













In diesem praktischen Labor von ScyllaDB University erfahren Sie, wie Sie den ScyllaDB CDC Source Connector verwenden, um die zeilenbezogenen Änderungsereignisse in den Tabellen eines ScyllaDB-Clusters auf einen Kafka-Server zu pushen.
Was ist ScyllaDB CDC?
Zusammenfassend ist Change Data Capture (CDC) eine Funktion, die Ihnen nicht nur die Möglichkeit gibt, den aktuellen Zustand einer Datenbanktabelle abzufragen, sondern auch die Historie aller Änderungen an der Tabelle abzufragen. CDC ist ab ScyllaDB Enterprise 2021.1.1 und ScyllaDB Open Source 4.3 produktionsbereit (GA).
In ScyllaDB ist CDC optional und auf einer pro-Tabelle-Basis aktiviert. Die Historie der Änderungen an einer CDC-aktivierten Tabelle wird in einer separaten, damit verbundenen Tabelle gespeichert.
Sie können CDC bei der Erstellung oder Änderung einer Tabelle mithilfe der CDC-Option aktivieren, zum Beispiel:
CREATE TABLE ks.t (pk int, ck int, v int, PRIMARY KEY (pk, ck, v)) WITH cdc = {'enabled':true};ScyllaDB CDC Source Connector
Der ScyllaDB CDC Source Connector ist ein Quell-Connector, der Zeilenänderungen in den Tabellen eines ScyllaDB-Clusters erfasst. Es handelt sich um einen Debezium-Connector, der mit Kafka Connect (ab Kafka 2.6.0) kompatibel ist. Der Connector liest das CDC-Protokoll für angegebene Tabellen und erzeugt Kafka-Nachrichten für jede Zeilen-INSERT, UPDATE oder DELETE-Operation. Der Connector ist fehlertolerant und versucht im Falle eines Fehlers, Daten von Scylla erneut zu lesen. Er speichert regelmäßig die aktuelle Position im ScyllaDB CDC-Protokoll unter Verwendung der Kafka Connect-Offset-Nachverfolgung. Jede erzeugte Kafka-Nachricht enthält Informationen über die Quelle, wie z.B. das Zeitstempel und den Tabellennamen.
Hinweis: Stand der Dinge gibt es keine Unterstützung für Sammeltypen (LIST, SET, MAP) und UDTs – Spalten mit diesen Typen werden in den generierten Nachrichten ausgelassen. Bleiben Sie auf dem Laufenden über diesen Verbesserungsantrag und andere Entwicklungen im GitHub-Projekt.
Confluent und Kafka Connect
Confluent ist eine umfassende Datenstromplattform, die es Ihnen ermöglicht, Daten einfach als kontinuierliche, Echtzeit-Datenströme zu erfassen, zu speichern und zu verwalten. Sie erweitert die Vorteile von Apache Kafka um enterprise-grade Funktionen. Confluent erleichtert es, moderne, ereignisgesteuerte Anwendungen zu erstellen und einen universellen Datenfluss zu gewinnen, der Skalierbarkeit, Leistung und Zuverlässigkeit unterstützt.
Kafka Connect ist ein Werkzeug zur skalierbaren und zuverlässigen Datenübertragung zwischen Apache Kafka und anderen Datensystemen. Es erleichtert die Definition von Connectoren, die große Datenmengen in und aus Kafka verschieben. Es kann ganze Datenbanken oder Metriken von Anwendungsservern in Kafka-Themen aufnehmen, wodurch die Daten für die Streaming-Verarbeitung mit geringer Latenz verfügbar gemacht werden.
Kafka Connect umfasst zwei Arten von Connectoren:
- Quellconnector: Quellconnectoren nehmen ganze Datenbanken auf und streamen Tabellenaktualisierungen in Kafka-Themen. Quellconnectoren können auch Metriken von Anwendungsservern erfassen und die Daten in Kafka-Themen speichern, wodurch die Daten für die Streaming-Verarbeitung mit geringer Latenz verfügbar gemacht werden.
