













¿Alguna vez has querido visualizar el tráfico de tu red en tiempo real? En este tutorial, aprenderás cómo construir un panel interactivo de análisis de tráfico de red con Python y Streamlit. Streamlit es un marco de Python de código abierto que puedes utilizar para desarrollar aplicaciones web para análisis de datos y procesamiento de datos.
Al final de este tutorial, sabrás cómo capturar paquetes de red crudos desde la NIC (tarjeta de interfaz de red) de tu computadora, procesar los datos y crear visualizaciones hermosas que se actualizarán en tiempo real.
Tabla de contenidos
¿Por qué es importante el análisis del tráfico de red?
El análisis del tráfico de red es un requisito crítico en las empresas donde las redes forman la columna vertebral de casi todas las aplicaciones y servicios. En su núcleo, tenemos el análisis de paquetes de red que implica monitorear la red, capturar todo el tráfico (ingreso y egreso) e interpretar estos paquetes a medida que fluyen a través de una red. Puedes usar esta técnica para identificar patrones de seguridad, detectar anomalías y asegurar la seguridad y eficiencia de la red.
Este proyecto de prueba de concepto en el que trabajaremos en este tutorial es particularmente útil ya que te ayuda a visualizar y analizar la actividad de la red en tiempo real. Y esto te permitirá entender cómo se realizan la resolución de problemas, las optimizaciones de rendimiento y el análisis de seguridad en los sistemas empresariales.
Requisitos previos
-
Python 3.8 o una versión más nueva instalada en tu sistema.
-
Un entendimiento básico de conceptos de redes informáticas.
-
Familiaridad con el lenguaje de programación Python y sus bibliotecas de uso común.
-
Conocimientos básicos de técnicas y bibliotecas de visualización de datos.
Cómo configurar tu proyecto
Para comenzar, crea la estructura del proyecto e instala las herramientas necesarias con Pip con los siguientes comandos:
mkdir network-dashboard
cd network-dashboard
pip install streamlit pandas scapy plotly
Utilizaremos Streamlit para las visualizaciones del panel, Pandas para el procesamiento de datos, Scapy para la captura de paquetes de red y su procesamiento, y finalmente Plotly para trazar gráficos con nuestros datos recolectados.
Cómo construir las funcionalidades principales
Colocaremos todo el código en un solo archivo llamado dashboard.py. En primer lugar, comencemos importando todos los elementos que utilizaremos:
import streamlit as st
import pandas as pd
import plotly.express as px
import plotly.graph_objects as go
from scapy.all import *
from collections import defaultdict
import time
from datetime import datetime
import threading
import warnings
import logging
from typing import Dict, List, Optional
import socket
Ahora configuremos el registro configurando una configuración básica de registro. Esto se utilizará para rastrear eventos y ejecutar nuestra aplicación en modo de depuración. Actualmente hemos establecido el nivel de registro en INFO, lo que significa que se mostrarán los eventos con nivel INFO o superior. Si no estás familiarizado con el registro en Python, te recomendaría revisar este documento que profundiza en el tema.
# Configurar registro
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s - %(levelname)s - %(message)s'
)
logger = logging.getLogger(__name__)
A continuación, construiremos nuestro procesador de paquetes. Implementaremos la funcionalidad para procesar nuestros paquetes capturados en esta clase.
class PacketProcessor:
"""Process and analyze network packets"""
def __init__(self):
self.protocol_map = {
1: 'ICMP',
6: 'TCP',
17: 'UDP'
}
self.packet_data = []
self.start_time = datetime.now()
self.packet_count = 0
self.lock = threading.Lock()
def get_protocol_name(self, protocol_num: int) -> str:
"""Convert protocol number to name"""
return self.protocol_map.get(protocol_num, f'OTHER({protocol_num})')
def process_packet(self, packet) -> None:
"""Process a single packet and extract relevant information"""
try:
if IP in packet:
with self.lock:
packet_info = {
'timestamp': datetime.now(),
'source': packet[IP].src,
'destination': packet[IP].dst,
'protocol': self.get_protocol_name(packet[IP].proto),
'size': len(packet),
'time_relative': (datetime.now() - self.start_time).total_seconds()
}
# Agregar información específica de TCP
if TCP in packet:
packet_info.update({
'src_port': packet[TCP].sport,
'dst_port': packet[TCP].dport,
'tcp_flags': packet[TCP].flags
})
# Agregar información específica de UDP
elif UDP in packet:
packet_info.update({
'src_port': packet[UDP].sport,
'dst_port': packet[UDP].dport
})
self.packet_data.append(packet_info)
self.packet_count += 1
# Mantener solo los últimos 10000 paquetes para prevenir problemas de memoria
if len(self.packet_data) > 10000:
self.packet_data.pop(0)
except Exception as e:
logger.error(f"Error processing packet: {str(e)}")
def get_dataframe(self) -> pd.DataFrame:
"""Convert packet data to pandas DataFrame"""
with self.lock:
return pd.DataFrame(self.packet_data)
Esta clase construirá nuestra funcionalidad principal y tiene varias funciones de utilidad que se utilizarán para procesar los paquetes.
