













En la Parte 1, cubrimos varios temas clave. Te recomiendo que lo leas, ya que esta siguiente parte se basa en ello.
Como repaso rápido, en la parte 1, consideramos nuestros datos desde una perspectiva general y diferenciamos entre datos internos y datos externos. También discutimos sobre esquemas y contratos de datos y cómo estos proporcionan los medios para negociar, cambiar y evolucionar nuestros flujos con el tiempo. Finalmente, cubrimos los tipos de eventos Hecho (Estado) y Delta. Los eventos de Hecho son mejores para comunicar estado y desacoplar sistemas, mientras que los eventos de Delta tienden a usarse más para datos internos, como en la fuente de eventos y otros casos de uso fuertemente acoplados.
Tablas Normalizadas Crean Flujos Normalizados
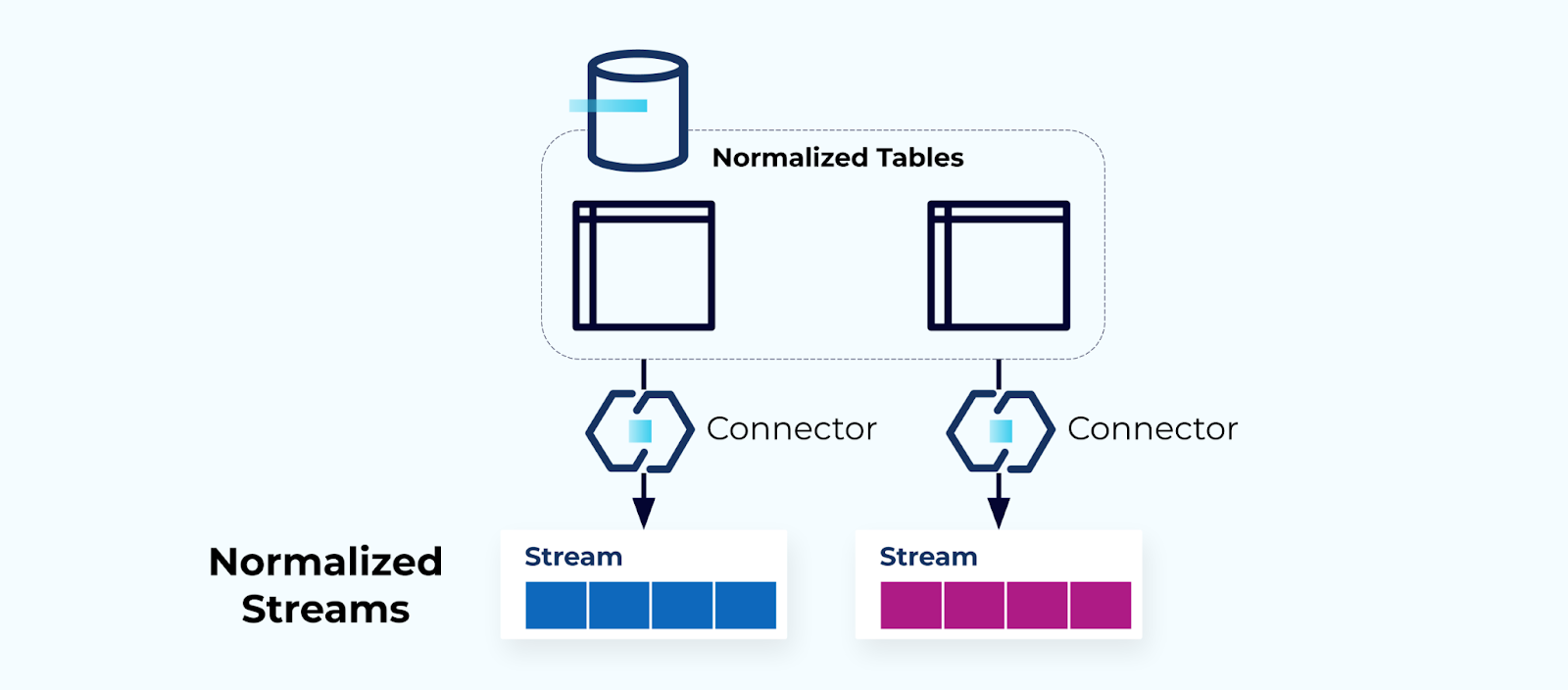
Las tablas normalizadas llevan a flujos de eventos normalizados. Los conectores (por ejemplo, CDC) extraen datos directamente de la base de datos hacia un conjunto reflejado de flujos de eventos. Esto no es ideal, ya que crea una fuerte耦合 entre las tablas internas de la base de datos y los flujos de eventos externos.
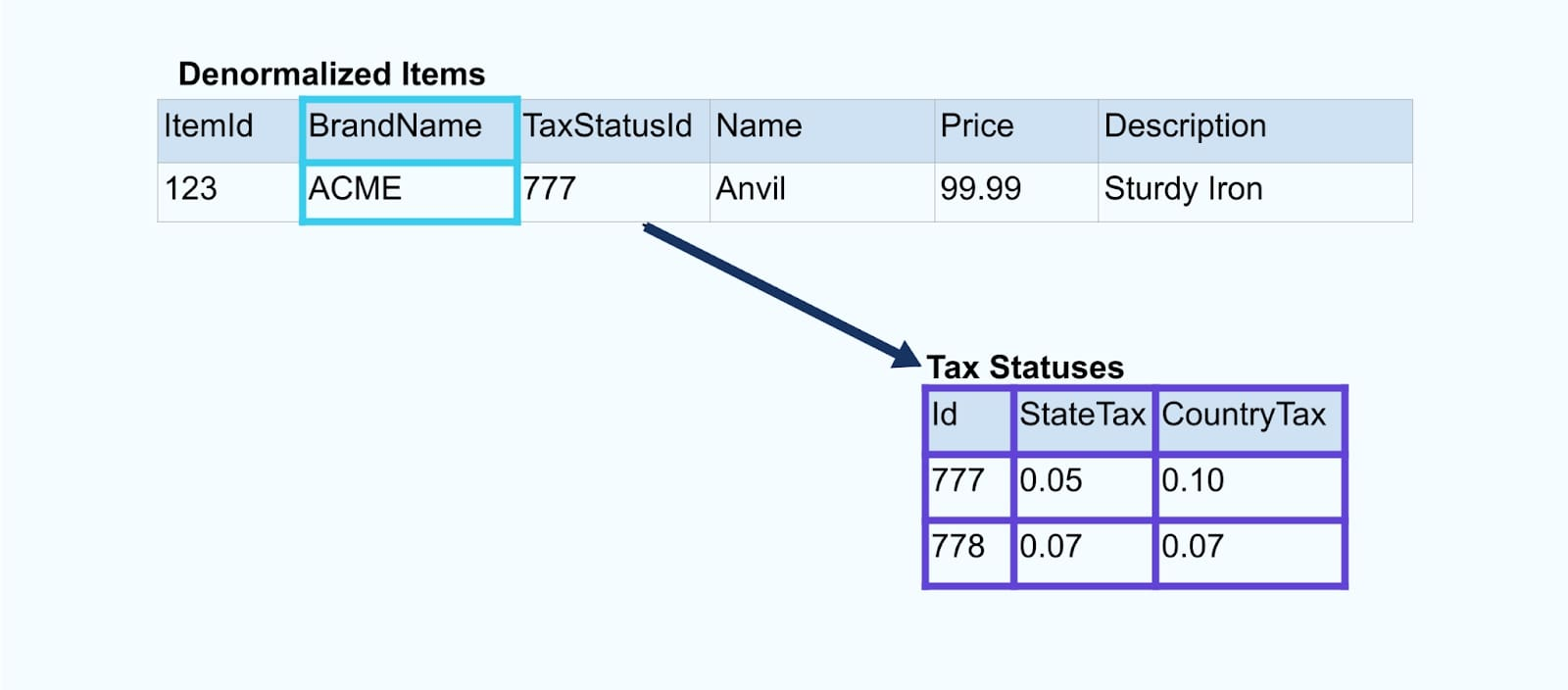
Considera un simple comercio electrónico Item y sus tablas asociadas Brand y Estado de Impuesto.
