













Hubo momentos en que creamos trabajos de Jenkins únicamente mediante la interfaz de usuario. Posteriormente, se planteó la idea de la canalización como código para abordar la creciente complejidad con los trabajos de compilación y despliegue. En Jenkins 2.0, el equipo de Jenkins introdujo el Jenkinsfile para lograr la canalización como código. Si deseas crear una canalización automatizada de solicitud de extracción o basada en ramas de Jenkins Integración Continua y Entrega Continua, la canalización de multirrama de Jenkins es la opción a seguir.
Dado que la canalización de multirrama de Jenkins es completamente basada en git como código, puedes desarrollar tus flujos de trabajo de CI/CD. La Canalización como Código (PaaC) facilita llevar las ventajas de la automatización y la portabilidad en la nube a tus pruebas de Selenium. Puedes utilizar el modelo de canalización de multirrama para construir, probar, desplegar, monitorizar, reportar y gestionar rápida y confiablemente tus pruebas de Selenium, y mucho más. En este tutorial de Jenkins, revisaremos cómo crear una canalización de multirrama de Jenkins y los conceptos clave involucrados en la configuración de una canalización de multirrama de Jenkins para pruebas de automatización de Selenium.
Empecemos.
¿Qué es la Canalización de Multirrama de Jenkins?
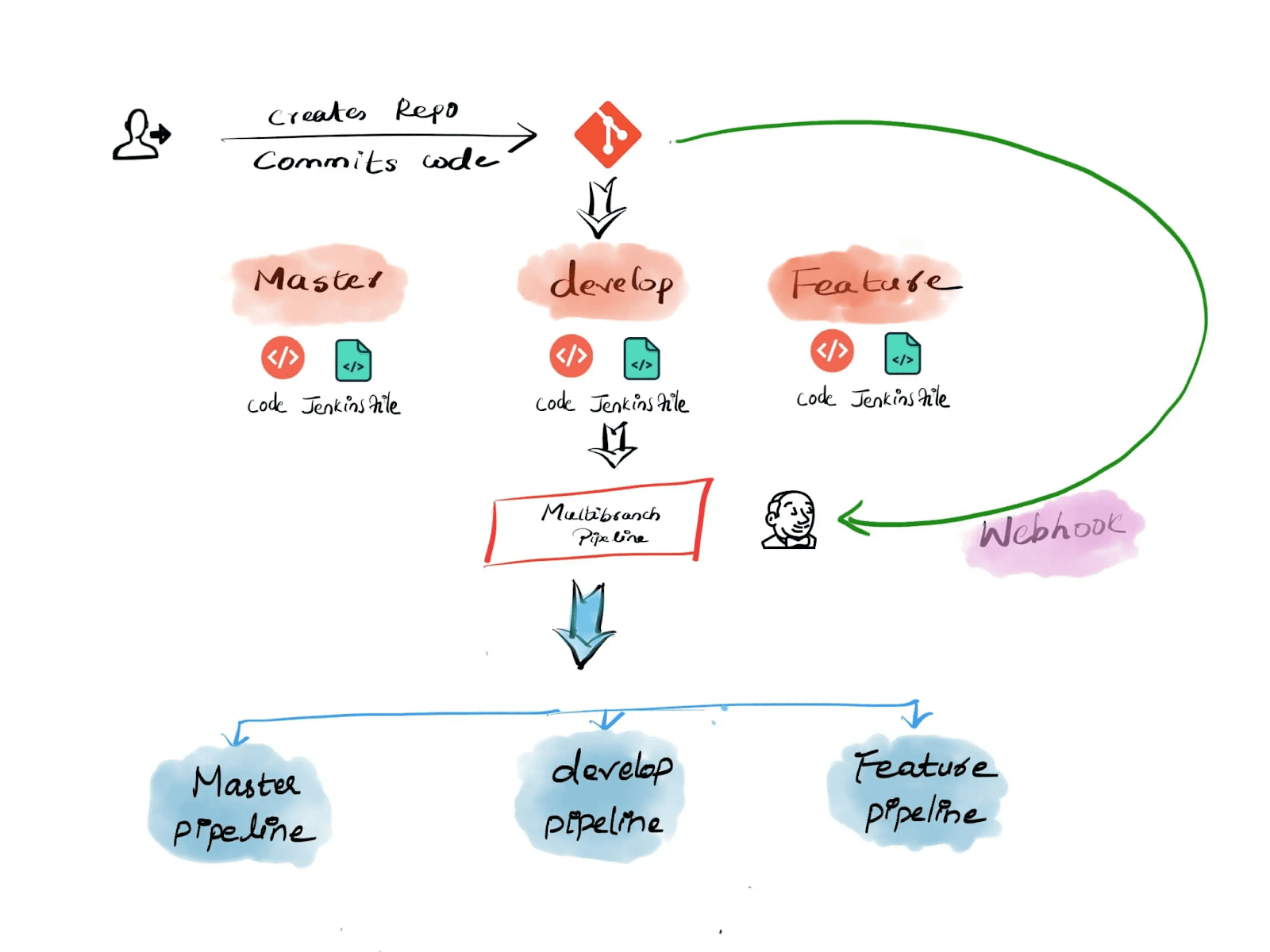
Según la documentación oficial, el tipo de trabajo de canalización de multirrama te permite definir un trabajo donde, a partir de un solo repositorio git, Jenkins detectará múltiples ramas y creará trabajos anidados cuando encuentre un Jenkinsfile.
