













Benutzer nehmen tendenziell einen Rückgang der Leistung bei niedriger Parallelität leichter wahr, während Verbesserungen der Leistung bei hoher Parallelität oft schwerer zu erkennen sind. Daher ist die Aufrechterhaltung der Leistung bei niedriger Parallelität entscheidend, da sie die Benutzererfahrung und die Bereitschaft zur Aktualisierung direkt beeinflusst [1].
Nach umfangreichem Benutzerfeedback haben die Benutzer nach dem Upgrade auf MySQL 8.0 im Allgemeinen einen Rückgang der Leistung wahrgenommen, insbesondere bei Batch-Insert- und Join-Operationen. Dieser Abwärtstrend ist in höheren Versionen von MySQL deutlicher geworden. Darüber hinaus haben einige MySQL-Enthusiasten und Tester von Leistungsverschlechterungen in mehreren Sysbench-Tests nach dem Upgrade berichtet.
Können diese Leistungsprobleme vermieden werden? Oder, spezifischer, wie sollten wir den fortlaufenden Trend des Leistungsrückgangs wissenschaftlich bewerten? Dies sind wichtige Fragen, die berücksichtigt werden sollten.
Obwohl das offizielle Team weiterhin optimiert, kann die schrittweise Verschlechterung der Leistung nicht ignoriert werden. In bestimmten Szenarien kann es Verbesserungen geben, aber das bedeutet nicht, dass die Leistung in allen Szenarien gleichermaßen optimiert ist. Zudem ist es auch einfach, die Leistung für spezifische Szenarien auf Kosten der Leistung in anderen Bereichen zu optimieren.
Die Hauptursachen für den Leistungsrückgang von MySQL
Im Allgemeinen, je mehr Funktionen hinzugefügt werden, desto größer wird der Code und mit der kontinuierlichen Erweiterung der Funktionalität wird die Leistung zunehmend schwerer zu kontrollieren.
MySQL-Entwickler bemerken oft nicht den Leistungsabfall, da jede Ergänzung des Codebestands nur zu einem sehr geringen Leistungsverlust führt. Im Laufe der Zeit addieren sich diese kleinen Rückgänge jedoch, was zu einer signifikanten kumulativen Wirkung führt. Dies führt dazu, dass Benutzer eine spürbare Leistungsverschlechterung in neueren Versionen von MySQL wahrnehmen.
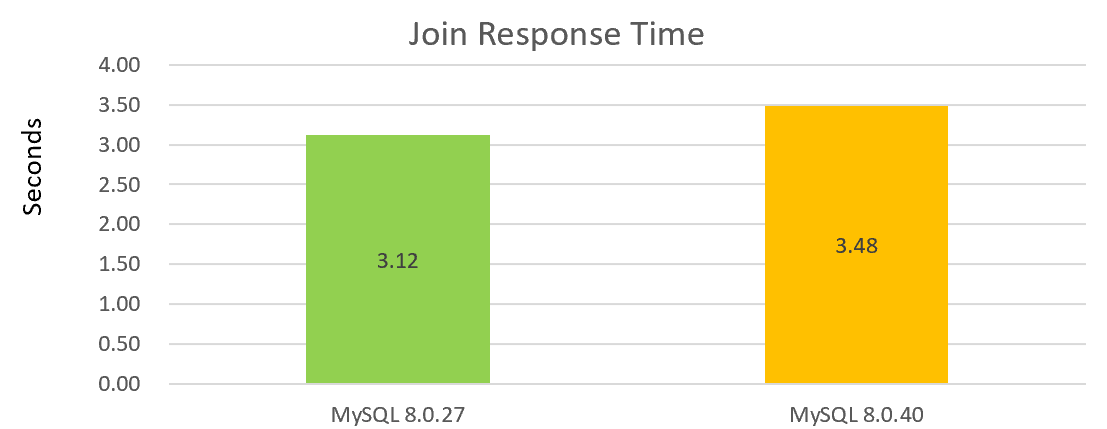
Zum Beispiel zeigt die folgende Abbildung die Leistung eines einfachen einzelnen Join-Vorgangs, wobei MySQL 8.0.40 einen Leistungsabfall im Vergleich zu MySQL 8.0.27 aufweist:
Die folgende Abbildung zeigt den Batch-Einfügeleistungstest unter einzelner Gleichzeitigkeit, wobei der Leistungsabfall von MySQL 8.0.40 im Vergleich zur Version 5.7.44 zu sehen ist:
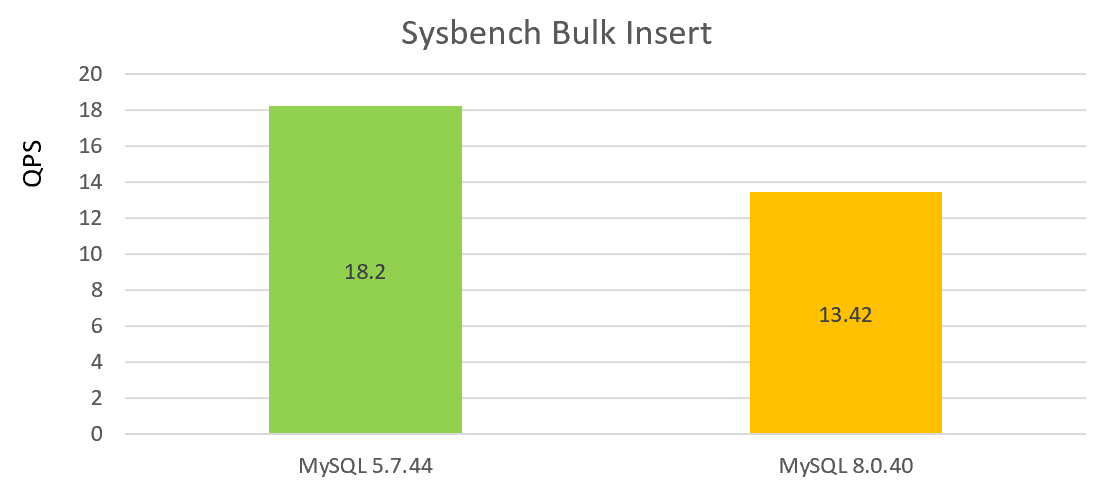
Anhand der beiden obigen Diagramme ist ersichtlich, dass die Leistung von Version 8.0.40 nicht gut ist.
Lassen Sie uns als Nächstes die Ursache für die Leistungsverschlechterung in MySQL auf Codeebene analysieren. Nachstehend die Funktion PT_insert_values_list::contextualize in MySQL 8.0:
Die entsprechende Funktion PT_insert_values_list::contextualize in MySQL 5.7 lautet wie folgt:
Anhand des Codevergleichs scheint MySQL 8.0 über eleganteren Code zu verfügen und Fortschritte zu machen.
Leider sind es oft gerade die Beweggründe hinter diesen Codeverbesserungen, die zu Leistungsverschlechterungen führen. Das MySQL-Entwicklerteam hat die vorherige Datenstruktur List durch ein deque ersetzt, was zu einer der Hauptursachen für den allmählichen Leistungsabfall geworden ist. Werfen wir einen Blick auf die Dokumentation zu deque:
std::deque (double-ended queue) is an indexed sequence container that allows fast insertion and deletion at both its
beginning and its end. In addition, insertion and deletion at either end of a deque never invalidates pointers or
references to the rest of the elements.
As opposed to std::vector, the elements of a deque are not stored contiguously: typical implementations use a sequence
of individually allocated fixed-size arrays, with additional bookkeeping, which means indexed access to deque must
perform two pointer dereferences, compared to vector's indexed access which performs only one.
The storage of a deque is automatically expanded and contracted as needed. Expansion of a deque is cheaper than the
expansion of a std::vector because it does not involve copying of the existing elements to a new memory location. On
the other hand, deques typically have large minimal memory cost; a deque holding just one element has to allocate its
full internal array (e.g. 8 times the object size on 64-bit libstdc++; 16 times the object size or 4096 bytes,
whichever is larger, on 64-bit libc++).
The complexity (efficiency) of common operations on deques is as follows:
Random access - constant O(1).
Insertion or removal of elements at the end or beginning - constant O(1).
Insertion or removal of elements - linear O(n).
Wie im obigen Text beschrieben, erfordert das Beibehalten eines einzelnen Elements in extremen Fällen die Zuweisung des gesamten Arrays, was zu einer sehr geringen Speichereffizienz führt. Zum Beispiel speichert die offizielle Implementierung bei Masseneinfügungen, bei denen eine große Anzahl von Datensätzen eingefügt werden muss, jeden Datensatz in einem separaten deque. Selbst wenn der Inhalt des Datensatzes minimal ist, muss dennoch ein deque zugewiesen werden. Die MySQL deque-Implementierung weist jedem deque 1 KB Speicher zu, um schnelle Lookups zu unterstützen.
The implementation is the same as classic std::deque: Elements are held in blocks of about 1 kB each.
Die offizielle Implementierung verwendet 1 KB Speicher, um Indexinformationen zu speichern, und selbst wenn die Datensatzlänge nicht groß ist, aber viele Datensätze vorhanden sind, können die Speicherzugriffsadressen nicht zusammenhängend werden, was zu schlechter Cache-Freundlichkeit führen kann. Diese Gestaltung sollte die Cache-Freundlichkeit verbessern, war allerdings nicht vollständig wirksam.
