













Las organizaciones comienzan su adopción de transmisión de datos con un único clúster de Apache Kafka para implementar los primeros casos de uso. La necesidad de gobernanza de datos y seguridad a nivel de grupo pero con diferentes SLA, latencia y requisitos de infraestructura introduce nuevos clústeres de Kafka. Los múltiples clústeres de Kafka son la norma, no la excepción. Los casos de uso incluyen integración híbrida, agregación, migración y recuperación ante desastres. Esta publicación de blog explora historias de éxito del mundo real y estrategias de clúster para diferentes implementaciones de Kafka en diversas industrias.

Apache Kafka: El estándar de facto para arquitecturas basadas en eventos y transmisión de datos
Apache Kafka es una plataforma de transmisión de eventos distribuida de código abierto diseñada para procesamiento de datos de alta capacidad y baja latencia. Permite publicar, suscribirse, almacenar y procesar flujos de registros en tiempo real.
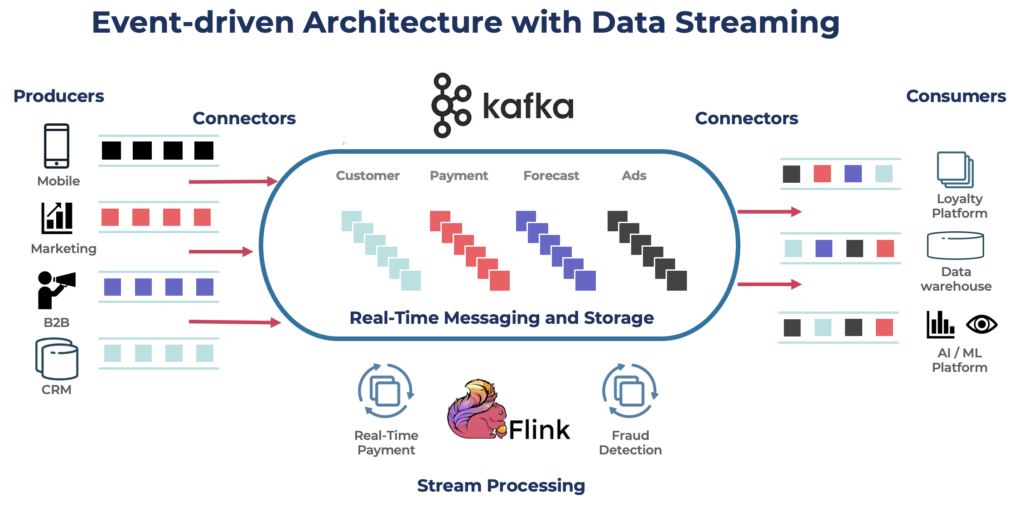
Kafka es una opción popular para construir tuberías de datos en tiempo real y aplicaciones de streaming. El protocolo Kafka se convirtió en el estándar de facto para el streaming de eventos a través de varios marcos, soluciones y servicios en la nube. Soporta cargas de trabajo operativas y analíticas con características como almacenamiento persistente, escalabilidad y tolerancia a fallos. Kafka incluye componentes como Kafka Connect para integración y Kafka Streams para procesamiento de flujos, lo que lo convierte en una herramienta versátil para varios casos de uso impulsados por datos.
Si bien Kafka es famoso por casos de uso en tiempo real, muchos proyectos aprovechan la plataforma de streaming de datos para la consistencia de datos en toda la arquitectura empresarial, incluidos bases de datos, lagos de datos, sistemas heredados, APIs abiertas y aplicaciones nativas de la nube.
Diferentes tipos de clústeres de Apache Kafka
Kafka es un sistema distribuido. Una configuración de producción generalmente requiere al menos cuatro brokers. Por lo tanto, la mayoría de las personas asume automáticamente que todo lo que necesitas es un solo clúster distribuido que escalas cuando agregas rendimiento y casos de uso. Esto no está mal al principio. Pero…
Un clúster de Kafka no es la respuesta correcta para cada caso de uso. Varias características influyen en la arquitectura de un clúster de Kafka:
- Disponibilidad: ¿Cero tiempo de inactividad? ¿99.99% de SLA de tiempo de actividad? ¿Análisis no críticos?
- Latencia: ¿Procesamiento de extremo a extremo en menos de 100 ms (incluido el procesamiento)? ¿Pipeline de almacén de datos de extremo a extremo de 10 minutos? ¿Viaje en el tiempo para reprocesar eventos históricos?
- Costo: ¿Valor vs. costo? Importa el Costo Total de Propiedad (TCO). ¡Por ejemplo, en la nube pública, la red puede representar hasta el 80% del costo total de Kafka!
- Seguridad y Privacidad de Datos: ¿Privacidad de datos (datos PCI, GDPR, etc.)? ¿Gobernanza de datos y cumplimiento normativo? ¿Cifrado de extremo a extremo a nivel de atributo? ¿Traer tu propia clave? ¿Acceso público y compartición de datos? ¿Entorno de borde con separación de aire?
