













Der Retrieval Augmented Generation (RAG) markiert eine bewegende Weiterentwicklung in den Großsprachmodellen (LLMs). Er verbindet die generativen Fähigkeiten von Transformer-Architekturen mit dynamischer Informationen-Retrieval.
Diese Integration ermöglicht es LLMs, auf relevante externe Kenntnisse zuzugreifen und sie während der Textgenerierung einzubinden, was zu Ergebnissen führt, die genauer, kontextueller und wahrheitsgemäßer sind.
Die Entwicklung von frühen regelbasierten Systemen bis hin zu fortschrittlichen neuronalen Modellen wie BERT und GPT-3 hat den Weg für RAG freigemacht, indem Limitationen des statischen parametrischen Speichers überwunden wurden. Auch die Einführung von Multimodal RAG erweitert diese Fähigkeiten, indem verschiedene Datentypen wie Bilder, Audio und Video integriert werden. Dies verbessert die Reichtum und die Relevanz der generierten Inhalte.
Diese Paradigmenwechsel verbessert nicht nur die Genauigkeit und die Interpretabilität der LLM-Ausgaben, sondern unterstützt auch innovative Anwendungen in verschiedenen Bereichen.
Das, was wir hier behandeln werden:
- Kapitel 1. Einführung in RAG
– 1.1 Was ist RAG? Ein Überblick
– 1.2 Wie RAG komplexe Probleme löst - Kapitel 2. Technische Grundlagen
– 2.1 Übergang von Neural LM zu RAG
– 2.2 Verständnis des Speichers von RAG: Parametrisch vs. Nicht-parametrisch
– 2.3 Multi-modales RAG: Integration mehrerer Datentypen - Kapitel 3. Kernmechanismen
– 3.1 Die Kraft der Kombination von Informationsabruf und Generierung in RAG
– 3.2 Integrationsstrategien für Abrufsysteme und Generatoren - Kapitel 4. Anwendungen und Anwendungsfälle
– 4.1 RAG in Aktion: Von QA bis zum kreativen Schreiben
– 4.2 RAG für Sprachen mit geringen Ressourcen: Erweiterung von Reichweite und Möglichkeiten - Kapitel 5. Optimierungstechniken
– 5.1 Fortgeschrittene Abruftechniken zur Optimierung von RAG-Systemen - Kapitel 6. Herausforderungen und Innovationen
– 6.1 Aktuelle Herausforderungen und zukünftige Entwicklungen für RAG
– 6.2 Hardware-Beschleunigung und effiziente Bereitstellung von RAG-Systemen - Kapitel 7. Abschließende Gedanken
– 7.1 Die Zukunft von RAG: Schlussfolgerungen und Reflexionen
Voraussetzungen
Für die Beschäftigung mit Inhalten, die sich auf große Sprachmodelle (LLMs) wie Retrieval-Augmented Generation (RAG) konzentrieren, sind zwei wesentliche Voraussetzungen erforderlich:
- Grundlagen des maschinellen Lernens: Das Verständnis grundlegender Konzepte und Algorithmen des maschinellen Lernens ist entscheidend, insbesondere in Bezug auf neuronale Netzwerkarchitekturen.
- Natural Language Processing (NLP): Ein grundlegendes Verständnis von NLP-Techniken, einschließlich von Text-Vorverarbeitung, Tokenisierung und der Nutzung von Embeddings, ist für die Arbeit mit Sprachmodellen unerlässlich.
Kapitel 1: Einstieg in RAG
Retrieval-Augmented Generation (RAG) revolutioniert die Natur Sprachverarbeitung durch die Kombination von Informationsretrieval und generativen Modellen. RAG dynamisch auf externe Wissensquellen zugreifen, verbessert die Genauigkeit und Relevanz des generierten Textes.
Dieses Kapitel untersucht die Mechanismen von RAG, seine Vorteile und Herausforderungen. Wir tauchen in die Retrieval-Techniken, die Integration mit generativen Modellen und den Einfluss auf verschiedene Anwendungen ein.
RAG reduziert Phantasieprodukte, integriert aktuelle Informationen und behandelt komplexe Probleme. Wir diskutieren auch Herausforderungen wie effizientes Retrieval und ethische Überlegungen. Dieses Kapitel bietet eine umfassende Übersicht über die transformative Potentiale von RAG in der Natur Sprachverarbeitung.
1.1 Was ist RAG? Ein Überblick
Retrieval-Augmented Generation (RAG) markiert einen Paradigmenwechsel in der Natur Sprachverarbeitung, indem es die Stärken von Informationsretrieval und generativen Sprachmodellen nahtlos integriert. RAG-Systeme nutzen externe Wissensquellen, um die Genauigkeit, Relevanz und Kohärenz des generierten Textes zu verbessern, um die beschränkten Möglichkeiten von rein parametrischem Gedächtnis in traditionellen Sprachmodellen zu überwinden. (Lewis et al., 2020)
Durch die dynamische Abfrage und Integration relevanter Informationen während des Generierungsprozesses ermöglicht RAG detailliertere und faktisch konsistente Ergebnisse für eine Vielzahl von Anwendungen, die von Fragestellungsbeantwortung und Dialogsystemen bis hin zu Zusammenfassungen und kreativem Schreiben reichen. (Petroni et al., 2021)
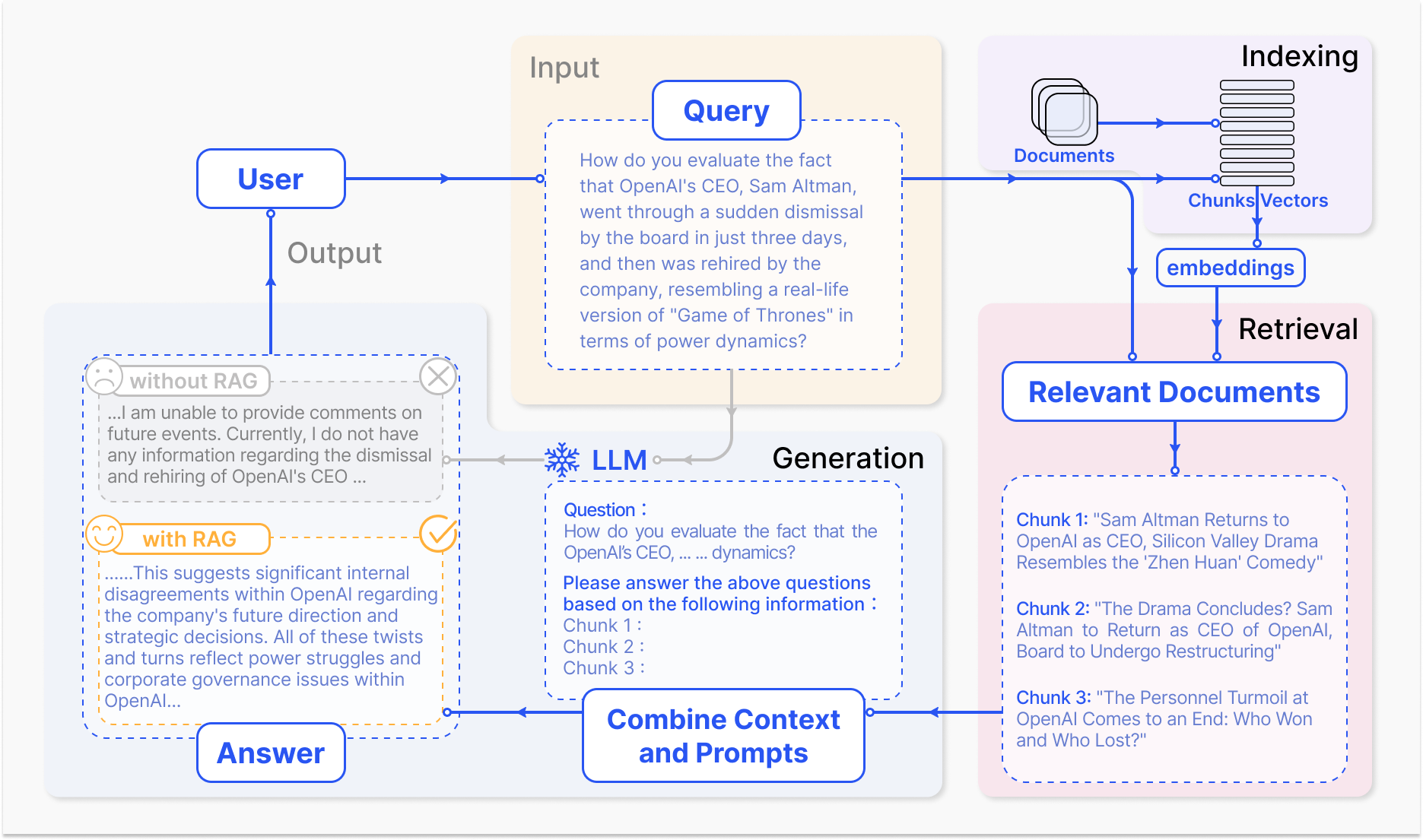
Wie ein RAG-System funktioniert – arxiv.org
Der Kernmechanismus von RAG umfasst zwei Hauptkomponenten: die Retrieval- und die Generierungsphase.
Der Retrieval-Komponente ist es erfolgreich, in großen Wissensbasen nach relevantester Information zu suchen, die auf der Basis der Eingabenachfrage oder des Kontexts identifiziert werden. Techniken wie das Sparse Retrieval, das Inverted Indizes und termbasierte Abgleiche nutzt, und das Dense Retrieval, das auf dichten Vektorerschätzungen und semantischer Ähnlichkeit basiert, werden verwendet, um den Retrievalprozess zu optimieren. (Karpukhin et al., 2020)
Die gefundenen Informationen werden dann in das generative Modell integriert, das typischerweise ein großes Sprachmodell wie GPT oder T5 ist, das den relevanten Inhalt in eine kohärente und flüssige Antwort überführt. (Izacard & Grave, 2021)
Der Einsatz von RAG Systems bringt mehrere Vorteile gegenüber traditionellen Sprachmodellen mit sich. Durch die Verankerung des generierten Textes in externem Wissen verringert RAG signifikant die Häufigkeit von Halluzinationen oder faktisch inkorrekten Ausgaben. (Shuster et al., 2021)
RAG ermöglicht auch die Einbindung aktuellster Informationen, sodass die generierten Antworten das neueste Wissen und Entwicklungen in einem bestimmten Bereich widerspiegeln. (Lewis et al., 2020) Diese Anpassbarkeit ist insbesondere in Bereichen wie der Gesundheitsversorgung, der Finanzbranche und der wissenschaftlichen Forschung von entscheidender Bedeutung, wo die Genauigkeit und Aktualität von Informationen von höchster Wichtigkeit sind. (Petroni et al., 2021)
Allerdings stellen die Entwicklung und das Deployment von RAG-Systemen auch bedeutende Herausforderungen dar. Effiziente Abrufe aus großangelegten Wissensbasen, die Verminderung von Halluzinationen und die Integration verschiedener Datenmodalitäten sind einige der technischen Hürden, die gemeistert werden müssen. (Izacard & Grave, 2021)
Auch ethische Überlegungen, wie die Sicherstellung objektiver und fairer Informationsabruf und -erstellung, sind für den verantwortungsvollen Einsatz von RAG-Systemen entscheidend. (Bender et al., 2021) Die Entwicklung umfassender Bewertungsmetriken und Rahmenwerke, die die Wechselwirkung zwischen Abrufgenauigkeit und generativer Qualität erfassen, sind wichtig für die Bewertung der Effektivität von RAG-Systemen. (Lewis et al., 2020)
Da die RAG-Forschung weiter voranschreitet, richten sich zukünftige Forschungsrichtungen auf die Optimierung von Abrufprozessen, die Erweiterung von multimodalen Fähigkeiten, die Entwicklung modularer Architekturen und die Schaffung robuster Bewertungsframeworks. (Izacard & Grave, 2021) Diese Fortschritte werden die Effizienz, Genauigkeit und Anpassungsfähigkeit von RAG-Systemen verbessern und den Weg für intelligenter und vielseitiger Anwendungen in der natürlichen Sprachverarbeitung ebnen.
