













Linux-Kenntnisse gehören zu den wertvollsten Fähigkeiten in der Technikbranche. Sie können Ihnen helfen, schneller und effizienter zu arbeiten. Viele der Weltweit leistungsfähigsten Server und Supercomputer laufen auf Linux.
Während Ihnen diese Fähigkeiten in Ihrer aktuellen Rolle Macht verleihen, kann das Lernen von Linux Ihnen auch helfen, in andere Technikberufe wie DevOps, Cybersicherheit und Cloud Computing zu wechseln.
In diesem Lehrbuch werden Sie die Grundlagen der Linux-Kommandozeile lernen und dann angehen, um fortgeschrittenere Themen wie Shell-Skripting und Systemadministration zu erlernen. Egal, ob Sie Linux neu entdecken oder bereits seit Jahren verwenden, dieses Buch hat für jeden etwas zu bieten.
Wichtiger Hinweis: Alle Beispiele in diesem Buch werden mit Ubuntu 22.04.2 LTS (Jammy Jellyfish) demonstriert. Die meisten Kommandozeilen-Tools sind in anderen Distributionen weitgehend gleich. Allerdings können einige GUI-Anwendungen und Befehle unterschiedlich sein, wenn Sie auf einer anderen Linux-Distribution arbeiten.
Inhaltsverzeichnis
Teil 1: Einführung in Linux
1.1. Erste Schritte mit Linux
Was ist Linux?
Linux ist ein quelloffenes Betriebssystem, das auf dem Betriebssystem Unix basiert. Es wurde 1991 von Linus Torvalds erstellt.
Open Source bedeutet, dass der Quellcode des Betriebssystems der Öffentlichkeit zugänglich ist. Dies ermöglicht es jedem, den ursprünglichen Code zu ändern, ihn anzupassen und die neue Version des Betriebssystems an potentielle Benutzer weiterzugeben.
Warum sollten Sie sich mit Linux auseinandersetzen?
Im heutigen Datenzentrum-Umfeld sind Linux und Microsoft Windows die Hauptkonkurrenten, wobei Linux einen bedeutenden Anteil hat.
Hier sind mehrere überzeugende Gründe, warum Sie Linux lernen sollten:
-
Angesichts der Verbreitung von Linux-Hosting ist es sehr wahrscheinlich, dass Ihre Anwendung auf Linux gehostet wird. Daher erwächst dem Entwickler das Wissen um Linux zunehmend Wert.
-
Mit dem zunehmenden Standard von Cloud Computing ist es sehr wahrscheinlich, dass Ihre Cloud-Instanzen auf Linux basieren.
-
Linux bildet die Grundlage für viele Betriebssysteme in der Internet of Things (IoT) und mobilen Anwendungen.
-
Im IT-Sektor gibt es viele Möglichkeiten für Personen mit Linux-Kenntnissen.
Was bedeutet es, dass Linux ein Open-Source-Betriebssystem ist?
Erstens, was ist Open Source? Open Source Software ist Software, deren Quellcode frei zugänglich ist, was es jedem erlaubt, sie zu verwenden, zu ändern und weiterzugeben.
Jederzeit, wenn Quellcode erstellt wird, ist er automatisch urheberrechtlich geschützt, und seine Verteilung wird durch den Rechteinhaber durch Softwarelizenzen geregelt.
Im Gegensatz zu Open Source verhält sich proprietäre oder geschlossene Quellcode-Software, indem Zugriff auf ihren Quellcode eingeschränkt wird. Nur die Schöpfer können ihn anschauen, ändern oder weitergeben.
Linux ist primär Open Source, was bedeutet, dass его Quellcode frei verfügbar ist. Jeder kann ihn anschauen, ändern und weitergeben. Entwickler aus der ganzen Welt können zu seiner Verbesserung beitragen. Dies legt die Grundlage der Zusammenarbeit, die ein wichtiges Merkmal von Open Source Software ist.
Dieser kollaborative Ansatz hat zu der breiten Verbreitung von Linux auf Servern, Desktopcomputern, integrierten Systemen und Mobilgeräten geführt.
Das Interessanteste an Linux als Open Source ist, dass jeder das Betriebssystem auf seine spezifischen Bedürfnisse zuschneiden kann, ohne von proprietären Einschränkungen behindert zu werden.
Chrome OS, das von Chromebooks verwendet wird, basiert auf Linux. Android, das vielen Smartphones weltweit Antrieb leistet, basiert ebenfalls auf Linux.
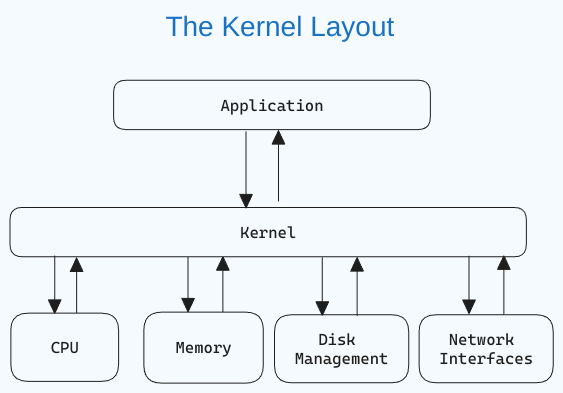
Was ist der Linux-Kernel?
