













¿Qué es Elasticsearch?
Elasticsearch es un motor de búsqueda y análisis altamente escalable y distribuido que se basa en la biblioteca de búsqueda Apache Lucene. Está diseñado para manejar grandes volúmenes de datos estructurados, semiestructurados y no estructurados, lo que lo hace ideal para una amplia gama de casos de uso, incluidos motores de búsqueda, análisis de registros, comercio electrónico y análisis de seguridad.
Elasticsearch utiliza una arquitectura distribuida que permite almacenar y procesar grandes volúmenes de datos en múltiples nodos de un clúster. Los datos se indexan y almacenan en fragmentos, que se distribuyen entre los nodos para mejorar la escalabilidad y la tolerancia a fallos. Elasticsearch también admite búsquedas y análisis en tiempo real, lo que permite a los usuarios consultar y analizar datos casi en tiempo real.
Una de las características clave de Elasticsearch es su potente capacidad de búsqueda. Admite una amplia gama de consultas de búsqueda, incluyendo búsqueda de texto completo, búsqueda geoespacial, etc. También proporciona soporte para características de análisis avanzadas como agregaciones, métricas y visualización de datos.
Elasticsearch se utiliza a menudo en conjunto con otras herramientas en el Stack Elastic, incluyendo Logstash para la recopilación y procesamiento de datos y Kibana para la visualización y análisis de datos. Juntas, estas herramientas proporcionan una solución integral para la búsqueda y análisis que puede ser utilizada para una amplia gama de aplicaciones y casos de uso.
¿Qué es Apache Lucene?
Apache Lucene es una biblioteca de búsqueda de código abierto que proporciona capacidades de búsqueda y indexación de texto potentes. Es ampliamente utilizado por desarrolladores y organizaciones para construir aplicaciones de búsqueda, que van desde motores de búsqueda hasta plataformas de comercio electrónico.
Lucene funciona indexando el contenido textual de documentos y almacenando el índice en un formato estructurado que puede ser buscado de manera eficiente. El índice se compone de una serie de listas invertidas, que proporcionan mapeos entre términos y los documentos que los contienen. Cuando se presenta una consulta de búsqueda, Lucene utiliza el índice para recuperar rápidamente los documentos que coinciden con la consulta.
Además de sus capacidades de búsqueda y indexación centrales, Lucene proporciona una gama de características avanzadas, incluyendo soporte para búsquedas difusas y búsquedas espaciales. También proporciona herramientas para resaltar resultados de búsqueda y clasificar resultados de búsqueda basándose en relevancia.
Lucene es utilizado por una amplia gama de organizaciones y proyectos, incluyendo Elasticsearch. Su conjunto rico de características, flexibilidad y extensibilidad lo hacen una opción popular para construir aplicaciones de búsqueda de todo tipo.
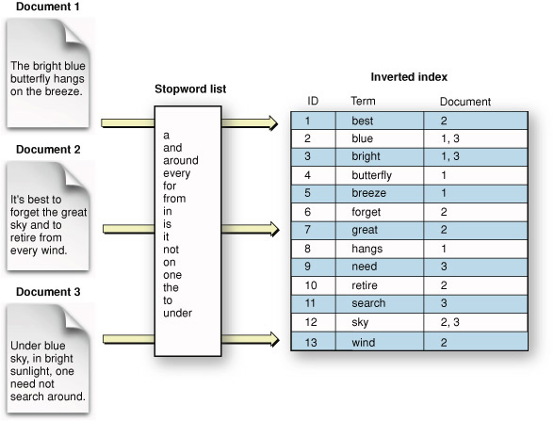
¿Qué es el Índice Invertido?
El Índice Invertido de Lucene es una estructura de datos utilizada para buscar y recuperar de manera eficiente datos de texto de una colección de documentos. El Índice Invertido es una característica central de Lucene y se utiliza para almacenar los términos y sus documentos asociados que conforman el índice.
El Índice Invertido ofrece varios beneficios en comparación con otras estrategias de búsqueda. Primero, permite la recuperación rápida y eficiente de documentos basados en términos de búsqueda. Segundo, puede manejar una gran cantidad de datos de texto, lo que lo hace ideal para casos de uso con grandes colecciones de documentos. Finalmente, admite una amplia gama de características de búsqueda avanzadas, como coincidencia difusa y stemming, que pueden mejorar la precisión y relevancia de los resultados de búsqueda.
¿Por qué Elasticsearch?
Existen varias razones por las que Elasticsearch es una opción popular para construir aplicaciones de búsqueda y análisis:
Fácil de escalar (Distribuido): Elasticsearch está diseñado para escalar horizontalmente de forma predeterminada. Cuando necesite aumentar la capacidad, simplemente agregue más nodos y deje que el clúster se reorganice para aprovechar el hardware adicional.
