













Cada organización orientada a datos tiene carga de trabajo operativa y analítica. Surge un enfoque de lo mejor de cada uno con varias plataformas de datos, incluyendo soluciones de flujo de datos, lagos de datos, almacenes de datos y soluciones de lakehouse, así como servicios en la nube. Un marco de formato de tabla abierta como Apache Iceberg es esencial en la arquitectura empresarial para garantizar una gestión y compartición de datos confiable, una evolución sin problemas de esquemas, un manejo eficiente de conjuntos de datos a gran escala y un almacenamiento eficiente en costos, mientras brinda un fuerte soporte para transacciones ACID y consultas de viaje en el tiempo.
Este artículo explora tendencias del mercado; la adopción de marcos de formato de tabla como Iceberg, Hudi, Paimon, Delta Lake y XTable; y la estrategia de producto de algunos de los proveedores líderes de plataformas de datos, como Snowflake, Databricks (Apache Spark), Confluent (Apache Kafka/Flink), Amazon Athena y Google BigQuery.
¿Qué Es un Formato de Tabla Abierto para una Plataforma de Datos?
Un formato de tabla abierto ayuda a mantener la integridad de los datos, optimizar el rendimiento de las consultas y garantizar una comprensión clara de los datos almacenados dentro de la plataforma.
El formato de tabla abierto para plataformas de datos típicamente incluye una estructura bien definida con componentes específicos que aseguran que los datos estén organizados, accesibles y fácilmente consultables. Un formato de tabla típico contiene un nombre de tabla, nombres de columnas, tipos de datos, claves primarias y foráneas, índices y restricciones.
Este no es un concepto nuevo. Tu base de datos favorita de hace décadas — como Oracle, IBM DB2 (incluso en el mainframe) o PostgreSQL — utiliza los mismos principios. Sin embargo, los requisitos y desafíos cambiaron un poco para los almacenes de datos en la nube, los lagos de datos y las lakehouses en cuanto a escalabilidad, rendimiento y capacidades de consulta.
Beneficios de un “Formato de Tabla Lakehouse” Como Apache Iceberg
Cada parte de una organización se vuelve orientada a datos. La consecuencia son conjuntos de datos extensos, compartición de datos con productos de datos entre unidades de negocio y nuevas requisitos para procesar datos en tiempo casi real.
Apache Iceberg proporciona muchos beneficios para la arquitectura empresarial:
- Almacenamiento único: Los datos se almacenan una vez (provenientes de varias fuentes de datos), lo que reduce costos y complejidad
- Interoperabilidad: Acceso sin esfuerzos de integración desde cualquier motor de análisis
- Todos los datos: Unificar las cargas de trabajo operativas y analíticas (sistemas transaccionales, registros de big data/IoT/clickstream, APIs móviles, interfaces B2B de terceros, etc.)
- Independencia del proveedor: Trabajar con cualquier motor de análisis favorito (no importa si es en tiempo real cercano, por lotes o basado en API)
Apache Hudi y Delta Lake proporcionan las mismas características. Sin embargo, Delta Lake está principalmente impulsado por Databricks como un proveedor único.
Formato de Tabla e Interfaz de Catálogo
Es importante entender que las discusiones sobre Apache Iceberg o marcos de formato de tablas similares incluyen dos conceptos: el formato de tabla y la interfaz de catálogo! Como usuario final de la tecnología, necesitas ambos!
El proyecto Apache Iceberg implementa el formato pero solo proporciona una especificación (pero no la implementación) para el catálogo:
- El formato de tabla define cómo se organiza, almacena y gestiona los datos dentro de una tabla.
- La interfaz de catálogo gestiona los metadatos de las tablas y proporciona una capa de abstracción para acceder a las tablas en un data lake.
