













Shift-left ist ein Ansatz für die Softwareentwicklung und -betrieb, der Tests, Überwachung und Automatisierung früher im Lebenszyklus der Softwareentwicklung betont. Ziel des Shift-left-Ansatzes ist es, Probleme zu verhindern, indem sie früh erkannt und schnell behoben werden.
Wenn man eine Skalierungsproblematik oder einen Fehler früh erkennt, ist es schneller und kosteneffizienter, diese zu beheben. Das Verschieben ineffizienter Code in Cloud-Container kann kostspielig sein, da es möglicherweise die automatische Skalierung aktiviert und somit die monatlichen Kosten erhöht. Darüber hinaus befindet man sich in einer Notlage, bis man das Problem identifizieren, isolieren und beheben kann.
Problemstellung
I would like to demonstrate to you a case where we managed to avert a potential issue with an application that could have caused a major issue in a production environment.
I was reviewing the performance report of the UAT infrastructure following the recent application change. It was a Spring Boot microservice with MariaDB as the backend, running behind Apache reverse proxy and AWS application load balancer. The new feature was successfully integrated, and all UAT test cases are passed. However, I noticed the performance charts in the MariaDB performance dashboard deviated from pre-deployment patterns.
Dies ist die Zeitachse der Ereignisse.
Am 6. August um 14:13 Uhr wurde die Anwendung mit einer neuen Spring Boot-JAR-Datei neu gestartet, die einen eingebetteten Tomcat enthält.
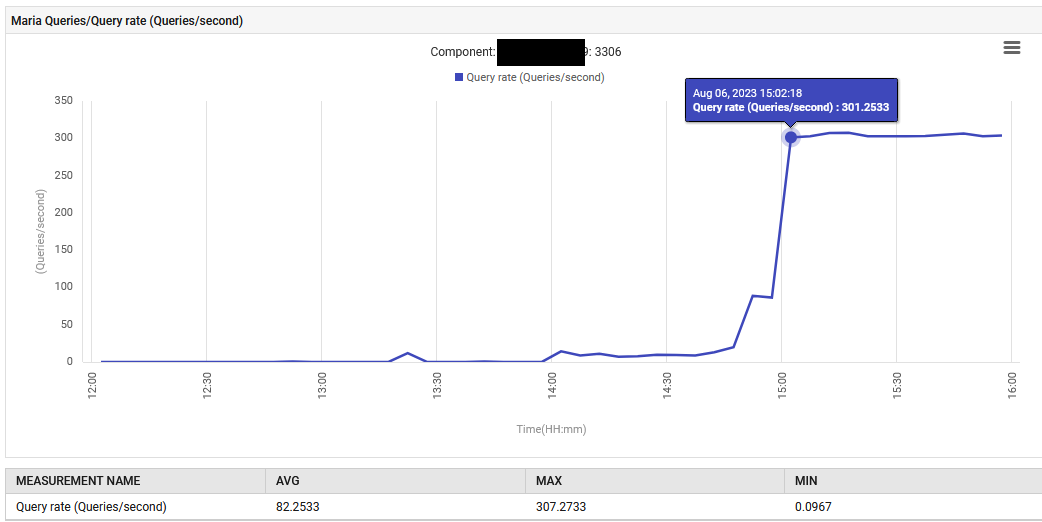
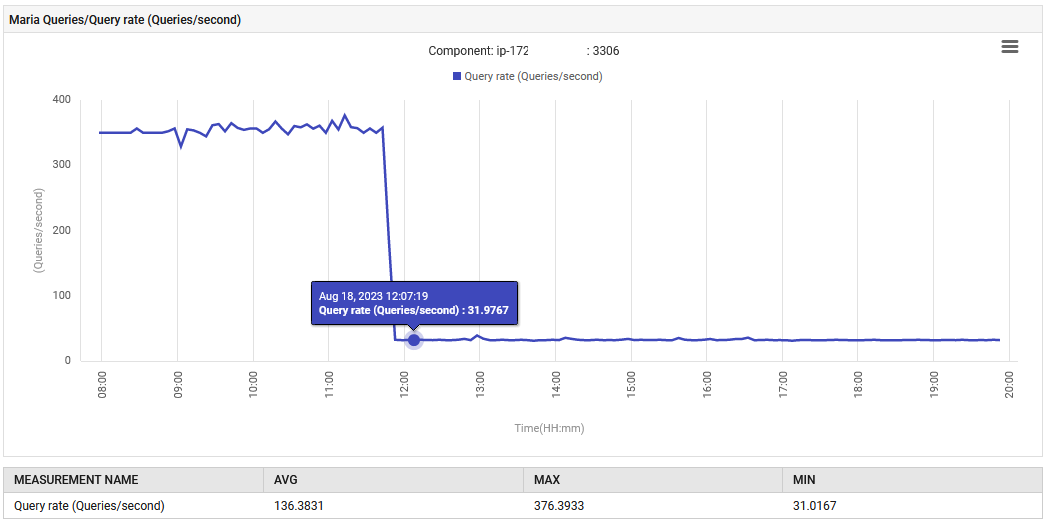
Um 14:52 Uhr stieg die Abfrageverarbeitungsrate für MariaDB von 0,1 auf 88 Abfragen pro Sekunde und dann auf 301 Abfragen pro Sekunde.
