













El sharding de bases de datos es el proceso de dividir los datos en piezas más pequeñas llamadas “fragmentos”. Fragmentación se introduce típicamente cuando existe la necesidad de escalar las escrituras. Durante la vida útil de una aplicación exitosa, el servidor de la base de datos alcanzará el número máximo de escrituras que puede realizar, ya sea en el nivel de procesamiento o de capacidad. Al dividir los datos en múltiples fragmentos, cada uno en su propio servidor de bases de datos, se reduce el estrés en cada nodo individual, aumentando efectivamente la capacidad de escritura de la base de datos en su conjunto. Esto es lo que es el sharding de bases de datos.
SQL distribuido es la nueva forma de escalar bases de datos relacionales con una estrategia similar a la fragmentación que es completamente automatizada y transparente para las aplicaciones. Las bases de datos SQL distribuidas están diseñadas desde cero para escalar casi de manera lineal. En este artículo, aprenderás los conceptos básicos de SQL distribuido y cómo comenzar.
Desventajas de la Fragmentación de Bases de Datos
La fragmentación introduce varios desafíos:
- Particionamiento de datos: Decidir cómo particionar los datos en múltiples fragmentos puede ser un desafío, ya que requiere encontrar un equilibrio entre la proximidad de los datos y la distribución uniforme de los datos para evitar puntos calientes.
- Manejo de fallos: Si un nodo clave falla y no hay suficientes fragmentos para soportar la carga, ¿cómo se obtiene los datos en un nuevo nodo sin tiempo de inactividad?
- Complejidad de las consultas: El código de la aplicación está acoplado a la lógica de particionamiento de datos y las consultas que requieren datos de múltiples nodos necesitan ser recombinadas.
- Consistencia de datos: Garantizar la consistencia de datos en múltiples particiones puede ser un desafío, ya que requiere coordinar actualizaciones en los datos a través de las particiones. Esto puede ser especialmente difícil cuando se realizan actualizaciones concurrentemente, ya que puede ser necesario resolver conflictos entre diferentes escrituras.
- Escalabilidad elástica: A medida que aumenta el volumen de datos o el número de consultas, puede ser necesario agregar más particiones al sistema de bases de datos. Este proceso puede ser complejo y con tiempo de inactividad inevitable, requiriendo procesos manuales para redistribuir los datos equitativamente en todas las particiones.
Algunos de estos inconvenientes pueden mitigarse adoptando la persistencia poliglota (usar diferentes bases de datos para diferentes cargas de trabajo), motores de almacenamiento de bases de datos con capacidades nativas de particionamiento, o proxies de bases de datos. Sin embargo, si bien ayudan con algunos de los desafíos en el particionamiento de bases de datos, estas herramientas tienen limitaciones e introducen una complejidad que requiere un manejo constante.
¿Qué es SQL Distribuido?
Distributed SQL se refiere a una nueva generación de bases de datos relacionales. En términos sencillos, una base de datos SQL distribuida es una base de datos relacional con fragmentación transparente que se presenta como una sola base de datos lógica a las aplicaciones. Las bases de datos SQL distribuidas se implementan como una arquitectura sin compartir y un motor de almacenamiento que escala tanto las lecturas como las escrituras manteniendo la verdadera conformidad ACID y alta disponibilidad. Las bases de datos SQL distribuidas tienen las características de escalabilidad de las bases de datos NoSQL—que ganaron popularidad en la década de 2000—pero no sacrifican la consistencia. Conservan las ventajas de las bases de datos relacionales y agregan compatibilidad con la nube con resiliencia en múltiples regiones.
A different but related term is NewSQL (coined by Matthew Aslett in 2011). This term also describes scalable and performant relational databases. However, NewSQL databases don’t necessarily include horizontal scalability.
¿Cómo funciona el Distributed SQL?
Para comprender cómo funciona el SQL distribuido, tomemos el caso de MariaDB Xpand—una base de datos SQL distribuida compatible con la base de datos de código abierto MariaDB. Xpand funciona dividiendo los datos e índices entre los nodos y automatizándose tareas como el reequilibrio de datos y la ejecución de consultas distribuidas. Las consultas se ejecutan en paralelo para minimizar el retraso. Los datos se replican automáticamente para asegurar que no haya un único punto de fallo. Cuando un nodo falla, Xpand reequilibra los datos entre los nodos supervivientes. Lo mismo ocurre cuando se agrega un nuevo nodo. Un componente llamado rebalancer garantiza que no haya puntos calientes—un desafío con el sharding de bases de datos manual—que ocurre cuando un nodo tiene que manejar de manera desigual demasiadas transacciones en comparación con otros nodos que pueden permanecer inactivos a veces.
