













Los grandes datos han evolucionado significativamente desde su inicio a finales de la década de 2000. Muchas organizaciones se adaptaron rápidamente a la tendencia y construyeron sus plataformas de big data utilizando herramientas de código abierto como Apache Hadoop. Más tarde, estas empresas comenzaron a enfrentar dificultades para gestionar las necesidades de procesamiento de datos en rápida evolución. Han enfrentado desafíos para manejar cambios a nivel de esquema, evolución de esquemas de partición y retroceder en el tiempo para observar los datos.
Yo enfrenté desafíos similares mientras diseñaba sistemas distribuidos a gran escala en la década de 2010 para una gran empresa tecnológica y un cliente del sector salud. Algunas industrias necesitan estas capacidades para cumplir con las regulaciones bancarias, financieras y de salud. Empresas intensamente basadas en datos como Netflix también enfrentaron desafíos similares. Inventaron un formato de tabla llamado “Iceberg”, que se sitúa sobre los archivos de datos existentes y ofrece características clave aprovechando su arquitectura. Esto se ha convertido rápidamente en el principal proyecto de ASF, ya que ganó un rápido interés en la comunidad de datos. Exploraré las 5 principales características clave de Apache Iceberg en este artículo con ejemplos y diagramas.
1. Viaje en el tiempo

Figura 1: Viaje en el tiempo en el formato de tabla de Apache Iceberg (imagen creada por el autor)
Esta función te permite consultar tus datos tal como existen en cualquier momento. Esto abrirá nuevas posibilidades para los analistas de datos y de negocios para entender las tendencias y cómo los datos evolucionaron a lo largo del tiempo. Puedes retroceder sin esfuerzo a un estado anterior en caso de errores. Esta función también facilita las auditorías al permitirte analizar los datos en un momento específico.
-- time travel to October 5th, 1978 at 07:00:00
SELECT * FROM prod.retail.cusotmers TIMESTAMP AS OF '1978-10-05 07:00:00';
-- time travel using a specific snapshot ID:
SELECT * FROM prod.retail.customers VERSON AS OF 949530903748831869;
2. Evolución del Esquema
La evolución del esquema de Apache Iceberg permite cambios en tu esquema sin ningún gran esfuerzo o migraciones costosas. A medida que tus necesidades comerciales evolucionan, puedes:
- Agregar y eliminar columnas sin tiempo de inactividad ni reescrituras de tablas.
- Actualizar la columna (ampliación).
- Cambiar el orden de las columnas.
- Renombrar una columna existente.
Estos cambios se manejan a nivel de metadatos sin necesidad de reescribir los datos subyacentes.
-- add a new column to the table
ALTER TABLE prod.retail.customers ADD COLUMNS (email_address STRING);
-- remove an existing column from the table
ALTER TABLE prod.retail.customers DROP COLUMN num_of_years;
-- rename an existing column
ALTER TABLE prod.retail.customers RENAME COLUMN email_address TO email;
-- iceberg allows updating column types from int to bigint, float to double
ALTER TABLE prod.retail.customers ALTER COLUMN customer_id TYPE bigint;
3. Evolución de Particiones
Usando el formato de tabla de Apache Iceberg, puedes cambiar la estrategia de particionamiento de la tabla sin reescribir la tabla subyacente ni migrar los datos a una nueva tabla. Esto es posible ya que las consultas no hacen referencia a los valores de partición directamente como en Apache Hadoop. Iceberg mantiene la información de metadatos para cada versión de partición por separado. Esto facilita la obtención de las divisiones al consultar los datos. Por ejemplo, consultar una tabla basada en el rango de fechas, mientras que la tabla usaba el mes como columna de partición (antes) como una división y el día como una nueva columna de partición (después) como otra división. Esto se llama planificación de divisiones. Consulta el ejemplo a continuación.
