













In einer Ära, die durch eine exponentielle Zunahme der Datenerzeugung gekennzeichnet ist, müssen Organisationen diese Fülle an Informationen effektiv nutzen, um ihren Wettbewerbsvorteil zu wahren. Die effiziente Suche und Analyse von Kundendaten – wie die Identifizierung von Benutzervorlieben für Filmempfehlungen oder Sentiment-Analyse – spielt eine entscheidende Rolle bei der Förderung fundierter Entscheidungsfindung und der Verbesserung von Benutzererfahrungen. Beispielsweise kann ein Streaming-Dienst Vektor-Suche einsetzen, um Filme anhand individueller Sehgewohnheiten und Bewertungen zu empfehlen, während eine Einzelhandelsmarke Kundensentiments analysieren kann, um Marketingstrategien zu optimieren.
Als Dateningenieure sind wir damit beauftragt, diese anspruchsvollen Lösungen umzusetzen, um sicherzustellen, dass Organisationen handlungsrelevante Erkenntnisse aus umfangreichen Datensätzen gewinnen können. Dieser Artikel untersucht die Feinheiten der Vektor-Suche mit Elasticsearch und konzentriert sich auf effektive Techniken und bewährte Verfahren zur Leistungsoptimierung. Anhand von Fallstudien zur Bildwiederherstellung für personalisiertes Marketing und zur Textanalyse für die Gruppierung von Kundensentiments zeigen wir, wie die Optimierung der Vektor-Suche zu verbesserten Kundeninteraktionen und signifikantem Geschäftswachstum führen kann.
Was ist Vektor-Suche?
Die Vektorsuche ist eine leistungsstarke Methode zur Identifizierung von Ähnlichkeiten zwischen Datenpunkten, indem sie als Vektoren in einem hochdimensionalen Raum dargestellt werden. Dieser Ansatz ist besonders nützlich für Anwendungen, die eine schnelle Wiederherstellung ähnlicher Elemente basierend auf ihren Attributen erfordern.
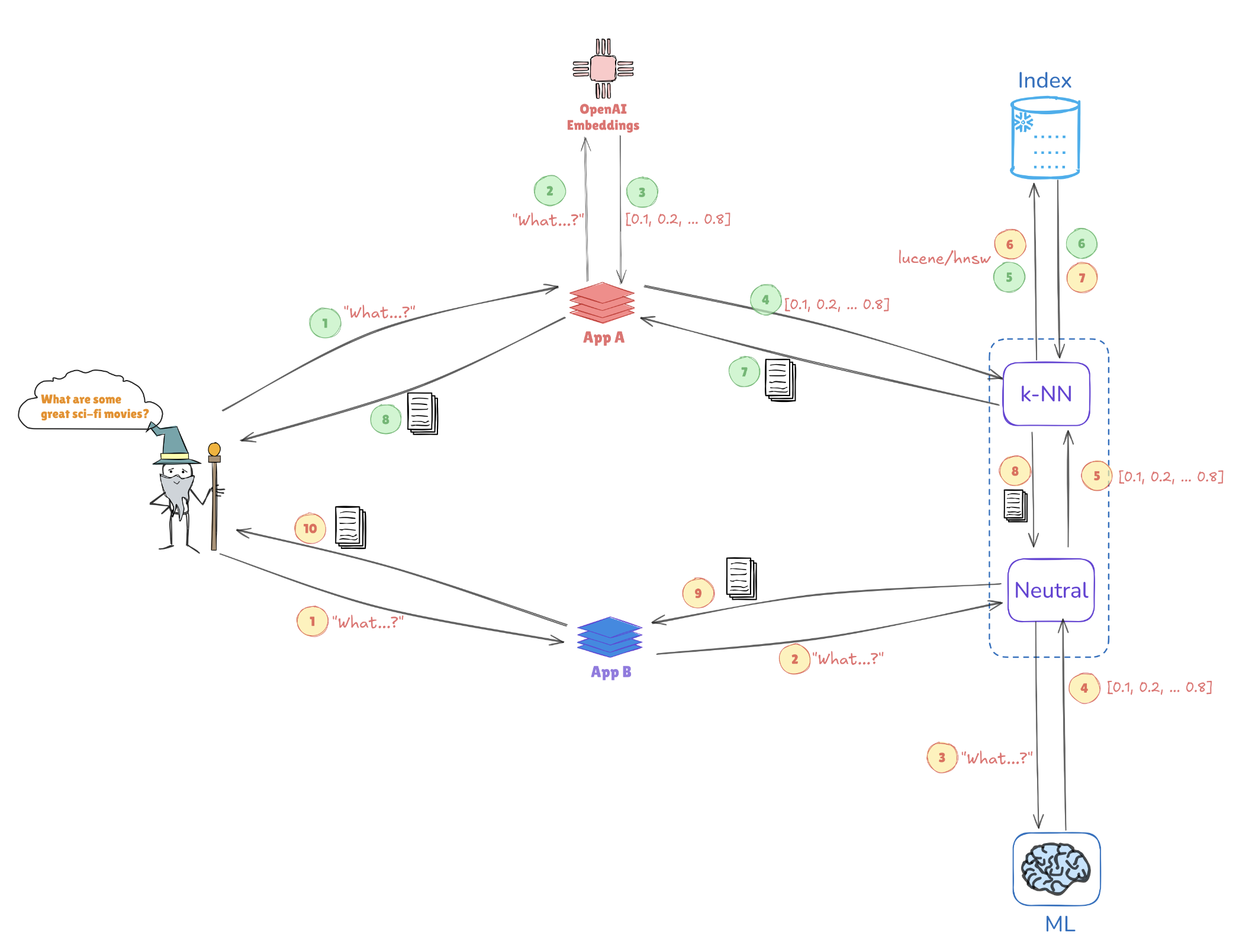
Illustration der Vektorsuche
Betrachten Sie die folgende Illustration, die zeigt, wie Vektorrepräsentationen Ähnlichkeitssuchen ermöglichen:
- Abfrageeinbettungen: Die Abfrage „Was sind einige großartige Sci-Fi-Filme?“ wird in eine Vektorrepräsentation umgewandelt, z. B. [0.1, 0.2, …, 0.4].
- Indizierung: Dieser Vektor wird mit vorindizierten Vektoren verglichen, die in Elasticsearch gespeichert sind (z. B. von Anwendungen wie AppA und AppB), um ähnliche Abfragen oder Datenpunkte zu finden.
- k-NN-Suche: Mit Algorithmen wie k-Nächste Nachbarn (k-NN) ruft Elasticsearch effizient die besten Übereinstimmungen aus den indizierten Vektoren ab, um schnell die relevantesten Informationen zu identifizieren.
Dieser Mechanismus ermöglicht es Elasticsearch, in Anwendungsfällen wie Empfehlungssystemen, Bildersuchen und der Verarbeitung natürlicher Sprache, in denen das Verständnis von Kontext und Ähnlichkeit entscheidend ist, hervorragende Leistungen zu erbringen.
Wesentliche Vorteile der Vektorsuche mit Elasticsearch
Unterstützung hoher Dimensionalität
Elasticsearch excelt im Umgang mit komplexen Datenstrukturen, die für KI- und Machine Learning-Anwendungen unerlässlich sind. Diese Fähigkeit ist entscheidend, wenn es darum geht, mehrschichtige Datentypen wie Bilder oder Textdaten zu verarbeiten.
Skalierbarkeit
Die Architektur unterstützt horizontale Skalierung, sodass Organisationen ständig wachsende Datensätze bewältigen können, ohne die Leistung zu opfern. Dies ist von entscheidender Bedeutung, da das Datenvolumen weiterhin zunimmt.
Integration
Elasticsearch funktioniert nahtlos mit dem Elastic Stack und bietet eine umfassende Lösung für Datenerfassung, -analyse und -visualisierung. Diese Integration stellt sicher, dass Dateningenieure eine einheitliche Plattform für verschiedene Datenverarbeitungsaufgaben nutzen können.
Best Practices zur Optimierung der Vektorsuche
1. Vektordimensionen reduzieren
Die Reduzierung der Dimensionalität Ihrer Vektoren kann die Suchleistung erheblich steigern. Techniken wie PCA (Hauptkomponentenanalyse) oder UMAP (Uniform Manifold Approximation and Projection) helfen, wesentliche Merkmale zu bewahren, während die Datenstruktur vereinfacht wird.
