













Amazon Simple Storage Service (S3) ist eine hoch skalierbare, dauerhafte und sichere Objektspeicherdienst von Amazon Web Services (AWS). S3 ermöglicht Unternehmen, beliebige Datenmengen von überall im Web zu speichern und abzurufen, indem es die Unternehmensklassen-Dienste nutzt. S3 ist so konzipiert, dass es hoch interoperabel ist und nahtlos mit anderen Amazon Web Services (AWS) und Drittanbieter-Tools und -Technologien integriert wird, um Daten, die in Amazon S3 gespeichert sind, zu verarbeiten. Eines davon ist Amazon EMR (Elastic MapReduce), das es Ihnen ermöglicht, große Datenmengen mit Open-Source-Tools wie Spark zu verarbeiten.
Apache Spark ist ein Open-Source-Verteilungsrechnungssystem zur Verarbeitung großer Datenmengen. Spark ist darauf ausgelegt, Geschwindigkeit zu ermöglichen, und unterstützt verschiedene Datenquellen, einschließlich Amazon S3. Spark bietet eine effiziente Möglichkeit, große Datenmengen zu verarbeiten und komplexe Berechnungen in kürzester Zeit durchzuführen.
Memphis.dev ist eine neue Generation von alternativen Nachrichtenbrokern. Ein einfacher, robuster und dauerhafter, cloud-nativer Nachrichtenbroker, der mit einem gesamten Ökosystem ausgestattet ist, das die kostengünstige, schnelle und zuverlässige Entwicklung moderner wartenbasierter Anwendungsfälle ermöglicht.
Das übliche Muster von Nachrichtenbrokern ist das Löschen von Nachrichten nach Überschreiten der definierten Aufbewahrungsrichtlinie, wie Zeit/Größe/Anzahl der Nachrichten. Memphis bietet eine zweite Speicherebene für längere, möglicherweise unendliche Aufbewahrung von gespeicherten Nachrichten. Jede Nachricht, die den Station verlässt, wird automatisch in die zweite Speicherebene migriert, die in diesem Fall AWS S3 ist.
In diesem Tutorial führen wir Sie durch den Prozess der Einrichtung einer Memphis-Station mit einer zweiten Speicherklasse, die mit AWS S3 verbunden ist. Ein auf AWS basierendes Umgebung. Anschließend erstellen wir einen S3-Bucket, richten einen EMR-Cluster ein, installieren und konfigurieren Apache Spark auf dem Cluster, bereiten Daten in S3 für die Verarbeitung vor, verarbeiten Daten mit Apache Spark, besprechen Best Practices und Performance-Tuning.
Einrichtung der Umgebung
Memphis
- Um loszulegen, installieren Sie zunächst Memphis.
- Aktivieren Sie die AWS S3-Integration über das Memphis Integrationszentrum.