Veamos un ejemplo. Supongamos que tenemos una instancia de base de datos con some_table y un número de filas:
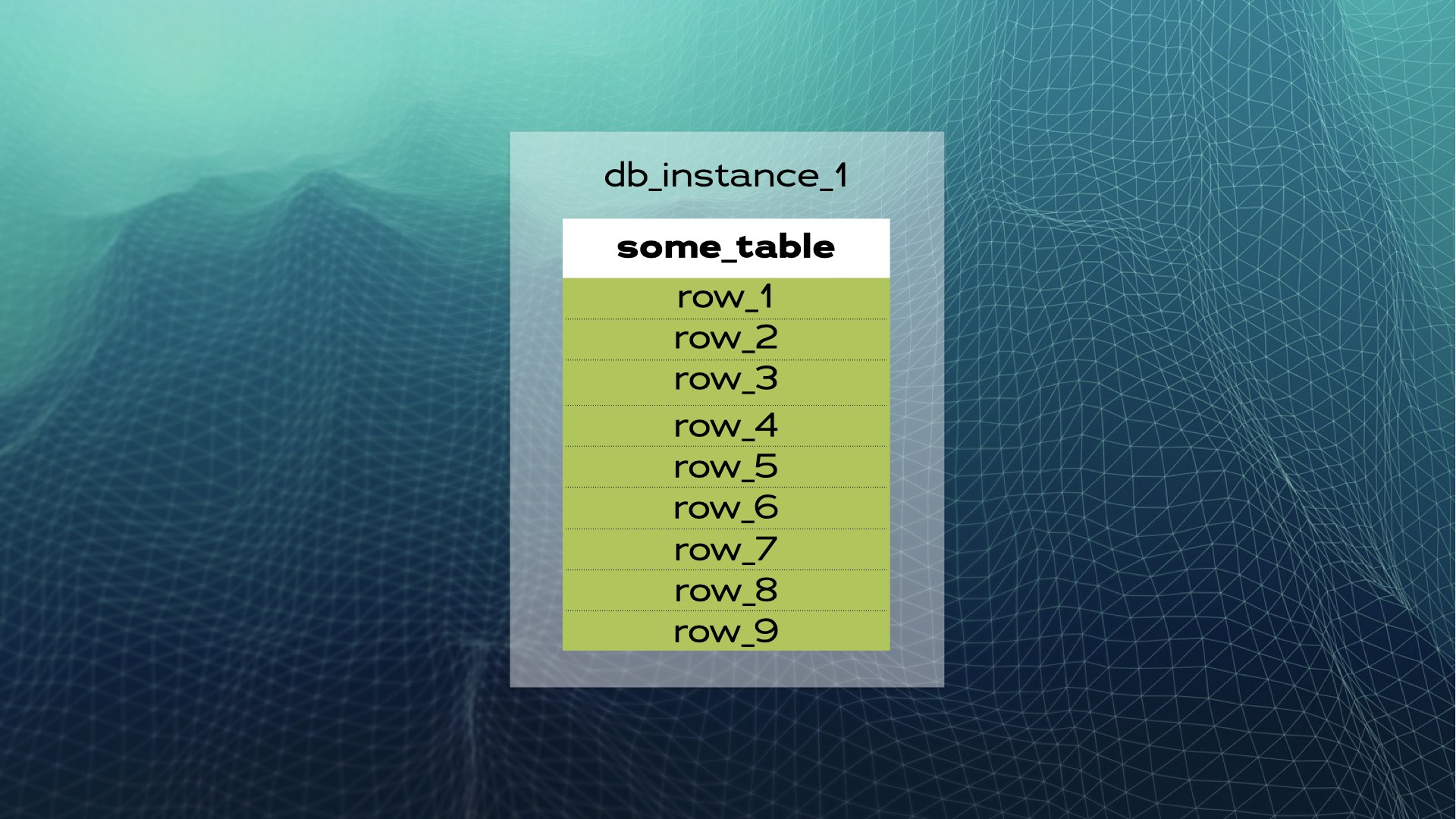
Podemos dividir los datos en tres trozos (fragmentos):

Y luego mover cada trozo de datos a una instancia de base de datos separada:
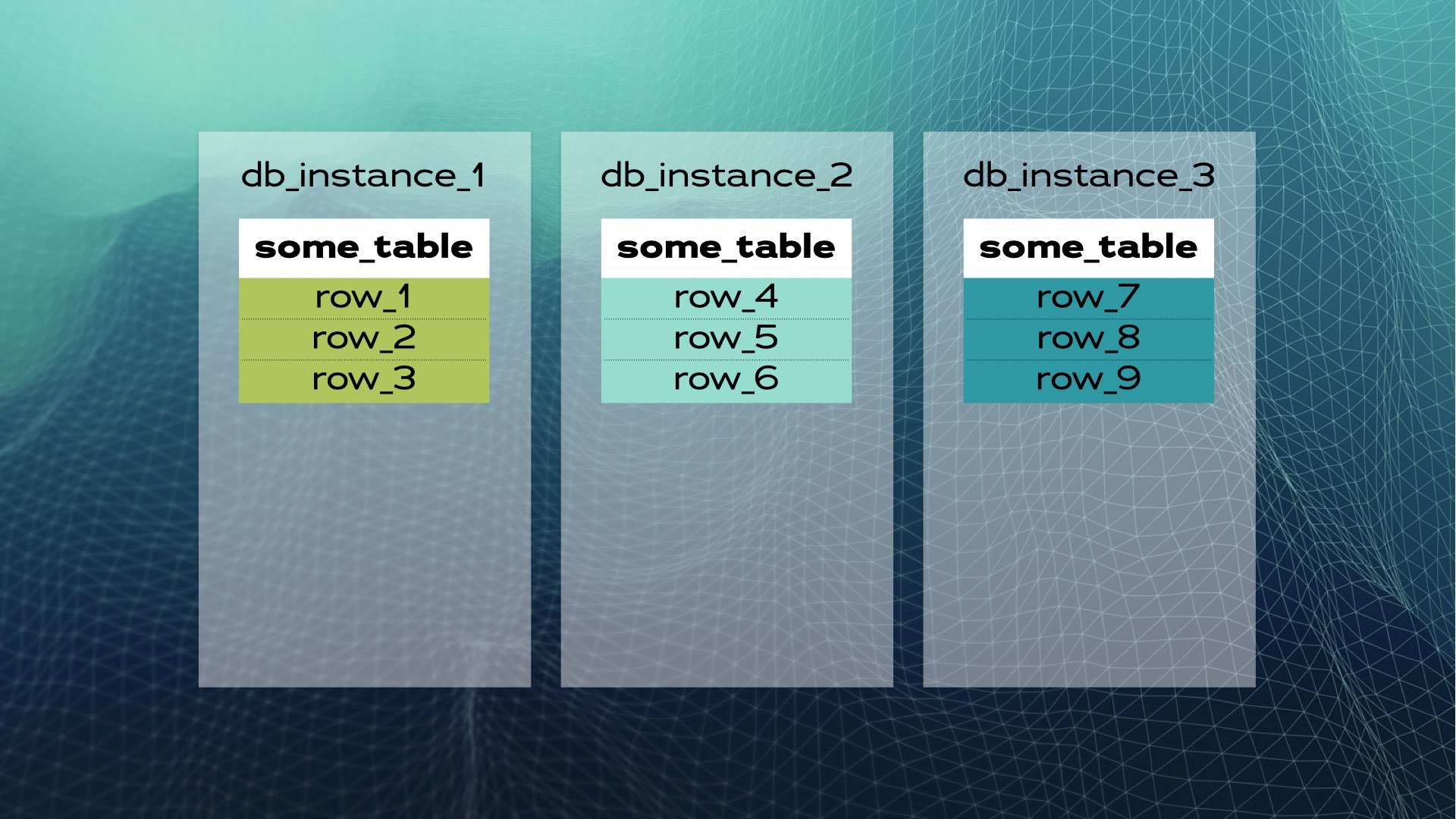
Esto es lo que se asemeja a compartir manualmente una base de datos. SQL distribuido lo hace automáticamente