













Wenn Sie mit Amazon S3 (Simple Storage Service) arbeiten, verwenden Sie wahrscheinlich die S3-Webkonsole, um Dateien von S3-Buckets herunterzuladen, zu kopieren oder hochzuladen. Die Verwendung der Konsole ist völlig in Ordnung, dafür wurde sie schließlich entwickelt.
Insbesondere für Administratoren, die eher Mausklicks als Tastaturbefehle gewohnt sind, ist die Webkonsole wahrscheinlich am einfachsten. Administratoren werden jedoch früher oder später die Notwendigkeit haben, Massenoperationen mit Dateien in Amazon S3 durchzuführen, wie beispielsweise einen unbeaufsichtigten Dateiupload. Die grafische Benutzeroberfläche ist dafür nicht das beste Werkzeug.
Für solche Automatisierungsanforderungen mit Amazon Web Services, einschließlich Amazon S3, bietet das AWS CLI-Tool Administratoren Befehlszeilenoptionen zum Verwalten von Amazon S3-Buckets und Objekten.
In diesem Artikel erfahren Sie, wie Sie das AWS CLI-Befehlszeilentool zum Hochladen, Kopieren, Herunterladen und Synchronisieren von Dateien mit Amazon S3 verwenden. Sie lernen auch die Grundlagen für die Bereitstellung des Zugriffs auf Ihren S3-Bucket und die Konfiguration dieses Zugriffsprofils für die Arbeit mit dem AWS CLI-Tool.
Voraussetzungen
Da es sich um einen Anleitung-Artikel handelt, wird es in den folgenden Abschnitten Beispiele und Demonstrationen geben. Damit Sie erfolgreich mitmachen können, müssen Sie mehrere Voraussetzungen erfüllen.
- Ein AWS-Konto. Wenn Sie noch kein bestehendes AWS-Abonnement haben, können Sie sich für eine AWS Free Tier registrieren.
- Ein AWS S3-Bucket. Sie können einen vorhandenen Bucket verwenden, wenn Sie möchten. Es wird jedoch empfohlen, stattdessen einen leeren Bucket zu erstellen. Bitte beachten Sie Erstellen eines Buckets.
- A Windows 10 computer with at least Windows PowerShell 5.1. In this article, PowerShell 7.0.2 will be used.
- Das Tool AWS CLI Version 2 muss auf Ihrem Computer installiert sein.
- Lokale Ordner und Dateien, die Sie mit Amazon S3 hochladen oder synchronisieren möchten
Vorbereitung Ihres AWS S3-Zugriffs
Nehmen wir an, Sie haben bereits die Voraussetzungen erfüllt. Sie denken, Sie können bereits mit AWS CLI und Ihrem S3-Bucket arbeiten. Das wäre doch schön, oder?
Für diejenigen von Ihnen, die gerade erst mit Amazon S3 oder AWS im Allgemeinen anfangen, soll Ihnen dieser Abschnitt dabei helfen, den Zugriff auf S3 einzurichten und ein AWS CLI-Profil zu konfigurieren.
Die vollständige Dokumentation zum Erstellen eines IAM-Benutzers in AWS finden Sie in folgendem Link. Erstellen eines IAM-Benutzers in Ihrem AWS-Konto
Erstellen eines IAM-Benutzers mit S3-Zugriffsberechtigung
Wenn Sie auf AWS mit der CLI zugreifen möchten, müssen Sie einen oder mehrere IAM-Benutzer mit ausreichendem Zugriff auf die Ressourcen erstellen, mit denen Sie arbeiten möchten. In diesem Abschnitt erstellen Sie einen IAM-Benutzer mit Zugriff auf Amazon S3.
Um einen IAM-Benutzer mit Zugriff auf Amazon S3 zu erstellen, müssen Sie sich zuerst in Ihre AWS IAM-Konsole anmelden. Klicken Sie unter der Gruppe Zugriffsverwaltung auf Benutzer. Klicken Sie dann auf Benutzer hinzufügen.
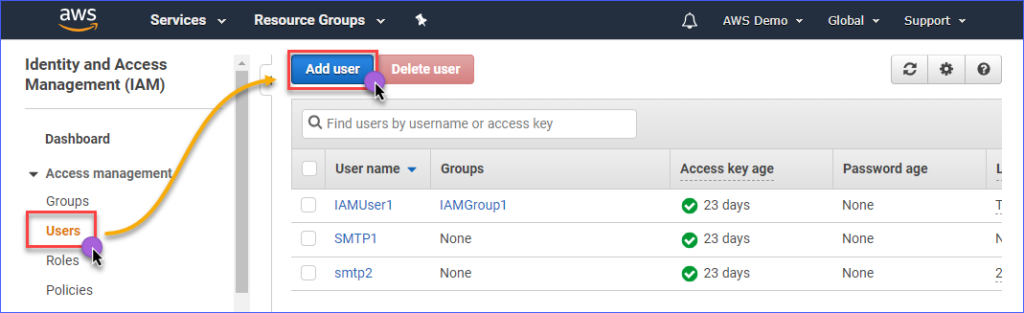
Geben Sie den Namen des IAM-Benutzers, den Sie erstellen möchten, in das Feld Benutzername* ein, z. B. s3Admin. Wählen Sie unter Zugriffstyp* Programmatischer Zugriff aus. Klicken Sie dann auf die Schaltfläche Weiter: Berechtigungen.