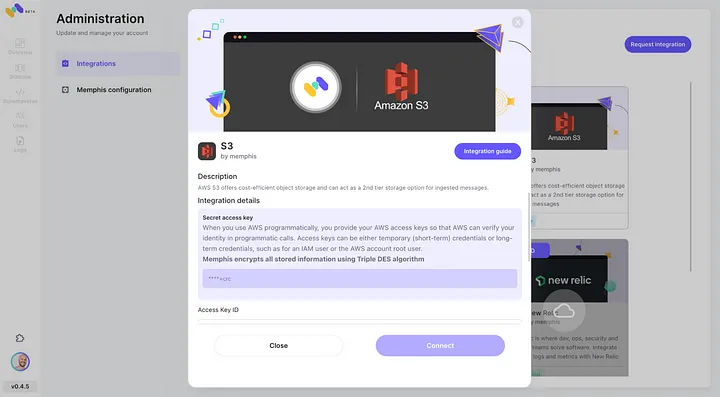
3. Erstellen Sie eine Station (Thema) und wählen Sie eine Aufbewahrungsrichtlinie.
4. Jedes über die konfigurierte Aufbewahrungsrichtlinie hinausgehende Nachrichten wird in einen S3-Bucket ausgelagert.
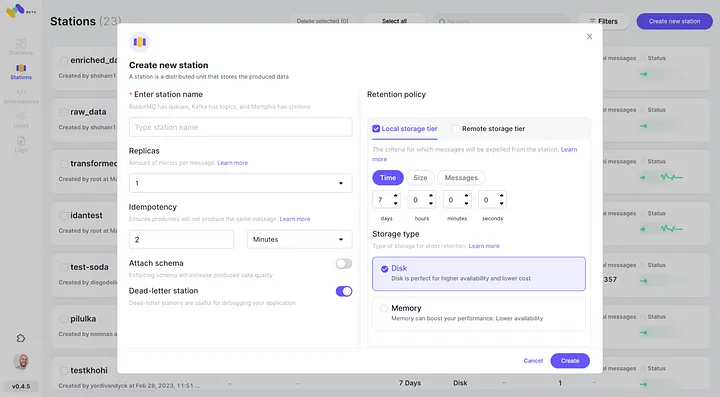
5. Überprüfen Sie die neu konfigurierte AWS S3-Integration als zweite Speicherklasse durch Klicken auf „Verbinden“.
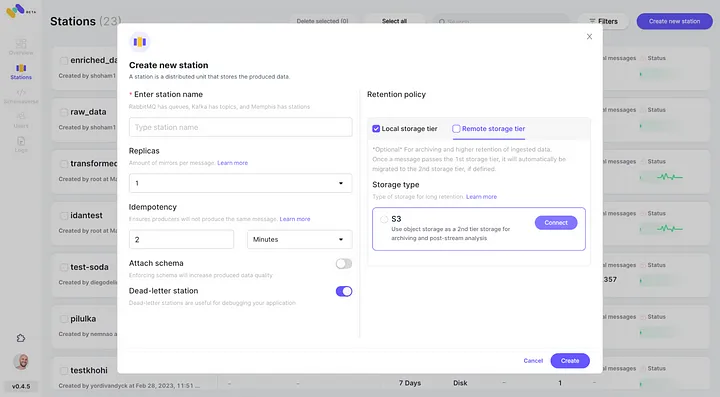
6. Starten Sie die Erzeugung von Ereignissen für Ihre neu erstellte Memphis-Station.
Erstellen eines AWS S3 Buckets
Wenn Sie dies noch nicht getan haben, müssen Sie zuerst ein AWS Konto erstellen. Als Nächstes erstellen Sie einen S3-Bucket, in dem Sie Ihre Daten speichern können. Sie können die AWS Management Console, die AWS CLI oder eine SDK verwenden, um einen Bucket zu erstellen. Für dieses Tutorial verwenden Sie die AWS Management Konsole.
Klicken Sie auf „Bucket erstellen“.
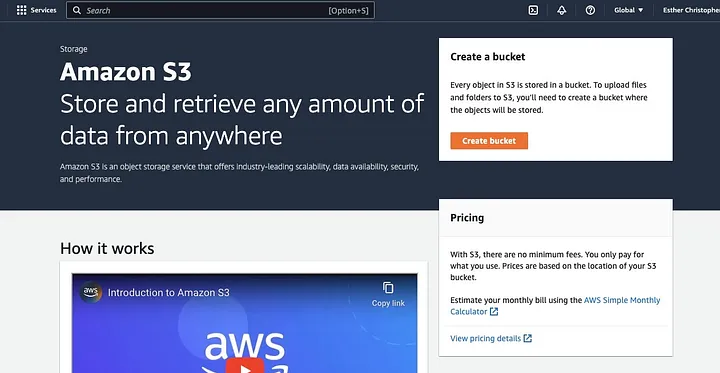
Gehen Sie dann dazu über, einen Bucketnamen zu erstellen, der den Namenskonventionen entspricht, und wählen Sie die Region aus, in der der Bucket platziert werden soll. Konfigurieren Sie „Objektbesitz“ und „Alle öffentlichen Zugriffe blockieren“ entsprechend Ihrem Anwendungsfall.
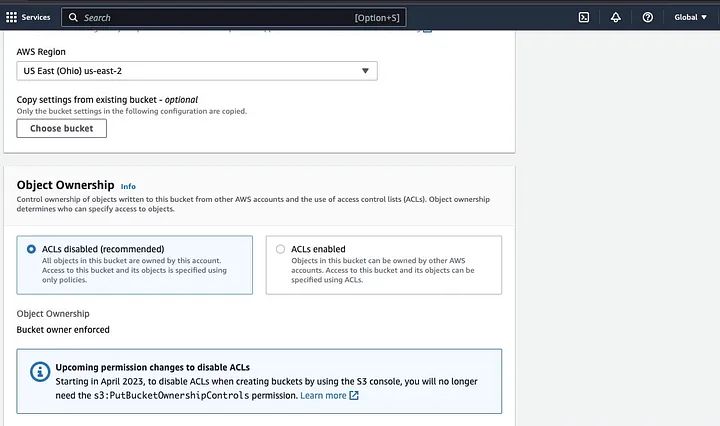
Stellen Sie außerdem sicher, dass die anderen Bucketberechtigungen so eingerichtet sind, dass Ihre Spark-Anwendung auf die Daten zugreifen kann. Schließlich klicken Sie auf die Schaltfläche „Bucket erstellen“, um den Bucket zu erstellen.
