













Der Autor hat den Free and Open Source Fund ausgewählt, um im Rahmen des Write for DOnations-Programms eine Spende zu erhalten.
Einführung
Flask ist ein leichtgewichtiges Python-Web-Framework, das nützliche Werkzeuge und Funktionen für die Erstellung von Webanwendungen in der Python-Sprache bereitstellt. SQLAlchemy ist ein SQL-Toolkit, das effizienten und leistungsstarken Datenbankzugriff für relationale Datenbanken bietet. Es bietet Möglichkeiten zur Interaktion mit mehreren Datenbank-Engines wie SQLite, MySQL und PostgreSQL. Es gewährt Zugriff auf die SQL-Funktionalitäten der Datenbank. Und es bietet auch einen Objekt-Relationen-Mapper (ORM), mit dem Sie Abfragen erstellen und Daten mithilfe einfacher Python-Objekte und -Methoden verarbeiten können. Flask-SQLAlchemy ist eine Flask-Erweiterung, die die Verwendung von SQLAlchemy mit Flask vereinfacht, indem sie Ihnen Werkzeuge und Methoden zur Verfügung stellt, um mit Ihrer Datenbank in Ihren Flask-Anwendungen über SQLAlchemy zu interagieren.
In diesem Tutorial verwenden Sie Flask und Flask-SQLAlchemy, um ein Mitarbeiterverwaltungssystem mit einer Datenbank zu erstellen, die eine Tabelle für Mitarbeiter enthält. Jeder Mitarbeiter wird eine eindeutige ID, einen Vornamen, einen Nachnamen, eine eindeutige E-Mail, einen Ganzzahlenwert für sein Alter, ein Datum für den Tag, an dem er dem Unternehmen beigetreten ist, und einen booleschen Wert haben, um zu bestimmen, ob ein Mitarbeiter derzeit aktiv oder außerhalb des Büros ist.
Sie werden die Flask-Shell verwenden, um eine Tabelle abzufragen und Tabellensätze basierend auf einem Spaltenwert (z. B. einer E-Mail) zu erhalten. Sie werden Mitarbeiterdatensätze unter bestimmten Bedingungen abrufen, wie zum Beispiel nur aktive Mitarbeiter oder eine Liste von außerhalb des Büros befindlichen Mitarbeitern. Sie werden die Ergebnisse nach einem Spaltenwert ordnen und Abfrageergebnisse zählen und begrenzen. Schließlich verwenden Sie die Paginierung, um eine bestimmte Anzahl von Mitarbeitern pro Seite in einer Webanwendung anzuzeigen.
Voraussetzungen
-
Eine lokale Python-3-Programmierumgebung. Befolgen Sie das Tutorial für Ihre Distribution in der So installieren und richten Sie eine lokale Programmierumgebung für Python 3 ein -Serie. In diesem Tutorial nennen wir unser Projektverzeichnis
flask_app. -
Ein Verständnis grundlegender Flask-Konzepte wie Routen, Ansichtsfunktionen und Vorlagen. Wenn Sie mit Flask nicht vertraut sind, schauen Sie sich Wie man Ihre erste Webanwendung mit Flask und Python erstellt und Wie man Vorlagen in einer Flask-Anwendung verwendet an.
-
Ein Verständnis grundlegender HTML-Konzepte. Sie können unsere Tutorialreihe Wie man eine Website mit HTML erstellt für Hintergrundwissen durchgehen.
-
Ein Verständnis grundlegender Flask-SQLAlchemy-Konzepte, wie das Einrichten einer Datenbank, das Erstellen von Datenbankmodellen und das Einfügen von Daten in die Datenbank. Siehe So verwenden Sie Flask-SQLAlchemy zur Interaktion mit Datenbanken in einer Flask-Anwendung für Hintergrundwissen.
Schritt 1 — Einrichten der Datenbank und des Modells
In diesem Schritt installieren Sie die erforderlichen Pakete und richten Ihre Flask-Anwendung, die Flask-SQLAlchemy-Datenbank und das Mitarbeitermodell ein, das die employee-Tabelle repräsentiert, in der Sie Ihre Mitarbeiterdaten speichern. Sie fügen einige Mitarbeiter in die employee-Tabelle ein und fügen eine Route und eine Seite hinzu, auf der alle Mitarbeiter auf der Indexseite Ihrer Anwendung angezeigt werden.
Zuerst, wenn Ihre virtuelle Umgebung aktiviert ist, installieren Sie Flask und Flask-SQLAlchemy:
Sobald die Installation abgeschlossen ist, erhalten Sie eine Ausgabe mit der folgenden Zeile am Ende:
Output
Successfully installed Flask-2.1.2 Flask-SQLAlchemy-2.5.1 Jinja2-3.1.2 MarkupSafe-2.1.1 SQLAlchemy-1.4.37 Werkzeug-2.1.2 click-8.1.3 greenlet-1.1.2 itsdangerous-2.1.2
Mit den erforderlichen Paketen installiert, öffnen Sie eine neue Datei namens app.py in Ihrem flask_app-Verzeichnis. Diese Datei wird den Code zum Einrichten der Datenbank und Ihrer Flask-Routen enthalten:
Fügen Sie den folgenden Code zu app.py hinzu. Dieser Code wird eine SQLite-Datenbank und ein Mitarbeiterdatenbankmodell einrichten, das die Mitarbeiter-Tabelle repräsentiert, die Sie zur Speicherung Ihrer Mitarbeiterdaten verwenden werden:
Speichern und schließen Sie die Datei.
Hier importieren Sie das os-Modul, das Ihnen Zugriff auf verschiedene Betriebssystem-Schnittstellen bietet. Sie werden es verwenden, um einen Dateipfad für Ihre database.db-Datenbankdatei zu konstruieren.
Aus dem flask-Paket importieren Sie die Hilfsprogramme, die Sie für Ihre Anwendung benötigen: die Flask-Klasse zur Erstellung einer Flask-Anwendungsinstanz, render_template() zum Rendern von Vorlagen, das request-Objekt zum Behandeln von Anfragen, url_for() zum Konstruieren von URLs und die redirect()-Funktion zum Umleiten von Benutzern. Weitere Informationen zu Routen und Vorlagen finden Sie unter So verwenden Sie Vorlagen in einer Flask-Anwendung.
Dann importieren Sie die SQLAlchemy-Klasse von der Flask-SQLAlchemy-Erweiterung, die Ihnen Zugriff auf alle Funktionen und Klassen von SQLAlchemy sowie Hilfsprogramme und Funktionen bietet, die Flask mit SQLAlchemy integrieren. Sie werden es verwenden, um ein Datenbankobjekt zu erstellen, das Ihre Flask-Anwendung mit der Datenbank verbindet.
Um einen Pfad für Ihre Datenbankdatei zu konstruieren, definieren Sie ein Basisverzeichnis als das aktuelle Verzeichnis. Sie verwenden die os.path.abspath() Funktion, um den absoluten Pfad des aktuellen Dateiverzeichnisses zu erhalten. Die spezielle __file__ Variable enthält den Dateinamen der aktuellen app.py Datei. Sie speichern den absoluten Pfad des Basisverzeichnisses in einer Variable namens basedir.