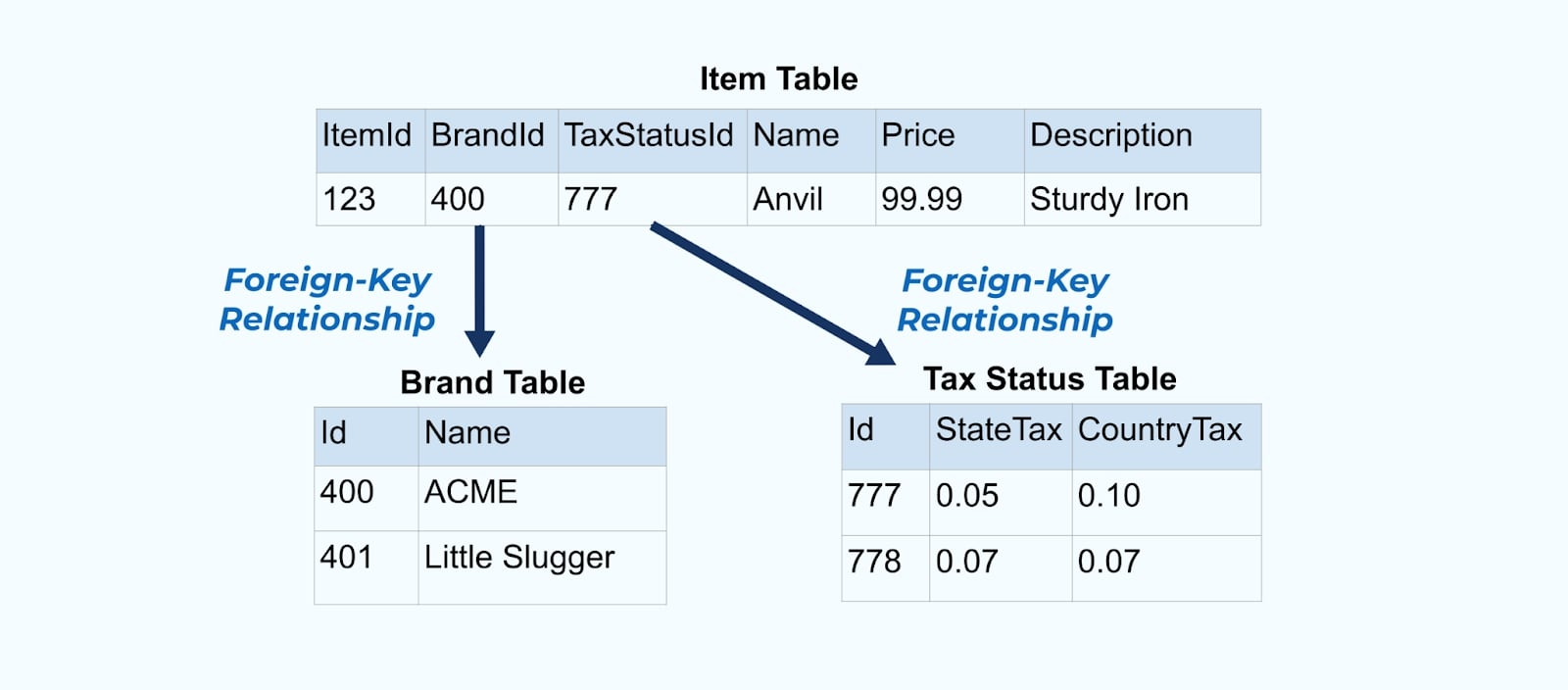
Las tablas Brand y Estado de Impuesto se relacionan con la tabla Item a través de relaciones de clave foránea. Aunque solo mostramos un artículo en la tabla, es probable que tengas miles (o millones), dependiendo de los productos que vendas.
Es común configurar un conector para cada tabla, extraer los datos de la tabla, componerlos en eventos y escribir cada tabla en un flujo de eventos dedicado.
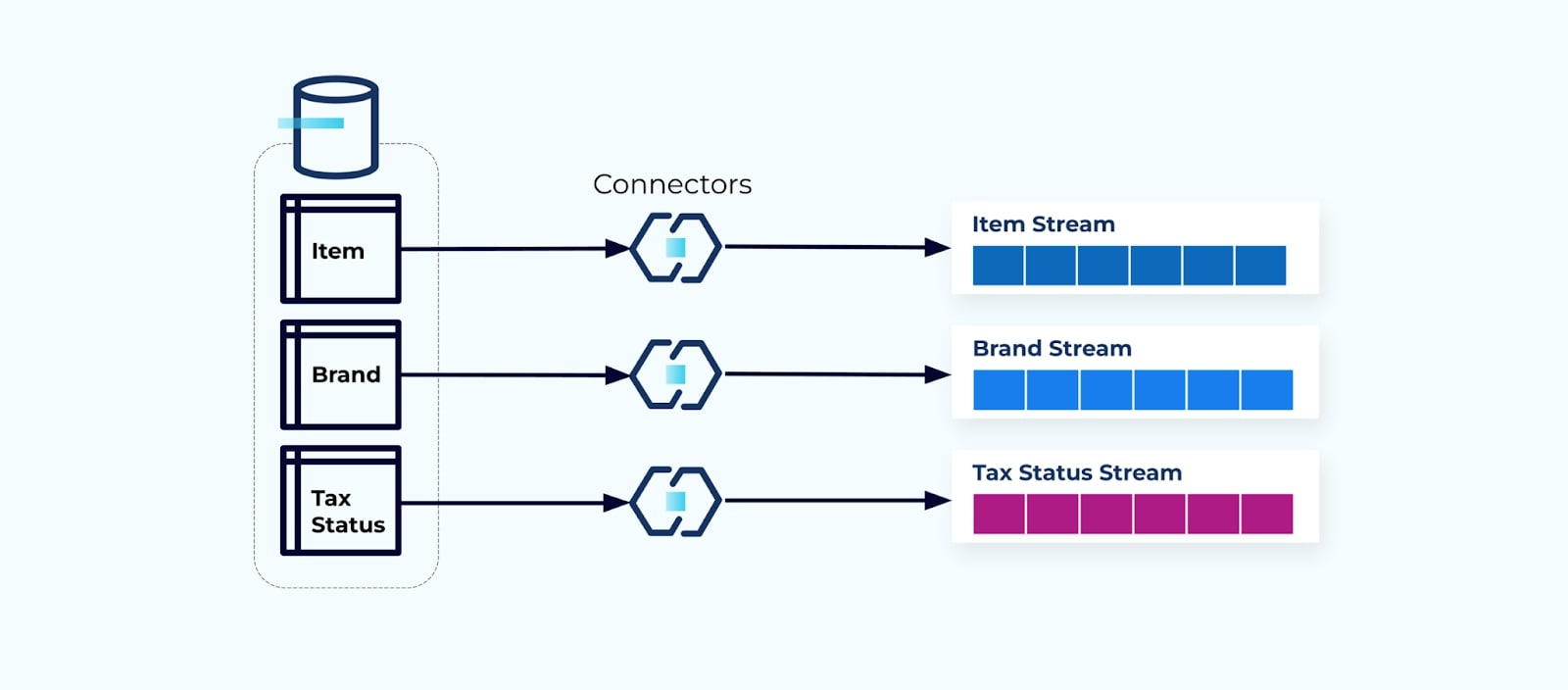
Exponer las tablas subyacentes en la base de datos conduce a un flujo de eventos correspondiente por tabla. Aunque es fácil comenzar de esta manera, conduce a múltiples problemas, que pueden resumirse como un problema de acoplamiento problema o un problema de costo problema. Veamos cada uno.
Problema: Los consumidores se acoplan al modelo interno
Exponer la tabla de Item tal cual fuerza a los consumidores a acoplarse directamente a ella. Los cambios en el modelo de datos del sistema de origen impactarán a los consumidores downstream.
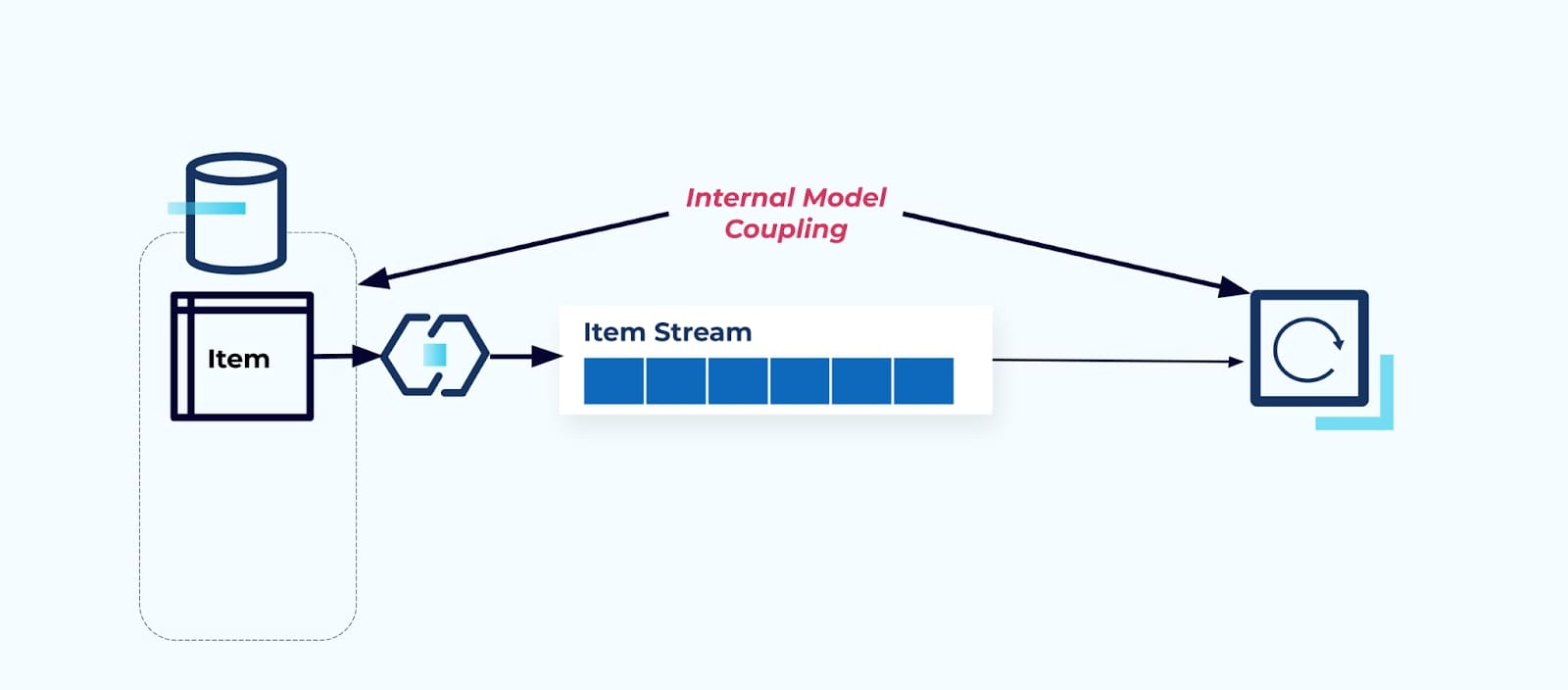
Supongamos que refactorizamos la tabla de Item para extraer Precios a su propia tabla.