- Rendimiento y Tamaño de Datos: ¿Transacciones críticas (normalmente de bajo volumen)? ¿Grandes flujos de datos (clickstream, sensores IoT, registros de seguridad, etc.)?
Temas relacionados como en las instalaciones frente a la nube pública, regional frente a global, y muchos otros requisitos también afectan la arquitectura de Kafka.
Estrategias y Arquitecturas de Clúster de Apache Kafka
Un solo clúster de Kafka es frecuentemente el punto de partida correcto para tu viaje de transmisión de datos. Puede abordar múltiples casos de uso de diferentes dominios comerciales y procesar gigabytes por segundo (si se opera y escala de la manera correcta).
Sin embargo, dependiendo de los requisitos de tu proyecto, necesitarás una arquitectura empresarial con múltiples clústeres de Kafka. Aquí tienes algunos ejemplos comunes:
- Arquitectura Híbrida: Integración de datos y sincronización de datos unidireccional o bidireccional entre múltiples centros de datos. A menudo, la conectividad entre un centro de datos local y un proveedor de servicios de nube pública. La descarga de datos de sistemas heredados a análisis en la nube es uno de los escenarios más comunes. Pero también es posible la comunicación de comando y control, es decir, enviar decisiones/recomendaciones/transacciones a un entorno regional (por ejemplo, almacenar un pago o pedido desde una aplicación móvil en el mainframe).
- Múltiples Regiones/Múltiples Nubes: Replicación de datos por razones de cumplimiento, costo o privacidad de datos. El intercambio de datos generalmente solo incluye una fracción de los eventos, no todos los temas de Kafka. La atención médica es una de las muchas industrias que sigue esta dirección.
- Recuperación ante Desastres: Replicación de datos críticos en modo activo-activo o activo-pasivo entre diferentes centros de datos o regiones de nube. Incluye estrategias y herramientas para mecanismos de conmutación por error y retroceso en caso de desastre para garantizar la continuidad del negocio y el cumplimiento.
- Agregación: Clústeres regionales para procesamiento local (por ejemplo, preprocesamiento, ETL en streaming, aplicaciones de negocios de procesamiento de flujo) y replicación de datos curados al centro de datos o nube de big data. Las tiendas minoristas son un excelente ejemplo.
- Migración: Modernización de TI con una migración de local a la nube o de código abierto autogestionado a un SaaS totalmente gestionado. Tales migraciones se pueden realizar con cero tiempo de inactividad o pérdida de datos mientras el negocio continúa durante el cambio.
- Edge (Desconectado/Aislado): La seguridad, el costo o la latencia requieren implementaciones en el borde, por ejemplo, en una fábrica o tienda minorista. Algunas industrias se despliegan en entornos críticos para la seguridad con un gateway de hardware unidireccional y diodo de datos.
- Broker Único: No es resiliente, pero es suficiente para escenarios como incrustar un broker de Kafka en una máquina o en un PC industrial (IPC) y replicar datos agregados en un gran clúster de análisis de Kafka en la nube. Un buen ejemplo es la instalación de transmisión de datos (incluida la integración y el procesamiento) en la computadora de un soldado en el campo de batalla.
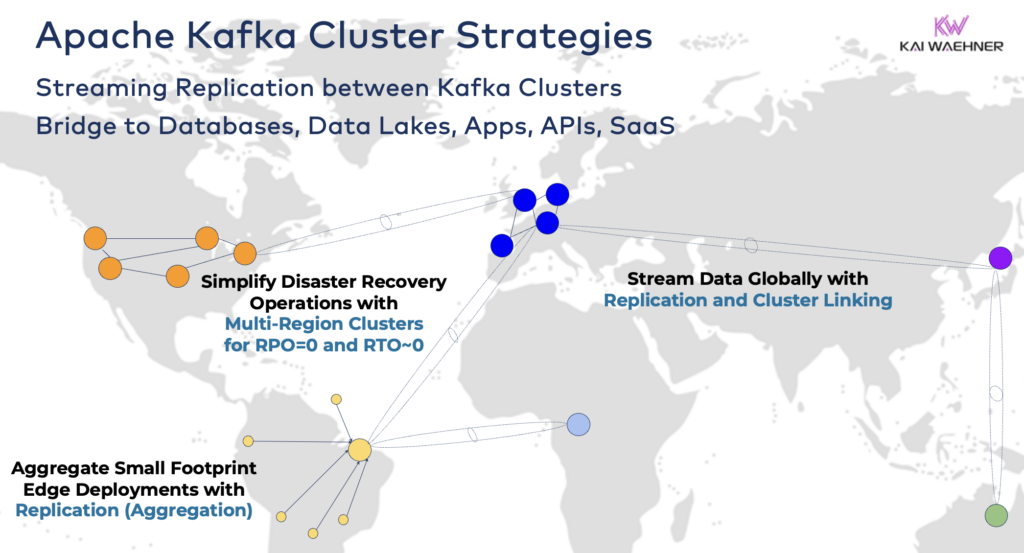
Puenteando Clústeres hibridos de Kafka
Estas opciones se pueden combinar. Por ejemplo, un broker único en el borde típicamente replica algunos datos curados a un centro de datos remoto. Los clústeres híbridos tienen diferentes arquitecturas dependiendo de cómo se conectan: conexiones a través de Internet público, enlace privado, emparejamiento de VPC, gateway de tránsito, etc.
