













Aktueller Zustand von MySQL 5.7
MySQL 5.7 ist im Hinblick auf Skalierbarkeit nicht ideal. Der folgende Diagramm illustriert die Beziehung zwischen TPC-C Durchsatz und Konkurrenzfähigkeit in MySQL 5.7.39 unter einer bestimmten Konfiguration. Dies beinhaltet das Setzen des Transaktionsisolationsgrades auf „Read Committed“ und diejustierung des Parameters innodb_spin_wait_delay, um eine Verringerung des Durchsatzes zu vermeiden.
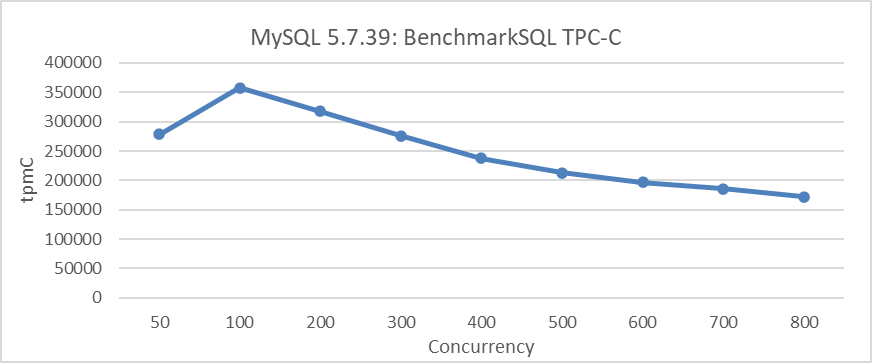
Abbildung 1: Skalierungsprobleme in MySQL 5.7.39 während BenchmarkSQL-Testen
Aus der Abbildung ist zu erkennen, dass die Skalierungsprobleme den Zuwachs des MySQL-Durchsatzes erheblich begrenzen. Zum Beispiel beginnt der Durchsatz nach 100 Konkurrenzen zu sinken.
Um das oben erwähnte Leistungskollapsproblem zu lösen, wurde Perconas Threadpool verwendet. Das folgende Diagramm zeigt die Beziehung zwischen TPC-C Durchsatz und Konkurrenzfähigkeit nach der Konfiguration des Percona-Threadpools.
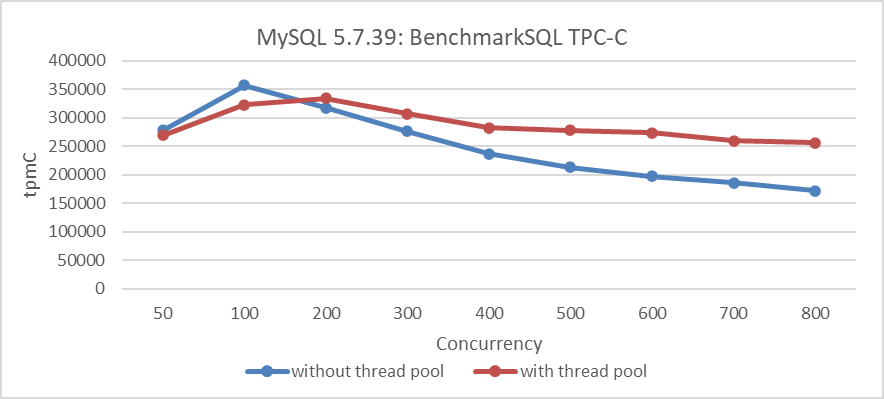
Abbildung 2: Percona Threadpool reduziert Skalierungsprobleme in MySQL 5.7.39
Obwohl der Threadpool einige Overhead verursacht und der Spitzenleistung abgegangen ist, hat er die Problematik des Leistungskollapses unter hoher Konkurrenzfähigkeit abgemildert.
Aktueller Zustand von MySQL 8.0
Lassen Sie uns die Anstrengungen von MySQL 8.0 im Hinblick auf Skalierbarkeit anschauen.
Optimierung der Redo-Logdatei
Der erste bedeutende Verbesserung ist die Optimierung der Redo-Logdatei [3].
commit 6be2fa0bdbbadc52cc8478b52b69db02b0eaff40
Author: Paweł Olchawa <[email protected]>
Date: Wed Feb 14 09:33:42 2018 +0100
WL#10310 Redo log optimization: dedicated threads and concurrent log buffer.