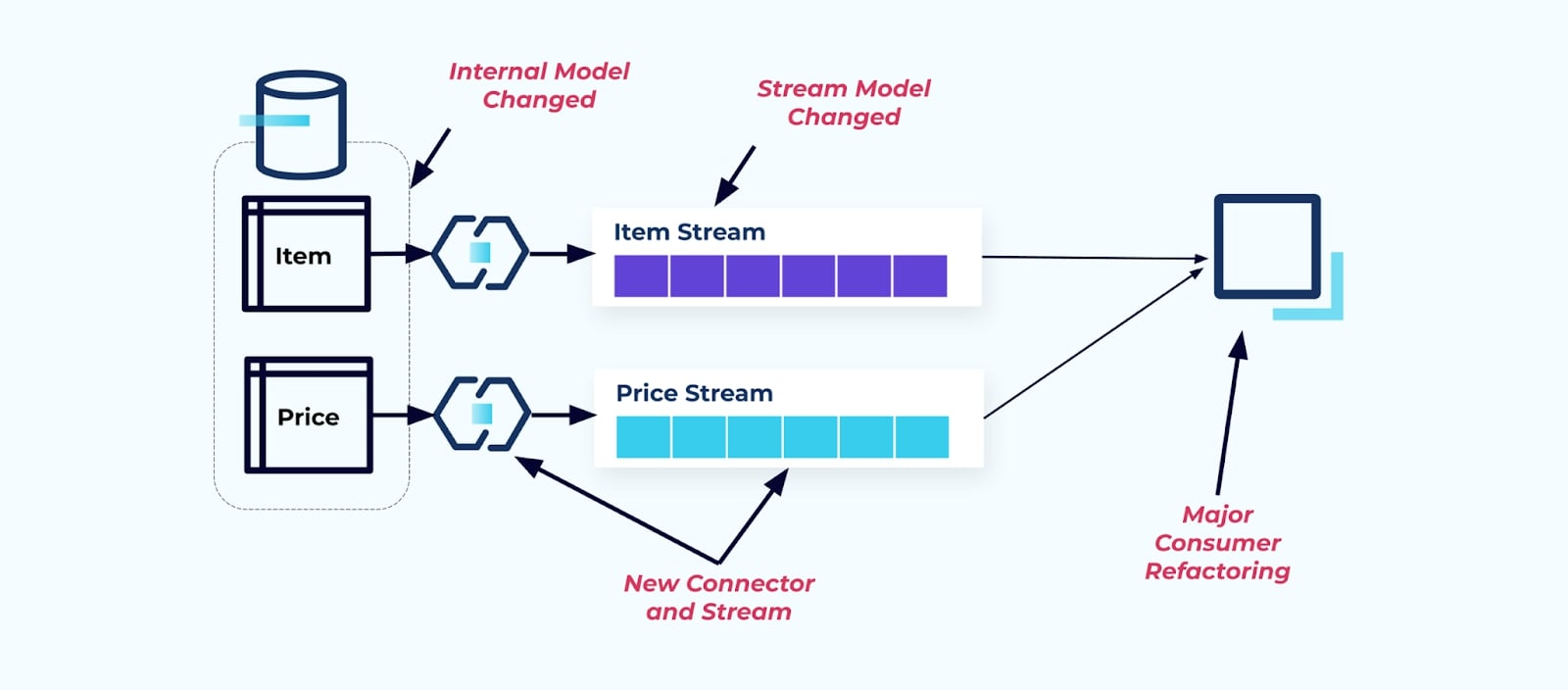
Reestructurar las tablas de origen resulta en un contrato de datos roto para el flujo de elementos. El consumidor ya no recibe los mismos datos de elementos que originalmente esperaba. También debemos crear un nuevo conector — un nuevo Precio stream — y, finalmente, refactorizar nuestra lógica de consumidor para que vuelva a funcionar. Renombrar columnas, cambiar valores predeterminados y cambiar tipos de columnas son otras formas de cambios que rompen introducidas por un acoplamiento estrecho en el modelo de datos interno.
Problema: Las uniones en streaming son (generalmente) costosas
Las bases de datos relacionales están diseñadas específicamente para resolver uniones rápidamente y a bajo costo. Las uniones en streaming, lamentablemente, no lo son.
Consideremos dos servicios que desean acceder a un Elemento, su Impuesto y su información de Marca. Si los datos ya están escritos en su flujo correspondiente, entonces cada consumidor (a la derecha en la imagen a continuación) tendrá que calcular las mismas uniones para desnormalizar Item, Marca y Impuesto.
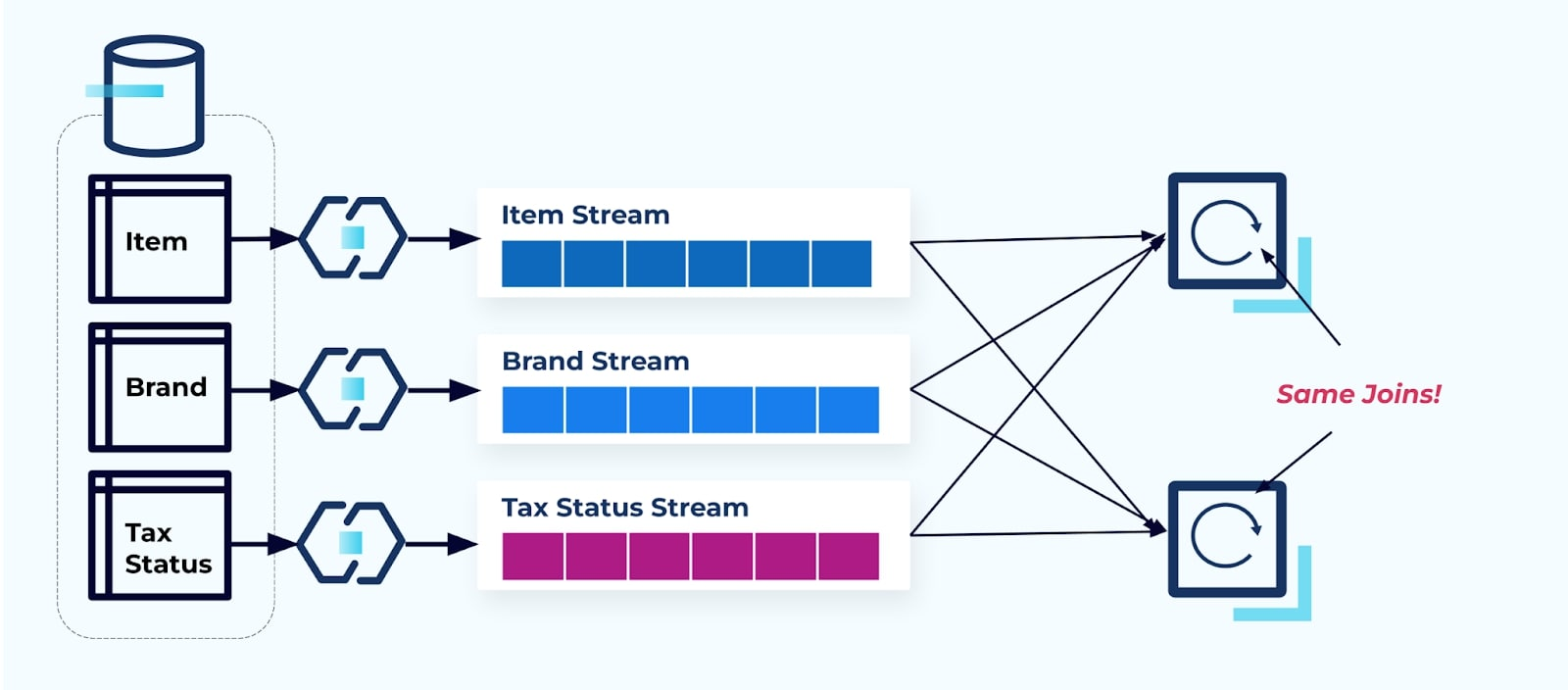
Esta estrategia puede incurrir en altos costos, tanto en horas de desarrollo para escribir las aplicaciones como en costos de servidor para calcular los joins. Resolver joins de streaming a gran escala puede resultar en mucho movimiento de datos, lo que implica costos de potencia de procesamiento, red y almacenamiento. Además, no todos los marcos de procesamiento de streams admiten joins, especialmente en claves foráneas. De los que lo hacen, como Flink, Spark, KSQL o Kafka Streams (por ejemplo), te encontrarás limitado a un subconjunto de lenguajes de programación (Java, Scala, Python).