-- create customers table partitioned by month of the create_date initially
CREATE TABLE local.retail.customer (
id BIGINT,
name STRING,
street STRING,
city STRING,
state STRING,
create_date DATE
USING iceberg
PARTITIONED BY (month(create_date));
-- insert some data into the table
INSERT INTO local.retail.customer VALUES
(1, 'Alice', '123 Maple St', 'Springfield', 'IL', DATE('2024-01-10')),
(2, 'Bob', '456 Oak St', 'Salem', 'OR', DATE('2024-02-15')),
(3, 'Charlie', '789 Pine St', 'Austin', 'TX', DATE('2024-02-20'));
-- change the partition scheme from month to date
ALTER TABLE local.retail.customer
REPLACE PARTITION FIELD month(create_date) WITH days(create_date);
-- insert couple more records
INSERT INTO local.retail.customer VALUES
(4, 'David', '987 Elm St', 'Portland', 'ME', DATE('2024-03-01')),
(5, 'Eve', '654 Birch St', 'Miami', 'FL', DATE('2024-03-02'));
-- select all columns from the table
SELECT * FROM local.retail.customer
WHERE create_date BETWEEN DATE('2024-01-01') AND DATE('2024-03-31');
-- output
1 Alice 123 Maple St Springfield IL 2024-01-10
5 Eve 654 Birch St Miami FL 2024-03-02
4 David 987 Elm St Portland ME 2024-03-01
2 Bob 456 Oak St Salem OR 2024-02-15
3 Charlie 789 Pine St Austin TX 2024-02-20
-- View parition details
SELECT partition, file_path, record_count
FROM local.retail.customer.files;
-- output
{"create_date_month":null,"create_date_day":2024-03-02} /Users/rellaturi/warehouse/retail/customer/data/create_date_day=2024-03-02/00000-6-ae2fdf0d-5567-4c77-9bd1-a5d9f6c83dfe-0-00002.parquet 1
{"create_date_month":null,"create_date_day":2024-03-01} /Users/rvellaturi/warehouse/retail/customer/data/create_date_day=2024-03-01/00000-6-ae2fdf0d-5567-4c77-9bd1-a5d9f6c83dfe-0-00001.parquet 1
{"create_date_month":648,"create_date_day":null} /Users/rvellaturi/warehouse/retail/customer/data/create_date_month=2024-01/00000-3-64c8b711-f757-45b4-828f-553ae9779d14-0-00001.parquet 1
{"create_date_month":649,"create_date_day":null} /Users/rvellaturi/warehouse/retail/customer/data/create_date_month=2024-02/00000-3-64c8b711-f757-45b4-828f-553ae9779d14-0-00002.parquet 2
4. Transacciones ACID
Iceberg proporciona un sólido soporte para transacciones en términos de Atomicidad, Consistencia, Aislamiento y Durabilidad (ACID). Permite múltiples operaciones de escritura concurrentes, lo que habilita un alto rendimiento en trabajos intensivos en datos sin comprometer la consistencia de los mismos.
-- Start a transaction
START TRANSACTION;
-- Insert new records
INSERT INTO customers VALUES (1, 'John'), (2, 'Mike');
-- Update existing records
UPDATE customers SET column1 = 'Josh' WHERE id = 1;
-- Delete records
DELETE FROM customers WHERE id = 2;
-- Commit the transaction
COMMIT;
Todas las operaciones en Iceberg son transaccionales, lo que significa que los datos permanecen consistentes a pesar de fallos o modificaciones a los datos de manera concurrente.
-- Atomic update across multiple tables
START TRANSACTION;
UPDATE orders SET status = 'processed' WHERE order_id = 100;
INSERT INTO orders_processed SELECT * FROM orders WHERE order_id = 100;
COMMIT;
También soporta diferentes niveles de aislamiento, lo que te permite equilibrar el rendimiento y la consistencia según los requisitos.
-- Set isolation level (syntax may vary depending on the query engine)
SET TRANSACTION ISOLATION LEVEL SERIALIZABLE;
-- Perform operations
SELECT * FROM customers WHERE id = 1;
UPDATE customers SET rec_status= 'updated' WHERE id = 1;
COMMIT;
A continuación se presenta un resumen que muestra cómo Iceberg maneja las actualizaciones y eliminaciones a nivel de fila.