Dann erstellen Sie eine Flask-Anwendungsinstanz namens app, die Sie verwenden, um zwei Flask-SQLAlchemy Konfigurationsschlüssel zu konfigurieren:
-
SQLALCHEMY_DATABASE_URI: Die Datenbank-URI, um die Datenbank zu spezifizieren, mit der Sie eine Verbindung herstellen möchten. In diesem Fall folgt die URI dem Formatsqlite:///Pfad/zur/datenbank.db. Sie verwenden dieos.path.join()Funktion, um das Basisverzeichnis, das Sie konstruiert und in der Variablenbasedirgespeichert haben, intelligent mit dem Dateinamendatabase.dbzu verbinden. Dadurch wird eine Verbindung zu einerdatabase.dbDatenbankdatei in Ihremflask_appVerzeichnis hergestellt. Die Datei wird erstellt, sobald Sie die Datenbank initialisieren. -
SQLALCHEMY_TRACK_MODIFICATIONS: Eine Konfiguration, um das Verfolgen von Änderungen an Objekten zu aktivieren oder zu deaktivieren. Sie setzen es aufFalse, um das Tracking zu deaktivieren, was weniger Speicher verbraucht. Weitere Informationen finden Sie auf der Konfigurationsseite in der Flask-SQLAlchemy-Dokumentation.
Nach der Konfiguration von SQLAlchemy durch Festlegen einer Datenbank-URI und Deaktivieren des Trackings erstellen Sie ein Datenbankobjekt, indem Sie die Klasse SQLAlchemy verwenden und die Anwendungsinstanz übergeben, um Ihre Flask-Anwendung mit SQLAlchemy zu verbinden. Sie speichern Ihr Datenbankobjekt in einer Variablen namens db, mit der Sie mit Ihrer Datenbank interagieren können.
Nachdem Sie die Anwendungsinstanz und das Datenbankobjekt eingerichtet haben, erben Sie von der db.Model-Klasse, um ein Datenbankmodell namens Employee zu erstellen. Dieses Modell stellt die employee-Tabelle dar und hat die folgenden Spalten:
id: Die Mitarbeiter-ID, ein ganzzahliger Primärschlüssel.firstname: Der Vorname des Mitarbeiters, eine Zeichenkette mit einer maximalen Länge von 100 Zeichen.nullable=Falsebedeutet, dass diese Spalte nicht leer sein darf.lastname: Der Nachname des Mitarbeiters, eine Zeichenkette mit einer maximalen Länge von 100 Zeichen.nullable=Falsebedeutet, dass diese Spalte nicht leer sein darf.email: Die E-Mail-Adresse des Mitarbeiters, eine Zeichenkette mit einer maximalen Länge von 100 Zeichen.unique=Truebedeutet, dass jede E-Mail-Adresse eindeutig sein sollte.nullable=Falsebedeutet, dass ihr Wert nicht leer sein sollte.age: Das Alter des Mitarbeiters, ein ganzzahliger Wert.hire_date: Das Datum, an dem der Mitarbeiter eingestellt wurde. Sie setzendb.Dateals Spaltentyp, um es als Spalte zu deklarieren, die Daten enthält.active: Eine Spalte, die einen booleschen Wert enthält, um anzuzeigen, ob der Mitarbeiter derzeit aktiv ist oder nicht im Büro ist.
Die spezielle __repr__-Funktion ermöglicht es Ihnen, jedem Objekt eine Zeichenfolgendarstellung zu geben, um es zu erkennen, zu Debugging-Zwecken. In diesem Fall verwenden Sie den Vor- und Nachnamen des Mitarbeiters, um jedes Mitarbeiterobjekt darzustellen.
Nun, da Sie die Datenbankverbindung und das Mitarbeitermodell eingerichtet haben, werden Sie ein Python-Programm schreiben, um Ihre Datenbank und die Tabelle employee zu erstellen und die Tabelle mit einigen Mitarbeiterdaten zu befüllen.
Öffnen Sie eine neue Datei namens init_db.py in Ihrem flask_app-Verzeichnis:
Fügen Sie den folgenden Code hinzu, um vorhandene Datenbanktabellen zu löschen, um mit einer leeren Datenbank zu beginnen, die Tabelle employee zu erstellen und neun Mitarbeiter darin einzufügen:
Hier importieren Sie die date()-Klasse aus dem datetime-Modul, um sie zur Festlegung von Einstellungsdaten für Mitarbeiter zu verwenden.
Sie importieren das Datenbankobjekt und das Employee-Modell. Sie rufen die Funktion db.drop_all() auf, um alle vorhandenen Tabellen zu löschen und die Chance zu vermeiden, dass bereits eine bevölkerte employee-Tabelle in der Datenbank existiert, was Probleme verursachen könnte. Dies löscht alle Datenbankdaten, wenn Sie das Programm init_db.py ausführen. Weitere Informationen zum Erstellen, Ändern und Löschen von Datenbanktabellen finden Sie in Wie man Flask-SQLAlchemy verwendet, um mit Datenbanken in einer Flask-Anwendung zu interagieren.
Sie erstellen dann mehrere Instanzen des Employee-Modells, die die Mitarbeiter repräsentieren, die Sie in diesem Tutorial abfragen werden, und fügen sie mit der Funktion db.session.add_all() zur Datenbanksitzung hinzu. Schließlich bestätigen Sie die Transaktion und wenden die Änderungen an der Datenbank mit db.session.commit() an.
Speichern und schließen Sie die Datei.
Führen Sie das Programm init_db.py aus:
Um sich die Daten anzusehen, die Sie Ihrer Datenbank hinzugefügt haben, stellen Sie sicher, dass Ihre virtuelle Umgebung aktiviert ist, und öffnen Sie die Flask-Shell, um alle Mitarbeiter abzufragen und ihre Daten anzuzeigen:
Führen Sie den folgenden Code aus, um alle Mitarbeiter abzufragen und ihre Daten anzuzeigen:
Sie verwenden die Methode all() des Attributs query, um alle Mitarbeiter zu erhalten. Sie durchlaufen die Ergebnisse und zeigen die Mitarbeiterinformationen an. Für die Spalte active verwenden Sie eine bedingte Anweisung, um den aktuellen Status des Mitarbeiters anzuzeigen, entweder 'Active' oder 'Out of Office'.
Sie erhalten die folgende Ausgabe:
OutputJohn Doe
Email: [email protected]
Age: 32
Hired: 2012-03-03
Active
----
Mary Doe
Email: [email protected]
Age: 38
Hired: 2016-06-07
Active
----
Jane Tanaka
Email: [email protected]
Age: 32
Hired: 2015-09-12
Out of Office
----
Alex Brown
Email: [email protected]
Age: 29
Hired: 2019-01-03
Active
----
James White
Email: [email protected]
Age: 24
Hired: 2021-02-04
Active
----
Harold Ishida
Email: [email protected]
Age: 52
Hired: 2002-03-06
Out of Office
----
Scarlett Winter
Email: [email protected]
Age: 22
Hired: 2021-04-07
Active
----
Emily Vill
Email: [email protected]
Age: 27
Hired: 2019-06-09
Active
----
Mary Park
Email: [email protected]
Age: 30
Hired: 2021-08-11
Active
----
Sie können sehen, dass alle Mitarbeiter, die wir der Datenbank hinzugefügt haben, ordnungsgemäß angezeigt werden.
Verlassen Sie die Flask-Shell:
Als nächstes erstellen Sie eine Flask-Route, um Mitarbeiter anzuzeigen. Öffnen Sie app.py zum Bearbeiten:
Fügen Sie am Ende der Datei die folgende Route hinzu:
Speichern und schließen Sie die Datei.