Según la definición anterior, podemos entender que Jenkins puede escanear el repositorio Git para buscar un Jenkinsfile y crear trabajos automáticamente. Todo lo que necesita de nosotros son los detalles del Repositorio Git. En este artículo, vamos a utilizar un repositorio de GitHub de ejemplo. Nuestro repositorio de GitHub de ejemplo contiene un proyecto de Spring Boot de ejemplo, que puede ser desplegado en Tomcat.
En el directorio raíz del proyecto, tenemos el Jenkinsfile. Utilizamos la sintaxis de la tubería declarativa de Jenkins para crear este Jenkinsfile. Si eres nuevo en la tubería declarativa de Jenkins, por favor lee nuestro artículo detallado aquí.
Jenkinsfile de ejemplo
pipeline {
agent any
stages {
stage('Build Code') {
steps {
sh """
echo "Building Artifact"
"""
}
}
stage('Deploy Code') {
steps {
sh """
echo "Deploying Code"
"""
}
}
}
}Creamos dos etapas “Compilar Código” y “Desplegar Código” en nuestro Jenkinsfile, cada una de ellas configurada para imprimir mensajes apropiados. Ahora, tenemos el repositorio Git con Jenkinsfile listo.
Vamos a crear una canalización multinúcleo en el servidor de Jenkins.
Canalización de Jenkins vs Canalización multinúcleo de Jenkins
La canalización de Jenkins es la nueva sensación, pero no es para todos. Y las canalizaciones multinúcleo siguen siendo increíbles. En esta sección del tutorial de canalización multinúcleo de Jenkins, comprendamos los casos de uso ideales para la canalización de Jenkins y la canalización multinúcleo de Jenkins a través de esta comparación de canalización de Jenkins vs canalización multinúcleo de Jenkins.
Jenkins pipeline es un sistema de configuración de trabajos que te permite configurar un pipeline de trabajos, que se ejecutarán automáticamente en tu nombre. Un Jenkins pipeline puede tener múltiples etapas y cada etapa será ejecutada por un solo agente, todos corriendo en una sola máquina o múltiples máquinas. Un pipeline se crea normalmente para una rama específica del código fuente. Cuando creas un nuevo trabajo, verás una opción para seleccionar el repositorio de código fuente y la rama. También puedes crear un pipeline fresco para un nuevo proyecto o nueva característica de un proyecto existente.
Jenkins pipeline te permite tener un Jenkinsfile flexible con etapas para tu compilación. Así, puedes tener una etapa inicial donde ejecutas linting, pruebas, etc., y luego etapas separadas para construir artefactos o desplegarlos. Esto es muy útil cuando deseas hacer múltiples cosas en tu pipeline.
¿Qué pasa si solo tienes una cosa que hacer? ¿O si todas las cosas que deseas hacer son diferentes dependiendo de alguna configuración? ¿Tiene sentido usar Jenkins pipeline aquí?
El pipeline multibranch es un enfoque alternativo que podría ser más adecuado en estos casos. El pipeline multibranch te permite dividir tareas en ramas y fusionarlas más tarde. Esto es muy similar a cómo funcionan las ramas en Git.
A multibranch pipeline is a pipeline that has multiple branches. The main advantage of using a multibranch pipeline is to build and deploy multiple branches from a single repository. Having a multibranch pipeline also allows you to have different environments for different branches. However, it is not recommended to use a multibranch pipeline if you do not have a standard branching and CI/CD strategy.
Ahora, ya que has visto la comparación entre Jenkins pipeline y multibranch pipeline, veamos los pasos para crear un Jenkins multibranch pipeline.
Creando un Jenkins Multibranch Pipeline
Paso 1
Abre la página principal de Jenkins (http://localhost:8080 en local) y haz clic en “Nuevo Elemento” en el menú de la izquierda.
Paso 2
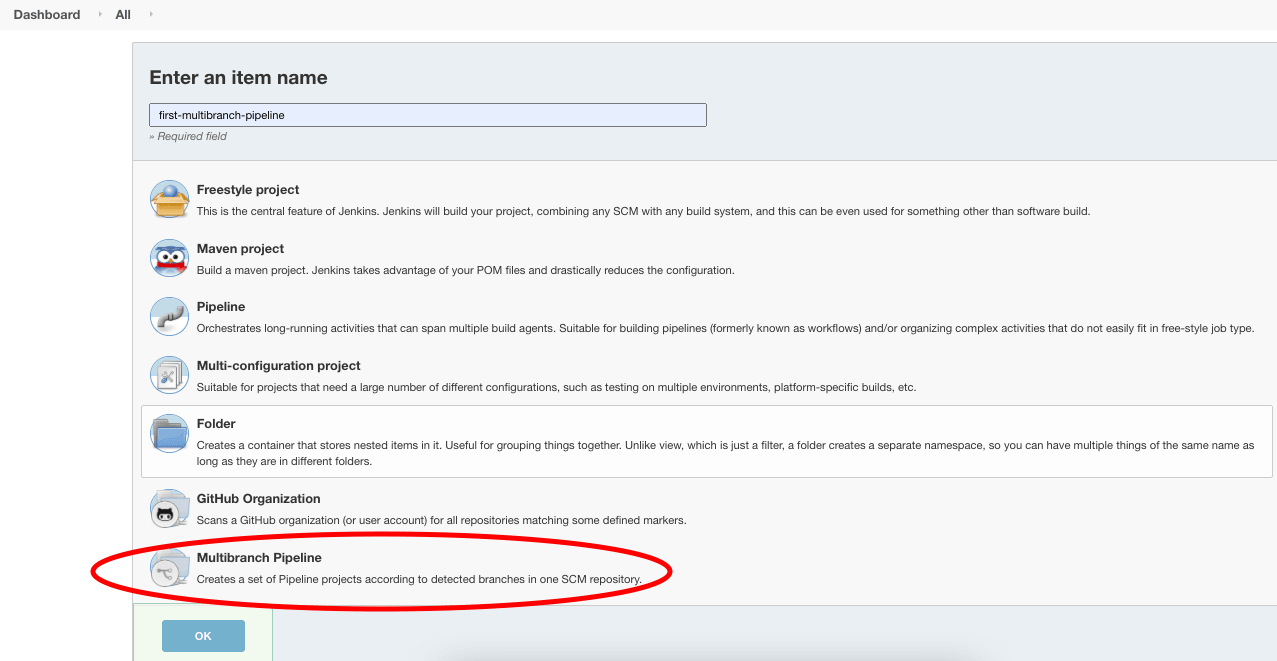
Introduce el nombre del trabajo de Jenkins, selecciona el estilo como “canal multinivel,” y haz clic en “Aceptar.”
