













El auge de la inteligencia artificial agente ha generado entusiasmo en torno a agentes que realizan tareas de manera autónoma, hacen recomendaciones y ejecutan flujos de trabajo complejos combinando la IA con la computación tradicional. Pero la creación de tales agentes en entornos impulsados por productos en el mundo real presenta desafíos que van más allá de la IA en sí misma.
Sin una arquitectura cuidadosa, las dependencias entre los componentes pueden crear cuellos de botella, limitar la escalabilidad y complicar el mantenimiento a medida que los sistemas evolucionan. La solución radica en desacoplar los flujos de trabajo, donde los agentes, la infraestructura y otros componentes interactúan fluidamente sin dependencias rígidas.
Este tipo de integración flexible y escalable requiere un “lenguaje” compartido para el intercambio de datos: una arquitectura robusta basada en eventos (EDA) alimentada por flujos de eventos. Al organizar las aplicaciones en torno a eventos, los agentes pueden operar en un sistema receptivo y desacoplado donde cada parte realiza su trabajo de forma independiente. Los equipos pueden elegir tecnologías libremente, gestionar las necesidades de escalado por separado y mantener límites claros entre los componentes, permitiendo una verdadera agilidad.
Para poner a prueba estos principios, desarrollé PodPrep AI, un asistente de investigación impulsado por IA que me ayuda a prepararme para entrevistas de podcast en Software Engineering Daily y Software Huddle. En esta publicación, profundizaré en el diseño y la arquitectura de PodPrep AI, mostrando cómo EDA y los flujos de datos en tiempo real impulsan un sistema agente efectivo.
Nota: Si desea ver solo el código, vaya a mi repositorio en GitHub aquí.
¿Por qué una Arquitectura Basada en Eventos para la IA?
En aplicaciones de inteligencia artificial en el mundo real, un diseño estrechamente acoplado y monolítico no es sostenible. Si bien las pruebas de concepto o demostraciones a menudo utilizan un sistema único y unificado por simplicidad, este enfoque rápidamente se vuelve impráctico en producción, especialmente en entornos distribuidos. Los sistemas estrechamente acoplados crean cuellos de botella, limitan la escalabilidad y ralentizan la iteración, todos desafíos críticos para evitar a medida que las soluciones de inteligencia artificial crecen.
Consideremos un agente de inteligencia artificial típico.
Puede necesitar extraer datos de múltiples fuentes, manejar ingeniería de consultas y flujos de trabajo RAG, e interactuar directamente con varias herramientas para ejecutar flujos de trabajo deterministas. La orquestación requerida es compleja, con dependencias en múltiples sistemas. Y si el agente necesita comunicarse con otros agentes, la complejidad aumenta aún más. Sin una arquitectura flexible, estas dependencias hacen que escalar y modificar sea casi imposible.

En producción, normalmente equipos diferentes manejan partes diferentes del stack: MLOps y data engineering gestionan el pipeline RAG, data science selecciona modelos, y los desarrolladores de aplicaciones construyen la interfaz y el backend. Una configuración estrechamente acoplada obliga a estos equipos a depender unos de otros, lo que ralentiza la entrega y dificulta la escalabilidad. Idealmente, las capas de aplicación no deberían necesitar comprender los detalles internos de la inteligencia artificial; simplemente deberían consumir los resultados cuando sea necesario.
Además, las aplicaciones de IA no pueden operar de forma aislada. Para obtener un verdadero valor, las percepciones de IA deben fluir sin problemas a través de plataformas de datos de clientes (CDPs), CRMs, analíticas y más. Las interacciones con los clientes deberían activar actualizaciones en tiempo real, alimentando directamente a otras herramientas para la acción y el análisis. Sin un enfoque unificado, integrar percepciones a través de plataformas se convierte en un mosaico difícil de gestionar e imposible de escalar.
La IA impulsada por EDA aborda estos desafíos al crear un “sistema nervioso central” para los datos. Con EDA, las aplicaciones transmiten eventos en lugar de depender de comandos encadenados. Esto desacopla los componentes, permitiendo que los datos fluyan de manera asíncrona donde sea necesario, lo que permite a cada equipo trabajar de forma independiente. EDA promueve una integración de datos sin fisuras, un crecimiento escalable y resiliencia, convirtiéndola en una base poderosa para los sistemas modernos impulsados por IA.