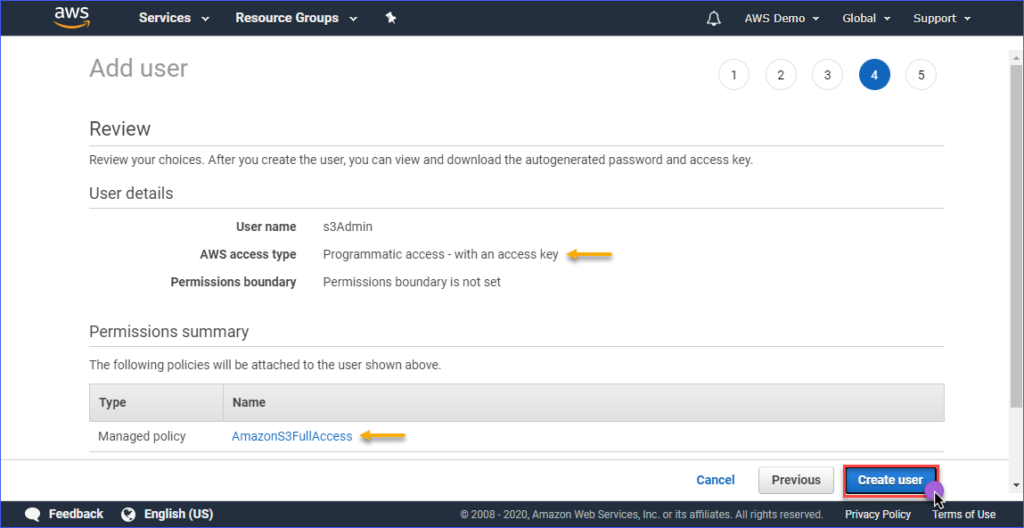
Klicken Sie als nächstes auf Vorhandene Richtlinien direkt anhängen. Suchen Sie nach dem Namen der Richtlinie AmazonS3FullAccess und setzen Sie ein Häkchen. Wenn Sie fertig sind, klicken Sie auf Weiter: Tags.