Hier ist ein grundlegendes Python-Codebeispiel, das ein Retrieval Augmented Generation (RAG)-Setup mit den populären Bibliotheken LangChain und FAISS demonstriert:
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import FAISS
from langchain.document_loaders import TextLoader
from langchain.chains import RetrievalQA
from langchain.llms import OpenAI
# 1. Dokumente laden und einbetten
loader = TextLoader('your_documents.txt') # Ersetzen Sie durch Ihre Dokumentenquelle
documents = loader.load()
embeddings = OpenAIEmbeddings()
vectorstore = FAISS.from_documents(documents, embeddings)
# 2. Relevante Dokumente abrufen
def retrieve_docs(query):
return vectorstore.similarity_search(query)
# 3. RAG-Kette einrichten
llm = OpenAI(temperature=0.1) # Temperatur für Antwortkreativität anpassen
chain = RetrievalQA.from_chain_type(llm=llm, chain_type="stuff", retriever=vectorstore.as_retriever())
# 4. RAG-Modell verwenden
def get_answer(query):
return chain.run(query)
# Beispielverwendung
query = "What are the key features of Company X's latest product?"
answer = get_answer(query)
print(answer)
#Beispielverwendung Firmengeschichte
query = "When was Company X founded and who were the founders?"
answer = get_answer(query)
print(answer)
#Beispielverwendung Finanzielles Ergebnis
query = "What were Company X's revenue and profit figures for the last quarter?"
answer = get_answer(query)
print(answer)
#Beispielverwendung Zukunftsübersicht
query = "What are Company X's plans for expansion or new product development?"
answer = get_answer(query)
print(answer)
Indem die Kraft der Abrufung und Generierung genutzt wird, hält RAG enorme Versprechen für die Transformation unserer Interaktion und Informationsgenerierung, revolutioniert verschiedene Bereiche und formt die Zukunft der menschlich-maschinellen Interaktion.
1.2 Wie RAG komplexe Probleme löst
Retrieval-Augmented Generation (RAG) bietet eine kraftvolle Lösung für komplexe Probleme, mit denen traditionelle große Sprachmodelle (LLM) zu kämpfen haben, insbesondere in Szenarien mit immensen Mengen an unstrukturierten Daten.
Eines solcher Probleme ist die Fähigkeit, bedeutungsvolle Gespräche über spezifische Dokumente oder multimedialen Inhalt, wie YouTube-Videos, zu führen, ohne vorherige Feintuning oder explizite Training auf dem Zielmaterial.
Traditional LLMs, trotz ihrer beeindruckenden generativen Fähigkeiten, sind durch ihre parametrische Speicherung beschränkt, die bei der Trainingszeit festgelegt ist. (Lewis et al., 2020) Dies bedeutet, dass sie keinen direkten Zugriff auf neue Informationen haben oder diese in ihre Antworten einbinden können, die über ihre Trainingsdaten hinausgehen, was es schwierig macht, informierte Diskussionen über nicht gesehene Dokumente oder Videos zu führen.
Daher können LLMs Antworten generieren, die inkonsistent, irrelevant oder faktisch falsch sind, wenn sie mit Fragen zu spezifischen Inhalten angesprochen werden. (Petroni et al., 2021)
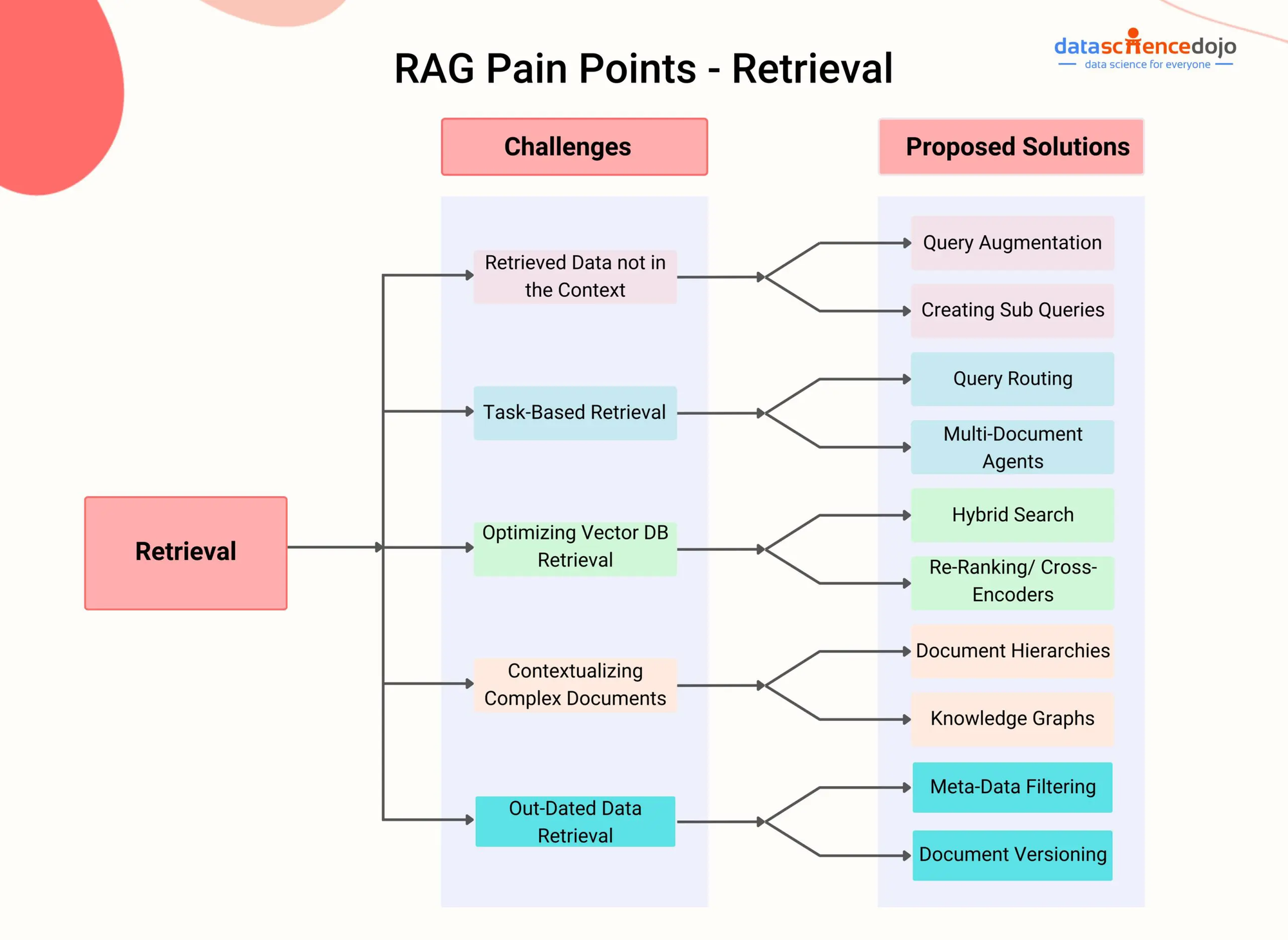
RAG Pain Points – DataScienceDojo
RAG überwindet diese Einschränkung, indem es einen Retrieval-Komponenten integriert, der es dem Modell ermöglicht, während des Generierungsprozesses dynamisch auf relevante Informationen aus externen Wissensquellen zuzugreifen und sie einzubinden.
Durch die Nutzung fortschrittlicher Retrieval-Techniken, wie dichter Passage-Retrieval (Karpukhin et al., 2020) oder Hybrid-Suche (Izacard & Grave, 2021), können RAG-Systeme effizient die relevantesten Abschnitte oder Segmente aus einem gegebenen Dokument oder Video basierend auf dem konversationellen Kontext identifizieren.
Beispielsweise betrachten wir eine Situation, in der ein Nutzer eine Unterhaltung über ein bestimmtes YouTube-Video zu einem wissenschaftlichen Thema beginnen möchte. Ein RAG-System kann zunächst die Audioinhalte des Videos transkribieren und anschließend die erzeugten Texte mit dichten Vektoreinbindungen indizieren.
Wenn der Nutzer dann eine Frage zu dem Video aufstellt, kann der Abrufkomponente des RAG-Systems aufgrund der semantischen Ähnlichkeit zwischen der Anfrage und dem indizierten Inhalt schnell die relevantesten Passagen aus der Transkription erkennen.
Diese Passagen werden dann in das generative Modell eingespeist, das eine zusammenhängende und informative Antwort synthetisiert, die direkt auf die Frage des Nutzers eingeht und die Antwort auf den Inhalt des Videos gründet. (Shuster et al., 2021)
Dieser Ansatz ermöglicht es RAG-Systemen, über eine breite Palette von Dokumenten und multimedialen Inhalten wissenswerte Unterhaltungen zu führen, ohne dass eine explizite Feinjustierung erforderlich ist. Durch die dynamische Retrieval und Integration von relevanten Informationen kann RAG Antworten generieren, die vergleichbar genauer, kontenziell relevanter und faktisch konsistenter als traditionelle LLM sind. (Lewis et al., 2020)
Also kann RAG unstrukturierte Daten verschiedener Modalitäten wie Text, Bilder und Audio verarbeiten, was es zu einer vielseitigen Lösung für komplexe Probleme macht, die sich aus heterogenen Informationsquellen ergeben. (Izacard & Grave, 2021) Mit der Weiterentwicklung von RAG-Systemen wächst ihr Potenzial, komplexe Probleme in verschiedenen Bereichen zu lösen.
Indem fortgeschrittene Abruftechniken und eine Multimodale Integration genutzt werden, kann RAG intelligente und kontextbewusste conversational Agents, personalisierte Empfehlungssysteme und wissensextrakte Anwendungen ermöglichen.
Angesichts der Fortschritte in Bereichen wie effizienter Indexierung, cross-modaler Ausrichtung und Integration von Abruf- und Generationsprozessen wird RAG sicherlich eine entscheidende Rolle spielen, um die Grenzen der Möglichkeiten mit Sprachmodellen und künstlicher Intelligenz zu erweitern.
Kapitel 2: Technische Grundlagen
In diesem Kapitel tauchen wir in die faszinierende Welt des Multimodalen Retrieval-Augmented Generation (RAG) ein, einem fortschrittlichen Ansatz, der die Beschränkungen traditioneller textbasierter Modelle überwindet.
Indem es verschiedenartige Datenspezies wie Bilder, Audio und Video nahtlos mit Großen Sprachmodellen (LLM) integriert, ermöglicht Multimodal RAG AI-Systemen, über einen reichhaltigeren Informationsraum zu resonieren.
Wir werden die Mechanismen hinter dieser Integration erkunden, wie z.B. kontrastives Lernen und cross-modaler Aufmerksamkeit, und wie sie LLMs ermöglichen, nuanciertere und kontextuell relevantere Antworten zu generieren.
Während die Multimodale RAG vielversprechende Vorteile wie verbesserte Genauigkeit und die Fähigkeit bietet, neuartige Anwendungsfälle wie visuelle Fragestellung zu unterstützen, stellt sie auch eigentümliche Herausforderungen dar. Diese Herausforderungen schließen den Bedarf an großskaligen multimodalen Datensätzen, die zunehmende Rechenkomplexität und die Möglichkeit der Verzerrung in gelieferten Informationen ein.
Während wir auf dieser Reise beginnen, werden wir nicht nur die transformative Potenzial von Multimodal RAG entdecken, sondern auch kritisch die Hindernisse untersuchen, die uns im Weg stehen, was den Weg für eine tiefere Verständnis dieser schnell entwickelten Disziplin ebnen wird.
2.1 neuronale LMs zu RAG
Der evolutionäre Fortschritt der Sprachmodelle ist durch eine ständige Progression von frühen regelbasierten Systemen zu immer komplexeren statistischen und neuronalen Netzwerkmodellen gekennzeichnet.