- Senkconnector: Senkconnectoren liefern Daten von Kafka-Themen an Sekundärindizes, wie Elasticsearch, oder Batch-Systeme, wie Hadoop, für die Offline-Analyse.
Dienst-Einrichtung mit Docker
In dieser Laborarbeit verwenden Sie Docker.
Stellen Sie bitte sicher, dass Ihre Umgebung die folgenden Voraussetzungen erfüllt:
- Docker für Linux, Mac oder Windows.
- Hinweis: Das Ausführen von ScyllaDB in Docker wird nur zur Bewertung und zum Ausprobieren von ScyllaDB empfohlen.
- ScyllaDB Open Source. Für die besten Leistungen wird eine reguläre Installation empfohlen.
- 8 GB RAM oder mehr für Kafka- und ScyllaDB-Dienste.
- docker-compose
- Git
ScyllaDB Installieren und Tabelle Initialisieren
Zuerst starten Sie einen drei-Knoten-ScyllaDB-Cluster und erstellen eine Tabelle mit aktivierter CDC.
Wenn Sie dies noch nicht getan haben, laden Sie das Beispiel von git herunter:
git clone https://github.com/scylladb/scylla-code-samples.git cd scylla-code-samples/CDC_Kafka_LabDies ist die docker-compose-Datei, die Sie verwenden werden. Sie startet einen drei-Knoten-ScyllaDB-Cluster:
version: "3"
services:
scylla-node1:
container_name: scylla-node1
image: scylladb/scylla:5.0.0
ports:
- 9042:9042
restart: always
command: --seeds=scylla-node1,scylla-node2 --smp 1 --memory 750M --overprovisioned 1 --api-address 0.0.0.0
scylla-node2:
container_name: scylla-node2
image: scylladb/scylla:5.0.0
restart: always
command: --seeds=scylla-node1,scylla-node2 --smp 1 --memory 750M --overprovisioned 1 --api-address 0.0.0.0
scylla-node3:
container_name: scylla-node3
image: scylladb/scylla:5.0.0
restart: always
command: --seeds=scylla-node1,scylla-node2 --smp 1 --memory 750M --overprovisioned 1 --api-address 0.0.0.0Starten Sie den ScyllaDB-Cluster:
docker-compose -f docker-compose-scylladb.yml up -dWarten Sie eine Minute oder so, und überprüfen Sie, ob der ScyllaDB-Cluster hochgefahren ist und im Normalstatus ist:
docker exec scylla-node1 nodetool statusAls Nächstes verwenden Sie cqlsh, um mit ScyllaDB zu interagieren. Erstellen Sie einen Keyspace und eine Tabelle mit aktivierter CDC und fügen Sie einer Tabelle eine Zeile hinzu:
docker exec -ti scylla-node1 cqlsh
CREATE KEYSPACE ks WITH replication = {'class': 'NetworkTopologyStrategy', 'replication_factor' : 1};
CREATE TABLE ks.my_table (pk int, ck int, v int, PRIMARY KEY (pk, ck, v)) WITH cdc = {'enabled':true};
INSERT INTO ks.my_table(pk, ck, v) VALUES (1, 1, 20);
exit[guy@fedora cdc_test]$ docker-compose -f docker-compose-scylladb.yml up -d
Creating scylla-node1 ... done
Creating scylla-node2 ... done
Creating scylla-node3 ... done
[guy@fedora cdc_test]$ docker exec scylla-node1 nodetool status
Datacenter: datacenter1
=======================
Status=Up/Down
|/ State=Normal/Leaving/Joining/Moving
-- Adresse Last Token Besitzt Host-ID Rack
UN 172.19.0.3 ? 256 ? 4d4eaad4-62a4-485b-9a05-61432516a737 rack1
UN 172.19.0.2 496 KB 256 ? bec834b5-b0de-4d55-b13d-a8aa6800f0b9 rack1
UN 172.19.0.4 ? 256 ? 2788324e-548a-49e2-8337-976897c61238 rack1
Note: Non-system keyspaces don't have the same replication settings, effective ownership information is meaningless
[guy@fedora cdc_test]$ docker exec -ti scylla-node1 cqlsh
Connected to at 172.19.0.2:9042.
