













VAR-As-A-Service ist ein MLOps Ansatz zur Vereinheitlichung und Wiederverwendung von statistischen Modellen und Pipelines zur Bereitstellung von maschinellem Lernen. Es handelt sich um den zweiten Teil einer Artikelserie, die auf diesem Projekt aufbaut und Experimente mit verschiedenen statistischen und maschinellen Lernmodellen, Datenpipelines, die mithilfe vorhandener DAG Tools implementiert wurden, und Speicherdiensten, sowohl cloudbasiert als auch alternativen lokalen Lösungen, darstellt. Dieser Artikel konzentriert sich auf die Modelldateispeicherung unter Verwendung eines Ansatzes, der auch für maschinelle Lernmodelle anwendbar und verwendet wird. Der implementierte Speicher basiert auf MinIO als AWS S3-kompatiblem Objektspeicherdienst. Darüber hinaus gibt der Artikel einen Überblick über alternative Speicherlösungen und zeigt die Vorteile des objektbasierten Speichers auf.
Der erste Artikel der Serie (Zeitreihenanalyse: VARMAX-As-A-Service) vergleicht statistische und maschinelle Lernmodelle als mathematische Modelle und bietet eine End-to-End-Implementierung eines VARMAX-basierten statistischen Modells zur makroökonomischen Prognose unter Verwendung einer Python-Bibliothek namens statsmodels. Das Modell wird als REST-Dienst mithilfe von Python Flask und dem Apache Webserver bereitgestellt, in einem Docker-Container verpackt. Die hochlevel Architektur der Anwendung ist in folgendem Bild dargestellt:
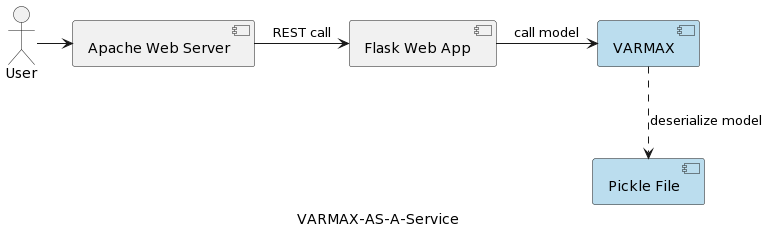
Der Modell ist als Pickle-Datei serialisiert und auf dem Webserver als Teil des REST-Dienstpakets bereitgestellt. In echten Projekten werden jedoch Modelle versioniert, begleitet von Metadateninformationen, gesichert, und die Trainingsexperimente müssen protokolliert und reproduzierbar gehalten werden. Darüber hinaus widerspricht das Speichern des Modells im Dateisystem neben der Anwendung aus architektonischer Sicht dem Prinzip der Einhaltung der einzelnen Verantwortung. Ein gutes Beispiel ist eine auf Microservices basierende Architektur. Das horizontale Skalieren des Modellservices bedeutet, dass jede Instanz des Microservices ihre eigene Version der physischen Pickle-Datei über alle Dienstinstanzen repliziert. Das bedeutet auch, dass die Unterstützung mehrerer Modelle Versionen erforderlich ist eine neue Version und erneute Bereitstellung des REST-Diensts und seiner Infrastruktur. Das Ziel dieses Artikels ist es, Modelle von der Webdienstinfrastruktur zu entkoppeln und die Wiederverwendung der Webservice-Logik mit verschiedenen Modellversionen zu ermöglichen.