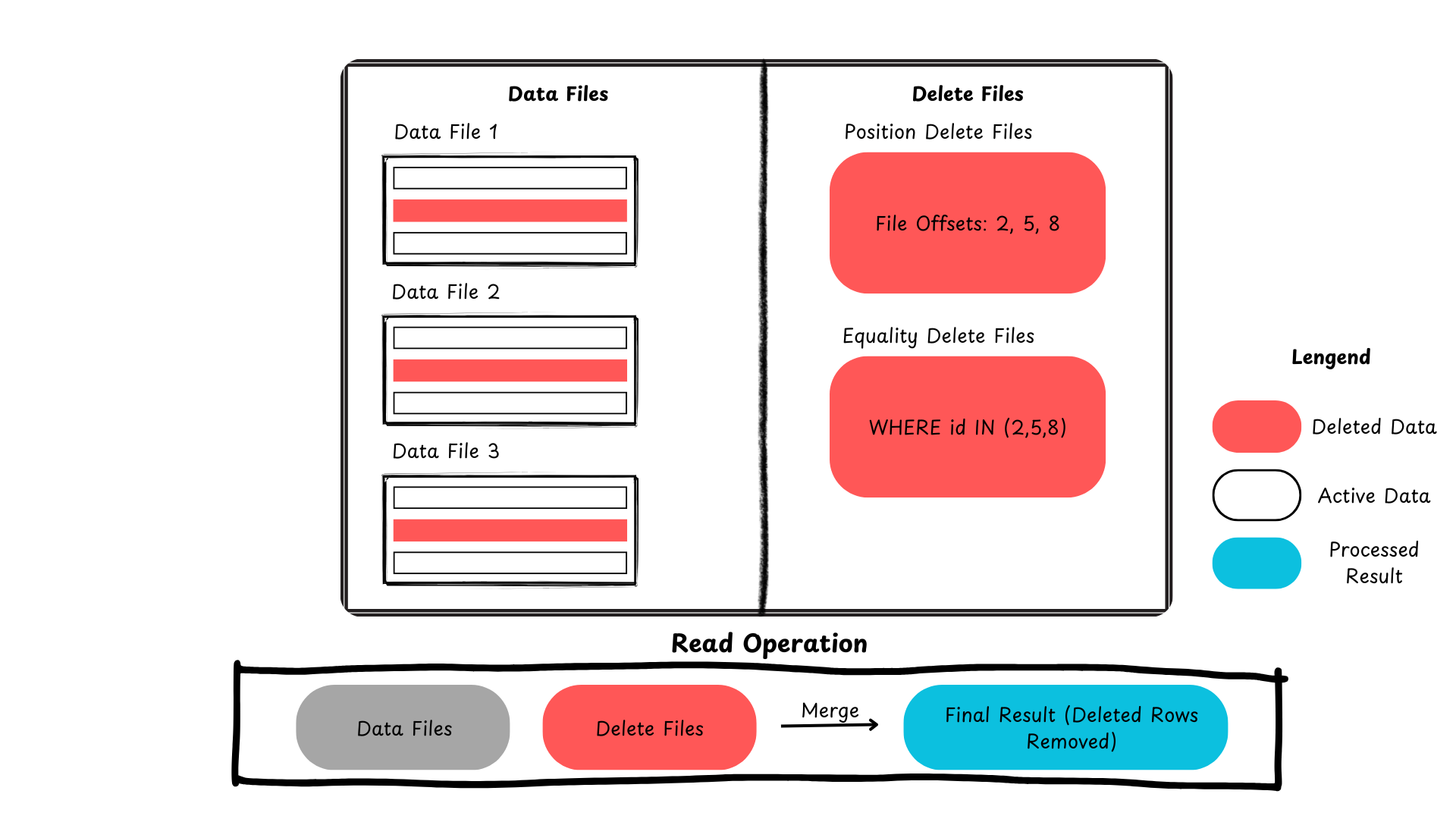
Figura 2: Proceso de eliminación de registros en Apache Iceberg (imagen creada por el autor)
5. Operaciones Avanzadas de Tablas
Iceberg soporta operaciones avanzadas de tablas como:
- Creación/gestión de instantáneas de tablas: Esto otorga la capacidad de tener un control de versiones robusto.
- Planificación y ejecución de consultas rápidas con su metadato altamente optimizado
- Herramientas integradas para el mantenimiento de tablas, como la compactación y la limpieza de archivos huérfanos
Iceberg está diseñado para trabajar con todos los principales almacenamiento en la nube, como AWS S3, GCS y Azure Blob Storage. Además, Iceberg se integra fácilmente con motores de procesamiento de datos como Spark, Presto, Trino y Hive.
Reflexiones Finales
Estas características destacadas permiten a las empresas construir lagos de datos modernos, flexibles, escalables y eficientes, que pueden viajar en el tiempo, manejar fácilmente cambios de esquema, soportar transacciones ACID y evolución de particiones.
Source:
https://dzone.com/articles/key-features-of-apache-iceberg-for-data-lakes