Einrichten eines EMR-Clusters mit installiertem Spark
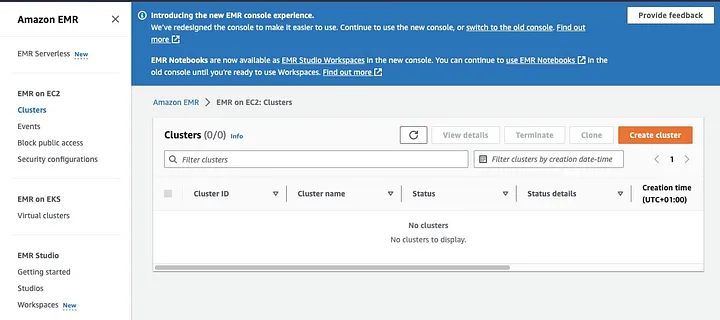
Amazon Elastic MapReduce (EMR) ist ein webbasiertes Dienst auf Basis von Apache Hadoop, der es Benutzern ermöglicht, große Datenmengen kosteneffizient mit Big Data-Technologien, einschließlich Apache Spark, zu verarbeiten. Um einen EMR-Cluster mit installiertem Spark zu erstellen, öffnen Sie die EMR-Konsole und wählen Sie „Cluster“ unter „EMR on EC2“ auf der linken Seite der Seite.
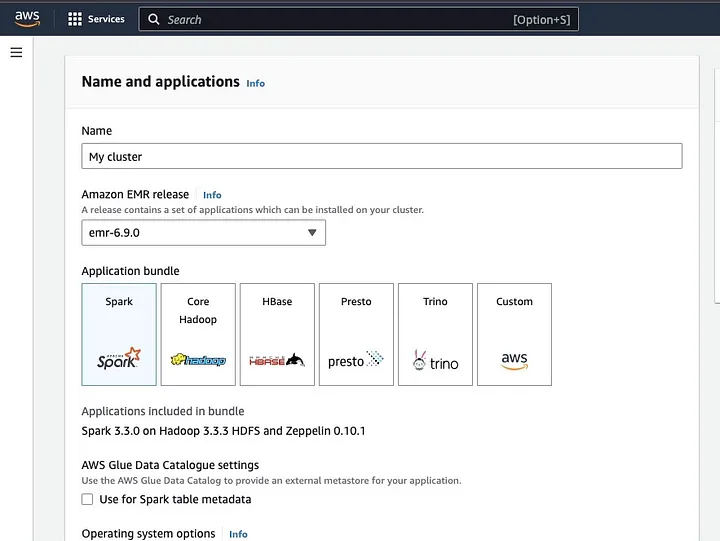
Klicken Sie auf „Cluster erstellen“ und geben Sie dem Cluster einen aussagekräftigen Namen. Unter „Anwendungspaket“ wählen Sie Spark, um es auf Ihrem Cluster zu installieren.
Scrollen Sie nach unten zum Abschnitt „Cluster-Protokolle“ und wählen Sie das Kontrollkästchen „Cluster-spezifische Protokolle an Amazon S3 veröffentlichen“.
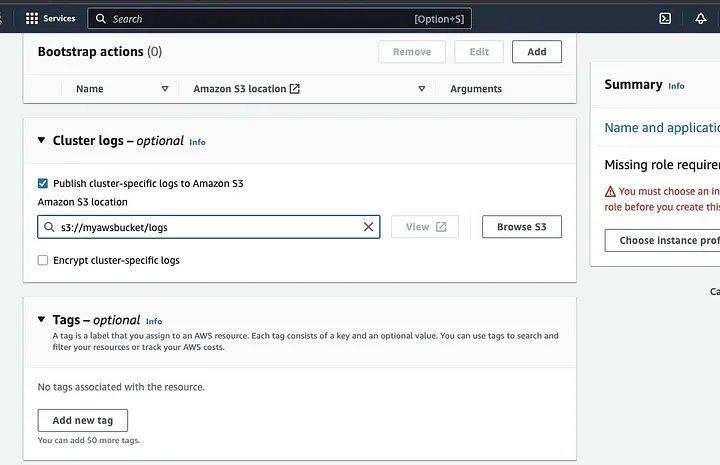
Dies erzeugt eine Eingabeaufforderung, um die Amazon S3-Speicherort mit dem in der vorherigen Schritt erstellten S3-Bucket-Namen einzugeben, gefolgt von /logs, z.B. s3://myawsbucket/logs. /logs sind von Amazon erforderlich, um einen neuen Ordner in Ihrem Bucket zu erstellen, in dem Amazon EMR die Protokolldateien Ihres Clusters kopieren kann.