Un servidor puede contener una o más partes de uno o más índices, y cada vez que se introducen nuevos nodos al clúster, simplemente se están sumando a la fiesta. Cada uno de estos índices, o parte de él, se llama un shard, y los shards de Elasticsearch pueden moverse fácilmente alrededor del clúster.
Todo está a una llamada JSON (API RESTful): Elasticsearch es impulsado por API. Casi cualquier acción se puede realizar utilizando una API RESTful simple que utiliza JSON sobre HTTP. Las respuestas siempre están en formato JSON.
Potencia liberada de Lucene bajo el capó: Elasticsearch emplea internamente Lucene para desarrollar sus avanzadas capacidades de búsqueda distribuida y análisis. Dado que Lucene es una tecnología estable y probada, y se le añaden constantemente más características y buenas prácticas, tener a Lucene como motor subyacente que impulsa a Elasticsearch.
Excelente DSL de consulta: La API REST expone un DSL de consulta muy complejo y capaz que resulta muy fácil de utilizar. Cada consulta es simplemente un objeto JSON que puede contener prácticamente cualquier tipo de consulta o incluso varias de ellas combinadas. El uso de consultas filtradas, con algunas consultas expresadas como filtros de Lucene, ayuda a aprovechar la caché y, por tanto, acelera las consultas comunes o las complejas con partes que pueden reutilizarse.
Multi-inquilinado: Se pueden almacenar múltiples índices en una instalación de Elasticsearch – nodo o clúster. Lo bueno es que puedes consultar múltiples índices con una sola consulta simple.
Soporte para características avanzadas de búsqueda (Texto completo): Elasticsearch utiliza a Lucene bajo el capó para ofrecer las capacidades de búsqueda de texto completo más potentes disponibles en cualquier producto de código abierto. La búsqueda cuenta con soporte multilingüe, un lenguaje de consulta potente, soporte para geolocalización, sugerencias did-you-mean contextuales, autocompletar y fragmentos de búsqueda. Soporte de scripts en filtros y puntuadores.
Configurable y Extensible: Muchas configuraciones de Elasticsearch pueden cambiarse mientras Elasticsearch está en ejecución, pero algunas requerirán un reinicio (e, en algunos casos, reindexación). La mayoría de las configuraciones también pueden modificarse mediante la API REST.
Orientado a documentos: Almacene entidades del mundo real complejas en Elasticsearch como documentos JSON estructurados. Todos los campos se indexan de forma predeterminada, y todos los índices pueden utilizarse en una sola consulta para devolver resultados a una velocidad impresionante.
Sin esquema: Elasticsearch te permite comenzar fácilmente. Envía un documento JSON, e intentará detectar la estructura de datos, indexar los datos y hacerlos accesibles para la búsqueda.
Gestión de conflictos: Se puede utilizar el control de versiones optimista donde sea necesario para garantizar que los datos nunca se pierden debido a cambios conflictivos de múltiples procesos.
Comunidad activa: Además de crear buenos herramientas y complementos, la comunidad es muy útil y solidaria. El ambiente general es excelente, y este es un importante indicador de cualquier proyecto de OSS. También hay algunos libros actualmente en redacción por miembros de la comunidad y muchos artículos de blog en la red compartiendo experiencias y conocimientos.
Arquitectura de Elasticsearch
Los componentes principales de la arquitectura de Elasticsearch son:
Nodo: Un nodo es una instancia de Elasticsearch que almacena datos y proporciona capacidades de búsqueda e indexación. Los nodos pueden configurarse para ser un nodo maestro o un nodo de datos, o ambos. Los nodos maestros son responsables de la gestión a nivel de clúster, mientras que los nodos de datos almacenan los datos y realizan operaciones de búsqueda.
Clúster: Un clúster es un grupo de uno o más nodos que trabajan juntos para almacenar y procesar datos. Un clúster puede contener múltiples índices (colecciones de documentos) y fragmentos (una forma de distribuir datos entre varios nodos).
Índice: Un índice es una colección de documentos que comparten una estructura similar. Cada documento se representa como un objeto JSON y contiene uno o más campos. Elasticsearch indexa todos los campos de forma predeterminada, lo que facilita la búsqueda y el análisis de datos.
Fragmentos: Un índice puede dividirse en múltiples fragmentos, que son esencialmente subconjuntos más pequeños del índice. El fragmentado permite el procesamiento paralelo de datos y el almacenamiento distribuido en múltiples nodos.
