













En este laboratorio práctico de la Universidad de ScyllaDB, aprenderás a utilizar el conector de origen de CDC de ScyllaDB para enviar los eventos de cambios a nivel de fila en las tablas de un clúster de ScyllaDB a un servidor de Kafka.
¿Qué es ScyllaDB CDC?
Para recapitular, Change Data Capture (CDC) es una característica que te permite no solo consultar el estado actual de una tabla de base de datos, sino también consultar el historial de todos los cambios realizados en la tabla. CDC está listo para producción (GA) a partir de ScyllaDB Enterprise 2021.1.1 y ScyllaDB Open Source 4.3.
En ScyllaDB, CDC es opcional y se habilita de forma individual para cada tabla. El historial de cambios realizados en una tabla habilitada para CDC se almacena en una tabla asociada separada.
Puedes habilitar CDC al crear o modificar una tabla utilizando la opción CDC, por ejemplo:
CREATE TABLE ks.t (pk int, ck int, v int, PRIMARY KEY (pk, ck, v)) WITH cdc = {'enabled':true};Conector de Origen de CDC de ScyllaDB
El Conector de Fuente ScyllaDB CDC es un conector que captura cambios a nivel de fila en las tablas de un clúster ScyllaDB. Es un conector Debezium, compatible con Kafka Connect (con Kafka 2.6.0+). El conector lee el registro de CDC para las tablas especificadas y produce mensajes de Kafka para cada operación de nivel de fila INSERT, UPDATE o DELETE. El conector es tolerante a fallos, reintentando la lectura de datos desde Scylla en caso de fallo. Periodicamente guarda la posición actual en el registro de CDC de ScyllaDB utilizando el seguimiento de desplazamiento de Kafka Connect. Cada mensaje de Kafka generado contiene información sobre el origen, como la marca de tiempo y el nombre de la tabla.
Nota: en el momento de escribir, no hay soporte para tipos de colección (LIST, SET, MAP) y UDTs—las columnas con esos tipos se omiten de los mensajes generados. Manténgase al tanto de esta solicitud de mejora y otros desarrollos en el proyecto de GitHub.
Confluent y Kafka Connect
Confluent es una plataforma integral de streaming de datos que te permite acceder, almacenar y administrar datos como flujos continuos y en tiempo real. Amplía las ventajas de Apache Kafka con características de nivel empresarial. Confluent facilita la construcción de aplicaciones modernas impulsadas por eventos y proporciona una tubería de datos universal, soportando escalabilidad, rendimiento y confiabilidad.
Kafka Connect es una herramienta para transmitir datos de manera escalable y confiable entre Apache Kafka y otros sistemas de datos. Facilita la definición de conectores que mueven grandes conjuntos de datos hacia adentro y hacia afuera de Kafka. Puede ingerir bases de datos completas o recopilar métricas de servidores de aplicaciones en temas de Kafka, haciendo que los datos estén disponibles para el procesamiento de flujo con baja latencia.
Kafka Connect incluye dos tipos de conectores:
- Conector fuente: Los conectores fuente ingieren bases de datos completas y transmiten actualizaciones de tablas a temas de Kafka. Los conectores fuente también pueden recopilar métricas de servidores de aplicaciones y almacenar los datos en temas de Kafka, haciendo que los datos estén disponibles para el procesamiento de flujo con baja latencia.
- Conector sumidero: Los conectores sumidero entregan datos de temas de Kafka a índices secundarios, como Elasticsearch, o sistemas por lotes, como Hadoop, para análisis fuera de línea.
Configuración del servicio con Docker
En este laboratorio, usarás Docker.
Asegúrate de que tu entorno cumpla con los siguientes requisitos previos:
- Docker para Linux, Mac o Windows.
- Nota: utilizar ScyllaDB en Docker solo se recomienda para evaluar y probar ScyllaDB.
- ScyllaDB de código abierto. Para obtener el mejor rendimiento, se recomienda una instalación regular.
- 8 GB de RAM o superior para los servicios de Kafka y ScyllaDB.
- docker-compose
- Git
Instalación y Inicialización de Tabla de ScyllaDB
Primero, lanzará un clúster de tres nodos de ScyllaDB y creará una tabla con CDC habilitado.