Solución: Servir Datos Desnormalizados Es lo Mejor
Como principio, haz que los flujos de eventos sean fáciles de usar para tus consumidores. Desnormaliza los datos antes de ponerlos a disposición de los consumidores utilizando una capa de abstracción y crea un modelo externo explícito contrato de datos (datos en el exterior) para que los consumidores se acoplen.
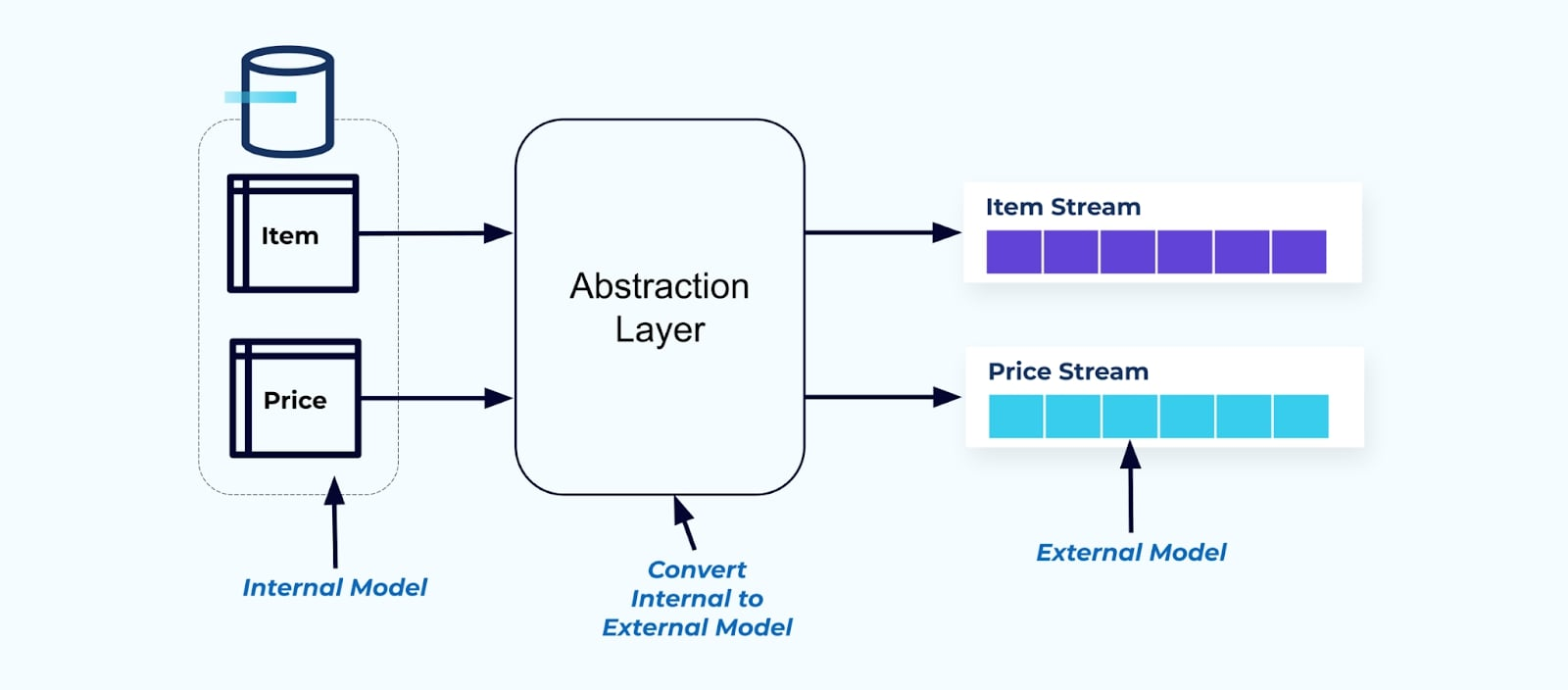
Los cambios en el modelo interno permanecen aislados en los sistemas fuente. Los consumidores obtienen un contrato de datos bien definido para acoplarse. Los cambios realizados en el modelo fuente pueden proseguir sin impedimentos, siempre que el sistema fuente mantenga el contrato de datos para los consumidores.
¿Pero dónde desnormalizamos? Dos opciones:
- Reconstruir fuera del sistema fuente mediante un servicio de unión específico.
- Durante la creación del evento en el sistema fuente utilizando el patrón Transactional Outbox.
Vamos a echar un vistazo a cada solución a su vez.
Opción 1: Desnormalizar Usando un Servicio de Unión Específico
En este ejemplo, los streams a la izquierda reflejan las tablas de las que provienen en la base de datos.
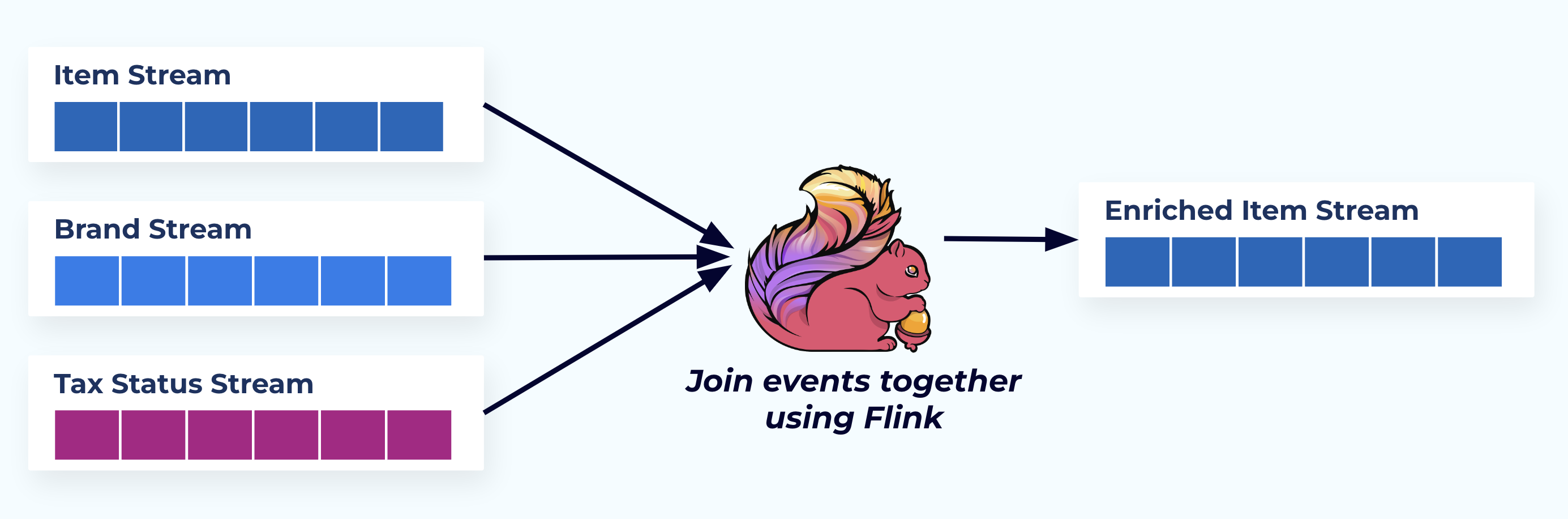
Nos unimos a los eventos utilizando una aplicación construida con un propósito específico (o consulta SQL en tiempo real) basada en las relaciones de clave foránea y emitimos un único flujo de elementos enriquecidos.

Lógicamente, estamos resolviendo las relaciones y comprimiendo los datos en una sola fila desnormalizada.
