













Descargo de responsabilidad: Todas las opiniones expresadas en el blog pertenecen únicamente al autor y no necesariamente a su empleador u otro grupo o individuo. Este artículo no es una promoción de ninguna plataforma de gestión de nube/datos. Todas las imágenes y APIs están disponibles públicamente en el sitio web de Azure/Databricks.
¿Qué es el Monitoreo de Lakehouse de Databricks?
En mis otros artículos, he descrito qué son Databricks y Unity Catalog, y cómo crear un catálogo desde cero utilizando un script. En este artículo, describiré la función de Monitoreo de Lakehouse disponible como parte de la plataforma Databricks y cómo habilitar la función utilizando scripts.
El Monitoreo de Lakehouse proporciona perfilado de datos y métricas relacionadas con la calidad de datos para las Tablas Delta en Lakehouse. El Monitoreo de Lakehouse de Databricks ofrece una perspectiva integral de los datos, como cambios en el volumen de datos, cambios en la distribución numérica, % de nulos y ceros en las columnas, y detección de anomalías categóricas a lo largo del tiempo.
¿Por qué utilizar el Monitoreo de Lakehouse?
El monitoreo de tus datos y el rendimiento del modelo de ML proporciona medidas cuantitativas que te ayudan a seguir y confirmar la calidad y consistencia de tus datos y el rendimiento del modelo con el tiempo.
Aquí tienes un desglose de las características clave:
- Seguimiento de la calidad de los datos y la integridad de los datos: Sigue el flujo de datos a través de tuberías, asegurando la integridad de los datos y proporcionando visibilidad sobre cómo los datos han cambiado con el tiempo, 90º percentil de una columna numérica, % de columnas nulas y con cero, etc.
- Derivas de datos con el tiempo: Proporciona métricas para detectar la deriva de datos entre los datos actuales y una línea base conocida, o entre ventanas de tiempo sucesivas de los datos
- Distribución estadística de los datos: Proporciona cambio de distribución numérica de los datos con el tiempo que responde a la distribución de valores en una columna categórica y cómo difiere del pasado
- Rendimiento del modelo de ML y deriva en predicciones: Entradas del modelo de ML, predicciones y tendencias de rendimiento con el tiempo
Cómo funciona
El monitoreo de Lakehouse de Databricks proporciona los siguientes tipos de análisis: series temporales, instantáneas e inferencias.
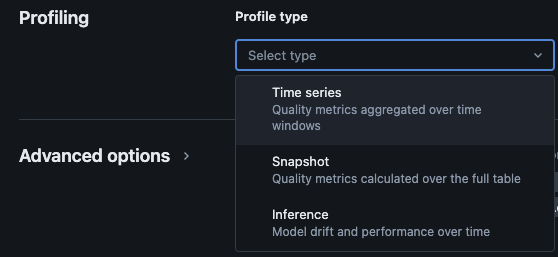
Tipos de perfiles para monitoreo
Cuando habilitas el monitoreo del Lakehouse para una tabla en el Catálogo Unity, crea dos tablas en el esquema de monitoreo especificado. Puedes realizar consultas y crear paneles de control (Databricks proporciona un panel de control configurable predeterminado) y notificaciones en las tablas para obtener información estadística y de perfil completa sobre tus datos a lo largo del tiempo.
- Tabla de métricas de desviación: La tabla de métricas de desviación contiene estadísticas relacionadas con la desviación de los datos a lo largo del tiempo. Captura información como diferencias en el recuento, diferencias en el promedio, diferencias en el % de nulos y ceros, etc.
- Tabla de métricas de perfil: La tabla de métricas de perfil contiene estadísticas resumidas para cada columna y para cada combinación de ventana de tiempo, segmento y columnas de agrupación. Para el análisis de InferenceLog, la tabla de análisis también contiene métricas de precisión del modelo.
Cómo habilitar el monitoreo del Lakehouse a través de scripts
Prerrequisitos
- Se requiere que estén presentes Unity Catalog, esquema y Delta Live Tables.
