













Los registros suelen ocupar la mayoría de los activos de datos de una empresa. Ejemplos de registros incluyen registros comerciales (como registros de actividad de usuarios) y registros de Operaciones y Mantenimiento de servidores, bases de datos, dispositivos de red o IoT.
Los registros son el ángel de la guarda de los negocios. Por un lado, proporcionan alertas de riesgo del sistema y ayudan a los ingenieros a localizar rápidamente las causas raíz en la resolución de problemas. Por otro lado, si los amplías en el rango de tiempo, podrías identificar algunas tendencias y patrones útiles, por no mencionar que los registros comerciales son la piedra angular de las percepciones de los usuarios.
Sin embargo, los registros pueden ser un desafío debido a:
- Fluyen como locos. Cada evento del sistema o clic del usuario genera un registro. Una empresa a menudo produce decenas de miles de millones de nuevos registros al día.
- Son voluminosos. Los registros están destinados a permanecer. Pueden no ser útiles hasta que lo sean. Por lo tanto, una empresa puede acumular hasta PBs de datos de registro, muchos de los cuales son raramente visitados pero ocupan un gran espacio de almacenamiento.
- Deben cargarse y encontrarse rápidamente. Localizar el registro objetivo para la resolución de problemas es literalmente como buscar una aguja en un pajar. La gente anhela la escritura de registros en tiempo real y respuestas en tiempo real a las consultas de registros.
Ahora puedes tener una imagen clara de cómo es un sistema ideal de procesamiento de registros. Debería soportar lo siguiente:
- Ingestión de datos en tiempo real de alta capacidad: Debería poder escribir blogs en masa y hacerlos visibles de inmediato.