Dies ruft alle Mitarbeiter ab, rendert eine index.html-Vorlage und übergibt die abgerufenen Mitarbeiter.
Erstellen Sie ein Verzeichnis für Vorlagen und eine Basisschablone:
Fügen Sie das Folgende zu base.html hinzu:
Speichern und schließen Sie die Datei.
Hier verwenden Sie einen Titelblock und fügen einige CSS-Stile hinzu. Sie fügen eine Navigationsleiste mit zwei Elementen hinzu, eins für die Indexseite und eins für eine inaktive Infoseite. Diese Navigationsleiste wird in den Vorlagen wiederverwendet, die von dieser Basisschablone erben. Der Inhaltsblock wird durch den Inhalt jeder Seite ersetzt. Weitere Informationen zu Vorlagen finden Sie unter So verwenden Sie Vorlagen in einer Flask-Anwendung.
Öffnen Sie als nächstes eine neue index.html-Vorlage, die Sie in app.py gerendert haben:
Fügen Sie den folgenden Code zur Datei hinzu:
Hier durchlaufen Sie die Mitarbeiter und zeigen die Informationen jedes Mitarbeiters an. Wenn der Mitarbeiter aktiv ist, fügen Sie ein (Aktiv)-Label hinzu, sonst zeigen Sie ein (Außerhalb des Büros)-Label an.
Speichern und schließen Sie die Datei.
Während sich Ihr flask_app-Verzeichnis mit Ihrer virtuellen Umgebung aktiviert befindet, teilen Sie Flask über die Anwendung (app.py in diesem Fall) mithilfe der Umgebungsvariable FLASK_APP Bescheid. Legen Sie dann die Umgebungsvariable FLASK_ENV auf development fest, um die Anwendung im Entwicklungsmodus auszuführen und Zugriff auf den Debugger zu erhalten. Weitere Informationen zum Flask-Debugger finden Sie unter Wie Fehler in einer Flask-Anwendung behandelt werden. Verwenden Sie die folgenden Befehle dazu:
Als nächstes führen Sie die Anwendung aus:
Mit dem Entwicklungsserver aktiviert, besuchen Sie die folgende URL in Ihrem Browser:
http://127.0.0.1:5000/
Sie sehen die Mitarbeiter, die Sie der Datenbank hinzugefügt haben, auf einer Seite ähnlich der folgenden:
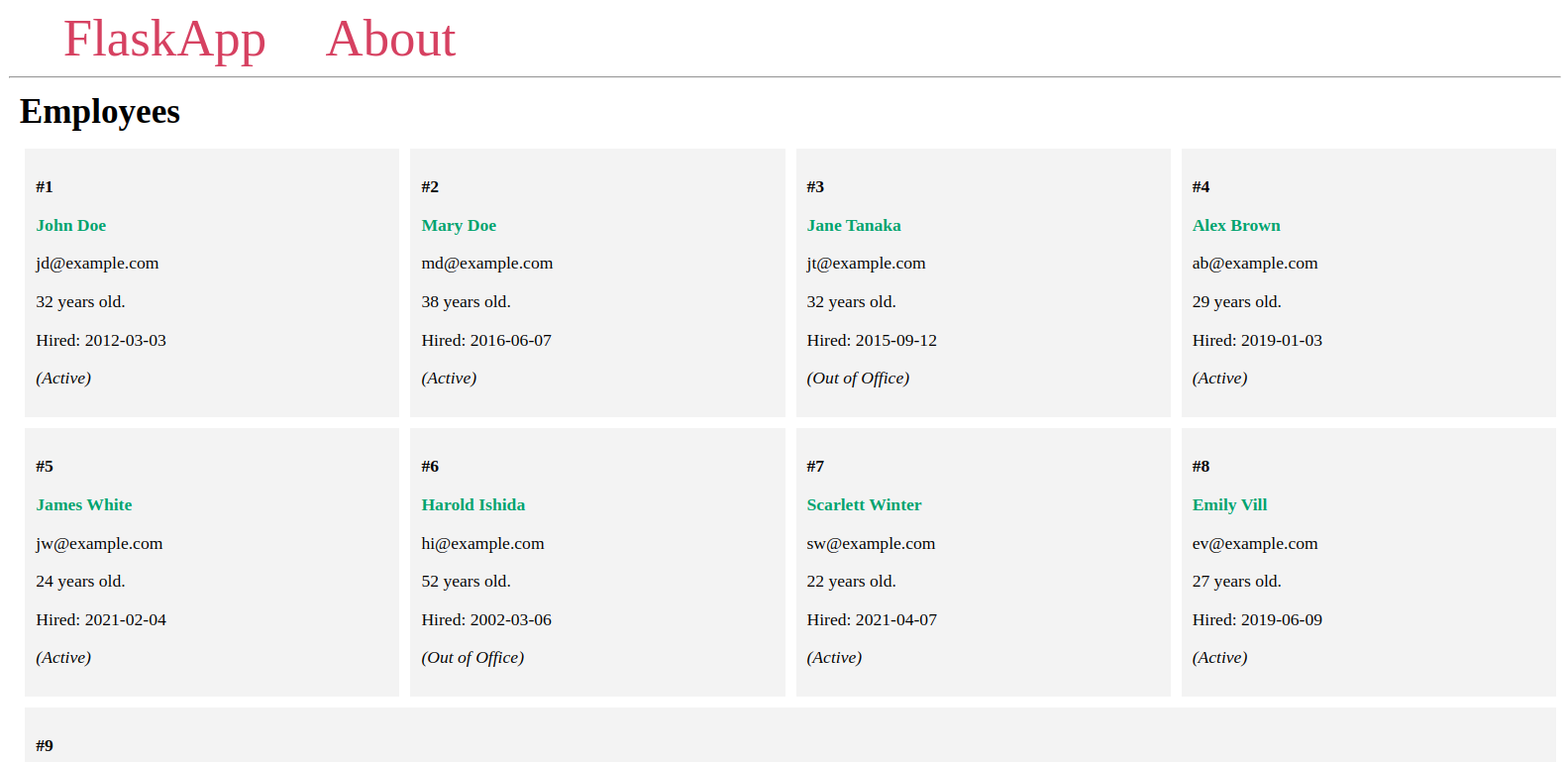
Lassen Sie den Server weiter laufen, öffnen Sie ein weiteres Terminal und fahren Sie mit dem nächsten Schritt fort.
Sie haben die Mitarbeiter, die Sie in Ihrer Datenbank haben, auf der Indexseite angezeigt. Als nächstes verwenden Sie die Flask-Shell, um Mitarbeiter mit verschiedenen Methoden abzufragen.
Schritt 2 — Abfragen von Datensätzen
In diesem Schritt verwenden Sie die Flask-Shell, um Datensätze abzufragen, und filtern und erhalten Ergebnisse unter Verwendung mehrerer Methoden und Bedingungen.
