













Estado: Obsoleto
Este artículo está obsoleto y ya no se mantiene.
Razón
Los pasos en este tutorial aún funcionan, pero producirán una configuración que ahora es innecesariamente difícil de mantener.
Ver en su lugar
Este artículo aún puede ser útil como referencia, pero puede que no siga las mejores prácticas. Recomendamos encarecidamente usar un artículo más reciente.
Introducción
Junto con el rastreo y el registro, el monitoreo y la alerta son componentes esenciales de un conjunto de observabilidad de Kubernetes. Configurar el monitoreo para su clúster de Kubernetes de DigitalOcean le permite rastrear el uso de recursos, analizar y depurar errores de aplicaciones.
A monitoring system usually consists of a time-series database that houses metric data and a visualization layer. In addition, an alerting layer creates and manages alerts, handing them off to integrations and external services as necessary. Finally, one or more components generate or expose the metric data that will be stored, visualized, and processed for alerts by the stack.
Una solución de monitoreo popular es el conjunto de código abierto Prometheus, Grafana y Alertmanager, implementado junto con kube-state-metrics y node_exporter para exponer métricas de objetos de Kubernetes a nivel de clúster, así como métricas a nivel de máquina como el uso de CPU y memoria.
Implementar este conjunto de monitoreo en un clúster de Kubernetes requiere configurar componentes individuales, manifiestos, métricas de Prometheus y paneles de Grafana, lo que puede llevar algún tiempo. El Inicio rápido de Monitoreo de Clúster de Kubernetes de DigitalOcean, lanzado por el equipo de Educación de Desarrolladores de la Comunidad de DigitalOcean, contiene manifiestos totalmente definidos para un conjunto de monitoreo de clúster de Prometheus-Grafana-Alertmanager, así como un conjunto de alertas preconfiguradas y paneles de Grafana. Puede ayudarlo a comenzar rápidamente y forma una base sólida desde la cual construir su conjunto de observabilidad.
En este tutorial, implementaremos este conjunto preconfigurado en Kubernetes de DigitalOcean, accederemos a las interfaces de Prometheus, Grafana y Alertmanager, y describiremos cómo personalizarlo.
Prerrequisitos
Antes de comenzar, necesitarás un clúster de Kubernetes de DigitalOcean disponible para ti, y las siguientes herramientas instaladas en tu entorno de desarrollo local:
- La interfaz de línea de comandos
kubectlinstalada en tu máquina local y configurada para conectarse a tu clúster. Puedes leer más sobre cómo instalar y configurarkubectlen su documentación oficial. - El sistema de control de versiones git instalado en tu máquina local. Para aprender cómo instalar git en Ubuntu 18.04, consulta Cómo instalar Git en Ubuntu 18.04.
- La herramienta base64 de Coreutils instalada en tu máquina local. Si estás utilizando una máquina Linux, es probable que ya esté instalada. Si estás utilizando OS X, puedes usar
openssl base64, que viene instalado por defecto.
<$>[nota]
Nota: El inicio rápido de monitoreo del clúster solo ha sido probado en clústeres de Kubernetes de DigitalOcean. Para utilizar el inicio rápido con otros clústeres de Kubernetes, puede ser necesario realizar algunas modificaciones en los archivos de manifiesto.
<$>
Paso 1 — Clonar el Repositorio de GitHub y Configurar Variables de Entorno
Para empezar, clona el repositorio de GitHub de Monitoreo de Clúster de Kubernetes de DigitalOcean en tu máquina local usando git:
Luego, navega hasta el repositorio:
Deberías ver la siguiente estructura de directorios:
OutputLICENSE
README.md
changes.txt
manifest
El directorio manifest contiene manifiestos de Kubernetes para todos los componentes del stack de monitoreo, incluyendo Cuentas de Servicio, Despliegues, Sets de Estados, ConfigMaps, etc. Para aprender más sobre estos archivos de manifiesto y cómo configurarlos, avanza hasta Configurar el Stack de Monitoreo.