Diseñando un Agente de Investigación Potenciado por IA Escalable
En los últimos dos años, he realizado cientos de podcasts en Software Engineering Daily, Software Huddle y Partially Redacted.
Para preparar cada podcast, llevo a cabo un proceso de investigación en profundidad para elaborar un resumen del podcast que contiene mis pensamientos, antecedentes sobre el invitado y el tema, y una serie de preguntas potenciales. Para construir este resumen, normalmente investigo al invitado y la empresa para la que trabaja, escucho otros podcasts en los que puede haber aparecido, leo publicaciones en blogs que escribió y me informo sobre el tema principal que discutiremos.
Intento tejer conexiones con otros podcasts que he alojado o con mi propia experiencia relacionada con el tema o temas similares. Todo este proceso lleva mucho tiempo y esfuerzo. Las grandes operaciones de podcasts tienen investigadores y asistentes dedicados que hacen este trabajo para el presentador. No estoy dirigiendo ese tipo de operación aquí. Tengo que hacer todo esto yo mismo.
Para abordar esto, quería construir un agente que pudiera hacer este trabajo por mí. A un nivel alto, el agente se vería algo así como en la imagen a continuación.

Proporciono materiales fuente básicos como el nombre del invitado, la empresa, los temas en los que quiero centrarme, algunas URL de referencia como entradas de blog y podcasts existentes, y luego sucede algo de magia AI, y mi investigación está completa.
Esta simple idea me llevó a crear PodPrep AI, mi asistente de investigación con AI que solo me cuesta tokens.
El resto de este artículo analiza el diseño de PodPrep AI, comenzando con la interfaz de usuario.
Construyendo la Interfaz de Usuario del Agente
Diseñé la interfaz del agente como una aplicación web donde puedo introducir fácilmente el material fuente para el proceso de investigación. Esto incluye el nombre del invitado, su empresa, el tema de la entrevista, cualquier contexto adicional, y enlaces a blogs relevantes, sitios web y entrevistas anteriores en podcasts.
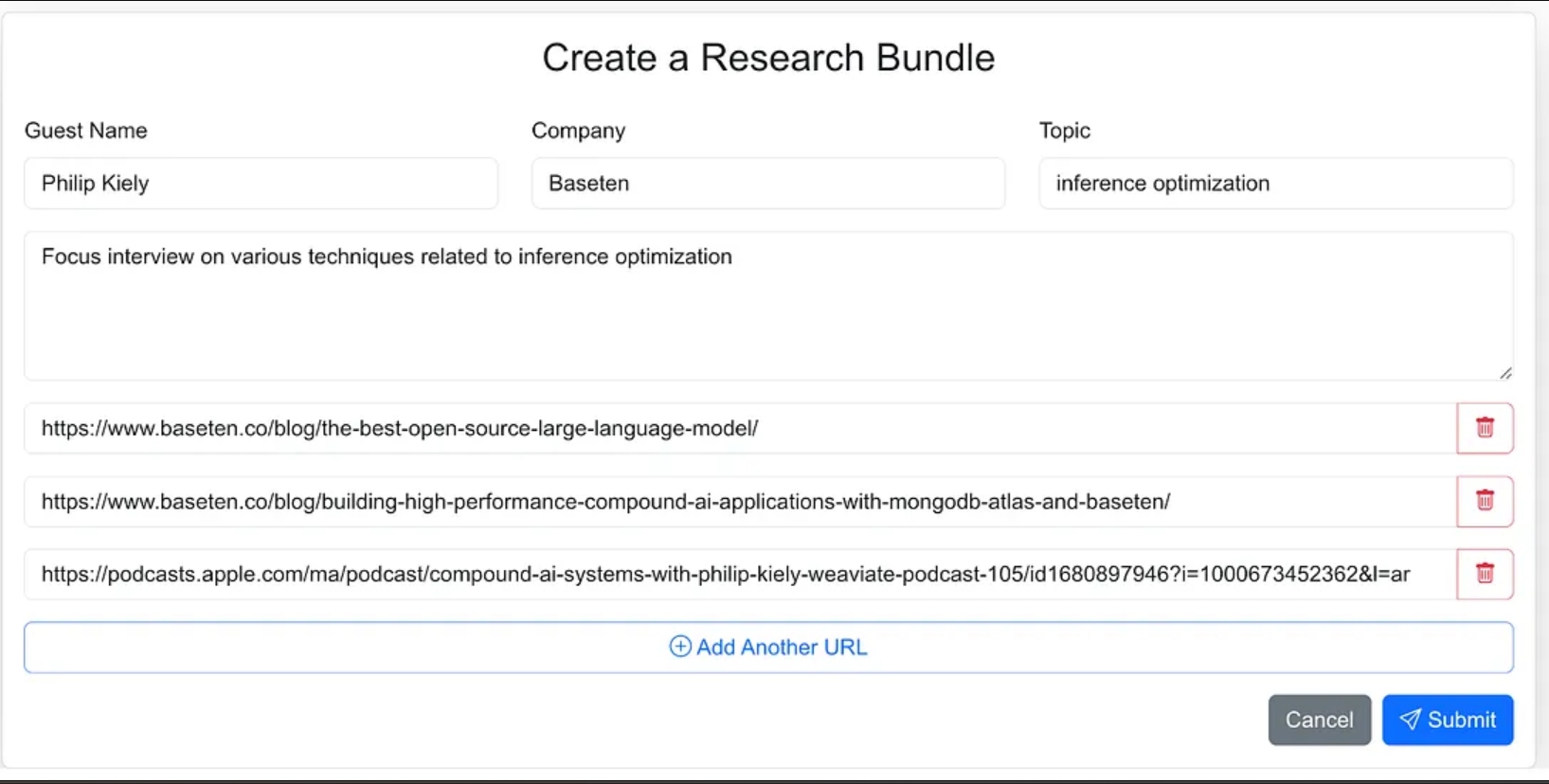
Podría haber dado al agente menos dirección y como parte del flujo de trabajo del agente hacer que busque los materiales fuente, pero para la versión 1.0, decidí proporcionar las URL fuente.
La aplicación web es una aplicación estándar de tres capas construida con Next.js y MongoDB para la base de datos de la aplicación. No sabe nada sobre IA. Simplemente permite al usuario ingresar nuevos paquetes de investigación y estos aparecen en un estado de procesamiento hasta que el proceso agente ha completado el flujo de trabajo y ha poblado un resumen de investigación en la base de datos de la aplicación.