Paso 3
En la página “Configurar”, solo necesitamos configurar una cosa: La fuente del repositorio Git.
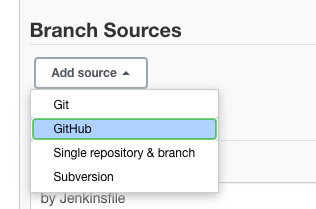
Desplázate hacia abajo hasta la sección “Fuentes de Ramas” y haz clic en el menú desplegable “Agregar Fuente”.
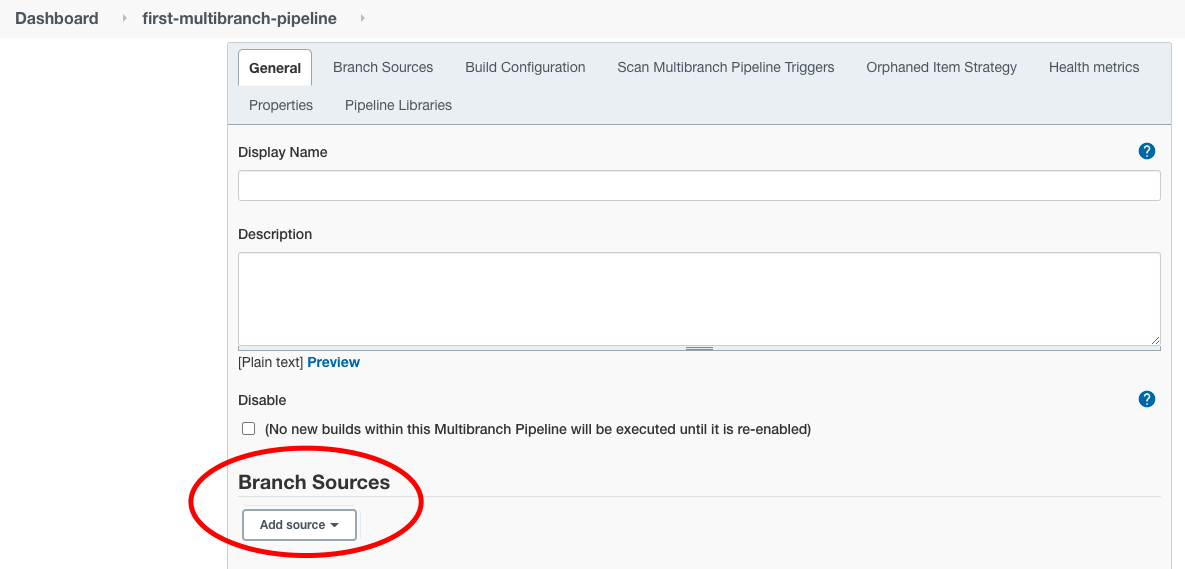
Selecciona “GitHub” como fuente porque nuestro repositorio de ejemplo en GitHub está alojado allí.
Paso 4
Introduce la URL HTTPS del repositorio como https://github.com/iamvickyav/spring-boot-h2-war-tomcat.git y haz clic en “Validar.”
Dado que nuestro repositorio en GitHub está alojado como repositorio público, no necesitamos configurar credenciales para acceder a él. Para repositorios empresariales/privados, puede que necesitemos credenciales para acceder a ellos.

El mensaje “Credenciales correctas” representa que la conexión entre el servidor de Jenkins y el repositorio Git es exitosa.
Paso 5
Deja el resto de las secciones de configuración tal cual por ahora y haz clic en el botón “Guardar” en la parte inferior.
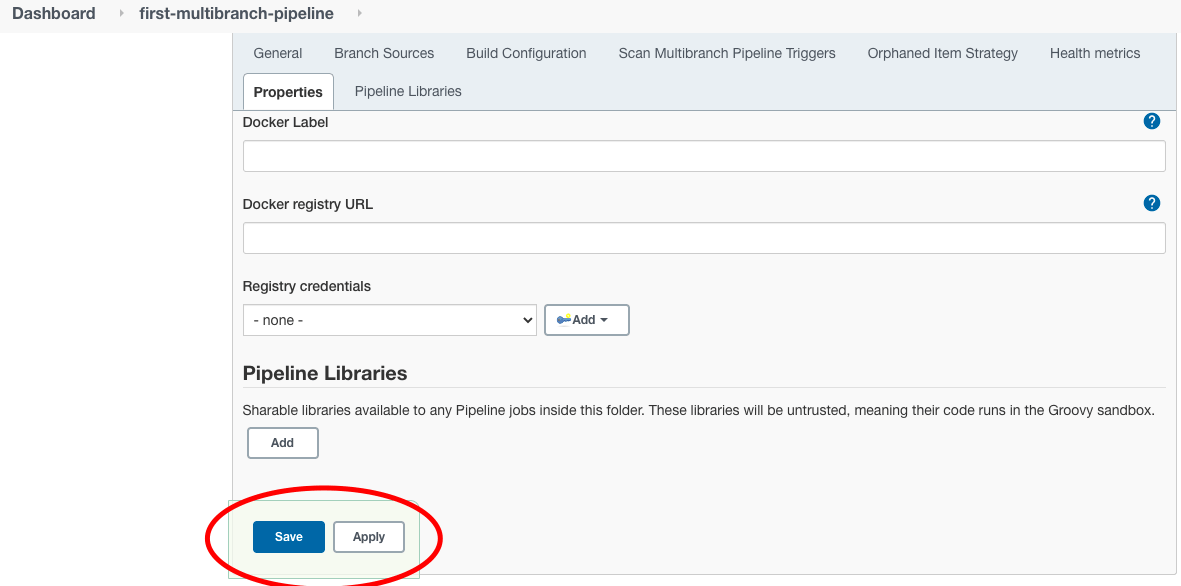
Al guardar, Jenkins realizará automáticamente los siguientes pasos:
Escaneo del Repositorio
- Escanea el repositorio Git que configuramos.