La documentación de Apache Iceberg explora los conceptos en mucho más detalle, basada en este diagrama:
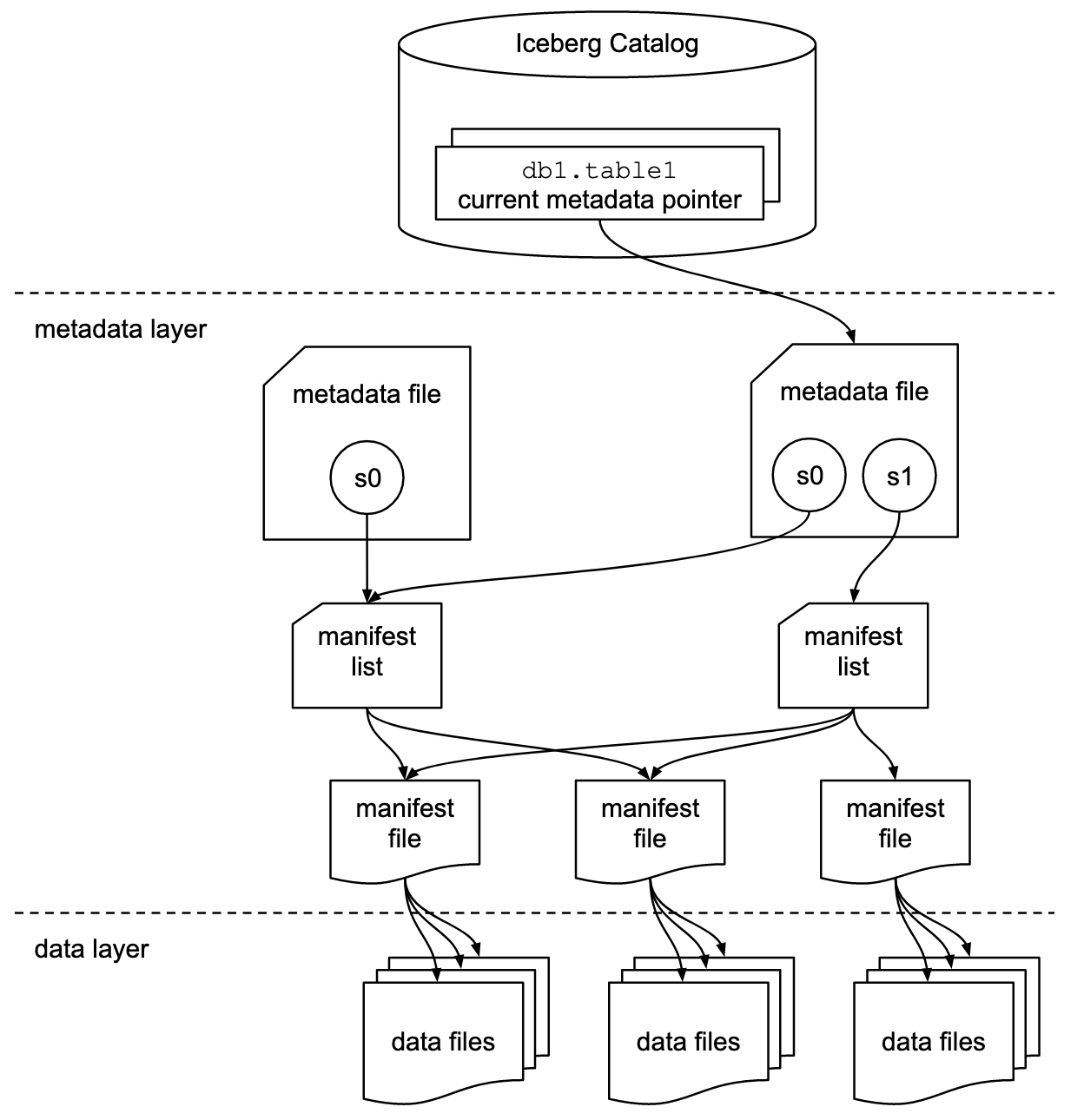
Las organizaciones utilizan varias implementaciones para la interfaz de catálogo de Iceberg. Cada una se integra con diferentes almacenes de metadatos y servicios. Las implementaciones clave incluyen:
- Catálogo Hadoop: Usa el Sistema de Archivos Distribuido de Hadoop (HDFS) u otros sistemas de archivos compatibles para almacenar metadatos. Adecuado para entornos que ya utilizan Hadoop.
- Catálogo Hive: Se integra con el Metastore de Apache Hive para gestionar los metadatos de las tablas. Ideal para usuarios que utilizan Hive para su gestión de metadatos.
- Catálogo AWS Glue: Usa el Catálogo de Datos de AWS Glue para el almacenamiento de metadatos. Diseñado para usuarios que operan dentro del ecosistema de AWS.
- Catálogo REST: Proporciona una interfaz RESTful para operaciones de catálogo a través de HTTP. Permite la integración con servicios de metadatos personalizados o de terceros.
- Catálogo Nessie: Utiliza el Proyecto Nessie, que ofrece una experiencia similar a Git para la gestión de datos.
El impulso y la creciente adopción de Apache Iceberg motivan a muchos proveedores de plataformas de datos a implementar su propio catálogo Iceberg. Discuto algunas estrategias en la sección inferior sobre estrategias de proveedores de plataformas de datos y proveedores en la nube, incluyendo Polaris de Snowflake, Unity de Databricks y Tableflow de Confluent.
