













Angenommen, Sie haben eine Anwendung, die in Node.js (oder einer anderen Plattform) entwickelt wurde. Diese Anwendung verbindet sich mit einer MongoDB-Datenbank (NoSQL), um Bewertungen von Büchern (Anzahl der gegebenen Sterne und einen Kommentar) zu speichern. Nehmen wir weiter an, dass Sie eine andere Anwendung in Java (oder Python, C#, TypeScript… irgendetwas) entwickelt haben. Diese Anwendung verbindet sich mit einer MariaDB-Datenbank (SQL, relational), um einen Katalog von Büchern (Titel, Erscheinungsjahr, Seitenzahl) zu verwalten.
Sie werden aufgefordert, einen Bericht zu erstellen, der den Titel und die Bewertungsinformationen für jedes Buch zeigt. Beachten Sie, dass die MongoDB-Datenbank den Titel der Bücher nicht enthält, und die relationale Datenbank keine Bewertungen enthält. Wir müssen Daten, die von einer NoSQL-Anwendung erstellt wurden, mit Daten, die von einer SQL-Anwendung erstellt wurden, mischen.
A common approach to this is to query both databases independently (using different data sources) and process the data to match by, for example, ISBN (the id of a book) and put the combined information in a new object. This needs to be done in a programming language like Java, TypeScript, C#, Python, or any other imperative programming language that is able to connect to both databases.
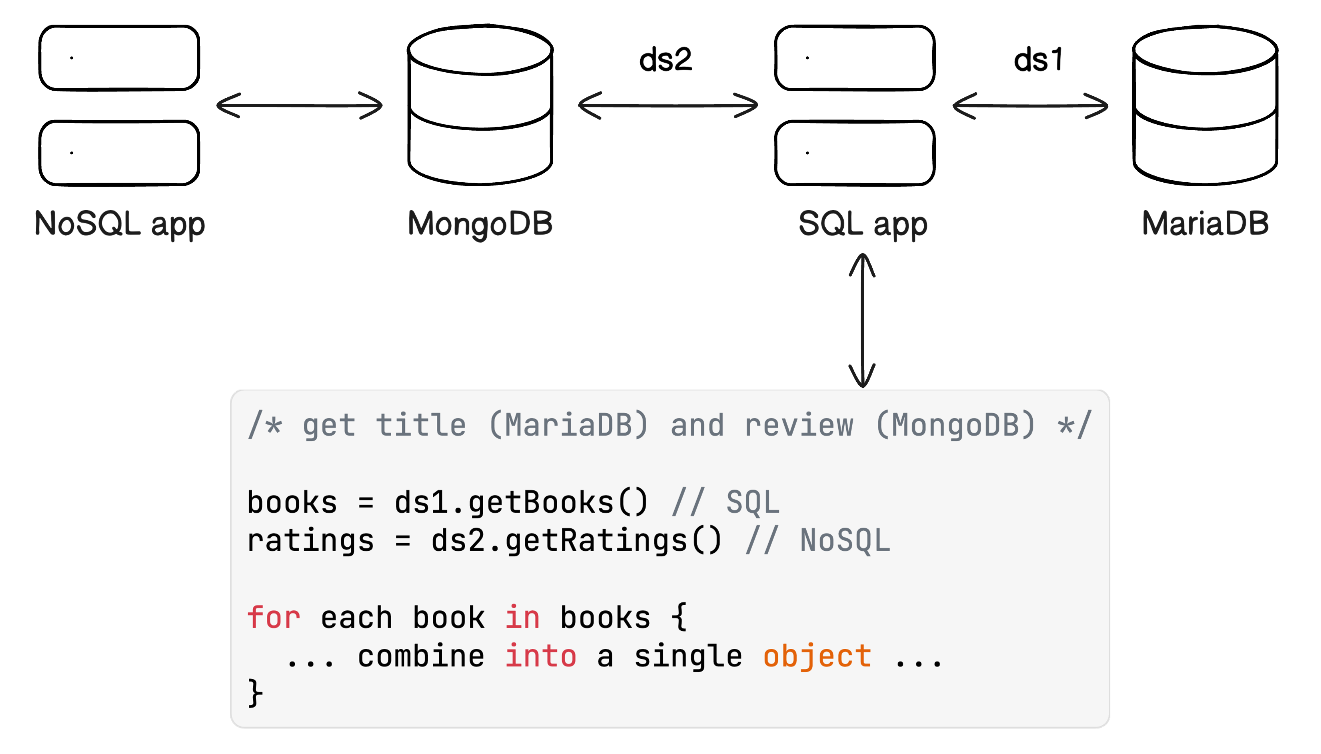
A polyglot application
Dieser Ansatz funktioniert. Allerdings ist das Verknüpfen von Daten die Aufgabe einer Datenbank. Sie sind dafür konzipiert, solche Datenoperationen durchzuführen. Auch erhöht dieser Ansatz die Komplexität, da die SQL-Anwendung nicht mehr nur eine SQL-Anwendung ist; sie wird zu einer polyglotten Datenbank, was die Wartung erschwert.
Mit einem Datenbank-Proxy wie MaxScale können Sie diese Daten auf Datenbankebene mithilfe der besten Sprache für Daten — SQL — verknüpfen. Ihre SQL-Anwendung muss nicht zu einer Polyglot-Anwendung werden.
Obwohl dies ein zusätzliches Element in der Infrastruktur erfordert, erhalten Sie auch alle Funktionen, die ein Datenbank-Proxy bietet. Dinge wie automatisches Failover, transparentes Datenmaskieren, Topologieisolation, Puffer, Sicherheitsfilter und mehr.
MaxScale ist ein leistungsstarker, intelligenter Datenbank-Proxy, der sowohl SQL als auch NoSQL versteht. Es versteht auch Kafka (für CDC oder Dateneinführung), aber das ist ein Thema für eine andere Gelegenheit. Kurz gesagt, mit MaxScale können Sie Ihre NoSQL-Anwendung mit einer voll ACID-kompatiblen relationale Datenbank verbinden und die Daten direkt neben Tabellen speichern, die von anderen SQL-Anwendungen verwendet werden.