In den Anfängen lieferten Sprachmodelle aufgrund von Handcrafted-Regeln und sprachlichen Kenntnissen Textgenerierung, was eine starke und begrenzte Ausgabe ergab. Mit der Einführung statistischer Modelle wie n-Gram-Modelle wurde ein datengesteuerter Ansatz eingeführt, der von großen Korpora gelernte Muster unterstützte, was eine natürlichere und kohärenteren Sprachgenerierung ermöglichte. (Redis)
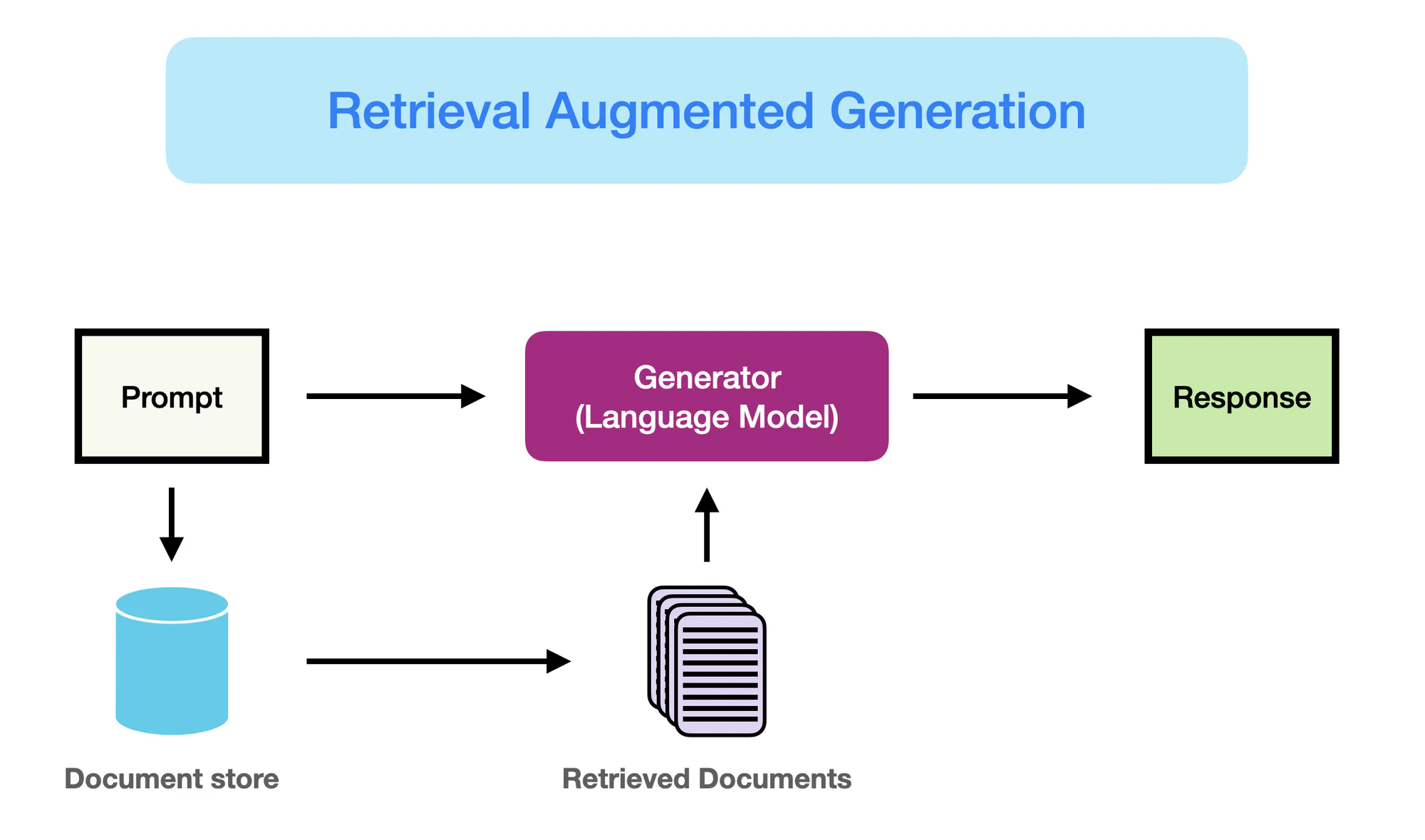
Wie RAG arbeitet – promptingguide.ai
Allerdings revolutionierte der Aufstieg neuronaler Netzwerkmodelle, insbesondere Transformations-Architekturen wie BERT und GPT-3, das Feld der natürlichen Sprachverarbeitung (NLP).
Diese Modelle, bekannt als Large Language Models (LLMs), nutzen die Kraft des tiefen Lernens, um komplexe sprachliche Muster zu erfassen und menschenähnlichen Text mit beispiellosem Flüssigkeit und Kohärenz zu generieren. (Yarnit) Die zunehmende Komplexität und Skalierung von LLMs, mit Modellen wie GPT-3, das über 175 Milliarden Parameter verfügt, hat zu bemerkenswerten Fähigkeiten in Aufgaben wie Übersetzung, Fragebeantwortung und Inhaltserschaffung geführt.
Obwohl ihre Leistung beeindruckend ist, leiden traditionelle LLMs unter Einschränkungen aufgrund ihrer Abhängigkeit von rein parametrischer Speicherung. (StackOverflow) Die in diesen Modellen kodierten Kenntnisse sind statisch und durch das Cut-off-Datum ihrer Trainingsdaten eingeschränkt.
Daher können LLMs Ausgaben generieren, die faktisch inkorrekt oder nicht mit den neuesten Informationen konsistent sind. Außerdem fehlt der explizite Zugriff auf externe Wissensquellen, was ihre Fähigkeit hemmt, genaue und kontextuell relevante Antworten auf wissensintensive Fragen zu liefern.
Retrieval Augmented Generation (RAG) tritt als paradigmenverschiebende Lösung auf, um diese Einschränkungen zu adressieren. Indem es die Informationserfassungsfähigkeiten nahtlos mit der generativen Kraft von LLMs integriert, ermöglicht RAG es Modellen, während des Generationsprozesses dynamisch auf relevante Kenntnisse aus externen Quellen zuzugreifen und diese einzubinden.
Diese Fusion von parametrischen und nicht-parametrischen Speicherungen ermöglicht es RAG-ausgestatteten LLM, Ergebnisse zu produzieren, die nicht nur flüssig und kohärent, sondern auch faktisch korrekt und konztextbezogen sind.
RAG stellt einen bedeutenden Fortschritt in der Sprachgenerierung dar, indem die Stärken von LLM mit dem umfangreichen Wissen, das in externen Depots verfügbar ist, verbunden werden. Durch die optimalische Nutzung beider Welten ist RAG Modellen die Fähigkeit zu geben, Text zu generieren, der verlässlicher, informativer und auf reales Weltwissen abgestimmter ist.
Diese Paradigmenverschiebung öffnet neue Möglichkeiten für NLP-Anwendungen, von Fragebeantwortung und Inhaltserstellung bis zu wissensintensiven Aufgaben in Bereichen wie Gesundheitswesen, Finanzen und wissenschaftlicher Forschung.
2.2 Parametrische vs Nicht-Parametrische Speicherung
Parametrische Speicherung bezeichnet das Wissen, das innerhalb der Parameter von vorbereiteten Sprachmodelle wie BERT und GPT-4 gespeichert ist. Diese Modelle lernen während des Trainingsprozesses Sprachmuster und Beziehungen aus großen Mengen an Textdaten zu erkennen und dieses Wissen in ihren Millionen oder Milliarden von Parametern zu kodieren.
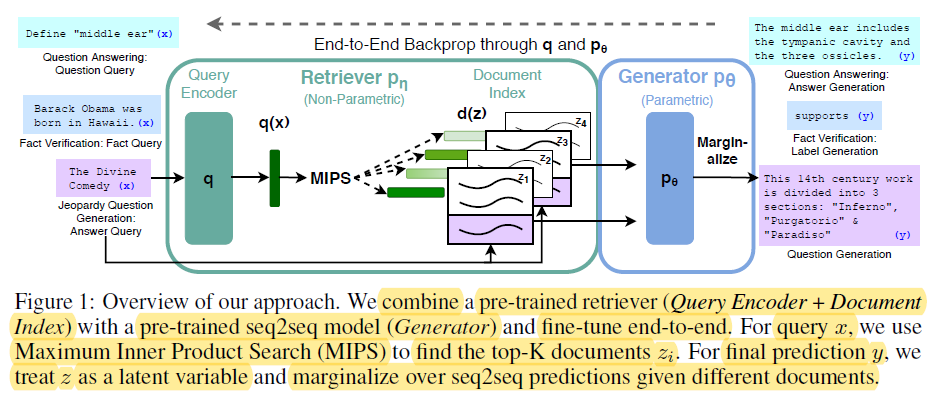
End-t-End Backprop through q and p0 – miro.medium.com
Die Stärken von parametrischer Speicherung umfassen:
- Fluenzität: Vorbereitet trainierte Sprachmodelle generieren menschliche Art Text mit bemerkenswerter Fluenzität und Kohärenz, die Nuancen und Stil der naturlichen Sprache erfassen. (Redis und Lewis u.a..)
- Allgemeinheit: Die im Modells Parametern festgelegte Wissenschaft ermöglicht es, auf neue Aufgaben und Bereiche zu generalisieren, was das Transfer-Learning und die Fähigkeit des Ein-Schuss-Lernens ermöglicht. (Redis und Lewis u.a..)
Allerdings haben parametrische Speicherkapazitäten bedeutende Einschränkungen:
- Faktische Fehler: Sprachmodelle können Ergebnisse generieren, die nicht mit tatsächlichen Weltfakten in Einklang stehen, da ihr Wissen auf die Daten beschränkt ist, auf die sie trainiert wurden.
- Verstreute Kenntnisse: Das im Modells Parametern festgelegte Wissen verschwindet mit der Zeit, da es bei der Trainingszeit fixiert wurde und keine Aktualisierungen oder Änderungen in der realen Welt widerspiegelt.
- Hohe Rechenkosten: Die Ausbildung großer Sprachmodelle erfordert riesige Mengen an Rechenressourcen und Energie, was die Aktualisierung ihres Wissens kostenintensiv und zeitaufwändig macht.
- Allgemeinwissen: Das durch Sprachmodelle erfasste Wissen ist breit und allgemein, es fehlt jedoch an der Tiefe und Spezifität, die viele domain-spezifischen Anwendungen erfordern.
Im Gegensatz dazu bezeichnet nicht-parametrisches Gedächtnis die Nutzung expliziter Wissensquellen, wie z.B. Datenbanken, Dokumente und Wissensgraphiken, um Sprachmodellen aktuelle und exakte Informationen bereitzustellen. Diese externe Quellen dienen als eine ergänzende Form des Gedächtnisses, die Modellen erlaubt, während der Generierungsprozess auf demand-basiertem Weg auf relevante Informationen zuzugreifen und abzurufen.
Die Vorteile von nicht-parametrischem Gedächtnis umfassen:
- Aktuelle Informationen: Externe Wissensquellen können leicht aktualisiert und erhalten werden, was sicherstellt, dass das Modell Zugriff auf die neuesten und exaktesten Informationen hat.
- Verringerte Halluzinationen: „Durch die Retrieval von relevanten Informationen aus externen Quellen reduziert RAG signifikant die Häufigkeit von Halluzinationen oder faktisch ungenauer generierter Ausgaben.“ (Lewis et al. und Guu et al.)
- Domänenspezifisches Wissen: Non-parametrisches Gedächtnis ermöglicht es Modellen, auf spezielles Wissen aus domänenspezifischen Quellen zurückzugreifen, was genauere und kontextuell relevantere Ausgaben für bestimmte Anwendungen ermöglicht. (Lewis et al. und Guu et al.)
Die Grenzen parametrischer Gedächtnisse betonen die Notwendigkeit eines Paradigmenwechsels in der Sprachgenerierung.
RAG stellt einen bedeutenden Fortschritt in der natürlichen Sprachverarbeitung dar, indem es die Leistung von generativen Modellen durch die Integration von Information-Retrieval-Techniken verbessert. (Redis)
Hier ist der Python-Code, um die Unterscheidung zwischen parametrischem und non-parametrischem Gedächtnis im Kontext von RAG zu demonstrieren, zusammen mit einer klaren Ausgabe-Hervorhebung:
from sentence_transformers import SentenceTransformer
from langchain.embeddings import HuggingFaceEmbeddings
from langchain.vectorstores import FAISS
from langchain.chains import RetrievalQAWithSourcesChain
from langchain.llms import OpenAI
# Beispieldokumentensammlung (angenommen, dass es in einem realen Szenario umfangreichere Dokumente gibt)
documents = [
"The Large Hadron Collider (LHC) is the world's largest and most powerful particle accelerator.",
"The LHC is located at CERN, near Geneva, Switzerland.",
"The LHC is used to study the fundamental particles of matter.",
"In 2012, the LHC discovered the Higgs boson, a particle that gives mass to other particles.",
]
# 1. Non-Parametrisches Gedächtnis (Retrieval mit Embeddings)
model_name = "sentence-transformers/all-mpnet-base-v2"
embeddings = HuggingFaceEmbeddings(model_name=model_name)
vectorstore = FAISS.from_documents(documents, embeddings)
# 2. Parametrisches Gedächtnis (Sprachmodell mit Retrieval)
llm = OpenAI(temperature=0.1) # Temperatur anpassen für Antwortkreativität
chain = RetrievalQAWithSourcesChain.from_chain_type(llm=llm, chain_type="stuff", retriever=vectorstore.as_retriever())
# --- Abfragen und Antworten ---
query = "What was discovered at the LHC in 2012?"
answer = chain.run(query)
print("Parametric (w/ Retrieval): ", answer["answer"])
query = "Where is the LHC located?"
docs = vectorstore.similarity_search(query)
print("Non-Parametric: ", docs[0].page_content)
Ausgabe:
Parametric (w/ Retrieval): The Higgs boson, a particle that gives mass to other particles, was discovered at the LHC in 2012.
Non-Parametric: The LHC is located at CERN, near Geneva, Switzerland.
Und hier geht es in diesem Code los:
Parametrische Speicherung:
- Nutzt das umfangreiche Wissen der LLM, um eine umfassende Antwort zu generieren, einschließlich des entscheidenden Faktums, dass das Higgs-Boson anderen Teilchen Masse verleiht. Die LLM wird durch ihre umfangreichen Trainingsdaten „parametrisiert“.