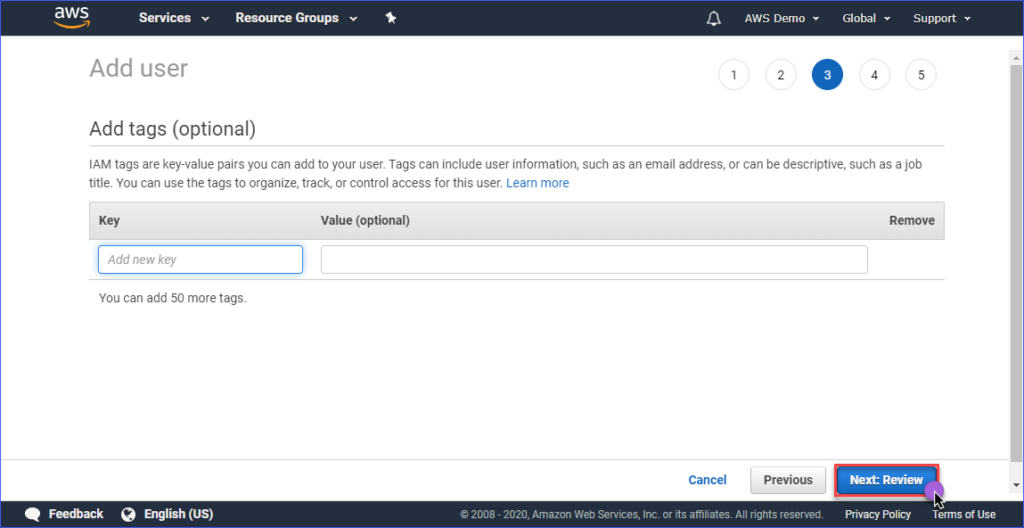
Das Erstellen von Tags ist optional auf der Seite Tags hinzufügen, Sie können dies überspringen und auf die Schaltfläche Weiter: Überprüfen klicken.
Auf der Seite Überprüfen erhalten Sie eine Zusammenfassung des neuen Benutzerkontos. Klicken Sie auf Benutzer erstellen.
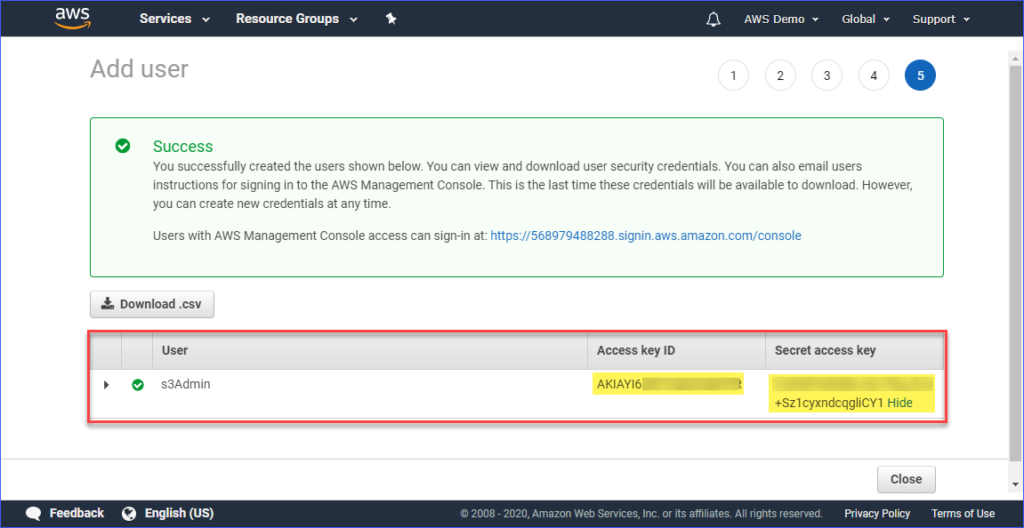
Sobald der Benutzer erstellt ist, müssen Sie den Zugriffsschlüssel-ID und den Geheimen Zugriffsschlüssel kopieren und für später speichern. Beachten Sie, dass dies der einzige Zeitpunkt ist, an dem Sie diese Werte sehen können.
Einrichten eines AWS-Profils auf Ihrem Computer
Jetzt, da Sie den IAM-Benutzer mit dem entsprechenden Zugriff auf Amazon S3 erstellt haben, ist der nächste Schritt das Einrichten des AWS CLI-Profils auf Ihrem Computer.
Dieser Abschnitt setzt voraus, dass Sie bereits das AWS CLI Version 2-Tool installiert haben, wie erforderlich. Für die Profilerstellung benötigen Sie folgende Informationen:
- Die Zugriffsschlüssel-ID des IAM-Benutzers.
- Der geheime Zugriffsschlüssel, der mit dem IAM-Benutzer verbunden ist.
- Der Standardregion-Name entspricht dem Standort Ihres AWS S3-Buckets. Sie können die Liste der Endpunkte über diesen Link überprüfen. In diesem Artikel befindet sich der AWS S3-Bucket in der Asia Pacific (Sydney)-Region und der entsprechende Endpunkt ist ap-southeast-2.
- Das Standardausgabeformat. Verwenden Sie hierfür JSON.
Um das Profil zu erstellen, öffnen Sie PowerShell und geben Sie den folgenden Befehl ein. Befolgen Sie die Anweisungen.
Geben Sie die Zugriffsschlüssel-ID, den geheimen Zugriffsschlüssel, den Standardregion-Namen und den Standardausgabename ein. Sehen Sie sich die folgende Demonstration an.