Soporte de Clase Primaria para Iceberg vs. Conector Iceberg
Por favor note que soportar Apache Iceberg (o Hudi/Delta Lake) significa mucho más que simplemente proporcionar un conector e integración con el formato de tabla a través de API. Los proveedores y servicios en la nube se diferencian por características avanzadas como el mapeo automático entre formatos de datos, SLAs críticos, capacidad de viajar en el tiempo, interfaces de usuario intuitivas, y así sucesivamente.
Veamos un ejemplo: Integración entre Apache Kafka y Iceberg. Ya se han implementado varios conectores Kafka Connect. Sin embargo, aquí están los beneficios de usar una integración de clase primaria con Iceberg (por ejemplo, Tableflow de Confluent) en comparación con solo usar un conector Kafka Connect:
- Sin configuración de conector
- Sin consumo a través de conector
- Mantenimiento integrado (compresión, recolección de basura, gestión de instantáneas)
- Evolución automática de esquemas
- Sincronización de servicio de catálogo externo
- Operaciones más simples (en una solución SaaS completamente gestionada, es sin servidor y no requiere ninguna escala ni operaciones por parte del usuario final)
Beneficios similares se aplican a otras plataformas de datos y posibles integraciones de primer nivel en comparación con proporcionar simples conectores.
Formato de Tabla Abierto para un Data Lake/Lakehouse utilizando Apache Iceberg, Apache Hudi y Delta Lake
El objetivo general de los marcos de formato de tablas como Apache Iceberg, Apache Hudi y Delta Lake es mejorar la funcionalidad y confiabilidad de los data lakes abordando desafíos comunes asociados con la administración de datos a gran escala. Estos marcos ayudan a:
- Mejorar la administración de datos
- Facilitar un manejo más fácil de la ingesta, almacenamiento y recuperación de datos en data lakes.
- Permitir una organización y almacenamiento de datos eficiente, que soporte un mejor rendimiento y escalabilidad.
- Garantizar la consistencia de los datos
- Proporcionar mecanismos para transacciones ACID, asegurando que los datos se mantengan consistentes y confiables incluso durante operaciones de lectura y escritura concurrentes.
- Soporte para evolución de esquema
- Permitir cambios en el esquema de datos (como agregar, renombrar o eliminar columnas) sin interrumpir los datos existentes o requerir migraciones complejas.
- Optimizar el rendimiento de las consultas
- Implementar estrategias avanzadas de indexación y particionado para mejorar la velocidad y eficiencia de las consultas de datos.
- Habilitar una gestión eficiente de metadatos para manejar grandes conjuntos de datos y consultas complejas de manera efectiva.
- Mejorar la gobernanza de datos
- Proporcionar herramientas para una mejor rastreo y gestión de la linaje de datos, versionado y auditoría, lo cual es crucial para mantener la calidad y el cumplimiento de los datos.
Al abordar estos objetivos, marcos de formato de tabla como Apache Iceberg, Apache Hudi y Delta Lake ayudan a las organizaciones a construir lagos de datos y lakehouses más robustos, escalables y confiables. Ingenieros de datos, científicos de datos y analistas de negocio aprovechan analíticas, AI/ML, o herramientas de informe/visualización sobre el formato de tabla para gestionar y analizar grandes volúmenes de datos.
Comparación de Apache Iceberg, Hudi, Paimon y Delta Lake
No haré una comparación de los marcos de formato de tabla Apache Iceberg, Apache Hudi, Apache Paimon y Delta Lake aquí. Muchos expertos ya escribieron sobre esto. Cada marco de formato de tabla tiene fuerzas y beneficios únicos. Pero se requieren actualizaciones todos los meses debido a la rápida evolución e innovación, añadiendo nuevas mejoras y capacidades dentro de estos marcos.
Aquí hay un resumen de lo que veo en varias publicaciones de blogs sobre las cuatro opciones:
- Apache Iceberg: Se destaca en la evolución de esquemas y particiones, gestión eficiente de metadatos y amplia compatibilidad con varios motores de procesamiento de datos.
- Apache Hudi: Es el más adecuado para la ingesta de datos en tiempo real y actualizaciones, con fuertes capacidades de captura de cambios de datos y versionado de datos.
- Apache Paimon: Un formato de lago que permite construir una arquitectura de lakehouse en tiempo real con Flink y Spark para operaciones de flujo y lote.