Mit Ihrer Programmierumgebung aktiviert, setzen Sie die Variablen FLASK_APP und FLASK_ENV und öffnen Sie die Flask-Shell:
Importieren Sie das db-Objekt und das Employee-Modell:
Abrufen aller Datensätze
Wie Sie im vorherigen Schritt gesehen haben, können Sie die all()-Methode auf dem query-Attribut verwenden, um alle Datensätze in einer Tabelle zu erhalten:
Die Ausgabe wird eine Liste von Objekten sein, die alle Mitarbeiter repräsentieren:
Output
[<Employee John Doe>, <Employee Mary Doe>, <Employee Jane Tanaka>, <Employee Alex Brown>, <Employee James White>, <Employee Harold Ishida>, <Employee Scarlett Winter>, <Employee Emily Vill>, <Employee Mary Park>]
Abrufen des ersten Datensatzes
Außerdem können Sie die first()-Methode verwenden, um den ersten Datensatz zu erhalten:
Die Ausgabe wird ein Objekt sein, das die Daten des ersten Mitarbeiters enthält:
Output<Employee John Doe>
Abrufen eines Datensatzes nach ID
In den meisten Datenbanktabellen werden Datensätze mit einer eindeutigen ID identifiziert. Flask-SQLAlchemy ermöglicht es Ihnen, einen Datensatz mithilfe seiner ID mit der get()-Methode abzurufen:
Output<Employee James White> | ID: 5
<Employee Jane Tanaka> | ID: 3
Abrufen eines Datensatzes oder mehrerer Datensätze nach einem Spaltenwert
Um einen Datensatz anhand des Werts einer seiner Spalten zu erhalten, verwenden Sie die Methode filter_by(). Zum Beispiel, um einen Datensatz anhand seines ID-Werts zu erhalten, ähnlich der get()-Methode:
Output<Employee John Doe>
Sie verwenden first(), weil filter_by() mehrere Ergebnisse zurückgeben kann.
Hinweis: Um einen Datensatz nach ID zu erhalten, ist die Verwendung der get()-Methode ein besserer Ansatz.
Als weiteres Beispiel können Sie einen Mitarbeiter anhand seines Alters erhalten:
Output<Employee Harold Ishida>
Für ein Beispiel, in dem das Abfrageergebnis mehr als einen übereinstimmenden Datensatz enthält, verwenden Sie die Spalte firstname und den Vornamen Mary, der von zwei Mitarbeitern geteilt wird:
Output[<Employee Mary Doe>, <Employee Mary Park>]
Hier verwenden Sie all(), um die vollständige Liste zu erhalten. Sie können auch first() verwenden, um nur das erste Ergebnis zu erhalten:
Output<Employee Mary Doe>
Sie haben Datensätze über Spaltenwerte abgerufen. Als nächstes werden Sie Ihre Tabelle unter Verwendung logischer Bedingungen abfragen.
Schritt 3 — Filtern von Datensätzen unter Verwendung logischer Bedingungen
In komplexen, umfangreichen Webanwendungen müssen Sie oft Datensätze aus der Datenbank abfragen und dabei komplizierte Bedingungen verwenden, z. B. Mitarbeiter basierend auf einer Kombination von Bedingungen abrufen, die ihren Standort, ihre Verfügbarkeit, ihre Rolle und ihre Verantwortlichkeiten berücksichtigen. In diesem Schritt üben Sie den Einsatz von bedingten Operatoren. Sie verwenden die filter()-Methode auf dem query-Attribut, um Abfrageergebnisse mithilfe logischer Bedingungen mit verschiedenen Operatoren zu filtern. Sie können beispielsweise logische Operatoren verwenden, um eine Liste der Mitarbeiter abzurufen, die derzeit nicht im Büro sind, oder Mitarbeiter, die für eine Beförderung vorgesehen sind, und vielleicht einen Kalender der Urlaubszeiten der Mitarbeiter bereitzustellen, usw.
Gleich
Der einfachste logische Operator, den Sie verwenden können, ist der Gleichheitsoperator ==, der ähnlich wie filter_by() funktioniert. Um beispielsweise alle Datensätze zu erhalten, bei denen der Wert der firstname-Spalte Mary ist, können Sie die filter()-Methode wie folgt verwenden:
Hier verwenden Sie die Syntax Model.column == value als Argument für die filter()-Methode. Die filter_by()-Methode ist eine Abkürzung für diese Syntax.
Das Ergebnis ist dasselbe wie das Ergebnis der filter_by()-Methode mit derselben Bedingung:
Output[<Employee Mary Doe>, <Employee Mary Park>]
Wie filter_by() können Sie auch die first()-Methode verwenden, um das erste Ergebnis zu erhalten:
Output<Employee Mary Doe>
Nicht gleich
Die Methode filter() ermöglicht es Ihnen, den Python-Operator != zu verwenden, um Datensätze zu erhalten. Zum Beispiel, um eine Liste der Mitarbeiter im Außendienst zu erhalten, können Sie den folgenden Ansatz verwenden:
Output[<Employee Jane Tanaka>, <Employee Harold Ishida>]
Hier verwenden Sie die Bedingung Employee.active != True, um die Ergebnisse zu filtern.
Weniger als
Sie können den Operator < verwenden, um einen Datensatz zu erhalten, bei dem der Wert einer bestimmten Spalte kleiner als der angegebene Wert ist. Zum Beispiel, um eine Liste der Mitarbeiter unter 32 Jahren zu erhalten:
Output
Alex Brown
Age: 29
----
James White
Age: 24
----
Scarlett Winter
Age: 22
----
Emily Vill
Age: 27
----
Mary Park
Age: 30
----
Verwenden Sie den Operator <= für Datensätze, die kleiner oder gleich dem angegebenen Wert sind. Zum Beispiel, um Mitarbeiter im Alter von 32 Jahren in der vorherigen Abfrage einzuschließen:
Output
John Doe
Age: 32
----
Jane Tanaka
Age: 32
----
Alex Brown
Age: 29
----
James White
Age: 24
----
Scarlett Winter
Age: 22
----
Emily Vill
Age: 27
----
Mary Park
Age: 30
----
Größer als
Ähnlich dazu gibt der Operator > einen Datensatz zurück, bei dem der Wert einer bestimmten Spalte größer als der angegebene Wert ist. Zum Beispiel, um Mitarbeiter über 32 Jahre zu erhalten:
OutputMary Doe
Age: 38
----
Harold Ishida
Age: 52
----
Und der Operator >= ist für Datensätze, die größer oder gleich dem angegebenen Wert sind. Zum Beispiel können Sie erneut 32-jährige Mitarbeiter in der vorherigen Abfrage einschließen:
Output
John Doe
Age: 32
----
Mary Doe
Age: 38
----
Jane Tanaka
Age: 32
----
Harold Ishida
Age: 52
----
In
SQLAlchemy bietet auch eine Möglichkeit, Datensätze abzurufen, bei denen der Wert einer Spalte mit einem Wert aus einer gegebenen Liste von Werten übereinstimmt, indem Sie die Methode in_() auf der Spalte wie folgt verwenden:
Output[<Employee Mary Doe>, <Employee Alex Brown>, <Employee Emily Vill>, <Employee Mary Park>]
Hier verwenden Sie eine Bedingung mit der Syntax Modell.spalte.in_(iterierbar), wobei iterierbar ein beliebiger Typ von Objekt ist, das Sie durchlaufen können. Als weiteres Beispiel können Sie die Python-Funktion range() verwenden, um Mitarbeiter in einem bestimmten Altersbereich zu erhalten. Die folgende Abfrage ruft alle Mitarbeiter ab, die sich in ihren Dreißigern befinden.
OutputJohn Doe
Age: 32
----
Mary Doe
Age: 38
----
Jane Tanaka
Age: 32
----
Mary Park
Age: 30
----
Nicht In
Ähnlich wie bei der Methode in_() können Sie die Methode not_in() verwenden, um Datensätze abzurufen, bei denen ein Spaltenwert nicht in einem gegebenen Iterable liegt:
Output
[<Employee John Doe>, <Employee Jane Tanaka>, <Employee James White>, <Employee Harold Ishida>, <Employee Scarlett Winter>]
Hier erhalten Sie alle Mitarbeiter außer denen mit einem Vornamen in der Liste names.