Testen des AWS CLI-Zugriffs
Nachdem Sie das AWS CLI-Profil konfiguriert haben, können Sie mit dem Ausführen des folgenden Befehls in PowerShell bestätigen, dass das Profil funktioniert.
Der oben genannte Befehl sollte die Amazon S3-Buckets auflisten, die Sie in Ihrem Konto haben. Die folgende Demonstration zeigt den Befehl in Aktion. Das Ergebnis zeigt, dass die Profilkonfiguration erfolgreich war.

Um mehr über die AWS CLI-Befehle spezifisch für Amazon S3 zu erfahren, besuchen Sie bitte die Seite AWS CLI-Befehlsreferenz S3.
Dateiverwaltung in S3
Mit AWS CLI können typische Dateiverwaltungsvorgänge wie das Hochladen von Dateien in S3, das Herunterladen von Dateien aus S3, das Löschen von Objekten in S3 und das Kopieren von S3-Objekten an einen anderen S3-Speicherort durchgeführt werden. Es geht nur darum, den richtigen Befehl, die richtige Syntax, Parameter und Optionen zu kennen.
In den folgenden Abschnitten besteht die verwendete Umgebung aus folgendem:
- Zwei S3-Buckets, nämlich atasync1 und atasync2. Der Screenshot unten zeigt die vorhandenen S3-Buckets in der Amazon S3-Konsole.
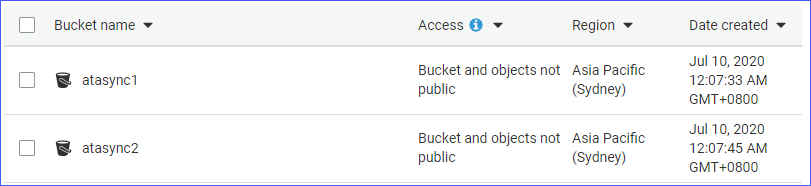
- Lokales Verzeichnis und Dateien unter c:\sync.

Einzeldateien in S3 hochladen
Beim Hochladen von Dateien in S3 können Sie entweder eine Datei nach der anderen hochladen oder mehrere Dateien und Ordner rekursiv hochladen. Je nach Anforderungen können Sie diejenige Methode wählen, die Sie für angemessen halten.
Um eine Datei in S3 hochzuladen, müssen Sie dem Befehl aws s3 cp zwei Argumente (Quelle und Ziel) angeben.
Zum Beispiel können Sie mit dem folgenden Befehl die Datei c:\sync\logs\log1.xml in das Stammverzeichnis des Buckets atasync1 hochladen.
Hinweis: S3-Bucket-Namen werden immer mit S3:// vorangestellt, wenn sie mit AWS CLI verwendet werden
Führen Sie den obigen Befehl in PowerShell aus, ändern Sie jedoch zuerst die Quelle und das Ziel, die Ihrer Umgebung entsprechen. Die Ausgabe sollte ähnlich aussehen wie in der folgenden Demonstration.

Die obige Demo zeigt, dass die Datei mit dem Namen c:\sync\logs\log1.xml fehlerfrei zum S3-Ziel s3://atasync1/ hochgeladen wurde.
Verwenden Sie den folgenden Befehl, um die Objekte im Stammverzeichnis des S3-Buckets aufzulisten.
Wenn Sie den obigen Befehl in PowerShell ausführen, erhalten Sie eine ähnliche Ausgabe wie in der folgenden Demonstration gezeigt. Wie Sie in der unten stehenden Ausgabe sehen können, befindet sich die Datei log1.xml im Stammverzeichnis des S3-Speicherorts.