- Busca la lista de ramas disponibles en el repositorio Git.
- Selecciona las ramas que tienen Jenkinsfile.
Ejecución de Construcción
- Ejecutar la compilación para cada una de las ramas encontradas en el paso anterior con los pasos mencionados en el Jenkinsfile.
Desde la sección “Scan Repository Log”“, podemos entender lo que sucedió durante el paso de escaneo del repositorio.
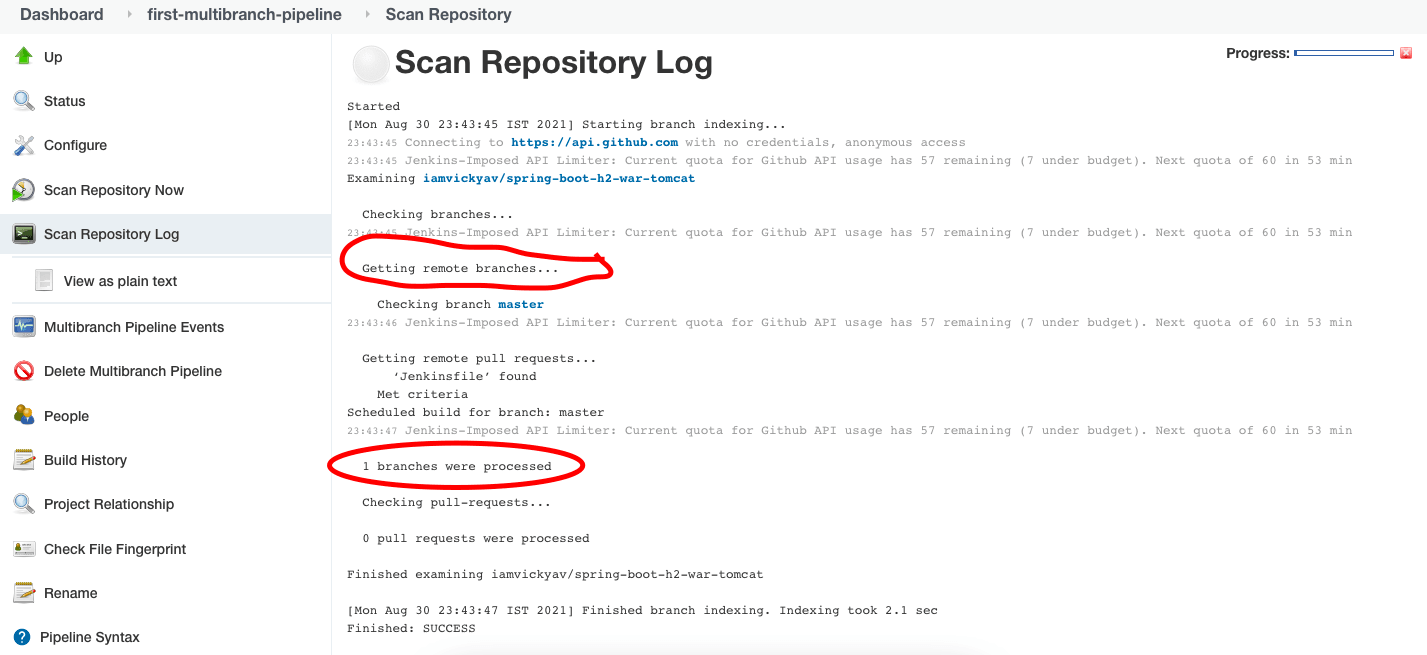
Como solo tenemos una rama master en nuestro repositorio git, el Log de Escaneo del Repositorio dice “Se procesaron 1 rama(s).”
Una vez completado el escaneo, Jenkins creará y ejecutará un trabajo de compilación para cada rama procesada por separado.
En nuestro caso, solo teníamos una rama llamada master. Por lo tanto, la compilación se ejecutará solo para nuestra rama master. Podemos verificarlo haciendo clic en “Status”” en el menú de la izquierda.
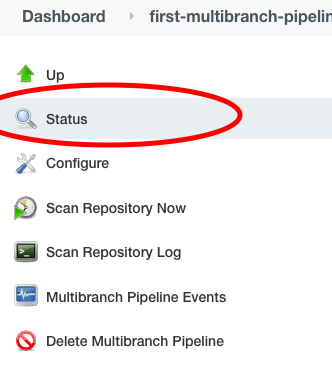
Podemos ver un trabajo de compilación creado para la rama master en la sección de estado.