Und
Sie können mehrere Bedingungen miteinander verknüpfen, indem Sie die Funktion db.and_() verwenden, die wie der and-Operator in Python funktioniert.
Zum Beispiel, sagen wir, Sie möchten alle Mitarbeiter, die 32 Jahre alt sind, und derzeit aktiv sind. Zuerst können Sie überprüfen, wer 32 ist, indem Sie die Methode filter_by() verwenden (Sie können auch filter() verwenden, wenn Sie möchten):
Output<Employee John Doe>
Age: 32
Active: True
-----
<Employee Jane Tanaka>
Age: 32
Active: False
-----
Hier sehen Sie, dass John und Jane die Mitarbeiter sind, die 32 Jahre alt sind. John ist aktiv und Jane ist außerhalb des Büros.
Um die Mitarbeiter zu erhalten, die 32 Jahre alt sind und aktiv sind, verwenden Sie zwei Bedingungen mit der Methode filter():
Employee.age == 32Employee.active == True
Um diese beiden Bedingungen zusammenzuführen, verwenden Sie die Funktion db.and_() wie folgt:
Output[<Employee John Doe>]
Hier verwenden Sie die Syntax filter(db.and_(Bedingung1, Bedingung2)).
Mit all() auf der Abfrage erhalten Sie eine Liste aller Datensätze, die den beiden Bedingungen entsprechen. Sie können die Methode first() verwenden, um das erste Ergebnis zu erhalten:
Output<Employee John Doe>
Für ein komplexeres Beispiel können Sie db.and_() mit der Funktion date() verwenden, um Mitarbeiter zu erhalten, die in einem bestimmten Zeitraum eingestellt wurden. In diesem Beispiel erhalten Sie alle Mitarbeiter, die im Jahr 2019 eingestellt wurden:
Output<Employee Alex Brown> | Hired: 2019-01-03
<Employee Emily Vill> | Hired: 2019-06-09
Hier importieren Sie die Funktion date() und filtern die Ergebnisse mit der Funktion db.and_(), um die folgenden beiden Bedingungen zu kombinieren:
Employee.einstellungsdatum >= date(year=2019, month=1, day=1): Dies istTruefür Mitarbeiter, die am ersten Januar 2019 oder später eingestellt wurden.Employee.hire_date < date(year=2020, month=1, day=1): Dies istTruefür Mitarbeiter, die vor dem ersten Januar 2020 eingestellt wurden.
Die Kombination der beiden Bedingungen erfasst Mitarbeiter, die ab dem ersten Tag des Jahres 2019 und vor dem ersten Tag des Jahres 2020 eingestellt wurden.
Oder
Ähnlich wie db.and_() kombiniert die Funktion db.or_() zwei Bedingungen und verhält sich wie der or-Operator in Python. Es werden alle Datensätze abgerufen, die eine der beiden Bedingungen erfüllen. Um beispielsweise Mitarbeiter im Alter von 32 oder 52 Jahren zu erhalten, können Sie zwei Bedingungen mit der Funktion db.or_() wie folgt kombinieren:
Output<Employee John Doe> | Age: 32
<Employee Jane Tanaka> | Age: 32
<Employee Harold Ishida> | Age: 52
Sie können auch die Methoden startswith() und endswith() auf String-Werten in Bedingungen verwenden, die Sie an die filter()-Methode übergeben. Um beispielsweise alle Mitarbeiter zu erhalten, deren Vorname mit dem String 'M' beginnt, und diejenigen mit einem Nachnamen, der mit dem String 'e' endet:
Output<Employee John Doe>
<Employee Mary Doe>
<Employee James White>
<Employee Mary Park>
Hier kombinieren Sie die folgenden beiden Bedingungen:
Employee.firstname.startswith('M'): Übereinstimmung mit Mitarbeitern, deren Vorname mit'M'beginnt.Employee.lastname.endswith('e'): Übereinstimmung mit Mitarbeitern, deren Nachname mit'e'endet.
Sie können nun Abfrageergebnisse in Ihren Flask-SQLAlchemy-Anwendungen mit logischen Bedingungen filtern. Als nächstes ordnen, begrenzen und zählen Sie die Ergebnisse, die Sie aus der Datenbank erhalten.
Schritt 4 — Bestellen, Begrenzen und Zählen von Ergebnissen
In Webanwendungen müssen Sie oft Ihre Datensätze ordnen, wenn Sie sie anzeigen. Zum Beispiel haben Sie möglicherweise eine Seite, um die neuesten Einstellungen in jedem Bereich anzuzeigen, um den Rest des Teams über Neueinstellungen zu informieren, oder Sie können Mitarbeiter ordnen, indem Sie zuerst die ältesten Einstellungen anzeigen, um langjährige Mitarbeiter anzuerkennen. Sie müssen auch Ihre Ergebnisse in bestimmten Fällen begrenzen, z. B. nur die neuesten drei Einstellungen in einer kleinen Seitenleiste anzeigen. Und Sie müssen oft die Ergebnisse einer Abfrage zählen, um beispielsweise die Anzahl der Mitarbeiter anzuzeigen, die derzeit aktiv sind. In diesem Schritt erfahren Sie, wie Sie Ergebnisse bestellen, begrenzen und zählen.
Ergebnisse bestellen
Um Ergebnisse nach den Werten einer bestimmten Spalte zu bestellen, verwenden Sie die Methode order_by(). Zum Beispiel, um Ergebnisse nach dem Vornamen der Mitarbeiter zu ordnen:
Output[<Employee Alex Brown>, <Employee Emily Vill>, <Employee Harold Ishida>, <Employee James White>, <Employee Jane Tanaka>, <Employee John Doe>, <Employee Mary Doe>, <Employee Mary Park>, <Employee Scarlett Winter>]
Wie die Ausgabe zeigt, werden die Ergebnisse alphabetisch nach dem Vornamen des Mitarbeiters sortiert.
Sie können auch nach anderen Spalten bestellen. Zum Beispiel können Sie den Nachnamen verwenden, um Mitarbeiter zu bestellen:
Output[<Employee Alex Brown>, <Employee John Doe>, <Employee Mary Doe>, <Employee Harold Ishida>, <Employee Mary Park>, <Employee Jane Tanaka>, <Employee Emily Vill>, <Employee James White>, <Employee Scarlett Winter>]
Sie können Mitarbeiter auch nach ihrem Einstellungsdatum ordnen:
Output
Harold Ishida 2002-03-06
John Doe 2012-03-03
Jane Tanaka 2015-09-12
Mary Doe 2016-06-07
Alex Brown 2019-01-03
Emily Vill 2019-06-09
James White 2021-02-04
Scarlett Winter 2021-04-07
Mary Park 2021-08-11
Wie die Ausgabe zeigt, ordnet dies die Ergebnisse von der frühesten Einstellung bis zur neuesten Einstellung. Um die Reihenfolge umzukehren und sie absteigend von der neuesten Einstellung bis zur frühesten zu machen, verwenden Sie die desc()-Methode wie folgt:
OutputMary Park 2021-08-11
Scarlett Winter 2021-04-07
James White 2021-02-04
Emily Vill 2019-06-09
Alex Brown 2019-01-03
Mary Doe 2016-06-07
Jane Tanaka 2015-09-12
John Doe 2012-03-03
Harold Ishida 2002-03-06
Sie können auch die order_by()-Methode mit der filter()-Methode kombinieren, um gefilterte Ergebnisse zu ordnen. Das folgende Beispiel ruft alle Mitarbeiter ab, die 2021 eingestellt wurden, und ordnet sie nach Alter:
OutputScarlett Winter 2021-04-07 | Age 22
James White 2021-02-04 | Age 24
Mary Park 2021-08-11 | Age 30
Hier verwenden Sie die db.and_()-Funktion mit zwei Bedingungen: Employee.hire_date >= date(year=2021, month=1, day=1) für Mitarbeiter, die am ersten Tag des Jahres 2021 oder später eingestellt wurden, und Employee.hire_date < date(year=2022, month=1, day=1) für Mitarbeiter, die vor dem ersten Tag von 2022 eingestellt wurden. Anschließend verwenden Sie die order_by()-Methode, um die resultierenden Mitarbeiter nach ihrem Alter zu ordnen.
