













Whisper AI ist ein fortschrittliches automatisches Spracherkennungsmodell (ASR), das von OpenAI entwickelt wurde und Audiowiedergaben mit beeindruckender Genauigkeit in Text umwandeln kann und mehrere Sprachen unterstützt. Obwohl Whisper AI hauptsächlich für die Stapelverarbeitung konzipiert ist, kann es für die Echtzeit-Sprach-zu-Text-Transkription auf Linux konfiguriert werden.
In diesem Leitfaden werden wir den schrittweisen Prozess der Installation, Konfiguration und Ausführung von Whisper AI für die Live-Transkription auf einem Linux-System durchgehen.
Was ist Whisper AI?
Whisper AI ist ein Open-Source-Spracherkennungsmodell, das auf einem umfangreichen Datensatz von Audioaufnahmen trainiert wurde und auf einer Deep-Learning-Architektur basiert, die es ermöglicht:
- Sprache in mehreren Sprachen zu transkribieren.
- Akzente und Hintergrundgeräusche effizient zu handhaben.
- Übersetzung gesprochener Sprache ins Englische durchzuführen.
Da es für hochgenaue Transkription konzipiert ist, wird es häufig verwendet in:
- Live-Transkriptionsdiensten (z. B. für Zugänglichkeit).
- Sprachassistenten und Automatisierung.
- Transkription von aufgezeichneten Audiodateien.
Standardmäßig ist Whisper AI nicht für die Echtzeitverarbeitung optimiert. Mit einigen zusätzlichen Tools kann es jedoch Live-Audioströme für sofortige Transkription verarbeiten.
Whisper AI Systemanforderungen
Vor der Ausführung von Whisper AI unter Linux stellen Sie sicher, dass Ihr System die folgenden Anforderungen erfüllt:
Hardware-Anforderungen:
- Prozessor: Ein Multi-Core-Prozessor (Intel/AMD).
- RAM: Mindestens 8 GB (16 GB oder mehr werden empfohlen).
- GPU: NVIDIA-GPU mit CUDA (optional, beschleunigt die Verarbeitung erheblich).
- Speicher: Mindestens 10 GB freier Festplattenspeicher für Modelle und Abhängigkeiten.
Software-Anforderungen:
- Eine Linux-Distribution wie Ubuntu, Debian, Arch, Fedora, etc.
- Python Version 3.8 oder höher.
- Pip-Paketmanager zur Installation von Python-Paketen.
- FFmpeg zur Bearbeitung von Audio-Dateien und -Streams.
Schritt 1: Installation der erforderlichen Abhängigkeiten
Bevor Sie Whisper AI installieren, aktualisieren Sie Ihre Paketliste und aktualisieren Sie vorhandene Pakete.
sudo apt update [On Ubuntu] sudo dnf update -y [On Fedora] sudo pacman -Syu [On Arch]
Anschließend müssen Sie Python 3.8 oder höher und den Pip-Paketmanager installieren, wie gezeigt.
sudo apt install python3 python3-pip python3-venv -y [On Ubuntu] sudo dnf install python3 python3-pip python3-virtualenv -y [On Fedora] sudo pacman -S python python-pip python-virtualenv [On Arch]
Zuletzt müssen Sie FFmpeg installieren, das ein Multimedia-Framework zur Verarbeitung von Audio- und Videodateien ist.
sudo apt install ffmpeg [On Ubuntu] sudo dnf install ffmpeg [On Fedora] sudo pacman -S ffmpeg [On Arch]
Schritt 2: Whisper AI in Linux installieren
Sobald die erforderlichen Abhängigkeiten installiert sind, können Sie mit der Installation von Whisper AI in einer virtuellen Umgebung fortfahren, die es Ihnen ermöglicht, Python-Pakete zu installieren, ohne die Systempakete zu beeinträchtigen.
python3 -m venv whisper_env source whisper_env/bin/activate pip install openai-whisper
Nach Abschluss der Installation überprüfen Sie, ob Whisper AI korrekt installiert wurde, indem Sie Folgendes ausführen.
