CPU maneja interrupciones, lo cual puede ser crucial para la configuración del rendimiento en tiempo real.
Estos ejemplos ilustran cómo puede utilizar sar para monitorear varios aspectos de desempeño del sistema. El uso regular de sar puede ayudar en la identificación de los cuellos de botella del sistema y en la garantía de que las aplicaciones se ejecutan eficientemente.
8.9. Estrategia general de resolución de problemas para servidores
¿Por qué necesitamos entender el monitoreo?
El monitoreo del sistema es un aspecto importante de la administración del sistema. Aplicaciones críticas exigen un alto nivel de proactividad para prevenir fallas y reducir el impacto de los fallos.
Linux ofrece herramientas muy poderosas para medir la salud del sistema. En esta sección, aprenderá sobre los diversos métodos disponibles para revisar la salud del sistema y identificar los cuellos de botella.
[user@host ~]$ uptime 19:15:00 up 1:04, 0 users, load average: 2.92, 4.48, 5.20
Encuentre la media de carga y el tiempo de actividad del sistema
Pueden ocurrir reinicios del sistema que, a veces, pueden arruinar algunas configuraciones. Para ver cuánto tiempo ha estado funcionando la máquina, use el comando: uptime. Además del tiempo de actividad, el comando también muestra la media de carga.
La media de carga es la carga del sistema durante los últimos 1, 5 y 15 minutos. Una rápida mirada indica si la carga del sistema parece aumentar o disminuir con el tiempo.
Nota: La cola de CPU ideal es 0. Esto solo es posible cuando no hay colas de espera para la CPU.
lscpu
La carga por CPU se puede calcular dividiendo la media de carga por el número total de CPUs disponibles.
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Address sizes: 48 bits physical, 48 bits virtual
Byte Order: Little Endian
CPU(s): 12
On-line CPU(s) list: 0-11
.
.
.
output omitted
Para encontrar el número de CPUs, use el comando lscpu.
# output
Si la media de carga parece aumentar y no disminuye, las CPU están sobrecargadas. Hay algún proceso bloqueado o hay una pérdida de memoria.
free -mh
Calculando memoria libre
total used free shared buff/cache available
Mem: 14Gi 3.5Gi 7.7Gi 109Mi 3.2Gi 10Gi
Swap: 8.0Gi 0B 8.0Gi
A veces, un alto uso de memoria podría estar causando problemas. Para ver la memoria disponible y la memoria en uso, use el comando free.
# output
Calculando espacio en disco
df -h
Filesystem Size Used Avail Use% Mounted on
tmpfs 1.5G 2.4M 1.5G 1% /run
/dev/nvme0n1p2 103G 34G 65G 35% /
tmpfs 7.3G 42M 7.2G 1% /dev/shm
tmpfs 5.0M 4.0K 5.0M 1% /run/lock
efivarfs 246K 93K 149K 39% /sys/firmware/efi/efivars
/dev/nvme0n1p3 130G 47G 77G 39% /home
/dev/nvme0n1p1 511M 6.1M 505M 2% /boot/efi
tmpfs 1.5G 140K 1.5G 1% /run/user/1000
Para asegurar que el sistema esté saludable, no olvide el espacio en disco. Para listar todos los puntos de montaje disponibles y su porcentaje respectivo de uso, use el comando de abajo. Idealmente, los espacios en disco utilizados no deberían superar el 80%.
El comando df proporciona detalles del espacio en disco.
Determinando los estados de los procesos
[user@host ~]$ ps aux
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
runner 1 0.1 0.0 1535464 15576 ? S 19:18 0:00 /inject/init
runner 14 0.0 0.0 21484 3836 pts/0 S 19:21 0:00 bash --norc
runner 22 0.0 0.0 37380 3176 pts/0 R+ 19:23 0:00 ps aux
Los estados de los procesos se pueden monitorear para ver si hay algún proceso bloqueado con un uso de memoria o de CPU alto.
Vimos anteriormente que el comando ps proporciona información útil sobre un proceso. Espere un vistazo a las columnas CPU y MEM.
Monitoreo de sistema en tiempo real
El monitoreo en tiempo real ofrece una ventana en el estado real del sistema.
Una herramienta que puede utilizar para hacer esto es el comando top.
El comando top muestra una vista dinámica de los procesos del sistema, mostrando un encabezado resumen seguido de una lista de procesos o hilos. A diferencia de su contraparte estática ps, top actualiza continuamente las estadísticas del sistema.
Con top, puedes ver detalles bien organizados en una ventana compacta. Hay una serie de banderas, atajos y métodos de resaltado que vienen con top.
También puedes matar procesos usando top. Para eso, presiona k y luego introduce el ID del proceso.
La interpretación de logs
Los logs del sistema y de aplicaciones llevan montones de información sobre lo que está pasando con el sistema. Contienen información útil y códigos de error que señalan errores. Si buscas códigos de error en los logs, la identificación de problemas y el tiempo de corrección pueden reducirse notablemente.