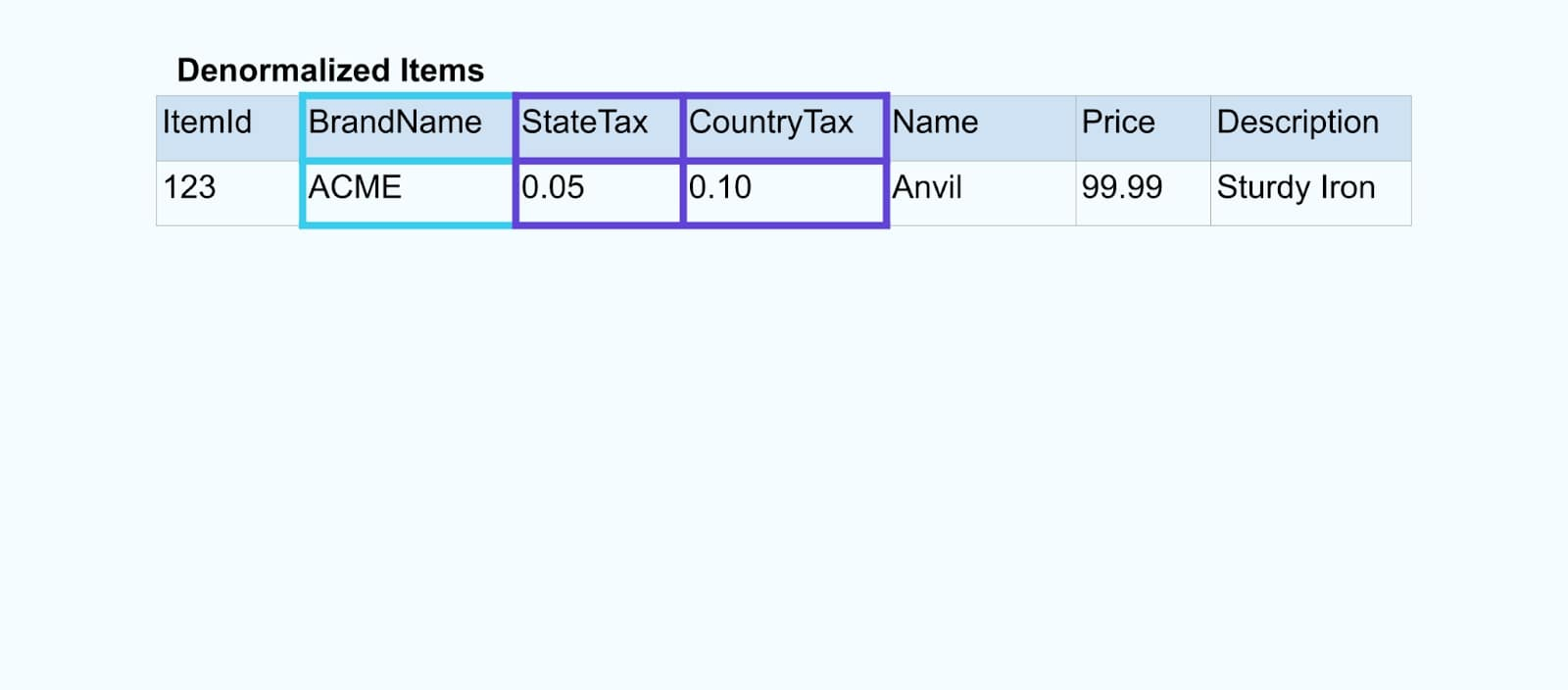
Los unificadores construidos con un propósito específico dependen de marcos de procesamiento de flujos como Apache Kafka Streams y Apache Flink para resolver tanto las uniones de clave primaria como de clave foránea. Materializan los datos del flujo en formatos de tabla interna duraderos, permitiendo que la aplicación unificadora una eventos a lo largo de cualquier período – no solo aquellos limitados por una ventana de tiempo.
Los unificadores que utilizan Flink o Kafka Streams también son notablemente escalables — pueden escalar hacia arriba y hacia abajo con la carga y manejar volúmenes masivos de tráfico.
Un consejo: No coloques ninguna lógica de negocio en el unificador. Para tener éxito en este patrón, los datos unificados deben representar con precisión la fuente, simplemente como un resultado desnormalizado. Deja que los consumidores downstream apliquen su propia lógica de negocio, utilizando los datos desnormalizados como una única fuente de verdad.
Si no deseas utilizar un unificador downstream, hay otras opciones. Veamos el patrón de bandeja de salida transaccional a continuación.
Opción 2: Patrón de Bandeja de Salida Transaccional
Primero, crea una tabla de bandeja de salida dedicada para escribir eventos en el flujo.
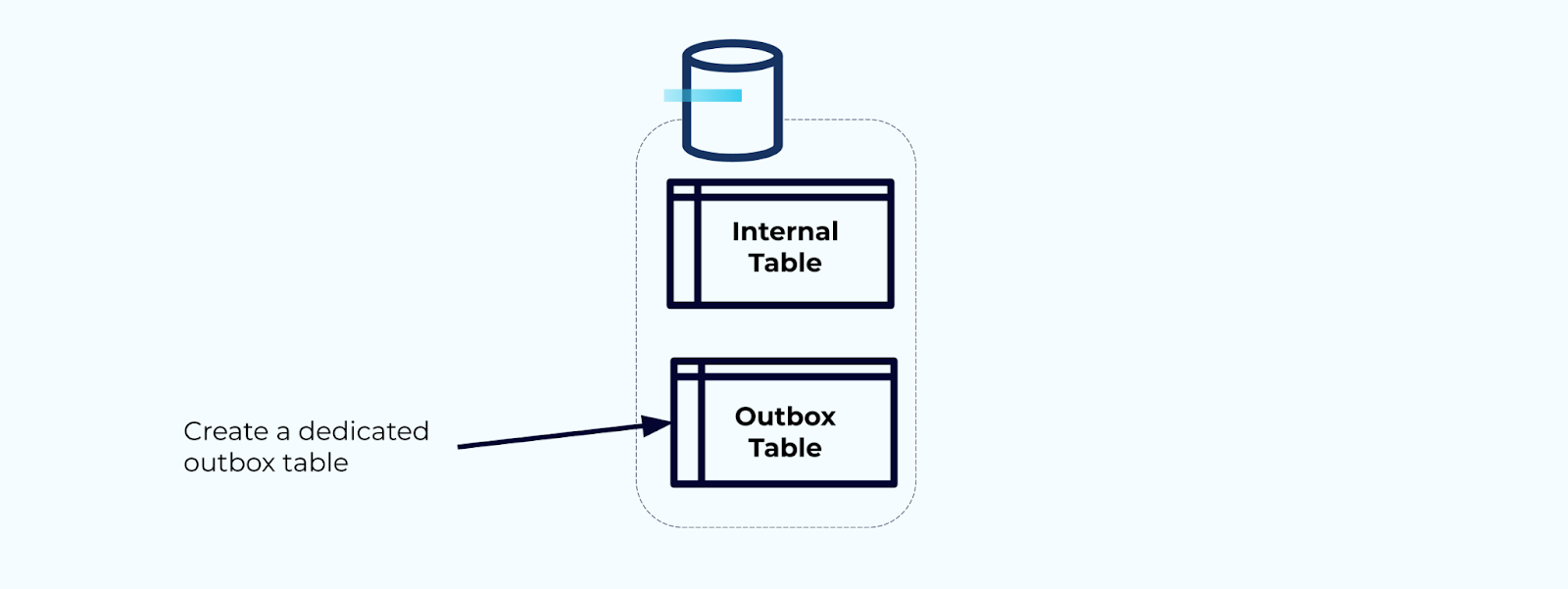
Segundo, envuelve todas las actualizaciones necesarias de las tablas internas dentro de una transacción. Las transacciones garantizan que cualquier actualización realizada en la tabla interna también se escribirá en la tabla de salida.
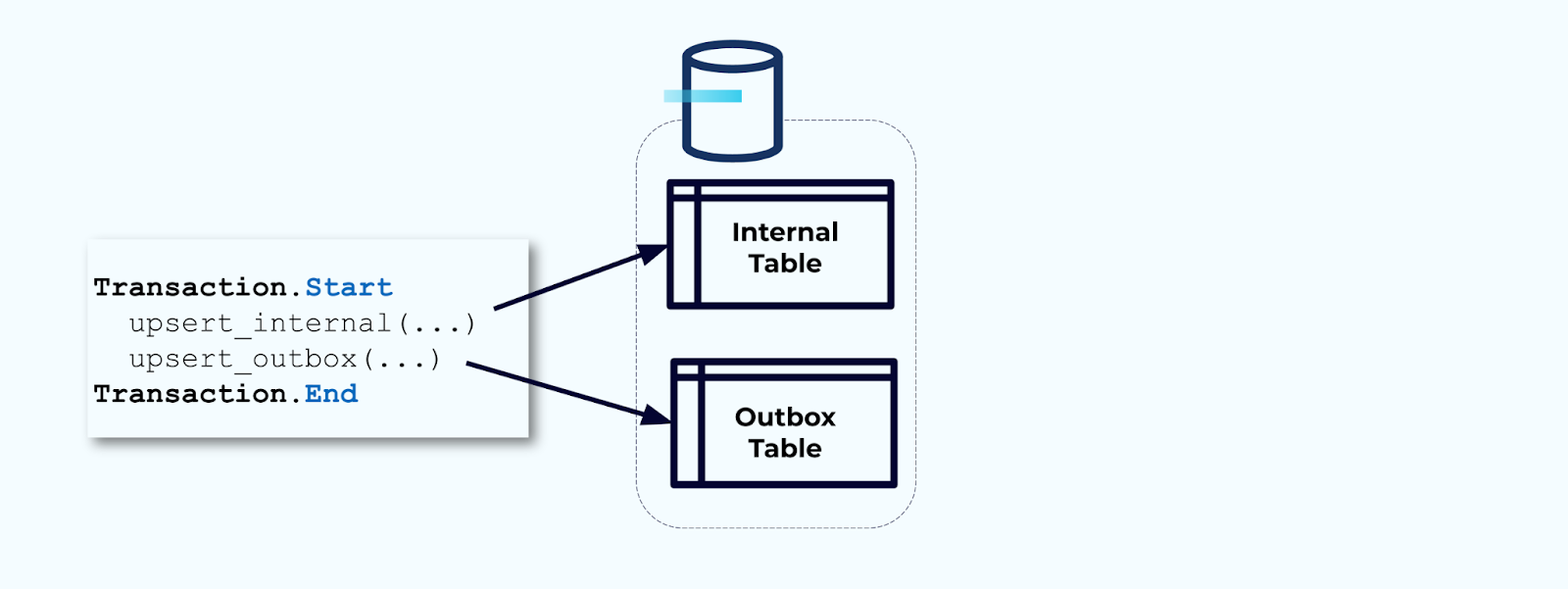
La tabla de salida te permite aislar el modelo de datos interno ya que puedes unir y transformar los datos antes de escribirlos en tu tabla de salida. La tabla de salida actúa como la capa de abstracción entre tus datos internos y los datos externos, funcionando como un contrato de datos para tus consumidores.