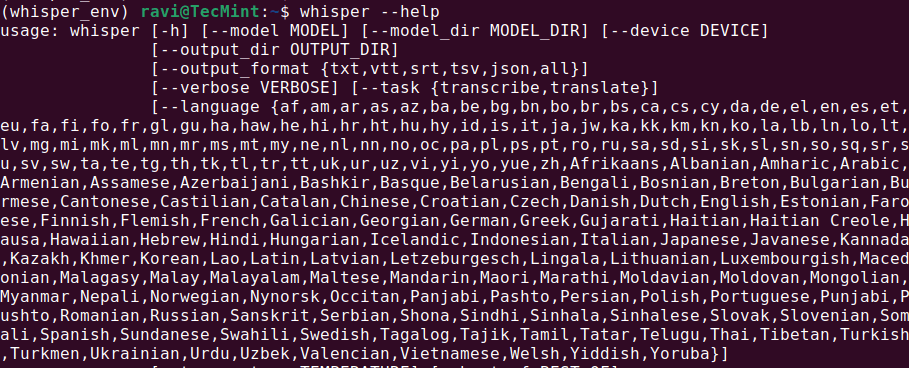
whisper --help
Dies sollte ein Hilfemenü mit verfügbaren Befehlen und Optionen anzeigen, was bedeutet, dass Whisper AI installiert und einsatzbereit ist.
Schritt 3: Whisper AI unter Linux ausführen
Nach der Installation von Whisper AI können Sie Audio-Dateien mithilfe verschiedener Befehle transkribieren.
Transkription einer Audio-Datei
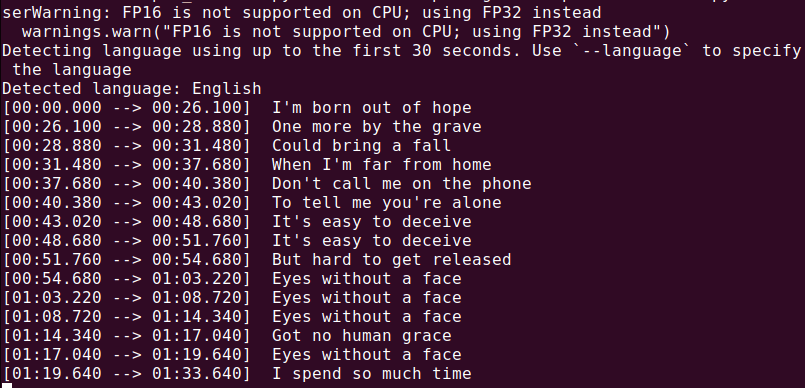
Um eine Audio-Datei (audio.mp3) zu transkribieren, führen Sie Folgendes aus:
whisper audio.mp3
Whisper wird die Datei verarbeiten und ein Transkript im Textformat generieren.
Jetzt, da alles installiert ist, erstellen wir ein Python-Skript, um Audio von Ihrem Mikrofon aufzunehmen und es in Echtzeit zu transkribieren.
nano real_time_transcription.py
Kopieren und fügen Sie den folgenden Code in die Datei ein.
import sounddevice as sd
import numpy as np
import whisper
import queue
import threading
# Load the Whisper model
model = whisper.load_model("base")
# Audio parameters
SAMPLE_RATE = 16000
BUFFER_SIZE = 1024
audio_queue = queue.Queue()
def audio_callback(indata, frames, time, status):
"""Callback function to capture audio data."""
if status:
print(status)
audio_queue.put(indata.copy())
def transcribe_audio():
"""Thread to transcribe audio in real time."""
while True:
audio_data = audio_queue.get()
audio_data = np.concatenate(list(audio_queue.queue)) # Combine buffered audio
audio_queue.queue.clear()
# Transcribe the audio
result = model.transcribe(audio_data.flatten(), language="en")
print(f"Transcription: {result['text']}")
# Start the transcription thread
transcription_thread = threading.Thread(target=transcribe_audio, daemon=True)
transcription_thread.start()
# Start capturing audio from the microphone
with sd.InputStream(callback=audio_callback, channels=1, samplerate=SAMPLE_RATE, blocksize=BUFFER_SIZE):
print("Listening... Press Ctrl+C to stop.")
try:
while True:
pass
except KeyboardInterrupt:
print("\nStopping...")
Führen Sie das Skript mit Python aus, das mit dem Lauschen auf die Eingabe Ihres Mikrofons beginnt und den transkribierten Text in Echtzeit anzeigt. Sprechen Sie deutlich in Ihr Mikrofon, und Sie sollten die Ergebnisse auf dem Terminal angezeigt bekommen.
python3 real_time_transcription.py
Abschluss
Whisper AI ist ein leistungsstarkes Sprache-zu-Text-Werkzeug, das für die Echtzeit-Transkription unter Linux angepasst werden kann. Für beste Ergebnisse verwenden Sie eine GPU und optimieren Sie Ihr System für die Echtzeitverarbeitung.
Source:
https://www.tecmint.com/whisper-ai-audio-transcription-on-linux/