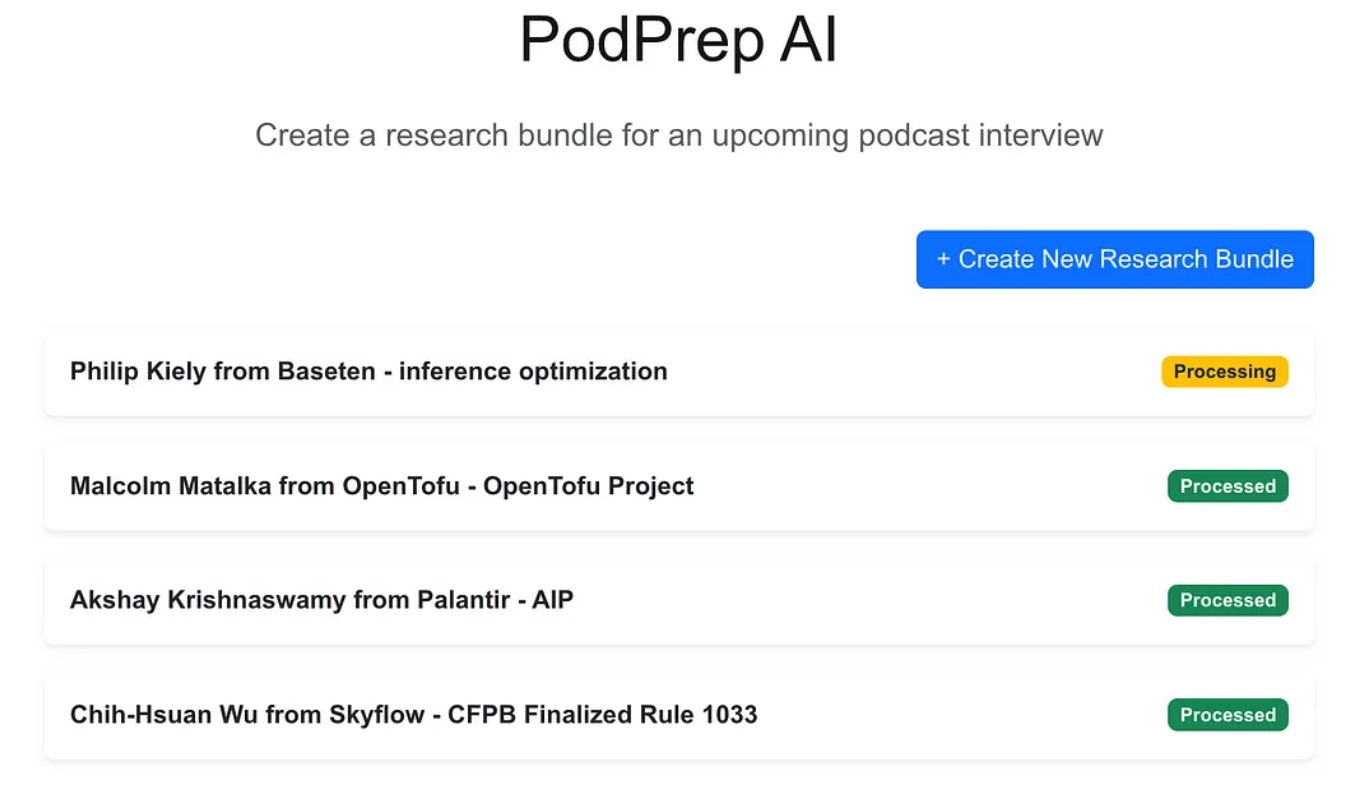
Una vez que la magia de la IA está completa, puedo acceder a un documento de resumen para la entrada como se muestra a continuación.

Creando el Flujo de Trabajo Agente
Para la versión 1.0, quería poder realizar tres acciones principales para construir el resumen de investigación:
- Para cualquier URL de sitio web, publicación de blog o podcast, recuperar el texto o resumen, dividir el texto en tamaños razonables, generar incrustaciones y almacenar la representación vectorial.
- Para todo el texto extraído de las URLs de las fuentes de investigación, extraer las preguntas más interesantes y almacenarlas.
- Generar un resumen de investigación de podcast combinando el contexto más relevante basado en las incrustaciones, las mejores preguntas formuladas anteriormente y cualquier otra información que formara parte de la entrada del paquete.
La imagen a continuación muestra la arquitectura desde la aplicación web hasta el flujo de trabajo agente.
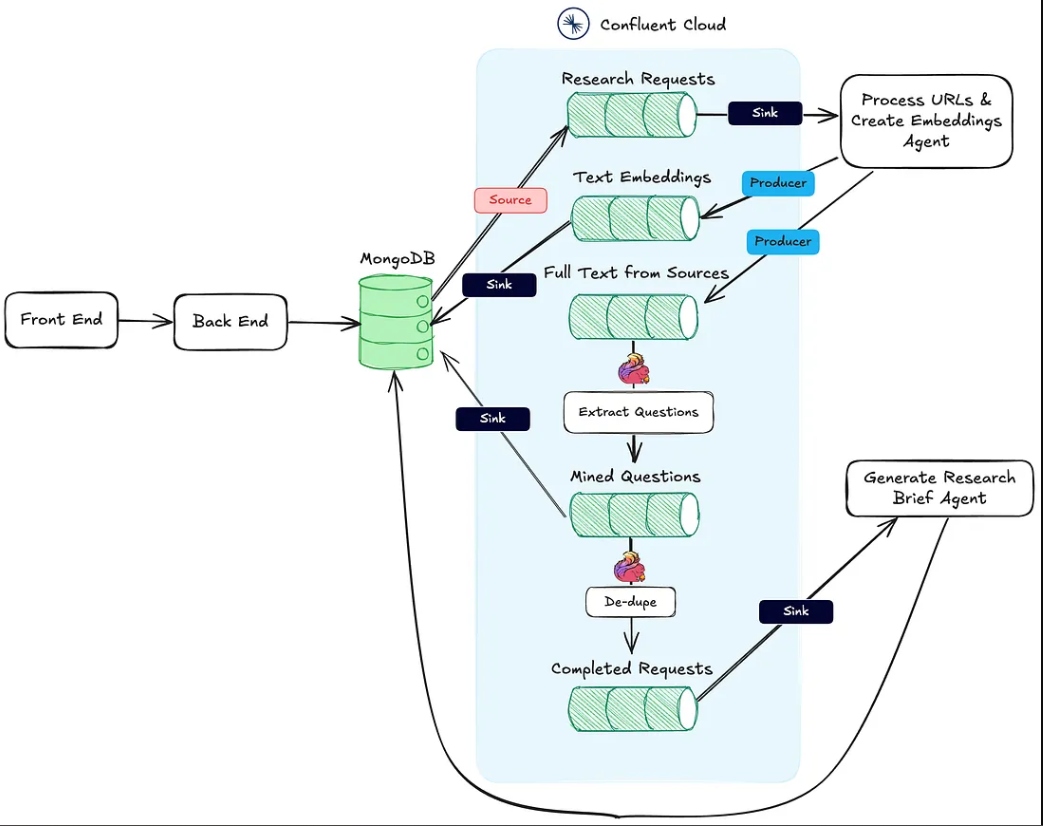
La acción #1 mencionada anteriormente está soportada por el endpoint HTTP Procesar URLs y Crear Incrustaciones Agent.