Si solo quieres poner las cosas en marcha, comienza configurando las variables de entorno APP_INSTANCE_NAME y NAMESPACE, las cuales se utilizarán para configurar un nombre único para los componentes del stack y configurar el Namespace en el cual se desplegará el stack:
En este tutorial, configuramos APP_INSTANCE_NAME como sammy-cluster-monitoring, lo cual agregará un prefijo a todos los nombres de los objetos Kubernetes del stack de monitoreo. Debes sustituirlo por un prefijo descriptivo único para tu stack de monitoreo. También configuramos el Namespace como default. Si deseas desplegar el stack de monitoreo en un Namespace diferente al default, asegúrate de crearlo primero en tu clúster:
Deberías ver la siguiente salida:
Outputnamespace/sammy created
En este caso, la variable de entorno NAMESPACE se configuró como sammy. A lo largo del resto del tutorial, asumiremos que NAMESPACE ha sido configurado como default.
Ahora, utiliza el comando base64 para codificar en base64 una contraseña segura para Grafana. Asegúrate de sustituir una contraseña de tu elección por tu_contraseña_de_grafana:
Si estás usando macOS, puedes sustituir el comando openssl base64 el cual viene instalado por defecto.
En este punto, has obtenido los manifiestos Kubernetes del stack y configurado las variables de entorno requeridas, así que ahora estás listo para sustituir las variables configuradas en los archivos de manifiesto Kubernetes y crear el stack en tu clúster Kubernetes.
Paso 2 — Creación del Conjunto de Monitoreo
El repositorio de inicio rápido de monitoreo de Kubernetes de DigitalOcean contiene manifiestos para los siguientes componentes de monitoreo, rastreo y visualización:
- Prometheus es una base de datos de series temporales y una herramienta de monitoreo que funciona mediante la obtención de métricas desde puntos finales y el rastreo y procesamiento de los datos expuestos por estos puntos finales. Te permite consultar estos datos utilizando PromQL, un lenguaje de consulta de datos de series temporales. Prometheus se implementará en el clúster como un StatefulSet con 2 réplicas que utiliza Volúmenes Persistentes con Almacenamiento en Bloque de DigitalOcean. Además, un conjunto preconfigurado de Alertas, Reglas y Tareas de Prometheus se almacenará como un ConfigMap. Para obtener más información sobre estos, avanza a la sección de Prometheus de Configuración del Conjunto de Monitoreo.
- Alertmanager, generalmente implementado junto con Prometheus, forma la capa de alerta del conjunto, manejando alertas generadas por Prometheus y eliminando duplicados, agrupándolos y enviándolos a integraciones como correo electrónico o PagerDuty. Alertmanager se instalará como un StatefulSet con 2 réplicas. Para obtener más información sobre Alertmanager, consulta Alerting en la documentación de Prometheus.
- Grafana es una herramienta de visualización y análisis de datos que te permite construir paneles y gráficos para tus datos métricos. Grafana se instalará como un StatefulSet con una réplica. Además, un conjunto preconfigurado de paneles generados por kubernetes-mixin se almacenará como un ConfigMap.
- kube-state-metrics es un agente complementario que escucha el servidor de la API de Kubernetes y genera métricas sobre el estado de objetos de Kubernetes como Implementaciones y Pods. Estas métricas se sirven como texto plano en puntos finales HTTP y son consumidas por Prometheus. kube-state-metrics se instalará como un Deployment escalable automáticamente con una réplica.
- node-exporter, un exportador de Prometheus que se ejecuta en nodos del clúster y proporciona métricas del sistema operativo y hardware como uso de CPU y memoria a Prometheus. Estas métricas también se sirven como texto plano en puntos finales HTTP y son consumidas por Prometheus. node-exporter se instalará como un DaemonSet.
Por defecto, junto con el raspado de métricas generadas por node-exporter, kube-state-metrics y los otros componentes enumerados anteriormente, Prometheus se configurará para raspar métricas de los siguientes componentes:
- kube-apiserver, el servidor de la API de Kubernetes.
- kubelet, el agente principal del nodo que interactúa con kube-apiserver para gestionar Pods y contenedores en un nodo.
- cAdvisor, un agente de nodo que descubre contenedores en ejecución y recopila métricas de uso de CPU, memoria, sistema de archivos y red.
Para obtener más información sobre la configuración de estos componentes y trabajos de raspado de Prometheus, avance a Configuración del stack de monitoreo. Ahora sustituiremos las variables de entorno definidas en el paso anterior en los archivos de manifiesto del repositorio y concatenaremos los manifiestos individuales en un solo archivo maestro.