por ti. En el caso de Xpand, cada fragmento se llama un rebanada. Las filas se dividen utilizando una función hash de un subconjunto de las columnas de la tabla. No solo se fragmenta la información, sino que también se fragmentan y distribuyen entre los nodos (instancias de base de datos) los índices. Además, para mantener la alta disponibilidad, las rebanadas se replican en otros nodos (el número de réplicas por nodo es configurable). Esto también ocurre automáticamente:
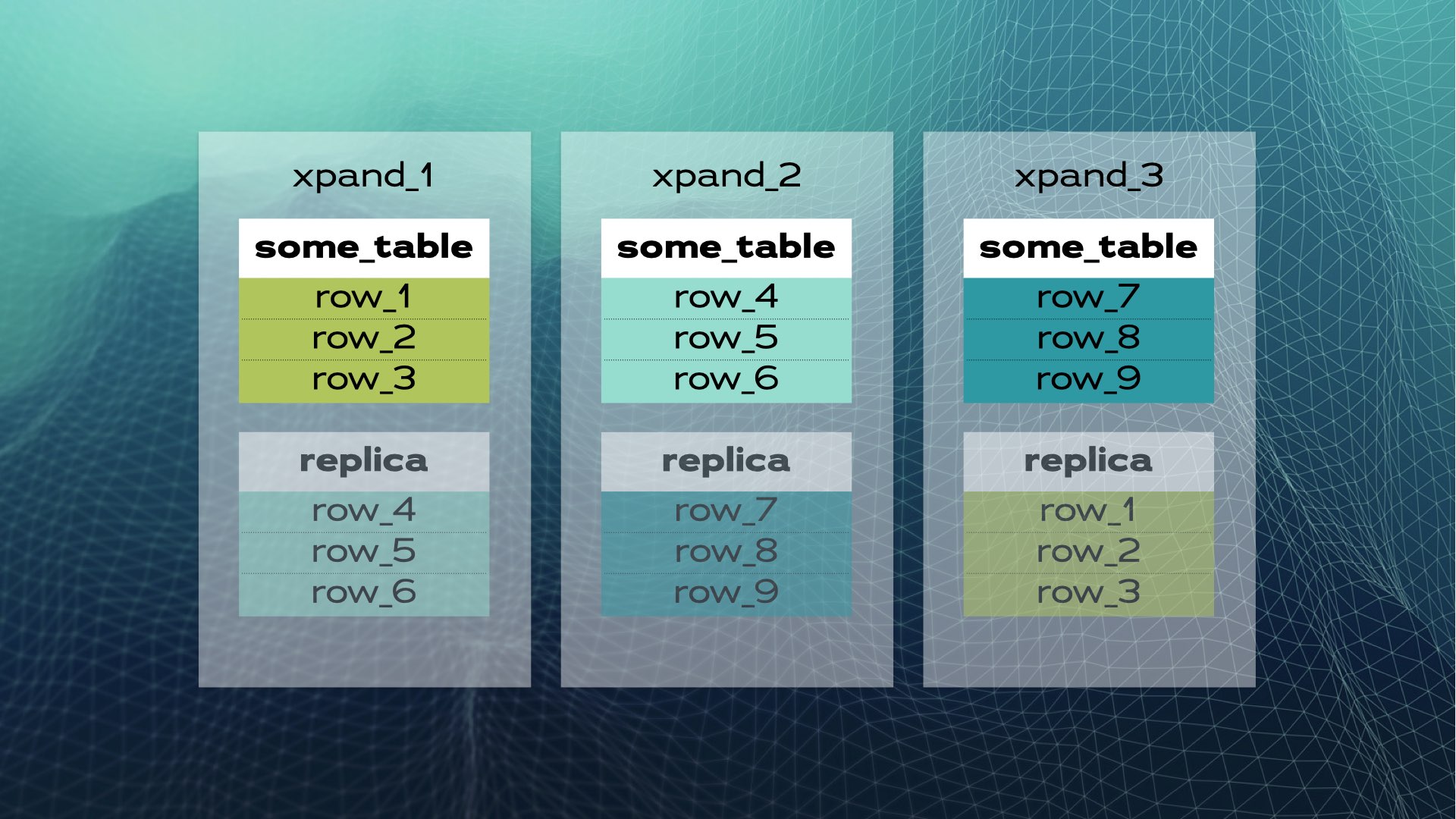
Cuando se agrega un nuevo nodo al clúster o cuando un nodo falla, Xpand equilibra automáticamente los datos sin necesidad de intervención manual. Esto es lo que sucede cuando se agrega un nodo al clúster anterior:

Algunas filas se mueven al nuevo nodo para aumentar la capacidad general del sistema. Tenga en cuenta que, aunque