Bevor wir uns der Implementierung widmen, wollen wir einige Worte über statistische Modelle und das in diesem Projekt verwendete VAR-Modell sagen. Statistische Modelle sind mathematische Modelle, genau wie maschinelle Lernmodelle. Weitere Informationen über den Unterschied zwischen den beiden finden Sie im ersten Artikel der Serie. Ein statistisches Modell wird normalerweise als mathematische Beziehung zwischen einer oder mehreren Zufallsvariablen und anderen nicht zufälligen Variablen spezifiziert. Vektorautoregression (VAR) ist ein statistisches Modell, das verwendet wird, um die Beziehung zwischen mehreren Größen bei ihrer zeitlichen Änderung zu erfassen. VAR-Modelle verallgemeinern das eindimensionale autoregressive Modell (AR), indem sie für multivariate Zeitreihen zugelassen werden. Im vorgestellten Projekt wird das Modell trainiert, um Prognosen für zwei Variablen zu erstellen. VAR-Modelle werden häufig in der Wirtschaftswissenschaft und den Naturwissenschaften eingesetzt. Im Allgemeinen wird das Modell durch ein System von Gleichungen dargestellt, die im Projekt hinter der Python-Bibliothek statsmodels verborgen sind.
Die Architektur der VAR-Modell-Dienstanwendung ist in folgendem Bild dargestellt:
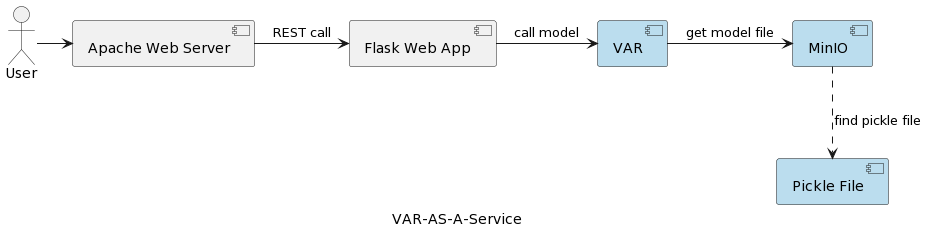
Der VAR-Laufzeitkomponente steht die tatsächliche Modellausführung basierend auf Parametern, die vom Benutzer gesendet werden. Sie verbindet sich über eine REST-Schnittstelle mit einem MinIO-Dienst, lädt das Modell und führt die Vorhersage aus. Im Vergleich zur Lösung im ersten Artikel, bei der das VARMAX-Modell beim Anwendungsstart geladen und deserialisiert wird, wird das VAR-Modell bei jedem Auslösen einer Vorhersage aus dem MinIO-Server gelesen. Dies hat den Nachteil eines zusätzlichen Lade- und Deserialisierungsaufwands, bietet aber auch den Vorteil, dass bei jeder einzelnen Ausführung die aktuellste Version des bereitgestellten Modells verwendet wird. Darüber hinaus ermöglicht es eine dynamische Versionsverwaltung von Modellen, die für externe Systeme und Endbenutzer automatisch zugänglich sind, wie später im Artikel gezeigt wird. Beachten Sie, dass aufgrund dieses Ladeaufwands die Leistung des ausgewählten Speicherdiensts von großer Bedeutung ist.
Aber warum MinIO und objektbasiertes Speicherung im Allgemeinen?
MinIO ist eine leistungsstarke Objektspeicherlösung mit nativer Unterstützung für Kubernetes-Bereitstellungen, die eine Amazon Web Services S3-kompatible API bietet und alle Kern-S3-Funktionen unterstützt. Im vorgestellten Projekt wird MinIO im Standalone-Modus betrieben, bestehend aus einem einzelnen MinIO-Server und einer einzelnen Festplatte oder Speichervolumina unter Linux mit Docker Compose. Für erweiterte Entwicklungs- oder Produktionsumgebungen steht die Option für ein verteiltes Modus zur Verfügung, wie im Artikel Deploy MinIO in Distributed Mode beschrieben.