0. Log buffer became a ring buffer, data inside is no longer shifted.
1. User threads are able to write concurrently to log buffer.
2. Relaxed order of dirty pages in flush lists - no need to synchronize
the order in which dirty pages are added to flush lists.
3. Concurrent MTR commits can interleave on different stages of commits.
4. Introduced dedicated log threads which keep writing log buffer:
* log_writer: writes log buffer to system buffers,
* log_flusher: flushes system buffers to disk.
As soon as they finished writing (flushing) and there is new data to
write (flush), they start next write (flush).
5. User threads no longer write / flush log buffer to disk, they only
wait by spinning or on event for notification. They do not have to
compete for the responsibility of writing / flushing.
6. Introduced a ring buffer of events (one per log-block) which are used
by user threads to wait for written/flushed redo log to avoid:
* contention on single event
* false wake-ups of all waiting threads whenever some write/flush
has finished (we can wake-up only those waiting in related blocks)
7. Introduced dedicated notifier threads not to delay next writes/fsyncs:
* log_write_notifier: notifies user threads about written redo,
* log_flush_notifier: notifies user threads about flushed redo.
8. Master thread no longer has to flush log buffer.
...
30. Mysql test runner received a new feature (thanks to Marcin):
--exec_in_background.
Review: RB#15134
Reviewers:
- Marcin Babij <[email protected]>,
- Debarun Banerjee <[email protected]>.
Performance tests:
- Dimitri Kravtchuk <[email protected]>,
- Daniel Blanchard <[email protected]>,
- Amrendra Kumar <[email protected]>.
QA and MTR tests:
- Vinay Fisrekar <[email protected]>.Es wurde ein Test durchgeführt, der den TPC-C Durchsatz mit unterschiedlichem Level der Konkurrenz vor und nach der Optimierung verglich. Die spezifischen Details sind in folgendem Diagramm gezeigt:
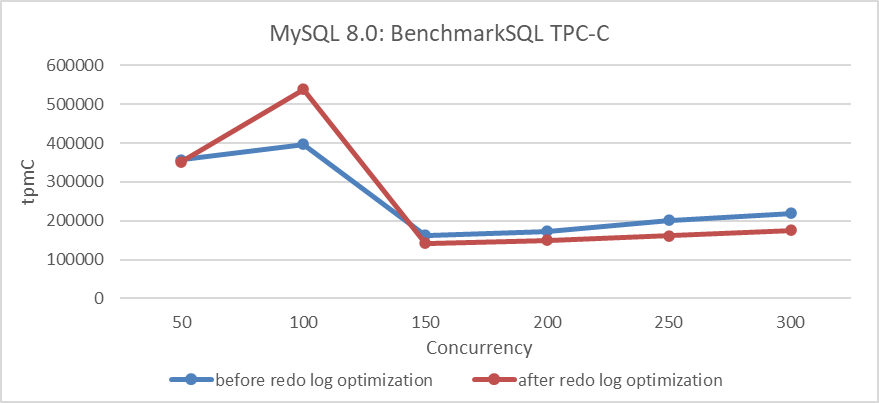
Abbildung 3: Einfluss der Optimierung des Wiederherstellungslogs bei unterschiedlichen Konkurrenzstufen
Die Ergebnisse in der Abbildung zeigen eine erhebliche Verbesserung der Durchsatzleistung bei niedrigen Konkurrenzstufen.
Optimierung von Lock-Sys durch Latch-Sharding
Der zweite wichtige Fortschritt ist die Optimierung von Lock-Sys [5].
commit 1d259b87a63defa814e19a7534380cb43ee23c48
Author: Jakub Łopuszański <[email protected]>
Date: Wed Feb 5 14:12:22 2020 +0100
WL#10314 - InnoDB: Lock-sys optimization: sharded lock_sys mutex
The Lock-sys orchestrates access to tables and rows. Each table, and each row,
can be thought of as a resource, and a transaction may request access right for
a resource. As two transactions operating on a single resource can lead to
problems if the two operations conflict with each other, Lock-sys remembers
lists of already GRANTED lock requests and checks new requests for conflicts in
which case they have to start WAITING for their turn.
