













Klassischer Fall 1
Viele Softwareprofis haben nicht das nötige tiefgehende Wissen über die Logik des TCP/IP, was oft dazu führt, dass Probleme fälschlicherweise als mysteriöse Probleme identifiziert werden. Einige lassen sich von der Komplexität der TCP/IP-Netzwerkliteratur entmutigen, während andere durch verwirrende Details in Wireshark in die Irre geführt werden. Beispielsweise könnte ein DBA, der mit Leistungsproblemen konfrontiert ist, die Daten aus der Paketaufzeichnung in Wireshark falsch interpretieren und fälschlicherweise zu dem Schluss kommen, dass TCP-Retransmissionen die Ursache sind.

Da Retransmissionen verdächtigt werden, ist es wichtig, ihre Natur zu verstehen. Retransmission umfasst grundlegend die Retransmission nach einem Timeout. Um zu bestätigen, ob die Retransmission tatsächlich die Ursache ist, sind zeitbezogene Informationen notwendig, die im obigen Screenshot nicht bereitgestellt werden. Nach der Anforderung eines neuen Screenshots vom DBA wurden die Zeitstempelinformationen hinzugefügt.

Bei der Analyse von Netzwerkpaketen sind Zeitstempelinformationen entscheidend für eine genaue logische Argumentation. Ein Zeitunterschied im Mikrosekundenbereich zwischen zwei identischen Paketen deutet entweder auf eine Retransmission nach einem Timeout oder auf die Erfassung von doppelten Paketen hin. In einer typischen LAN-Umgebung mit einer Round-trip Time (RTT) von etwa 100 Mikrosekunden, in der TCP-Retransmissionen mindestens eine RTT erfordern, deutet eine Retransmission, die nur 1/100 der RTT auftritt, wahrscheinlich auf die Erfassung doppelter Pakete hin, anstatt auf eine tatsächliche Retransmission nach einem Timeout.
Klassischer Fall 2
Ein weiterer klassischer Fall veranschaulicht die Bedeutung logischen Denkens bei der Analyse von Netzwerkproblemen.
Eines Tages kam ein Geschäftsentwickler hastig herbei und berichtete, dass ein geplanter Skriptlauf mit der MySQL-Datenbankmiddleware in den frühen Morgenstunden ohne Rückmeldung fehlgeschlagen war. Nachdem ich von dem Problem erfahren hatte, überprüfte ich die Fehlerprotokolle der MySQL-Datenbankmiddleware, fand jedoch keine wertvollen Hinweise. Also fragte ich die Entwickler, ob sie das Problem reproduzieren könnten, da ein reproduzierbares Problem einfacher zu lösen ist.
Die Entwickler versuchten mehrmals, das Problem zu reproduzieren, waren jedoch erfolglos. Sie machten jedoch eine neue Entdeckung: Sie stellten fest, dass die Ausführung derselben SQL-Abfragen tagsüber zu anderen Antwortzeiten führte als in den frühen Morgenstunden. Sie vermuteten, dass die MySQL-Datenbankmiddleware die Sitzung blockierte und keine Ergebnisse an den Client zurückgab, wenn die SQL-Antwort langsam war.
Aufgrund dieser Erkenntnis wurde das Datenbankbetriebsteam gebeten, das SQL des Skripts zu ändern, um eine langsame SQL-Antwort zu simulieren. Als Ergebnis gab die MySQL-Datenbankmiddleware die Ergebnisse zurück, ohne dass das Hängeproblem aus den frühen Morgenstunden auftrat.
Eine Weile lang konnte die Ursache nicht identifiziert werden, und die Entwickler entdeckten ein funktionales Problem mit der MySQL-Datenbankmiddleware. Daher waren die Entwickler und DBA-Betriebsteams immer mehr davon überzeugt, dass die MySQL-Datenbankmiddleware die Antworten verzögerte. In Wirklichkeit waren diese Probleme jedoch nicht mit den Antwortzeiten der MySQL-Datenbankmiddleware verbunden.
Von den Ereignissen des ersten Tages war das Problem tatsächlich aufgetreten. Alle Beteiligten versuchten, die Ursache zu ermitteln, stellten verschiedene Vermutungen an, aber der wahre Grund blieb verborgen.