- Almacenamiento de bajo costo: Debería poder almacenar grandes cantidades de registros sin costar demasiros recursos.
- Búsqueda de texto en tiempo real: Debe ser capaz de realizar búsquedas de texto rápidas.
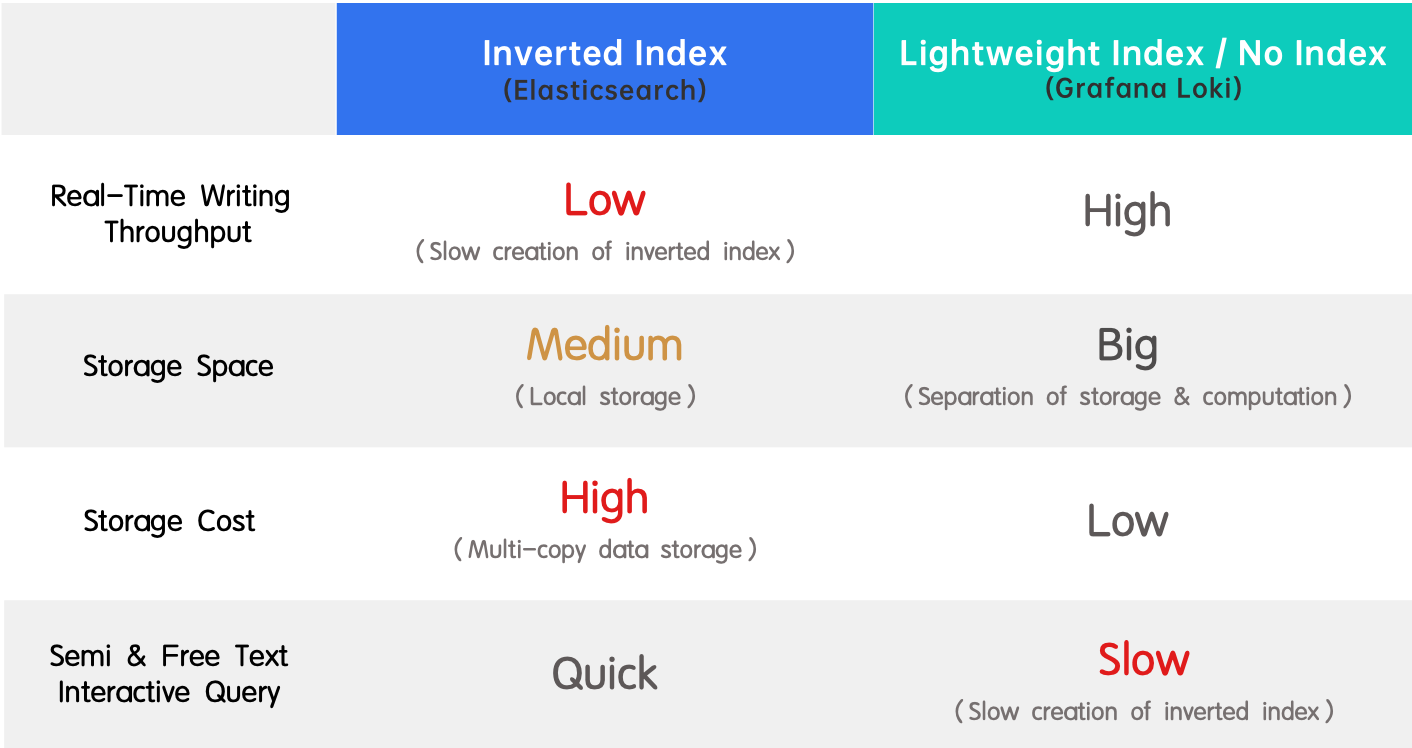
Soluciones comunes: Elasticsearch y Grafana Loki
Existen dos soluciones comunes de procesamiento de registros en la industria, ejemplificadas por Elasticsearch y Grafana Loki, respectivamente.
- Índice invertido (Elasticsearch): Es ampliamente adoptado debido a su soporte para búsqueda de texto completo y alto rendimiento. La desventaja es el bajo rendimiento en la escritura en tiempo real y el alto consumo de recursos en la creación del índice.
- Índice ligero / sin índice (Grafana Loki): Es lo opuesto a un índice invertido porque cuenta con un alto rendimiento en la escritura en tiempo real y un bajo costo de almacenamiento, pero ofrece consultas lentas.
Introducción al Índice Invertido
A prominent strength of Elasticsearch in log processing is quick keyword search among a sea of logs. This is enabled by inverted indexes.
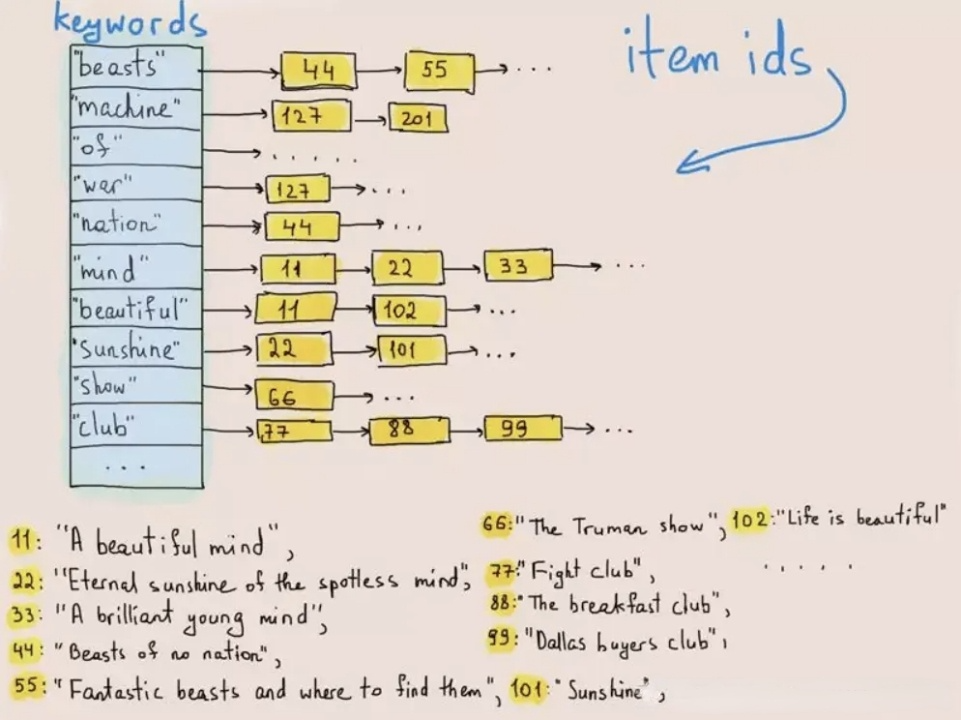
El índice invertido se utilizó originalmente para recuperar palabras o frases en textos. La figura a continuación ilustra cómo funciona:
Al escribir datos, el sistema tokeniza los textos en términos y almacena estos términos en una lista de publicación que mapea términos al ID de la fila donde existen. En las consultas de texto, la base de datos encuentra el correspondiente ID de fila de la palabra clave (término) en la lista de publicación y recupera la fila objetivo basada en el ID de fila. Al hacerlo, el sistema no tendrá que recorrer todo el conjunto de datos y, por lo tanto, mejora las velocidades de consulta en órdenes de magnitud.