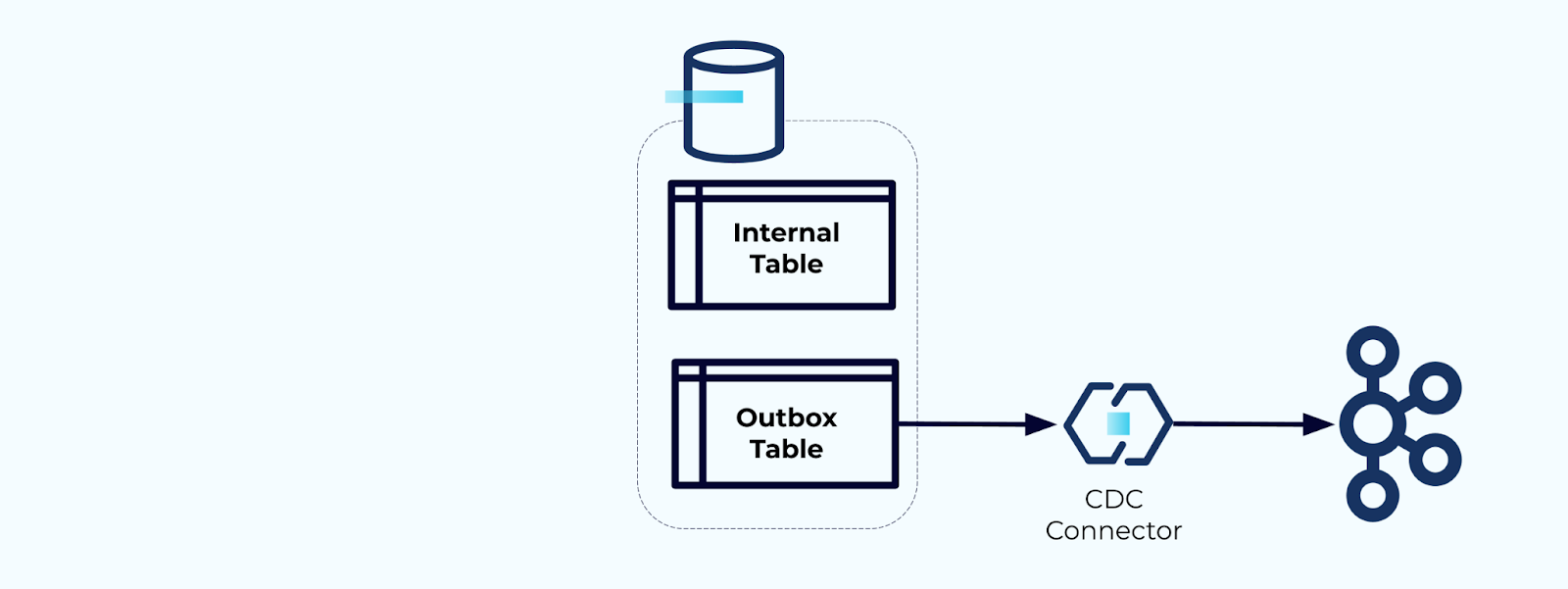
Finalmente, puedes usar un conector para obtener los datos de la tabla de salida y llevarlos a Kafka.
Debes asegurarte de que la tabla de salida no crezca indefinidamente: elimina los datos después de que sean capturados por el CDC o periódicamente con un trabajo programado.
Ejemplo: Desnormalizar eventos de seguimiento del comportamiento del usuario
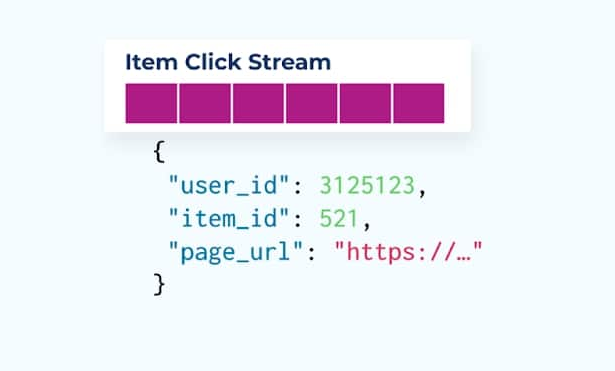
El seguimiento del comportamiento del usuario en tus páginas web y aplicaciones es una fuente común de eventos normalizados – piensa en Google Analytics u opciones internas de primera parte. Pero no incluimos toda la información en el evento; en su lugar, lo limitamos a identificadores (más rápidos, más pequeños, más baratos), desnormalizando después de que los hechos se crean.
Considera una secuencia de eventos de clics en artículos que detallan cuándo un usuario ha hecho clic en un artículo mientras navega por artículos de comercio electrónico. Ten en cuenta que este evento de clic en el artículo no contiene información más rica del artículo como nombre, precio y descripción, solo ids básicos.
Lo primero que hacen muchos consumidores de flujo de clics es unirlo con el flujo de hechos del artículo. Y dado que estás lidiando con muchos eventos de clic, descubres que termina utilizando una gran cantidad de recursos computacionales. Una aplicación de Flink construida con un propósito específico puede unir los clics del artículo con los datos detallados del artículo y emitirlos a un flujo enriquecido de clics del artículo.
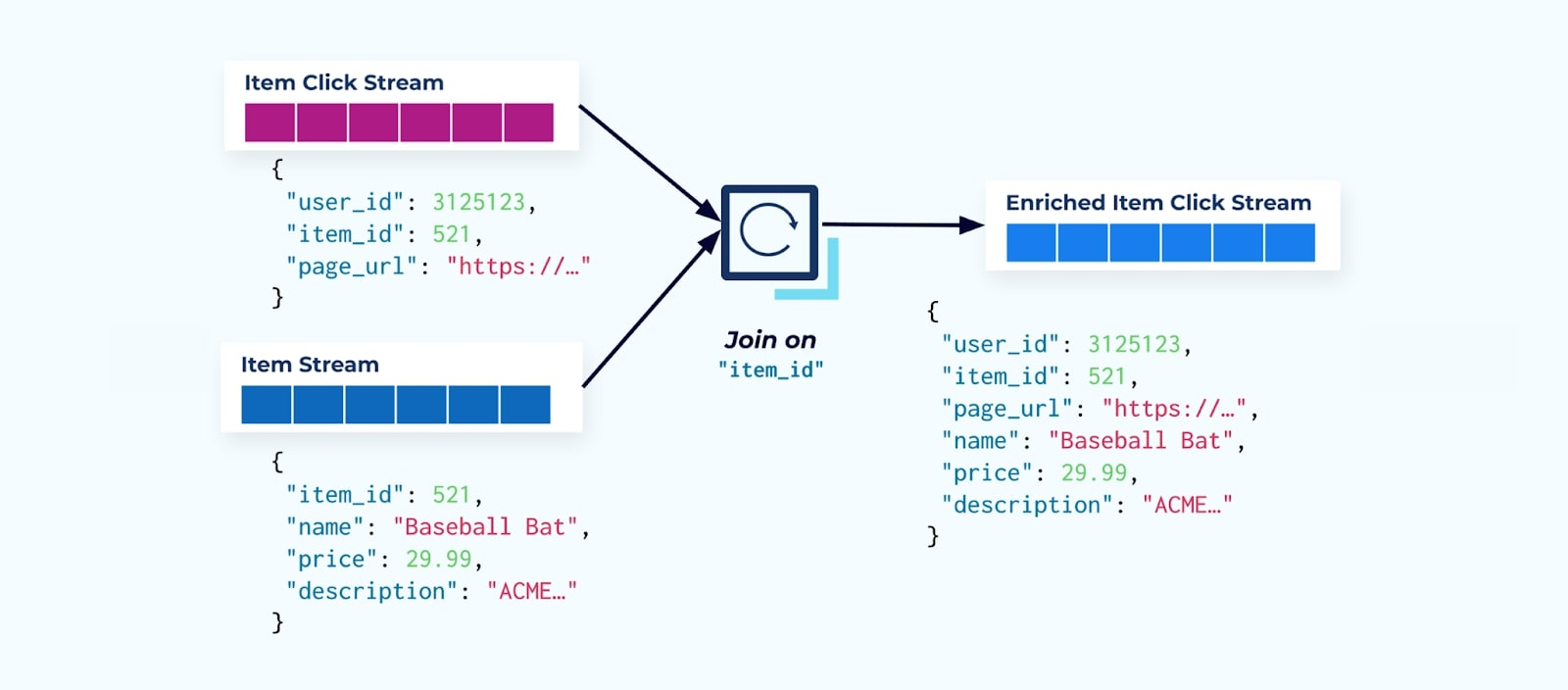
Las compañías más grandes con múltiples divisiones (y sistemas) probablemente verán que sus datos provienen de diferentes fuentes, y unir después del hecho utilizando un unidor de flujos es el resultado más probable.