Ergebnisse begrenzen
In den meisten realen Fällen, bei Abfragen einer Datenbanktabelle, erhalten Sie möglicherweise bis zu Millionen von übereinstimmenden Ergebnissen, und es ist manchmal notwendig, die Ergebnisse auf eine bestimmte Anzahl zu beschränken. Um Ergebnisse in Flask-SQLAlchemy zu begrenzen, können Sie die limit()-Methode verwenden. Das folgende Beispiel fragt die Mitarbeiter-Tabelle ab und gibt nur die ersten drei übereinstimmenden Ergebnisse zurück:
Output[<Employee John Doe>, <Employee Mary Doe>, <Employee Jane Tanaka>]
Sie können limit() mit anderen Methoden wie filter und order_by verwenden. Zum Beispiel können Sie die letzten beiden Mitarbeiter abfragen, die 2021 eingestellt wurden, indem Sie die limit()-Methode wie folgt verwenden:
OutputScarlett Winter 2021-04-07 | Age 22
James White 2021-02-04 | Age 24
Hier verwenden Sie dieselbe Abfrage wie im vorherigen Abschnitt mit einem zusätzlichen limit(2) Methodenaufruf.
Ergebnisse zählen
Um die Anzahl der Ergebnisse einer Abfrage zu zählen, können Sie die Methode count() verwenden. Zum Beispiel, um die Anzahl der Mitarbeiter zu erhalten, die sich derzeit in der Datenbank befinden:
Output9
Sie können die Methode count() mit anderen Abfragemethoden ähnlich wie limit() kombinieren. Zum Beispiel, um die Anzahl der im Jahr 2021 eingestellten Mitarbeiter zu erhalten:
Output3
Hier verwenden Sie dieselbe Abfrage wie zuvor, um alle Mitarbeiter abzurufen, die im Jahr 2021 eingestellt wurden. Und Sie verwenden count(), um die Anzahl der Einträge abzurufen, die 3 beträgt.
Sie haben Abfrageergebnisse in Flask-SQLAlchemy sortiert, begrenzt und gezählt. Als nächstes erfahren Sie, wie Sie Abfrageergebnisse in mehrere Seiten aufteilen und wie Sie ein Paginierungssystem in Ihren Flask-Anwendungen erstellen können.
Schritt 5 — Anzeige langer Datensatzlisten auf mehreren Seiten
In diesem Schritt werden Sie die Hauptroute ändern, um die Indexseite so zu gestalten, dass Mitarbeiter auf mehreren Seiten angezeigt werden, um die Navigation durch die Mitarbeiterliste zu erleichtern.
Zuerst verwenden Sie die Flask-Shell, um eine Demonstration zur Verwendung der Paginierungsfunktion in Flask-SQLAlchemy zu sehen. Öffnen Sie die Flask-Shell, wenn Sie dies noch nicht getan haben:
Angenommen, Sie möchten die Mitarbeiterdatensätze in Ihrer Tabelle in mehrere Seiten aufteilen, wobei zwei Elemente pro Seite angezeigt werden. Sie können dies mit der paginate()-Abfragefunktion wie folgt tun:
Output<flask_sqlalchemy.Pagination object at 0x7f1dbee7af80>
[<Employee John Doe>, <Employee Mary Doe>]
Sie verwenden den page-Parameter der paginate()-Abfragefunktion, um die Seite anzugeben, die Sie abrufen möchten, was in diesem Fall die erste Seite ist. Der per_page-Parameter legt fest, wie viele Elemente sich auf jeder Seite befinden müssen. In diesem Fall setzen Sie ihn auf 2, um jede Seite zwei Elemente haben zu lassen.
Die Variable page1 ist hier ein Paginierungsobjekt, das Ihnen den Zugriff auf Attribute und Methoden gibt, die Sie zur Verwaltung Ihrer Paginierung verwenden werden.
Sie greifen auf die Elemente der Seite über das items-Attribut zu.
Um zur nächsten Seite zu gelangen, können Sie die next()-Methode des Paginierungsobjekts verwenden. Das zurückgegebene Ergebnis ist ebenfalls ein Paginierungsobjekt:
Output[<Employee Jane Tanaka>, <Employee Alex Brown>]
<flask_sqlalchemy.Pagination object at 0x7f1dbee799c0>
Sie können ein Paginierungsobjekt für die vorherige Seite mithilfe der prev()-Methode abrufen. Im folgenden Beispiel greifen Sie auf das Paginierungsobjekt für die vierte Seite zu, dann greifen Sie auf das Paginierungsobjekt der vorherigen Seite zu, was Seite 3 ist:
Output[<Employee Scarlett Winter>, <Employee Emily Vill>]
[<Employee James White>, <Employee Harold Ishida>]
Sie können die aktuelle Seitennummer über das page-Attribut abrufen, wie folgt:
Output1
2
Um die Gesamtanzahl der Seiten zu erhalten, verwenden Sie das pages-Attribut des Paginierungsobjekts. Im folgenden Beispiel geben sowohl page1.pages als auch page2.pages den gleichen Wert zurück, da die Gesamtanzahl der Seiten konstant ist:
Output5
5
Für die Gesamtanzahl der Elemente verwenden Sie das total-Attribut des Paginierungsobjekts:
Output9
9
Hier, da Sie alle Mitarbeiter abfragen, beträgt die Gesamtanzahl der Elemente in der Paginierung 9, weil es neun Mitarbeiter in der Datenbank gibt.
Hier sind einige der anderen Attribute, die Paginierungsobjekte haben:
prev_num: Die vorherige Seitennummer.next_num: Die nächste Seitennummer.has_next:True, wenn es eine nächste Seite gibt.has_prev:True, wenn es eine vorherige Seite gibt.per_page: Die Anzahl der Elemente pro Seite.
Das Paginierungsobjekt hat auch eine iter_pages()-Methode, durch die Sie Schleifen durchlaufen können, um Seitennummern zu erhalten. Sie können beispielsweise alle Seitennummern wie folgt drucken:
Output1
2
3
4
5
Das Folgende ist eine Demonstration, wie Sie alle Seiten und ihre Elemente mit einem Paginierungsobjekt und der iter_pages()-Methode abrufen können:
Output
PAGE 1
-
[<Employee John Doe>, <Employee Mary Doe>]
--------------------
PAGE 2
-
[<Employee Jane Tanaka>, <Employee Alex Brown>]
--------------------
PAGE 3
-
[<Employee James White>, <Employee Harold Ishida>]
--------------------
PAGE 4
-
[<Employee Scarlett Winter>, <Employee Emily Vill>]
--------------------
PAGE 5
-
[<Employee Mary Park>]
--------------------
Hier erstellen Sie ein Paginierungsobjekt, das von der ersten Seite aus beginnt. Sie durchlaufen die Seiten mit einer for-Schleife und der iter_pages()-Paginierungsmethode. Sie drucken die Seitennummer und die Seitenelemente aus, und Sie setzen das pagination-Objekt auf das Paginierungsobjekt seiner nächsten Seite mit der next()-Methode.