Schauen wir uns kurz einige Speicheralternativen an, während eine umfassende Beschreibung hier und hier zu finden ist:
- Lokales/Verteiltes Dateispeicherung: Lokale Dateispeicherung ist die in der ersten Artikel implementierte Lösung, da sie die einfachste Option ist. Berechnung und Speicherung erfolgen auf demselben System. Es ist akzeptabel während der PoC-Phase oder für sehr einfache Modelle, die eine einzige Version des Modells unterstützen. Lokale Dateisysteme haben begrenzte Speicherkapazität und sind für größere Datensätze ungeeignet, wenn wir zusätzliche Metadaten wie den verwendeten Trainingsdatensatz speichern möchten. Da es keine Replikation oder Automatische Skalierung gibt, kann ein lokales Dateisystem nicht in einer verfügbaren, zuverlässigen und skalierbaren Weise arbeiten. Jeder für die horizontale Skalierung bereitgestellte Dienst wird mit seiner eigenen Kopie des Modells bereitgestellt. Darüber hinaus ist der lokale Speicher so sicher wie das Hostsystem. Alternativen zum lokalen Dateispeicher sind NAS (Netzwerk-anbieter Speicher), SAN (Storage-area network), verteilte Dateisysteme (Hadoop Distributed File System (HDFS), Google File System (GFS), Amazon Elastic File System (EFS) und Azure Files). Im Vergleich zum lokalen Dateisystem zeichnen sich diese Lösungen durch Verfügbarkeit, Skalierbarkeit und Robustheit aus, verursachen jedoch den Nachteil einer erhöhten Komplexität.
- Relationale Datenbanken: Aufgrund der binären Serialisierung von Modellen bieten relationale Datenbanken die Möglichkeit, Modelle als Blob oder binäre Daten in Spalten von Tabellen zu speichern. Softwareentwickler und viele Datenwissenschaftler sind mit relationalen Datenbanken vertraut, was diese Lösung unkompliziert macht. Modellversionen können als separate Tabellenzeilen mit zusätzlichen Metadaten gespeichert werden, die auch leicht aus der Datenbank gelesen werden können. Ein Nachteil ist, dass die Datenbank mehr Speicherplatz benötigt und dies Auswirkungen auf Sicherungen hat. Das Vorhandensein großer Mengen binärer Daten in einer Datenbank kann auch Auswirkungen auf die Leistung haben. Darüber hinaus setzen relationale Datenbanken einige Einschränkungen an die Datenstrukturen, was das Speichern heterogener Daten wie CSV-Dateien, Bilder und JSON-Dateien als Modellmetadaten erschweren könnte.
- Objektspeicherung: Objektspeicherung gibt es bereits seit einiger Zeit, wurde jedoch revolutioniert, als Amazon sie 2006 mit Simple Storage Service (S3) zum ersten AWS-Dienst machte. Moderne Objektspeicherung ist nativ für die Cloud, und andere Cloud-Anbieter brachten bald auch ihre Angebote auf den Markt. Microsoft bietet Azure Blob Storage und Google sein Google Cloud Storage-Angebot. Die S3-API ist die De-facto-Standard-Schnittstelle für Entwickler, um mit Speicher in der Cloud zu interagieren, und es gibt mehrere Unternehmen, die S3-kompatiblen Speicher für die öffentliche Cloud, private Cloud und private On-Premises-Lösungen anbieten. Unabhängig davon, wo sich ein Objektspeicher befindet, wird er über eine RESTful-Schnittstelle zugegriffen. Während Objektspeicher die Notwendigkeit für Verzeichnisse, Ordner und andere komplexe hierarchische Organisationen beseitigen, ist es keine gute Lösung für dynamische Daten, die sich ständig ändern, da man das gesamte Objekt neu schreiben muss, um es zu ändern, aber es ist eine gute Wahl für die Speicherung von serialisierten Modellen und der Modellmetadaten.
A summary of the main benefits of object storage are:
- Massive Skalierbarkeit: Die Größe von Objektspeicher ist im Wesentlichen grenzenlos, sodass Daten einfach durch Hinzufügen neuer Geräte auf Exabyte skaliert werden können. Objektspeicherlösungen funktionieren auch am besten, wenn sie als verteiltes Cluster ausgeführt werden.
- Verminderte Komplexität: Daten werden in einer flachen Struktur gespeichert. Das Fehlen komplexer Bäume oder Partitionen (keine Ordner oder Verzeichnisse) reduziert die Komplexität des Dateizugriffs, da man die genaue Position nicht kennen muss.