Der Kernel ist der zentrale Bestandteil eines Betriebssystems, der die Computer- und Hardwareoperationen verwaltet. Er handhabt Speicheroperationen und CPU-Zeit.
Der Kernel fungiert als Brücke zwischen Anwendungen und der Hardware-Ebene Datenverarbeitung mittels Interprozesskommunikation und Systemaufrufen.
Der Kernel wird beim Start des Betriebssystems zunächst in den Arbeitsspeicher geladen und bleibt dort bis zum Herunterfahren des Systems. Er ist verantwortlich für Aufgaben wie Festplattenverwaltung, Aufgabenverwaltung und Speicherverwaltung.
Wenn Sie sich fragen, was der Linux-Kernel aussieht,hier ist der GitHub-Link.
Was ist eine Linux-Distribution?
Bis zu diesem Punkt wissen Sie, dass Sie den Linux-Kernel-Code wiederverwenden, ihn ändern und einen neuen Kernel erstellen können. Sie können weiterhin unterschiedliche Utilities und Software kombinieren, um eine komplett neue Betriebssystemversion zu erstellen.
Eine Linux-Distribution oder Distro ist eine Version des Linux-Betriebssystems, die den Linux-Kernel, System-Utilities und andere Software beinhaltet. Being open source, a Linux distribution is a collaborative effort involving multiple independent open-source development communities.
Was bedeutet es, dass eine Distribution abgeleitet ist? Wenn Sie sagen, eine Distribution ist „abgeleitet“ von einer anderen, dann ist die neue Distro auf der Basis oder Grundlage der ursprünglichen Distro aufgebaut. Diese Ableitung kann den gleichen Paketverwaltungssystem (mehr dazu später) beinhalten, die gleiche Kernelversion und manchmal die gleichen Konfigurationstools.
Heute gibt es tausende von Linux-Distributionen zu wählen, die unterschiedliche Ziele und Kriterien für die Auswahl und Unterstützung der Software bieten, die sie bereitstellen.
Distributionen unterscheiden sich von einer another, aber sie haben im Prinzip mehrere gemeinsame Merkmale:
-
Eine Distribution besteht aus einem Linux-Kernel.
-
Sie unterstützt Programme aus dem Benutzerraum.
-
Eine Distribution kann klein und auf eine bestimmte Aufgabe beschränkt sein oder mehrere tausend Open-Source- Programme beinhalten.
-
Es sollte eine Methode zum Installieren und Aktualisieren der Distribution und ihrer Komponenten bereitgestellt werden.
Wenn Sie die Linux-Distributions-Zeitleiste anschauen, sehen Sie zwei bedeutende Distribitionen: Slackware und Debian. Mehrere Distributionen sind von ihnen abgeleitet. Zum Beispiel sind Ubuntu und Kali von Debian abgeleitet.
Was sind die Vorteile der Ableitung? Es gibt verschiedene Vorteile der Ableitung. Abgeleitete Distributionen können die Stabilität, Sicherheit und die großen Software-Repositories der Elterndistribution nutzen.
Beim Aufbau auf einer bestehenden Grundlage können Entwickler ihre Konzentration und Anstrengungen ganz auf die spezialisierten Funktionen der neuen Distribution lenken. Benutzer von abgeleiteten Distributionen können von der Dokumentation, der Community-Unterstützung und den Ressourcen, die bereits für die Elterndistribution verfügbar sind, profitieren.
Eine Reihe von populären Linux-Distributionen sind:
-
Ubuntu
: Eine der am weitesten verbreiteten und beliebtesten Linux-Distributionen. Sie ist benutzerfreundlich und wird für Anfänger empfohlen. Mehr über Ubuntu erfahren Sie hier.
-
Linux Mint: Basierend auf Ubuntu, bietet Linux Mint eine benutzerfreundliche Erfahrung mit einem Schwerpunkt auf Multimedien Unterstützung. Mehr über Linux Mint erfahren Sie hier.
-
Arch Linux: Beliebt unter erfahrenen Benutzern, ist Arch eine leichte und flexible Distribution, die auf Benutzern, die eine selbstgemachte Herangehensweise bevorzugen, zielt. Mehr über Arch Linux erfahren Sie hier.
-
Manjaro: Basierend auf Arch Linux bietet Manjaro eine benutzerfreundliche Erfahrung mit vorinstallierter Software und einfachen Systemverwaltungstools. Erfahren Sie hier mehr über Manjaro.
-
Kali Linux: Kali Linux bietet eine umfassende Suite von Sicherheitstools und konzentriert sich hauptsächlich auf Cybersicherheit und Hacking. Erfahren Sie hier mehr über Kali Linux.