no se muestra en el diagrama, tanto los índices como las réplicas también se trasladan y actualizan de manera correspondiente. Una vista ligeramente más completa (con un traslado ligeramente diferente de los datos) del clúster anterior se muestra en este diagrama:
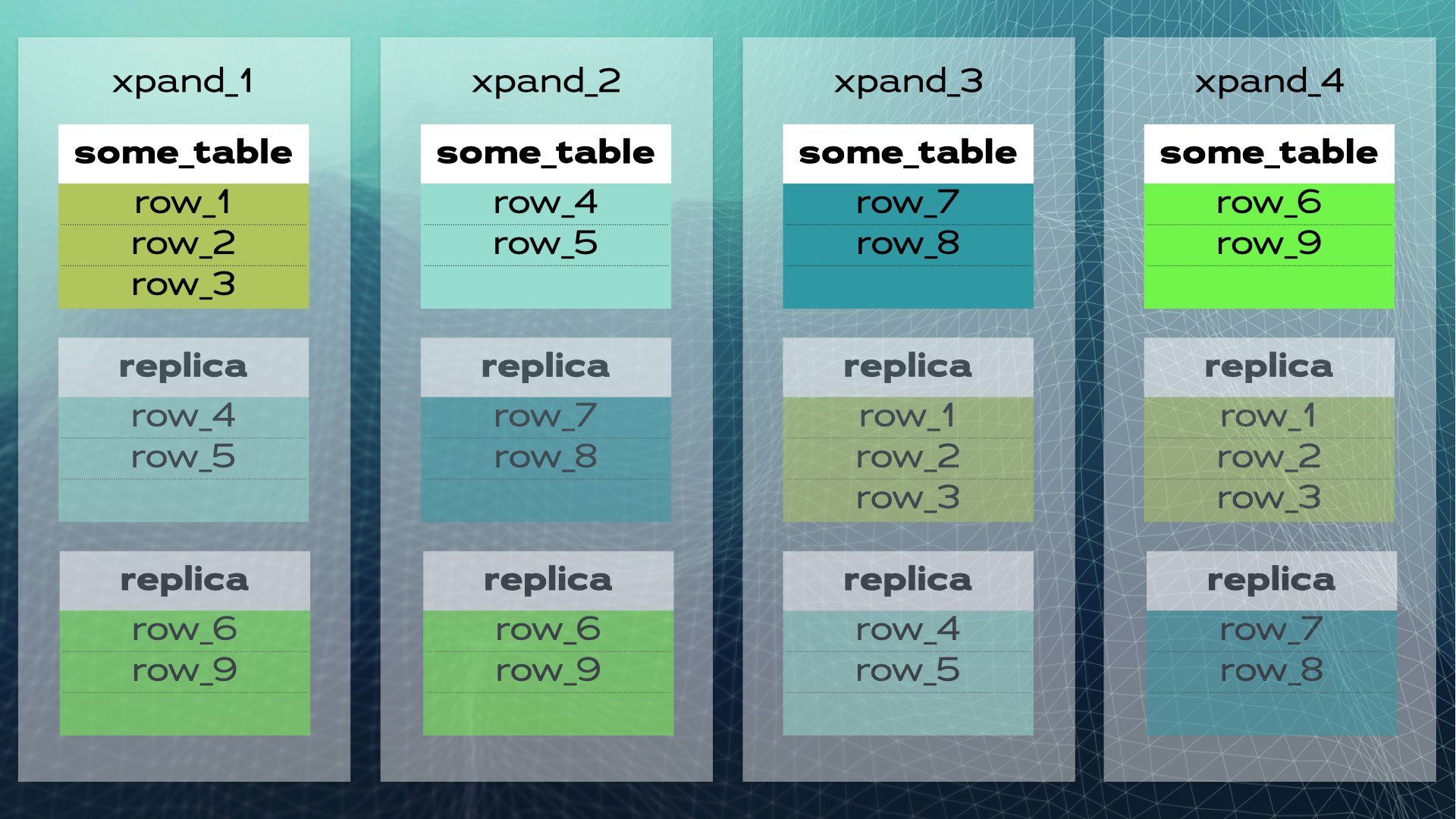
Esta arquitectura permite una escalabilidad casi lineal. No es necesario intervenir manualmente a nivel de aplicación. Para