En el sistema de índices invertidos de Elasticsearch, la rápida recuperación tiene como costo la velocidad de escritura, el rendimiento de escritura y el espacio de almacenamiento. ¿Por qué? En primer lugar, el tokenizado, la ordenación del diccionario y la creación del índice invertido son todas operaciones intensivas en CPU y memoria. En segundo lugar, Elasticsearch debe almacenar los datos originales, el índice invertido y una copia adicional de los datos almacenados en columnas para acelerar las consultas. Eso es una redundancia triple.
Pero sin un índice invertido, Grafana Loki, por ejemplo, está perjudicando la experiencia del usuario con sus consultas lentas, que es el mayor punto doloroso para los ingenieros en el análisis de registros.
En pocas palabras, Elasticsearch y Grafana Loki representan diferentes compensaciones entre alto rendimiento de escritura, bajo costo de almacenamiento y rápida capacidad de consulta. ¿Y si te digo que hay una manera de tenerlo todo? Hemos introducido índices invertidos en Apache Doris 2.0.0 y lo hemos optimizado aún más para lograr dos veces más rápido el rendimiento de consulta de registros que Elasticsearch con 1/5 del espacio de almacenamiento que utiliza. Ambos factores combinados, es una solución 10 veces mejor.
Índice Invertido en Apache Doris
Generalmente, hay dos formas de implementar índices: sistema de indexación externo o índices integrados.
Sistema de indexación externo: Conectas un sistema de indexación externo a tu base de datos. En la ingesta de datos, estos se importan a ambos sistemas. Después de que el sistema de indexación cree índices, elimina los datos originales dentro de sí mismo. Cuando los usuarios de datos introducen una consulta, el sistema de indexación proporciona los IDs de los datos relevantes, y luego la base de datos busca los datos objetivo basándose en los IDs.
Construir un sistema de indexación externo es más fácil y menos intrusivo para la base de datos, pero viene con algunas fallas molestas:
- La necesidad de escribir datos en dos sistemas puede resultar en inconsistencia de datos y redundancia de almacenamiento.
- La interacción entre la base de datos y el sistema de indexación trae sobrecostos, por lo que cuando los datos objetivo son enormes, la consulta a través de los dos sistemas puede ser lenta.
- Es agotador mantener dos sistemas.
En Apache Doris, optamos por el otro camino. Los índices invertidos incorporados son más difíciles de hacer, pero una vez que se hace, es más rápido, más amigable para el usuario y sin problemas para mantener.
En Apache Doris, los datos se organizan en el siguiente formato. Los índices se almacenan en la Región de Índice:
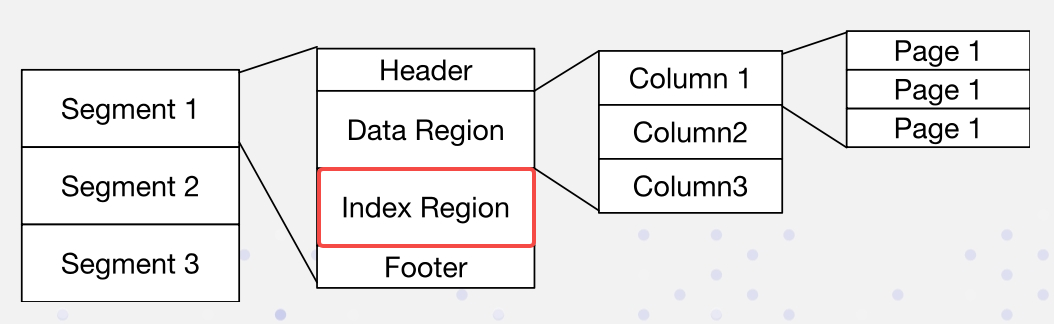
Implementamos índices invertidos de manera no intrusiva:
- Ingesta y compactación de datos: Mientras un archivo de segmento se escribe en Doris, también se escribirá un archivo de índice invertido. La ruta del archivo de índice se determina por el ID de segmento y el ID de índice. Las filas en los segmentos corresponden a los docs en los índices, al igual que el RowID y el DocID.