La acción #2 se lleva a cabo utilizando Flink y el soporte integrado de modelos de IA en Confluent Cloud.
Finalmente, la Acción #3 es ejecutada por el Agente Generador de Resúmenes de Investigación, también un punto final de destino HTTP, que es llamado una vez que las dos primeras acciones han sido completadas.
En las secciones siguientes, discuto cada una de estas acciones en detalle.
El Agente de Procesamiento de URLs y Creación de Incrustaciones
Este agente es responsable de extraer texto de las URLs de origen de la investigación y del pipeline de incrustación de vectores. A continuación se muestra el flujo de alto nivel de lo que está sucediendo detrás de escena para procesar los materiales de investigación.

Una vez que un paquete de investigación es creado por el usuario y guardado en MongoDB, un conector de origen de MongoDB produce mensajes a un tema de Kafka llamado solicitudes-de-investigación. Esto es lo que inicia el flujo de trabajo agente.
Cada solicitud POST al punto final HTTP contiene las URLs de la solicitud de investigación y la clave primaria en la colección de paquetes de investigación de MongoDB.
El agente recorre cada URL y si no es un podcast de Apple, recupera el HTML de la página completa. Dado que no conozco la estructura de la página, no puedo depender de las bibliotecas de análisis HTML para encontrar el texto relevante. En su lugar, envío el texto de la página al modelo gpt-4o-mini con una temperatura de cero usando el prompt a continuación para obtener lo que necesito.
`Here is the content of a webpage:
${text}
Instructions:
- If there is a blog post within this content, extract and return the main text of the blog post.
- If there is no blog post, summarize the most important information on the page.`
Para los podcasts, necesito hacer un poco más de trabajo.
Ingeniería Inversa de las URLs de Apple Podcasts
Para extraer datos de episodios de podcasts, primero necesitamos convertir el audio en texto usando el modelo Whisper. Pero antes de hacer eso, tenemos que localizar el archivo MP3 real de cada episodio de podcast, descargarlo y dividirlo en fragmentos de 25MB o menos (el tamaño máximo para Whisper).
El desafío es que Apple no proporciona un enlace MP3 directo para sus episodios de podcast. Sin embargo, el archivo MP3 está disponible en el feed RSS original del podcast, y podemos encontrar este feed programáticamente usando el ID de podcast de Apple.
Por ejemplo, en la URL a continuación, la parte numérica después de /id es el ID único de Apple del podcast:
https://podcasts.apple.com/us/podcast/deep-dive-into-inference-optimization-for-llms-with/id1699385780?i=1000675820505
Usando la API de Apple, podemos buscar el ID del podcast y recuperar una respuesta JSON que contenga la URL del feed RSS:
https://itunes.apple.com/lookup?id=1699385780&entity=podcast
Una vez que tenemos el XML del feed RSS, lo buscamos para encontrar el episodio específico. Dado que solo tenemos la URL del episodio de Apple (y no el título real), usamos el slug del título de la URL para localizar el episodio dentro del feed y recuperar su URL MP3.