Am nächsten Tag berichteten die Entwickler, dass das Skriptproblem in den frühen Morgenstunden erneut aufgetreten sei, sie konnten es jedoch tagsüber nicht reproduzieren. Die Entwickler, die sich unter Druck gesetzt fühlten, da das Skript bald online verwendet werden sollte, beschwerten sich über die Situation. Mein einziger Vorschlag war, dass sie das Skript tagsüber verwenden sollten, um Probleme in den frühen Morgenstunden zu vermeiden. Mit all den Verdachtsmomenten, die sich auf die MySQL-Datenbank-Middleware konzentrierten, war es schwierig, das Problem aus anderen Perspektiven zu analysieren.
Als Entwickler, der für die MySQL-Datenbank-Middleware verantwortlich ist, können solche mysteriösen Probleme nicht leicht übersehen werden. Sie zu ignorieren könnte die nachfolgende Nutzung der MySQL-Datenbank-Middleware beeinträchtigen, und es gibt auch Druck von der Führungsebene, das Problem schnell zu lösen. Schließlich wurde entschieden, eine kostengünstige Lösung zur Paketaufzeichnung und -analyse zu implementieren: Während der Ausführung des Skripts in den frühen Morgenstunden sollten Paketaufzeichnungen auf dem Server durchgeführt werden, um zu analysieren, was zu diesem Zeitpunkt geschah. Das Ziel war es festzustellen, ob die MySQL-Datenbank-Middleware überhaupt keine Antwort gesendet hatte oder ob sie eine Antwort gesendet hatte, die das Client-Skript nicht empfangen hatte. Sobald bestätigt werden konnte, dass die MySQL-Datenbank-Middleware eine Antwort gesendet hatte, würde das Problem nicht den Entwicklern der MySQL-Datenbank-Middleware zugeschrieben werden.
Am dritten Tag berichteten die Entwickler, dass das Problem am frühen Morgen nicht erneut aufgetreten sei, und die Analyse der Paketaufzeichnung bestätigte, dass das Problem nicht aufgetreten war. Nach sorgfältiger Überlegung schien es unwahrscheinlich, dass das Problem allein am MySQL-Datenbank-Middleware lag: häufige Vorkommnisse am frühen Morgen und seltene Vorkommnisse tagsüber waren rätselhaft. Der einzige Ausweg war, auf das erneute Auftreten des Problems zu warten und es anhand der Paketaufzeichnungen zu analysieren.
Am vierten Tag trat das Problem nicht erneut auf.
Am fünften Tag jedoch tauchte das Problem schließlich wieder auf und brachte Hoffnung auf eine Lösung.
Die Paketaufzeichnungsdateien sind zahlreich. Zunächst sollten die Entwickler um den Zeitstempel bitten, wann das Problem auftrat, und dann die umfangreichen Paketaufzeichnungsdaten durchsuchen, um die SQL-Abfrage zu identifizieren, die das Problem verursachte. Das Endergebnis lautet wie folgt:
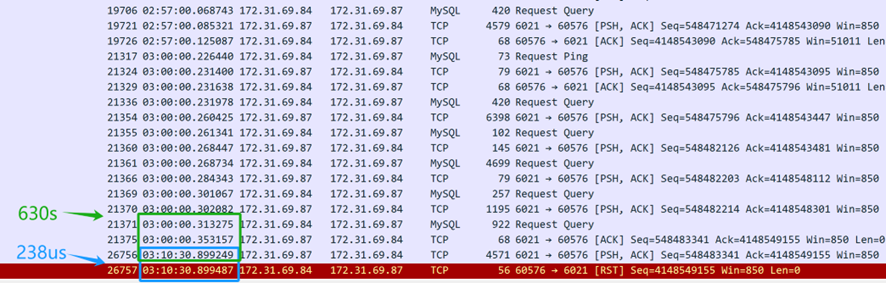
Aus dem oben genannten Paketaufzeichnungsinhalt (vom Server erfasst) geht hervor, dass die SQL-Abfrage um 3 Uhr morgens gesendet wurde. Die MySQL-Datenbank-Middleware benötigte 630 Sekunden (03:10:30.899249-03:00:00.353157), um die SQL-Antwort an den Client zurückzugeben, was darauf hindeutet, dass die MySQL-Datenbank-Middleware tatsächlich auf die SQL-Abfrage reagierte. Allerdings erhielt die TCP-Schicht des Servers nur 238 Mikrosekunden später (03:10:30.899487-03:10:30.899249) ein Reset-Paket, was verdächtig schnell war. Es ist wichtig zu beachten, dass dieses Reset-Paket nicht sofort vom Client stammen kann.