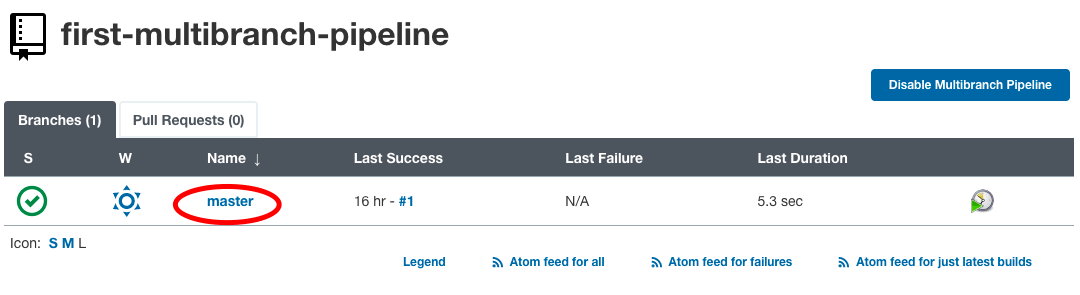
Haga clic en el nombre de la rama para ver el registro y el estado del trabajo de compilación.
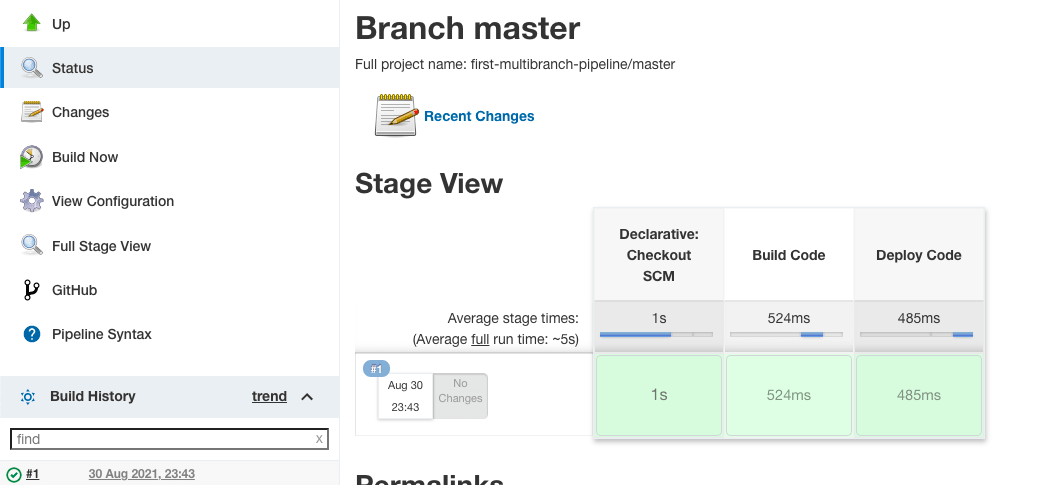
“Stage View”” proporciona una representación visual del tiempo que tardó cada etapa en ejecutarse y el estado del trabajo de compilación.
Acceder a los Registros de Ejecución del Trabajo de Compilación
Paso 1
Haga clic en el “Número de compilación”” en la sección “Historial de compilaciones”“.
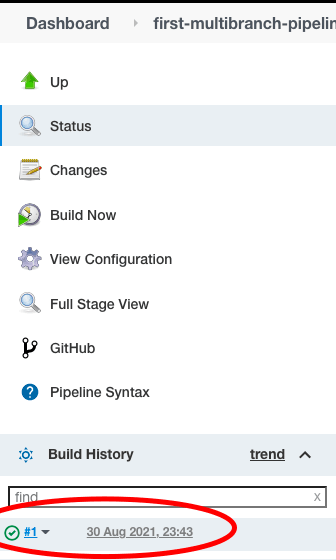
Paso 2
A continuación, elija “Salida de la consola”” en el menú de la izquierda para ver los registros.
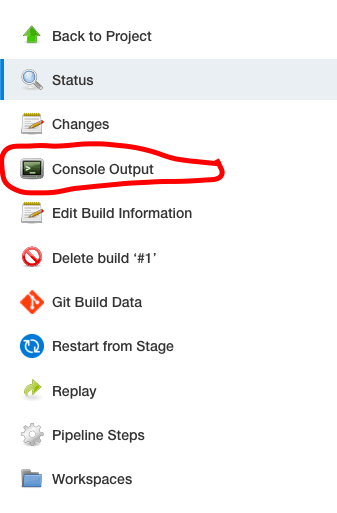
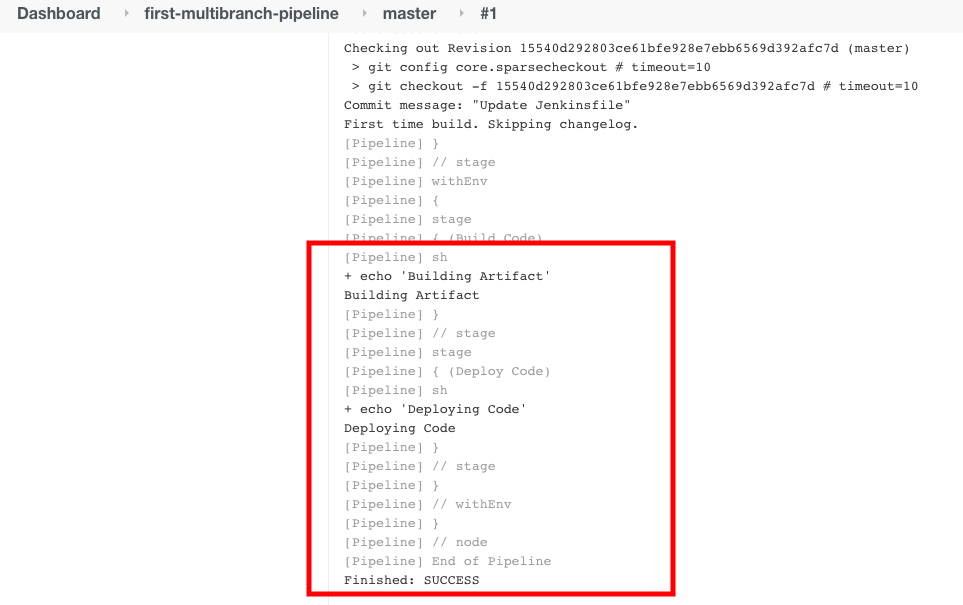
¿Qué sucede si tenemos más de una rama en nuestro repositorio Git? Vamos a comprobarlo ahora.