- Suchbarkeit: Metadaten sind Teil von Objekten, was das Durchsuchen und Navigieren ohne die Notwendigkeit einer separaten Anwendung erleichtert. Man kann Objekte mit Attributen und Informationen wie Verbrauch, Kosten und Richtlinien für automatisierte Löschung, Beibehaltung und Schichtung versehen. Aufgrund des flachen Adressraums des zugrunde liegenden Speichers (jedes Objekt befindet sich in nur einem Bucket und es gibt keine Buckets innerhalb von Buckets) können Objektspeicher ein Objekt unter potentiell Milliarden von Objekten schnell finden.
- Resilienz: Objektspeicher können Daten automatisch replizieren und es auf mehreren Geräten und geografischen Standorten speichern. Dies kann dazu beitragen, Ausfälle zu verhindern, Datenverluste abzuwenden und Unterstützung für Disaster-Recovery-Strategien zu bieten.
- Einfachheit: Die Verwendung einer REST-API zum Speichern und Abrufen von Modellen impliziert fast keinen Lernaufwand und macht die Integrationen in auf Microservices basierenden Architekturen zu einer natürlichen Wahl.
Es ist an der Zeit, die Implementierung des VAR-Modells als Dienst und die Integration mit MinIO zu betrachten. Die Bereitstellung der vorgestellten Lösung wird durch die Verwendung von Docker und Docker Compose vereinfacht. Die Organisation des gesamten Projekts sieht wie folgt aus:

Wie im ersten Artikel besteht die Vorbereitung des Modells aus einigen Schritten, die in einem Python-Skript namens var_model.py geschrieben sind und sich in einem dedizierten GitHub-Repository :
- Laden der Daten
- Teilen der Daten in Trainings- und Testdatensatz
- Vorbereiten der endogenen Variablen
- Suchen der optimalen Modellparameter p (ersten p Verzögerungen jeder Variablen als Regressionsprädiktoren verwendet)
- Instanziieren des Modells mit den identifizierten optimalen Parametern
- Serialisieren des instanziierten Modells in eine Pickle-Datei
- Speichern der Pickle-Datei als versioniertes Objekt in einem MinIO-Bucket
Diese Schritte können auch als Aufgaben in einem Workflow-Engine (z.B. Apache Airflow) implementiert werden, die durch die Notwendigkeit ausgelöst wird, eine neue Modellversion mit aktuelleren Daten zu trainieren. DAGs und ihre Anwendungen in MLOps werden Gegenstand eines weiteren Artikels sein.
Der letzte Schritt in var_model.py besteht darin, das serialisierte Modell als Pickle-Datei in einem Bucket in S3 zu speichern. Aufgrund der flachen Struktur der Objektspeicherung wird das gewählte Format:
<Bucket-Name>/<Dateiname>
Allerdings ist es bei Dateinamen erlaubt, einen Schrägstrich zu verwenden, um eine hierarchische Struktur nachzuahmen, während man den Vorteil einer schnellen linearen Suche beibehält. Die Konvention zur Speicherung von VAR-Modellen lautet wie folgt:
models/var/0_0_1/model.pkl
Hierbei ist der Bucket-Name models, und der Dateiname lautet var/0_0_1/model.pkl. In der MinIO-Benutzeroberfläche sieht es folgendermaßen aus:

Dies ist eine sehr praktische Methode zur Strukturierung verschiedener Arten von Modellen und Modellversionen, während man noch die Leistungsfähigkeit und Einfachheit von flachem Dateispeicher nutzt.