Comienza usando awk y envsubst para completar las variables APP_INSTANCE_NAME, NAMESPACE y GRAFANA_GENERATED_PASSWORD en los archivos de manifiesto del repositorio. Después de sustituir los valores de las variables, los archivos se combinarán y guardarán en un archivo de manifiesto principal llamado sammy-cluster-monitoring_manifest.yaml.
Deberías considerar almacenar este archivo en control de versiones para poder hacer un seguimiento de los cambios en la pila de monitoreo y revertir a versiones anteriores. Si haces esto, asegúrate de eliminar la variable admin-password del archivo para que no subas tu contraseña de Grafana al control de versiones.
Ahora que has generado el archivo de manifiesto principal, usa kubectl apply -f para aplicar el manifiesto y crear la pila en el Namespace que configuraste:
Deberías ver una salida similar a la siguiente:
Outputserviceaccount/alertmanager created
configmap/sammy-cluster-monitoring-alertmanager-config created
service/sammy-cluster-monitoring-alertmanager-operated created
service/sammy-cluster-monitoring-alertmanager created
. . .
clusterrolebinding.rbac.authorization.k8s.io/prometheus created
configmap/sammy-cluster-monitoring-prometheus-config created
service/sammy-cluster-monitoring-prometheus created
statefulset.apps/sammy-cluster-monitoring-prometheus created
Puedes seguir el progreso de implementación de la pila usando kubectl get all. Una vez que todos los componentes de la pila estén RUNNING, puedes acceder a los paneles preconfigurados de Grafana a través de la interfaz web de Grafana.
Paso 3 — Accediendo a Grafana y Explorando los Datos de Métricas
El manifiesto del servicio de Grafana expone Grafana como un Servicio ClusterIP, lo que significa que solo es accesible a través de una dirección IP interna del clúster. Para acceder a Grafana fuera de su clúster de Kubernetes, puede utilizar kubectl patch para actualizar el Servicio en su lugar a un tipo orientado al público como NodePort o LoadBalancer, o kubectl port-forward para reenviar un puerto local a un puerto de Pod de Grafana. En este tutorial reenviaremos puertos, así que puede saltar a Reenvío de un Puerto Local para Acceder al Servicio Grafana. La siguiente sección sobre la exposición de Grafana externamente se incluye únicamente con fines de referencia.
Exponiendo el Servicio de Grafana usando un Balanceador de Carga (opcional)
Si desea crear un Balanceador de Carga DigitalOcean para Grafana con una IP pública externa, use kubectl patch para actualizar el Servicio existente de Grafana en su lugar al tipo de Servicio LoadBalancer:
El comando patch de kubectl te permite actualizar objetos de Kubernetes en su lugar para realizar cambios sin tener que volver a implementar los objetos. También puedes modificar directamente el archivo de manifiesto maestro, agregando un parámetro type: LoadBalancer a la especificación del Servicio de Grafana. Para obtener más información sobre kubectl patch y los tipos de servicio de Kubernetes, puedes consultar los recursos Actualizar objetos de la API en su lugar usando kubectl patch y Servicios en la documentación oficial de Kubernetes.
Después de ejecutar el comando anterior, deberías ver lo siguiente:
Outputservice/sammy-cluster-monitoring-grafana patched
Puede tardar varios minutos en crear el balanceador de carga y asignarle una IP pública. Puedes seguir su progreso utilizando el siguiente comando con la bandera -w para observar los cambios:
Una vez que se haya creado el Balanceador de Carga de DigitalOcean y se le haya asignado una dirección IP externa, puedes obtener su IP externa utilizando los siguientes comandos:
Ahora puedes acceder a la interfaz de usuario de Grafana navegando a http://SERVICE_IP/.
Reenvío de un puerto local para acceder al Servicio de Grafana
Si no quieres exponer el servicio de Grafana externamente, también puedes reenviar el puerto local 3000 directamente al clúster a través de un Pod de Grafana usando kubectl port-forward.
Deberías ver la siguiente salida:
OutputForwarding from 127.0.0.1:3000 -> 3000
Forwarding from [::1]:3000 -> 3000
Esto reenviará el puerto local 3000 al containerPort 3000 del Pod de Grafana sammy-cluster-monitoring-grafana-0. Para obtener más información sobre el reenvío de puertos en un clúster de Kubernetes, consulta Usar el Reenvío de Puertos para Acceder a Aplicaciones en un Clúster.