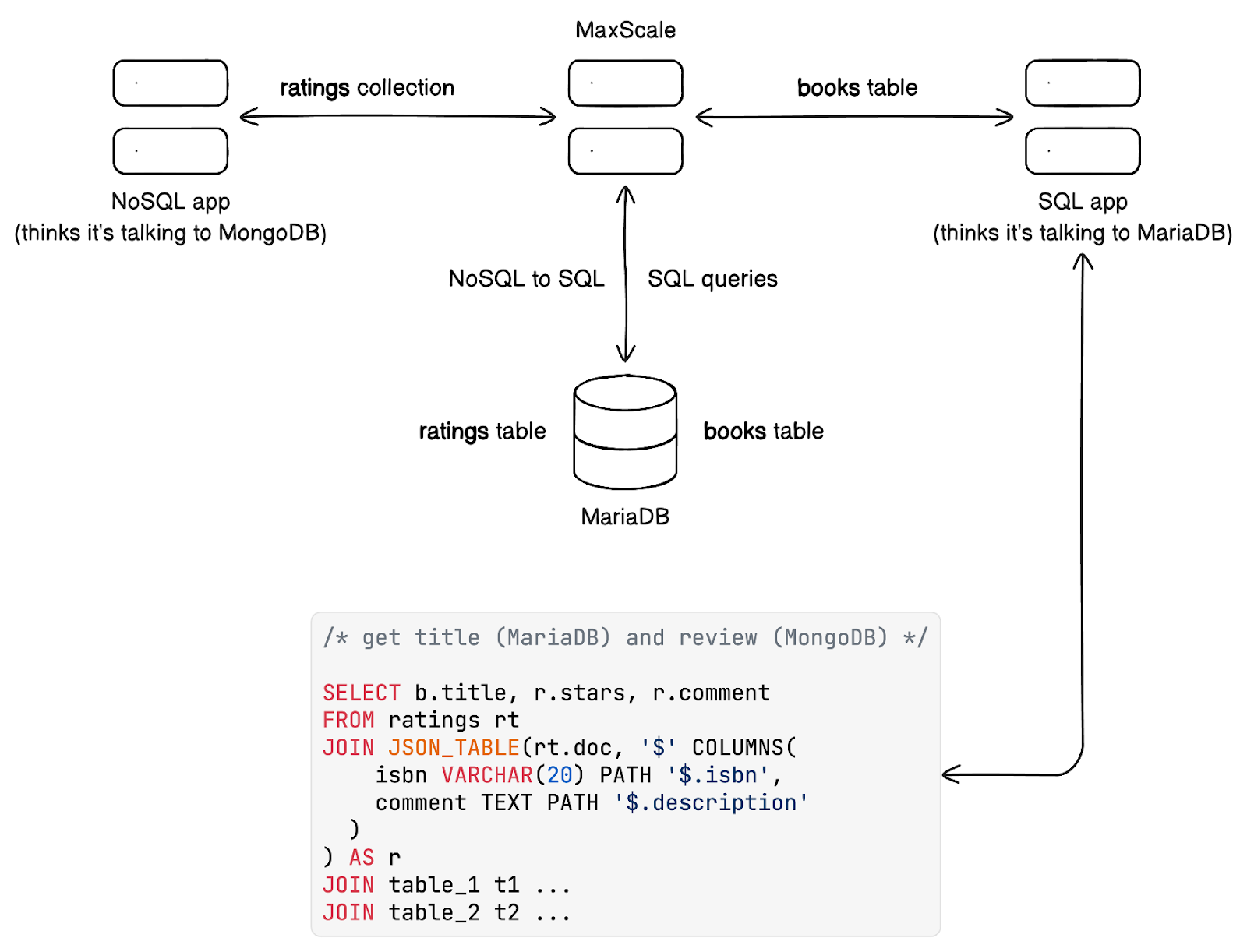
MaxScale ermöglicht es einer SQL-Anwendung, NoSQL-Daten zu verbrauchen.
Versuchen wir diesen letzten Ansatz in einem kurzen und leicht verständlichen Experiment mit MaxScale. Sie benötigen Folgendes auf Ihrem Computer installiert:
Einrichtung der MariaDB-Datenbank
Erstellen Sie mit einem einfachen Texteditor eine neue Datei und speichern Sie sie unter dem Namen docker-compose.yml. Die Datei sollte Folgendes enthalten:
version: "3.9"
services:
mariadb:
image: alejandrodu/mariadb
environment:
- MARIADB_CREATE_DATABASE=demo
- MARIADB_CREATE_USER=user:Password123!
- MARIADB_CREATE_MAXSCALE_USER=maxscale_user:MaxScalePassword123!
maxscale:
image: alejandrodu/mariadb-maxscale
command: --admin_host 0.0.0.0 --admin_secure_gui false
ports:
- "3306:4000"
- "27017:27017"
- "8989:8989"
environment:
- MAXSCALE_USER=maxscale_user:MaxScalePassword123!
- MARIADB_HOST_1=mariadb 3306
- MAXSCALE_CREATE_NOSQL_LISTENER=user:Password123!Dies ist eine Docker Compose Datei. Sie beschreibt eine Reihe von Diensten, die von Docker erstellt werden sollen. Wir erstellen zwei Dienste (oder Container) — einen MariaDB-Datenbankserver und einen MaxScale-Datenbankproxy. Sie laufen lokal auf Ihrem Computer, aber in Produktionsumgebungen werden sie häufig auf separaten physischen Maschinen bereitgestellt. Denken Sie daran, dass diese Docker-Images für Produktionsumgebungen nicht geeignet sind! Sie sind für schnelle Demos und Tests vorgesehen. Sie können den Quellcode für diese Images auf GitHub finden. Für die offiziellen Docker-Images von MariaDB gehen Sie zur MariaDB-Seite auf Docker Hub.
