













¿Qué es Elasticsearch?
Elasticsearch es un motor de búsqueda y analítica de código abierto distribuido construido sobre la biblioteca Apache Lucene. Elasticsearch también ofrece búsqueda vectorial y generación de recuperación aumentada (RAG), admitiendo aplicaciones de IA modernas de manera fluida. Las aplicaciones pueden almacenar datos estructurados y no estructurados en Elasticsearch, con o sin un esquema definido, enviando cargas útiles JSON a un clúster de Elasticsearch.
Arquitectura de Elasticsearch
Desde cero, los principales componentes de un clúster de Elasticsearch son:
Documento
Un documento es el registro más pequeño de información almacenado por Elasticsearch y está representado como JSON. Un documento consta de múltiples campos (pares clave-valor) de diferentes tipos y puede tener un esquema predefinido o ser sin esquema, deduciendo los tipos de datos de cualquier campo nuevo que se indexe.
Índice
Un índice es una colección lógica de documentos con el mismo esquema, identificados por un nombre de índice.
Fragmento
Los índices de Elasticsearch se dividen en unidades manejables llamadas fragmentos, que son una colección de documentos. Los fragmentos son la unidad básica de búsqueda y se replican en múltiples nodos para redundancia y tolerancia a fallas.
Nodo
Un nodo es una instancia independiente de Elasticsearch y administra una colección de fragmentos que pertenecen a uno o más índices. Los nodos pueden tener diferentes papeles como nodo de datos, nodo maestro y nodo de ingestión.
Cluster
Un clúster de Elasticsearch es una colección de nodos interconectados. Todos los nodos en un clúster pueden manejar solicitudes de clientes y comunicarse entre sí. Cada nodo en un clúster es propietario de un subconjunto de los fragmentos que pertenecen a un índice.
Arquitectura de consulta
El siguiente diagrama de arquitectura muestra el flujo de una solicitud de búsqueda:

- El usuario o la aplicación realiza una consulta de búsqueda. La consulta puede ser manejada por cualquier nodo en el clúster. El nodo que maneja la solicitud es el nodo “coordinador”.
- El nodo coordinador difunde la consulta a todos los fragmentos involucrados y sus réplicas.
- Cada fragmento ejecuta la consulta localmente y devuelve un conjunto ligero de resultados al nodo coordinador.