Visita http://localhost:3000 en tu navegador web. Deberías ver la siguiente página de inicio de sesión de Grafana:

Para iniciar sesión, utiliza el nombre de usuario predeterminado admin (si no has modificado el parámetro admin-user), y la contraseña que configuraste en el Paso 1.
Serás llevado al siguiente Panel de Control Principal:
En la barra de navegación izquierda, selecciona el botón Paneles, luego haz clic en Gestionar:
Serás llevado a la siguiente interfaz de gestión de paneles, que lista los paneles configurados en el manifiesto dashboards-configmap.yaml:
Estos paneles de control son generados por kubernetes-mixin, un proyecto de código abierto que te permite crear un conjunto estandarizado de paneles de control de Grafana para monitorear clústeres y alertas de Prometheus. Para obtener más información, consulta el repositorio de GitHub de kubernetes-mixin.
Haz clic en el panel Kubernetes / Nodos, que visualiza el uso de CPU, memoria, disco y red para un nodo dado:
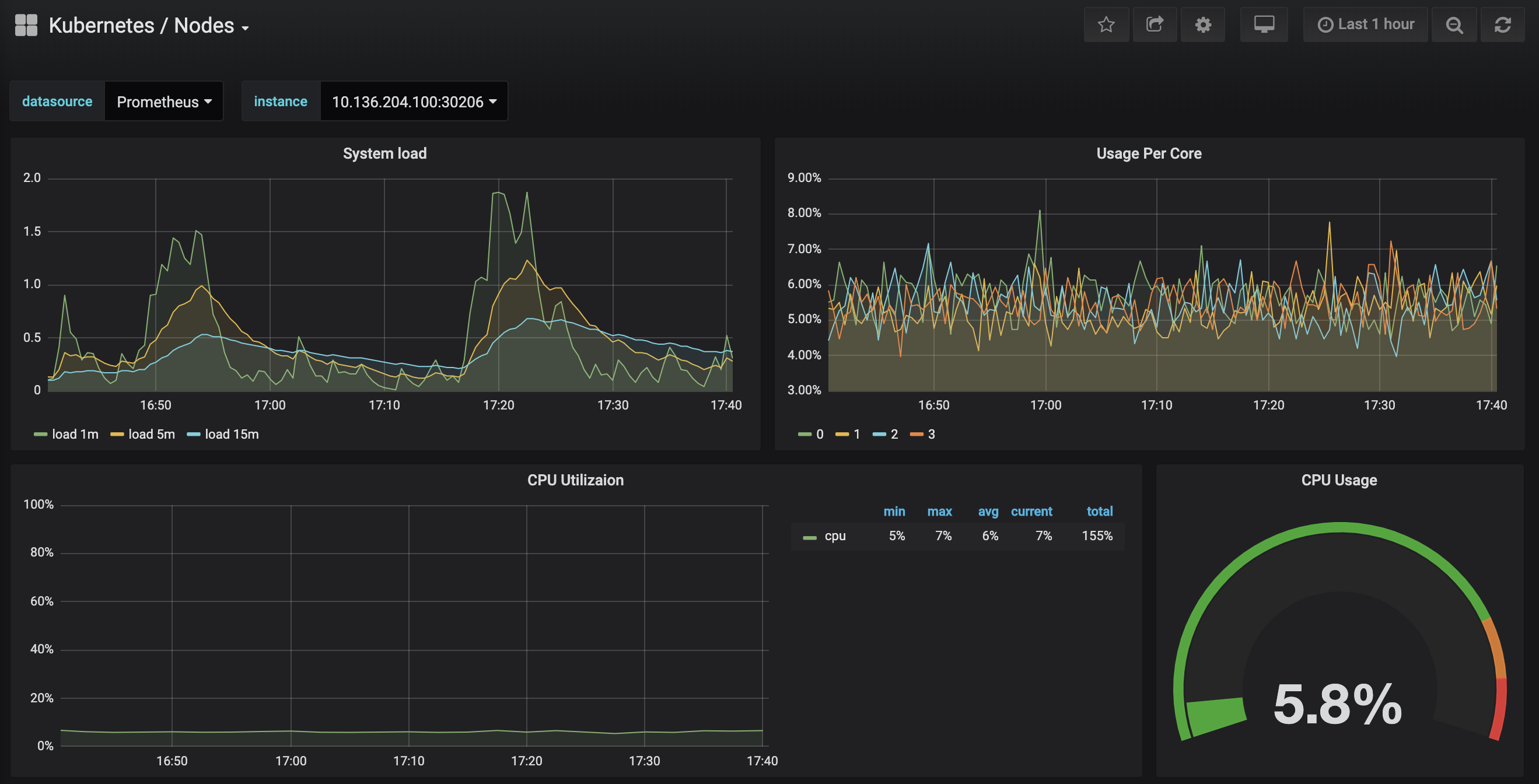
Describir cómo usar estos paneles está fuera del alcance de este tutorial, pero puedes consultar los siguientes recursos para obtener más información:
- Para aprender más sobre el método USE para analizar el rendimiento de un sistema, puedes consultar la página de método de Utilización, Saturación y Errores (USE) de Brendan Gregg.