- Consulta: Si la cláusula
whereincluye una columna con índice invertido, el sistema buscará en el archivo de índice, devolverá una lista de DocID y convertirá la lista de DocID en un Bitmap de RowID. Bajo el mecanismo de filtrado de RowID de Apache Doris, solo se leerán las filas objetivo. Así es como se aceleran las consultas.
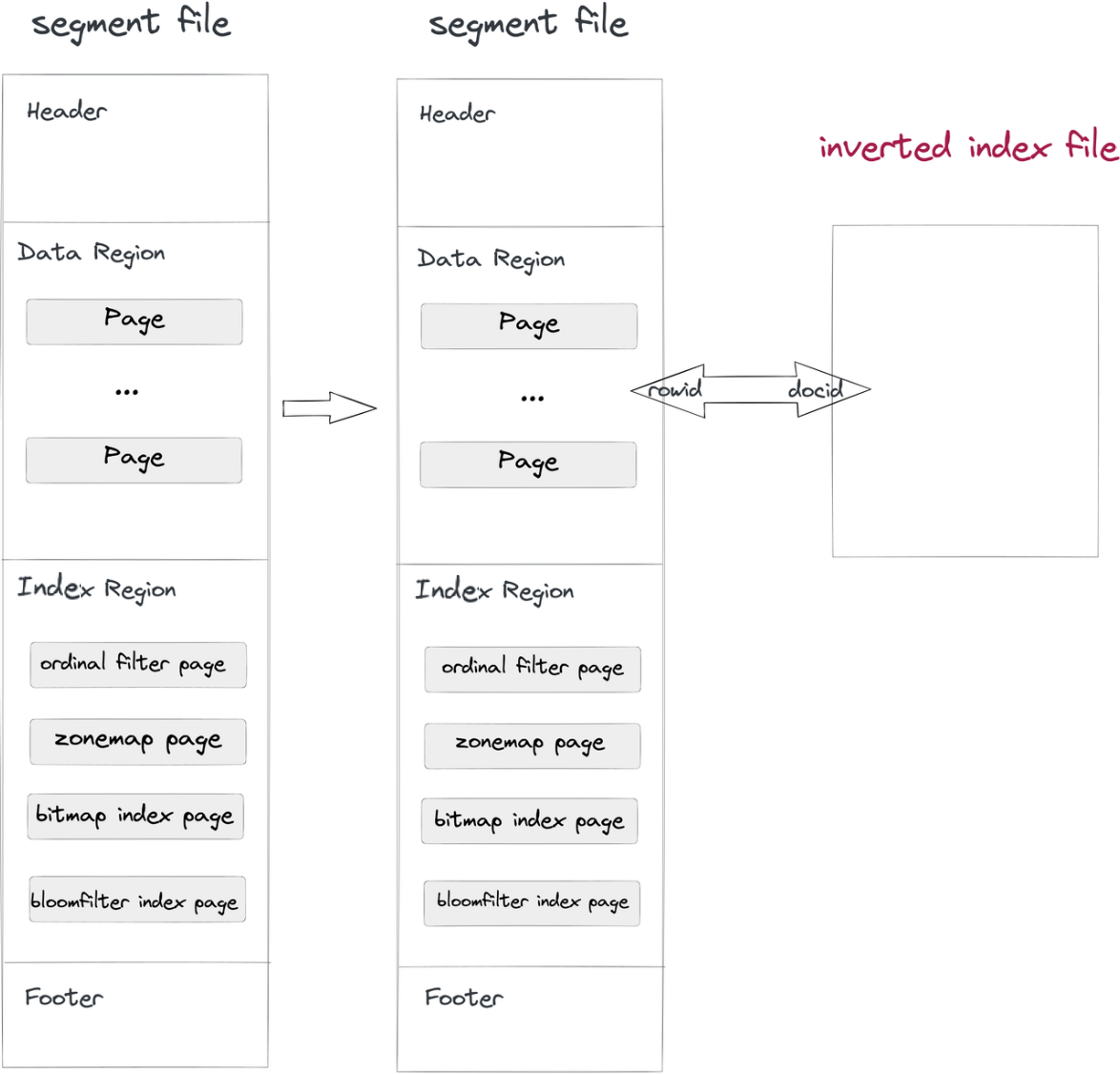
Este método no intrusivo separa el archivo de índice de los archivos de datos, por lo que puedes realizar cualquier cambio en los índices invertidos sin preocuparte por afectar los archivos de datos en sí o otros índices.