Lock-sys stores both GRANTED and WAITING lock requests in lists known as queues.
To allow concurrent operations on these queues, we need a mechanism to latch
these queues in safe and quick fashion.
In the past a single latch protected access to all of these queues.
This scaled poorly, and the managment of queues become a bottleneck.
In this WL, we introduce a more granular approach to latching.
Reviewed-by: Pawel Olchawa <[email protected]>
Reviewed-by: Debarun Banerjee <[email protected]>
RB:23836Basierend auf dem Programm vor und nach der Optimierung mit Lock-Sys, verwendet BenchmarkSQL, um den TPC-C-Durchsatz bei unterschiedlicher Konkurrenz zu vergleichen, zeigen die konkreten Ergebnisse die folgende Abbildung:
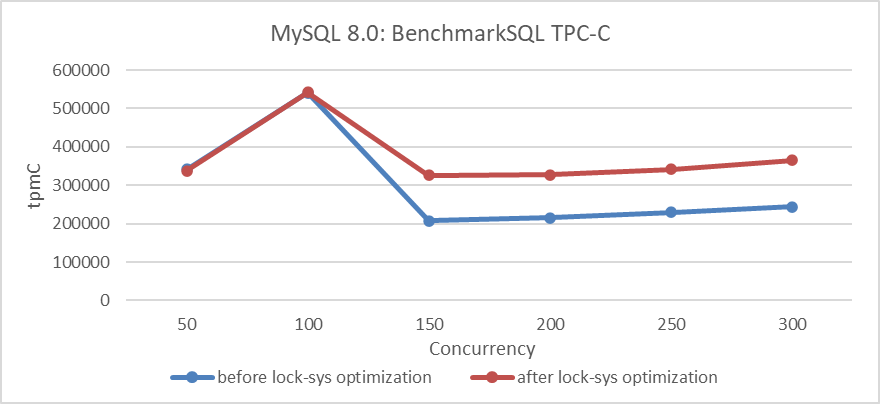
Abbildung 4: Einfluss der Optimierung von Lock-Sys bei unterschiedlichen Konkurrenzstufen
Aus der Abbildung ist zu erkennen, dass die Optimierung von Lock-Sys den Durchsatz bei hohen Konkurrenzbedingungen deutlich verbessert, während der Effekt bei niedrigen Konkurrenzbedingungen weniger stark ist, da es aufgrund von weniger Konflikten keine bedeutende Verbesserung gibt.
Latch-Sharding für trx-sys
Der dritte wichtige Fortschritt ist Latch-Sharding für trx-sys.
commit bc95476c0156070fd5cedcfd354fa68ce3c95bdb
Author: Paweł Olchawa <[email protected]>
Date: Tue May 25 18:12:20 2021 +0200
BUG#32832196 SINGLE RW_TRX_SET LEADS TO CONTENTION ON TRX_SYS MUTEX
1. Introduced shards, each with rw_trx_set and dedicated mutex.
2. Extracted modifications to rw_trx_set outside its original critical sections
(removal had to be extracted outside trx_erase_lists).
3. Eliminated allocation on heap inside TrxUndoRsegs.
4. [BUG-FIX] The trx->state and trx->start_time became converted to std::atomic<>
fields to avoid risk of torn reads on egzotic platforms.
5. Added assertions which ensure that thread operating on transaction has rights
to do so (to show there is no possible race condition).