Gehen Sie zum Abschnitt „Sicherheitskonfiguration und Berechtigungen“ und geben Sie Ihr EC2-Schlüsselpaar ein oder wählen Sie die Option, eines zu erstellen.
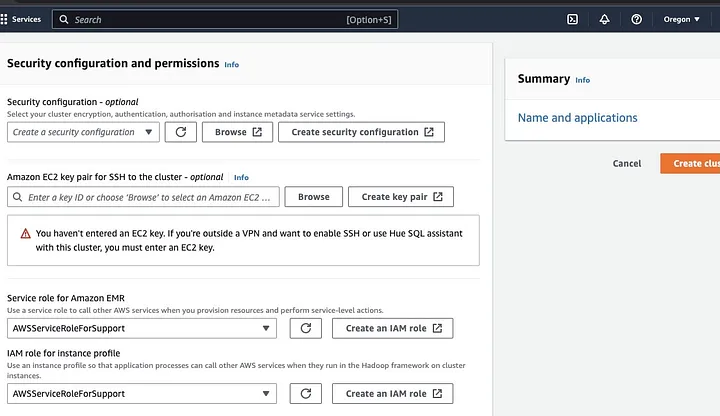
Klicken Sie dann auf die Dropdown-Optionen für „Dienstrolle für Amazon EMR“ und wählen Sie AWSServiceRoleForSupport. Wählen Sie die gleiche Dropdown-Option für „IAM-Rolle für Instanzprofil“. Aktualisieren Sie das Symbol gegebenenfalls, um diese Dropdown-Optionen zu erhalten.
Schließlich klicken Sie auf die Schaltfläche „Cluster erstellen“, um den Cluster zu starten und den Clusterstatus zu überwachen, um zu validieren, dass er erstellt wurde.
Installation und Konfiguration von Apache Spark auf EMR-Cluster
Nachdem Sie erfolgreich einen EMR-Cluster erstellt haben, ist der nächste Schritt die Konfiguration von Apache Spark auf dem EMR-Cluster. Die EMR-Cluster bieten eine verwaltete Umgebung zum Ausführen von Spark-Anwendungen in der AWS-Infrastruktur, was es einfach macht, Spark-Cluster in der Cloud zu starten und zu verwalten. Es konfiguriert Spark für die Arbeit mit Ihren Daten und Verarbeitungsbedürfnissen und leitet dann Spark-Aufträge an den Cluster weiter, um Ihre Daten zu verarbeiten.
Sie können Apache Spark auf dem Cluster mithilfe des Secure Shell (SSH) Protokolls konfigurieren. Zunächst müssen Sie jedoch die SSH-Sicherheitsverbindungen zu Ihrem Cluster autorisieren, die beim Erstellen des EMR-Clusters standardmäßig eingerichtet wurden. Eine Anleitung zur Autorisierung von SSH-Verbindungen finden Sie hier.
Um eine SSH-Verbindung herzustellen, müssen Sie das EC2-Schlüsselpaar angeben, das Sie beim Erstellen des Clusters ausgewählt haben. Verbinden Sie dann über das Spark-Shell mit dem EMR-Cluster, indem Sie zuerst mit dem primären Knoten verbinden. Zuerst müssen Sie die öffentliche DNS des primären Knotens abrufen, indem Sie in der AWS-Konsole links unter EMR auf EC2 auf Cluster klicken und dann das Cluster mit der gewünschten öffentlichen DNS-Adresse auswählen.