Der vorherige Docker Compose-Datei konfiguriert einen MariaDB-Datenbankserver mit einer Datenbank (oder Schema; sie sind Synonyme in MariaDB) namens demo. Es wird auch ein Benutzername user mit dem Passwort Password123! erstellt. Dieser Benutzer verfügt über geeignete Berechtigungen für die demo-Datenbank. Es gibt einen zusätzlichen Benutzer mit dem Namen maxscale_user und dem Passwort MaxScalePassword123!. Dies ist der Benutzer, den der MaxScale-Datenbankproxy zum Herstellen einer Verbindung mit dem MariaDB-Datenbank verwenden wird.
Die Docker Compose-Datei konfiguriert auch den Datenbankproxy, indem sie HTTPS deaktiviert (tun Sie dies nicht in der Produktion!), eine Reihe von Ports freigibt (mehr dazu in Kürze) und den Datenbankbenutzer und den Speicherort des MariaDB-Datenbankproxys konfiguriert (normalerweise eine IP-Adresse, aber hier können wir den Namen des Containers verwenden, der zuvor in der Docker-Datei definiert wurde). Die letzte Zeile erstellt einen NoSQL-Listener, den wir verwenden werden, um als MongoDB-Client auf dem Standardport (27017) zu verbinden.
Um die Dienste (Container) über die Kommandozeile zu starten, wechseln Sie in das Verzeichnis, in dem Sie die Docker Compose-Datei gespeichert haben, und führen Sie Folgendes aus:
docker compose up -dNach dem Herunterladen aller Software und dem Starten der Container verfügen Sie über eine MariaDB-Datenbank und einen MaxScale-Proxy, beide vorab für dieses Experiment konfiguriert.
Erstellen einer SQL-Tabelle in MariaDB
Lassen Sie uns eine Verbindung zur relationalen Datenbank herstellen. Führen Sie im Kommandozeilenfenster Folgendes aus:
mariadb-shell --dsn mariadb://user:'Password123!'@127.0.0.1Prüfen Sie, ob Sie auf die demo-Datenbank zugreifen können:
show databases;Wechseln Sie zur demo-Datenbank:
use demo;
Verbindung zu einer Datenbank mit MariaDB Shell herstellen.
Erstellen Sie die books-Tabelle:
CREATE TABLE books(
isbn VARCHAR(20) PRIMARY KEY,
title VARCHAR(256),
year INT
);Fügen Sie einige Daten ein. Ich werde das Klischee verwenden, um meine eigenen Bücher einzufügen:
INSERT INTO books(title, isbn, year)
VALUES
("Vaadin 7 UI Design By Example", "978-1-78216-226-1", 2013),
("Data-Centric Applications with Vaadin 8", "978-1-78328-884-7", 2018),
("Practical Vaadin", "978-1-4842-7178-0", 2021);Überprüfen Sie, ob die Bücher im Datenbank gespeichert sind, indem Sie Folgendes ausführen:
SELECT * FROM books;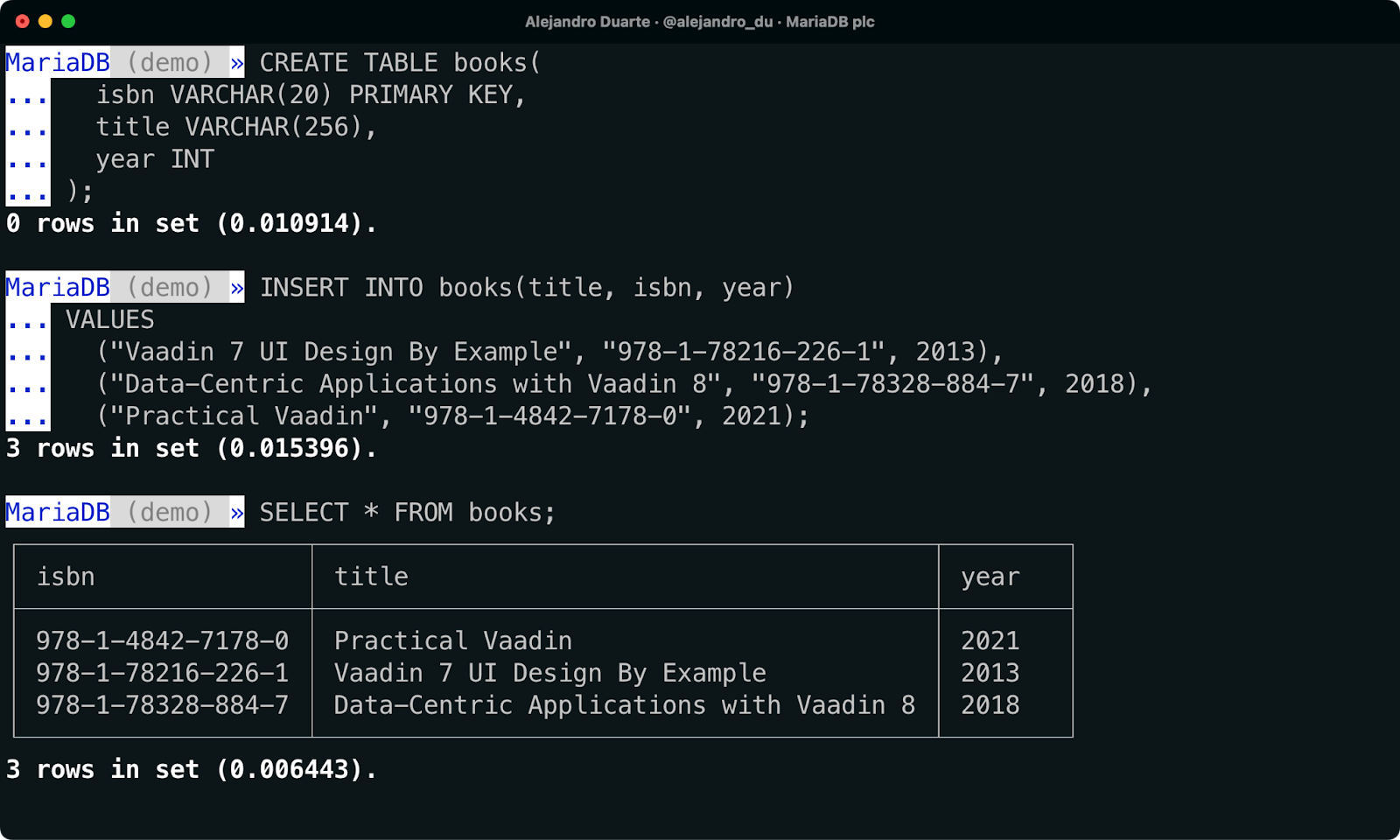
Daten mit MariaDB Shell einfügen.