- Delta Lake: Proporciona transacciones ACID robustas, aplicación de esquemas y características de viaje en el tiempo, lo que lo hace ideal para mantener la calidad e integridad de los datos.
Un punto de decisión clave podría ser que Delta Lake no está impulsado por una comunidad amplia como Iceberg y Hudi, sino principalmente por Databricks como un solo proveedor detrás de él.
Apache XTable como Marco Interoperable de Tablas Cruzadas que admite Iceberg, Hudi y Delta Lake
Los usuarios tienen muchas opciones. XTable, antes conocida como OneTable, es otra framework de tablas en incubación bajo la licencia de código abierto de Apache para interoperar de manera fluida entre tablas cruzadas de Apache Hudi, Delta Lake y Apache Iceberg.
Apache XTable:
- Proporciona interoperabilidad omnidireccional entre tablas de formatos de lakehouse.
- Es no un nuevo formato o separado. Apache XTable proporciona abstracciones y herramientas para la traducción de metadatos de formatos de tablas de lakehouse.
Quizás Apache XTable sea la respuesta para proporcionar opciones para plataformas de datos específicas y proveedores en la nube, mientras aún ofrece integración y interoperabilidad simple.
Pero tenga cuidado: Una envoltura superior sobre diferentes tecnologías no es una bala de plata. Vimos esto hace años cuando apareció Apache Beam. Apache Beam es un modelo unificado de código abierto y un conjunto de SDK específicos de lenguaje para definir y ejecutar flujos de trabajo de ingesta y procesamiento de datos. Soporta una variedad de motores de procesamiento de streams, como Flink, Spark y Samza. El impulsor principal detrás de Apache Beam es Google, lo que permite la migración de flujos de trabajo en Google Cloud Dataflow. Sin embargo, las limitaciones son enormes, ya que una envoltura así necesita encontrar el menor común denominador de las características soportadas. Y la principal ventaja de la mayoría de los marcos es el 20% que no entra en tal envoltura. Por estas razones, por ejemplo, Kafka Streams no admite Apache Beam porque habría requerido demasiadas limitaciones de diseño.
Adopción de Mercado de Marcos de Formato de Tablas
En primer lugar, aún estamos en las etapas iniciales. Estamos aún en el disparador de la innovación en términos del Ciclo de Hype de Gartner, acercándonos a la cima de expectativas infladas. La mayoría de las organizaciones todavía están evaluando, pero no han adoptado estos formatos de tablas en producción a través de la organización aún.
Flashback: La Guerra de Contenedores de Kubernetes contra Mesosphere contra Cloud Foundry
El debate sobre Apache Iceberg me recuerda a la guerra de contenedores hace unos años. El término “Guerra de Contenedores” se refiere a la competencia y rivalidad entre diferentes tecnologías y plataformas de contenedorización en el ámbito del desarrollo de software e infraestructura de TI.
Las tres tecnologías competidoras eran Kubernetes, Mesosphere y Cloud Foundry. Aquí es donde se dirigió:

Cloud Foundry y Mesosphere fueron pioneros, pero Kubernetes aún así ganó la batalla. ¿Por qué? Nunca entendí todas las detalles técnicos y diferencias. Al final, si los tres marcos son bastante similares, se trata de:
- Adopción comunitaria
- Momento adecuado del lanzamiento de características
- Buena mercadotecnia
- Suerte
- Y algunos otros factores
Pero es bueno para la industria del software tener un marco de código abierto líder para construir soluciones y modelos de negocio en lugar de tres que compiten.