Es ist erwähnenswert, dass die ursprüngliche Implementierung eine Listen-Datenstruktur verwendete, bei der der Speicher über einen Speicherpool zugewiesen wurde, was ein gewisses Maß an Cache-Freundlichkeit bot. Obwohl der zufällige Zugriff weniger effizient ist, verbessert die Optimierung für den sequenziellen Zugriff auf Listenelemente die Leistung erheblich.
Während des Upgrades auf MySQL 8.0 beobachteten Benutzer einen erheblichen Rückgang der Leistung bei Stapel-Inserts, wobei eine der Hauptursachen die wesentliche Änderung der zugrunde liegenden Datenstrukturen war.
Zusätzlich führte die Verbesserung des Redo-Log-Mechanismus durch das offizielle Team zu einer Verringerung der Effizienz des MTR-Commit-Betriebs. Im Vergleich zu MySQL 5.7 verringert der hinzugefügte Code die Leistung einzelner Commits signifikant, obwohl insgesamt die Schreibleistung erheblich verbessert wurde.
Lassen Sie uns den Kern der execute-Operation des MTR-Commit in MySQL 5.7.44 untersuchen:
Lassen Sie uns die Kernoperation execute des MTR-Commit in MySQL 8.0.40 untersuchen:
Im Vergleich dazu wird deutlich, dass in MySQL 8.0.40 die Ausführung des MTR-Commit viel komplexer geworden ist, mit mehr Schritten. Diese Komplexität ist eine der Hauptursachen für den Rückgang der Leistung bei geringer Konkurrenzschreiblast.
Insbesondere die Operationen m_impl->m_log.for_each_block(write_log) und log_wait_for_space_in_log_recent_closed(*log_sys, handle.start_lsn) haben erhebliche Overheads. Diese Änderungen wurden vorgenommen, um die Leistung bei hoher Konkurrenz zu verbessern, gingen jedoch auf Kosten der Leistung bei geringer Konkurrenz.
Die Priorisierung des Redo-Logs im Hochkonkurrenzmodus führt zu schlechter Leistung bei geringer Konkurrenz. Obwohl die Einführung von innodb_log_writer_threads dazu gedacht war, Leistungsprobleme bei geringer Konkurrenz zu mildern, beeinflusst dies nicht die Ausführung der obigen Funktionen. Da diese Operationen komplexer geworden sind und häufige MTR-Commits erfordern, ist die Leistung dennoch erheblich gesunken.
Werfen wir einen Blick auf die Auswirkungen des Instant-Add/Drop-Features auf die Leistung. Hier ist die Funktion rec_init_offsets_comp_ordinary in MySQL 5.7:
Die Funktion rec_init_offsets_comp_ordinary in MySQL 8.0.40 lautet wie folgt:
Aus dem obigen Code wird deutlich, dass mit der Einführung des Features zur sofortigen Hinzufügung/Löschung von Spalten die Funktion rec_init_offsets_comp_ordinary deutlich komplexer geworden ist. Es gibt nun mehr Funktionsaufrufe und eine Switch-Anweisung, die die Cache-Optimierung stark beeinträchtigt. Da diese Funktion häufig aufgerufen wird, wirkt sich dies direkt auf die Leistung des Indexupdates, der Stapeleinfügungen und der Joins aus und führt zu erheblichen Leistungseinbußen.
Zusätzlich beschränkt sich der Leistungsverlust in MySQL 8.0 nicht nur auf das Obige; es gibt viele andere Bereiche, die zur allgemeinen Leistungsverschlechterung beitragen, insbesondere die Auswirkungen auf die Erweiterung von Inline-Funktionen. Zum Beispiel beeinträchtigt der folgende Code die Erweiterung von Inline-Funktionen:
Unsere Tests zufolge stört die Anweisung ib::fatal die Inline-Optimierung erheblich. Für häufig aufgerufene Funktionen ist es ratsam, Anweisungen zu vermeiden, die die Inline-Optimierung beeinträchtigen.
Lassen Sie uns nun ein ähnliches Problem betrachten. Die Funktion row_sel_store_mysql_field wird häufig aufgerufen, wobei row_sel_field_store_in_mysql_format eine Hotspot-Funktion darin ist. Der spezifische Code lautet wie folgt:
Die Funktion row_sel_field_store_in_mysql_format ruft letztendlich row_sel_field_store_in_mysql_format_func auf.
Die Funktion row_sel_field_store_in_mysql_format_func kann aufgrund des Codes ib::fatal nicht inline ausgeführt werden.
Ineffiziente Funktionen, die häufig aufgerufen werden und Millionen von Malen pro Sekunde ausgeführt werden, können die Leistung von Joins schwerwiegend beeinträchtigen.
Lassen Sie uns weiterhin die Gründe für die Leistungsabnahme erforschen. Die folgende offizielle Leistungsoptimierung ist tatsächlich eine der Hauptursachen für den Rückgang der Join-Leistung. Obwohl bestimmte Abfragen verbessert werden können, sind sie dennoch einige der Gründe für die Leistungsverschlechterung bei gewöhnlichen Join-Operationen.