Habiendo visto el desarrollo de Confluent Cloud a lo largo de los años, subestimé cuánto tiempo de ingeniería necesita ser gastado en seguridad y conectividad. Sin embargo, la falta de puentes de seguridad son los principales obstáculos para la adopción de un servicio de Kafka en la nube. Por lo tanto, no hay forma de evitar proporcionar varios puentes de seguridad entre clústeres de Kafka más allá de solo Internet público.
Incluso hay casos de uso en los que las organizaciones necesitan replicar datos desde el centro de datos a la nube, pero el servicio en la nube está no permitido iniciar la conexión. Confluent construyó una función específica, “enlace iniciado por la fuente”, para tales requisitos de seguridad donde la fuente (es decir, el clúster de Kafka local) siempre inicia la conexión, aunque los clústeres de Kafka en la nube estén consumiendo los datos:
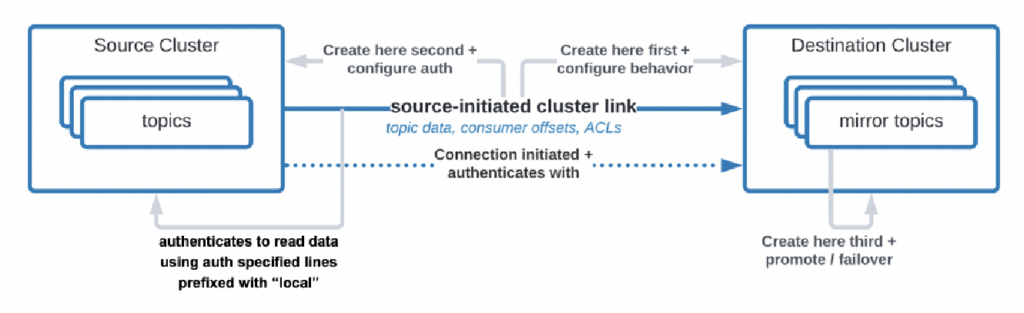 Fuente: Confluent
Fuente: Confluent
Como puedes ver, se complica rápidamente. Encuentra a los expertos adecuados para ayudarte desde el principio, no después de que ya hayas desplegado los primeros clústeres y aplicaciones.
Hace mucho tiempo, ya describí en una presentación detallada los patrones de arquitectura para implementaciones distribuidas, híbridas, en el borde y globales de Apache Kafka. Mira esa presentación y grabación de video para más detalles sobre las opciones de implementación y compensaciones.
RPO vs. RTO = Pérdida de Datos vs. Tiempo de Inactividad
RPO y RTO son dos KPI críticos que necesitas discutir antes de decidir sobre una estrategia de clúster de Kafka:
- RPO (Objetivo de Punto de Recuperación) es la cantidad máxima aceptable de pérdida de datos medida en tiempo, indicando con qué frecuencia deben ocurrir las copias de seguridad para minimizar la pérdida de datos.
- RTO (Objetivo de Tiempo de Recuperación) es la duración máxima aceptable del tiempo que se tarda en restaurar las operaciones comerciales después de una interrupción. Juntos, ayudan a las organizaciones a planificar sus estrategias de respaldo de datos y recuperación ante desastres para equilibrar el costo y el impacto operativo.
Si bien las personas a menudo comienzan con el objetivo de RPO = 0 y RTO = 0, rápidamente se dan cuenta de lo difícil (pero no imposible) que es lograr esto. Necesitas decidir cuánto dato puedes perder en un desastre. Necesitas un plan de recuperación ante desastres si ocurre uno. Los equipos legales y de cumplimiento tendrán que decirte si está bien perder algunos conjuntos de datos en caso de un desastre o no. Estos y muchos otros desafíos deben discutirse al evaluar tu estrategia de clúster Kafka.
La replicación entre clústeres Kafka con herramientas como MirrorMaker o Cluster Linking es asíncrona y RPO > 0. Solo un clúster Kafka extendido proporciona RPO = 0.
Clúster Kafka Extendidos: Cero Pérdida de Datos con Replicación Sincrónica a Través de Centros de Datos
La mayoría de las implementaciones con múltiples clústeres Kafka utilizan replicación asíncrona a través de centros de datos o nubes mediante herramientas como MirrorMaker o Confluent Cluster Linking. Esto es lo suficientemente bueno para la mayoría de los casos de uso. Pero en caso de un desastre, perderás algunos mensajes. El RPO es > 0.
Un clúster Kafka extendido despliega corredores Kafka de un solo clúster a través de tres centros de datos. La replicación es sincrónica (ya que así es como Kafka replica datos dentro de un clúster) y garantiza cero pérdida de datos (RPO = 0) – ¡incluso en caso de un desastre!