[cqlsh 5.0.1 | Cassandra 3.0.8 | CQL spec 3.3.1 | Native protocol v4]
Use HELP for help.
cqlsh> CREATE KEYSPACE ks WITH replication = {'class': 'NetworkTopologyStrategy', 'replication_factor' : 1};
cqlsh> CREATE TABLE ks.my_table (pk int, ck int, v int, PRIMARY KEY (pk, ck, v)) WITH cdc = {'enabled':true};
cqlsh> INSERT INTO ks.my_table(pk, ck, v) VALUES (1, 1, 20);
cqlsh> exit
[guy@fedora cdc_test]$ Confluent-Einrichtung und Connector-Konfiguration
Zum Starten eines Kafka-Servers verwenden Sie die Confluent-Plattform, die eine benutzerfreundliche Web-GUI zur Verfolgung von Themen und Nachrichten bietet. Die Confluent-Plattform stellt eine docker-compose.yml-Datei bereit, um die Dienste einzurichten.
Hinweis: So würden Sie Apache Kafka in der Produktion nicht verwenden. Das Beispiel ist nur für Schulungszwecke und Entwicklung nützlich. Holen Sie sich die Datei:
wget -O docker-compose-confluent.yml https://raw.githubusercontent.com/confluentinc/cp-all-in-one/7.3.0-post/cp-all-in-one/docker-compose.ymlAls nächstes laden Sie den ScyllaDB CDC-Connector herunter:
wget -O scylla-cdc-plugin.jar https://github.com/scylladb/scylla-cdc-source-connector/releases/download/scylla-cdc-source-connector-1.0.1/scylla-cdc-source-connector-1.0.1-jar-with-dependencies.jarFüge den ScyllaDB CDC Connector zum Plugin-Verzeichnis des Confluent Connect-Dienstes mithilfe einer Docker-Volumes hinzu, indem du docker-compose-confluent.yml bearbeitest, um die folgenden zwei Zeilen hinzuzufügen, wobei du das Verzeichnis durch das Verzeichnis deines scylla-cdc-plugin.jar Datei ersetzt.
image: cnfldemos/cp-server-connect-datagen:0.5.3-7.1.0
hostname: connect
container_name: connect
+ volumes:
+ - <directory>/scylla-cdc-plugin.jar:/usr/share/java/kafka/plugins/scylla-cdc-plugin.jar
depends_on:
- broker
- schema-registryStarte die Confluent-Dienste:
docker-compose -f docker-compose-confluent.yml up -dWarte eine Minute oder so, dann greife auf http://localhost:9021 für die Confluent Web-GUI zu.
Füge den ScyllaConnector über das Confluent-Dashboard hinzu:
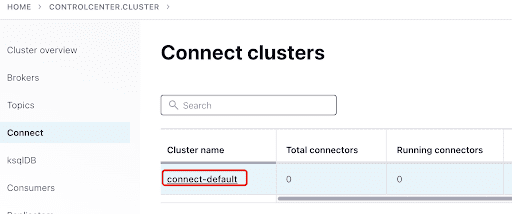
Füge den Scylla Connector hinzu, indem du auf das Plugin klickst:
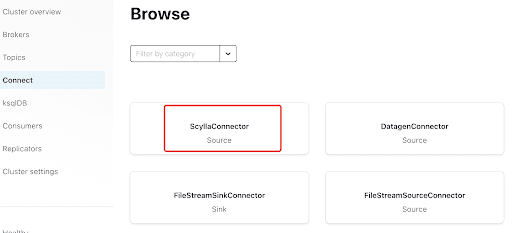
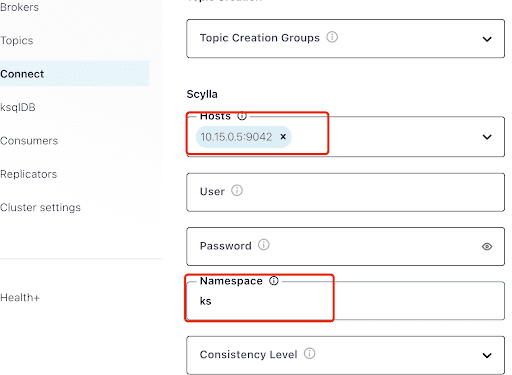
Trage in die “Hosts” die IP-Adresse eines der Scylla-Nodes ein (die du im Ausgabebereich des nodetool status Befehls sehen kannst) und Port 9042, den der ScyllaDB-Dienst abhört.