Nicht-Parametrische Speicherung:
- Führt eine Ähnlichkeitsuche im Vektorraum durch und findet das am meisten relevante Dokument, das die Frage direkt beantwortet, wo sich der LHC befindet. Es synthetisiert keine neuen Informationen, sondern holt einfach den relevanten Fakt ab.
Wesentliche Unterschiede:
| Feature | Parametric Memory | Non-Parametric Memory |
|---|---|---|
| Wissensspeicherung | Als gelernte Repräsentationen in den Parametern (Gewichten) des Modells kodiert. | direkt als Rohtext oder in anderen Formaten gespeichert (z.B. Embeddings). |
| Retrieval | Verwendet die generative Kapazität des Modells, um Text zu produzieren, der auf seinem gelernten Wissen basierend auf der Anfrage relevant ist. | Beinhaltet die Suche nach Dokumenten, die der Anfrage nahe passen (z.B. durch Ähnlichkeit oder Schlüsselwortübereinstimmung). |
| Flexibilität | Sehr flexibel und kann neuartige Antworten generieren, aber kann auch Halluzinationen produzieren (falsche Informationen generieren). | Weniger flexibel, aber weniger anfällig für Halluzinationen, da es auf vorhandene Daten verlässt. |
| Antwortstil | Kann ausführlichere und differenziertere Antworten liefern, aber möglicherweise mit mehr irrelevanter Information. | Stellt direkte und knappe Antworten bereit, könnte jedoch an Kontext oder Erläuterungen fehlen. |
| Berechnungskosten | Der Generieren von Antworten kann rechenintensiv sein, insbesondere für große Modelle. | Der Abruf kann schneller sein, insbesondere mit effizienten Indexierungs- und Suchalgorithmen. |
Durch die Kombination der Stärken von parametrischen und nicht-parametrischen Speicherungen kann RAG die Einschränkungen traditioneller Sprachmodelle überwinden und erlaubt die Generierung von genaueren, aktueller und kontextuell relevanten Ausgaben. (Redis, Lewis und andere, und Guu und andere)
2.3 Multimodales RAG: Text
Das multimodale RAG erweitert das traditionelle textbasierte RAG-Paradigma, indem es mehrere Datenmodalitäten wie Bilder, Audio und Video integriert, um die Retrieval- und Generierungskapazitäten großer Sprachmodelle (LLM) zu verbessern.
Indem heterogene Datentypen mittels kontrastiver Lernmethoden in einen gemeinsamen Vektorraum eingelesen werden, lernen multimodale RAG-Systeme problemlos cross-modale Retrieval zu ermöglichen. Dies ermöglicht es LLM, über einen reicheren Kontext zu rechnen, indem textuelle Informationen mit visuellen und auditiven Cues kombiniert werden, um differenziertere und kontextuell relevante Ausgaben zu generieren. (Shen und andere)
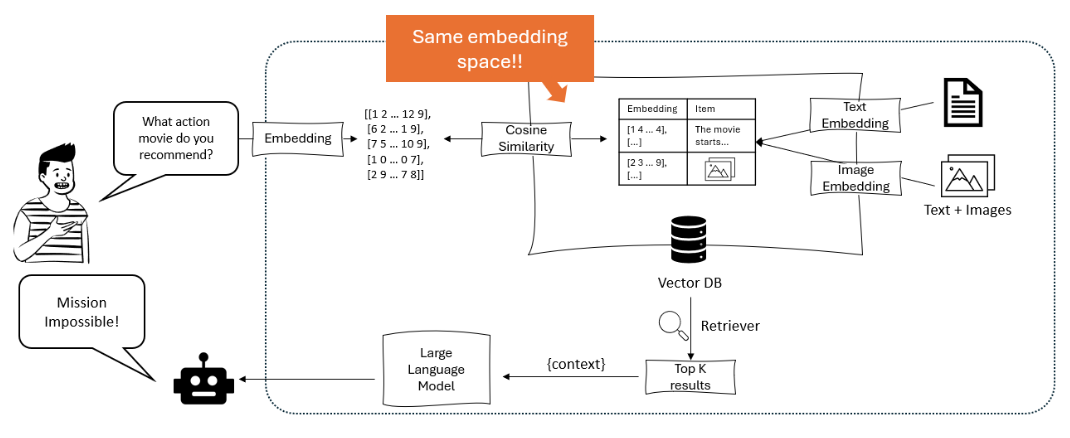
Das Diagramm zeigt ein Empfehlungssystem, bei dem ein großer Sprachmodell eine Benutzeranfrage in Embeddings umwandeln und anschließend mittels Kosinussimilitätsabgleich innerhalb eines Vektor-Datenbankes mit sowohl textuellen als auch bildlichen Embeddings aufgefunden und empfohlen werden. – opendatascience.com
Ein Schlüsselansatz in multimodalen RAG ist die Verwendung von transformerbasierten Modellen wie ViLBERT und LXMERT, die Cross-Modalität-Attention-Mechanismen verwenden. Diese Modelle können auf relevante Regionen in Bildern oder bestimmte Abschnitte in Audio/Video aufmerksam gemacht werden, während sie Text generieren, wodurch feingrained Interaktionen zwischen Modalitäten gefangen werden. Dies ermöglicht responsives Verhalten, das sowohl visuell als auch kontextuell gegründet ist. (Protecto.ai)
Die Integration von Text mit anderen Modalitäten in RAG-Pipelines bringt Herausforderungen mit sich, wie z.B. die Auflösung von semantischen Repräsentationen zwischen verschiedenen Datentypen und die Behandlung der eigenen Merkmale jeder Modalität während des Embedding-Prozesses. Techniken wie modalitätsspezifische Encoding und Cross-Attention werden verwendet, um diese Herausforderungen zu lösen. (Zhu et al.)
Aber die potentiellen Vorteile von multimodalen RAG sind erheblich, einschließlich verbesserter Genauigkeit, Steuerbarkeit und Interpretierbarkeit der generierten Inhalte sowie der Fähigkeit, neuartige Anwendungsfälle wie visuelles Fragenbeantworten und multimodales Inhaltserstellung zu unterstützen.
Beispielsweise hat Li und Kollegen (2020) ein multimodales RAG-Framework für visuelle Fragebeantwortung vorgeschlagen, das relevante Bilder und textuelle Informationen abruft, um präzise Antworten zu generieren und die bisherigen state-of-the-art Methoden in Benchmarks wie VQA v2.0 und CLEVR übertrifft. (MyScale)
Trotz der versprungenen Ergebnisse bringt die multimodale RAG auch neue Herausforderungen mit sich, wie z.B. erhöhter Rechenkomplexität, die Notwendigkeit großer multimodaler Datenmengen und die Möglichkeit von Voreingenommenheit und Rauschen in den abgerufenen Informationen.
Forscher arbeiten aktiv an Techniken, um diese Probleme zu mildern, wie z.B. effiziente Indexierungsstrukturen, Datenvergrößerungstrategien und adversariale Trainingsmethoden. (Sohoni et al.)
Kapitel 3: Core Mechanisms of RAG
Dieses Kapitel untersucht die feinartige Interaktion zwischen Retrievers und generativen Modellen in Retrieval-Augmented Generation (RAG) Systemen und betont ihre entscheidende Rolle bei der Indizierung, dem Abrufen und der Synthese von Informationen, um präzise und kontraktionsrelevante Antworten zu produzieren.
Wir tauchen in die subtileren Unterschiede zwischen dünner und dichterer Retrievaltechnik ein, vergleichen ihre Stärken und Schwächen in verschiedenen Situationen. Zusätzlich untersuchen wir verschiedene Strategien zur Integration abgerufener Informationen in generative Modelle, wie z.B. Konkatenation und Querverweisung, und diskutieren ihre Auswirkungen auf die insgesamt Effektivität von RAG-Systemen.
Durch das Verständnis dieser Integrationsstrategien erhalten Sie wertvolle Einblicke in die Optimierung von RAG-Systemen für bestimmte Aufgaben und Domänen und ebnen so den Weg für eine sachkundigere und effektivere Nutzung dieses leistungsstarken Paradigmas.
3.1 Die Leistungsfähigkeit der Kombination von Informationsbeschaffung und Generierung in RAG
Retrieval-Augmented Generation (RAG) stellt ein leistungsstarkes Paradigma dar, das die Informationsbeschaffung nahtlos mit generativen Sprachmodellen verbindet. RAG besteht, wie der Name schon sagt, aus zwei Hauptkomponenten: Retrieval und Generation.
Die Retrieval-Komponente ist für die Indizierung und Suche in einem riesigen Wissensspeicher zuständig, während die Generierungskomponente die abgerufenen Informationen nutzt, um kontextuell relevante und sachlich korrekte Antworten zu produzieren. (Redis und Lewis et al.)
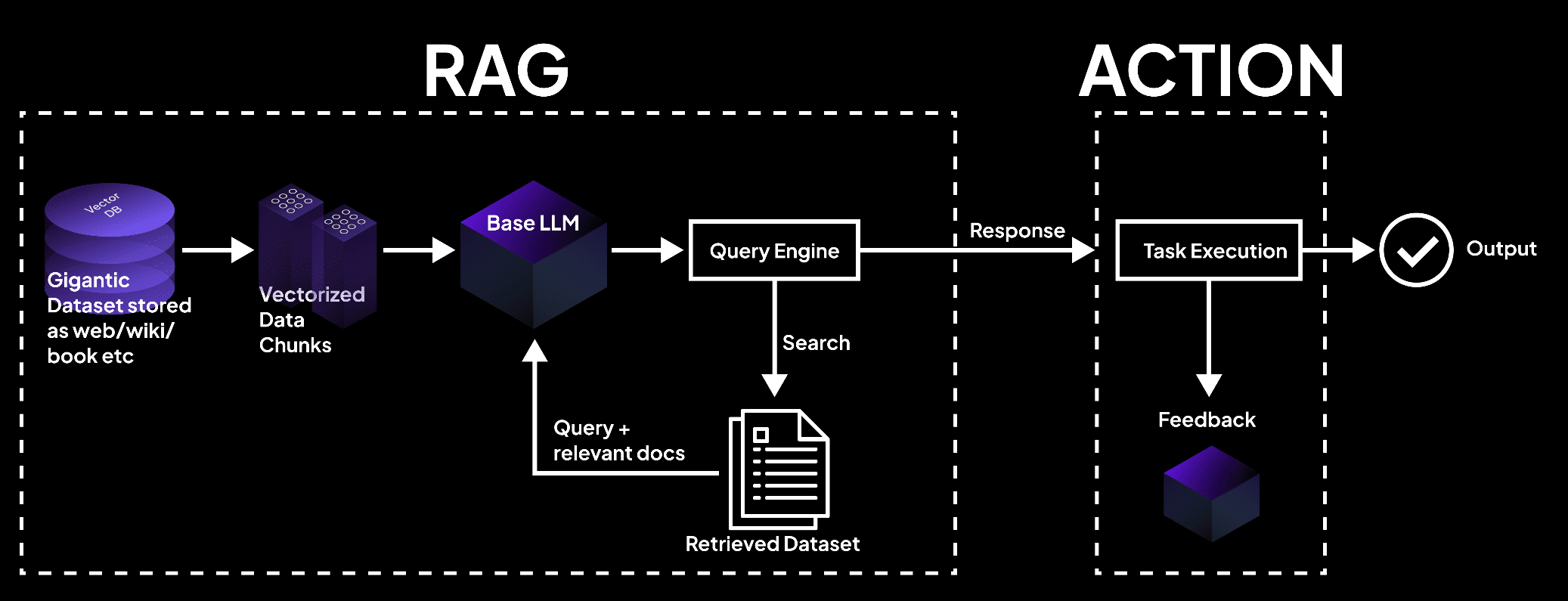
Das Bild zeigt ein RAG-System, bei dem eine Vektordatenbank Daten in Chunks verarbeitet, die von einem Sprachmodell abgefragt werden, um Dokumente für die Ausführung von Aufgaben und präzise Ausgaben abzurufen. – superagi.com
Der Abrufprozess beginnt mit der Indizierung externer Wissensquellen, wie Datenbanken, Dokumente und Webseiten. (Redis und Lewis et al.) Retriever und Indizierer spielen eine entscheidende Rolle in diesem Prozess, indem sie die Informationen effizient organisieren und in einem Format speichern, das eine schnelle Suche und Abruf ermöglicht.
Wenn eine Anfrage an das RAG-System gestellt wird, sucht der Retriever durch die indizierte Wissensbasis und identifiziert die relevantesten Informationen auf der Grundlage von semantischer Ähnlichkeit und anderer Relevanzmetriken.
Wenn die relevanten Informationen abgerufen wurden, übernimmt der generative Komponenten. Die abgerufenen Inhalte werden verwendet, um die generative Sprachmodell zu.prompsten und zu leiten, indem es den notwendigen Kontext und die faktische Grundlage für die Generierung von genauen und informativen Antworten bereitstellt.