¿Por qué no deberías hacer siempre clústeres extendidos?
- Se requiere una latencia baja (<~50ms) y conexión estable entre los centros de datos.
- ¡Se necesitan tres (!) centros de datos! dos no son suficientes, ya que la mayoría (quórum) debe reconocer las escrituras y lecturas para garantizar la fiabilidad del sistema.
- Son difíciles de configurar, operar y monitorear y mucho más complicados que un clúster que se ejecuta en un solo centro de datos.
- El costo frente al valor no lo justifica en muchos casos de uso; durante un desastre real, la mayoría de las organizaciones y casos de uso tienen problemas más grandes que perder unos pocos mensajes (incluso si se trata de datos críticos como un pago o un pedido).
Para ser claros, en la nube pública, una región suele tener tres centros de datos (= zonas de disponibilidad). Por lo tanto, en la nube, depende de sus SLAs si una región en la nube cuenta como un clúster extendido o no. La mayoría de las ofertas de Kafka como servicio (SaaS) se implementan en un clúster extendido aquí.
Sin embargo, muchos escenarios de cumplimiento no consideran que un clúster de Kafka en una región en la nube sea suficiente para garantizar SLAs y continuidad empresarial en caso de desastre.
Confluent construyó un producto dedicado para resolver (algunos de) estos desafíos: Clústeres Multi-Región (MRC). Proporciona capacidades para realizar replicación síncrona y asíncrona dentro de un clúster de Kafka extendido.
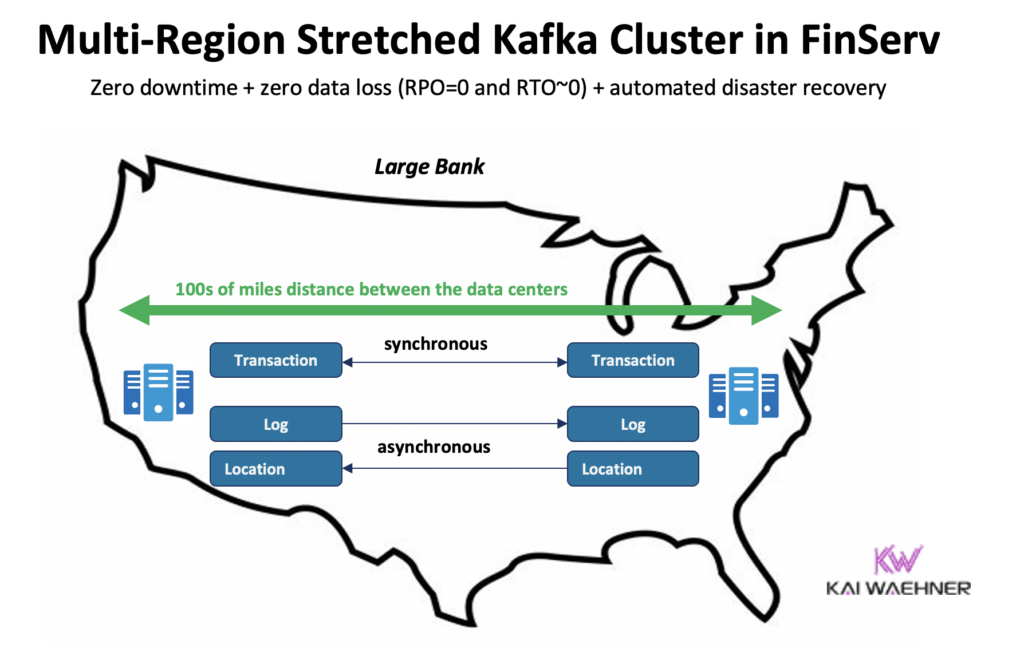
Por ejemplo, en un escenario de servicios financieros, MRC replica transacciones críticas de bajo volumen de forma síncrona pero registros de alto volumen de forma asíncrona:
- Maneja transacciones de ‘Pago’ que ingresan desde Estados Unidos Este y Estados Unidos Oeste con replicación totalmente síncrona
- La información de ‘Registro’ y ‘Ubicación’ en el mismo clúster se utiliza de forma asíncrona, optimizada para latencia
- Recuperación de desastres automatizada (cero tiempo de inactividad, cero pérdida de datos)
Más detalles sobre los clústeres de Kafka extendidos frente a la replicación activa-activa / activa-pasiva entre dos clústeres de Kafka en mi presentación global de Kafka.
Precios de las ofertas de Kafka en la nube (vs. Autoadministrado)
Las secciones anteriores explican por qué es necesario considerar diferentes arquitecturas de Kafka según los requisitos de su proyecto. Los clústeres de Kafka autoadministrados pueden configurarse según sea necesario. En la nube pública, las ofertas completamente administradas se ven diferentes (de la misma manera que cualquier otro SaaS completamente administrado). Los precios son diferentes porque los proveedores de SaaS necesitan configurar límites razonables. El proveedor debe proporcionar SLAs específicos.