Consideraciones sobre Dimensiones que Cambian Lentamente
Ya hemos discutido las consideraciones de rendimiento de escribir eventos que contienen grandes conjuntos de datos (por ejemplo, grandes blobs de texto) y dominios de datos que cambian con frecuencia (por ejemplo, inventario de artículos). Ahora, examinaremos las dimensiones que cambian lentamente (SCD, por sus siglas en inglés), a menudo indicadas mediante una relación de clave foránea, ya que estas pueden ser otra fuente de volúmenes significativos de datos.
Volvamos a nuestro ejemplo del artículo. Digamos que tienes una operación que actualiza la Tabla de Artículos. Vamos a cambiar el nombre del artículo de Yunque a Yunque de Hierro.
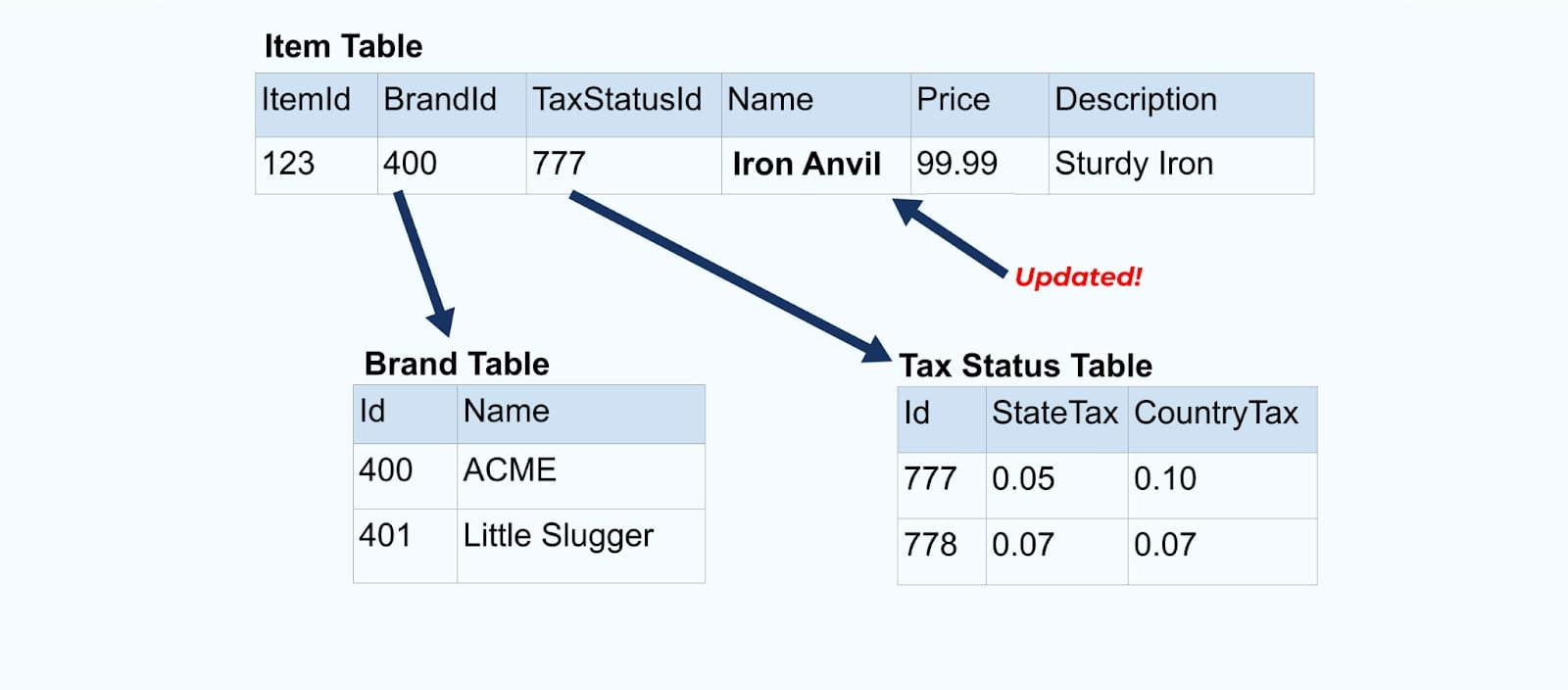
Al actualizar los datos en la base de datos, también emitimos el artículo actualizado (digamos mediante el patrón de buzón de salida), completo con el estado fiscal desnormalizado y la tabla de marca.
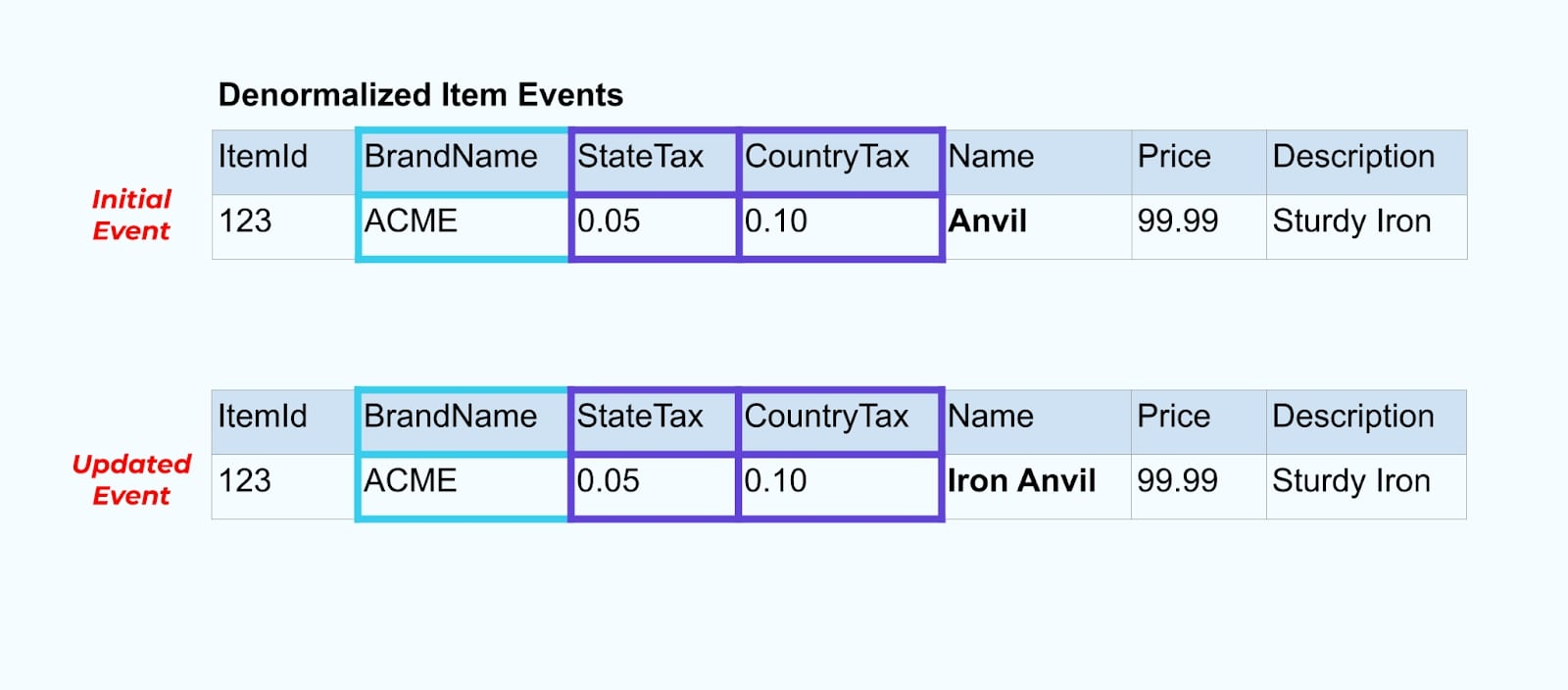
Sin embargo, también necesitamos considerar qué sucede cuando cambiamos valores en las tablas de marca o impuestos. Actualizar una de estas dimensiones que cambian lentamente puede resultar en una cantidad significativamente grande de actualizaciones para todos los artículos afectados.