En el repositorio Git, se crea una nueva rama llamada “develop”“.
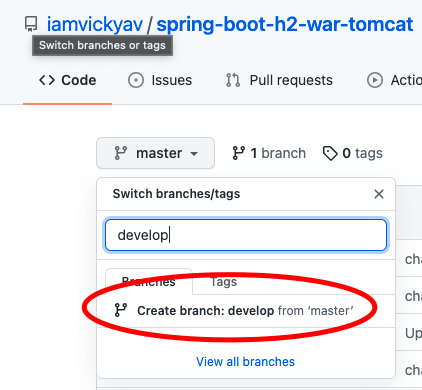
Para diferenciar la compilación de la rama “desarrollo“, hicimos pequeños cambios en los comandos echo en Jenkinsfile.
Jenkinsfile en la Rama Maestra
pipeline {
agent any
stages {
stage('Build Code') {
steps {
sh """
echo "Building Artifact"
"""
}
}
stage('Deploy Code') {
steps {
sh """
echo "Deploying Code"
"""
}
}
}
}Jenkinsfile en la Rama Desarrollo
pipeline {
agent any
stages {
stage('Build Code') {
steps {
sh """
echo "Building Artifact from Develop Branch"
"""
}
}
stage('Deploy Code') {
steps {
sh """
echo "Deploying Code from Develop Branch"
"""
}
}
}
}Ahora, tenemos dos Jenkinsfile en dos ramas diferentes. Vamos a volver a ejecutar el escaneo del repositorio en Jenkins para ver el comportamiento.
Podemos ver que la nueva rama (rama de desarrollo) fue detectada por Jenkins. Por lo tanto, se creó un nuevo trabajo por separado para la rama de desarrollo.
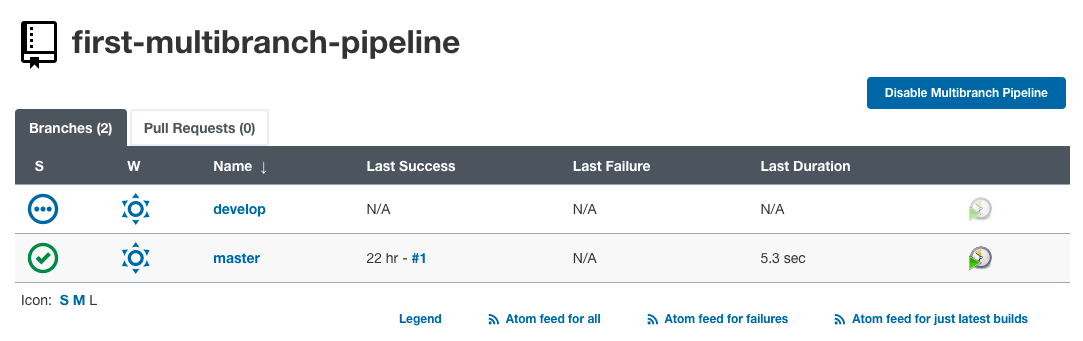
Al hacer clic en “desarrollo“, podemos ver el registro del trabajo de compilación de la rama de desarrollo.
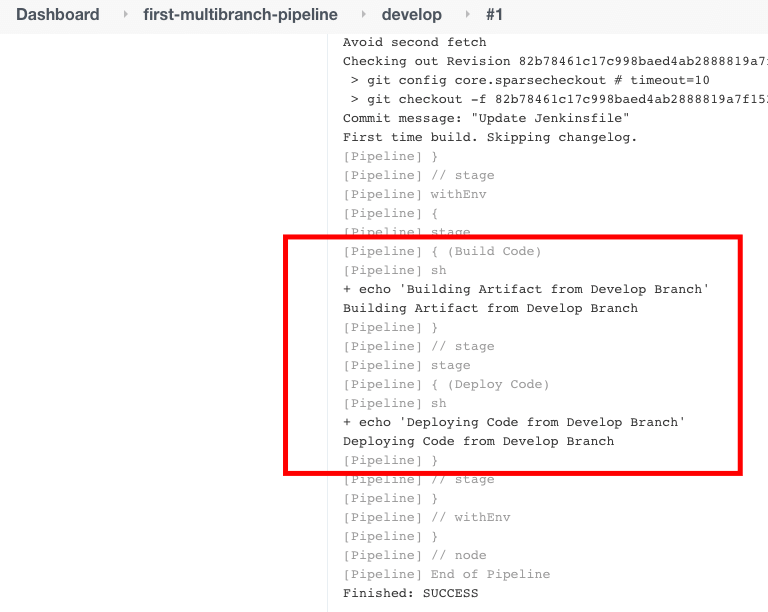
En el ejemplo anterior, mantuvimos contenidos diferentes para Jenkinsfile en las ramas maestra y desarrollo. Pero no es así como lo hacemos en aplicaciones del mundo real. Utilizamos bloques when dentro del bloque stage para verificar la rama.