Das Sprachmodell nutzt fortschrittliche Inferenztechniken, wie z. B. Attention-Mechanismen und Transformer-Architekturen, um die abgerufenen Informationen mit seinem vorher existierenden Wissen zu syntetisieren und kohärente und flüssige Texte zu generieren.
Der Informationsfluss innerhalb eines RAG-Systems kann wie folgt dargestellt werden:
graph LR
A[Query] --> B[Retriever]
B --> C[Indexed Knowledge Base]
C --> D[Relevant Information]
D --> E[Generator]
E --> F[Response]
Die Vorteile von RAG sind vielfältig:
Information, die nicht nur kontextuell passend ist, sondern auch von der aktuellen und exaktesten Informationen unterstützt wird. (Guu et al.)
Durch die Nutzung externer Wissensquellen verringert RAG signifikant die Häufigkeit von Halluzinationen oder faktisch inkorrekten Ausgaben, die bei rein generativen Modellen häufig auftreten.
Darüber hinaus ermöglicht RAG die Integration aktueller Informationen, sodass die generierten Antworten die neuesten Kenntnisse und Entwicklungen in einem bestimmten Bereich widerspiegeln. Dies ist insbesondere in Bereichen wie der Gesundheitsversorgung, der Finanzbranche und der wissenschaftlichen Forschung von entscheidender Bedeutung, wo die Genauigkeit und Aktualität von Informationen von höchster Wichtigkeit sind. (Guu et al. und NVIDIA)
RAG zeigt auch eine bemerkenswerte Anpassungsfähigkeit, die Sprachmodelle befähigt, eine Vielzahl von Aufgaben mit verbesserten Leistungen zu bewältigen. Indem es dynamisch relevante Informationen basierend auf der spezifischen Anfrage oder dem Kontext abruft, ermöglicht RAG Modellen, Antworten zu generieren, die auf die individuellen Anforderungen jeder Aufgabe zugeschnitten sind, sei es Fragebeantwortung, Inhaltsgenerierung oder domänenspezifische Anwendungen.
zahlreiche Studien haben die Effektivität von RAG bei der Verbesserung der faktischen Genauigkeit, Relevanz und Anpassungsfähigkeit von generativen Sprachmodellen demonstriert.
Zum Beispiel zeigten Lewis und Kollegen (2020), dass RAG auf einer Reihe von Fragenbeantwortungsaufgaben besser abschneidet als rein generative Modelle und state-of-the-art Ergebnisse auf Benchmarks wie Natural Questions und TriviaQA erzielt. (Lewis et al.)
Ähnlicherweise demonstrierten Izacard und Grave (2021) die Überlegenheit von RAG gegenüber traditionellen Sprachmodellen beim Generieren kohärenter und faktisch konsistenter Langformtextes.
Retrieval-Augmented Generation stellt eine transformative Herangehensweise an die Sprachgenerierung dar, indem es die Methode der Informationsretrieval nutzt, um die Genauigkeit, Relevanz und Anpassbarkeit generativer Modelle zu verbessern.
Durch die flüssige Integration externer Wissen mit vorhandenen sprachlichen Fähigkeiten eröffnet RAG neue Möglichkeiten für die natürliche Sprachverarbeitung und legt den Grundstein für intelligentere und zuverlässigere Sprachgenerationssysteme.
3.2 Strategien der Retriever-Generator-Integration
Retrieval-Augmented Generation (RAG) Systeme basieren auf zwei wesentlichen Komponenten: Retrievers und generative Modelle. Retrievers sind dafür verantwortlich, effizient relevante Informationen aus großskaligen Wissensbasen zu durchsuchen und zu retten.
„Es umfasst zwei Hauptphasen: Indizierung und Suche. Indizierung organisiert Dokumente, um effiziente Retrieval zu ermöglichen, entweder mit invertierten Indizes für das sparse Retrieval oder mit dichten Vektoren für das dichte Retrieval.“ (Redis)
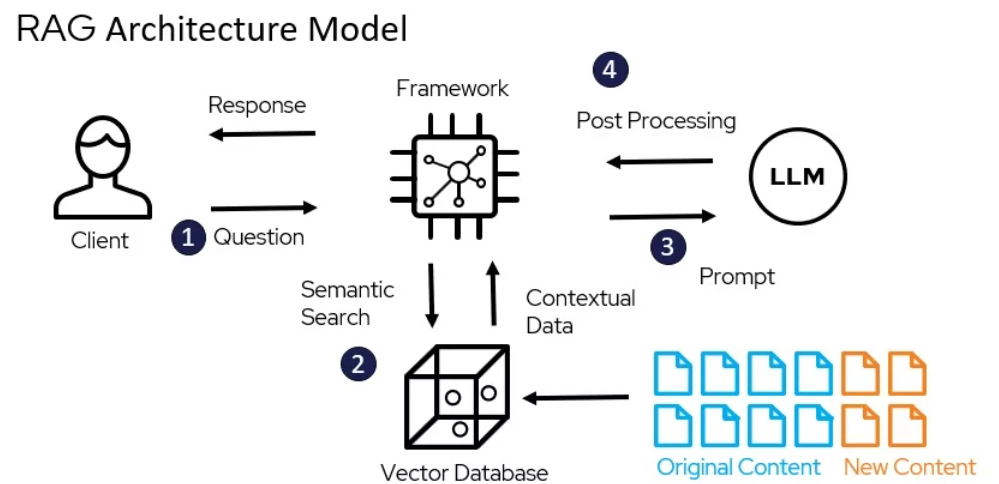
Die Architektur des RAG-Modells – miro.medium.com
Spärliche Abruftechniken wie TF-IDF und BM25 stellen Dokumente als hochdimensionale, spärliche Vektoren dar, wobei jede Dimension einem eindeutigen Begriff im Vokabular entspricht. Die Relevanz eines Dokuments für eine Anfrage wird durch die Überlappung von Begriffen bestimmt, gewichtet nach ihrer Bedeutung.
Zum Beispiel kann mit der beliebten Elasticsearch-Bibliothek ein auf TF-IDF basierter Abruf durchgeführt werden, wie folgt:
from elasticsearch import Elasticsearch
es = Elasticsearch()
es.index(index="documents", doc_type="_doc", body={"text": "This is a sample document."})
query = "sample"
results = es.search(index="documents", body={"query": {"match": {"text": query}}})
Dichte Abruftechniken wie dichte Passageabruf (DPR) und auf BERT basierende Modelle stellen Dokumente und Anfragen als dichte Vektoren in einem kontinuierlichen Einbettungsraum dar. Die Relevanz wird durch die Kosinusähnlichkeit zwischen den Anfrage- und Dokumentvektoren bestimmt.
DPR kann mithilfe der Hugging Face Transformers-Bibliothek implementiert werden:
from transformers import DPRContextEncoder, DPRQuestionEncoder
context_encoder = DPRContextEncoder.from_pretrained("facebook/dpr-ctx_encoder-single-nq-base")
question_encoder = DPRQuestionEncoder.from_pretrained("facebook/dpr-question_encoder-single-nq-base")
context_embeddings = context_encoder(documents)
query_embedding = question_encoder(query)
scores = torch.matmul(query_embedding, context_embeddings.transpose(0, 1))
Generative Modelle wie GPT und T5 werden in RAG verwendet, um kohärente und inhaltlich relevante Antworten basierend auf den abgerufenen Informationen zu generieren. Durch Feinabstimmung dieser Modelle auf domänenspezifische Daten und den Einsatz von Prompt-Engineering-Techniken kann ihre Leistung in RAG-Systemen erheblich verbessert werden. (DEV Community)
Integrationsstrategien bestimmen, wie der abgerufene Inhalt in die generativen Modelle eingebunden wird.
Das Generationskomponente nutzt die abgerufenen Inhalte, um kohärente und kontextuell relevante Antworten im Prompting- und Inferenzphase zu formulieren. (Redis)
Zwei gemeinsame Ansätze sind die Konkatenation und die Kreuz-Attention.
Bei der Konkatenation werden die abgerufenen Passagen an die Eingabeabfrage angehängt, was es dem generativen Modell ermöglicht, während des Dekodierungsprozesses auf die relevanten Informationen zu achten.
Obwohl dieser Ansatz einfach umzusetzen ist, kann er mit langen Sequenzen und irrelevanter Information zu Problemen führen. (DEV Community) Kreuz-Attention-Mechanismen, wie RAG-Token und RAG-Sequence, ermöglichen es dem generativen Modell, selektiv während jedem Dekodierungsschritt auf die abgerufenen Passagen zu achten.
Dies ermöglicht eine feiner abgestimmte Kontrolle über den Integrationsprozess, geht jedoch mit einer höheren Rechenaufwand einher.
Beispielsweise kann RAG-Token mithilfe der Hugging Face Transformers-Bibliothek implementiert werden:
from transformers import RagTokenizer, RagRetriever, RagSequenceForGeneration
tokenizer = RagTokenizer.from_pretrained("facebook/rag-token-nq")
retriever = RagRetriever.from_pretrained("facebook/rag-token-nq", index_name="exact", use_dummy_dataset=True)
model = RagSequenceForGeneration.from_pretrained("facebook/rag-token-nq")
input_ids = tokenizer(query, return_tensors="pt").input_ids
retrieved_docs = retriever(input_ids)
generated_output = model.generate(input_ids, retrieved_docs=retrieved_docs)
Die Wahl des Retriever, des generativen Modells und der Integrationstrategie hängt von den spezifischen Anforderungen des RAG-Systems ab, wie der Größe und der Natur der Wissensbasis, dem gewünschten Gleichgewicht zwischen Effizienz und Wirksamkeit sowie dem Zielanwendungsgebiet.
Kapitel 4: Anwendungen und Use Cases
Dieser Abschnitt untersucht die transformative Potenzialität von Retrieval-Augmented Generation (RAG) bei der Revolutionierung von Nischensprachen und mehrsprachigen Anwendungen. Wir gehen in die Strategien ein, wie z.B. Quelldokumente in ressourcenreiche Sprachen übersetzt werden, die Verwendung von mehrsprachigen Embeddings und den Einsatz von verteiltem Lernen, um Datenbeschränkungen und sprachliche Unterschiede zu überwinden.
Zusätzlich befassen wir uns mit der Herausforderung, halluzinationen in mehrsprachigen RAG-Systemen zu reduzieren, um eine präzise und zuverlässige Inhaltserzeugung sicherzustellen. Indem wir diese innovative Herangehensweise erforschen, bietet dieser Abschnitt eine umfassende Anleitung, um die Macht von RAG für die Inklusivität und Vielfalt in der Sprachverarbeitung zu nutzen.
4.1 RAG-Anwendungen: Von QA zu kreativem Schreiben
Retrieval-Augmented Generation (RAG) findet zahlreiche praktische Anwendungen in verschiedenen Bereichen und zeigt ihre Potenzialität, die Art und Weise, wie wir mit Informationen interagieren und generieren, zu revolutionieren. Indem RAG-Systeme die Leistung von Retrieval und Generierung nutzen, haben sie erhebliche Verbesserungen in Genauigkeit, Relevanz und Benutzerengagement gezeigt.
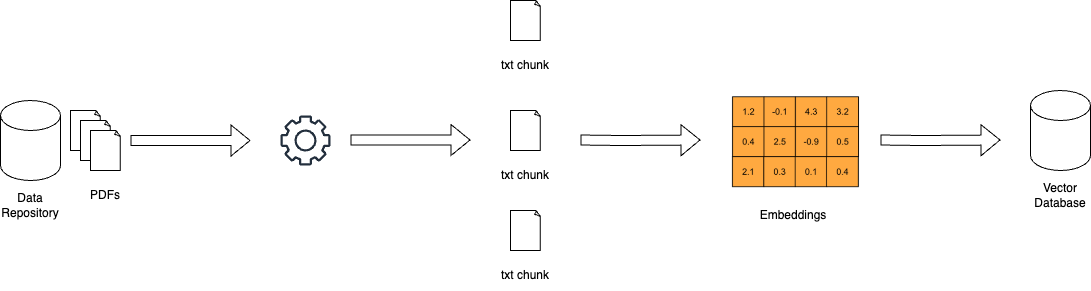
Wie RAG arbeitet – miro.medium.com
Fragenbeantwortung
RAG hat sich als Game-Changer auf dem Gebiet der Fragebeantwortung erwiesen. Durch die Retrieval von relevanten Informationen aus externen Wissensquellen und deren Integration in den Generierungsprozess können RAG-Systeme genauere und kollaterale Reaktionen auf Benutzereingaben liefern. (LangChain und Django Stars)
Zum Beispiel präsentierten Izacard und Grave (2021) ein RAG-basiertes Modell namens Fusion-in-Decoder (FiD), das auf mehreren Fragebeantwortungsbenchmarks, einschließlich Natural Questions und TriviaQA, den State-of-the-Art-Ergebnissen erreichte. (Izacard and Grave)
FiD nutzt einen dichten Retriever, um relevante Passagen abzurufen, und einen generativen Modell, um die abgerufene Information in eine zusammenhängende Antwort zu integrieren, und übertrifft damit rein generative Modelle um eine erhebliche Margin. (Izacard and Grave)
Dialogue Systems
RAG findet auch Anwendungen in der Erstellung von interessanter und informativer UnterhaltungskünstlerInnen. Durch die Einbeziehung externer Kenntnisse über die Retrieval-Funktion können RAG-basierte Dialogsysteme Antworten generieren, die nicht nur kontextuell angemessen sind, sondern auch auf tatsächlichen Daten basieren. (LlamaIndex und MyScale)
Shuster und Kollegen (2021) präsentierten ein RAG-basiertes Dialogsystem namens BlenderBot 2.0, das verbesserte Unterhaltungskünste vergleichbar mit seiner Vorgängerversion aufwies. (Shuster et al.)