Mehrere Dateien und Ordner rekursiv nach S3 hochladen
Der vorherige Abschnitt hat gezeigt, wie Sie eine einzelne Datei an einen S3-Speicherort kopieren. Was ist, wenn Sie mehrere Dateien aus einem Ordner und Unterverzeichnissen hochladen müssen? Sie möchten sicherlich nicht den gleichen Befehl mehrmals für verschiedene Dateinamen ausführen, oder?
Der Befehl aws s3 cp verfügt über eine Option zur rekursiven Verarbeitung von Dateien und Ordnern, nämlich die Option --recursive.
Als Beispiel enthält das Verzeichnis c:\sync 166 Objekte (Dateien und Unterverzeichnisse).
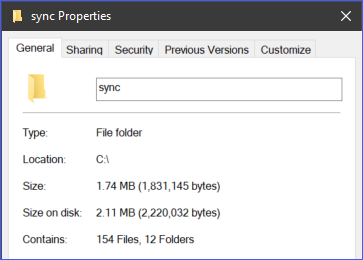
Mit der Option --recursive werden alle Inhalte des Ordners c:\sync auf S3 hochgeladen und dabei die Ordnerstruktur beibehalten. Zum Testen verwenden Sie den untenstehenden Beispielcode, ändern Sie jedoch die Quelle und das Ziel entsprechend Ihrer Umgebung.
Sie werden feststellen, dass im untenstehenden Code die Quelle c:\sync ist und das Ziel s3://atasync1/sync ist. Der /sync-Schlüssel, der auf den S3-Bucket-Namen folgt, gibt dem AWS CLI an, die Dateien im /sync-Ordner in S3 hochzuladen. Wenn der /sync-Ordner in S3 nicht vorhanden ist, wird er automatisch erstellt.
Der obige Code führt zu der Ausgabe, wie im folgenden Beispiel gezeigt.

Mehrere Dateien und Ordner selektiv auf S3 hochladen
In einigen Fällen ist es nicht die beste Option, ALLE Arten von Dateien hochzuladen. Zum Beispiel, wenn Sie nur Dateien mit bestimmten Dateierweiterungen (z. B. *.ps1) hochladen müssen. Zwei weitere Optionen, die für den cp-Befehl verfügbar sind, sind --include und --exclude.
Während der Befehl in der vorherigen Sektion alle Dateien im rekursiven Upload einschließt, werden im folgenden Befehl nur die Dateien eingeschlossen, die der Dateierweiterung *.ps1 entsprechen, und alle anderen Dateien werden vom Upload ausgeschlossen.
Das folgende Beispiel zeigt, wie der obige Code bei der Ausführung funktioniert.

Ein weiteres Beispiel ist, wenn Sie mehrere verschiedene Dateierweiterungen einschließen möchten, müssen Sie die --include-Option mehrmals angeben.
Der folgende Beispielbefehl schließt nur die *.csv– und *.png-Dateien in den Kopierbefehl ein.
Wenn Sie den obigen Code in PowerShell ausführen, erhalten Sie ein ähnliches Ergebnis, wie unten gezeigt.

Objekte von S3 herunterladen
Basierend auf den Beispielen, die Sie in diesem Abschnitt gelernt haben, können Sie auch die Kopiervorgänge umkehren. Das bedeutet, Sie können Objekte von der S3-Bucket-Position auf den lokalen Computer herunterladen.
Um von S3 auf den lokalen Speicher zu kopieren, müssen Sie die Positionen von Quelle und Ziel vertauschen. Die Quelle ist der S3-Speicherort und das Ziel ist der lokale Pfad, wie im folgenden Beispiel gezeigt.
Beachten Sie, dass dieselben Optionen, die beim Hochladen von Dateien in S3 verwendet werden, auch beim Herunterladen von Objekten von S3 auf den lokalen Speicher verwendet werden können. Zum Beispiel können Sie alle Objekte mit dem Befehl unten und der Option --recursive herunterladen.
Kopieren von Objekten zwischen S3-Speicherorten
Neben dem Hochladen und Herunterladen von Dateien und Ordnern können Sie mit AWS CLI auch Dateien zwischen zwei S3-Bucket-Speicherorten kopieren oder verschieben.
Der folgende Befehl verwendet einen S3-Speicherort als Quelle und einen anderen S3-Speicherort als Ziel.
Die folgende Demonstration zeigt, wie die Quelldatei mit dem oben genannten Befehl an einen anderen S3-Speicherort kopiert wird.