Optimizaciones para el Índice Invertido
Optimizaciones Generales
C++ Implementation and Vectorization
A diferencia de Elasticsearch, que utiliza Java, Apache Doris implementa C++ en sus módulos de almacenamiento, motor de ejecución de consultas y índices invertidos. En comparación con Java, C++ ofrece un mejor rendimiento, permite una vectorización más fácil y no produce overheads de GC de JVM. Hemos vectorizado cada paso del indexado invertido en Apache Doris, como la tokenización, la creación de índices y las consultas. Para darte una perspectiva, en el indexado invertido, Apache Doris escribe datos a una velocidad de 20MB/s por núcleo, que es cuatro veces la de Elasticsearch (5MB/s).
Almacenamiento y Compresión en Columna
Apache Lucene establece la base para los índices invertidos en Elasticsearch. Dado que Lucene está construido para soportar el almacenamiento de archivos, almacena datos en un formato orientado a filas.
En Apache Doris, los índices invertidos para diferentes columnas están aislados entre sí, y los archivos de índice invertido adoptan un almacenamiento en columna para facilitar la vectorización y la compresión de datos.
Al emplear la compresión Zstandard, Apache Doris logra una relación de compresión que varía de 5:1 a 10:1, velocidades de compresión más rápidas y un uso de espacio un 50% menor que la compresión GZIP.
Árboles BKD para Columnas Numéricas / de Fecha y Hora
Apache Doris implementa árboles BKD para columnas numéricas y de fecha y hora. Esto no solo mejora el rendimiento de las consultas de rango, sino que es un método más económico en espacio que convertir esas columnas en cadenas de longitud fija. Otros beneficios incluyen:
- Consultas de rango eficientes: Puede localizar rápidamente el rango de datos objetivo en columnas numéricas y de fecha y hora.
- Menos espacio de almacenamiento: Agrupa y comprime bloques de datos adyacentes para reducir los costos de almacenamiento.
- Soporte para datos multidimensionales: Los árboles BKD son escalables y adaptativos a tipos de datos multidimensionales, como puntos GEO y rangos.
Además de los árboles BKD, hemos optimizado aún más las consultas en columnas numéricas y de fecha y hora.
- Optimización para escenarios de baja cardinalidad: Hemos ajustado finamente el algoritmo de compresión para escenarios de baja cardinalidad, por lo que descomprimir y deserializar grandes cantidades de listas invertidas consumirá menos recursos de CPU.
- Pre-fetching: Para escenarios de alta tasa de acierto, adoptamos el pre-fetching. Si la tasa de acierto supera un umbral determinado, Doris omitirá el proceso de indexación y comenzará el filtrado de datos.
Optimizaciones personalizadas para OLAP
Por lo general, el análisis de registros es un tipo de consulta simple que no requiere características avanzadas (por ejemplo, puntuación de relevancia en Apache Lucene). La capacidad principal de un herramienta de procesamiento de logs es consultas rápidas y costos de almacenamiento bajos. Por lo tanto, en Apache Doris, hemos optimizado la estructura del índice invertido para satisfacer las necesidades de una base de datos OLAP.
- En la ingesta de datos, evitamos que múltiples hilos escriban datos en el mismo índice y, por lo tanto, evitamos los gastos generales causados por la contención de bloqueos.
- Descartamos los archivos de índice directo y los archivos Norm para liberar espacio de almacenamiento y reducir los gastos generales de E/S.
- Simplificamos la lógica de cálculo de puntuación de relevancia y clasificación para reducir aún más los gastos generales y aumentar el rendimiento.
Teniendo en cuenta que los logs se dividen por rango de tiempo y los logs históricos se consultan con menos frecuencia, planeamos proporcionar una gestión de índices más granular y flexible en futuras versiones de Apache Doris:
- Crear un índice invertido para un partición de datos específico: crear un índice para logs de los últimos siete días, etc.