Erstellen einer JSON-Sammlung in MariaDB
Wir haben MongoDB noch nicht installiert, aber wir können einen MongoDB-Client (oder eine Anwendung) verwenden, um eine Verbindung herzustellen, um Sammlungen und Dokumente zu erstellen, als würden wir MongoDB verwenden, mit der Ausnahme, dass die Daten in einer leistungsstarken, vollständig ACID-konformen und skalierbaren relationalen Datenbank gespeichert sind. Probieren wir das aus!
Verwenden Sie in der Kommandozeile das MongoDB Shell-Tool, um eine Verbindung zum MongoDB… warten Sie… es ist tatsächlich die MariaDB-Datenbank! Führen Sie Folgendes aus:
mongoshStandardmäßig versucht dieses Tool, eine Verbindung zu einem MongoDB-Server (der diesmal wieder MariaDB ist) auf Ihrem lokalen Computer (127.0.0.1) über den Standardport (20017) herzustellen. Wenn alles gut geht, sollten Sie beim Ausführen des folgenden Befehls die demo-Datenbank auflisten können:
show databasesWechseln Sie zur demo-Datenbank:
use demo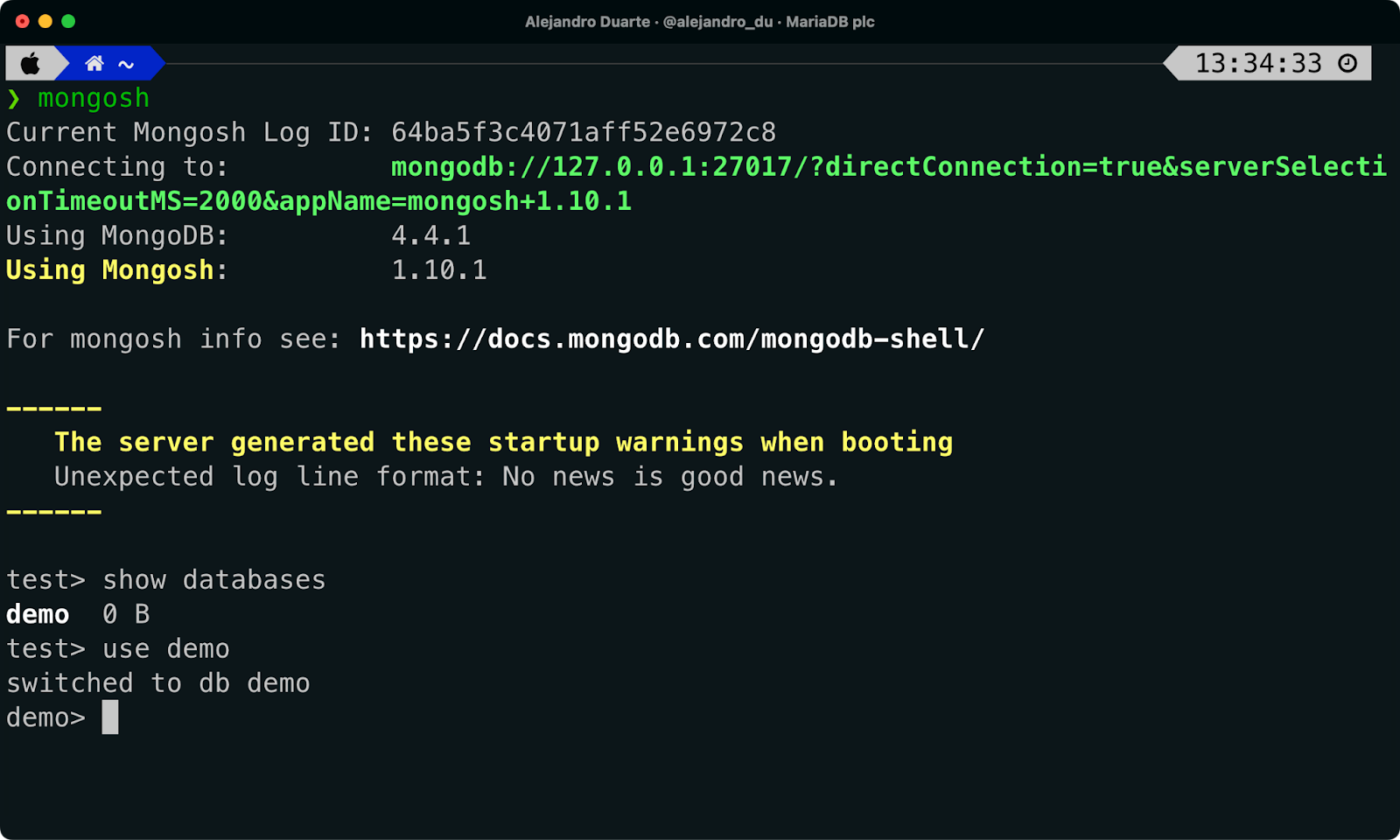
Verbindung zu MariaDB mit Mongo Shell herstellen.
