













Jeder, der heute im DevOps-Bereich arbeitet, würde wahrscheinlich zustimmen, dass die Kodifizierung von Ressourcen es einfacher macht, zu beobachten, zu verwalten und zu automatisieren. Die meisten Ingenieure würden jedoch auch anerkennen, dass diese Transformation eine neue Reihe von Herausforderungen mit sich bringt.
Vielleicht ist die größte Herausforderung bei IaC-Operationen Abweichungen — ein Szenario, in dem sich Laufzeitumgebungen von ihren IaC-definierten Zuständen entfernen, was ein schwelendes Problem schafft, das ernsthafte langfristige Auswirkungen haben könnte. Diese Diskrepanzen untergraben die Konsistenz von Cloud-Umgebungen, was zu potenziellen Problemen mit der Zuverlässigkeit und Wartbarkeit der Infrastruktur und sogar zu erheblichen Sicherheits- und Compliance-Risiken führen kann.
Um diese Risiken zu minimieren, klassifizieren die Verantwortlichen für die Verwaltung dieser Umgebungen Abweichungen als hochpriorisierte Aufgabe (und als großen Zeitfresser) für Infrastruktur-Betriebsteams.
Dies hat zur zunehmenden Akzeptanz von Drift-Erkennungstools geführt, die Diskrepanzen zwischen der gewünschten Konfiguration und dem tatsächlichen Zustand der Infrastruktur kennzeichnen. Obwohl sie effektiv darin sind, Abweichungen zu erkennen, sind diese Lösungen darauf beschränkt, Warnungen auszugeben und Code-Diffs hervorzuheben, ohne tiefere Einblicke in die Ursachen zu bieten.
Warum die Drift-Erkennung nicht ausreicht
Der aktuelle Stand der Drift-Erkennung ergibt sich aus der Tatsache, dass Drifts außerhalb der etablierten CI/CD-Pipeline auftreten und oft auf manuelle Anpassungen, API-gesteuerte Updates oder Notfallkorrekturen zurückzuführen sind. Infolgedessen hinterlassen diese Änderungen normalerweise keine Prüfspur in der IaC-Ebene, was einen blinden Fleck schafft, der die Werkzeuge darauf beschränkt, lediglich Codeabweichungen zu kennzeichnen. Das lässt die Plattform-Ingenieurteams spekulieren über die Ursprünge des Drifts und wie er am besten angegangen werden kann.
Diese Unklarheit macht die Behebung von Drift zu einer riskanten Aufgabe. Schließlich könnte das automatische Zurücksetzen von Änderungen, ohne deren Zweck zu verstehen – ein häufiger Standardansatz – eine Büchse der Pandora öffnen und eine Kaskade von Problemen auslösen.
Ein Risiko besteht darin, dass dies legitime Anpassungen oder Optimierungen rückgängig machen könnte, was potenziell Probleme wieder einführen könnte, die bereits gelöst wurden, oder den Betrieb eines wertvollen Drittanbietertools stören könnte.
Nehmen wir zum Beispiel eine manuelle Korrektur, die außerhalb des üblichen IaC-Prozesses angewendet wurde, um ein plötzliches Produktionsproblem anzugehen. Bevor solche Änderungen zurückgesetzt werden, ist es wichtig, sie zu kodifizieren, um ihre Absicht und Auswirkungen zu bewahren, oder das Risiko einzugehen, ein Heilmittel vorzuschreiben, das sich als schlimmer als die Krankheit herausstellen könnte.