- El Libro de SRE de Google es otro recurso útil, en particular el Capítulo 6: Monitoreo de Sistemas Distribuidos.
- Para aprender cómo construir tus propios paneles de control de Grafana, visita la página de Inicio de Grafana.
En el próximo paso, seguiremos un proceso similar para conectarnos y explorar el sistema de monitoreo Prometheus.
Paso 4 — Accediendo a Prometheus y Alertmanager
Para conectarse a los Pods de Prometheus, podemos usar kubectl port-forward para reenviar un puerto local. Si has terminado de explorar Grafana, puedes cerrar el túnel de reenvío de puerto presionando CTRL-C. Alternativamente, puedes abrir un nuevo shell y crear una nueva conexión de reenvío de puerto.
Comienza enumerando los Pods en ejecución en el espacio de nombres default:
Deberías ver los siguientes Pods:
Outputsammy-cluster-monitoring-alertmanager-0 1/1 Running 0 17m
sammy-cluster-monitoring-alertmanager-1 1/1 Running 0 15m
sammy-cluster-monitoring-grafana-0 1/1 Running 0 16m
sammy-cluster-monitoring-kube-state-metrics-d68bb884-gmgxt 2/2 Running 0 16m
sammy-cluster-monitoring-node-exporter-7hvb7 1/1 Running 0 16m
sammy-cluster-monitoring-node-exporter-c2rvj 1/1 Running 0 16m
sammy-cluster-monitoring-node-exporter-w8j74 1/1 Running 0 16m
sammy-cluster-monitoring-prometheus-0 1/1 Running 0 16m
sammy-cluster-monitoring-prometheus-1 1/1 Running 0 16m
Vamos a reenviar el puerto local 9090 al puerto 9090 del Pod sammy-cluster-monitoring-prometheus-0:
Deberías ver la siguiente salida:
OutputForwarding from 127.0.0.1:9090 -> 9090
Forwarding from [::1]:9090 -> 9090
Esto indica que el puerto local 9090 se está reenviando correctamente al Pod de Prometheus.
Visita http://localhost:9090 en tu navegador web. Deberías ver la siguiente página de Gráficos de Prometheus:

Desde aquí puedes usar PromQL, el lenguaje de consulta de Prometheus, para seleccionar y agregar métricas de series temporales almacenadas en su base de datos. Para obtener más información sobre PromQL, consulta Consulta de Prometheus en la documentación oficial de Prometheus.
En el campo de Expresión, escribe kubelet_node_name y haz clic en Ejecutar. Deberías ver una lista de series temporales con la métrica kubelet_node_name que reporta los Nodos en tu clúster de Kubernetes. Puedes ver qué nodo generó la métrica y qué trabajo raspó la métrica en las etiquetas de la métrica:

Finalmente, en la barra de navegación superior, haz clic en Estado y luego en Objetivos para ver la lista de objetivos que Prometheus ha sido configurado para raspar. Deberías ver una lista de objetivos correspondientes a la lista de puntos finales de monitoreo descritos al principio de Paso 2.
Para obtener más información sobre Prometheus y cómo consultar las métricas de tu clúster, consulta la documentación oficial de Prometheus.