Wir sind mit einer relationalen Datenbank von einem nicht-relationalen Client verbunden! Lass uns die ratings Sammlung erstellen und einige Daten hinein einfügen:
db.ratings.insertMany([
{
"isbn": "978-1-78216-226-1",
"starts": 5,
"comment": "A good resource for beginners who want to learn Vaadin"
},
{
"isbn": "978-1-78328-884-7",
"starts": 4,
"comment": "Explains Vaadin in the context of other Java technologies"
},
{
"isbn": "978-1-4842-7178-0",
"starts": 5,
"comment": "The best resource to learn web development with Java and Vaadin"
}
])Überprüfen Sie, ob die Bewertungen im Datenbank persistiert sind:
db.ratings.find()
Abfragen einer MariaDB-Datenbank mit Mongo Shell.
Verwenden von JSON-Funktionen in MariaDB
An diesem Punkt haben wir eine einzelne Datenbank, die von außen wie eine NoSQL (MongoDB) Datenbank und eine relationale (MariaDB) Datenbank aussieht. Wir können mit der gleichen Datenbank verbinden und Daten von MongoDB-Clients und SQL-Clients schreiben und lesen. Alle Daten werden in MariaDB gespeichert, so dass wir SQL verwenden können, um Daten von MongoDB-Clients oder -Anwendungen mit Daten von MariaDB-Clients oder -Anwendungen zu verbinden. Lass uns untersuchen, wie MaxScale MariaDB verwendet, um MongoDB-Daten (Sammlungen und Dokumente) zu speichern.
Verbinden Sie sich mit der Datenbank mithilfe eines SQL-Clients wie mariadb-shell und zeigen Sie die Tabellen im Demo-Schema auf:
show tables in demo;Sie sollten sowohl die books als auch die ratings Tabellen aufgelistet sehen. ratings wurde als MongoDB-Sammlung erstellt. MaxScale hat die vom MongoDB-Client gesendeten Befehle übersetzt und eine Tabelle erstellt, um die Daten in einer Tabelle zu speichern. Lass uns die Struktur dieser Tabelle anschauen:
describe demo.ratings;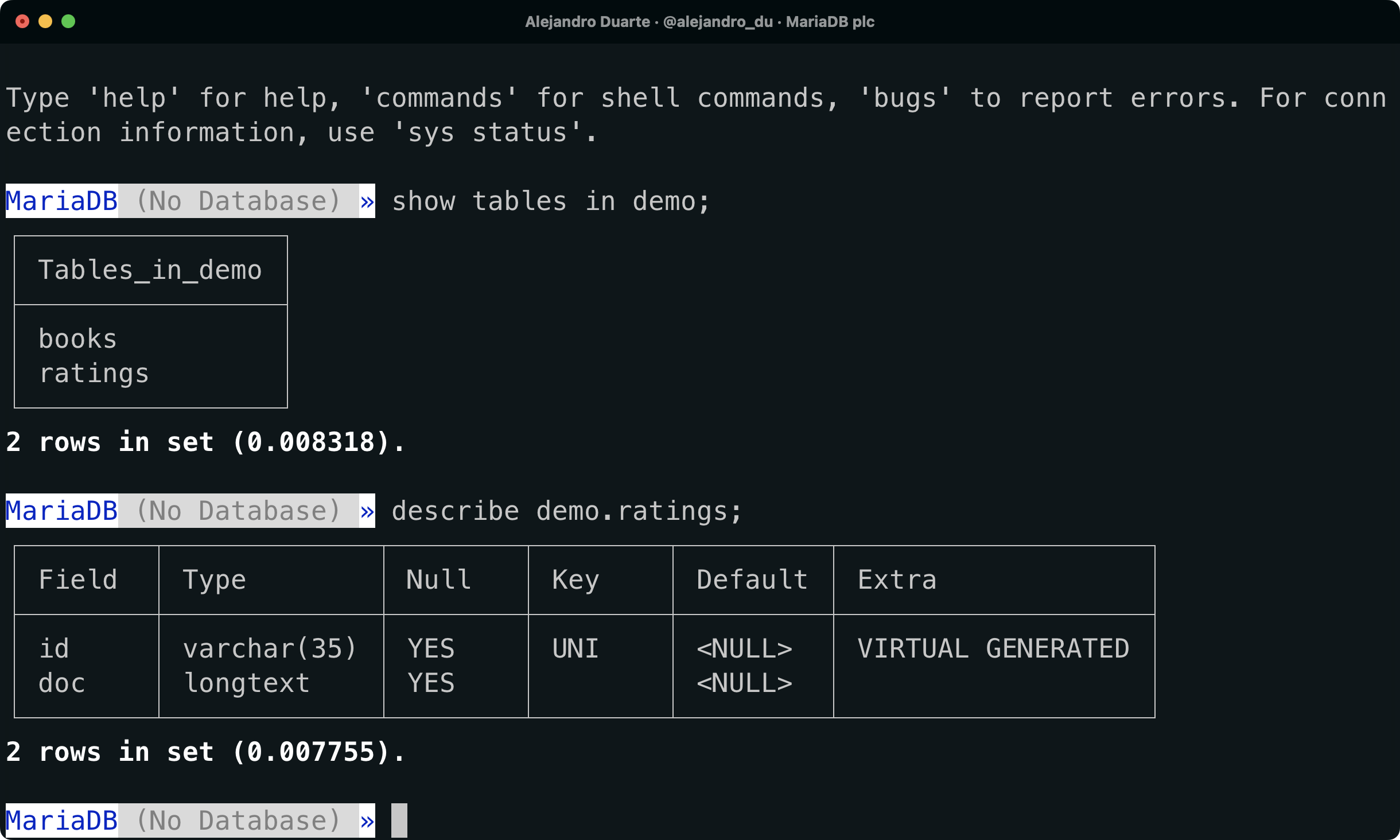
A NoSQL collection is stored as a MariaDB relational table.
Die ratings Tabelle enthält zwei Spalten:
id: die Objekt-ID.doc: das Dokument im JSON Format.