Die “Namespace” ist der Keyspace, den du zuvor in ScyllaDB erstellt hast.
Beachte, dass es eine Minute oder so dauern kann, bis ks.my_table erscheint:
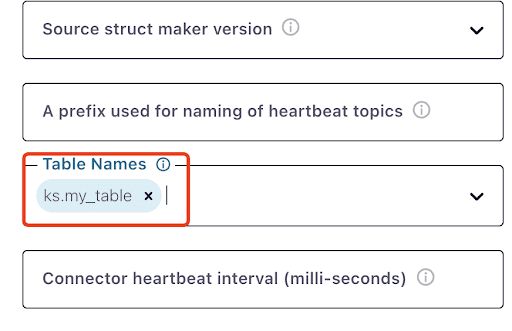
Teste Kafka-Nachrichten
Du kannst sehen, dass MyScyllaCluster.ks.my_table der von dem ScyllaDB CDC Connector erstellte Topic ist.
Überprüfe nun die Kafka-Nachrichten über das Topics-Panel:
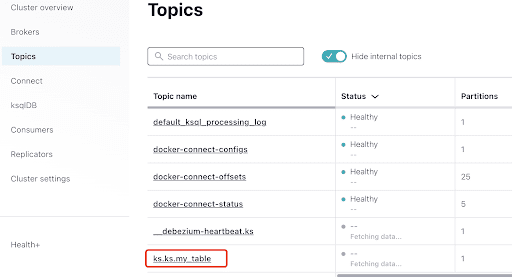
Wähle den Topic aus, der dem gleichen Keyspace und Tabellenname entspricht, die du in ScyllaDB erstellt hast:
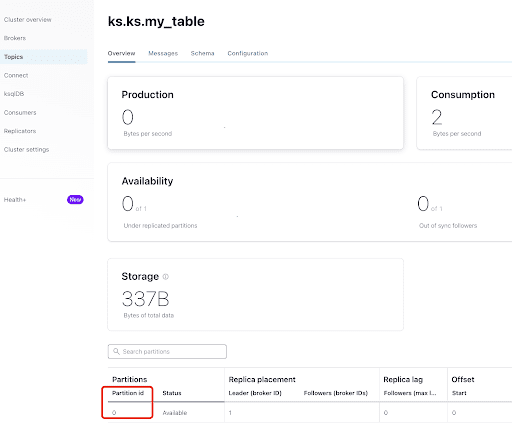
Aus dem Tab “Übersicht” kannst du die Topic-Info sehen. Unten wird angezeigt, dass dieser Topic sich auf Partition 0 befindet.
A partition is the smallest storage unit that holds a subset of records owned by a topic. Each partition is a single log file where records are written to it in an append-only fashion. The records in the partitions are each assigned a sequential identifier called the offset, which is unique for each record within the partition. The offset is an incremental and immutable number maintained by Kafka.