El panorama de transmisión de datos incluye varias ofertas de Kafka en la nube. Aquí hay un ejemplo de las ofertas actuales en la nube de Confluent, que incluyen entornos multiinquilino y dedicados con diferentes SLAs, características de seguridad y modelos de costos.
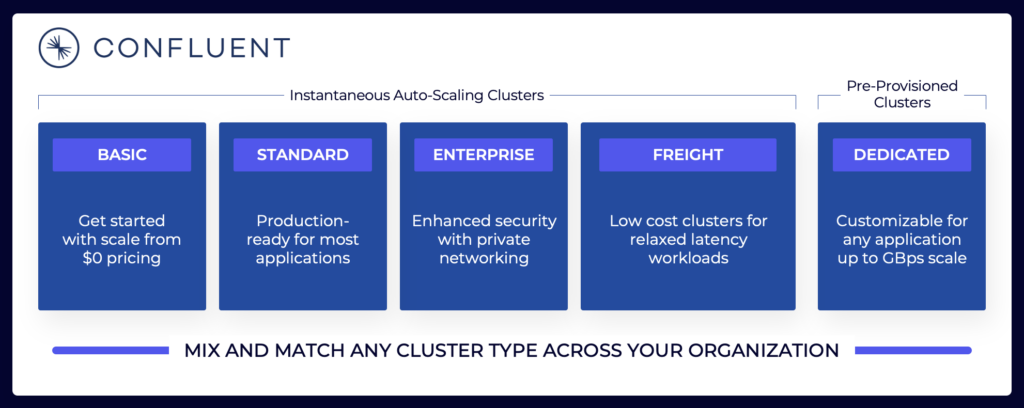 Origen: Confluent
Origen: Confluent
Asegúrate de evaluar y comprender los diversos tipos de clústeres de diferentes proveedores disponibles en la nube pública, incluyendo el TCO, los SLAs de tiempo de actividad proporcionados, los costos de replicación entre regiones o proveedores de nube, y así sucesivamente. Las brechas y limitaciones a menudo están intencionalmente ocultas en los detalles.
Por ejemplo, si utilizas Amazon Managed Streaming for Apache Kafka (MSK), debes tener en cuenta que los términos y condiciones establecen que “El compromiso del servicio no se aplica a ninguna falta de disponibilidad, suspensión o terminación … causada por el software del motor subyacente de Apache Kafka o Apache Zookeeper que provoca fallos en las solicitudes.”
Sin embargo, la fijación de precios y los SLAs de soporte son solo una pieza crítica de la comparación. Hay muchas “decisiones de construir vs. comprar” que debes tomar como parte de la evaluación de una plataforma de transmisión de datos.
Almacenamiento de Kafka: Almacenamiento escalonado y formato de tabla Iceberg para almacenar los datos solo una vez
Apache Kafka agregó Almacenamiento de Niveles para separar la computación y el almacenamiento. La capacidad permite arquitecturas empresariales más escalables, confiables y rentables. El Almacenamiento de Niveles para Kafka habilita un nuevo tipo de clúster de Kafka: Almacenar Petabytes de datos en el registro de compromiso de Kafka de manera rentable (como en su lago de datos) con marcas de tiempo y orden garantizado para retroceder en el tiempo y reprocesar datos históricos. KOR Financial es un buen ejemplo de uso de Apache Kafka como base de datos para persistencia a largo plazo.
Kafka habilita una Arquitectura de Desplazamiento a la Izquierda para almacenar datos solo una vez para conjuntos de datos operativos y analíticos:

Con esto en mente, piense nuevamente en los casos de uso que describí anteriormente para múltiples clústeres de Kafka. ¿Debería seguir replicando datos en lotes en reposo en la base de datos, lago de datos o casa del lago de un centro de datos o región en la nube a otro? No. Debería sincronizar los datos en tiempo real, almacenar los datos una vez (generalmente en un almacenamiento de objetos como Amazon S3), y luego conectar todos los motores analíticos como Snowflake, Databricks, Amazon Athena, Google Cloud BigQuery, y así sucesivamente a este formato de tabla estándar.
Historias de Éxito del Mundo Real para Múltiples Clústeres de Kafka
La mayoría de las organizaciones tienen múltiples clústeres de Kafka. Esta sección explora cuatro historias de éxito en diferentes industrias:
- Paypal (Servicios Financieros)– EE. UU.: Pagos instantáneos, prevención de fraudes.
- JioCinema (Telco/Media) – APAC: Integración de datos, análisis de flujo de clics, publicidad, personalización.
- Audi (Automotriz/Fabricación) – EMEA: Automóviles conectados con requisitos críticos y analíticos.
- New Relic (Software/Cloud) – EE. UU.: Observabilidad y gestión del rendimiento de aplicaciones (APM) en todo el mundo.
Paypal: Separación por Zona de Seguridad
PayPal es una plataforma de pago digital que permite a los usuarios enviar y recibir dinero en línea de forma segura y conveniente en todo el mundo en tiempo real. Esto requiere una infraestructura de Kafka escalable, segura y conforme.