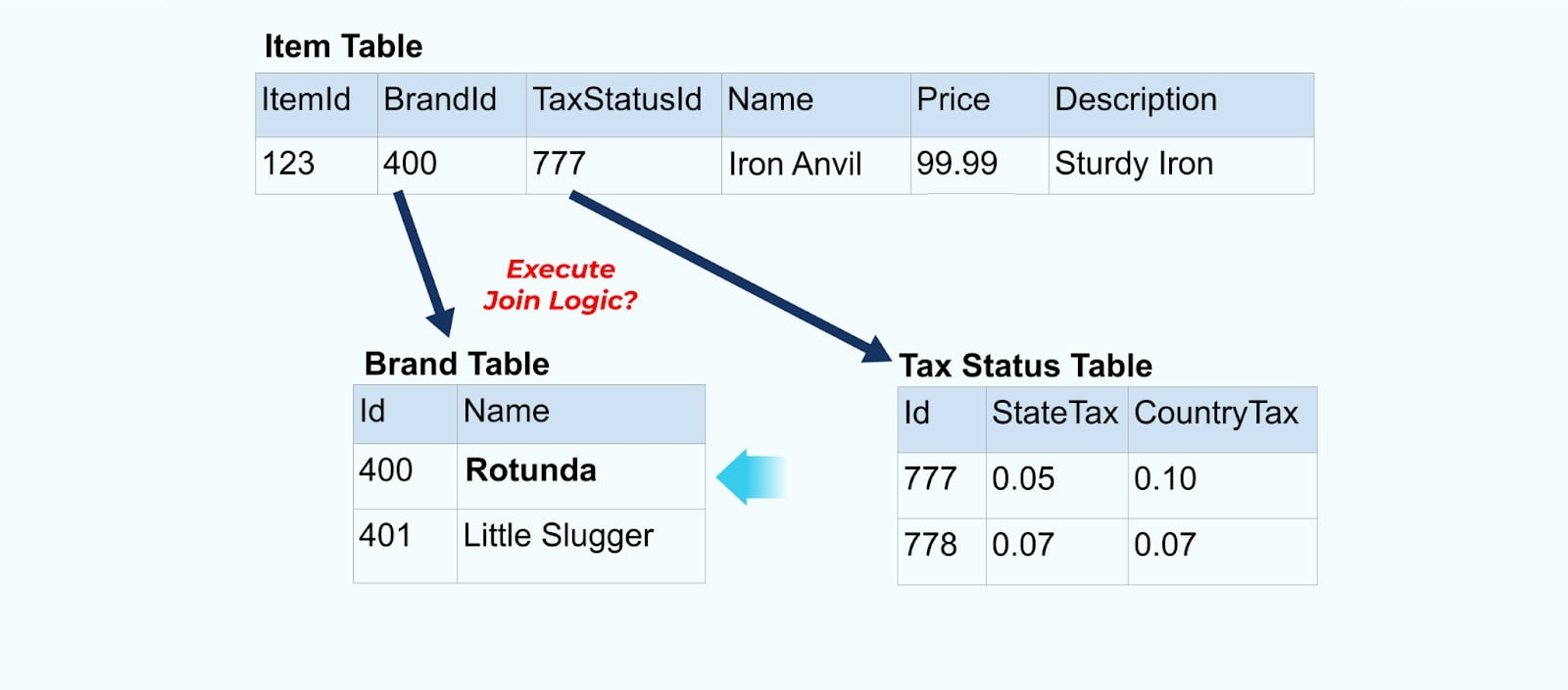
Por ejemplo, la empresa ACME atraviesa un proceso de rebranding y adopta un nuevo nombre de marca, cambiando de ACME a Rotunda. Producimos otro evento para ItemId=123.
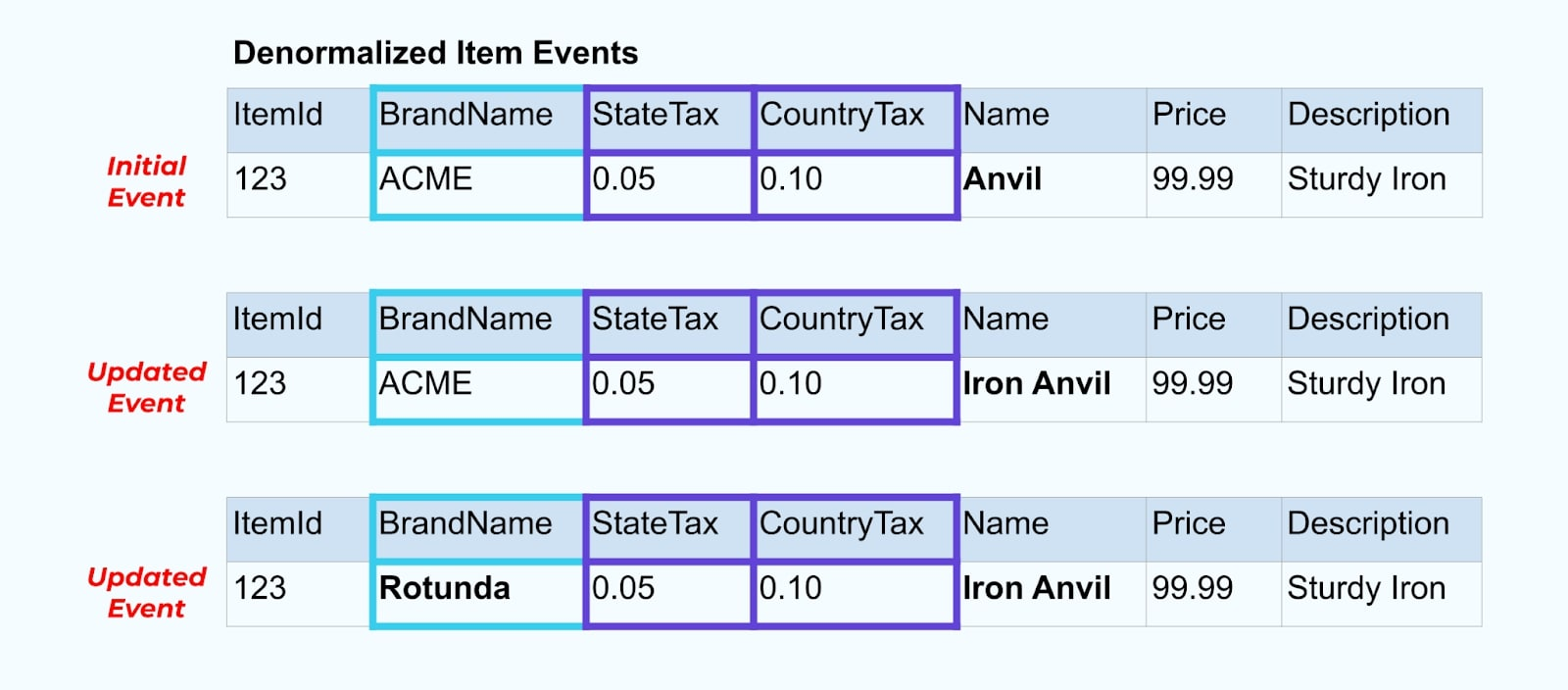
Sin embargo, Rotunda (anteriormente ACME) probablemente tiene cientos (o miles) de artículos que también se actualizan con este cambio, resultando en una cantidad correspondiente de eventos de artículos enriquecidos actualizados.
Al desnormalizar SCDs y relaciones de clave foránea, ten en cuenta el impacto que un cambio en el SCD puede tener en el flujo de eventos en su totalidad. Puede que decidas omitir la desnormalización y dejarla en manos del consumidor en el caso de que cambiar el SCD resulte en millones o miles de millones de eventos actualizados.
Resumen
La desnormalización facilita el uso de datos para los consumidores, pero conlleva un mayor procesamiento upstream y una cuidadosa selección de los datos a incluir. Los consumidores pueden tener una tarea más fácil al construir aplicaciones y pueden elegir entre una gama más amplia de tecnologías, incluidas aquellas que no admiten de forma nativa uniones de streaming.
La normalización de datos upstream funciona bien cuando los datos son pequeños y se actualizan con poca frecuencia. Los tamaños de eventos más grandes, las actualizaciones frecuentes y los SCDs son todos factores a tener en cuenta al determinar qué desnormalizar upstream y qué dejar para que los consumidores hagan por su cuenta.
En última instancia, elegir qué datos incluir en un evento y qué dejar fuera es un acto de equilibrio entre las necesidades de los consumidores, las capacidades de los productores y las relaciones únicas del modelo de datos. Pero el mejor lugar para comenzar es entendiendo las necesidades de tus consumidores y la isolación del modelo de datos interno de tu sistema de origen.
Source:
https://dzone.com/articles/how-to-design-event-streams-part-2