Los paquetes de red se clasifican en dos a nivel de transporte (TCP y UDP) y el protocolo ICMP a nivel de red. Si no estás familiarizado con los conceptos de TCP/IP, te recomiendo revisar este artículo en freeCodeCamp News.
Nuestro constructor llevará un registro de todos los paquetes vistos que se clasifican en estos bloques de tipo de protocolo TCP/IP que hemos definido. También tomaremos nota del tiempo de captura del paquete, los datos capturados y el número de paquetes capturados.
También utilizaremos un bloqueo de hilo para asegurar que solo se procese un paquete a la vez. Esto se puede extender aún más para permitir que el proyecto tenga un procesamiento de paquetes paralelo.
La función auxiliar get_protocol_name nos ayuda a obtener el tipo correcto de protocolo basado en sus números de protocolo. Para dar un poco de contexto sobre esto, la Autoridad de Números Asignados de Internet (IANA) asigna números estandarizados para identificar diferentes protocolos en un paquete de red. Cuando vemos estos números en el paquete de red analizado, sabremos qué tipo de protocolo se está utilizando en el paquete interceptado actualmente. Para el alcance de este proyecto, mapearemos solo a TCP, UDP e ICMP (Ping). Si encontramos algún otro tipo de paquete, lo categorizaremos como OTRO(<número_de_protocolo>).
La función process_packet maneja nuestra funcionalidad principal que procesará estos paquetes individuales. Si el paquete contiene una capa IP, tomará nota de las direcciones IP de origen y destino, el tipo de protocolo, el tamaño del paquete y el tiempo transcurrido desde el inicio de la captura del paquete.
Para paquetes con protocolos específicos de capa de transporte (como TCP y UDP), capturaremos los puertos de origen y destino junto con las banderas TCP para paquetes TCP. Estos detalles extraídos se almacenarán en memoria en la lista packet_data. También llevaremos un registro del packet_count a medida que se procesan estos paquetes.
La función get_dataframe nos ayuda a convertir la lista packet_data en un marco de datos Pandas que luego se utilizará para nuestra visualización.
Cómo crear las visualizaciones de Streamlit
Ahora es el momento de construir nuestro panel interactivo de Streamlit. Definiremos una función llamada create_visualization en el script dashboard.py (fuera de nuestra clase de procesamiento de paquetes).
def create_visualizations(df: pd.DataFrame):
"""Create all dashboard visualizations"""
if len(df) > 0:
# Distribución de protocolos
protocol_counts = df['protocol'].value_counts()
fig_protocol = px.pie(
values=protocol_counts.values,
names=protocol_counts.index,
title="Protocol Distribution"
)
st.plotly_chart(fig_protocol, use_container_width=True)
# Línea de tiempo de paquetes
df['timestamp'] = pd.to_datetime(df['timestamp'])
df_grouped = df.groupby(df['timestamp'].dt.floor('S')).size()
fig_timeline = px.line(
x=df_grouped.index,
y=df_grouped.values,
title="Packets per Second"
)
st.plotly_chart(fig_timeline, use_container_width=True)
# Principales direcciones IP de origen
top_sources = df['source'].value_counts().head(10)
fig_sources = px.bar(
x=top_sources.index,
y=top_sources.values,
title="Top Source IP Addresses"
)
st.plotly_chart(fig_sources, use_container_width=True)
Esta función tomará el marco de datos como entrada y nos ayudará a graficar tres gráficos:
-
Gráfico de Distribución de Protocolos: Este gráfico mostrará la proporción de diferentes protocolos (por ejemplo, TCP, UDP, ICMP) en el tráfico de paquetes capturado.