- Eliminar índice invertido para un partición de datos específico: eliminar índice para logs de hace más de un mes, etc. (con el fin de liberar espacio de índice).
Pruebas comparativas
Evaluamos Apache Doris con conjuntos de datos públicamente disponibles frente a Elasticsearch y ClickHouse.
Para una comparación justa, garantizamos la uniformidad de las condiciones de prueba, incluidas la herramienta de pruebas comparativas, los conjuntos de datos y el hardware.
Apache Doris vs. Elasticsearch
- Herramienta de benchmarking: ES Rally, la herramienta oficial de pruebas para Elasticsearch
- Conjunto de datos: Registros del servidor HTTP de la Copa Mundial de 1998 (conjunto de datos autónomo en ES Rally)
- Tamaño de datos (antes de la compresión): 32G, 247 millones de filas, 134 bytes por fila (en promedio)
- Consulta: 11 consultas, incluyendo búsqueda por palabras clave, consulta de rango, agregación y clasificación; Cada consulta se ejecuta de manera serial 100 veces.
- Entorno: 3 máquinas virtuales en la nube con 16C 64G
Resultados de Apache Doris:
- Velocidad de escritura: 550 MB/s,4.2 veces más que Elasticsearch
- Relación de compresión: 10:1
- Uso de almacenamiento: 20% de lo que usa Elasticsearch
- Tiempo de respuesta: 43% de lo que tarda Elasticsearch

Apache Doris vs. ClickHouse
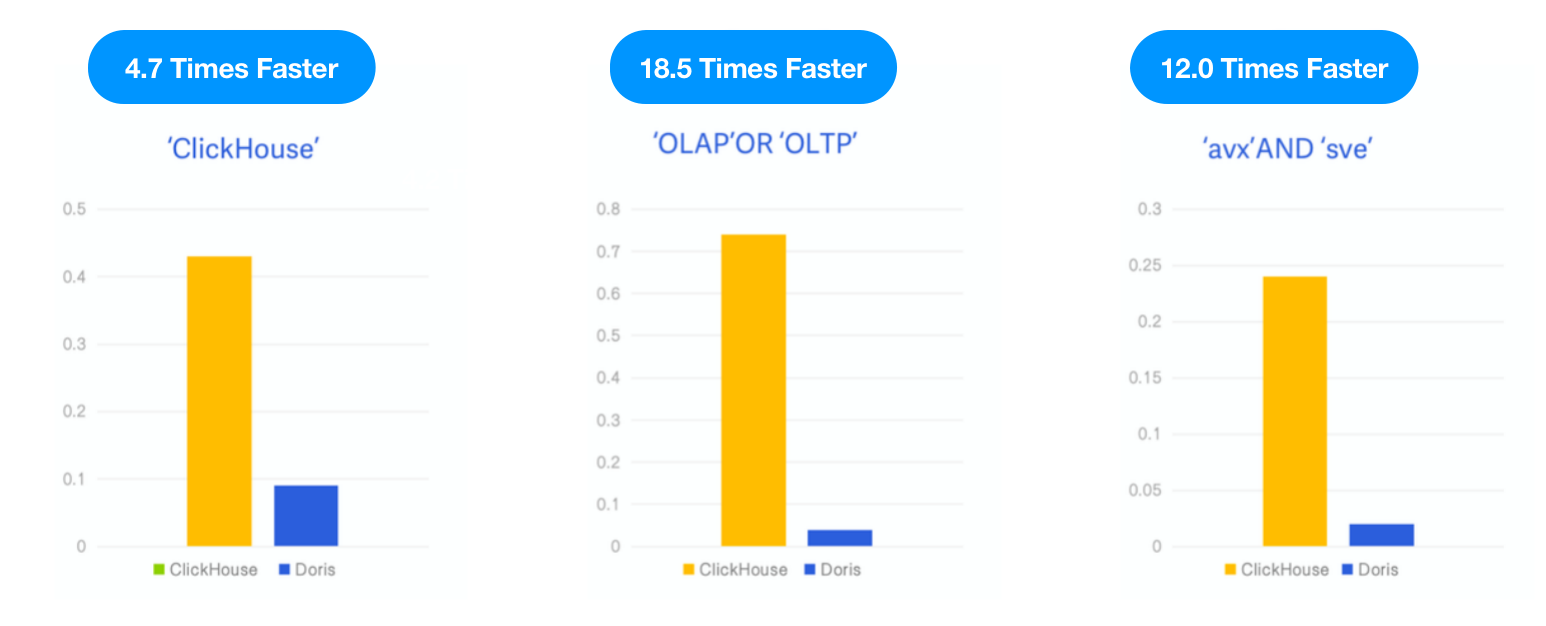
Como ClickHouse lanzó un índice invertido como una función experimental en la versión 23.1, probamos Apache Doris con el mismo conjunto de datos y SQL como se describe en el blog de ClickHouse y comparamos el rendimiento de ambos bajo los mismos recursos de prueba, caso y herramienta.