la aplicación, el clúster parece una única base de datos lógica. La aplicación simplemente se conecta a la base de datos a través de un equilibrador de carga (MariaDB MaxScale):
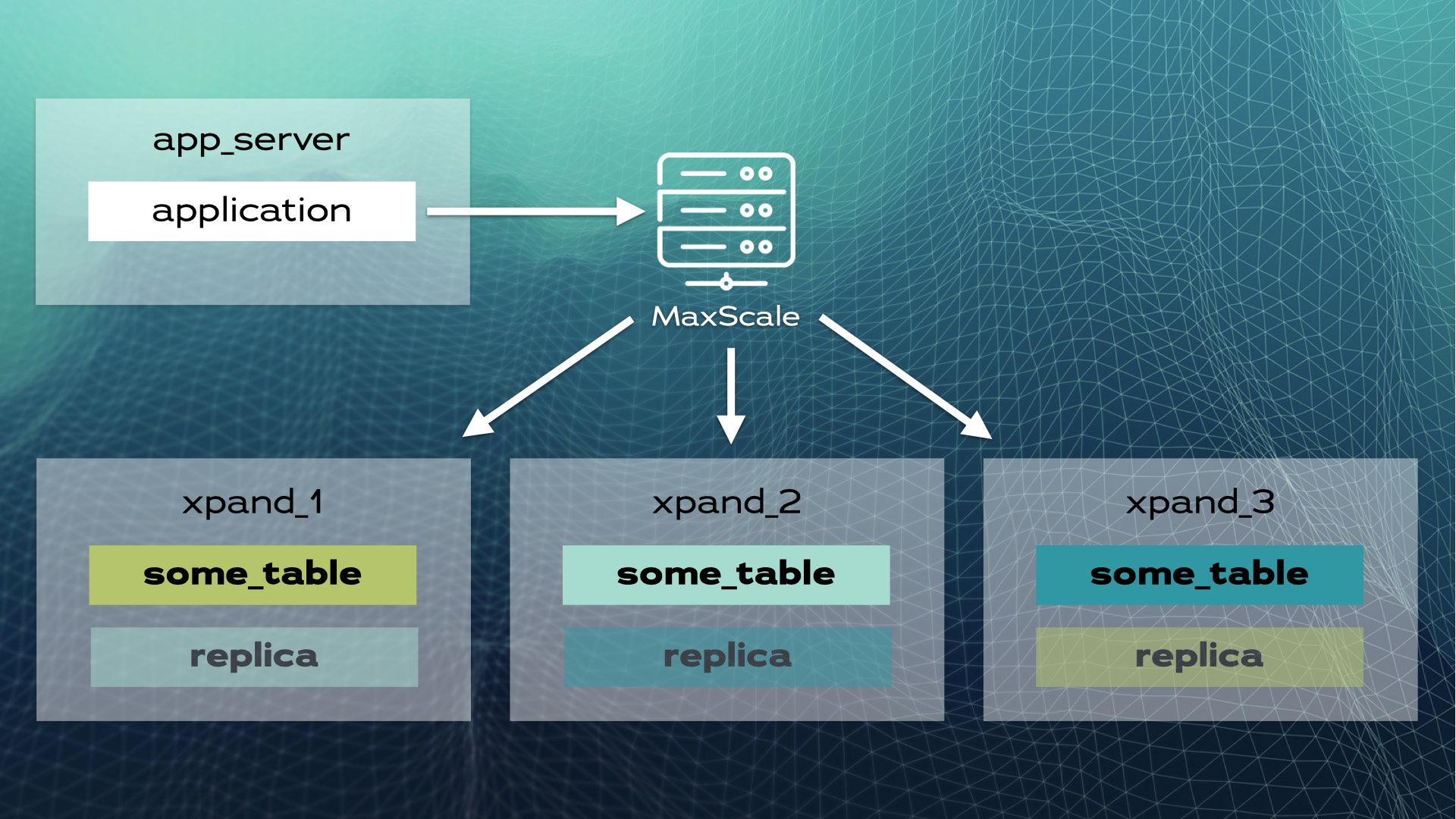
Cuando la aplicación envía una operación de escritura (por ejemplo, INSERT o UPDATE), se calcula la función hash y se envía al fragmento correcto. Se envían varias escrituras en paralelo a múltiples nodos.