Replicas: Elasticsearch puede crear copias de cada fragmento para proporcionar tolerancia a fallos y alta disponibilidad. Las copias son réplicas del fragmento original y pueden estar ubicadas en diferentes nodos.
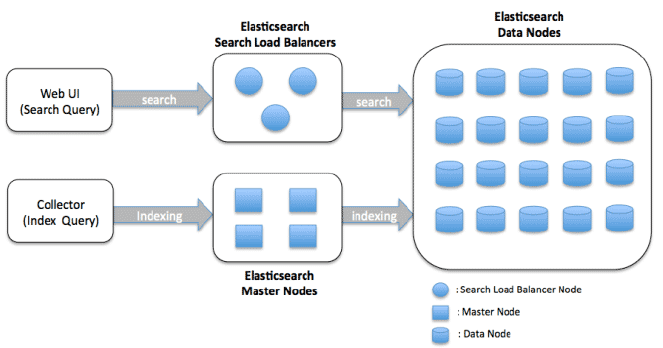
Arquitectura de Clúster de Nodos de Datos
Los nodos de datos son responsables de almacenar e indexar datos, así como de realizar operaciones de búsqueda y agregación. La arquitectura está diseñada para ser escalable y distribuida, lo que permite escalar horizontalmente agregando más nodos al clúster.
A continuación se presentan los componentes principales de una arquitectura de clúster de nodos de datos de Elasticsearch:
Nodo de Datos: Un nodo es una instancia de Elasticsearch que almacena datos y proporciona capacidades de búsqueda e indexación. En un clúster de nodos de datos, cada nodo es responsable de almacenar una porción de los datos del índice y de servir consultas de búsqueda en relación con esos datos.
Estado del Clúster: El estado del clúster es una estructura de datos que contiene información sobre el clúster, incluyendo la lista de nodos, índices, fragmentos y sus ubicaciones. El nodo maestro es responsable de mantener el estado del clúster y distribuirlo a todos los demás nodos en el clúster.
Descubrimiento y transporte: Los nodos en un clúster de Elasticsearch se comunican entre sí utilizando dos protocolos: descubrimiento y transporte. El protocolo de descubrimiento se encarga de descubrir nuevos nodos que se unen al clúster o nodos que han dejado el clúster. El protocolo de transporte se encarga de enviar y recibir datos entre nodos.
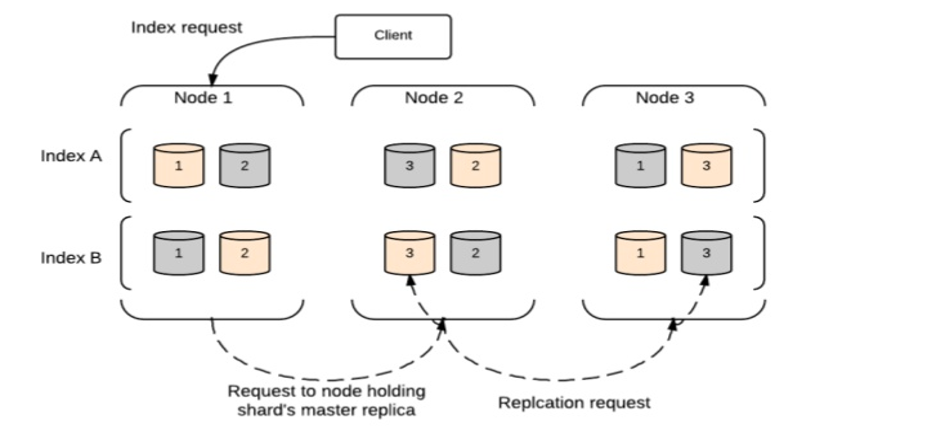
Solicitud de índice
La solicitud de índice se ejecuta como se muestra en el siguiente diagrama de bloques en Elasticsearch.
¿Quién está usando Elasticsearch?
Pocas empresas y organizaciones que utilizan Elasticsearch:
Netflix: Netflix utiliza Elasticsearch para impulsar su motor de búsqueda y recomendaciones, permitiendo a los usuarios encontrar rápidamente contenido para ver.
GitHub: GitHub utiliza Elasticsearch para proporcionar capacidades de búsqueda rápida y eficiente en sus repositorios de código, problemas y solicitudes de extracción.
Uber: Uber utiliza Elasticsearch para impulsar su plataforma de análisis en tiempo real, permitiéndoles rastrear y analizar datos sobre su servicio de alquiler de viajes en tiempo real.
Wikipedia: Wikipedia utiliza Elasticsearch para impulsar su motor de búsqueda y proporcionar resultados de búsqueda rápidos y precisos a los usuarios.
Source:
https://dzone.com/articles/introduction-to-elasticsearch-1