Geben Sie im Terminal Ihrer Betriebssystemumgebung den folgenden Befehl ein.
ssh hadoop@ec2-###-##-##-###.compute-1.amazonaws.com -i ~/mykeypair.pemErsetzen Sie ec2-###-##-##-###.compute-1.amazonaws.com durch den Namen Ihrer master public DNS und ~/mykeypair.pem durch den Datei- und Pfadnamen Ihrer .pem-Datei (Befolgen Sie diese Anleitung, um die .pem Datei zu erhalten). Es wird eine Aufforderung angezeigt, auf die Sie mit „yes“ antworten sollten – geben Sie „exit“ ein, um den SSH-Befehl zu schließen.
Vorbereiten von Daten zur Verarbeitung mit Spark und Hochladen in S3-Bucket
Datenverarbeitung erfordert eine Vorbereitung, bevor sie zum Upload auf ein Format gebracht wird, das Spark leicht verarbeiten kann. Das verwendete Format wird durch die Art der Daten und die geplante Analyse beeinflusst. Zu den verwendeten Formaten gehören CSV, JSON und Parquet.
Erstellen Sie eine neue Spark-Sitzung und laden Sie Ihre Daten mit der entsprechenden API in Spark. Verwenden Sie beispielsweise die spark.read.csv()-Methode, um CSV-Dateien in einen Spark DataFrame zu lesen.
Amazon EMR, ein verwalteter Dienst für Hadoop-Ökosystem-Cluster, kann zur Datenverarbeitung verwendet werden. Es reduziert die Notwendigkeit, Cluster einzurichten, zu optimieren und zu warten. Es bietet auch andere Integrationen mit Amazon SageMaker, zum Beispiel, um einen SageMaker-Modelltrainingsjob aus einem Spark-Pipeline in Amazon EMR zu starten.
Sobald Ihre Daten bereit sind, können Sie mit der DataFrame.write.format("s3")-Methode eine CSV-Datei aus dem Amazon S3-Bucket in einen Spark DataFrame lesen. Sie sollten Ihre AWS-Anmeldeinformationen konfiguriert haben und Schreibberechtigungen zum Zugreifen auf den S3-Bucket besitzen.
Geben Sie den S3-Bucket und den Pfad an, wo Sie die Daten speichern möchten. Sie können beispielsweise die df.write.format("s3").save("s3://my-bucket/path/to/data")-Methode verwenden, um die Daten in den angegebenen S3-Bucket zu speichern.
Sobald die Daten in den S3-Bucket gespeichert sind, können Sie sie von anderen Spark-Anwendungen oder -Tools abrufen oder sie zum weiteren Analysieren oder Verarbeiten herunterladen. Um den Bucket hochzuladen, erstellen Sie einen Ordner und wählen Sie den zuvor erstellten Bucket aus. Wählen Sie die Aktionen-Schaltfläche und klicken Sie auf „Ordner erstellen“ in den Dropdown-Elementen. Sie können nun den neuen Ordner benennen.
Um die Datendateien in den Bucket hochzuladen, wählen Sie den Namen der Datenordner.
Klicken Sie im Upload-Menü auf „Datei-Assistent“ und wählen Sie „Dateien hinzufügen“.
Fahren Sie mit den Anweisungen im Amazon S3-Konsolenbereich fort, um die Dateien hochzuladen und auf „Upload starten“ zu klicken.
Es ist wichtig, die besten Sicherheitsmaßnahmen für Ihre Daten zu berücksichtigen und sicherzustellen, bevor Sie Ihre Daten in den S3-Bucket hochladen.
Verständnis von Datenformaten und Schemas
Datenformate und Schemas sind zwei verwandte, aber vollkommen unterschiedliche und wichtige Konzepte in der Datenverwaltung. Das Datenformat bezieht sich auf die Organisation und Struktur von Daten innerhalb der Datenbank. Es gibt verschiedene Formate zum Speichern von Daten, z.B. CSV, JSON, XML, YAML usw. Diese Formate definieren, wie Daten strukturiert werden sollen, zusammen mit den verschiedenen Arten von Daten und Anwendungen, die darauf anwendbar sind. Gleichzeitig sind Datenschemata die Struktur der Datenbank selbst. Sie definieren die Anordnung der Datenbank und stellen sicher, dass Daten entsprechend gespeichert werden. Ein Datenbankschema legt Ansichten, Tabellen, Indizes, Typen und andere Elemente fest. Diese Konzepte sind wichtig für Analysen und die Visualisierung der Datenbank.