Sie können auch die filter()– und die order_by()-Methoden mit der paginate()-Methode verwenden, um gefilterte und sortierte Abfrageergebnisse zu paginieren. Zum Beispiel können Sie Mitarbeiter über dreißig erhalten und die Ergebnisse nach Alter ordnen und die Ergebnisse paginieren wie folgt:
OutputPAGE 1
-
<Employee John Doe> | Age: 32
<Employee Jane Tanaka> | Age: 32
--------------------
PAGE 2
-
<Employee Mary Doe> | Age: 38
<Employee Harold Ishida> | Age: 52
--------------------
Jetzt, da Sie ein solides Verständnis dafür haben, wie die Paginierung in Flask-SQLAlchemy funktioniert, werden Sie die Indexseite Ihrer Anwendung bearbeiten, um Mitarbeiter auf mehreren Seiten anzuzeigen, um die Navigation zu erleichtern.
Beenden Sie die Flask-Shell:
Um auf verschiedene Seiten zuzugreifen, verwenden Sie URL-Parameter, auch bekannt als URL-Abfragezeichenfolgen, die eine Möglichkeit sind, Informationen an die Anwendung über die URL zu übergeben. Parameter werden der Anwendung in der URL nach einem ?-Symbol übergeben. Zum Beispiel können Sie zum Übergeben eines page-Parameters mit unterschiedlichen Werten die folgenden URLs verwenden:
http://127.0.0.1:5000/?page=1
http://127.0.0.1:5000/?page=3
Hier gibt die erste URL einen Wert 1 an den URL-Parameter page weiter. Die zweite URL gibt einen Wert 3 an denselben Parameter weiter.
Öffnen Sie die Datei app.py:
Bearbeiten Sie die Index-Route wie folgt:
Hier erhalten Sie den Wert des page-URL-Parameters mithilfe des request.args-Objekts und seiner get()-Methode. Zum Beispiel wird /?page=1 den Wert 1 aus dem page-URL-Parameter abrufen. Sie geben 1 als Standardwert an und übergeben den int-Python-Typ als Argument an den type-Parameter, um sicherzustellen, dass der Wert eine Ganzzahl ist.
Als nächstes erstellen Sie ein Paginierungs-Objekt, ordnen die Abfrageergebnisse nach dem Vornamen. Sie übergeben den Wert des page-URL-Parameters an die paginate()-Methode und teilen die Ergebnisse in zwei Elemente pro Seite auf, indem Sie den Wert 2 an den per_page-Parameter übergeben.
Zuletzt übergeben Sie das erstellte Paginierungs-Objekt an das gerenderte index.html-Template.
Speichern und schließen Sie die Datei.
Als nächstes bearbeiten Sie das index.html-Template, um die Paginierungselemente anzuzeigen:
Ändern Sie den Inhalt des div-Tags, indem Sie eine h2-Überschrift hinzufügen, die die aktuelle Seite angibt, und ändern Sie die Schleife, sodass sie durch das pagination.items-Objekt anstelle des nicht mehr verfügbaren employees-Objekts iteriert:
Speichern und schließen Sie die Datei.
Wenn Sie dies noch nicht getan haben, setzen Sie die Umgebungsvariablen FLASK_APP und FLASK_ENV und starten Sie den Entwicklungsserver:
Navigieren Sie nun zur Indexseite mit unterschiedlichen Werten für den page-URL-Parameter:
http://127.0.0.1:5000/
http://127.0.0.1:5000/?page=2
http://127.0.0.1:5000/?page=4
http://127.0.0.1:5000/?page=19
Sie sehen verschiedene Seiten mit jeweils zwei Elementen und unterschiedlichen Elementen auf jeder Seite, wie Sie es zuvor in der Flask-Shell gesehen haben.
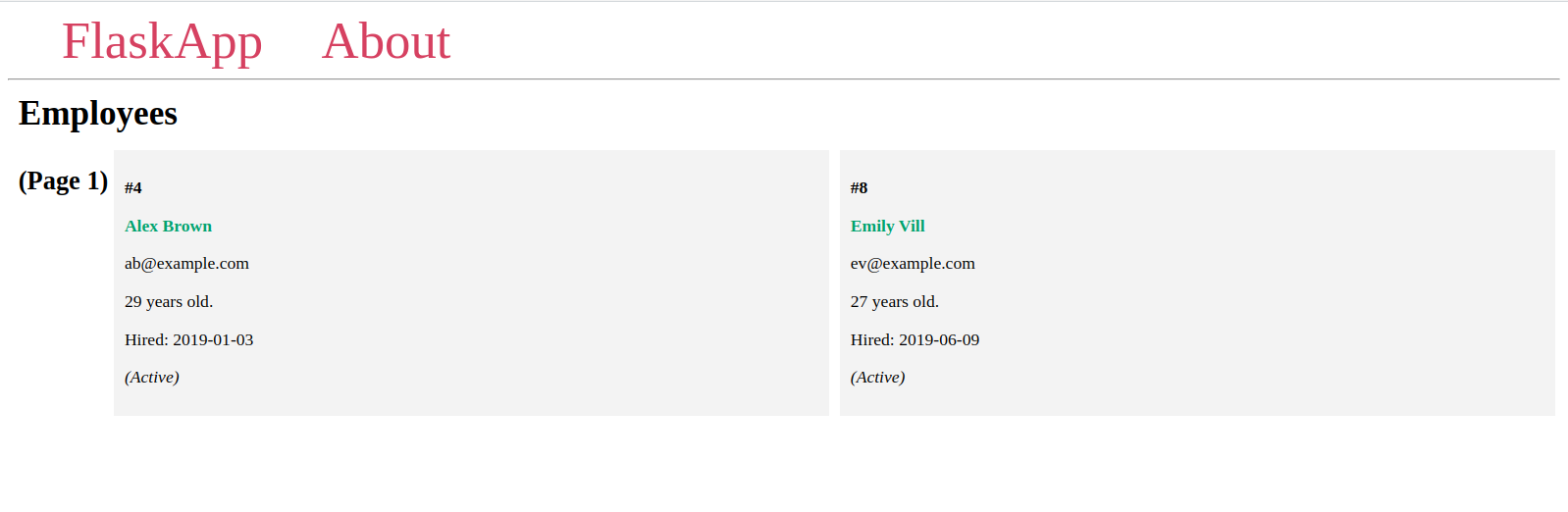
Wenn die angegebene Seitenzahl nicht existiert, erhalten Sie einen 404 Not Found HTTP-Fehler, was bei der letzten URL in der vorherigen URL-Liste der Fall ist.