async function getMp3DownloadUrl(url) {
let podcastId = extractPodcastId(url);
let titleToMatch = extractAndFormatTitle(url);
if (podcastId) {
let feedLookupUrl = `https://itunes.apple.com/lookup?id=${podcastId}&entity=podcast`;
const itunesResponse = await axios.get(feedLookupUrl);
const itunesData = itunesResponse.data;
// Check if results were returned
if (itunesData.resultCount === 0 || !itunesData.results[0].feedUrl) {
console.error("No feed URL found for this podcast ID.");
return;
}
// Extract the feed URL
const feedUrl = itunesData.results[0].feedUrl;
// Fetch the document from the feed URL
const feedResponse = await axios.get(feedUrl);
const rssContent = feedResponse.data;
// Parse the RSS feed XML
const rssData = await parseStringPromise(rssContent);
const episodes = rssData.rss.channel[0].item; // Access all items (episodes) in the feed
// Find the matching episode by title, have to transform title to match the URL-based title
const matchingEpisode = episodes.find(episode => {
return getSlug(episode.title[0]).includes(titleToMatch);
}
);
if (!matchingEpisode) {
console.log(`No episode found with title containing "${titleToMatch}"`);
return false;
}
// Extract the MP3 URL from the enclosure tag
return matchingEpisode.enclosure[0].$.url;
}
return false;
}
Ahora, con el texto de publicaciones de blogs, sitios web y MP3 disponibles, el agente utiliza el divisor de texto de caracteres recursivo de LangChain para dividir el texto en fragmentos y generar las incrustaciones de estos fragmentos. Los fragmentos se publican en el tema text-embeddings y se envían a MongoDB.
- Nota: Elegí usar MongoDB como mi base de datos de aplicación y base de datos vectorial. Sin embargo, debido al enfoque EDA que he tomado, estos pueden ser fácilmente sistemas separados, y solo es cuestión de intercambiar el conector de envío del tema de Text Embeddings.
Además de crear y publicar los embeddings, el agente también publica el texto de las fuentes en un tema llamado full-text-from-sources. La publicación en este tema activa la Acción #2.
Extracción de preguntas con Flink y OpenAI
Apache Flink es un marco de procesamiento de transmisiones de código abierto diseñado para manejar grandes volúmenes de datos en tiempo real, ideal para aplicaciones de alto rendimiento y baja latencia. Al combinar Flink con Confluent, podemos integrar modelos de lenguaje de aprendizaje profundo como el GPT de OpenAI directamente en flujos de trabajo de transmisión. Esta integración permite flujos de trabajo RAG en tiempo real, asegurando que el proceso de extracción de preguntas funcione con los datos más recientes disponibles.
Tener el texto original de la fuente en el flujo también nos permite introducir nuevos flujos de trabajo más adelante que utilicen los mismos datos, mejorando el proceso de generación de informes de investigación o enviándolo a servicios descendentes como un almacén de datos. Esta configuración flexible nos permite agregar funciones de IA y no IA adicionales con el tiempo sin necesidad de revisar por completo la canalización central.
En PodPrep AI, uso Flink para extraer preguntas del texto extraído de URLs de origen.
Configurar Flink para llamar a un LLM implica configurar una conexión a través de la CLI de Confluent. A continuación se muestra un ejemplo de comando para configurar una conexión con OpenAI, aunque hay disponibles múltiples opciones.
confluent flink connection create openai-connection \
--cloud aws \
--region us-east-1 \
--type openai \
--endpoint https://api.openai.com/v1/chat/completions \
--api-key <REPLACE_WITH_OPEN_AI_KEY>
Una vez establecida la conexión, puedo crear un modelo tanto en la Consola de la Nube como en la terminal de Flink SQL. Para la extracción de preguntas, configuro el modelo correspondientemente.
-- Creates model for pulling questions from research source material
CREATE MODEL `question_generation`
INPUT (text STRING)
OUTPUT (response STRING)
WITH (
'openai.connection'='openai-connection',
'provider'='openai',
'task'='text_generation',
'openai.model_version' = 'gpt-3.5-turbo',
'openai.system_prompt' = 'Extract the most interesting questions asked from the text. Paraphrase the questions and seperate each one by a blank line. Do not number the questions.'
);
Con el modelo listo, utilizo la función ml_predict incorporada en Flink para generar preguntas a partir del material fuente, escribiendo la salida en un flujo llamado mined-questions, el cual se sincroniza con MongoDB para un uso posterior.