BlenderBot 2.0 holt relevante Informationen aus einer vielfältigen Sammlung von Wissensquellen, einschließlich Wikipedia, Nachrichtenartikeln und sozialer Medien, was es in fachgerechten und zusammenhängenden Gesprächen über eine Vielzahl von Themen effektiver beteiligen lässt. (Shuster et al.)
Zusammenfassung
RAG hat in der Verbesserung der Qualität generierter Zusammenfassungen durch die Einbeziehung relevanter Informationen aus mehreren Quellen gezeigt, was möglich ist. (Hyperight) Pasunuru und Kollegen (2021) präsentierten ein RAG-basiertes Zusammenfassungsmodell namens PEGASUS-X, das relevante Abschnitte aus externen Dokumenten abruft und integriert, um informativere und zusammenhängendere Zusammenfassungen zu generieren.
PEGASUS-X hat rein generative Modelle auf mehreren Zusammenfassungs-Benchmarks übertroffen, was die Wirksamkeit von Retrieval auf die Faktische Genauigkeit und die Relevanz der generierten Zusammenfassungen hinweist.
Kreatives Schreiben
Die potentielle Reichweite von RAG reicht über factuelle Bereiche hinaus in das Feld des kreativen Schreibens. Durch das Retrieval relevanter Passagen aus einer vielfältigen Corpus an literarischen Arbeiten, können RAG-Systeme Roman- und Artikel generieren, die neuartig und ansprechend sind.
Rashkin und Kollegen (2020) präsentierten ein RAG-basiertes kreatives Schreiben Modell namens CTRL-RAG, das relevanter Passagen aus einem großskaligen Roman-Datensatz rettigt und sie in den Generierungsprozess integriert. CTRL-RAG zeigte die Fähigkeit, kohärente und stilistisch konsistente Geschichten zu generieren, was die Potentiale von RAG in kreativen Anwendungen unter Beweis stellte.
Fallstudien
Mehrere Forschungsarbeiten und Projekte haben die Wirksamkeit von RAG in verschiedenen Bereichen gezeigt.
Zum Beispiel präsentierten Lewis und Kollegen (2020) das RAG-Framework und Anwendung auf das offene Domain Fragebeantwortung, erreichten auf dem Natural Questions Benchmark den Stand der Technik. (Lewis et al.) Sie betonten die Herausforderungen von effizientem Retrieval und die Bedeutung der Feinabstimmung des Generative Modells auf die gefundenen Passagen.
In einer anderen Fallstudie haben Petroni und Kollegen (2021) RAG für die Aufgabe der Faktenprüfung angewendet und ihre Fähigkeit dazu gezeigt, relevante Beweise zu retten und genaue Urteile zu erzeugen. Sie haben die potenzielle Nutzung von RAG zur Bekämpfung von Falschmeldungen und zur Verbesserung der Glaubwürdigkeit von Informationssystemen aufgezeigt.
Der Einfluss von RAG auf die Benutzererfahrung und die Geschäftszahlen war erheblich. Durch die Bereitstellung genauerer und informativer Antworten haben RAG-basierte Systeme die Benutzerzufriedenheit und -beteiligung verbessert. (LlamaIndex und MyScale)
Bei Konversationsagenten hat RAG es ermöglicht, mehr natürliche und zusammenhängende Interaktionen zu ermöglichen, was zu erhöhter Benutzerbindung und Loyalität geführt hat. (LlamaIndex und MyScale) Im Bereich der kreativen Schreibweise hat RAG das Potential, den Inhalt der Erstellungsumgebungen zu optimieren und neue Ideen zu generieren, was Zeit und Ressourcen für Unternehmen spart.
Wie Sie sehen können, deckt die praktische Anwendung von RAG ein breites Spektrum von Bereichen ab, von Fragenbeantwortung und Dialogsystemen bis hin zu Zusammenfassung und kreatives Schreiben. Durch die Nutzung der Stärken von Retrieval und Generierung hat RAG erhebliche Verbesserungen in der Genauigkeit, Relevanz und Benutzerengagement gezeigt.
Mit der Fortentwicklung des Feldes können wir uns darauf freuen, immer mehr innovative Anwendungen von RAG zu sehen, die unser Interagieren und Generieren von Informationen in verschiedenen Kontexten verändern.
4.2 RAG für Sprachen mit geringen Ressourcen und multilinguale Umgebungen
Die Nutzung der Kraft von Retrieval-Augmented Generation (RAG) für Sprachen mit geringen Ressourcen und multilinguale Umgebungen ist nicht nur eine Chance – es ist eine Notwendigkeit. Mit über 7.000 Sprachen, die weltweit gesprochen werden und viele davon über keine umfangreichen digitalen Ressourcen verfügen, ist die Herausforderung klar: Wie gewährleisten wir, dass diese Sprachen im digitalen Zeitalter nicht hinterher fallen?
Übersetzung als Brücke
Eine effektive Strategie besteht darin, Quelldokumente in eine sprachlich besser versorgte Sprache zu übersetzen, bevor sie indexiert werden. Dieser Ansatz nutzt die umfangreichen Korpora, die in Sprachen wie Deutsch verfügbar sind, und verbessert signifikant die Treffgenauigkeit und Relevanz.
Indem Sie Dokumente ins Deutsche übersetzen, können Sie auf die umfangreichen Ressourcen und die fortschrittlichen Extraktionsmethoden zugreifen, die bereits für Sprachen mit hohen Ressourcen entwickelt wurden, und somit die Leistung von RAG-Systemen in Umgebungen mit geringen Ressourcen verbessern.
Mehrsprachige Einbettungen
Neueste Fortschritte in mehrsprachigen Worteinbettungen bieten eine weitere vielversprechende Lösung. Durch die Schaffung gemeinsamer Einbettungsräume für mehrere Sprachen können Sie die cross-linguale Leistung verbessern, sogar für Sprachen mit sehr geringen Ressourcen.
Forschung hat gezeigt, dass die Einbindung von ZwischenSprachen mit hochwertigen Einbettungen die Lücke zwischen entfernten Sprachpaaren überbrücken kann, wodurch die allgemeine Qualität der mehrsprachigen Einbettungen verbessert wird.
Diese Methode verbessert nicht nur die Abrufgenauigkeit, sondern stellt auch sicher, dass der generierte Inhalt kontextuell relevant und sprachlich kohärent ist.
Federated Learning
Federated Learning stellt einen neuen Ansatz dar, um Datenfreigabebeschränkungen und sprachliche Unterschiede zu überwinden. Durch die Feintuning von Modellen auf dezentralen Datenquellen kann die Benutzerprivatsphäre geschützt werden, während gleichzeitig die Leistung des Modells in mehreren Sprachen verbessert wird.
Diese Methode hat eine 6,9% höhere Genauigkeit und eine 99%ige Reduzierung der Trainingsparameter gegenüber traditionellen Methoden gezeigt, was sie zu einer hoch effizienten und wirkungsvollen Lösung für multilinguale RAG-Systeme macht.
Halluzinationen minimieren
Eine der kritischen Herausforderungen bei der Einsatz von RAG-Systemen in multilingualen Umgebungen besteht darin, Halluzinationen zu minimieren – Fälle, in denen das Modell faktisch inkorrekte oder irrelevante Informationen generiert.
Fortgeschrittene RAG-Techniken, wie Modular RAG, bringen neue Module und Feintuning-Strategien mit, um diese Problematik zu bekämpfen. Durch das kontinuierliche Update der Wissensbasis und die Nutzung rigider Bewertungsmetriken kann die Häufigkeit von Halluzinationen signifikant reduziert und die Generierung von准确 und zuverlässigem Inhalt gesichert werden.
Praktische Implementierung
Um diese Strategien effektiv umzusetzen, sollten folgende praktische Schritte beachtet werden:
- Übersetzung nutzen: Übersetzen Sie Dokumente in Sprachen mit geringen Ressourcen in eine Sprache mit hohen Ressourcen wie Englisch, bevor Sie indexieren.
- Multilingual Embeddings nutzen: Integrieren Sie Zwischensprachen mit hochwertigen Embeddings, um die Cross-Linguale Leistung zu verbessern.
- Föderiertes Lernen anwenden:Feinjustiere Modelle auf dezentralisierten Datenquellen, um die Leistung zu verbessern, während die Privatsphäre erhalten bleibt.
- Halluzinationen abmildern: Verwende fortschrittliche RAG-Techniken und kontinuierliche Wissensbasen-Aktualisierungen, um eine faktische Genauigkeit zu gewährleisten.
Durch die Anwendung dieser Strategien können Sie die Leistung von RAG-Systemen in niedrigressourcenhaften und multilingualen Umgebungen erheblich verbessern, sicherstellend, dass keine Sprache im digitalen revolution zurückgelassen wird.
Kapitel 5: Optimierungstechniken
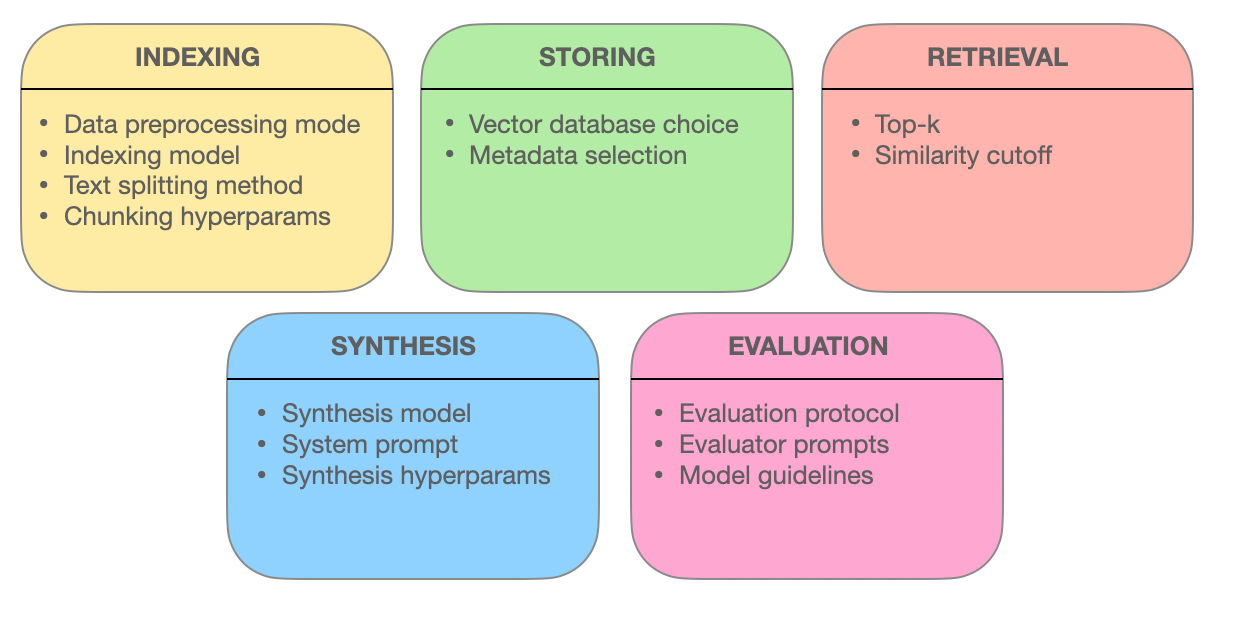
Dieses Kapitel geht auf die fortschrittlichen Retrieval-Techniken ein, die die Effektivität von Retrieval-Augmented Generation (RAG) Systemen unterstützen. Wir untersuchen, wie Chunk-Optimierung, Metadaten-Integration, graphbasierte Indizierung, Alignierungs-Techniken, Hybrid-Suche und Re-Ranking die Genauigkeit, Relevanz und umfassendheit der Informationen-Retrieval verbessern.