Cuando no usar SQL distribuido
El particionamiento de una base de datos mejora el rendimiento pero también introduce un overhead adicional a nivel de comunicación entre nodos. Esto puede llevar a un rendimiento más lento si la base de datos no está configurada correctamente o si el enrutador de consultas no está optimizado. El SQL distribuido podría no ser la mejor alternativa en aplicaciones con menos de 10K consultas por segundo o 5K transacciones por segundo. Además, si su base de datos consiste principalmente en muchas tablas pequeñas, entonces una base de datos monolítica podría funcionar mejor.
Empezando con SQL distribuido
Dado que una base de datos SQL distribuida se ve a una aplicación como si fuera una sola base de datos lógica, comenzar es sencillo. Todo lo que necesitas es lo siguiente:
- Un cliente SQL como DBeaver, DbGate, DataGrip, o cualquier extensión de cliente SQL para tu IDE
- A distributed SQL database
Docker facilita la segunda parte. Por ejemplo, MariaDB publica la imagen de Docker mariadb/xpand-single que te permite lanzar una base de datos Xpand de un solo nodo para evaluación, pruebas y desarrollo.
Para iniciar un contenedor Xpand, ejecuta el siguiente comando:
docker run --name xpand \
-d \
-p 3306:3306 \
--ulimit memlock=-1 \
mariadb/xpand-single \
--user "user" \
--passwd "password"Consulte la documentación de la imagen Docker para obtener detalles.
Nota: En el momento de escribir este artículo, la imagen Docker mariadb/xpand-single no está disponible en arquitecturas ARM. En estas arquitecturas (por ejemplo, máquinas Apple con procesadores M1), utilice UTM para crear una máquina virtual (VM) e instale, por ejemplo, Debian. Asigne un nombre de host y utilice SSH para conectarse a la VM para instalar Docker y crear el contenedor MariaDB Xpand.
Conectar a la Base de Datos
Conectar a una base de datos Xpand es igual que conectarse a un servidor MariaDB Comunidad o Empresa. Si tiene la herramienta CLI mariadb instalada, simplemente ejecute lo siguiente:
mariadb -h 127.0.0.1 -u user -pPuedes conectarte a la base de datos utilizando una GUI para bases de datos SQL como DBeaver, DataGrip, o una extensión SQL para tu IDE (como esta para VS Code). Vamos a utilizar un cliente SQL gratuito y de código abierto llamado DbGate. Puedes descargar DbGate y ejecutarlo como una aplicación de escritorio o, si estás utilizando Docker, puedes desplegarlo como una aplicación web que puedas acceder desde cualquier lugar a través de un navegador web (similar al popular phpMyAdmin). Simplemente ejecuta el siguiente comando:
docker run -d --name dbgate -p 3000:3000 dbgate/dbgateUna vez que el contenedor se inicie, dirige tu navegador a http://localhost:3000/. Completa los detalles de conexión:
Haz clic en Probar y confirma que la conexión es exitosa:

Haz clic en Guardar y crea una nueva base de datos haciendo clic derecho en la conexión en el panel izquierdo y seleccionando Crear base de datos. Intenta crear tablas o importar un script SQL. Si solo quieres probar algo, la Nación o Sakila son buenas bases de datos de ejemplo.
Conectándose desde Java, JavaScript, Python y C++
Para conectarse a Xpand desde aplicaciones, puede utilizar los Conectores de MariaDB. Existen muchas combinaciones posibles de lenguajes de programación y frameworks de persistencia. Cubrir esto está fuera del alcance de este artículo, pero si solo desea comenzar y ver algo en acción, eche un vistazo a esta página de inicio rápido con ejemplos de código para Java, JavaScript, Python y C++.
El verdadero poder de SQL distribuido
En este artículo, aprendimos cómo lanzar un solo nodo de Xpand para fines de desarrollo y pruebas en lugar de cargas de trabajo de producción. Sin embargo, el verdadero poder de una base de datos SQL distribuida radica en su capacidad para escalar no solo las lecturas (como en el sharding de bases de datos clásicas) sino también las escrituras al simplemente agregar más nodos y dejar que el rebalanceador reubique óptimamente los datos. Aunque es posible desplegar Xpand en una topología de múltiples nodos, la forma más fácil de usarlo en producción es a través de SkySQL.
Si desea obtener más información sobre SQL distribuido y MariaDB Xpand, aquí hay una lista de recursos útiles:
Source:
https://dzone.com/articles/distributed-sql-an-alternative-to-sharding