Para conectarte a Alertmanager, que gestiona las alertas generadas por Prometheus, seguiremos un proceso similar al que usamos para conectarnos a Prometheus. En general, puedes explorar las alertas de Alertmanager haciendo clic en Alertas en la barra de navegación superior de Prometheus.
Para conectarte a los Pods de Alertmanager, una vez más utilizaremos kubectl port-forward para reenviar un puerto local. Si has terminado de explorar Prometheus, puedes cerrar el túnel de reenvío de puerto presionando CTRL-C o abrir una nueva terminal para crear una nueva conexión.
Vamos a reenviar el puerto local 9093 al puerto 9093 del Pod sammy-cluster-monitoring-alertmanager-0:
Deberías ver la siguiente salida:
OutputForwarding from 127.0.0.1:9093 -> 9093
Forwarding from [::1]:9093 -> 9093
Esto indica que el puerto local 9093 se está reenviando correctamente a un Pod de Alertmanager.
Visita http://localhost:9093 en tu navegador web. Deberías ver la página de Alertas de Alertmanager:
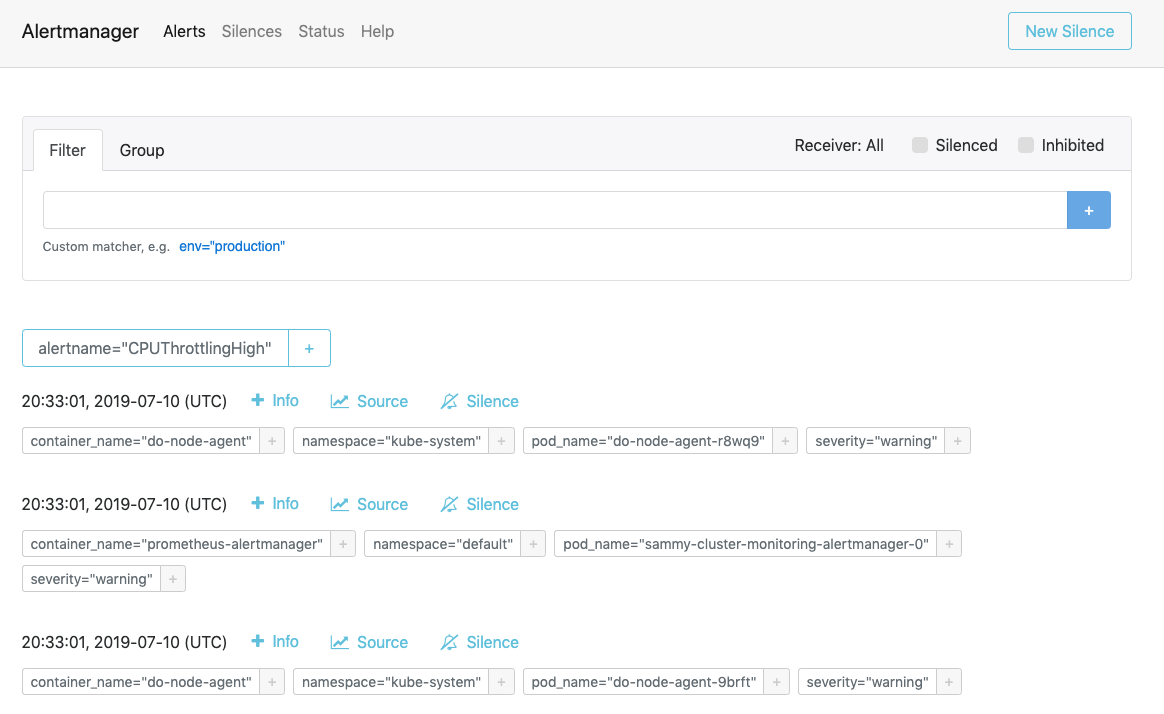
Desde aquí, puedes explorar las alertas activadas y opcionalmente silenciarlas. Para obtener más información sobre Alertmanager, consulta la documentación oficial de Alertmanager.
En el siguiente paso, aprenderás cómo configurar opcionalmente y escalar algunos de los componentes del conjunto de monitoreo.
Paso 6 — Configuración del conjunto de monitoreo (opcional)
Los manifiestos incluidos en el repositorio de inicio rápido de monitoreo de clúster de Kubernetes de DigitalOcean pueden modificarse para usar imágenes de contenedor diferentes, diferentes números de réplicas de Pod, diferentes puertos y archivos de configuración personalizados.