-
Gráfico de Línea de Tiempo de Paquetes: Este gráfico mostrará la cantidad de paquetes procesados por segundo durante un período de tiempo.
-
Gráfico de las principales direcciones IP de origen: Este gráfico resaltará las 10 direcciones IP que enviaron la mayor cantidad de paquetes en el tráfico capturado.
El gráfico de distribución de protocolos es simplemente un gráfico circular de los conteos de protocolos para los tres tipos diferentes (junto con OTROS). Usamos las herramientas de Python Streamlit y Plotly para trazar estos gráficos. Dado que también anotamos la marca de tiempo desde que comenzó la captura de paquetes, utilizaremos estos datos para trazar la tendencia de los paquetes capturados a lo largo del tiempo.
Para el segundo gráfico, realizaremos una operación groupby en los datos y obtendremos el número de paquetes capturados en cada segundo (S representa segundos), y luego finalmente trazaremos el gráfico.
Finalmente, para el tercer gráfico, contaremos las direcciones IP de origen distintas observadas y trazaremos un gráfico de los conteos de IP para mostrar las 10 principales IPs.
Cómo Capturar los Paquetes de Red
Ahora, vamos a construir la funcionalidad que nos permita capturar los datos de paquetes de red.
def start_packet_capture():
"""Start packet capture in a separate thread"""
processor = PacketProcessor()
def capture_packets():
sniff(prn=processor.process_packet, store=False)
capture_thread = threading.Thread(target=capture_packets, daemon=True)
capture_thread.start()
return processor
Esta es una función simple que instancia la clase PacketProcessor y luego utiliza la función sniff en el módulo scapy para comenzar a capturar los paquetes.
Usamos threading aquí para permitirnos capturar paquetes de forma independiente del flujo principal del programa. Esto asegura que la operación de captura de paquetes no bloquee otras operaciones como la actualización del panel en tiempo real. También devolvemos la instancia de PacketProcessor creada para que pueda ser utilizada en nuestro programa principal.
Uniendo Todo
Ahora vamos a unir todas estas piezas con nuestra función main que actuará como la función controladora para nuestro programa.
def main():
"""Main function to run the dashboard"""
st.set_page_config(page_title="Network Traffic Analysis", layout="wide")
st.title("Real-time Network Traffic Analysis")
# Inicializar procesador de paquetes en estado de sesión
if 'processor' not in st.session_state:
st.session_state.processor = start_packet_capture()
st.session_state.start_time = time.time()
# Crear diseño del panel de control
col1, col2 = st.columns(2)
# Obtener datos actuales
df = st.session_state.processor.get_dataframe()
# Mostrar métricas
with col1:
st.metric("Total Packets", len(df))
with col2:
duration = time.time() - st.session_state.start_time
st.metric("Capture Duration", f"{duration:.2f}s")
# Mostrar visualizaciones
create_visualizations(df)
# Mostrar paquetes recientes
st.subheader("Recent Packets")
if len(df) > 0:
st.dataframe(
df.tail(10)[['timestamp', 'source', 'destination', 'protocol', 'size']],
use_container_width=True
)
# Agregar botón de actualización
if st.button('Refresh Data'):
st.rerun()
# Actualización automática
time.sleep(2)
st.rerun()
Esta función también instanciará el panel de control de Streamlit e integrará todos nuestros componentes juntos. Primero establecemos el título de página de nuestro panel de control de Streamlit y luego inicializamos nuestro PacketProcessor. Usamos el estado de sesión en Streamlit para asegurar que se cree solo una instancia de captura de paquetes y se mantenga su estado.
Ahora, obtendremos dinámicamente el dataframe del estado de sesión cada vez que se procesen los datos y comenzaremos a mostrar las métricas y las visualizaciones. También mostraremos los paquetes capturados recientemente junto con información como la marca de tiempo, las IPs de origen y destino, el protocolo y el tamaño del paquete. También agregaremos la capacidad para que el usuario actualice manualmente los datos desde el panel de control mientras también los actualizamos automáticamente cada dos segundos.
Finalmente, ejecutemos el programa con el siguiente comando:
sudo streamlit run dashboard.py
Ten en cuenta que tendrás que ejecutar el programa con sudo ya que las capacidades de captura de paquetes requieren privilegios administrativos. Si estás en Windows, abre tu terminal como Administrador y luego ejecuta el programa sin el prefijo de sudo.