Presente: Las guerras de formatos de tablas de Apache Iceberg vs. Hudi vs. Delta Lake
Obviamente, Google Trends no es una evidencia estadística ni una investigación sofisticada. Pero lo he utilizado mucho en el pasado como una herramienta intuitiva, simple y gratuita para analizar tendencias del mercado. Por lo tanto, también utilicé esta herramienta para ver si las búsquedas en Google coinciden con mi experiencia personal de la adopción de mercado de Apache Iceberg, Hudi y Delta Lake (Apache XTable es aún demasiado pequeño para ser añadido):
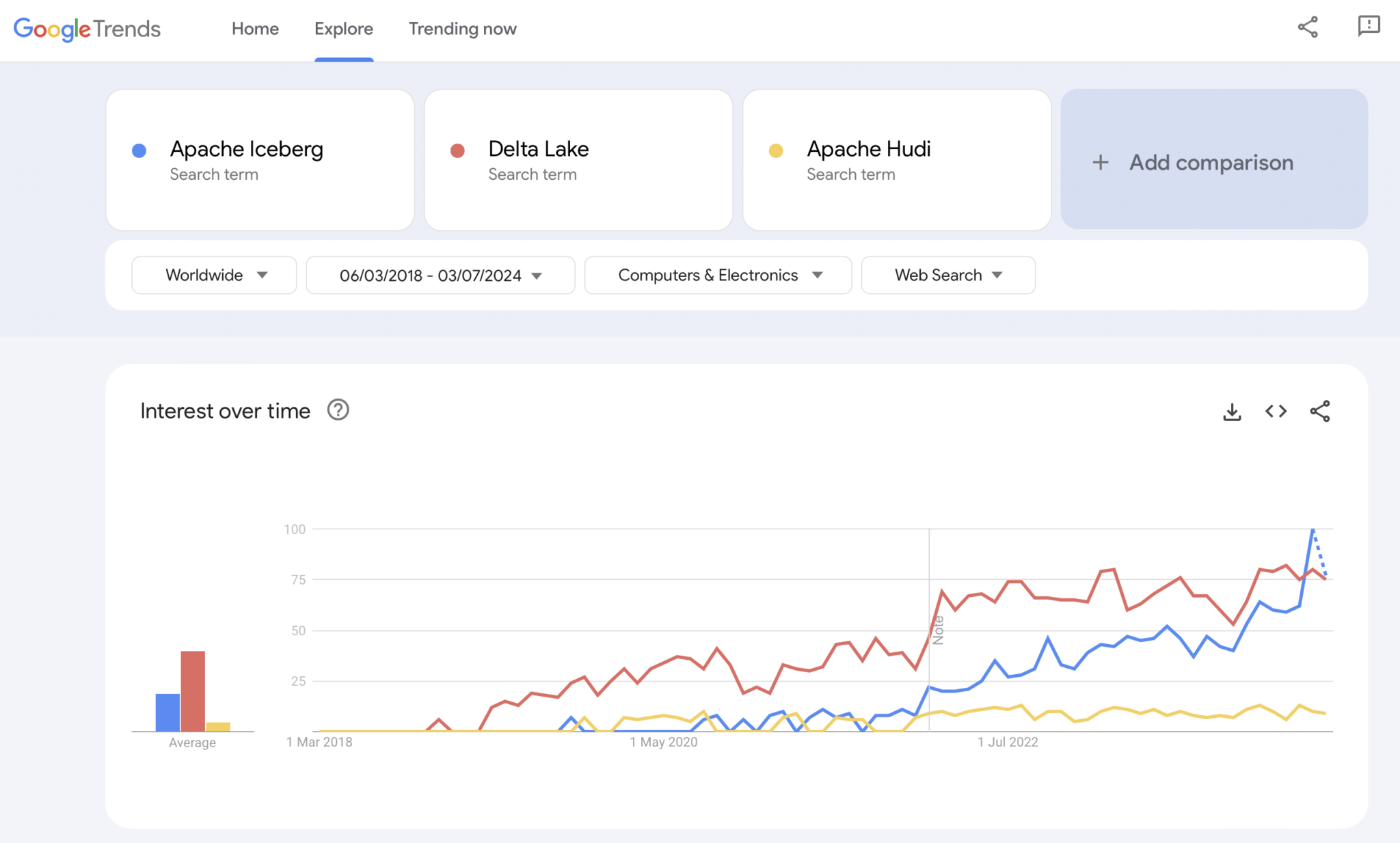
Claramente vemos un patrón similar al que mostraron las guerras de contenedores hace unos años. No tengo ni idea adónde va esto. Y si alguna tecnología gana, o si los marcos se diferencian lo suficiente para demostrar que no hay una bala de plata, el futuro nos lo mostrará.
Opinión personal, ¿verdad? Creo que Apache Iceberg ganará la carrera. ¿Por qué? No puedo discutir con razones técnicas. Solo veo que muchos clientes de todas las industrias hablan de él cada vez más. Y cada vez más proveedores comienzan a respaldarlo. Pero veremos. En realidad, a mí no me importa quién gane. Sin embargo, al igual que las guerras de contenedores, creo que es bueno tener un estándar único y que los proveedores se diferencien con características en torno a él, como ocurre con Kubernetes.
Pero con esto en mente, exploremos la estrategia actual de las plataformas de datos líderes y proveedores de servicios en la nube regarding el soporte de formatos de tablas en sus plataformas y servicios en la nube.