Zunächst ist es notwendig zu bestätigen, wer das Reset-Paket gesendet hat — ob es vom Client oder von einem Zwischengerät unterwegs gesendet wurde. Da die Paketaufnahme nur auf der Serverseite durchgeführt wurde, sind Informationen über die Paketlage des Clients nicht verfügbar. Durch die Analyse der Paketaufnahme-Dateien von der Serverseite und die Anwendung logischer Überlegungen soll die Ursache des Problems identifiziert werden.
Wenn die Annahme getroffen wird, dass der Client ein Reset gesendet hat, würde dies bedeuten, dass die TCP-Schicht des Clients den TCP-Zustand dieser Verbindung nicht mehr erkennt — der Übergang von einem etablierten Zustand zu einem nicht vorhandenen. Diese Änderung im TCP-Zustand würde die Client-Anwendung über ein Verbindungsproblem informieren, was dazu führen würde, dass das Client-Skript sofort einen Fehler ausgibt. In der Realität wartet das Client-Skript jedoch weiterhin auf die Rückantwort. Daher ist die Annahme, dass der Client ein Reset gesendet hat, nicht zutreffend — der Client hat kein Reset gesendet. Die Verbindung des Clients ist weiterhin aktiv, aber auf der Serverseite wurde die entsprechende Verbindung durch das Reset beendet.
Wer hat dann das Reset gesendet? Der Hauptverdächtige ist die Cloud-Umgebung von Amazon. Basierend auf dieser Analyse der Paketaufnahme hat der DBA-Dienst Amazon-Kundendienst kontaktiert und folgende Informationen erhalten:
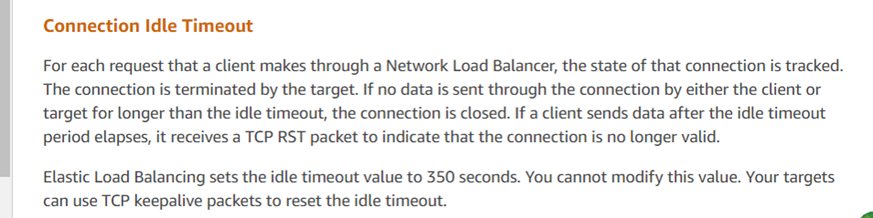
Die Antwort des Kundenservice stimmt mit den Analyseergebnissen überein und deutet darauf hin, dass der ELB von Amazon (Elastic Load Balancer, ähnlich wie LVS) die TCP-Sitzung zwangsweise beendet hat. Laut ihrem Feedback sendet das Amazon ELB-Gerät einen Reset an die antwortende Partei (in diesem Fall den Server), wenn eine Antwort die 350-Sekunden-Schwelle überschreitet (wie in der Paketaufzeichnung als 630 Sekunden beobachtet). Die vom Entwicklerteam bereitgestellten Client-Skripte haben den Reset nicht erhalten und fälschlicherweise angenommen, dass die Serververbindung noch aktiv war. Die offiziellen Empfehlungen für solche Probleme umfassen die Verwendung von TCP Keepalive-Mechanismen zur Minderung dieser Probleme.
Mit der erhaltenen offiziellen Antwort wurde das Problem als vollständig gelöst betrachtet.
Dieser spezifische Fall veranschaulicht, wie Online-Probleme äußerst komplex sein können und die Erfassung von kritischen Informationen — in diesem Fall von Paketaufzeichnungsdaten — erforderlich ist, um die Situation zu verstehen, wie sie aufgetreten ist. Durch logisches Denken und die Anwendung von reductio ad absurdum wurde die Ursache identifiziert.
Source:
https://dzone.com/articles/logical-reasoning-in-network-problems