- El nodo coordinador fusiona los resultados que recibe. Esta es la finalización de la fase de “consulta”. La fase de consulta identifica los documentos básicos que forman el resultado de la búsqueda, pero aún es necesario recuperar el documento completo.
- El nodo coordinador envía solicitudes de recuperación a los fragmentos propietarios, que enriquecen los documentos en el conjunto de resultados.
- Los documentos enriquecidos se devuelven al nodo coordinador.
- El conjunto completo de resultados de búsqueda, clasificados y enriquecidos, se devuelve al llamante.
Arquitectura de Indexación
El siguiente diagrama de arquitectura describe el flujo de una solicitud de indexación:
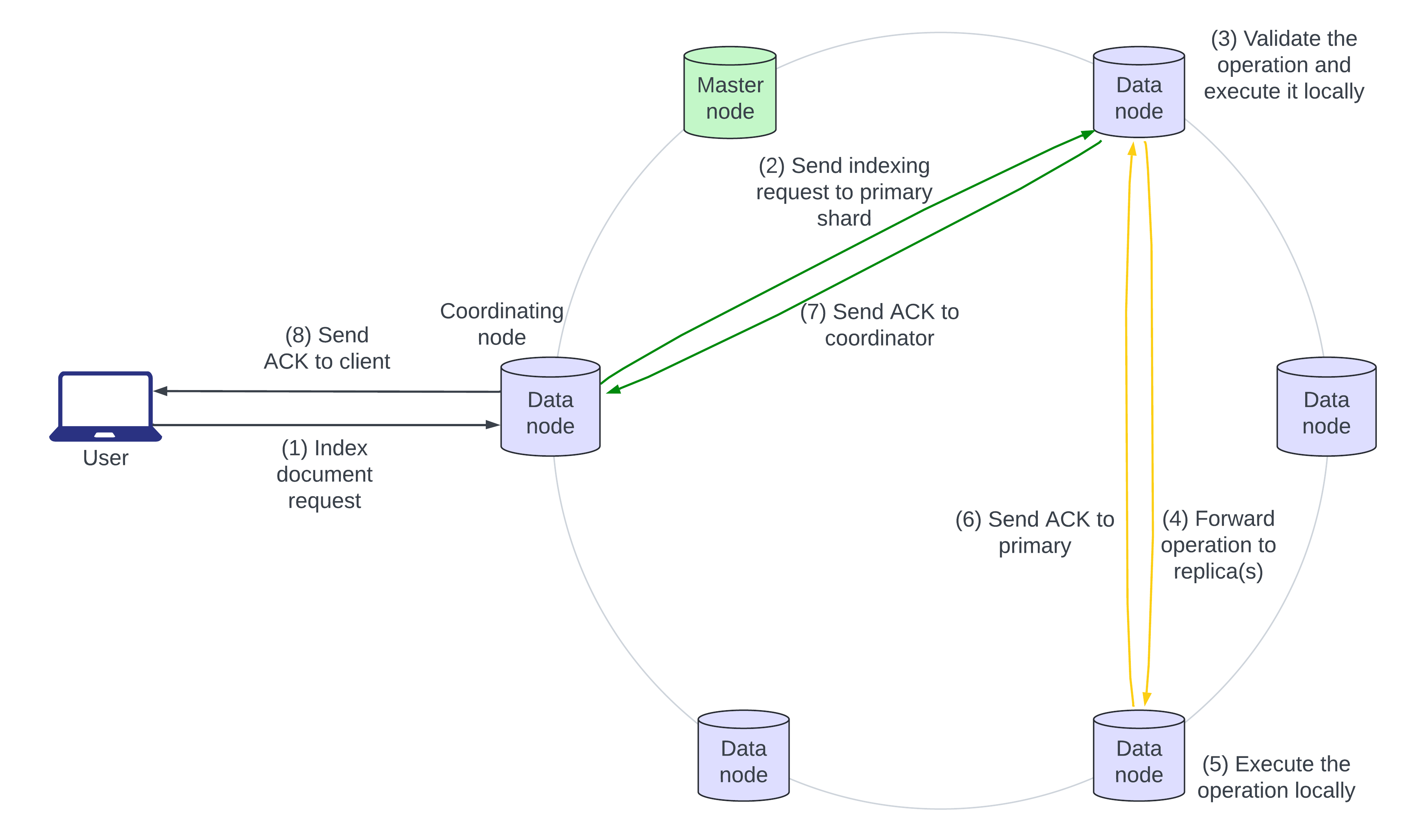
- El usuario envía un documento JSON para que Elasticsearch lo indexe. Si el documento ya existe, se añaden nuevos campos y los campos existentes son sobrescritos. El nodo que primero recibe la solicitud es el nodo “coordinador”.
- El nodo coordinador identifica el fragmento primario del documento entrante, generalmente basado en el ID del documento, y envía la solicitud al nodo de datos que posee el fragmento primario.
- El fragmento primario valida la operación y la ejecuta localmente.
- El fragmento primario luego envía la operación a todos sus réplicas en paralelo.
- Las réplicas aplican la operación localmente en sus nodos.
- Los pasos 6, 7 y 8 muestran la confirmación de la escritura que va desde la réplica hasta el fragmento primario, al nodo coordinador y al solicitante.
Conclusión
Este artículo describe los diferentes componentes de un clúster de Elasticsearch: documentos, índices, fragmentos y nodos. También describe la duración de una solicitud de búsqueda y una solicitud de indexación. Su arquitectura flexible facilita la adición y eliminación de nodos a medida que el clúster se expande. Combinado con características como la indexación sin esquema y el soporte para funciones de búsqueda de IA, esto convierte a Elasticsearch en el estándar de facto para organizaciones que necesitan almacenar, buscar y analizar de manera eficiente grandes volúmenes de datos en tiempo real.
Source:
https://dzone.com/articles/elasticsearch-query-and-indexing-architecture