RB: 26314
Reviewed-by: Jakub Łopuszański [email protected]Basierend auf diesen Optimierungen vor und nach, verwendet BenchmarkSQL, um den TPC-C-Durchsatz bei unterschiedlicher Konkurrenz zu vergleichen, zeigen die konkreten Ergebnisse die folgende Abbildung:
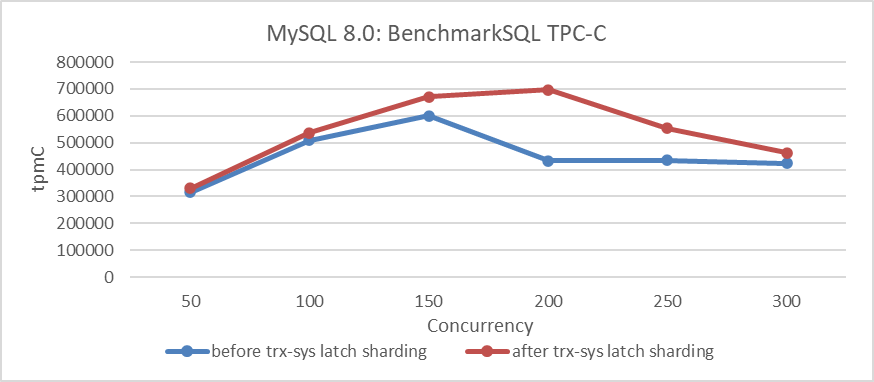
Abbildung 5: Einfluss von Latch-Sharding in trx-sys bei unterschiedlichen Konkurrenzstufen
Aus der Abbildung ist zu erkennen, dass diese Verbesserung den TPC-C-Durchsatz deutlich verbessert, seine Spitze erreicht bei 200 Konkurrenz. Es ist zu beachten, dass der Effekt bei 300 Konkurrenz abnimmt, was primär auf die anhaltenden Skalierungsprobleme im trx-sys-Subsystem mit MVCC ReadView zurückzuführen ist.
Verbesserung von MySQL 8.0
Die verbleibenden Verbesserungen sind unsere eigenen Erweiterungen.
Verbesserungen an der MVCC ReadView-Struktur
Die erste bedeutende Verbesserung besteht in der Optimierung der MVCC ReadView-Datenstruktur [1].
Zur Bewertung der Effektivität der MVCC ReadView-Optimierung wurden Leistungsvergleichstests durchgeführt. Die untere Abbildung zeigt eine Vergleich von TPC-C-Durchsatz mit unterschiedlichen Konkurrenzstufen vor und nach der Änderung der MVCC ReadView-Datenstruktur.
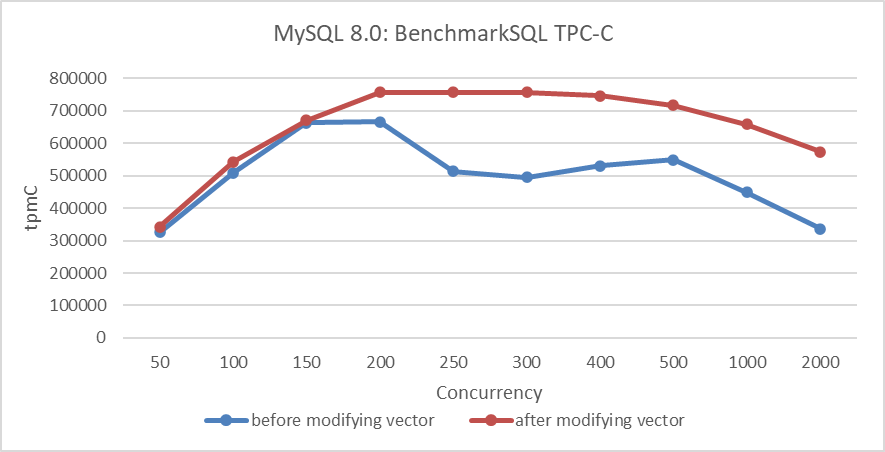
Abbildung 6: Leistungsvergleich vor und nach der Einführung der neuen Hybriddatenstruktur in NUMA
Aus der Abbildung ist klar zu erkennen, dass diese Transformation primär die Skalierbarkeit optimiert und den Leistungshöchstwert von MySQL in NUMA-Umgebungen verbessert hat.
Vermeidung von Doppelverratenproblemen
Die zweite bedeutende Verbesserung besteht in der Lösung des Doppelverratenproblems, bei dem „Doppelverraten“ auf die Notwendigkeit der globalen trx-sys-Sperre beim view_open und view_close Befehlen hinweist [1].