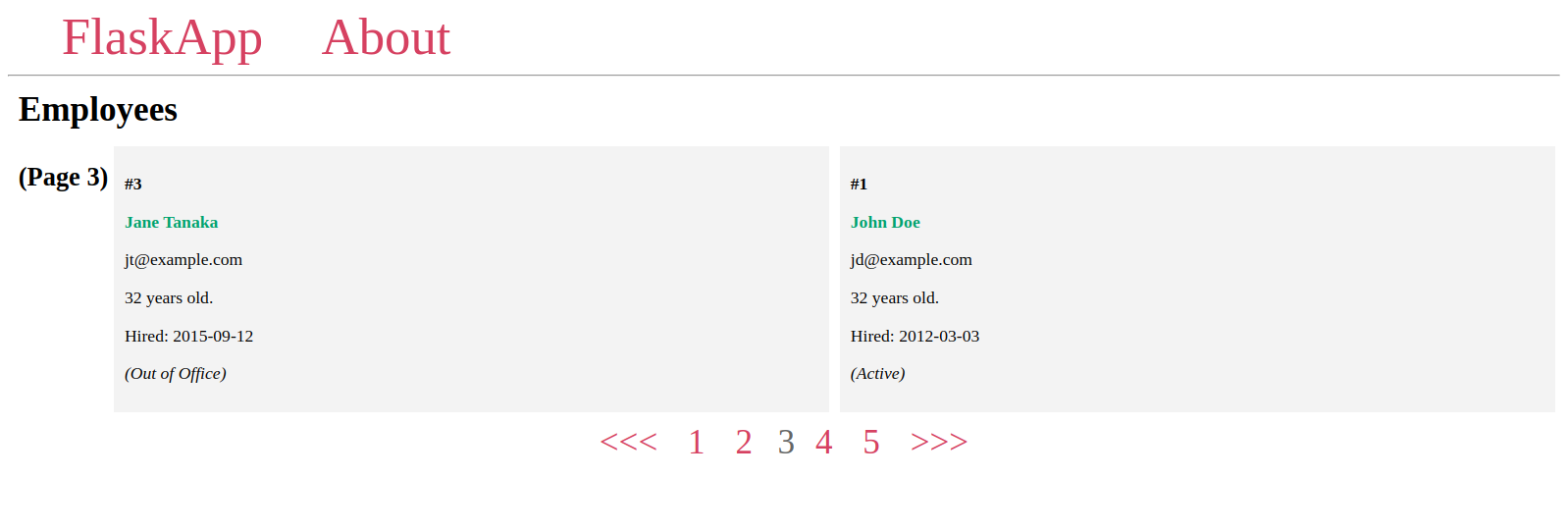
Als nächstes erstellen Sie ein Pagination-Widget zum Navigieren zwischen Seiten. Sie verwenden einige Attribute und Methoden des Pagination-Objekts, um alle Seitennummern anzuzeigen. Jede Nummer verlinkt mit ihrer eigenen Seite. Zudem fügen Sie einen <<<-Button hinzu, um zur vorherigen Seite zu gelangen, falls die aktuelle Seite eine vorherige Seite hat, und einen >>>-Button, um zur nächsten Seite zu gelangen, sofern sie existiert.
Das Pagination-Widget wird wie folgt aussehen:

Um es hinzuzufügen, öffnen Sie die Datei index.html:
Bearbeiten Sie die Datei, indem Sie den folgenden hervorgehobenen div-Tag unter dem Inhalts-div-Tag hinzufügen:
Speichern und schließen Sie die Datei.
Hier verwenden Sie die Bedingung if pagination.has_prev, um einen <<<-Link zur vorherigen Seite hinzuzufügen, wenn die aktuelle Seite nicht die erste Seite ist. Sie verlinken zur vorherigen Seite mit dem Funktionsaufruf url_for('index', page=pagination.prev_num), bei dem Sie zur Index-Ansichtsfunktion verlinken und den Wert pagination.prev_num an den page-URL-Parameter übergeben.
Um Links zu allen verfügbaren Seitennummern anzuzeigen, durchlaufen Sie die Elemente der Methode pagination.iter_pages(), die Ihnen in jeder Schleife eine Seitennummer liefert.
Sie verwenden die Bedingung if pagination.page != number, um zu überprüfen, ob die aktuelle Seitenzahl nicht mit der Zahl in der aktuellen Schleife übereinstimmt. Wenn die Bedingung wahr ist, verlinken Sie zur Seite, um dem Benutzer zu ermöglichen, die aktuelle Seite zu einer anderen Seite zu ändern. Andernfalls, wenn die aktuelle Seite mit der Schleifennummer übereinstimmt, zeigen Sie die Nummer ohne Link an. Dies ermöglicht es Benutzern, die aktuelle Seitenzahl im Paginierungselement zu kennen.
Zuletzt verwenden Sie die Bedingung pagination.has_next, um zu überprüfen, ob die aktuelle Seite eine nächste Seite hat. In diesem Fall verlinken Sie darauf mit dem Aufruf url_for('index', page=pagination.next_num) und einem Link >>>.
Navigieren Sie zu Ihrer Browser-Startseite: http://127.0.0.1:5000/
Sie sehen, dass das Paginierungselement voll funktionsfähig ist:
Hier verwenden Sie >>> für das Navigieren zur nächsten Seite und <<< für die vorherige Seite, aber Sie können auch andere Zeichen verwenden, wie z.B. > und < oder Bilder in <img>-Tags.
Sie haben Mitarbeiter auf mehreren Seiten angezeigt und gelernt, wie Sie Paginierung in Flask-SQLAlchemy handhaben. Und Sie können Ihr Paginierungselement jetzt in anderen Flask-Anwendungen verwenden, die Sie erstellen.
Schlussfolgerung
Sie haben Flask-SQLAlchemy verwendet, um ein Mitarbeiterverwaltungssystem zu erstellen. Sie haben eine Tabelle abgefragt und Ergebnisse basierend auf Spaltenwerten und einfachen und komplexen logischen Bedingungen gefiltert. Sie haben Abfrageergebnisse sortiert, gezählt und begrenzt. Und Sie haben ein Paginierungssystem erstellt, um eine bestimmte Anzahl von Datensätzen auf jeder Seite in Ihrer Webanwendung anzuzeigen und zwischen den Seiten zu navigieren.
Sie können das Gelernte aus diesem Tutorial in Kombination mit den in einigen unserer anderen Flask-SQLAlchemy-Tutorials erklärten Konzepten verwenden, um Ihrem Mitarbeiterverwaltungssystem weitere Funktionalitäten hinzuzufügen:
- So verwenden Sie Flask-SQLAlchemy, um mit Datenbanken in einer Flask-Anwendung zu interagieren, um zu lernen, wie man Mitarbeiter hinzufügt, bearbeitet oder löscht.
- So verwenden Sie One-to-Many-Datenbankbeziehungen mit Flask-SQLAlchemy, um zu lernen, wie man One-to-Many-Beziehungen verwendet, um eine Abteilungstabelle zu erstellen, um jeden Mitarbeiter mit der Abteilung zu verknüpfen, zu der er gehört.
- So verwenden Sie viele-zu-viele-Datenbankbeziehungen mit Flask-SQLAlchemy, um zu lernen, wie man viele-zu-viele-Beziehungen verwendet, um eine
tasks-Tabelle zu erstellen und sie mit deremployee-Tabelle zu verknüpfen, wobei jeder Mitarbeiter viele Aufgaben hat und jede Aufgabe mehreren Mitarbeitern zugewiesen ist.
Wenn Sie mehr über Flask erfahren möchten, schauen Sie sich die anderen Tutorials in der How To Build Web Applications with Flask-Serie an.