Wenn wir den Inhalt der Tabelle untersuchen, werden wir feststellen, dass alle Daten zu Bewertungen im Spalte doc im JSON-Format gespeichert sind:
SELECT doc FROM demo.ratings \G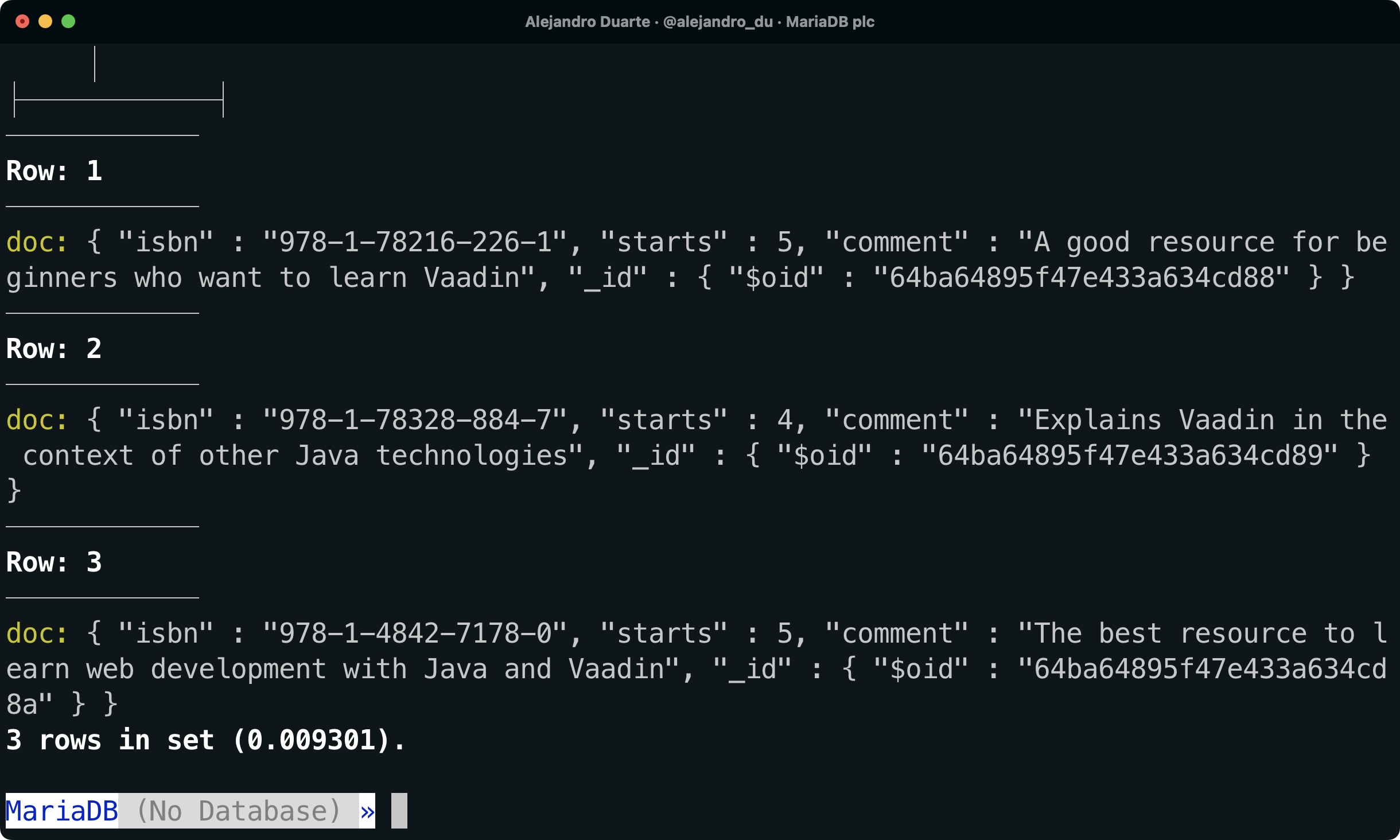
NoSQL-Dokumente werden in einer MariaDB-Datenbank gespeichert.
Kehren wir zu unserem ursprünglichen Ziel zurück—zeige die Buchtitel mit ihren Bewertungsinformationen. Das folgende ist zwar nicht der Fall, aber nehmen wir für einen Moment an, dass die ratings-Tabelle eine reguläre Tabelle mit Spalten stars und comment ist. Wenn das der Fall wäre, wäre das Joining dieser Tabelle mit der books-Tabelle einfach und unsere Aufgabe wäre erledigt:
/* this doesn’t work */
SELECT b.title, r.stars, r.comment
FROM ratings r
JOIN books b USING(isbn)Zurück zur Realität. Wir müssen die doc-Spalte der tatsächlichen ratings-Tabelle in eine relationale Ausdruck umwandeln, der als neue Tabelle in der Abfrage verwendet werden kann. Etwas in der Art:
/* this still doesn’t work */
SELECT b.title, r.stars, r.comment
FROM ratings rt
JOIN ...something to convert rt.doc to a table... AS r
JOIN books b USING(isbn)Das etwas ist die JSON_TABLE Funktion. MariaDB enthält eine umfassende Sammlung von JSON-Funktionen zur Bearbeitung von JSON-Strings. Wir werden die JSON_TABLE-Funktion verwenden, um die doc-Spalte in eine relationale Form zu konvertieren, die wir zur Durchführung von SQL-Joins verwenden können. Die allgemeine Syntax der JSON_TABLE-Funktion ist wie folgt:
JSON_TABLE(json_document, context_path COLUMNS (
column_definition_1,
column_definition_2,
...
)
) [AS] the_new_relational_tableWo:
json_document: ein String oder Ausdruck, der die zu verwendenden JSON-Dokumente zurückgibt.context_path: ein JSON Path Ausdruck, der die Knoten definiert, die als Quelle der Zeilen verwendet werden sollen.