En este paso, proporcionaremos una visión general de alto nivel del propósito de cada manifiesto, y luego demostraremos cómo escalar Prometheus hasta 3 réplicas modificando el archivo de manifiesto maestro.
Para comenzar, navega hasta el subdirectorio manifests en el repositorio y lista el contenido del directorio:
Outputalertmanager-0serviceaccount.yaml
alertmanager-configmap.yaml
alertmanager-operated-service.yaml
alertmanager-service.yaml
. . .
node-exporter-ds.yaml
prometheus-0serviceaccount.yaml
prometheus-configmap.yaml
prometheus-service.yaml
prometheus-statefulset.yaml
Aquí encontrarás manifestos para los diferentes componentes del stack de monitoreo. Para obtener más información sobre parámetros específicos en los manifestos, haz clic en los enlaces y consulta los comentarios incluidos a lo largo de los archivos YAML:
Alertmanager
-
alertmanager-0serviceaccount.yaml: La cuenta de servicio de Alertmanager, utilizada para otorgar a los Pods de Alertmanager una identidad en Kubernetes. Para obtener más información sobre las cuentas de servicio, consulta Configurar cuentas de servicio para Pods. -
alertmanager-configmap.yaml: Un ConfigMap que contiene un archivo de configuración mínimo de Alertmanager, llamadoalertmanager.yml. Configurar Alertmanager está más allá del alcance de este tutorial, pero puedes aprender más consultando la sección de Configuración de la documentación de Alertmanager. -
alertmanager-operated-service.yaml: El serviciomeshde Alertmanager, que se utiliza para enrutar solicitudes entre los pods de Alertmanager en la configuración actual de alta disponibilidad con 2 réplicas. -
alertmanager-service.yaml: El servicio Alertmanagerweb, que se utiliza para acceder a la interfaz web de Alertmanager, lo cual puede haber hecho en el paso anterior. -
alertmanager-statefulset.yaml: El StatefulSet de Alertmanager, configurado con 2 réplicas.
Grafana
-
dashboards-configmap.yaml: Un ConfigMap que contiene los paneles de monitoreo preconfigurados de Grafana en formato JSON. Generar un nuevo conjunto de paneles y alertas desde cero va más allá del alcance de este tutorial, pero para obtener más información puedes consultar el repositorio de GitHub de kubernetes-mixin. -
grafana-0serviceaccount.yaml: La Cuenta de Servicio de Grafana. -
grafana-configmap.yaml: Un ConfigMap que contiene un conjunto predeterminado de archivos de configuración mínimos de Grafana. -
grafana-secret.yaml: Un Secret de Kubernetes que contiene el usuario y la contraseña de administrador de Grafana. Para obtener más información sobre los Secrets de Kubernetes, consulta Secrets. -
grafana-service.yaml: El manifiesto que define el Servicio de Grafana. -
grafana-statefulset.yaml: El StatefulSet de Grafana, configurado con 1 réplica, que no es escalable. Escalar Grafana está fuera del alcance de este tutorial. Para aprender cómo crear una configuración de Grafana altamente disponible, puedes consultar Cómo configurar Grafana para alta disponibilidad en la documentación oficial de Grafana.
kube-state-metrics
-
kube-state-metrics-0serviceaccount.yaml: La cuenta de servicio y el ClusterRole de kube-state-metrics. Para obtener más información sobre ClusterRoles, consulta Role y ClusterRole en la documentación de Kubernetes. -
kube-state-metrics-deployment.yaml: El manifiesto principal de implementación de kube-state-metrics, configurado con 1 réplica escalable dinámicamente utilizandoaddon-resizer. -
kube-state-metrics-service.yaml: El Servicio que expone la Implementaciónkube-state-metrics.
node-exporter
-
node-exporter-0serviceaccount.yaml: La cuenta de servicio de node-exporter. -
node-exporter-ds.yaml: El manifiesto del conjunto de demonios de node-exporter. Dado que node-exporter es un conjunto de demonios, se ejecuta un pod de node-exporter en cada nodo del clúster.