Durante el Black Friday de 2022, el volumen de tráfico de Kafka alcanzó aproximadamente 1,3 billones de mensajes diarios. En la actualidad, PayPal cuenta con más de 85 clusters de Kafka, y en cada temporada de vacaciones amplían su infraestructura de Kafka para manejar el aumento del tráfico. La plataforma de Kafka continúa escalando sin problemas para soportar este crecimiento del tráfico sin impacto en su negocio.
Actualmente, la flota de Kafka de PayPal consta de más de 1,500 brokers que alojan más de 20,000 temas. Los eventos se replican entre los clusters, ofreciendo una disponibilidad del 99.99%.
Las implementaciones de clusters de Kafka están separadas en diferentes zonas de seguridad dentro de un centro de datos:
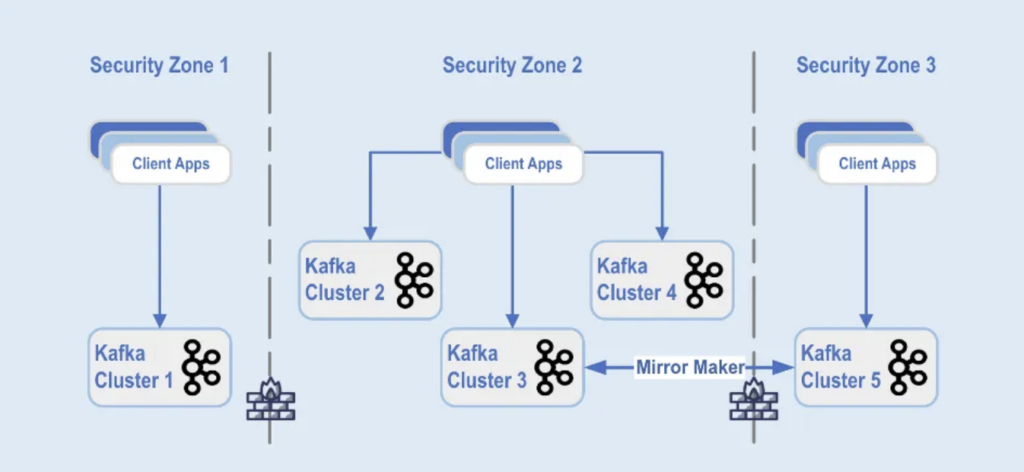 Origen: Paypal
Origen: Paypal
Los clústeres de Kafka se despliegan en estas zonas de seguridad, basados en la clasificación de datos y los requisitos empresariales. Se utiliza la replicación en tiempo real con herramientas como MirrorMaker (en este ejemplo, en ejecución en la infraestructura de Kafka Connect) o Confluent Cluster Linking (utilizando un enfoque más simple y menos propenso a errores utilizando directamente el protocolo de Kafka para la replicación) para reflejar los datos entre los centros de datos, lo que ayuda con la recuperación ante desastres y para lograr la comunicación entre zonas de seguridad.
JioCinema: Separación por Caso de Uso y Acuerdo de Nivel de Servicio
JioCinema es una plataforma de transmisión de video en rápido crecimiento en India. El servicio OTT de telecomunicaciones es conocido por su amplia oferta de contenido, que incluye deportes en vivo como la Indian Premier League (IPL) de cricket, un recién lanzado Anime Hub y planes integrales para cubrir eventos importantes como los Juegos Olímpicos de París 2024.
La arquitectura de datos aprovecha Apache Kafka, Flink y Spark para el procesamiento de datos, como se presentó en el Kafka Summit India 2024 en Bangalore:
 Origen: JioCinema
Origen: JioCinema
El streaming de datos desempeña un papel fundamental en diversos casos de uso para transformar las experiencias de usuario y la entrega de contenido. Más de diez millones de mensajes por segundo mejoran los análisis, las percepciones del usuario y los mecanismos de entrega de contenido.