Und die Spaltendefinitionen (column_definition_1, column_definition_2, etc…) haben die folgende Syntax:
new_column_name sql_type PATH path_in_the_json_doc [on_empty] [on_error]Mit diesem Wissen würde unsere SQL-Abfrage wie folgt aussehen:
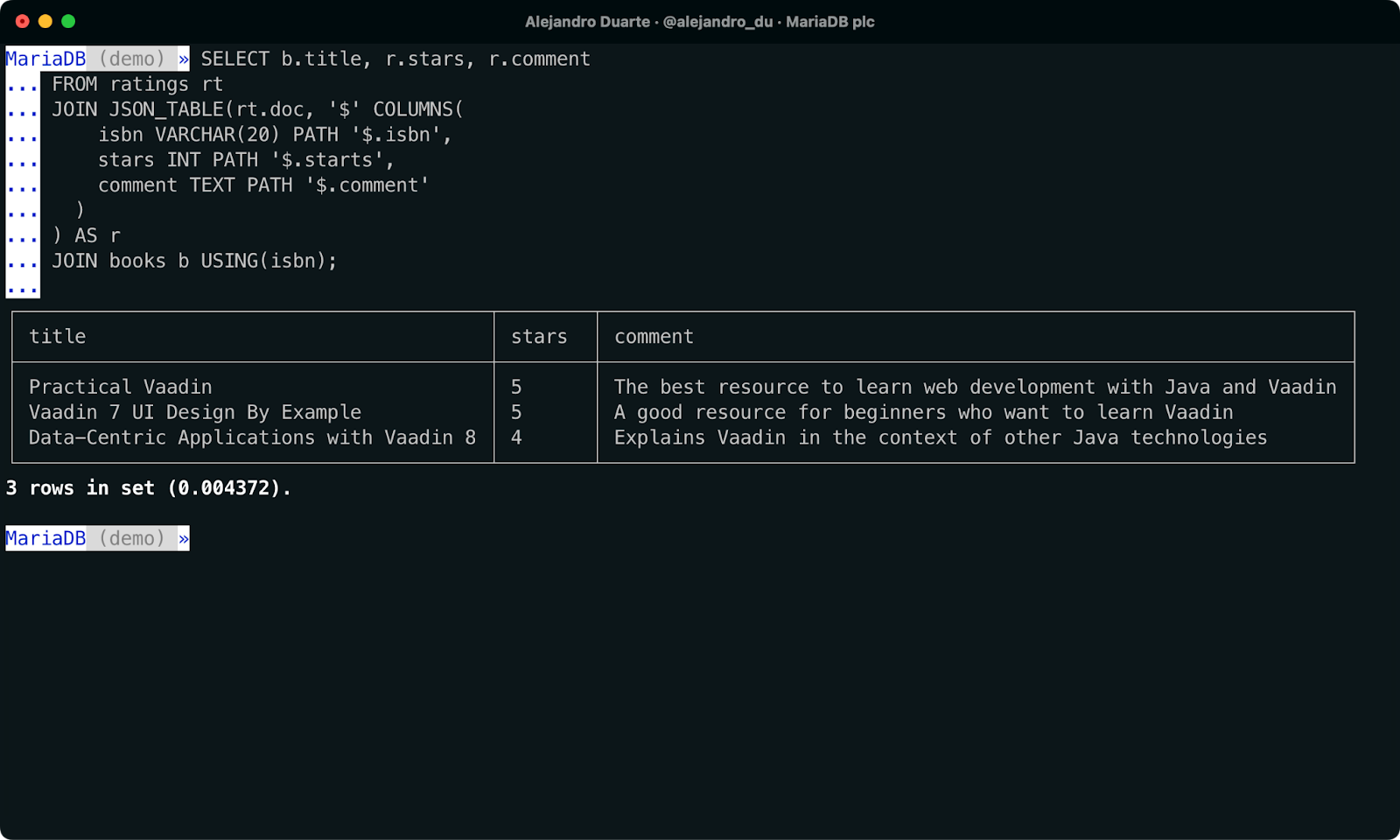
SELECT b.title, r.stars, r.comment
FROM ratings rt
JOIN JSON_TABLE(rt.doc, '$' COLUMNS(
isbn VARCHAR(20) PATH '$.isbn',
stars INT PATH '$.starts',
comment TEXT PATH '$.comment'
)
) AS r
JOIN books b USING(isbn);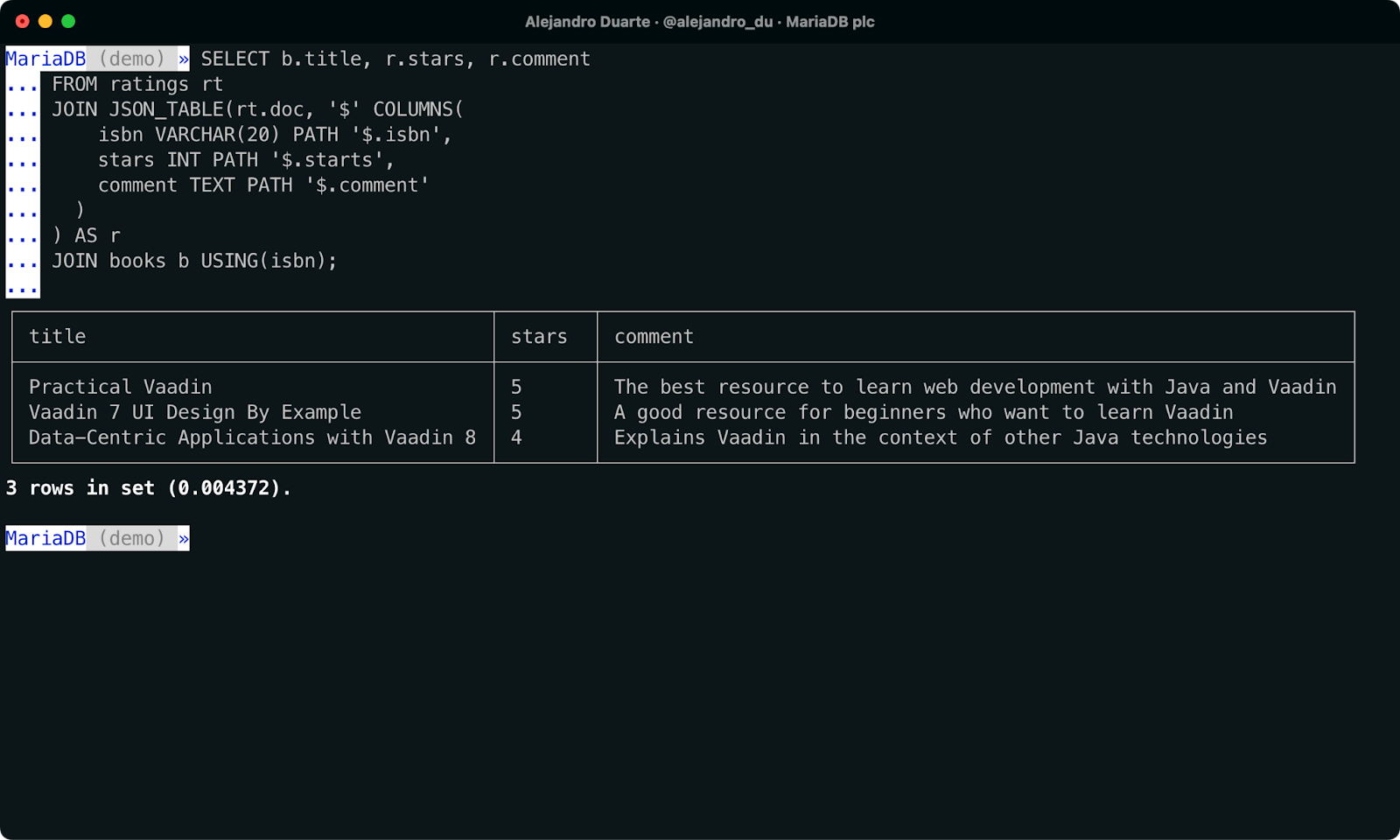
Zusammenführen von NoSQL- und SQL-Daten in einer einzigen SQL-Abfrage.
Wir hätten den ISBN-Wert als MongoDB ObjectID verwenden und somit auch als id-Spalte in der ratings-Tabelle verwenden können, aber ich überlasse das Ihnen als Übung (Tipp: Verwenden Sie _id anstelle von isbn beim Einfügen von Daten mit dem MongoDB-Client oder der App).
A Word on Scalability
Es gibt den Irrglauben, dass relationale Datenbanken nicht horizontal skalieren (mehr Knoten hinzufügen) während NoSQL-Datenbanken dies tun. Aber relationale Datenbanken skalieren ohne die ACID-Eigenschaften zu opfern. MariaDB verfügt über mehrere Speicher-Engines, die auf verschiedene Workloads zugeschnitten sind. Zum Beispiel können Sie eine MariaDB-Datenbank skalieren, indem Sie Datensplitting