Si aún no lo ha hecho, descargue el ejemplo de git:
git clone https://github.com/scylladb/scylla-code-samples.git cd scylla-code-samples/CDC_Kafka_LabEste es el archivo docker-compose que utilizará. Inicia un clúster de tres nodos de ScyllaDB:
version: "3"
services:
scylla-node1:
container_name: scylla-node1
image: scylladb/scylla:5.0.0
ports:
- 9042:9042
restart: always
command: --seeds=scylla-node1,scylla-node2 --smp 1 --memory 750M --overprovisioned 1 --api-address 0.0.0.0
scylla-node2:
container_name: scylla-node2
image: scylladb/scylla:5.0.0
restart: always
command: --seeds=scylla-node1,scylla-node2 --smp 1 --memory 750M --overprovisioned 1 --api-address 0.0.0.0
scylla-node3:
container_name: scylla-node3
image: scylladb/scylla:5.0.0
restart: always
command: --seeds=scylla-node1,scylla-node2 --smp 1 --memory 750M --overprovisioned 1 --api-address 0.0.0.0Inicie el clúster de ScyllaDB:
docker-compose -f docker-compose-scylladb.yml up -dEspere un minuto más o menos, y verifique que el clúster de ScyllaDB esté en funcionamiento y en estado normal:
docker exec scylla-node1 nodetool statusA continuación, utilizará cqlsh para interactuar con ScyllaDB. Cree un espacio de claves, una tabla con CDC habilitado, y inserte una fila en la tabla:
docker exec -ti scylla-node1 cqlsh
CREATE KEYSPACE ks WITH replication = {'class': 'NetworkTopologyStrategy', 'replication_factor' : 1};
CREATE TABLE ks.my_table (pk int, ck int, v int, PRIMARY KEY (pk, ck, v)) WITH cdc = {'enabled':true};
INSERT INTO ks.my_table(pk, ck, v) VALUES (1, 1, 20);
exit[guy@fedora cdc_test]$ docker-compose -f docker-compose-scylladb.yml up -d
Creating scylla-node1 ... done
Creating scylla-node2 ... done
Creating scylla-node3 ... done
[guy@fedora cdc_test]$ docker exec scylla-node1 nodetool status
Datacenter: datacenter1
=======================
Status=Up/Down
|/ State=Normal/Leaving/Joining/Moving
-- Dirección Carga Tokens Tiene ID de host Rascacielos
UN 172.19.0.3 ? 256 ? 4d4eaad4-62a4-485b-9a05-61432516a737 rack1
UN 172.19.0.2 496 KB 256 ? bec834b5-b0de-4d55-b13d-a8aa6800f0b9 rack1
UN 172.19.0.4 ? 256 ? 2788324e-548a-49e2-8337-976897c61238 rack1
Note: Non-system keyspaces don't have the same replication settings, effective ownership information is meaningless
[guy@fedora cdc_test]$ docker exec -ti scylla-node1 cqlsh
Connected to at 172.19.0.2:9042.
[cqlsh 5.0.1 | Cassandra 3.0.8 | CQL spec 3.3.1 | Native protocol v4]
Use HELP for help.
cqlsh> CREATE KEYSPACE ks WITH replication = {'class': 'NetworkTopologyStrategy', 'replication_factor' : 1};
cqlsh> CREATE TABLE ks.my_table (pk int, ck int, v int, PRIMARY KEY (pk, ck, v)) WITH cdc = {'enabled':true};
cqlsh> INSERT INTO ks.my_table(pk, ck, v) VALUES (1, 1, 20);
cqlsh> exit
[guy@fedora cdc_test]$ Configuración de Confluent y Configuración del Conector
Para lanzar un servidor Kafka, utilizará la plataforma Confluent, que proporciona una GUI web amigable para rastrear temas y mensajes. La plataforma confluent proporciona un archivo docker-compose.yml para configurar los servicios.
Nota: no es así como se usaría Apache Kafka en producción. El ejemplo es útil solo para fines de capacitación y desarrollo. Obtenga el archivo:
wget -O docker-compose-confluent.yml https://raw.githubusercontent.com/confluentinc/cp-all-in-one/7.3.0-post/cp-all-in-one/docker-compose.ymlA continuación, descargue el conector de CDC de ScyllaDB:
wget -O scylla-cdc-plugin.jar https://github.com/scylladb/scylla-cdc-source-connector/releases/download/scylla-cdc-source-connector-1.0.1/scylla-cdc-source-connector-1.0.1-jar-with-dependencies.jarAgrega el conector de CDC de ScyllaDB al directorio de plugins de servicio de Confluent Connect mediante un volumen de Docker editando docker-compose-confluent.yml para agregar las dos líneas como se indica a continuación, reemplazando el directorio con el directorio de tu archivo scylla-cdc-plugin.jar.