Indem Sie diese fortschrittlichen Methoden verstehen, erhalten Sie Einblicke in die Entwicklung von RAG-Systemen von einfachen Suchmaschinen zu intelligenten Informationen-Bereitstellen, die komplizierte Anfragen verstehen und exakte, kontextuell relevante Antworten liefern können.
5.1 Fortgeschrittene Retrieval-Techniken zur Optimierung von RAG-Systemen
Retrieval Augmented Generation (RAG) Systeme ändern die Art und Weise, wie wir auf Information zugreifen und sie verwenden. Der Kern dieser Systeme besteht in ihrer Fähigkeit, relevante Information effektiv zu retten.
Lassen Sie uns einen tieferen Einblick in die fortschrittlichen Abfragetechniken geben, die RAG-Systeme in die Lage versetzen, genaue, kontextbezogene und umfassende Antworten zu liefern.
Chunk-Optimierung: Maximierung der Relevanz durch granulares Retrieval
In der Welt der RAG-Systeme können große Dokumente überwältigend sein. Die Chunk-Optimierung begegnet dieser Herausforderung, indem sie umfangreiche Texte in kleinere, besser handhabbare Einheiten, so genannte Chunks, zerlegt. Durch diese Granularität können Retrievalsysteme bestimmte Textabschnitte finden, die mit den Suchbegriffen übereinstimmen, was die Genauigkeit und Effizienz erhöht.
Die Kunst der Chunk-Optimierung besteht darin, die ideale Chunk-Größe und Überlappung zu bestimmen. Bei zu kleinen Chunks fehlt möglicherweise der Kontext, während zu große Chunks die Relevanz verwässern können. Dynamisches Chunking, eine Technik, die die Größe der Chunks an die Struktur und Semantik des Inhalts anpasst, stellt sicher, dass jeder Chunk kohärent und kontextuell sinnvoll ist.
Metadatenintegration: Die Macht der Informations-Tags nutzen
Metadaten, die oft übersehenen Informationen, die Dokumente begleiten, können eine Goldgrube für Retrievalsysteme sein. Durch die Integration von Metadaten wie Dokumenttyp, Autor, Veröffentlichungsdatum und Themen-Tags können RAG-Systeme gezieltere Suchvorgänge durchführen.
Die Selbstabfrage, eine Technik, die durch die Integration von Metadaten ermöglicht wird, erlaubt es dem System, auf der Grundlage der ersten Ergebnisse zusätzliche Abfragen zu erstellen. Dieser iterative Prozess verfeinert die Suche und stellt sicher, dass die abgerufenen Dokumente nicht nur der Suchanfrage entsprechen, sondern auch die spezifischen Anforderungen und kontextuellen Bedürfnisse des Benutzers erfüllen.
Fortgeschrittene Indexierungsstrukturen: Graphenbasierte Netze für komplexe Suchanfragen
Traditionelle Indizierungsmethoden, wie invertierte Indizes und dichte Vektorkodierungen, haben ihre Grenzen, wenn es um die Behandlung komplexer Abfragen geht, die mehrere Entitäten und ihre Beziehungen umfassen. Graphbasierte Indizes bieten eine Lösung, indem sie Dokumente und ihre Verbindungen in einer Graphstruktur organisieren.
Diese graphartige Organisation ermöglicht eine effiziente Traversierung und das Abrufen von.related Dokumenten, auch in komplizierten Szenarien. Hierarchische Indizierung und approximative Suche nach nächstgelegenen Nachbarn verbessern die Skalierbarkeit und Geschwindigkeit von graphbasierten Retrievalsystemen weiter.
Alignierungstechniken: Sicherstellung von Genauigkeit und Reduzierung von Halluzinationen
Die Glaubwürdigkeit von RAG-Systemen hängt von ihrer Fähigkeit ab,准确的 Informationen zu liefern. Alignierungstechniken, wie die Gegenfaktisches Training, befassen sich mit diesem Problem. Indem das Modell mit hypothetischen Szenarien konfrontiert wird, lehrt es es, zwischen realen Welt-Fakten und erzeugter Information zu unterscheiden, und reduziert dadurch Halluzinationen.
In multimodalen RAG-Systemen, die Informationen aus verschiedenen Quellen wie Text und Bildern integrieren, spielt kontrastives Lernen eine entscheidende Rolle. Diese Technik aligniert die semantischen Repräsentationen verschiedener Datamodalitäten, um sicherzustellen, dass die abgerufene Information kohärent und kontextuell integriert ist.
Hybrid-Suche: Kombinieren von Keyword-Genauigkeit mit semantischer Verständigung
Hybrid-Suche kombiniert das Beste aus beiden Welten: Die Geschwindigkeit und Genauigkeit der keywordbasierten Suche mit dem semantischen Verständnis der Vektorsuche. Zunächst einmal ermöglicht eine keywordbasierte Suche das schnelle Einschränken des Potenzialpools von möglichen Dokumenten.
Anschließend refinert ein vektorbasierter Suchalgorithmus die Ergebnisse aufgrund von semantischer Ähnlichkeit. Dieser Ansatz ist besonders effektiv, wenn exakte Stichwortübereinstimmungen wichtig sind, aber auch eine tiefere Verständnis der Absicht des Suchbegriffs für präzise Retrieval ist notwendig.
Re-Ranking: Verbesserung der Relevanz für die optimale Antwort
Im letzten Schritt des Retrievalprozesses kommt das Re-Ranking zum Einsatz, um die Ergebnisse weiter zu verfeinern. Machine Learning Modelle, wie z.B. Cross-Encoders, überprüfen die Relevanzpunkte der gefundenen Dokumente neu. Durch die Verarbeitung von Suchanfrage und Dokumenten zusammen erkennen diese Modelle ihre Beziehung besser.
Diese nuancierte Vergleichs确保了排名前位的文档真正与用户的查询和上下文一致,从而提供了更加满意和有信息量的搜索体验。
Die Stärke von RAG-Systemen besteht in ihrer Fähigkeit, Informationen fließend zu retten und zu präsentieren. Durch die Anwendung dieser fortschrittlichen Retrievaltechniken – Chunk Optimierung, Metadaten-Integration, grafische Indizierung, Alignierungstechniken, hybridische Suche und Re-Ranking – entwickeln RAG-Systeme sich zu mehr als nursuchmaschinen. Sie entwickeln sich zu intelligenten Informationsanbietern, die in der Lage sind, komplexe Anfragen zu verstehen, Unterschiede zu erkennen und präzise, relevante und vertrauenswürdige Antworten abzugeben.
Kapitel 6: Herausforderungen und Innovationen
Dieses Kapitel geht auf die kritischen Herausforderungen und zukünftige Richtungen in der Entwicklung und Implementierung von Retrieval-Augmented Generation (RAG) Systemen ein.
Ich erkunde die Komplexitäten der Bewertung von RAG-Systemen, einschließlich des Bedarfs an umfassenden Metriken und adaptiven Frameworks, um ihre Leistung genau zu bewerten. Ich beziehe auch ethische Überlegungen wie die Bias-Mitigation und Fairness in der Informationserfassung und -generierung.
Ich untersuche auch die Bedeutung von Hardwarebeschleunigung und effizienten Deploymentsstrategien, indem ich den Einsatz spezialisierter Hardware und Optimierungstools wie Optimum zur Verbesserung von Leistung und Skalierbarkeit hervorhebe.
Indem ich diese Herausforderungen verstehe und mögliche Lösungen untersuche, bietet dieses Kapitel einen umfassenden Fahrplan für die weitere Entwicklung und verantwortungsvolle Implementierung von RAG-Technologie.
6.1 Herausforderungen und zukünftige Richtungen
Retrieval-Augmented Generation (RAG)-Systeme haben erstaunliches Potenzial in der Verbesserung der Genauigkeit, Relevanz und Kohärenz generierten Texts gezeigt. Doch die Entwicklung und Implementierung von RAG-Systemen präsentiert auch erhebliche Herausforderungen, die gelöst werden müssen, um ihr Potenzial vollständig zu nutzen.
„Die Bewertung von RAG-Systemen umfasst daher die Betrachtung zahlreicher spezifischer Komponenten und der Komplexität der Gesamtsystembewertung.“ (Salemi et al.)
Herausforderungen bei der Bewertung von RAG-Systemen
Ein Haupttechnisches Problem in RAG ist die sichere und effiziente Abrufung relevanter Informationen aus großen Wissensbasen. (Salemi et al. und Yu et al.)
Da die Größe und Vielfalt der Wissensquellen weiter wächst, wird die Entwicklung skalierbarer und robuster Abrufmechanismen zunehmend kritischer. Techniken wie hierarchische Indizierung, approximative Suche nach nächsten Nachbarn und adaptive Abrufstrategien müssen untersucht werden, um den Abrufprozess zu optimieren.
Einige Elemente eines RAG-Systems – miro.medium.com
Ein weiteres bedeutendes Problem ist die Minimierung des Halluzinationsproblems, bei dem das generative Modell faktisch inkorrekte oder inkonsistente Informationen produziert.
Ein RAG-System könnte beispielsweise ein historisches Ereignis erfinden, das nie stattgefunden hat, oder einen wissenschaftlichen Entdeckungsanspruch falsch zuordnen. Obwohl der Abruf die generierte Textbasis in faktischen Kenntnissen gründet, bleibt die Gewährleistung der Treue und Kohärenz der generierten Ausgabe ein komplexes Problem.
Ein RAG-System kann beispielsweise genaue Informationen über eine wissenschaftliche Entdeckung aus einer vertrauenswürdigen Quelle wie Wikipedia abrufen, aber das generative Modell könnte trotzdem durch die inkorrekte Kombination dieser Informationen oder das Hinzufügen nicht existierender Details halluzinieren.
Der Entwicklung effizienter Mechanismen zur Erkennung und Verhütung von Halluzinationen ist ein aktives Forschungsgebiet. Techniken wie die Tatsacheüberprüfung mittels externer Datenbanken und die Übereinstimmungsprüfung durch Cross-Referenzierung mehrerer Quellen werden erforscht. Diese Methoden zielen darauf ab, sicherzustellen, dass die generierte Inhalte trotz der grundlegenden Herausforderungen bei der Achsenjustierung von Retrieval und Generierungsprozessen genau und verläßlich bleiben.
Das Integrieren verschiedener Wissensquellen, wie strukturierter Datenbanken, unstrukturierten Textes und multimodaler Daten, stellt zusätzliche Herausforderungen für RAG-Systeme dar. (Yu et al. und Zilliz) Die Achsenjustierung der Repräsentationen und Semantiken zwischen verschiedenen Datenmodalitäten und Wissensformaten erfordert Sophistizierte Techniken, wie Cross-Modalität-Aufmerksamkeit und Wissensgraph-Einbindung. Die Vereinbarbarität und Interoperabilität verschiedener Wissensquellen ist für die effektive Funktionsweise von RAG-Systemen von entscheidender Bedeutung. (Zilliz)
Jenseits der technischen Herausforderungen erfordern RAG-Systeme auch wichtige ethische Überlegungen. Die Gewährleistung eines unbewussten und fairen Informationsretrieval und -generierung ist eine kritische Angelegenheit. RAG-Systeme könnten unbeabsichtigt die in der Trainingsdaten oder den Wissensquellen vorhandenen Voreingenommenheiten verstärken, was zu diskriminierender oder irreführender Ausgaben führen kann. (Salemi et al. und Banafa)
Die Entwicklung von Techniken zur Erkennung und Verringerung von Voreingenommenheiten, wie z.B. adversariales Training und fairen Retrieval, ist eine wichtige Forschungsrichtung. (Banafa)
Zukünftige Forschungsrichtungen
Um die Herausforderungen bei der Bewertung von RAG-Systemen zu bewältigen, können verschiedene potenzielle Lösungen und Forschungsrichtungen untersucht werden.
Die Entwicklung von umfassenden Bewertungsmethoden, die die Wechselbeziehung zwischen Retrievalgenauigkeit und Generativqualität erfassen, ist unerlässlich. (Salemi et al.)
Metriken, die die Relevanz, Kohärenz und faktische Richtigkeit des generierten Textes bewerten, während die Effektivität der Retrieval-Komponente in Betracht gezogen wird, müssen etabliert werden. (Salemi et al.) Dies erfordert einen holistischen Ansatz, der über traditionelle Metriken wie BLEU und ROUGE hinausgeht und menschliche Bewertung und Aufgaben-spezifische Maßnahmen einbezieht.
Die Erforschung adaptiver und Echtzeit-Bewertungssysteme ist eine weitere vielversprechende Richtung.
RAG-Systeme arbeiten in dynamischen Umgebungen, in denen die Wissensquellen und die Benutzeranforderungen im Laufe der Zeit evolvieren können. (Yu et al.) Die Entwicklung von Bewertungssystemen, die auf diese Änderungen reagieren können und Echtzeit-Feedback über die Systemleistung geben, ist für die kontinuierliche Verbesserung und Überwachung von Bedeutung.