Dateien und Ordner mit S3 synchronisieren
Sie haben bisher gelernt, wie Sie Dateien in S3 mithilfe der AWS CLI-Befehle hochladen, herunterladen und kopieren können. In diesem Abschnitt erfahren Sie mehr über einen weiteren Dateioperation-Befehl, der in AWS CLI für S3 verfügbar ist: den sync-Befehl. Der sync-Befehl verarbeitet nur aktualisierte, neue und gelöschte Dateien.
Es gibt einige Fälle, in denen Sie den Inhalt eines S3-Buckets aktualisiert und mit einem lokalen Verzeichnis auf einem Server synchronisiert halten müssen. Zum Beispiel kann es erforderlich sein, Transaktionsprotokolle auf einem Server in regelmäßigen Abständen mit S3 synchronisiert zu halten.
Mit dem untenstehenden Befehl werden alle *.XML-Protokolldateien, die sich im lokalen Verzeichnis c:\sync auf dem Server befinden, mit dem S3-Speicherort s3://atasync1 synchronisiert.
In der untenstehenden Demonstration sehen Sie, dass nach Ausführung des oben genannten Befehls in PowerShell alle *.XML-Dateien in das S3-Zielverzeichnis s3://atasync1/ hochgeladen wurden.

Synchronisieren neuer und aktualisierter Dateien mit S3
In diesem nächsten Beispiel wird angenommen, dass der Inhalt der Protokolldatei Log1.xml geändert wurde. Der sync-Befehl sollte diese Änderung erkennen und die Änderungen an der lokalen Datei in S3 hochladen, wie in der folgenden Demonstration gezeigt.
Der Befehl, der verwendet werden soll, ist immer noch derselbe wie im vorherigen Beispiel.

Wie aus der obigen Ausgabe ersichtlich ist, wurde nur die Datei Log1.xml lokal geändert und daher auch nur diese Datei mit S3 synchronisiert.
Synchronisieren von Löschungen mit S3
Standardmäßig werden beim sync-Befehl Löschungen nicht verarbeitet. Eine Datei, die am Quellort gelöscht wurde, wird nicht am Zielort entfernt. Es sei denn, Sie verwenden die Option --delete.
In diesem nächsten Beispiel wurde die Datei mit dem Namen Log5.xml aus der Quelle gelöscht. Der Befehl zum Synchronisieren der Dateien wird um die Option --delete erweitert, wie im folgenden Code gezeigt.
Wenn Sie den oben genannten Befehl in PowerShell ausführen, sollte auch die gelöschte Datei mit dem Namen Log5.xml am Zielort S3 gelöscht werden. Das Beispielergebnis wird unten angezeigt.

Zusammenfassung
Amazon S3 ist eine ausgezeichnete Ressource zum Speichern von Dateien in der Cloud. Mit Hilfe des AWS CLI-Tools wird die Nutzung von Amazon S3 weiter ausgebaut und eröffnet die Möglichkeit, Ihre Prozesse zu automatisieren.
In diesem Artikel haben Sie gelernt, wie Sie das AWS CLI-Tool verwenden, um Dateien und Ordner zwischen lokalen Speicherorten und S3-Buckets hochzuladen, herunterzuladen und zu synchronisieren. Sie haben auch gelernt, dass der Inhalt von S3-Buckets auch in andere S3-Standorte kopiert oder verschoben werden kann.
Es gibt viele weitere Anwendungsszenarien für die Verwendung des AWS CLI-Tools zur Automatisierung der Dateiverwaltung mit Amazon S3. Sie können es sogar mit PowerShell-Skripting kombinieren und Ihre eigenen Tools oder Module erstellen, die wiederverwendbar sind. Es liegt an Ihnen, diese Möglichkeiten zu finden und Ihre Fähigkeiten zu präsentieren.