Beispiel: Dimensionalitätsreduktion mit PCA
So implementieren Sie PCA in Python mit Scikit-learn:
from sklearn.decomposition import PCA
import numpy as np
# Sample high-dimensional data
data = np.random.rand(1000, 50) # 1000 samples, 50 features
# Apply PCA to reduce to 10 dimensions
pca = PCA(n_components=10)
reduced_data = pca.fit_transform(data)
print(reduced_data.shape) # Output: (1000, 10)
2. Effizient indizieren
Die Nutzung von Approximate Nearest Neighbor (ANN)-Algorithmen kann die Suchzeiten erheblich verkürzen. Erwägen Sie die Verwendung von:
- HNSW (Hierarchical Navigable Small World): Bekannt für sein ausgewogenes Verhältnis von Leistung und Genauigkeit.
- FAISS (Facebook AI Similarity Search): Optimiert für große Datensätze und in der Lage, die GPU-Beschleunigung zu nutzen.
Beispiel: Implementierung von HNSW in Elasticsearch
Sie können Ihre Indexeinstellungen in Elasticsearch definieren, um HNSW wie folgt zu nutzen:
PUT /my_vector_index
{
"settings": {
"index": {
"knn": true,
"knn.space_type": "l2",
"knn.algo": "hnsw"
}
},
"mappings": {
"properties": {
"my_vector": {
"type": "knn_vector",
"dimension": 10 // Adjust based on your data
}
}
}
}
3. Stapelabfragen
Zur Verbesserung der Effizienz minimiert die Stapelverarbeitung mehrerer Abfragen in einer einzelnen Anfrage den Overhead. Dies ist besonders nützlich für Anwendungen mit hohem Benutzertraffic.
Beispiel: Stapelverarbeitung in Elasticsearch
Sie können den _msearch-Endpunkt für Stapelabfragen verwenden:
POST /_msearch
{ "index": "my_vector_index" }
{ "query": { "match_all": {} } }
{ "index": "my_vector_index" }
{ "query": { "match": { "category": "sci-fi" } } }
4. Caching verwenden
Implementieren Sie Caching-Strategien für häufig abgerufene Abfragen, um die Rechenlast zu verringern und die Antwortzeiten zu verbessern.
5. Leistungsüberwachung
Die regelmäßige Analyse von Leistungsmetriken ist entscheidend, um Engpässe zu identifizieren. Tools wie Kibana können dabei helfen, diese Daten zu visualisieren und informierte Anpassungen an Ihrer Elasticsearch-Konfiguration vorzunehmen.
Abstimmen von Parametern in HNSW für eine verbesserte Leistung
Die Optimierung von HNSW beinhaltet die Anpassung bestimmter Parameter, um eine bessere Leistung bei großen Datensätzen zu erzielen:
M(maximale Anzahl von Verbindungen): Eine Erhöhung dieses Werts verbessert den Abruf, erfordert jedoch möglicherweise mehr Speicherplatz.EfConstruction(dynamische Listenlänge während des Aufbaus): Ein höherer Wert führt zu einem genaueren Graphen, kann jedoch die Indizierungszeit erhöhen.EfSearch(dynamische Listenlänge während der Suche): Die Anpassung beeinflusst den Kompromiss zwischen Geschwindigkeit und Genauigkeit; ein größerer Wert führt zu besserem Recall, benötigt jedoch länger zur Berechnung.
Beispiel: Anpassung der HNSW-Parameter
Sie können die HNSW-Parameter bei der Indexerstellung wie folgt anpassen:
PUT /my_vector_index
{
"settings": {
"index": {
"knn": true,
"knn.algo": "hnsw",
"knn.hnsw.m": 16, // More connections
"knn.hnsw.ef_construction": 200, // Higher accuracy
"knn.hnsw.ef_search": 100 // Adjust for search accuracy
}
},
"mappings": {
"properties": {
"my_vector": {
"type": "knn_vector",
"dimension": 10
}
}
}
}
Fallstudie: Auswirkungen der Dimensionalitätsreduktion auf die HNSW-Performance in Anwendungen für Kundendaten
Bildabruf für personalisiertes Marketing
Techniken zur Dimensionalitätsreduktion spielen eine entscheidende Rolle bei der Optimierung von Bildabrufsystemen in Kundendatenanwendungen. In einer Studie haben Forscher die Hauptkomponentenanalyse (PCA) angewendet, um die Dimensionalität vor der Indexierung von Bildern mit Hierarchical Navigable Small World (HNSW)-Netzwerken zu reduzieren. PCA sorgte für einen spürbaren Geschwindigkeitsschub bei der Suche – wichtig für Anwendungen, die große Mengen von Kundendaten verarbeiten – jedoch auf Kosten eines geringfügigen Präzisionsverlusts aufgrund der Informationsreduzierung. Um dies zu lösen, untersuchten die Forscher auch Uniform Manifold Approximation and Projection (UMAP) als Alternative. UMAP bewahrte lokale Datenstrukturen effektiver, wodurch die komplexen Details für personalisierte Marketingempfehlungen erhalten blieben. Während UMAP mehr Rechenleistung als PCA erforderte, balancierte es Suchgeschwindigkeit mit hoher Präzision aus, was es zu einer geeigneten Wahl für genauigkeitskritische Aufgaben macht.