Mit der optimierten MVCC ReadView-Version wurde der TPC-C-Durchsatz verglichen, vor und nach den Änderungen. Die Details sind in der folgenden Abbildung gezeigt:
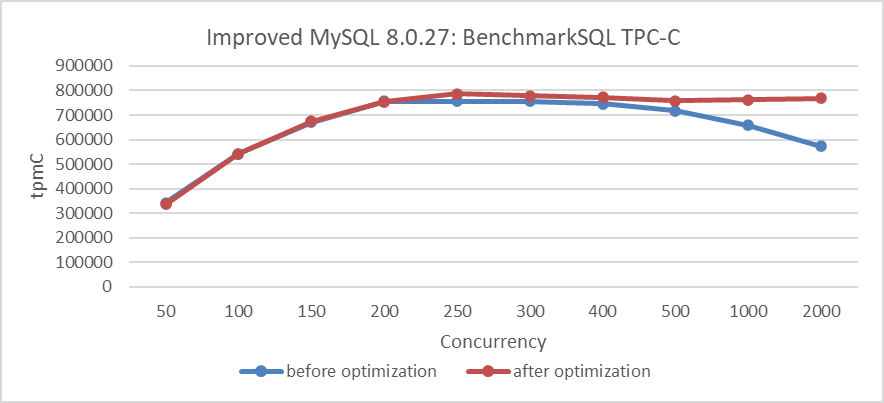
Abbildung 7: Leistungsverbesserung nach Beseitigung des Doppelverraten-Bottlenecks
Aus der Abbildung ist klar zu erkennen, dass die Änderungen die Skalierbarkeit unter hohen Konkurrenzbedingungen deutlich verbessert haben.
Transaktionsbremsmechanismus
Die letzte Verbesserung besteht in der Implementierung eines Transaktionsbremsmechanismus, um gegenüber extremer Konkurrenz ein Performanceverlust zu vermeiden [1] [2] [4].
Das folgende Bild zeigt die TPC-C-Skalierungsstresstest, der nach der Implementierung von Transaktionsbeschränkungen durchgeführt wurde. Der Test wurde in einem Szenario mit deaktiviertem NUMA BIOS durchgeführt, das die Anzahl der Benutzerthreads auf 512 begrenzte, die in das Transaktionssystem eintraten.
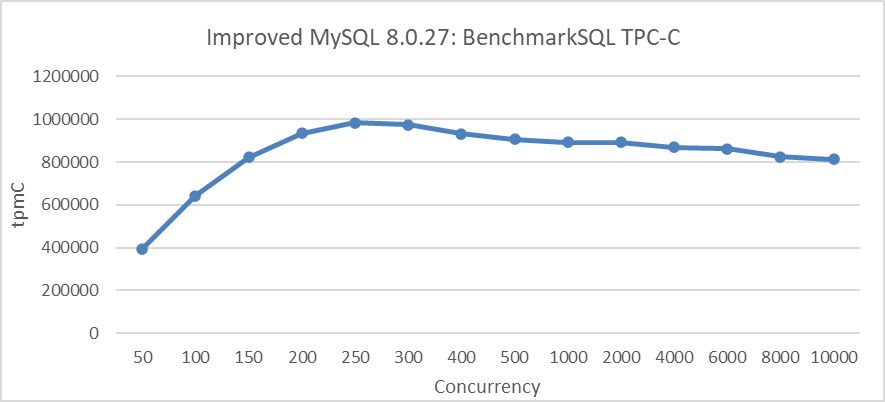
Abbildung 8: Maximale TPC-C-Durchsatz in BenchmarkSQL mit Transaktionsbeschränkungsmechanismen
Aus dem Bild ist erkennbar, dass die Implementierung von Transaktionsbeschränkungsmechanismen MySQL’s Skalierbarkeit erheblich verbessert.
Zusammenfassung
Insgesamt ist es durchaus möglich, dass MySQL bei zehntausenden von gleichzeitigen Verbindungen in BenchmarkSQL-TPC-C-Testumgebungen ohne Kollaps und mit annehmbarer Leistung funktioniert.
Referenzen
- Bin Wang (2024). Das Kunstwerk der Problemlösung in der Softwaretechnik: Wie man MySQL verbessern kann.
- Der neue MySQL-Threadpool
- Paweł Olchawa. 2018. MySQL 8.0: Neuer lockfreier, skalierbarer WAL-Entwurf. MySQL-Blogarchiv.
- Xiangyao Yu. Eine Bewertung von Konsistenzkontrollen mit tausend Kernen. Doktorarbeit, Massachusetts Institute of Technology, 2015.
- MySQL 8.0 Referenzhandbuch
Source:
https://dzone.com/articles/mysql-scalability-improvement-for-benchmarksql