- El usuario es el propietario de la Delta Live Table.
- Para clústeres privados de Azure Databricks, la conectividad privada desde el cálculo serverless está configurada.
Paso 1: Crear un cuaderno e instalar el SDK de Databricks
Cree una notebook en el espacio de trabajo de Databricks. Para crear un notebook en su espacio de trabajo, haga clic en el “+” Nuevo en la barra lateral, y luego elija Notebook.
Se abrirá un notebook en blanco en el espacio de trabajo. Asegúrese de que Python esté seleccionado como el lenguaje del notebook.
Copie y pegue el fragmento de código a continuación en la celda del notebook y ejecute la celda.
%pip install databricks-sdk --upgrade
dbutils.library.restartPython()
Paso 2: Crear Variables
Copie y pegue el fragmento de código a continuación en la celda del notebook y ejecute la celda.
catalog_name = "catalog_name" #Replace the catalog name as per your environment.
schema_name = "schema_name" #Replace the schema name as per your environment.
monitoring_schema = "monitoring_schema" #Replace the monitoring schema name as per your preferred name.
refresh_schedule_cron = "0 0 0 * * ?" #Replace the cron expression for the refresh schedule as per your need.
Paso 3: Crear Esquema de Monitoreo
Copie y pegue el fragmento de código a continuación en la celda del notebook y ejecute la celda. Este fragmento creará el esquema de monitoreo si aún no existe.
%sql
USE CATALOG `${catalog_name}`;
CREATE SCHEMA IF NOT EXISTS `${monitoring_schema}`
Paso 4: Crear Monitor
Copie y pegue el fragmento de código a continuación en la celda del notebook y ejecute la celda. Este fragmento creará el Monitoreo de Lakehouse para todas las tablas dentro del esquema.
import time
from databricks.sdk import WorkspaceClient
from databricks.sdk.errors import NotFound, ResourceDoesNotExist
from databricks.sdk.service.catalog import MonitorSnapshot, MonitorInfo, MonitorInfoStatus, MonitorRefreshInfoState, MonitorMetric, MonitorCronSchedule
databricks_url = 'https://adb-xxxx.azuredatabricks.net/' # replace the url with your workspace url
api_token = 'xxxx' # replace the token with your personal access token for the workspace. Best practice - store the token in Azure KV and retrieve the token using key-vault scope.
w = WorkspaceClient(host=databricks_url, token=api_token)
all_tables = list(w.tables.list(catalog_name=catalog_name, schema_name=schema_name))
for table in all_tables:
table_name = table.full_name
info = w.quality_monitors.create(
table_name = table_name,
assets_dir = "/Shared/databricks_lakehouse_monitoring/", # Creates monitoring dashboards in this location
output_schema_name = f"{catalog_name}.{monitoring_schema}",
snapshot = MonitorSnapshot(),
schedule = MonitorCronSchedule(quartz_cron_expression = refresh_schedule_cron, timezone_id = "PST") # update timezone as per your need.
)
# Wait for monitor to be created
while info.status == MonitorInfoStatus.MONITOR_STATUS_PENDING:
info = w.quality_monitors.get(table_name=table_name)
time.sleep(10)
assert info.status == MonitorInfoStatus.MONITOR_STATUS_ACTIVE, "Error creating monitor"
Validación
Después de que el script se ejecute correctamente, puede navegar a catálogo -> esquema -> tabla y dirigirse a la pestaña “Calidad” en la tabla para ver los detalles del monitoreo.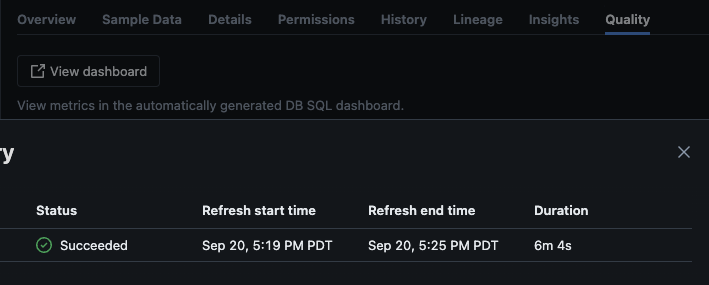
Si haces clic en el botón “Ver panel de control” en la esquina superior izquierda de la página de Monitoreo, se abrirá el panel de control de monitoreo predeterminado. Inicialmente, los datos estarán en blanco. A medida que se ejecuta el monitoreo según la programación, con el tiempo se llenarán todos los valores estadísticos, de perfil y de calidad de datos.