Erkennung trifft Kontext
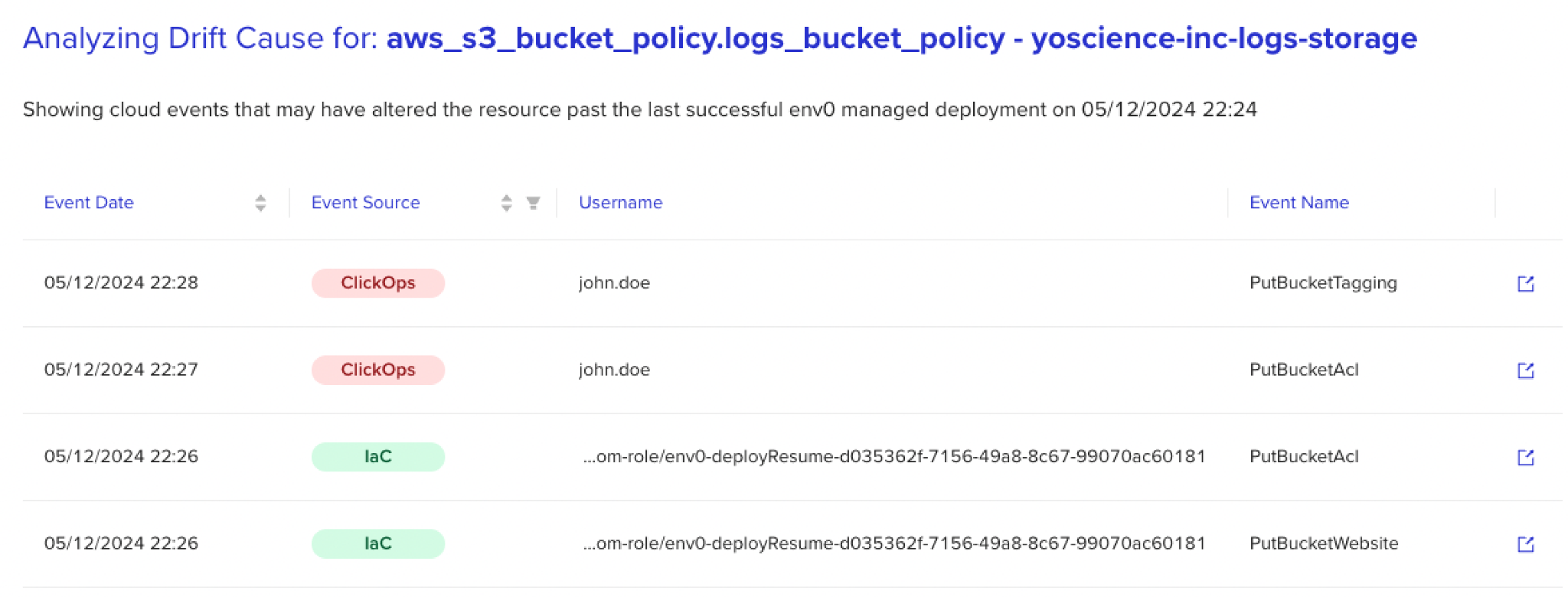
Das Ringen von Organisationen mit diesen Dilemmas hat das Konzept von ‚Drift Cause‚ inspiriert. Dieses Konzept verwendet KI-unterstützte Logik, um durch große Ereignisprotokolle zu filtern und zusätzlichen Kontext für jeden Drift bereitzustellen, Änderungen bis zu ihrem Ursprung zurückzuverfolgen — und nicht nur ‚was‘, sondern auch ‚wer‘, ‚wann‘ und ‚warum‘ aufzudecken.
Diese Fähigkeit, nicht einheitliche Protokolle in großen Mengen zu verarbeiten und driftbezogene Daten zu sammeln, kehrt den Rekonziliationsprozess um. Um dies zu veranschaulichen, lass mich dich zurück zu dem Szenario führen, das ich zuvor erwähnt habe, und ein Bild davon zeichnen, wie du einen Drift-Alarm von deiner Erkennungslösung erhältst — diesmal mit zusätzlichem Kontext.
Jetzt, mit den Informationen, die von Drift Cause bereitgestellt werden, kannst du nicht nur über den Drift informiert sein, sondern auch näher heranzoomen, um herauszufinden, dass die Änderung von John um 2 Uhr morgens vorgenommen wurde, genau zu der Zeit, als die Anwendung einen Verkehrsanstieg bewältigte.
Ohne diese Informationen könntest du annehmen, dass der Drift problematisch ist und die Änderung rückgängig machen, was möglicherweise kritische Operationen stört und zu nachgelagerten Ausfällen führt.