Análisis de puertos de red
No se debe ignorar el aspecto de red ya que los problemas de red son comunes y pueden afectar al sistema y las flujos de tráfico. Los problemas de red comunes incluyen agotamiento de puertos, bloqueo de puertos, recursos no liberados, y cosas así.
| Para identificar esos problemas, necesitamos entender los estados de los puertos. | Algunos de los estados de los puertos se explican brevemente aquí: |
| Estado | Descripción |
| ESCUCHA | Representa puertos que están esperando una solicitud de conexión de cualquier TCP remoto y puerto. |
| ESTABLECIDO | Representa conexiones abiertas en las que el flujo de datos recibidos puede entregarse a la destinación. |
| ESPERA | Representa el tiempo de espera para asegurar la confirmación de su solicitud de finalización de conexión. |
ESPERA_FIN2
Representa la espera de una solicitud de finalización de conexión del TCP remoto.
[user@host ~]$ /sbin/sysctl net.ipv4.ip_local_port_range
net.ipv4.ip_local_port_range = 15000 65000
Examinemos cómo podemos analizar información relacionada con puertos en Linux.
Intervallos de puertos: Los intervalos de puertos están definidos en el sistema y pueden ser aumentados o disminuidos según sea necesario. En el fragmento de texto siguiente, el intervalo es de 15000 a 65000, lo que resulta en un total de 50000 (65000 – 15000) puertos disponibles. Si los puertos utilizados alcanzan o superan este límite, entonces hay un problema.
El error reportado en los registros en tales casos puede ser Falló al intentar asociar el puerto o Demasiadas conexiones.
Identificar pérdida de paquetes
En el monitoreo del sistema, debemos asegurarnos que la comunicación de salida y entrada estén intactas.
[user@host ~]$ ping 10.13.6.113
PING 10.13.6.141 (10.13.6.141) 56(84) bytes of data.
64 bytes from 10.13.6.113: icmp_seq=1 ttl=128 time=0.652 ms
64 bytes from 10.13.6.113: icmp_seq=2 ttl=128 time=0.593 ms
64 bytes from 10.13.6.113: icmp_seq=3 ttl=128 time=0.478 ms
64 bytes from 10.13.6.113: icmp_seq=4 ttl=128 time=0.384 ms
64 bytes from 10.13.6.113: icmp_seq=5 ttl=128 time=0.432 ms
64 bytes from 10.13.6.113: icmp_seq=6 ttl=128 time=0.747 ms
64 bytes from 10.13.6.113: icmp_seq=7 ttl=128 time=0.379 ms
^C
--- 10.13.6.113 ping statistics ---
7 packets transmitted, 7 received,0% packet loss, time 6001ms
rtt min/avg/max/mdev = 0.379/0.523/0.747/0.134 ms
Un comando útil es ping. ping impacta el sistema de destino y trae la respuesta de vuelta. Tenga en cuenta las últimas líneas de estadísticas que muestran el porcentaje de pérdida de paquetes y el tiempo.
# ping IP de destino
Los paquetes también pueden ser capturados en tiempo de ejecución utilizando tcpdump. Lo examinaremos más adelante.
Recopilación de estadísticas para un post mortem de problemas
- Siempre es una buena práctica recopilar ciertas estadísticas que resultarán útiles para identificar la causa raíz posteriormente. Normalmente, después del reinicio del sistema o del reinicio de servicios, se pierde la captura anterior del sistema y los registros.
A continuación se enumeran algunos de los métodos para capturar la instantánea del sistema.
- Respaldo de registros
Antes de realizar cualquier cambio, copie los archivos de registro a otro lugar. Esto es fundamental para comprender qué condición tenía el sistema en el momento del incidente. A veces los archivos de registro son la única ventana para ver las condiciones del sistema pasadas ya que otras estadísticas de tiempo de ejecución se pierden.
sudo tcpdump -i any -w
Captura de Paquetes TCP
Tcpdump es una utilidad de línea de comandos que le permite capturar y analizar el tráfico de red entrante y saliente. Se utiliza principalmente para ayudar a resolver problemas de red. Si cree que el tráfico del sistema está siendo afectado, use tcpdump como sigue:
# Donde,
# -i any captura el tráfico de todas las interfaces
# -w especifica el nombre del archivo de salida
# Detenga el comando después de unos minutos ya que el tamaño del archivo puede aumentar
# Use la extensión de archivo como .pcap
Una vez que se haya capturado tcpdump, puede utilizar herramientas como Wireshark para analizar visualmente el tráfico.
Conclusión
Gracias por leer el libro hasta el final. Si lo encontró útil, considere compartirlo con otros.
Este libro no termina aquí, sin embargo. Continuaré mejorándolo y agregando materiales nuevos en el futuro. Si encontró algún problema o si le gustaría sugerir alguna mejora, no dude en abrir un PR/Incidencia.
- ¡Sigue conectado y continúa tu viaje de aprendizaje!
-
LinkedIn: Allí comparto artículos y publicaciones sobre tecnología. Deja una recomendación en LinkedIn y endósuite conmigo en habilidades relevantes.
Obtén acceso a contenido exclusivo: Para ayuda personalizada y contenido exclusivo, ve aquí.
Obtén acceso a contenido exclusivo: Para ayuda personalizada y contenido exclusivo, ve aquí.
Source:
https://www.freecodecamp.org/news/learn-linux-for-beginners-book-basic-to-advanced/