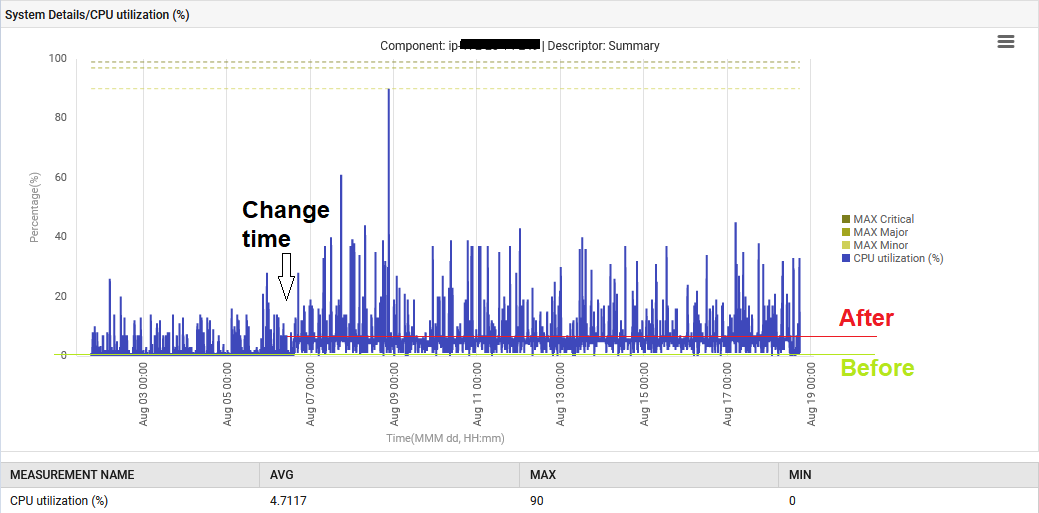
Darüber hinaus stieg der System-CPU-Anteil von 1% auf 6%.
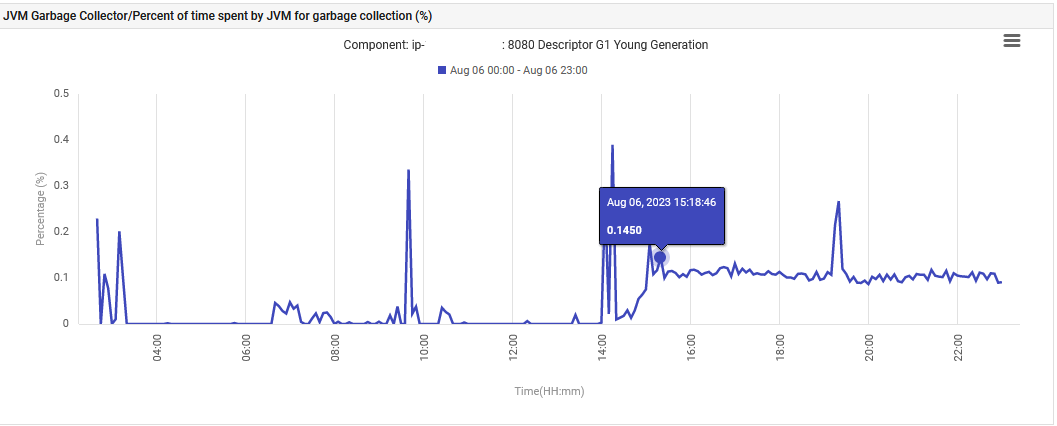
Schließlich erhöhte sich die JVM-Zeit, die für die G1 Young Generation Garbage Collection verwendet wurde, von 0% auf 0,1% und blieb auf diesem Niveau.
Die Anwendung, in ihrer UAT-Phase, gibt ungewöhnlich 300 Abfragen pro Sekunde aus, was weit über dem liegt, was sie ursprünglich ausgelegt war. Die neue Funktion hat zu einer Erhöhung der Datenbankverbindungen geführt, weshalb der Anstieg der Abfragen so drastisch ist. Allerdings zeigte das Überwachungsdashboard, dass die problematischen Messwerte vor der Bereitstellung der neuen Version normal waren.