-- Generates questions based on text pulled from research source material
INSERT INTO `mined-questions`
SELECT
`key`,
`bundleId`,
`url`,
q.response AS questions
FROM
`full-text-from-sources`,
LATERAL TABLE (
ml_predict('question_generation', content)
) AS q;
Flink también ayuda a rastrear cuándo todos los materiales de investigación han sido procesados, desencadenando la generación del resumen de investigación. Esto se logra escribiendo en un flujo completed-requests una vez que las URL en mined-questions coinciden con las de la secuencia de fuentes de texto completo.
-- Writes the bundleId to the complete topic once all questions have been created
INSERT INTO `completed-requests`
SELECT '' AS id, pmq.bundleId
FROM (
SELECT bundleId, COUNT(url) AS url_count_mined
FROM `mined-questions`
GROUP BY bundleId
) AS pmq
JOIN (
SELECT bundleId, COUNT(url) AS url_count_full
FROM `full-text-from-sources`
GROUP BY bundleId
) AS pft
ON pmq.bundleId = pft.bundleId
WHERE pmq.url_count_mined = pft.url_count_full;
A medida que se escriben mensajes en completed-requests, el ID único del paquete de investigación se envía al Agente Generador de Resúmenes de Investigación.
El Agente Generador de Resúmenes de Investigación
Este agente toma todos los materiales de investigación más relevantes disponibles y utiliza un LLM para crear un resumen de investigación. A continuación se muestra el flujo de eventos de alto nivel que tienen lugar para crear un resumen de investigación.

Diagrama de flujo para el agente Generador de Resúmenes de Investigación
Veamos detenidamente algunos de estos pasos. Para construir la indicación para el LLM, combino las preguntas extraídas, el tema, el nombre del invitado, el nombre de la empresa, una indicación del sistema para orientación y el contexto almacenado en la base de datos vectorial que es más semánticamente similar al tema del podcast.
Debido a que el paquete de investigación tiene información contextual limitada, es un desafío extraer el contexto más relevante directamente de la tienda de vectores. Para abordar esto, hago que el LLM genere una consulta de búsqueda para localizar el contenido que mejor coincida, como se muestra en el nodo “Crear Consulta de Búsqueda” en el diagrama.
async function getSearchString(researchBundle) {
const userPrompt = `
Guest:
${researchBundle.guestName}
Company:
${researchBundle.company}
Topic:
${researchBundle.topic}
Context:
${researchBundle.context}
Create a natural language search query given the data available.
`;
const systemPrompt = `You are an expert in research for an engineering podcast. Using the
guest name, company, topic, and context, create the best possible query to search a vector
database for relevant data mined from blog posts and existing podcasts.`;
const messages = [
new SystemMessage(systemPrompt),
new HumanMessage(userPrompt),
];
const response = await model.invoke(messages);
return response.content;
}
Usando la consulta generada por el LLM, creo una incrustación y busco en MongoDB a través de un índice de vectores, filtrando por el bundleId para limitar la búsqueda a materiales relevantes para el podcast específico.
Con la mejor información contextual identificada, construyo un aviso y genero el informe de investigación, guardando el resultado en MongoDB para que la aplicación web lo muestre.
Cosas a tener en cuenta sobre la implementación
Escribí tanto la aplicación de front-end para PodPrep AI como los agentes en Javascript, pero en un escenario del mundo real, el agente probablemente estaría en un lenguaje diferente como Python. Además, para simplificar, tanto el Agente de Procesar URLs y Crear Embeddings como el Agente de Generar Informe de Investigación están dentro del mismo proyecto ejecutándose en el mismo servidor web. En un sistema de producción real, estos podrían ser funciones sin servidor, ejecutándose de forma independiente.
Reflexiones finales
La construcción de PodPrep AI resalta cómo una arquitectura orientada a eventos permite que las aplicaciones de inteligencia artificial del mundo real se escalen y se adapten sin problemas. Con Flink y Confluent, creé un sistema que procesa datos en tiempo real, impulsando un flujo de trabajo impulsado por IA sin dependencias rígidas. Este enfoque desacoplado permite que los componentes operen de forma independiente, pero permanezcan conectados a través de flujos de eventos, esencial para aplicaciones complejas y distribuidas donde diferentes equipos gestionan diversas partes del stack.
En el entorno impulsado por la IA de hoy, acceder a datos frescos y en tiempo real a través de sistemas es esencial. EDA funciona como un “sistema nervioso central” para los datos, permitiendo una integración fluida y flexibilidad a medida que el sistema escala.
Source:
https://dzone.com/articles/build-a-research-assistant-with-kafka-flink