Datenbereinigung und -vorverarbeitung in S3
Es ist wichtig, Ihre Daten vor der Verarbeitung auf Fehler zu überprüfen. Um zu beginnen, greifen Sie auf den Datenordner zu, in dem Sie die Datendatei in Ihrem S3-Bucket gespeichert haben, und laden Sie sie auf Ihr lokales Gerät herunter. Als Nächstes laden Sie die Daten in das Datenverarbeitungstool, das zum Bereinigen und Vorverarbeiten der Daten verwendet wird. Für dieses Tutorial wird das verwendete Vorverarbeitungstool Amazon Athena sein, das hilft, unstrukturierte und strukturierte Daten, die in Amazon S3 gespeichert sind, zu analysieren.
Gehe zur Amazon Athena in der AWS-Konsole.
Klicke auf „Erstellen“, um eine neue Tabelle zu erstellen, und dann auf „CREATE TABLE“.
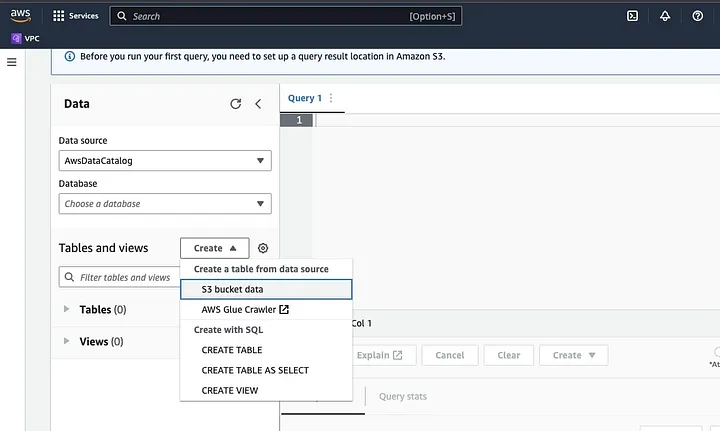
Gib den Pfad zu deinem Datendatei im Teil ein, der als STANDORT hervorgehoben ist.
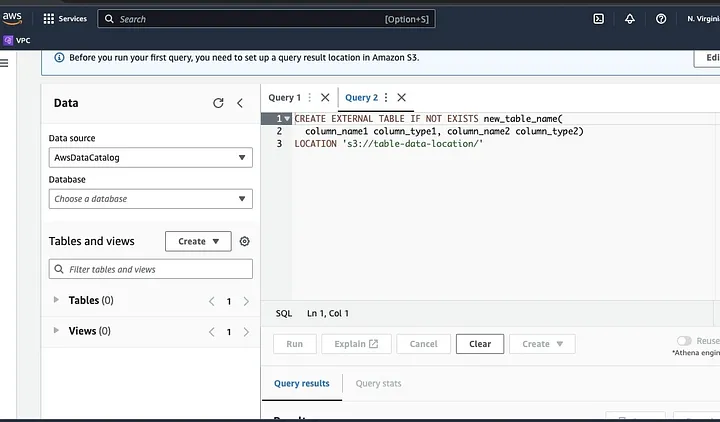
Folge den Aufforderungen, um das Schema für die Daten zu definieren und die Tabelle zu speichern. Jetzt kannst du eine Abfrage ausführen, um zu überprüfen, ob die Daten korrekt geladen wurden, und dann die Daten bereinigen und vorverarbeiten
Beispiel:
Diese Abfrage identifiziert die Duplikate in den Daten.
SELECT row1, row2, COUNT(*)
FROM table
GROUP row, row2
HAVING COUNT(*) > 1;Dieses Beispiel erstellt eine neue Tabelle ohne Duplikate:
CREATE TABLE new_table AS
SELECT DISTINCT *
FROM table;Schließlich exportiere die gereinigten Daten zurück zu S3, indem du zum S3-Bucket und dem Ordner navigierst, um die Datei hochzuladen.
Verständnis des Spark-Frameworks
Das Spark-Framework ist eine quelloffene, einfache und expressive Cluster-Computing-Lösung, die für schnelle Entwicklung konzipiert wurde. Es basiert auf der Java-Programmiersprache und fungiert als Alternative zu anderen Java-Frameworks. Das Hauptmerkmal von Spark ist seine Fähigkeit zur In-Memory-Datenverarbeitung, die die Verarbeitung großer Datensätze beschleunigt.