Da un momento para que el programa comience a capturar paquetes. Si todo va bien, deberías ver algo como esto:
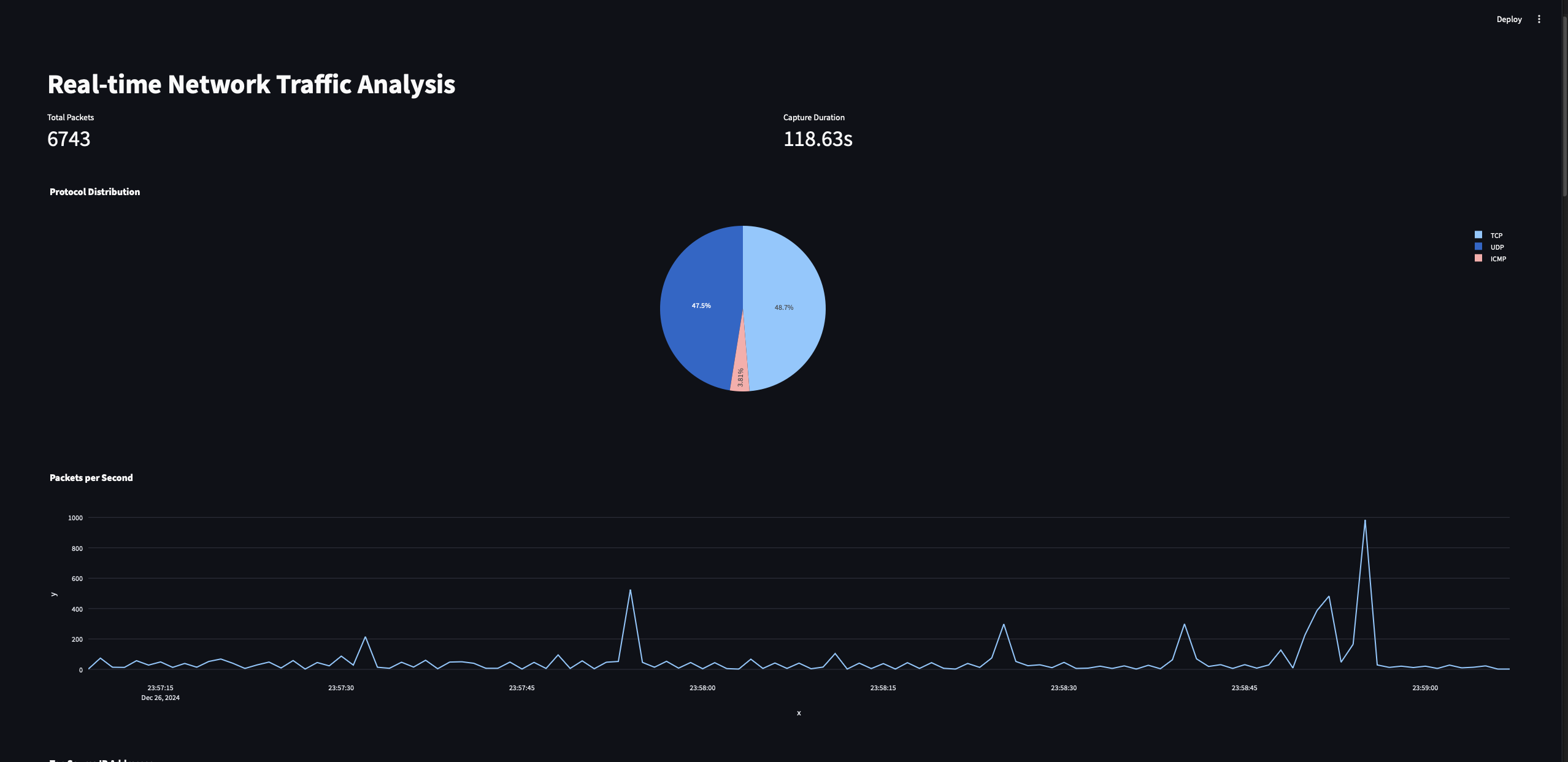
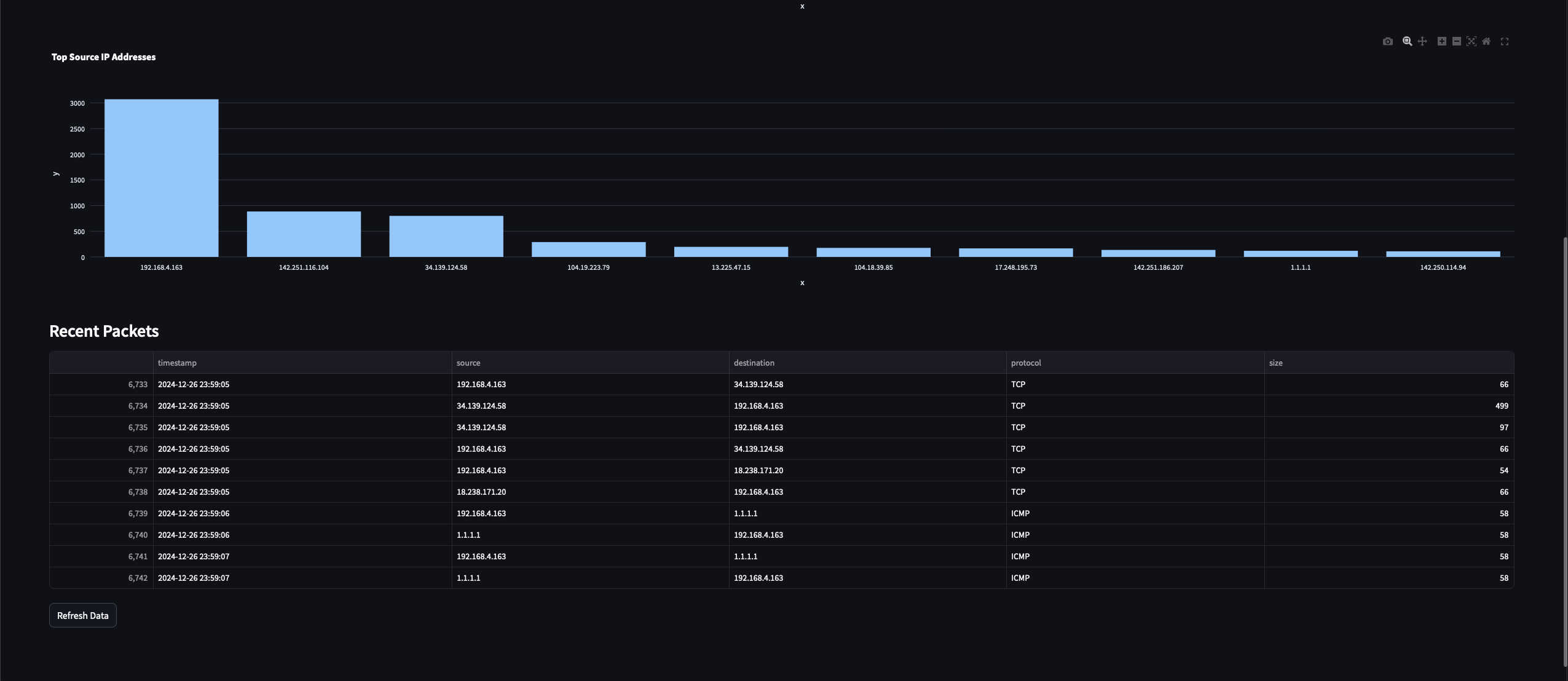
Estas son todas las visualizaciones que acabamos de implementar en nuestro programa de panel de control Streamlit.
Mejoras futuras
Con eso, aquí tienes algunas ideas de mejora futuras que puedes usar para ampliar las funcionalidades del panel de control:
-
Agregar capacidades de aprendizaje automático para detección de anomalías
-
Implementar mapeo de IP geográfico
-
Crear alertas personalizadas basadas en patrones de análisis de tráfico
-
Agregar opciones de análisis de carga útil de paquetes
Conclusión
¡Felicitaciones! Ahora has construido con éxito un panel de análisis de tráfico de red en tiempo real con Python y Streamlit. Este programa proporcionará información valiosa sobre el comportamiento de la red y puede ampliarse para diversos casos de uso, desde monitoreo de seguridad hasta optimización de red.
¡Con eso, espero que hayas aprendido algunos conceptos básicos sobre el análisis del tráfico de red, así como un poco de programación en Python. ¡Gracias por leer!