mit Hilfe von Spider implementieren. Sie können auch eine Vielzahl von Speicher-Engines verwenden, um verschiedene Workloads auf Spaltenbasis zu bewältigen. Cross-Engine-Joins sind in einer einzigen SQL-Abfrage möglich.
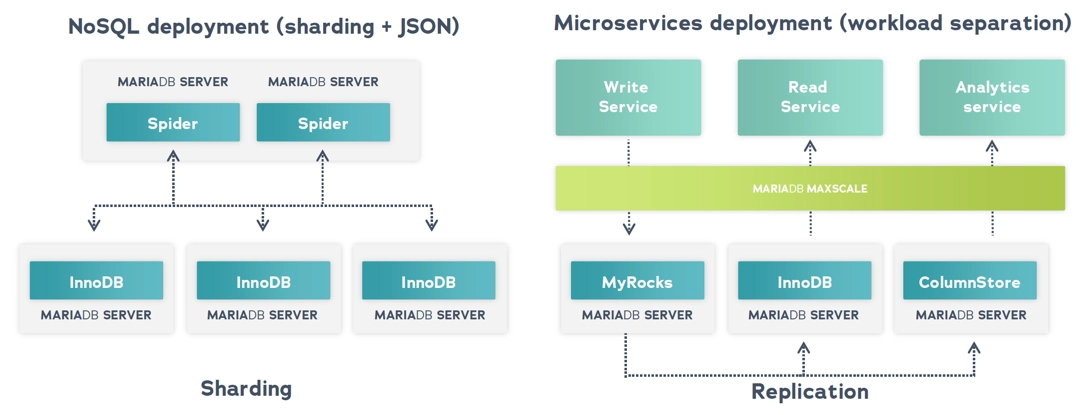
Kombinieren von mehreren Speicher-Engines in einer einzigen logischen MariaDB-Datenbank.
Eine weitere modernere Alternative ist Distributed SQL mit MariaDB Xpand. Ein verteiltes SQL-Datenbankmanagementsystem erscheint für Anwendungen als einzelnes logisches relationales Datenbankmanagementsystem durch transparentes Sharding. Es verwendet eine Shared-Nothing-Architektur, die sowohl Lese- als auch Schreibvorgänge skaliert.
A distributed SQL database deployment.
Schlussfolgerung
Unsere Aufgabe hier ist erledigt! Jetzt können Ihre Systeme eine skalierbare, ACID-konforme 360-Grad-Sicht Ihrer Daten haben, unabhängig davon, ob sie von SQL- oder NoSQL-Anwendungen erstellt wurden. Es besteht weniger Bedarf, Ihre Anwendungen von NoSQL zu SQL zu migrieren oder SQL-Anwendungen zu Datenbankpolyglotten zu machen. Wenn Sie mehr über andere Funktionen in MaxScale erfahren möchten, schauen Sie sich dieses Video an oder besuchen Sie die Dokumentation.
Source:
https://dzone.com/articles/mixing-sql-and-nosql-with-mariadb-and-mongodb