Los casos de uso de JioCinema incluyen:
- Comunicación entre Servicios
- Clickstream/Análisis
- Rastreador de Anuncios
- Aprendizaje Automático y Personalización
Kushal Khandelwal, Jefe de Plataforma de Datos, Análisis y Consumo en JioCinema, explicó que no todos los datos son iguales y que las prioridades y los SLA varían según el caso de uso:
 Fuente: JioCinema
Fuente: JioCinema
El streaming de datos es un viaje. Al igual que muchas otras organizaciones en todo el mundo, JioCinema comenzó con un gran clúster de Kafka utilizando más de 1000 Temas de Kafka y más de 100,000 Particiones de Kafka para diversos casos de uso. Con el tiempo, una separación de preocupaciones regarding use cases and SLAs developed into multiple Kafka clusters:
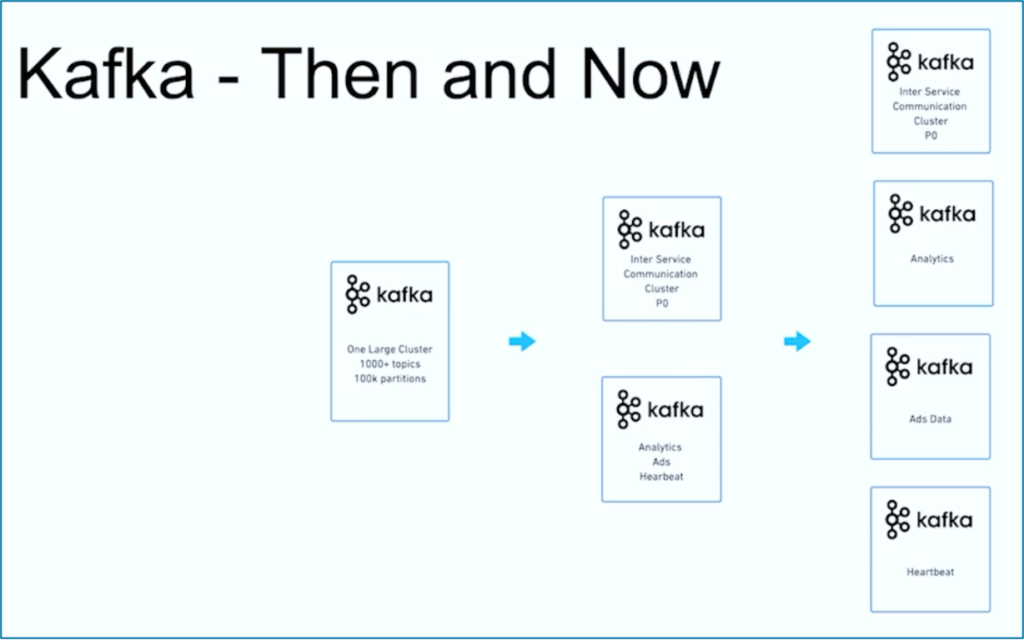 Fuente: JioCinema
Fuente: JioCinema
La historia de éxito de JioCinema muestra la evolución común de una organización de transmisión de datos. Ahora vamos a explorar otro ejemplo donde se implementaron desde el principio dos clusters de Kafka muy diferentes para un caso de uso.
Audi: Operaciones frente a Análisis para Autos Conectados
El fabricante de automóviles Audi proporciona autos conectados con tecnología avanzada que integra conectividad a internet y sistemas inteligentes. Los autos de Audi permiten navegación en tiempo real, diagnóstico remoto y entretenimiento mejorado en el automóvil. Estos vehículos están equipados con servicios de Audi Connect. Las características incluyen llamadas de emergencia, información de tráfico en línea e integración con dispositivos domésticos inteligentes, para mejorar la comodidad y seguridad de los conductores.
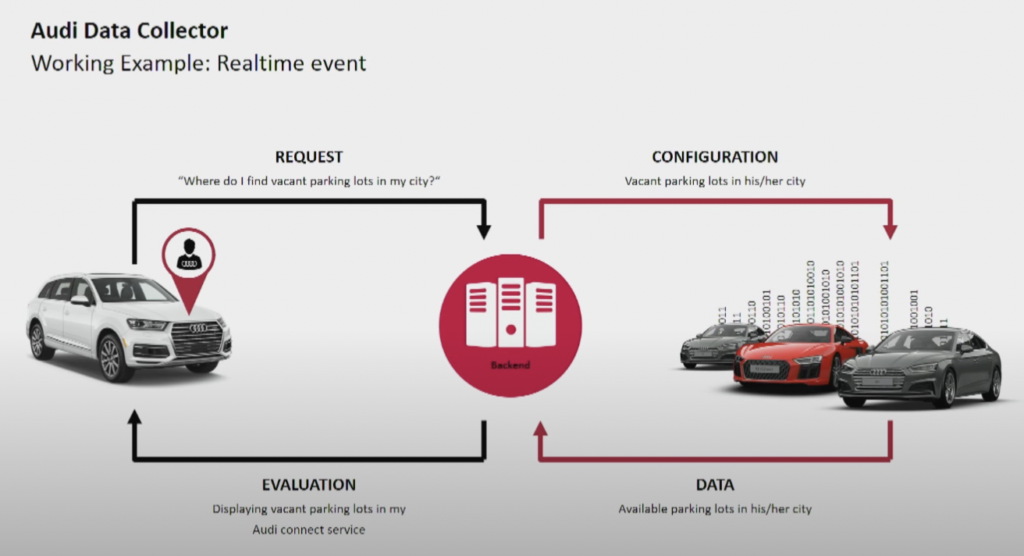 Fuente: Audi
Fuente: Audi
Audi presentó su arquitectura de autos conectados en el discurso principal de la Cumbre de Kafka de 2018. La arquitectura empresarial de Audi se basa en dos clusters de Kafka con SLAs y casos de uso muy diferentes.