Mit dem zusätzlichen Kontext hingegen kannst du die Zusammenhänge erkennen, dich an John wenden, bestätigen, dass die Korrektur ein unmittelbares Problem behoben hat, und entscheiden, dass sie nicht blind rekonziliert werden sollte. Darüber hinaus kannst du mithilfe dieses Kontexts auch vorausschauend denken und Anpassungen an der Konfiguration einführen, um die Skalierbarkeit zu verbessern und zu verhindern, dass das Problem erneut auftritt.
Dies ist ein einfaches Beispiel, aber ich hoffe, es zeigt gut den Nutzen von zusätzlichem Kontext zur Ursachenanalyse – ein Element, das beim Drift Detection lange Zeit fehlte, obwohl es in anderen Bereichen der Fehlersuche und Problembehebung Standard ist. Das Ziel ist natürlich, Teams dabei zu helfen, nicht nur zu verstehen, was sich geändert hat, sondern auch warum es sich geändert hat, um sie zu befähigen, mit Zuversicht die beste Vorgehensweise zu wählen.
Jenseits des IaC-Managements
Aber zusätzlicher Kontext für Drift, so wichtig er auch sein mag, ist nur ein Teil eines viel größeren Puzzles. Die Verwaltung großer Cloud-Flotten mit codierten Ressourcen bringt mehr als nur Drift-Herausforderungen mit sich, insbesondere im großen Maßstab. Aktuelle IaC-Managementtools der nächsten Generation sind effektiv bei der Bewältigung des Ressourcenmanagements, aber der Bedarf an größerer Transparenz und Kontrolle in unternehmensweiten Umgebungen führt zu neuen Anforderungen und treibt ihre unvermeidliche Evolution voran.
Eine Richtung, in die ich sehe, dass sich diese Evolution bewegt, ist das Cloud-Asset-Management (CAM), das alle Ressourcen in einer Cloud-Umgebung verfolgt und verwaltet – unabhängig davon, ob sie über IaC, APIs oder manuelle Operationen bereitgestellt wurden – und eine einheitliche Ansicht der Assets bietet, um Organisationen bei der Konfiguration, Abhängigkeiten und Risiken zu verstehen, die alle für die Einhaltung, Kostenoptimierung und operative Effizienz unerlässlich sind.
Während das IaC-Management sich auf die operativen Aspekte konzentriert, betont das Cloud Asset Management die Sichtbarkeit und das Verständnis der Cloud-Position. Als zusätzliche Beobachtungsebene überbrückt es die Kluft zwischen codierten Workflows und ad-hoc-Änderungen und bietet einen umfassenden Überblick über die Infrastruktur.
1+1 wird drei ergeben
Die Kombination von IaC-Management und CAM ermöglicht es Teams, Komplexität mit Klarheit und Kontrolle zu verwalten. Da sich das Jahresende nähert, beginnt die ‚Vorhersagesaison‘ – hier ist meine. Nachdem ich den größten Teil des letzten Jahrzehnts damit verbracht habe, eine der beliebteren (wenn ich das so sagen darf) IaC-Management-Plattformen aufzubauen und zu verfeinern, sehe ich dies als die natürliche Entwicklung unserer Branche: die Kombination von IaC-Management, Automatisierung und Governance mit erweiterter Sichtbarkeit in nicht-codierten Assets.
Diese Synergie wird meiner Meinung nach das Fundament für eine bessere Art von Cloud-Governance-Rahmen bilden – einen, der präziser, anpassungsfähiger und zukunftssicherer ist. Inzwischen ist es fast selbstverständlich, dass IaC der Grundpfeiler des Cloud-Infrastrukturmanagements ist. Dennoch müssen wir auch anerkennen, dass nicht alle Assets jemals codiert werden. In solchen Fällen kann eine End-to-End-Infrastrukturmanagementlösung nicht auf nur die IaC-Ebene beschränkt sein.
Die nächste Grenze besteht also darin, Teams dabei zu helfen, die Sichtbarkeit in nicht-codierte Assets zu erweitern, um sicherzustellen, dass die Infrastruktur sich nahtlos weiterentwickelt und performt – eine ausgeglichene Abweichung nach der anderen und darüber hinaus.
Source:
https://dzone.com/articles/the-problem-of-drift-detection-and-drift-cause-analysis