Estrategias de Proveedores de Plataformas de Datos y Cloud para Apache Iceberg
No haré especulaciones en esta sección. La evolución de los marcos de trabajo de formatos de tablas avanza rápidamente, y las estrategias de los proveedores cambian rápidamente. Por favor, consulte los sitios web de los proveedores para obtener la información más reciente. Pero aquí está el status quo sobre las estrategias de las plataformas de datos y proveedores de servicios en la nube regarding el soporte e integración de Apache Iceberg.
- Snowflake:
- Soporta Apache Iceberg desde hace ya algún tiempo
- Añadiendo mejoras en la integración y nuevas características regularmente
- Opciones de almacenamiento interno y externo (con compensaciones) como el almacenamiento de Snowflake o Amazon S3
- Ha anunciado Polaris, una implementación de catálogo de código abierto para Iceberg, con compromiso de respaldar una integración bidireccional comunitaria y sin dependencia de proveedores
- Databricks:
-
Se centra en Delta Lake como formato de tabla y (ahora de código abierto) Unity como catálogo
Adquirió Tabular, la empresa líder detrás de Apache Iceberg
Estrategia futura poco clara de apoyo a la interfaz de Iceberg abierto (en ambas direcciones) o solo para alimentar datos en su plataforma de lakehouse y tecnologías como Delta Lake y Unity Catalog - Confluent:
-
Integra Apache Iceberg como ciudadano de primera categoría en su plataforma de flujo de datos (el producto se llama Tableflow)
Convierte un Topic de Kafka y los metadatos de esquema relacionados (es decir, contrato de datos) en una tabla de Iceberg
- Más plataformas de datos y motores de análisis de código abierto:
- La lista de tecnologías y servicios en la nube que admiten Iceberg crece cada mes
- Algunos ejemplos: Apache Spark, Apache Flink, ClickHouse, Dremio, Starburst utilizando Trino (anteriormente PrestoSQL), Cloudera utilizando Impala, Imply utilizando Apache Druid, Fivetran
- Proveedores de servicios en la nube (AWS, Azure, Google Cloud, Alibaba):