Aquí hay un ejemplo con pasos combinados para las ramas maestra y desarrollo. Este mismo contenido se colocará en ambos Jenkinsfiles de las ramas maestra y desarrollo.
pipeline {
agent any
stages {
stage('Master Branch Deploy Code') {
when {
branch 'master'
}
steps {
sh """
echo "Building Artifact from Master branch"
"""
sh """
echo "Deploying Code from Master branch"
"""
}
}
stage('Develop Branch Deploy Code') {
when {
branch 'develop'
}
steps {
sh """
echo "Building Artifact from Develop branch"
"""
sh """
echo "Deploying Code from Develop branch"
"""
}
}
}
}Paso 3
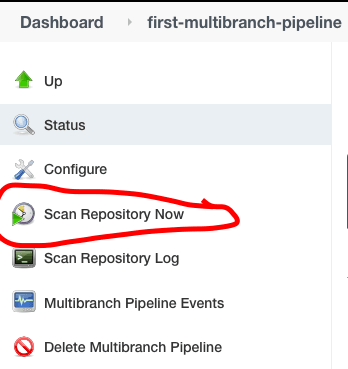
Haga clic en “Escanear Repositorio” desde el menú de la izquierda para que Jenkins detecte los nuevos cambios del repositorio Git.
Para este momento, podría haber notado que estamos usando el escaneo del repositorio cada vez que queremos que Jenkins detecte los cambios del repositorio.
¿Qué tal automatizar este paso?
Disparador Periódico para Escaneo de Pipeline Multirrama de Jenkins
Paso 1
Haga clic en “Configurar” desde el menú de la izquierda.
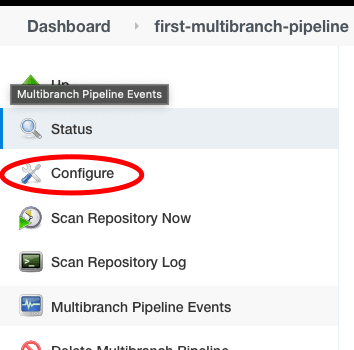
Paso 2
Desplácese hacia abajo hasta la sección “Scan Repository Triggers” y habilite la casilla “Periodically if not otherwise run” y elija el intervalo de tiempo para que se ejecute el escaneo de forma periódica (dos minutos en nuestro ejemplo).
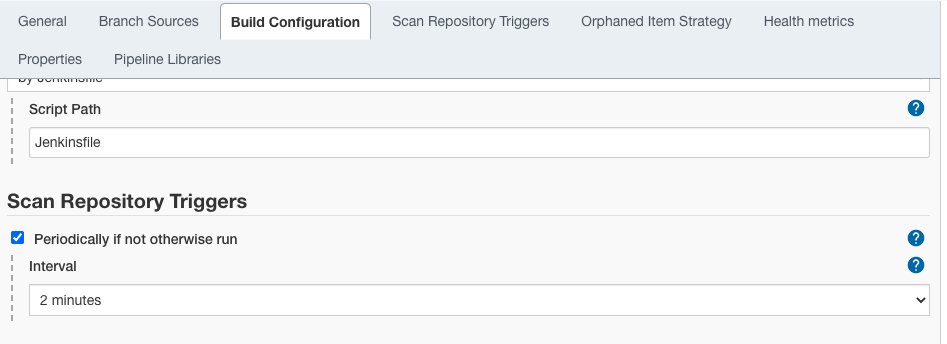
Paso 3
Haga clic en el botón “Save“.
A partir de ahora, Jenkins escaneará el repositorio cada dos minutos. Si se encuentra un nuevo commit en cualquier rama, Jenkins ejecutará un nuevo trabajo de compilación para esa rama específica utilizando Jenkinsfile.
A continuación se encuentra el “Scan Repository Log“, que muestra claramente el escaneo desencadenado cada dos minutos.

Casos de Uso en Tiempo Real para Jenkins Multibranch Pipeline
A continuación se presentan algunos escenarios en los que Jenkins multibranch pipeline puede ser útil:
- Cualquier nuevo commit en la rama master debe ser desplegado en el servidor automáticamente.
- Si un desarrollador intenta realizar una Solicitud de Extracción (Pull Request, PR) para desarrollar una rama, entonces:
- El código debe compilarse exitosamente sin errores de compilación.
- El código debe tener al menos un 80% de cobertura de pruebas.
- El código debe pasar la prueba de calidad de código de SONAR.
- Si los desarrolladores intentan enviar código a una rama que no sea master o develop, el código debe compilarse exitosamente. De lo contrario, enviar un correo de alerta.
Aquí hay un ejemplo de Jenkinsfile que cubre algunos de los casos de uso mencionados anteriormente:
pipeline {
agent any
tools {
maven 'MAVEN_PATH'
jdk 'jdk8'
}
stages {
stage("Tools initialization") {
steps {
sh "mvn --version"
sh "java -version"
}
}
stage("Checkout Code") {
steps {
checkout scm
}
}
stage("Check Code Health") {
when {
not {
anyOf {
branch 'master';
branch 'develop'
}
}
}
steps {
sh "mvn clean compile"
}
}
stage("Run Test cases") {
when {
branch 'develop';
}
steps {
sh "mvn clean test"
}
}
stage("Check Code coverage") {
when {
branch 'develop'
}
steps {
jacoco(
execPattern: '**/target/**.exec',
classPattern: '**/target/classes',
sourcePattern: '**/src',
inclusionPattern: 'com/iamvickyav/**',
changeBuildStatus: true,
minimumInstructionCoverage: '30',
maximumInstructionCoverage: '80')
}
}
stage("Build and Deploy Code") {
when {
branch 'master'
}
steps {
sh "mvn tomcat7:deploy"
}
}
}
}Hemos comprometido este nuevo Jenkinsfile en las ramas master y develop, para que pueda ser detectado por el Jenkins multibranch en el próximo escaneo del repositorio.