Beachten Sie, dass das Versionsverwaltung von Modellen als Teil des Modellnamens implementiert ist. MinIO bietet zwar auch die Versionsverwaltung von Dateien, aber der hier gewählte Ansatz hat einige Vorteile:
- Unterstützung von Snapshot-Versionen und Überschreibung
- Verwendung von semantischer Versionsverwaltung (Punkte durch Unterstriche ersetzt aufgrund von Einschränkungen)
- Größere Kontrolle über die Strategie der Versionsverwaltung
- Entkopplung des zugrunde liegenden Speichersystems in Bezug auf spezifische Versionsverwaltungsfunktionen
Sobald das Modell bereitgestellt ist, wird es als REST-Dienst mithilfe von Flask freigegeben und mithilfe von docker-compose, das MinIO und einen Apache-Webserver ausführt, bereitgestellt. Die Docker-Bilder sowie der Modellcode sind in einem dedizierten GitHub-Repository verfügbar.
Und schließlich sind die erforderlichen Schritte zum Ausführen der Anwendung:
- Anwendung bereitstellen:
docker-compose up -d - Ausführen des Modellvorbereitungsalgorithmus:
python var_model.py(erfordert einen laufenden MinIO-Dienst) - Überprüfen, ob das Modell bereits bereitgestellt wurde: http://127.0.0.1:9101/browser
- Testen des Modells:
http://127.0.0.1:80/apidocs
Nach der Bereitstellung des Projekts ist die Swagger-API über <host>:<port>/apidocs (z.B. 127.0.0.1:80/apidocs) erreichbar. Es gibt einen Endpunkt für das VAR-Modell, der neben den anderen beiden ein VARMAX-Modell offenbart:
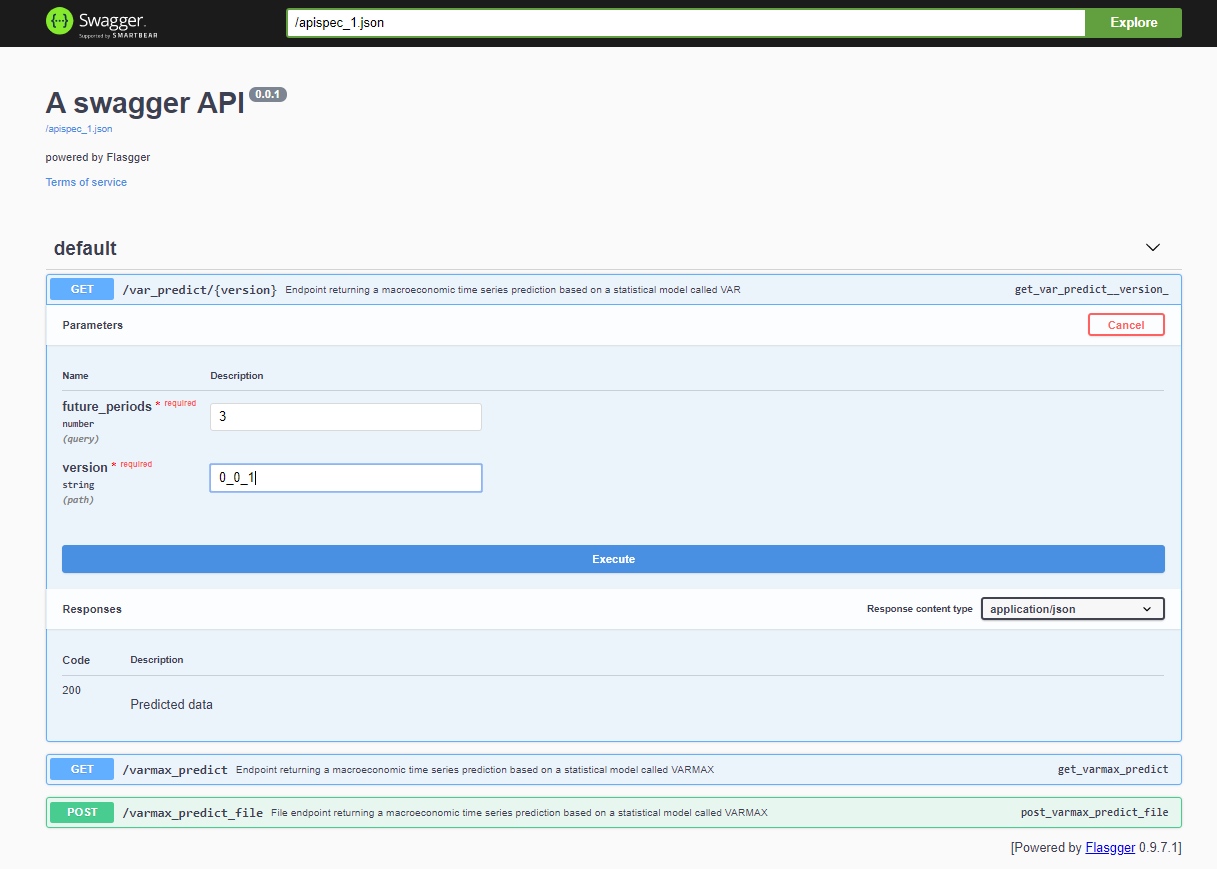
Intern verwendet der Dienst die deserialisierte Modell-Pickle-Datei, die aus einem MinIO-Dienst geladen wird:
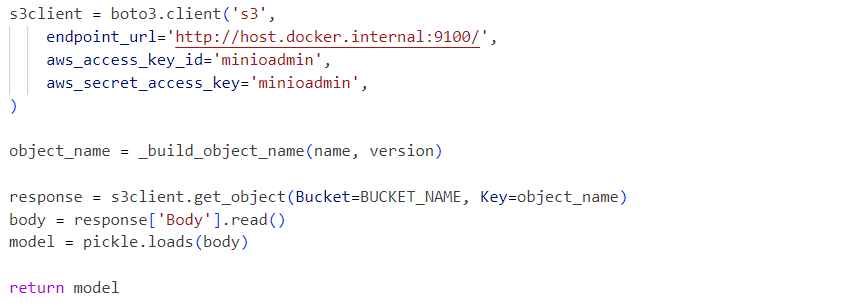
Anfragen werden an das initialisierte Modell wie folgt gesendet:

Das vorgestellte Projekt ist ein vereinfachtes VAR-Modell-Workflow, der schrittweise um zusätzliche Funktionalitäten erweitert werden kann:
- Untersuchen von Standard-Serialisierungsformaten und Ersetzen des Pickles durch eine alternative Lösung
- Integration von Zeitreihen-Datenvisualisierungstools wie Kibana oder Apache Superset
- Speichern von Zeitreihen-Daten in einer Zeitreihen-Datenbank wie Prometheus, TimescaleDB, InfluxDB oder einem Objektspeicher wie S3
- Erweitern des Pipelines mit Datenladung und Datenvorverarbeitungsschritten
- Einbeziehen von Metrikberichten als Teil der Pipelines
- Implementieren von Pipelines mit spezifischen Tools wie Apache Airflow oder AWS Step Functions oder Standardtools wie Gitlab oder GitHub
- Vergleichen Sie die Leistung und Genauigkeit statistischer Modelle mit maschinellem Lernen
- Implementieren Sie End-to-End-Cloud-integrierte Lösungen, einschließlich Infrastructure-As-Code
- Statistische und ML-Modelle als Dienste verfügbar machen
- Implementieren Sie eine Modell-Speicher-API, die den tatsächlichen Speichermechanismus und die Versionsverwaltung des Modells abstrahiert, Modellmetadaten speichert und Trainingsdaten
Diese zukünftigen Verbesserungen werden Gegenstand zukünftiger Artikel und Projekte sein. Das Ziel dieses Artikels ist es, eine S3-kompatible Speicher-API zu integrieren und die Speicherung von versionierten Modellen zu ermöglichen. Diese Funktionalität wird bald in einer separaten Bibliothek extrahiert. Die vorgestellte End-to-End-Infrastrukturlösung kann in Produktion eingesetzt und im Laufe der Zeit als Teil eines CI/CD-Prozesses verbessert werden, auch unter Verwendung der verteilten Bereitstellungsoptionen von MinIO oder durch deren Ersetzung durch AWS S3.
Source:
https://dzone.com/articles/time-series-analysis-var-model-as-a-service