Die Lösung
Es handelt sich um eine Spring Boot-Anwendung, die JPA verwendet, um eine MariaDB abzufragen. Die Anwendung ist so konzipiert, dass sie auf zwei Containern für minimale Belastung läuft, aber auf bis zu zehn skaliert werden kann.
Kann ein einzelner Container 300 Abfragen pro Sekunde generieren, kann er dann 3000 Abfragen pro Sekunde bewältigen, wenn alle zehn Container betriebsbereit sind? Kann die Datenbank genügend Verbindungen haben, um den Bedürfnissen der anderen Teile der Anwendung gerecht zu werden?
Wir hatten keine andere Wahl, als zurück zum Entwickler-Tisch zu gehen, um die Änderungen in Git zu inspizieren.
Die neue Änderung nimmt einige Datensätze aus einer Tabelle und verarbeitet sie. Das haben wir in der Service-Klasse beobachtet.
List<X> findAll = this.xRepository.findAll();
Nein, die Verwendung der Methode findAll() ohne Paginierung in Springs CrudRepository ist nicht effizient. Paginierung hilft dabei, die Zeit zum Abrufen von Daten aus der Datenbank zu reduzieren, indem die Menge der abgerufenen Daten begrenzt wird. Das haben wir in unserer primären RDBMS-Ausbildung gelernt. Darüber hinaus trägt die Paginierung dazu bei, den Speicherverbrauch gering zu halten, um ein Abstürzen der Anwendung aufgrund einer Überlastung von Daten zu verhindern, sowie den Aufwand für die Garbage Collection des Java Virtual Machines zu reduzieren, wie im Problemzusammenhang oben erwähnt.
Dieser Test wurde mit lediglich 2.000 Datensätzen in einem Container durchgeführt. Wenn dieser Code in die Produktion verschoben würde, wo es etwa 200.000 Datensätze in bis zu 10 Containern gibt, hätte es das Team an diesem Tag viel Stress und Sorge verursacht.
Die Anwendung wurde mit einem zusätzlichen WHERE Klausel in der Methode neu aufgebaut.
List<X> findAll = this.xRepository.findAllByY(Y);
Die normale Funktionsweise wurde wiederhergestellt. Die Anzahl der Abfragen pro Sekunde sank von 300 auf 30, und der Aufwand für die Garbage Collection kehrte auf sein ursprüngliches Niveau zurück. Darüber hinaus ging der CPU-Verbrauch des Systems zurück.
Lernen und Zusammenfassung
Jeder, der im Bereich Site Reliability Engineering (SRE) tätig ist, wird die Bedeutung dieser Entdeckung zu schätzen wissen. Wir konnten darauf reagieren, ohne eine Stufe 1-Warnung auslösen zu müssen. Hätte dieses fehlerhafte Paket in der Produktion bereitgestellt werden können, hätte es das Auto-Scaling-Limit des Kunden auslösen können, wodurch neue Container ohne zusätzliche Benutzerlast gestartet worden wären.
Aus dieser Geschichte lassen sich drei Haupterkenntnisse ziehen.
Erstens, es ist eine bewährte Praxis, von Anfang an eine Überwachungslösung einzusetzen, da sie eine Ereignisgeschichte bereitstellen kann, die zur Identifizierung potenzieller Probleme genutzt werden kann. Ohne diese Geschichte hätte ich möglicherweise eine Abfallbereinigungsrate von 0,1% und einen CPU-Verbrauch von 6% nicht ernst genommen, und der Code könnte mit katastrophalen Folgen in die Produktion freigegeben worden sein. Die Erweiterung des Überwachungssystems auf UAT-Server half dem Team, potentielle Ursachen zu identifizieren und Probleme zu verhindern, bevor sie auftreten.
Zweitens sollten Leistungsbezogene Testfälle im Testprozess existieren und von jemandem mit Erfahrung in der Überwachung überprüft werden. Dies stellt sicher, dass sowohl die Funktionalität des Codes als auch seine Leistung getestet werden.
Drittens sind cloud-native Leistungsüberwachungstechniken gut geeignet, um Warnungen über hohen Ressourcenverbrauch, Verfügbarkeit usw. zu erhalten. Um Überwachbarkeit zu gewährleisten, müssen Sie möglicherweise die richtigen Werkzeuge und Fachkenntnisse einsetzen. Happy Coding!
Source:
https://dzone.com/articles/shift-left-monitoring-approach-for-cloud-apps-in-c