Pruebas de Automatización de Selenium con Pipeline Multibranch de Jenkins
Consideremos que estamos escribiendo casos de prueba automatizados para un sitio web. Cuando se compromete un nuevo caso de prueba en una rama, queremos ejecutarlos y asegurarnos de que se están ejecutando como se esperaba.
Ejecutar casos de prueba automatizados en cada combinación de navegador y sistema operativo es una pesadilla para cualquier desarrollador. Ahí es donde la potente infraestructura de pruebas automatizadas de LambdaTest puede resultar útil.
Usando la cuadrícula Selenium de LambdaTest, puedes maximizar tu cobertura de navegadores.
En esta sección, veremos cómo aprovechar la infraestructura de pruebas de LambdaTest con el pipeline multibranch de Jenkins. Para demostrarlo, alojamos una aplicación de muestra Todo aquí: Aplicación Todo de LambdaTest. Casos de prueba automatizados escritos con Cucumber se han comprometido en el repositorio de muestra.
Desde Jenkins, queremos ejecutar estos casos de prueba en la plataforma de LambdaTest. Ejecutar casos de prueba en LambdaTest requiere un nombre de usuario y un accessToken. Regístrate en la plataforma de LambdaTest de forma gratuita para obtener tus credenciales.
Configuración de Variable de Entorno
Cuando se ejecuta el caso de prueba, buscarán el nombre de usuario de LambdaTest (LT_USERNAME) y la contraseña (LT_ACCESS_KEY) en variables de entorno. Por lo tanto, necesitamos configurarlas con anticipación.
Para evitar almacenarlas con el código fuente, las configuramos como secretos en Jenkins y cargamos variables de entorno desde ellas:
environment {
LAMBDATEST_CRED = credentials('Lambda-Test-Credentials-For-multibranch')
LT_USERNAME = "$LAMBDATEST_CRED_USR"
LT_ACCESS_KEY = "$LAMBDATEST_CRED_PSW"
}Aquí está nuestro Jenkinsfile final:
pipeline {
agent any
tools {
maven 'MAVEN_PATH'
jdk 'jdk8'
}
stages {
stage("Tools initialization") {
steps {
sh "mvn --version"
sh "java -version"
}
}
stage("Checkout Code") {
steps {
checkout scm
}
}
stage("Check Code Health") {
when {
not {
anyOf {
branch 'master';
branch 'develop'
}
}
}
steps {
sh "mvn clean compile"
}
}
stage("Run Test cases in LambdaTest") {
when {
branch 'develop';
}
environment {
LAMBDATEST_CRED = credentials('Lambda-Test-Credentials-For-multibranch')
LT_USERNAME = "$LAMBDATEST_CRED_USR"
LT_ACCESS_KEY = "$LAMBDATEST_CRED_PSW"
}
steps {
sh "mvn test"
}
}
}
}Ahora, crearemos un nuevo “Trabajo” en Jenkins como un pipeline multinúcleo siguiendo los pasos mencionados en las secciones anteriores. Apuntemos al repositorio de muestra.
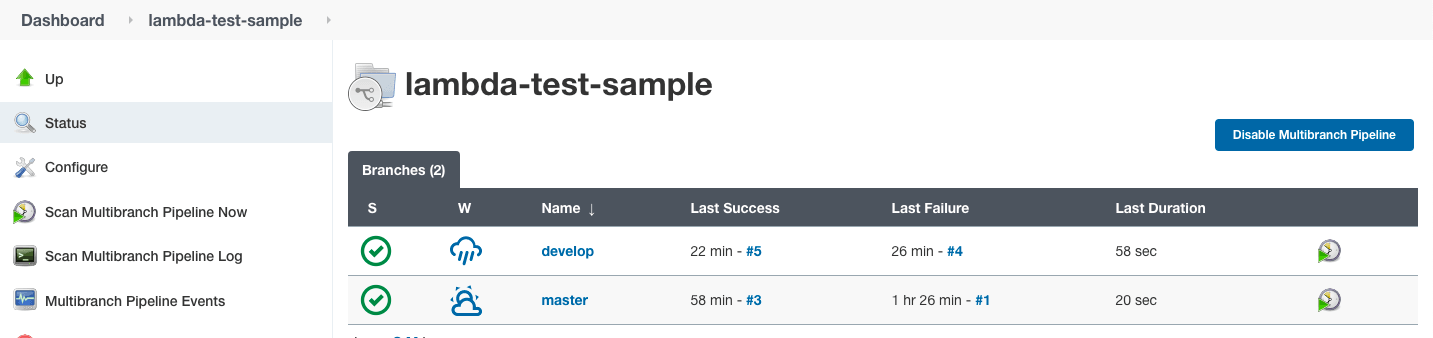
Una vez que la compilación se ejecute correctamente, visite el tablero de automatización de LambdaTest para obtener los registros de pruebas.
Conclusión
Con esto, hemos aprendido cómo crear un pipeline multinúcleo en Jenkins, cómo configurar un repositorio git en él, diferentes pasos de compilación para diferentes ramas, utilizando la escaneo automático periódico del repositorio por parte de Jenkins y aprovechando la potente infraestructura de pruebas de automatización de LambdaTest para automatizar nuestras compilaciones CI/CD. Espero que hayas encontrado útil este artículo. Por favor, comparte tus comentarios en la sección de comentarios.
Source:
https://dzone.com/articles/how-to-create-jenkins-multibranch-pipeline