- Diferentes estrategias e integraciones, pero todos los proveedores de servicios en la nube aumentan el soporte de Iceberg en sus servicios estos días, por ejemplo:
- Almacenamiento de objetos: Amazon S3, Azure Data Lake Storage (ALDS), Google Cloud Storage
- Catálogos: Específicos de la nube como AWS Glue Catalog o independientes del proveedor como Project Nessie o Hive Catalog
- Análisis: Amazon Athena, Azure Synapse Analytics, Microsoft Fabric, Google BigQuery
- Diferentes estrategias e integraciones, pero todos los proveedores de servicios en la nube aumentan el soporte de Iceberg en sus servicios estos días, por ejemplo:
Arquitectura de Corrimiento a la Izquierda con Kafka, Flink e Iceberg para Unificar Cargas de Trabajo Operativas y Analíticas
La arquitectura de corrimiento a la izquierda acerca el procesamiento de datos a la fuente de datos, utilizando tecnologías de streaming de datos en tiempo real como Apache Kafka y Flink para procesar datos en movimiento directamente después de su ingestión. Este enfoque reduce la latencia y mejora la consistencia y calidad de los datos.
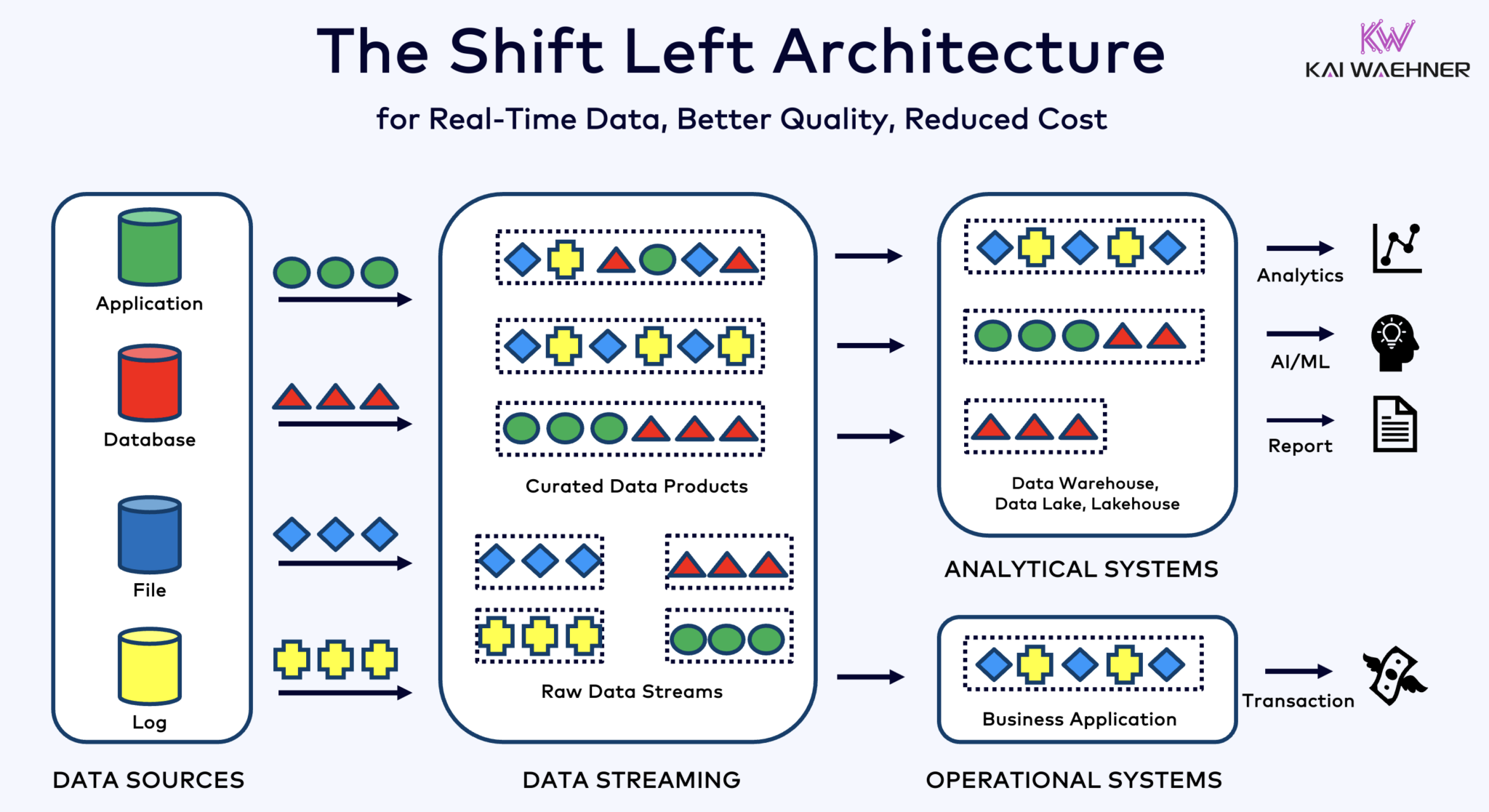
A diferencia de ETL y ELT, que involucran procesamiento por lotes con los datos almacenados en reposo, la arquitectura de corrimiento a la izquierda permite la captura y transformación de datos en tiempo real. Se alinea con el concepto de cero-ETL al hacer que los datos sean inmediatamente utilizables. Pero a diferencia de cero-ETL, desplazar el procesamiento de datos al lado izquierdo de la arquitectura empresarial evita una arquitectura compleja y difícil de mantener, con muchas conexiones punto a punto.
La arquitectura de desplazamiento a la izquierda también reduce la necesidad de ETL inverso al asegurar que los datos son accionables en tiempo real para ambos sistemas operativos y analíticos. En general, esta arquitectura mejora la frescura de los datos, reduce costos y acelera el tiempo de salida al mercado para aplicaciones basadas en datos. Aprende más sobre este concepto en mi publicación de blog sobre “La Arquitectura de Desplazamiento a la Izquierda.”