Konfiguration von Spark zur Arbeit mit S3
Um Spark zur Arbeit mit S3 zu konfigurieren, fange an, die Hadoop AWS-Abhängigkeit zu deinem Spark-Anwendung hinzuzufügen. Führe dies durch, indem du die folgende Zeile zu deinem Build-Datei (z.B. build.sbt für Scala oder pom.xml für Java) hinzufügst:
libraryDependencies += "org.apache.hadoop" % "hadoop-aws" % "3.3.1"Gib den AWS-Zugriffsschlüssel-ID und den geheimen Zugriffsschlüssel in deiner Spark-Anwendung ein, indem du die folgenden Konfigurationseigenschaften setzt:
spark.hadoop.fs.s3a.access.key <ACCESS_KEY_ID>
spark.hadoop.fs.s3a.secret.key <SECRET_ACCESS_KEY>Setze die folgenden Eigenschaften mithilfe des SparkConf-Objekts in deinem Code:
val conf = new SparkConf()
.set("spark.hadoop.fs.s3a.access.key", "<ACCESS_KEY_ID>")
.set("spark.hadoop.fs.s3a.secret.key", "<SECRET_ACCESS_KEY>")Setzen Sie die S3-Endpunkt-URL in Ihrer Spark-Anwendung, indem Sie die folgende Konfigurationseigenschaft setzen:
spark.hadoop.fs.s3a.endpoint s3.<REGION>.amazonaws.comErsetzen Sie <REGION> durch die AWS-Region, in der sich Ihr S3-Bucket befindet (z. B. us-east-1).
Ein DNS-kompatibler Bucket-Name ist erforderlich, um dem S3-Client in Hadoop den Zugriff auf die S3-Anfragen zu gewähren. Wenn Ihr Bucket-Name Punkte oder Unterstriche enthält, müssen Sie möglicherweise den Pfadstilzugriff für den S3-Client in Hadoop aktivieren, der einen virtuellen Hoststil verwendet. Setzen Sie die folgende Konfigurationseigenschaft, um den Pfadzugriff zu aktivieren:
spark.hadoop.fs.s3a.path.style.access trueSchließlich erstellen Sie eine Spark-Sitzung mit der S3-Konfiguration, indem Sie das spark.hadoop-Präfix in der Spark-Konfiguration setzen:
val spark = SparkSession.builder()
.appName("MyApp")
.config("spark.hadoop.fs.s3a.access.key", "<ACCESS_KEY_ID>")
.config("spark.hadoop.fs.s3a.secret.key", "<SECRET_ACCESS_KEY>")
.config("spark.hadoop.fs.s3a.endpoint", "s3.<REGION>.amazonaws.com")
.getOrCreate()Ersetzen Sie die Felder von <ACCESS_KEY_ID>, <SECRET_ACCESS_KEY> und <REGION> durch Ihre AWS-Anmeldeinformationen und die S3-Region.
Um die Daten aus S3 in Spark zu lesen, wird die spark.read-Methode verwendet und dann der S3-Pfad zu Ihren Daten als Eingabequelle angegeben.
Ein Beispielcode, der zeigt, wie man eine CSV-Datei aus S3 in eine DataFrame in Spark liest:
val spark = SparkSession.builder()
.appName("ReadDataFromS3")
.getOrCreate()
val df = spark.read
.option("header", "true") // Specify whether the first line is the header or not
.option("inferSchema", "true") // Infer the schema automatically
.csv("s3a://<BUCKET_NAME>/<FILE_PATH>")In diesem Beispiel ersetzen Sie <BUCKET_NAME> durch den Namen Ihres S3-Buckets und <FILE_PATH> durch den Pfad zu Ihrer CSV-Datei innerhalb des Buckets.
Datentransformation mit Spark
Datentransformationen mit Spark beziehen sich typischerweise auf Operationen zur Datenbereinigung, Filterung, Aggregation und Verknüpfung von Daten. Spark stellt eine umfangreiche Sammlung von APIs für Datentransformationen zur Verfügung. Dazu gehören die DataFrame-, Dataset- und RDD-APIs. Einige der häufigen Datentransformationsoperationen in Spark umfassen Filterung, Auswahl von Spalten, Aggregation von Daten, Verknüpfung von Daten und Sortierung von Daten.
Hier ist ein Beispiel für Datentransformationsoperationen:
Sortierung von Daten: Diese Operation beinhaltet das Sortieren von Daten basierend auf einer oder mehreren Spalten. Die Methode orderBy oder sort für ein DataFrame oder Dataset wird verwendet, um Daten basierend auf einer oder mehreren Spalten zu sortieren. Zum Beispiel:
val sortedData = df.orderBy(col("age").desc)Schließlich müssen Sie möglicherweise das Ergebnis zurück in S3 schreiben, um die Ergebnisse zu speichern.