###Prometheus
-
prometheus-0serviceaccount.yaml: La cuenta de servicio de Prometheus, el Rol de clúster y la Asignación de roles de clúster. -
prometheus-configmap.yaml: Un ConfigMap que contiene tres archivos de configuración:alerts.yaml: Contiene un conjunto preconfigurado de alertas generadas porkubernetes-mixin(que también se utilizó para generar los paneles de Grafana). Para obtener más información sobre cómo configurar reglas de alerta, consulte Reglas de Alerta en la documentación de Prometheus.prometheus.yaml: Archivo de configuración principal de Prometheus. Prometheus ha sido preconfigurado para raspar todos los componentes listados al principio de Paso 2. Configurar Prometheus va más allá del alcance de este artículo, pero para obtener más información, puede consultar Configuración en la documentación oficial de Prometheus.rules.yaml: Un conjunto de reglas de registro de Prometheus que permiten a Prometheus calcular expresiones frecuentemente necesarias o computacionalmente costosas, y guardar sus resultados como un nuevo conjunto de series temporales. Estas también son generadas porkubernetes-mixin, y configurarlas va más allá del alcance de este artículo. Para obtener más información, puede consultar Reglas de Registro en la documentación oficial de Prometheus.
-
prometheus-service.yaml: El Servicio que expone el conjunto de estados de Prometheus. -
prometheus-statefulset.yaml: El conjunto de estados de Prometheus, configurado con 2 réplicas. Este parámetro se puede escalar según sus necesidades.
Ejemplo: Escalando Prometheus
Para demostrar cómo modificar la pila de monitoreo, escalaremos el número de réplicas de Prometheus de 2 a 3.
Abra el archivo maestro del manifiesto sammy-cluster-monitoring_manifest.yaml usando su editor preferido:
Desplácese hacia abajo hasta la sección del conjunto de estados de Prometheus en el manifiesto:
Output. . .
apiVersion: apps/v1beta2
kind: StatefulSet
metadata:
name: sammy-cluster-monitoring-prometheus
labels: &Labels
k8s-app: prometheus
app.kubernetes.io/name: sammy-cluster-monitoring
app.kubernetes.io/component: prometheus
spec:
serviceName: "sammy-cluster-monitoring-prometheus"
replicas: 2
podManagementPolicy: "Parallel"
updateStrategy:
type: "RollingUpdate"
selector:
matchLabels: *Labels
template:
metadata:
labels: *Labels
spec:
. . .
Cambie el número de réplicas de 2 a 3:
Output. . .
apiVersion: apps/v1beta2
kind: StatefulSet
metadata:
name: sammy-cluster-monitoring-prometheus
labels: &Labels
k8s-app: prometheus
app.kubernetes.io/name: sammy-cluster-monitoring
app.kubernetes.io/component: prometheus
spec:
serviceName: "sammy-cluster-monitoring-prometheus"
replicas: 3
podManagementPolicy: "Parallel"
updateStrategy:
type: "RollingUpdate"
selector:
matchLabels: *Labels
template:
metadata:
labels: *Labels
spec:
. . .
Cuando haya terminado, guarde y cierre el archivo.
Aplica los cambios usando kubectl apply -f:
Puedes seguir el progreso usando kubectl get pods. Utilizando esta misma técnica, puedes actualizar muchos de los parámetros de Kubernetes y gran parte de la configuración de este conjunto de observabilidad.
Conclusión
En este tutorial, instalaste un conjunto de monitoreo Prometheus, Grafana y Alertmanager en tu clúster de Kubernetes de DigitalOcean con un conjunto estándar de paneles, reglas de Prometheus y alertas.
También puedes optar por implementar este conjunto de monitoreo usando el administrador de paquetes de Kubernetes Helm. Para obtener más información, consulta Cómo configurar el monitoreo del clúster de Kubernetes de DigitalOcean con Helm y Prometheus. Otra forma de poner en marcha un conjunto similar es utilizando la solución Conjunto de Monitoreo de Kubernetes de DigitalOcean Marketplace, que actualmente está en beta.
El repositorio de inicio rápido de monitoreo de clústeres de Kubernetes de DigitalOcean se basa en gran medida y se modifica a partir de la solución de Prometheus click-to-deploy de Google Cloud Platform. Un manifiesto completo de modificaciones y cambios del repositorio original se puede encontrar en el archivo changes.md del repositorio de inicio rápido.