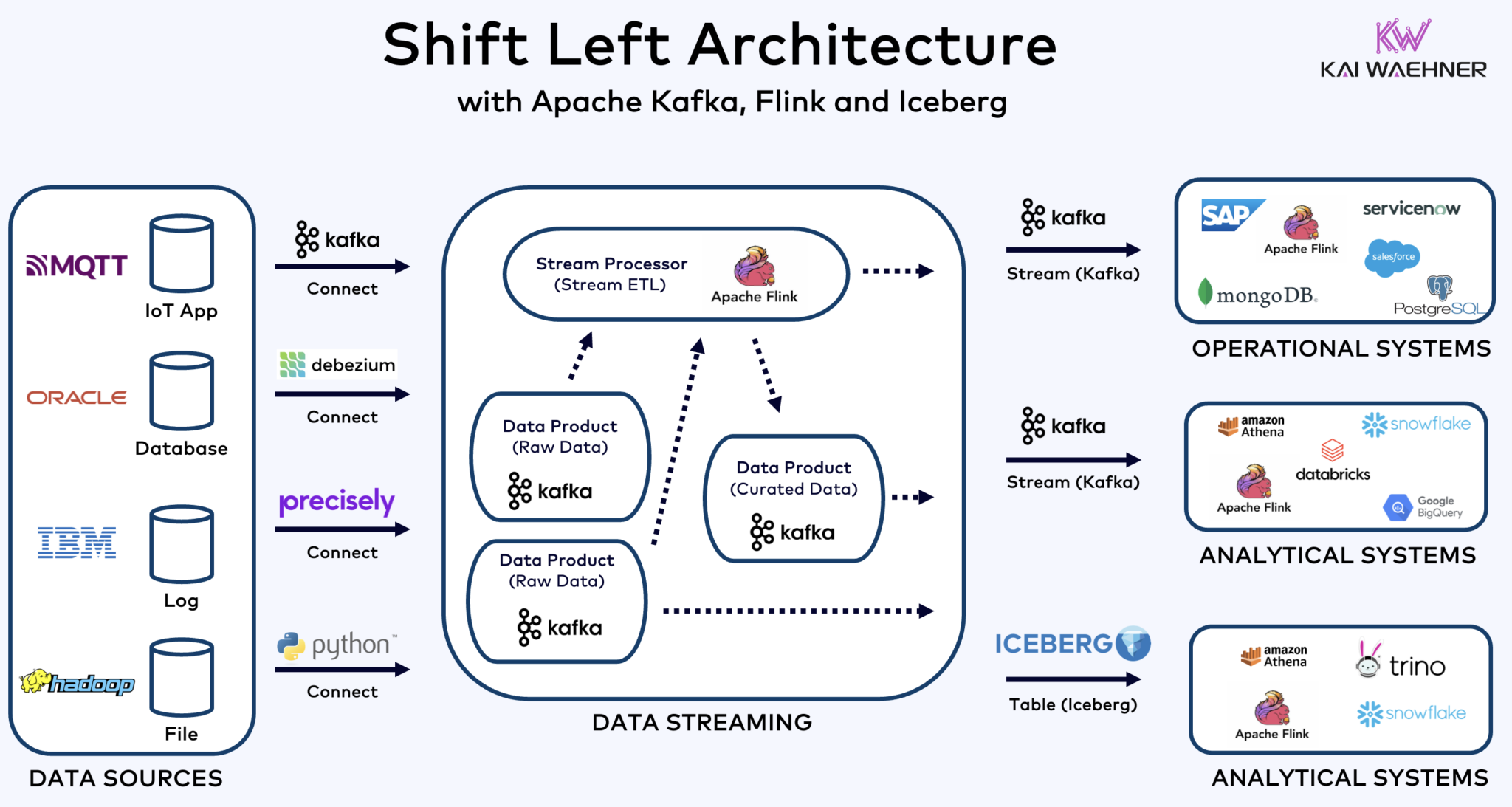
Apache Iceberg como Formato de Tabla Abierto y Catálogo para la Compartición Segura de Datos a Través de Motores de Análisis
Un formato de tabla abierto y un catálogo introducen enormes beneficios en la arquitectura empresarial:
- Interoperabilidad
- Libertad de elección de los motores de análisis
- Tiempo de salida al mercado más rápido
- Costo reducido
Apache Iceberg parece estar convirtiéndose en el estándar de facto entre proveedores y proveedores en la nube. Sin embargo, aún se encuentra en una etapa temprana y tecnologías competidoras y de envoltura como Apache Hudi, Apache Paimon, Delta Lake y Apache XTable también están tratando de ganar impulso.
El iceberg y otros formatos de tabla abierta no son solo una gran victoria para el almacenamiento único e integración con múltiples plataformas de análisis/datos/AI/ML como Snowflake, Databricks, Google BigQuery, entre otros, sino también para la unificación de las cargas de trabajo operativas y analíticas utilizando el flujo de datos con tecnologías como Apache Kafka y Flink. La arquitectura shift left representa un beneficio significativo para reducir esfuerzos, mejorar la calidad y consistencia de los datos, y habilitar aplicaciones e insights en tiempo real en lugar de por lotes.
Finalmente, si aún te preguntas cuáles son las diferencias entre el flujo de datos y los lakehouses (y cómo se complementan entre sí), echa un vistazo a este video de diez minutos:
¿Cuál es tu estrategia de formato de tabla? ¿Qué tecnologías y servicios en la nube conectas? ¡Conéctémonos en LinkedIn y discutámoslo!
Source:
https://dzone.com/articles/apache-iceberg-open-table-format-lakehouses-data-streaming