Spark bietet verschiedene APIs zum Schreiben von Daten in S3, wie DataFrameWriter, DatasetWriter und RDD.saveAsTextFile.
Das folgende ist ein Codebeispiel, das zeigt, wie ein DataFrame in S3 im Parquet-Format geschrieben wird:
val outputS3Path = "s3a://<BUCKET_NAME>/<OUTPUT_DIRECTORY>"
df.write
.mode(SaveMode.Overwrite)
.option("compression", "snappy")
.parquet(outputS3Path)Ersetzen Sie das Eingabefeld des <BUCKET_NAME> durch den Namen Ihres S3-Buckets und <OUTPUT_DIRECTORY> durch den Pfad zum Ausgabeverzeichnis im Bucket.
Die Methode mode gibt das Schreibmodus an, das Overwrite, Append, Ignore oder ErrorIfExists sein kann. Die Methode option kann verwendet werden, um verschiedene Optionen für das Ausgabeformat anzugeben, wie z.B. den Komprimierungs-Codec.
Sie können Daten auch in anderen Formaten wie CSV, JSON und Avro in S3 schreiben, indem Sie das Ausgabeformat ändern und die entsprechenden Optionen angeben.
Verständnis der Datenpartitionierung in Spark
In einfachen Worten bezieht sich die Datenpartitionierung in Spark auf das Aufteilen des Datensatzes in kleinere, überschaubarere Teile über das Cluster verteilt. Ziel hiervon ist es, die Leistung zu optimieren, die Skalierbarkeit zu reduzieren und letztendlich die Datenbankverwaltbarkeit zu verbessern. In Spark werden Daten parallel auf mehreren Clustern verarbeitet. Dies wird durch Resilient Distributed Datasets (RDD) ermöglicht, die eine Sammlung von großen, komplexen Daten sind. Standardmäßig werden RDD auf verschiedene Knoten aufgeteilt, bedingt durch ihre Größe.
Um optimal zu arbeiten, gibt es Möglichkeiten, Spark so zu konfigurieren, dass Aufträge zeitnah ausgeführt werden und die Ressourcen effektiv verwaltet werden. Dazu gehören das Zwischenspeichern, die Speicherverwaltung, die Datenkodierung und die Verwendung von mapPartitions() anstelle von map().
Das Spark UI ist eine webbasierte grafische Benutzeroberfläche, die umfassende Informationen über die Leistung und Ressourcenverwendung eines Spark-Anwendung liefert. Es enthält mehrere Seiten wie Übersicht, Ausführungsknoten, Phasen und Aufgaben, die Informationen über verschiedene Aspekte eines Spark-Auftrags bereitstellen. Das Spark UI ist ein wesentliches Werkzeug zur Überwachung und Fehlersuche bei Spark-Anwendungen, da es hilft, Leistungsengpässe und Ressourcenbeschränkungen zu identifizieren und Fehler zu beheben. Durch die Untersuchung von Metriken wie der Anzahl abgeschlossener Aufgaben, der Dauer des Auftrags, der CPU- und Speicherauslastung sowie der Schreib- und Lesevorgänge von Shuffle-Daten können Benutzer ihre Spark-Aufträge optimieren und sicherstellen, dass sie effizient laufen.
Schlussfolgerung
Zusammenfassend ist das Verarbeiten Ihrer Daten auf AWS S3 mithilfe von Apache Spark eine effektive und skalierbare Methode zur Analyse riesiger Datensätze. Durch die Nutzung der cloudbasierten Speicher- und Rechenressourcen von AWS S3 und Apache Spark können Benutzer ihre Daten schnell und effektiv verarbeiten, ohne sich um die Architekturverwaltung kümmern zu müssen.
In diesem Tutorial haben wir den Aufbau eines S3-Buckets und eines Apache Spark-Clusters auf AWS EMR durchgeführt, Spark so konfiguriert, dass es mit AWS S3 zusammenarbeitet, und Spark-Anwendungen zum Verarbeiten von Daten geschrieben und ausgeführt. Wir haben auch Datenpartitionierung in Spark, Spark UI und die Optimierung der Leistung in Spark behandelt.
Referenz
Für tiefergehende Informationen zur Konfiguration von Spark für optimale Leistung siehe hier.
https://docs.aws.amazon.com/emr/latest/ManagementGuide/emr-connect-master-node-ssh.html
Source:
https://dzone.com/articles/stateful-stream-processing-with-memphis-and-apache-spark