Wie Sie bereits wissen, werden die ScyllaDB CDC-Nachrichten an den ks.my_table Topic gesendet, und die Partition-ID des Topics ist 0. Wechseln Sie als Nächstes zur Registerkarte „Messages“ und geben Sie die Partition-ID 0 in das Feld „offset“ ein:
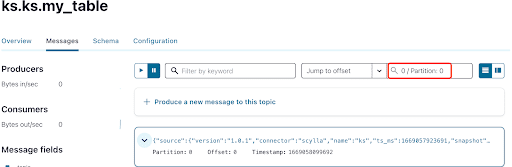
Aus der Ausgabe der Kafka-Topic-Nachrichten ist ersichtlich, dass das ScyllaDB-Tabelle INSERT-Ereignis und die Daten vom Scylla CDC Source Connector in Kafka-Nachrichten übertragen wurden. Klicken Sie auf die Nachricht, um die vollständigen Nachrichtendetails anzuzeigen:
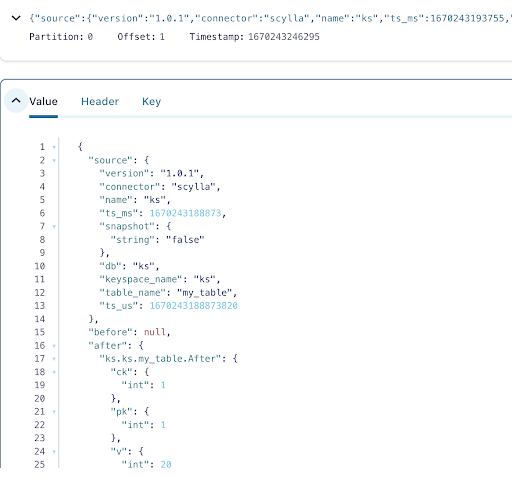
Die Nachricht enthält den ScyllaDB-Tabellennamen und den Keyspacename mit der Zeit sowie den Datenzustand vor und nach der Aktion. Da es sich um eine Einfügemarke handelt, ist die Daten vor dem Einfügen null.
Fügen Sie als Nächstes eine weitere Zeile in die ScyllaDB-Tabelle ein:
docker exec -ti scylla-node1 cqlsh
INSERT INTO ks.my_table(pk, ck, v) VALUES (200, 50, 70);Jetzt in Kafka, warten Sie einige Sekunden und Sie können die Details der neuen Nachricht sehen:
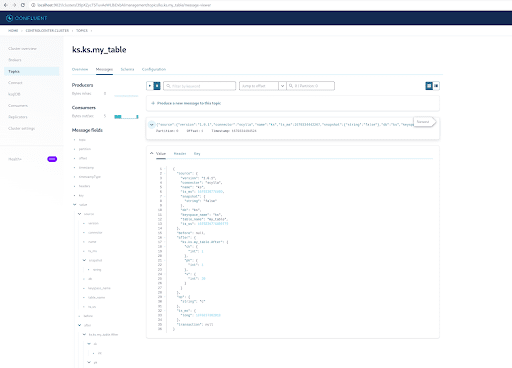
Aufräumen
Sobald Sie mit diesem Labor fertig sind, können Sie die Docker-Container und -Images anhalten und entfernen.
Um eine Liste aller Container-IDs anzuzeigen:
docker container ls -aqAnschließend können Sie die Container, die Sie nicht mehr verwenden, anhalten und entfernen:
docker stop <ID_or_Name>
docker rm <ID_or_Name>Später, wenn Sie das Labor erneut ausführen möchten, können Sie die Schritte befolgen und wie zuvor docker-compose verwenden.
Zusammenfassung
Mit dem CDC Source Connector, einem Kafka-Plugin kompatibel mit Kafka Connect, können Sie alle ScyllaDB-Tabellenzeilenänderungen (INSERT, UPDATE oder DELETE) erfassen und diese Ereignisse in Kafka-Nachrichten umwandeln. Anschließend können Sie die Daten von anderen Anwendungen verbrauchen oder mit Kafka andere Vorgänge durchführen.
Source:
https://dzone.com/articles/change-data-capture-apache-kafka-and-scylladb