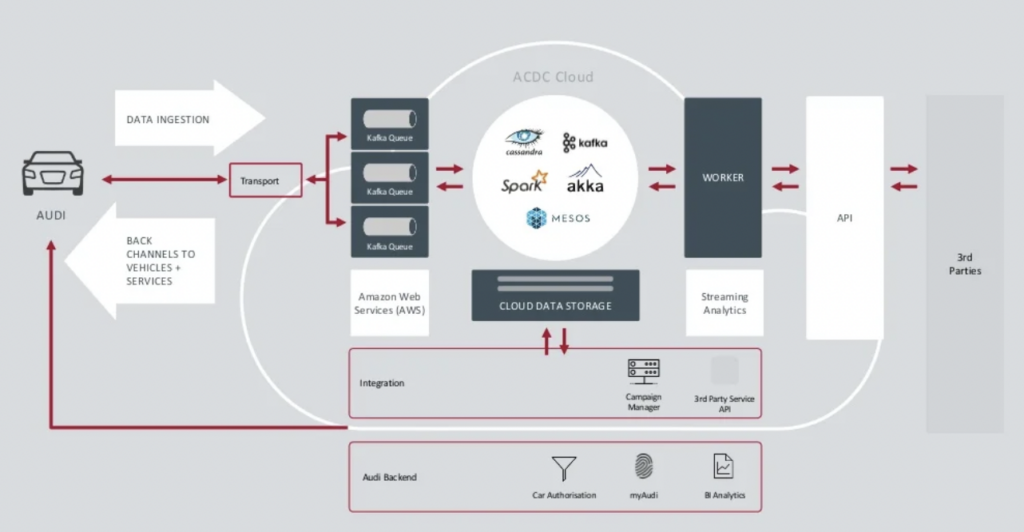 Fuente: Audi
Fuente: Audi
El clúster de ingestión de datos de Kafka es muy crítico. Necesita funcionar 24/7 a gran escala. Proporciona conectividad de última milla a millones de automóviles utilizando Kafka y MQTT. Los canales de retroalimentación del lado de TI hacia el vehículo ayudan con la comunicación de servicios y las actualizaciones por aire (OTA).
ACDC Cloud es el clúster de análisis de Kafka de la arquitectura de automóviles conectados de Audi. El clúster es la base de muchas cargas de trabajo analíticas, que procesan enormes volúmenes de datos de IoT y registros a gran escala con marcos de procesamiento por lotes como Apache Spark.
Esta arquitectura ya se presentó en 2018. El eslogan de Audi, “Progreso a través de la Tecnología”, muestra cómo la empresa aplicó nueva tecnología para la innovación mucho antes de que la mayoría de los fabricantes de automóviles desplegaran escenarios similares. Todos los datos de los sensores de los automóviles conectados se procesan en tiempo real y se almacenan para análisis e informes históricos.
New Relic: Observabilidad Multi-Nube a Nivel Mundial
New Relic es una plataforma de observabilidad basada en la nube que proporciona monitoreo de rendimiento en tiempo real y análisis para aplicaciones e infraestructura a clientes de todo el mundo.
Andrew Hartnett, VP de Ingeniería de Software en New Relic, explica cómo el streaming de datos es crucial para todo el modelo de negocio de New Relic:
“Kafka es nuestro sistema nervioso central. Es parte de todo lo que hacemos. La mayoría de los servicios en 110 equipos de ingeniería diferentes, con cientos de servicios, tocan Kafka de alguna manera, forma o modo en nuestra empresa, así que realmente es crítico para la misión. Lo que buscábamos era la capacidad de crecer, y Confluent Cloud proporcionó eso.”
New Relic ingirió hasta 7 mil millones de puntos de datos por minuto y está en camino de ingerir 2.5 exabytes de datos en 2023. A medida que New Relic expande sus estrategias de múltiples nubes, los equipos utilizarán Confluent Cloud para tener una vista unificada de todos los entornos.
“New Relic es multi-nube. Queremos estar donde están nuestros clientes. Queremos estar en esos mismos entornos, en esas mismas regiones, y queríamos tener nuestro Kafka allí con nosotros,” dice Artnett en un estudio de caso de Confluent.
Múltiples Clusters de Kafka son la norma, no una excepción
Las arquitecturas impulsadas por eventos y el procesamiento de flujos han existido durante décadas. La adopción crece con marcos de código abierto como Apache Kafka y Flink en combinación con servicios de nube totalmente gestionados. Cada vez más organizaciones luchan con la escala de su Kafka. La gobernanza de datos a nivel empresarial, el centro de excelencia, la automatización del despliegue y las operaciones, y las mejores prácticas de arquitectura empresarial ayudan a proporcionar con éxito el streaming de datos con múltiples clusters de Kafka para dominios de negocio independientes o colaborativos.
La existencia de múltiples clústeres de Kafka es la norma, no una excepción. Casos de uso como integración híbrida, recuperación ante desastres, migración o agregación permiten el streaming de datos en tiempo real en todas partes con los SLAs necesarios.
Source:
https://dzone.com/articles/apache-kafka-cluster-type-deployment-strategies