Textanalyse für Kundenstimmungsclustering
Im Bereich der Kundenstimmungsanalyse ergab eine andere Studie, dass UMAP in der Clusterung ähnlicher Textdaten besser abschneidet als PCA. UMAP ermöglichte es dem HNSW-Modell, Kundenstimmungen mit höherer Genauigkeit zu clustern – ein Vorteil beim Verständnis von Kundenfeedback und der Bereitstellung personalisierterer Antworten. Die Verwendung von UMAP erleichterte kleinere EfSearch-Werte im HNSW, was die Suchgeschwindigkeit und -genauigkeit verbesserte. Diese verbesserte Clusterungseffizienz ermöglichte eine schnellere Identifizierung relevanter Kundenstimmungen, was die zielgerichteten Marketingmaßnahmen und die stimmungsbasierte Kundensegmentierung verbesserte.
Integration automatisierter Optimierungstechniken
Die Optimierung der Dimensionsreduktion und der HNSW-Parameter ist entscheidend für die Maximierung der Leistung von Kundendatensystemen. Automatisierte Optimierungstechniken rationalisieren diesen Abstimmungsprozess und gewährleisten, dass die ausgewählten Konfigurationen in verschiedenen Anwendungen effektiv sind:
- Gitter- und Zufallssuche: Diese Methoden bieten eine breite und systematische Parameterexploration und identifizieren geeignete Konfigurationen effizient.
- Bayes’sche Optimierung: Diese Technik konzentriert sich mit weniger Bewertungen auf optimale Parameter und schont so die Rechenressourcen.
- Kreuzvalidierung: Die Kreuzvalidierung hilft, Parameter über verschiedene Datensätze zu validieren und deren Generalisierbarkeit auf unterschiedliche Kundendatenkontexte sicherzustellen.
Herausforderungen in der Automatisierung angehen
Die Integration von Automatisierung in Workflows zur Dimensionsreduktion und HNSW kann Herausforderungen mit sich bringen, insbesondere bei der Verwaltung der Rechenanforderungen und der Vermeidung von Overfitting. Strategien zur Überwindung dieser Herausforderungen umfassen:
- Reduzierung der Rechenbelastung: Der Einsatz von Parallelverarbeitung zur Verteilung der Arbeitslast verringert die Optimierungszeit und verbessert die Effizienz des Workflows.
- Modulare Integration: Ein modularer Ansatz erleichtert die nahtlose Integration automatisierter Systeme in bestehende Workflows und verringert die Komplexität.
- Vermeidung von Overfitting: Robuste Validierung durch Kreuzvalidierung stellt sicher, dass optimierte Parameter konsistent über Datensätze hinweg leistungsfähig sind, wodurch Overfitting minimiert und die Skalierbarkeit in Kundenanwendungen verbessert wird.
Fazit
Um die Leistung der Vektorsuche in Elasticsearch vollständig auszuschöpfen, ist es entscheidend, eine Strategie zu verfolgen, die Dimensionsreduktion, effiziente Indizierung und durchdachte Parameteranpassung kombiniert. Durch die Integration dieser Techniken können Dateningenieure ein hochreaktives und präzises Datenabrufsystem erstellen. Automatisierte Optimierungsmethoden heben diesen Prozess weiter an, indem sie eine kontinuierliche Verfeinerung von Suchparametern und Indizierungsstrategien ermöglichen. Da Organisationen zunehmend auf Echtzeiteinblicke aus umfangreichen Datensätzen angewiesen sind, können diese Optimierungen die Entscheidungsfindung erheblich verbessern und schnellere, relevantere Suchergebnisse liefern. Die Annahme dieses Ansatzes schafft die Grundlage für zukünftige Skalierbarkeit und verbesserte Reaktionsfähigkeit, indem die Suchfähigkeiten mit den sich entwickelnden Geschäftsanforderungen und dem Datenwachstum in Einklang gebracht werden.
Source:
https://dzone.com/articles/optimizing-vector-search-performance-with-elasticsearch