image: cnfldemos/cp-server-connect-datagen:0.5.3-7.1.0
hostname: connect
container_name: connect
+ volumes:
+ - <directory>/scylla-cdc-plugin.jar:/usr/share/java/kafka/plugins/scylla-cdc-plugin.jar
depends_on:
- broker
- schema-registryInicia los servicios de Confluent:
docker-compose -f docker-compose-confluent.yml up -dEspera un minuto más o menos, luego accede a http://localhost:9021 para la interfaz web de Confluent.
Agrega el ScyllaConnector usando el panel de Confluent:
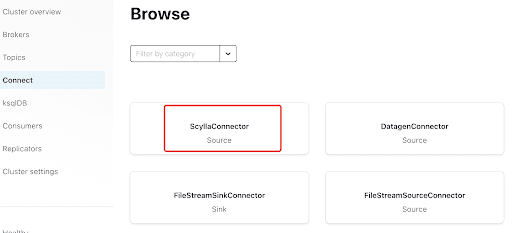
Agrega el conector de Scylla haciendo clic en el plugin:
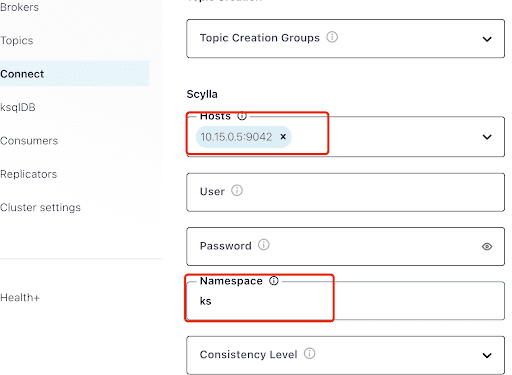
Llena el campo “Hosts” con la dirección IP de uno de los nodos de Scylla (puedes verla en la salida del comando nodetool status) y el puerto 9042, que es escuchado por el servicio de ScyllaDB.
El “Namespace” es el espacio de claves que creaste antes en ScyllaDB.
Ten en cuenta que puede tomar un minuto más o menos para que aparezca ks.my_table:
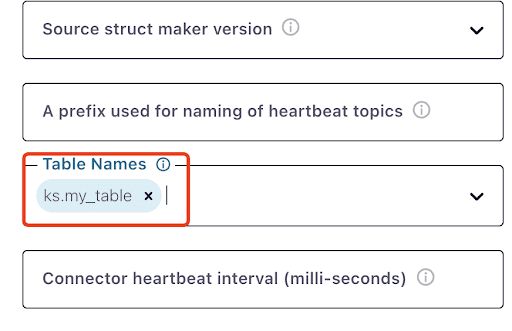
Prueba de mensajes de Kafka
Puedes ver que MyScyllaCluster.ks.my_table es el tema creado por el conector de CDC de ScyllaDB.
Ahora, busca mensajes de Kafka desde el panel de Temas:
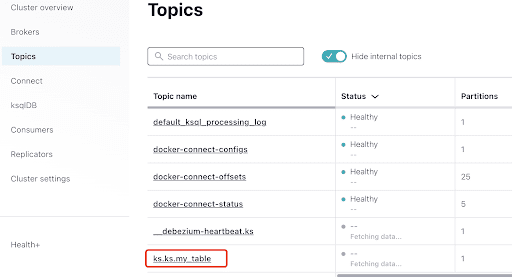
Selecciona el tema, que es el mismo que el nombre del espacio de claves y la tabla que creaste en ScyllaDB:
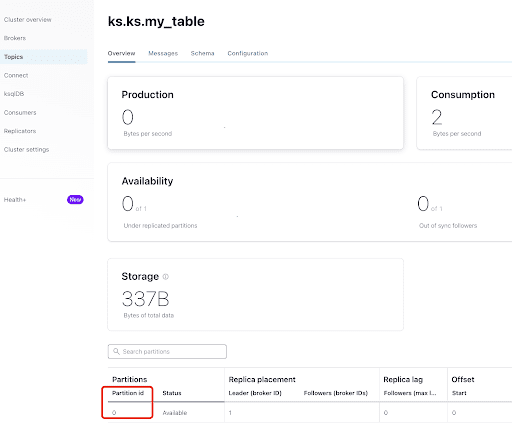
Desde la pestaña “Resumen”, puedes ver la información del tema. En la parte inferior, muestra que este tema está en la partición 0.