- Datos: 6.7G, 28.73 millones de filas, el conjunto de datos de Hacker News, formato Parquet
- Consulta: 3 búsquedas por palabras clave, contando el número de ocurrencias de las palabras clave “ClickHouse,” “OLAP,” OR “OLTP,” y “avx” AND “sve”.
- Entorno: 1 máquina virtual en la nube con 16C 64G
Resultado: Apache Doris fue 4.7 veces, 18.5 veces y 12 veces más rápido que ClickHouse en las tres consultas, respectivamente.
Uso y Ejemplo
- Conjunto de datos: un millón de registros de comentarios de Hacker News
Paso 1: Especificar el índice invertido a la tabla de datos al crear la tabla.
Parámetros:
- INDEX idx_comment (
comment): crear un índice llamado “idx_comment” para la columna “comment” - USING INVERTED: especificar índice invertido para la tabla
- PROPERTIES(“parser” = “english”): especificar el idioma de tokenización como inglés
CREATE TABLE hackernews_1m
(
`id` BIGINT,
`deleted` TINYINT,
`type` String,
`author` String,
`timestamp` DateTimeV2,
`comment` String,
`dead` TINYINT,
`parent` BIGINT,
`poll` BIGINT,
`children` Array<BIGINT>,
`url` String,
`score` INT,
`title` String,
`parts` Array<INT>,
`descendants` INT,
INDEX idx_comment (`comment`) USING INVERTED PROPERTIES("parser" = "english") COMMENT 'inverted index for comment'
)
DUPLICATE KEY(`id`)
DISTRIBUTED BY HASH(`id`) BUCKETS 10
PROPERTIES ("replication_num" = "1");(Nota: Puedes agregar un índice a una tabla existente a través de ADD INDEX idx_comment ON hackernews_1m(comment) USING INVERTED PROPERTIES("parser" = "english"). A diferencia del índice inteligente y del índice secundario, la creación de un índice invertido solo implica la lectura de la columna de comentarios, por lo que puede ser mucho más rápida.)
Paso 2: Recuperar las palabras “OLAP” y “OLTP” en la columna de comentarios con MATCH_ALL. El tiempo de respuesta aquí fue 1/10 de lo que era en coincidencia dura con like. (La brecha de rendimiento se agranda a medida que aumenta el volumen de datos.)
mysql> SELECT count() FROM hackernews_1m WHERE comment LIKE '%OLAP%' AND comment LIKE '%OLTP%';
+---------+
| count() |
+---------+
| 15 |
+---------+
1 row in set (0.13 sec)
mysql> SELECT count() FROM hackernews_1m WHERE comment MATCH_ALL 'OLAP OLTP';
+---------+
| count() |
+---------+
| 15 |
+---------+
1 row in set (0.01 sec)
Para obtener más información sobre las características y la guía de uso, consulte la documentación: Índice Invertido
Resumen
En resumen, lo que contribuye a que Apache Doris tenga una relación costo-beneficio 10 veces mayor que Elasticsearch es su optimización específica para OLAP en el índice invertido, respaldada por el motor de almacenamiento en columnas, el marco de procesamiento masivamente paralelo, el motor de consulta vectorizada y el optimizador basado en costos de Apache Doris.
Si bien estamos orgullosos de nuestra propia solución de índice invertido, entendemos que los benchmarks autoeditados pueden ser controvertidos, por lo que estamos abiertos a comentarios de cualquier tercero probadores y ver cómo Apache Doris funciona en casos del mundo real.
Source:
https://dzone.com/articles/building-a-log-analytics-solution-10-times-more-co