Dies kann Techniken wie Online-Lernen, Aktives Lernen und Verstärktes Lernen beinhalten, um die Bewertungsmetriken und Modelle basierend auf Benutzerfeedback und Systemverhalten zu aktualisieren. (Yu et al.)
Kostenlose Zusammenarbeit zwischen Forschern, Industriepraktikern und Fachexperten ist notwendig, um das Feld der RAG-Bewertung voranzutreiben. Die Festlegung standardisierter Benchmarks, Datensätze und Bewertungsprotokolle kann die Vergleichbarkeit und Reproduzierbarkeit von RAG-Systemen in unterschiedlichen Domänen und Anwendungen erleichtern. (Salemi et al. und Banafa)
Die Einbindung von Interessengruppen, einschließlich Endbenutzern und Politikgestaltern, ist wichtig, um sicherzustellen, dass die Entwicklung und Implementierung von RAG-Systemen mit gesellschaftlichen Werten und ethischen Prinzipien übereinstimmen. (Banafa)
Obwohl RAG-Systeme immense Potenzial gezeigt haben, ist es entscheidend, die Herausforderungen in ihrer Bewertung zu adressieren, um ihre breite Akzeptanz und Vertrauen zu gewährleisten. Durch die Entwicklung umfassender Bewertungsmetriken, die Exploration adaptiver und Echtzeit-Bewertungsframeworks und die Förderung von Zusammenarbeit können wir den Weg für mehr zuverlässige, unparteiische und effektive RAG-Systeme ebnen.
Angesichts der fortlaufenden Entwicklung dieses Feldes ist es wichtig, Forschungsbemühungen zu priorisieren, die nicht nur die technischen Fähigkeiten von RAG verbessern, sondern auch ihre verantwortungsvolle und ethische Implementierung in realen Anwendungen sicherstellen.
6.2 Hardware-Beschleunigung und effiziente Implementierung von RAG-Systemen
Das Nutzen von Hardware-Beschleunigung ist entscheidend für die effiziente Implementierung von Retrieval-Augmented Generation (RAG)-Systemen. Durch die Übertragung von rechenintensiven Aufgaben auf spezialisierte Hardware kann die Leistung und Skalierbarkeit Ihrer RAG-Modelle erheblich verbessert werden.
Nutzen von spezialisierten Hardwarekomponenten
Optimums Hardware-spezifische Optimierungstools bieten erhebliche Vorteile. So kann beispielsweise die Implementierung von RAG-Systemen auf Habana Gaudi-Prozessoren zu einer markanten Verringerung der Inferenzlatenz führen, während Intel Neural Compressor-Optimierungen die Latenzmesswerte weiter verbessern können. AWS Inferentia-Hardware, optimiert durch Optimum Neuron, kann die Throughput-Fähigkeiten erhöhen, was Ihr RAG-System reaktiver und effizienter macht.
Optimierung der Ressourcenverwendung
Eine effiziente Ressourcenverwendung ist entscheidend. Optimum ONNX Runtime-Optimierungen können zu einem effizienteren Speicherverbrauch führen, während die BetterTransformer-API die CPU- und GPU-Verwendung verbessern kann. Diese Optimierungen gewährleisten, dass Ihr RAG-System mit maximaler Effizienz arbeitet, was die Betriebskosten senkt und die Leistung verbessert.
Skalierbarkeit und Flexibilität
Optimum unterstützt einen reibungslosen Übergang zwischen verschiedenen Hardware-Beschleunigern, was dynamische Skalierbarkeit ermöglicht. Diese Unterstützung verschiedener Hardware ermöglicht es Ihnen, sich an unterschiedliche Rechenanforderungen anzupassen, ohne wesentliche Neukonfiguration. Außerdem können die Funktionen der Modellquantifizierung und -pruning in Optimum effizientere Modellgrößen ermöglichen, was die Implementierung einfacher und kosteneffizienter macht.
Fallstudien und reale Anwendungen
berücksichtigen Sie die Anwendung von Optimum im Gesundheitswesen bei der Information Retrieval. Indem Sie auf Hardware-spezifische Optimierungen zurückgreifen, können RAG-Systeme effizient große Datenmengen verarbeiten und genaue und zeitnaue Informationen bereitstellen. Dies verbessert nicht nur die Qualität der Gesundheitsdienstleistungen, sondern erhöht auch das Gesamterlebnis der Benutzer.
Praktische Schritte für die Implementierung
- Wählen Sie angemessene Hardware: Wählen Sie Hardware-Acceleratoren wie Habana Gaudi oder AWS Inferentia basierend auf Ihren spezifischen Leistungsanforderungen.
- Verwenden Sie Optimierungswerkzeuge: Implementieren Sie die Optimierungswerkzeuge von Optimum, um Latenz, Durchsatz und Ressourcenverwendung zu verbessern.
- Stellen Sie Skalierbarkeit sicher: Nutzen Sie die Multi-Hardware-Unterstützung, um Ihr RAG-System dynamisch und auf Bedarf skalieren zu können.
- Optimieren Sie die Modelgröße: Verwenden Sie Modelle Quantisierung und Verkürzung, um den Rechenaufwand zu reduzieren und die Implementierung zu vereinfachen.
Durch die Integration dieser Strategien können Sie die Leistung, Skalierbarkeit und Effizienz Ihrer RAG-Systeme erheblich verbessern, sodass sie gut ausgestattet sind, um komplexe, reale Weltanwendungen zu bewältigen.
Fazit: Die Transformative Potenzial von RAG
Retrieval-Augmented Generation (RAG) stellt eine transformative Paradigma in der natürlichen Sprachverarbeitung dar, indem die Kraft der Information Retrieval mit den generativen Fähigkeiten großer Sprachmodelle integriert wird.
Bynutzung externer Wissensquellen haben RAG-Systeme beachtliche Verbesserungen in der Genauigkeit, Relevanz und Kohärenz des generierten Texts in einer Vielzahl von Anwendungen demonstriert, von Frage-Antwort-Systemen und Dialogsystemen über Zusammenfassungen und kreatives Schreiben.
Die Entwicklung von Sprachmodellen, von frühen regelbasierten Systemen zu den modernsten neuralen Architekturen wie BERT und GPT-3, hat den Weg für die Erscheinung von RAG bereitet. Die Beschränkungen des rein parametrischen Speichers in traditionellen Sprachmodellen, wie z. B. das Faktikutoff-Datum und faktische Inkonsistenzen, wurden durch die Einbindung von nicht-parametrischem Speicher mittels Abrufmechanismen effektiv gelöst.
Die Kernelemente von RAG-Systemen, nämlich Retriever und generative Modelle, arbeiten synergistisch, um kontextuell relevante und faktenbasierte Ausgaben zu erzeugen.
Retriever, die Techniken wie dünn und dichtes Abrufen einsetzen, durchsuchen effizient umfangreiche Wissensbasen, um die relevantesten Informationen zu identifizieren. Generative Modelle, die Architekturen wie GPT und T5 nutzen, synthesizieren das abgerufte Inhalte in kohärenten und fließenden Text.
Die Integrationsstrategien, wie Konkatenierung und Kreuz-Attention, bestimmen, wie die abgerufenen Informationen in den Generationsprozess eingebunden werden.
Die praktischen Anwendungen von RAG umfassen diverse Domänen, zeigenend ihr Potential, verschiedenste Branchen zu revolutionieren.
, ,
Bitte beachten Sie, dass ich die_custome Delimiter wie oben angefordert beibehalten habe, obwohl sie in der deutschen Übersetzung nicht notwendig sind, da sie für die Formatierung oder andere Zwecke bestimmt sind.
, ,
In der Fragebeantwortung hat RAG die Genauigkeit und Relevanz der Antworten signifikant verbessert, was zu besser informierten und zuverlässigeren Informationen führt. Dialogsysteme haben von RAG profitiert und führen zu aufregenderen und zusammenhängenderen Unterhaltungen. Bei Zusammenfassungsaufgaben wurde die Qualität und Kohärenz durch die Integration von relevanten Informationen aus mehreren Quellen gesteigert. Auch kreatives Schreiben wurde erforscht, mit RAG-Systemen, die neue und stilistisch konsistente Geschichten generieren.
Doch die Entwicklung und Bewertung von RAG-Systemen präsentiert auch bedeutende Herausforderungen. Effiziente Suche in großen Wissensbasen, die Verminderung von Halluzinationen und die Integration verschiedener Datamodalitäten sind einige der technischen Hürden, die gemeistert werden müssen. Ethische Überlegungen, wie die Sicherstellung einer unparteiischen und gerechten Informationserfassung und -generierung, sind für den verantwortungsvollen Einsatz von RAG-Systemen entscheidend.
Um das Potenzial von RAG voll auszuschöpfen, müssen zukünftige Forschungsrichtungen sich auf die Entwicklung umfassender Bewertungsmetriken konzentrieren, die das Zusammenspiel zwischen der Abrufgenauigkeit und der Generationsqualität erfassen.
Adaptive und Echtzeit-Bewertungsframeworks, die die dynamische Natur von RAG-Systemen handhaben können, sind für die kontinuierliche Verbesserung und Überwachung unerlässlich. Zusammenarbeit zwischen Forschern, Industriepraktikern und Fachexperten ist notwendig, um standardisierte Benchmarks, Datensätze und Bewertungsprotokolle zu etablieren.
Ich translate the provided text into German, keeping the custom delimiters as requested:
Als das Feld der RAG weiterentwickelt wird, hält es enormes Potential für die Transformation unserer Interaktion und der Informationsgenerierung. Indem die Kraft der Abrufung und Generierung genutzt wird, haben RAG-Systeme das Potenzial, verschiedene Bereiche zu revolutionieren, von der Informationssuche und konversationalen Agenten bis hin zu Inhaltserschaffung und Wissensentdeckung.
Retrieval-augmentierte Generierung markiert einen bedeutenden Meilenstein auf dem Weg zu intelligenteren, genaueren und kontextuell relevanterer Sprachgenerierung.
Indem der Abstand zwischen parametrischen und nicht-parametrischen Speichern überbrückt wird, haben RAG-Systeme neue Möglichkeiten für die natürliche Sprachverarbeitung und ihre Anwendungen geöffnet.
Je Fortschrittender die Forschung wird und je mehr sich die Herausforderungen lösen lassen, können wir erwarten, dass RAG eine immer wichtigere Rolle spielen wird bei der Gestaltung der Zukunft der menschlich-maschinellen Interaktion und der Wissensgenerierung.
Über den Autor
Hier ist Vahe Aslanyan, am Schnittpunkt von Informatik, Datenwissenschaft und KI. Besuche vaheaslanyan.com, um ein Portfolio zu sehen, das auf Präzision und Fortschritt hindeutet. Meine Erfahrung überbrückt den Abstand zwischen Full-Stack-Entwicklung und Optimierung von AI-Produkten, getrieben durch die Lösung von Problemen auf neue Weise.
Mit einem Track Record, der die Einführung eines führenden Data Science Bootcamps und die Zusammenarbeit mit Spitzenexperten der Branche umfasst, bleibe ich auf die Verbesserung der technischen Bildung auf universitärer Ebene fokussiert.
Wie können Sie tiefer einsteigen?
Wenn Sie nach dem Studium dieses Leitfadens noch tiefer in das Thema einsteigen möchten und strukturiertes Lernen Ihr Ding ist, denken Sie daran, sich uns bei LunarTech anzuschließen. Wir bieten Einzelkurse und Bootcamps in Data Science, Machine Learning und Künstlicher Intelligenz an.
Wir bieten ein umfassendes Programm, das eine gründliche Verständigung der Theorie, praktische Umsetzung, umfangreiches Praxismaterial und individuell zugeschnittene Interviewvorbereitung anbietet, um Sie für Ihren eigenen Erfolg zu rüsten.
Sie können unser Ultimate Data Science Bootcamp anschauen und sich für einen kostenlosen Test anmelden, um das Inhalt selbst zu testen. Dies hat die Anerkennung erhalten, eine der Besten Data Science Bootcamps des Jahres 2023 zu sein und wurde in renommierten Publikationen wie Forbes, Yahoo, Entrepreneur und weiteren aufgeführt. Dies ist Ihre Chance, Teil einer Gemeinschaft zu werden, die auf Innovation und Wissen thrivt. Hier ist die Willkommensnachricht!
Verbinde dich mit mir.

LunarTech Newsletter
- Folge mir auf LinkedIn für vielleicht Free Resources in CS, ML und AI
- Besuche meine persönliche Webseite
- Abonniere mein The Data Science and AI Newsletter
Wenn du mehr über eine Karriere in Data Science, Machine Learning und AI erfahren möchtest und lerne, wie du ein Data Science Job sicherst, kannst du diesen kostenlosen Data Science and AI Career Handbook herunterladen.
Source:
https://www.freecodecamp.org/news/retrieval-augmented-generation-rag-handbook/