A partition is the smallest storage unit that holds a subset of records owned by a topic. Each partition is a single log file where records are written to it in an append-only fashion. The records in the partitions are each assigned a sequential identifier called the offset, which is unique for each record within the partition. The offset is an incremental and immutable number maintained by Kafka.
Como ya sabes, los mensajes de CDC de ScyllaDB se envían al tema ks.my_table, y el id de partición del tema es 0. A continuación, ve al pestaña “Mensajes” e introduce el id de partición 0 en el campo “offset”:
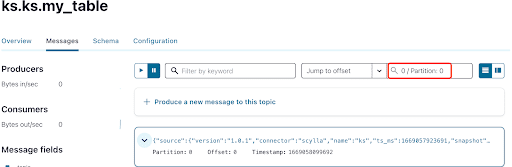
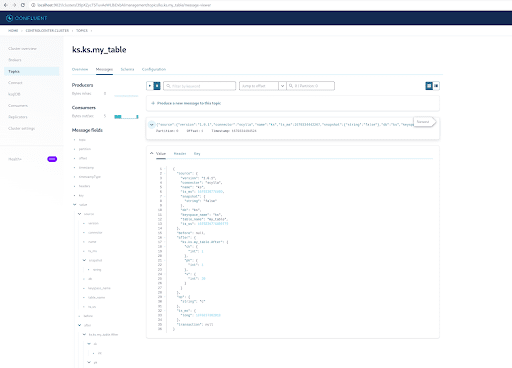
Puedes ver en la salida de los mensajes del tema Kafka que el evento de la tabla ScyllaDB INSERT y los datos fueron transferidos a mensajes de Kafka por el Conector Fuente CDC de Scylla. Haz clic en el mensaje para ver la información completa del mensaje:
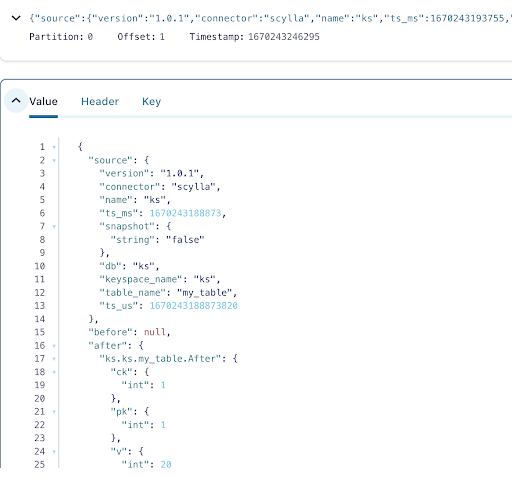
El mensaje contiene el nombre de la tabla ScyllaDB, el nombre del espacio de claves con la hora, así como el estado de los datos antes y después de la acción. Dado que se trata de una operación de inserción, los datos antes de la inserción son nulos.
A continuación, inserta otra fila en la tabla ScyllaDB:
docker exec -ti scylla-node1 cqlsh
INSERT INTO ks.my_table(pk, ck, v) VALUES (200, 50, 70);Ahora, en Kafka, espera unos segundos y podrás ver los detalles del nuevo Mensaje:
Limpieza
Una vez que hayas terminado de trabajar en este laboratorio, puedes detener y eliminar los contenedores y las imágenes de Docker.
Para ver una lista de todos los IDs de contenedor:
docker container ls -aqEntonces puedes detener y eliminar los contenedores que ya no estás utilizando:
docker stop <ID_or_Name>
docker rm <ID_or_Name>Más tarde, si deseas volver a ejecutar el laboratorio, puedes seguir los pasos y usar docker-compose como antes.
Resumen
Con el conector fuente CDC, un complemento de Kafka compatible con Kafka Connect, puedes capturar todos los cambios de nivel de fila de la tabla ScyllaDB (INSERT, UPDATE, o DELETE) y convertir esos eventos en mensajes de Kafka. Luego puedes consumir los datos desde otras aplicaciones o realizar cualquier otra operación con Kafka.
Source:
https://dzone.com/articles/change-data-capture-apache-kafka-and-scylladb