MySQL’s Probleme gehen über diese hinaus. Wie oben analysiert, ist der Leistungsabfall in MySQL nicht ohne Grund. Eine Reihe kleiner Probleme, wenn sie sich ansammeln, können zu spürbaren Leistungsverschlechterungen führen, die Benutzer erleben. Diese Probleme sind jedoch oft schwer zu identifizieren, was ihre Behebung noch schwieriger macht.
Die sogenannte „vorzeitige Optimierung“ ist die Wurzel allen Übels und trifft nicht auf die MySQL-Entwicklung zu. Die Datenbankentwicklung ist ein komplexer Prozess, und die Vernachlässigung der Leistung im Laufe der Zeit macht spätere Leistungsverbesserungen erheblich herausfordernder.
Lösungen zur Minderung des Leistungsabfalls von MySQL
Die Hauptgründe für den Rückgang der Schreibleistung hängen mit MTR-Commit-Problemen, dem sofortigen Hinzufügen/Löschen von Spalten und mehreren anderen Faktoren zusammen. Diese sind auf herkömmliche Weise schwer zu optimieren. Benutzer können jedoch den Leistungsabfall durch PGO-Optimierungausgleichen. Mit einer geeigneten Strategie kann die Leistung im Allgemeinen stabil gehalten werden.
Für die Leistungseinbußen bei der Stapelverarbeitung ersetzt unsere Open-Source-Version [2] die offizielle deque durch eine verbesserte Listenimplementierung. Dies betrifft hauptsächlich Probleme mit dem Speichereffizienz und kann teilweise Leistungseinbußen lindern. Durch die Kombination von PGO-Optimierung mit unserer Open-Source-Version kann die Leistung der Stapelverarbeitung annähernd an die von MySQL 5.7 heranreichen.

Benutzer können auch mehrere Threads für die gleichzeitige Stapelverarbeitung nutzen und die verbesserte Parallelität des Redo-Logs voll ausnutzen, was die Leistung der Stapelverarbeitung signifikant steigern kann.
In Bezug auf Update-Index-Probleme kann durch die unvermeidliche Hinzufügung von neuem Code die PGO-Optimierung helfen, dieses Problem zu mildern. Unsere PGO-Version [2] kann dieses Problem signifikant lindern.
Für die Leseleistung, insbesondere die Join-Leistung, haben wir wesentliche Verbesserungen vorgenommen, einschließlich der Behebung von Inline-Problemen und anderer Optimierungen. Mit der Ergänzung von PGO kann die Join-Leistung um über 30% im Vergleich zur offiziellen Version gesteigert werden.
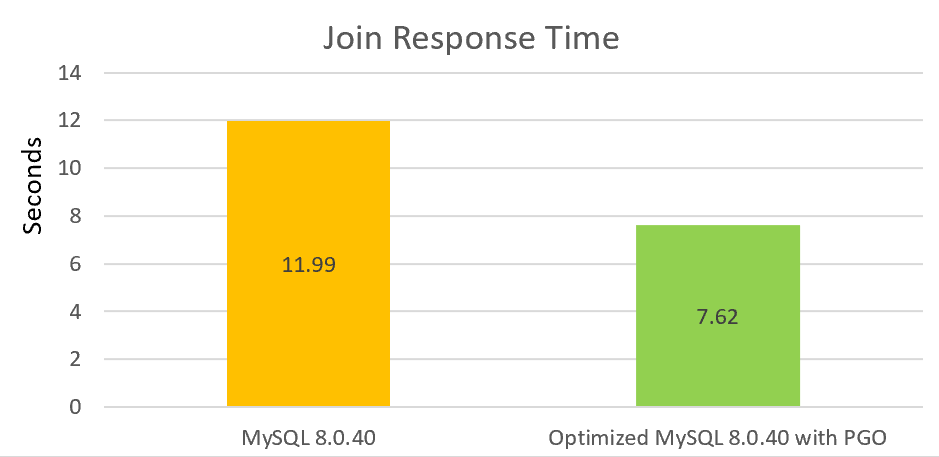
Wir werden weiterhin Zeit investieren, um die Leistung bei geringer Parallelität zu optimieren. Dieser Prozess ist langwierig, umfasst jedoch zahlreiche Bereiche, die Verbesserungen erfordern.
Die Open-Source-Version steht zum Testen zur Verfügung, und Anstrengungen werden fortgesetzt, um die Leistung von MySQL zu verbessern.
References
[1] Bin Wang (2024). Die Kunst der Problemlösung in der Softwaretechnik: Wie man MySQL verbessert.
Source:
https://dzone.com/articles/mysql-80-performance-degradation-analysis