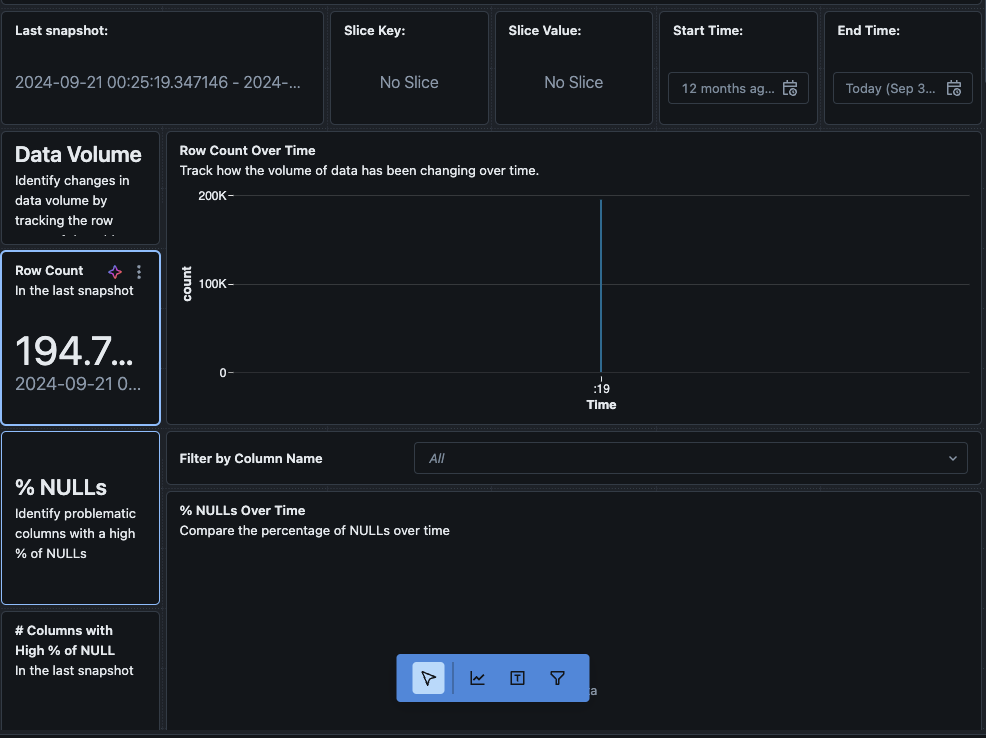
También puedes navegar a la pestaña “Datos” en el panel de control. Databricks proporciona de serie una lista de consultas para obtener la desviación y otra información de perfil. También puedes crear tus propias consultas según tus necesidades para obtener una vista completa de tus datos a lo largo del tiempo.
Conclusión
El Monitoreo de Lago de Databricks ofrece una forma estructurada de seguir la calidad de los datos, las métricas de perfil y detectar desviaciones de datos a lo largo del tiempo. Al habilitar esta función a través de scripts, los equipos pueden obtener información sobre el comportamiento de los datos y garantizar la fiabilidad de sus canalizaciones de datos. El proceso de configuración descrito en este artículo proporciona una base para mantener la integridad de los datos y apoyar los esfuerzos continuos de análisis de datos.
Source:
https://dzone.com/articles/how-to-enable-azure-databricks-lakehouse-monitoring