Wie man Linux installiert und darauf zugreift
Der beste Weg zu lernen, ist die Konzepte anzuwenden, während Sie voranschreiten. In diesem Abschnitt lernen wir, wie man Linux auf Ihrem Rechner installiert, damit Sie mitmachen können. Sie lernen auch, wie man auf einem Windows-Rechner auf Linux zugreift.
Ich empfehle, dass Sie eine der in diesem Abschnitt erwähnten Methoden befolgen, um Zugang zu Linux zu erhalten, damit Sie mitmachen können.
Installieren Sie Linux als primäres Betriebssystem
Die Installation von Linux als primäres Betriebssystem ist der effizienteste Weg, Linux zu verwenden, da Sie die volle Leistung Ihres Rechners nutzen können.
In diesem Abschnitt lernst du, wie du Ubuntu installierst, das eine der beliebtesten Linux-Distributionen ist. Ich habe andere Distributionen ausgelassen, da ich Dinge einfach halten möchte. Du kannst immer andere Distributionen erkunden, sobald du dich mit Ubuntu behaupten kannst.
-
Schritt 1 – Ubuntu-ISO herunterladen: Gehe zu der offiziellen Webseite und lade die ISO-Datei herunter. Stelle sicher, dass du eine stabile Version mit der Bezeichnung „LTS“ auswählst. LTS steht für Long Term Support, was bedeutet, dass du für einen lange Zeit (normalerweise 5 Jahre) kostenlose Sicherheits- und Wartungsupdates erhalten kannst.
-
Schritt 2 – Ein bootbares USB-Stick erstellen: Es gibt eine Reihe von Software, die ein bootbares USB-Stick erstellen können. Ich empfehle Rufus, da er recht einfach zu verwenden ist. Du kannst ihn von hier herunterladen.
-
Schritt 3 – Von der USB-Frischfleischdose starten:
Sobald Ihre bootbare USB-Frischfleischdose bereit ist, stecken Sie sie ein und starten Sie das System von der USB-Frischfleischdose. Das Startmenü hängt von Ihrem Laptop ab. Sie können das Startmenü für Ihren Laptop-Modell mit Google suchen.
-
Schritt 4 – Folgen Sie den Anweisungen. Sobald der Bootvorgang startet, wählen Sie
try or install ubuntu.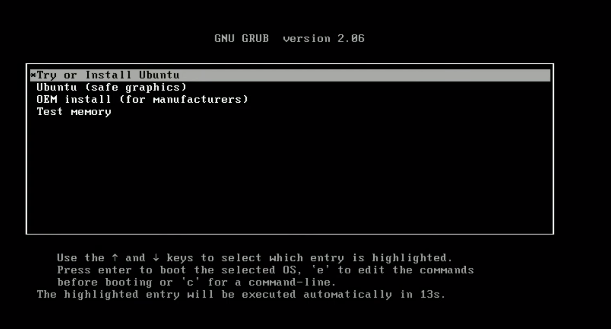
Der Vorgang dauert etwas Zeit. Sobald das GUI erscheint, können Sie die Sprache und die Tastaturbelegung auswählen und fortfahren. Geben Sie Ihren Login und Ihren Namen ein. Merken Sie die Zugangsdaten, da Sie sie benötigen, um sich auf Ihrem System einzuloggen und volle Berechtigungen zu erhalten. Warten Sie bis die Installation abgeschlossen ist.
-
Schritt 5 – Neustart: Klicken Sie auf „Jetzt neustarten“ und entfernen Sie die USB-Frischfleischdose.
-
Schritt 6 – Anmelden: Melde dich mit den zuvor eingegebenen Zugangsdaten an.
Und dann ist es soweit! Nun kannst du Anwendungen installieren und dein Desktop anpassen.

Für eine erweiterte Installation kannst du die folgenden Themen erkunden:
-
Diskonfiguration.
-
Swap-Speicher einrichten, um das Ruhezustand-Feature zu aktivieren.
Zugriff auf das Terminal
Ein wichtiger Bestandteil dieses Handbuchs besteht darin, das Terminal zu lernen, in dem du alle Befehle eingeben und das Magie passieren siehst. Du kannst das Terminal durch Drücken der „Windows“-Taste und Eingabe von „Terminal“ suchen. Du kannst das Terminal im Dock, wo andere Apps platziert sind, fixieren, um auf sie zügig zuzugreifen.
💡 Der Tastenkürzel für das Öffnen des Terminals ist
Strg+Alt+T
Du kannst das Terminal auch aus einem Verzeichnis heraus öffnen. Klicke mit der rechten Maustaste, wo du bist und wähle „Im Terminal öffnen“. Dadurch wird das Terminal in demselben Pfad geöffnet.
Wie man Linux auf einem Windows-Rechner verwendet
Manchmal möchtest du möglicherweise sowohl Linux als auch Windows nebeneinander ausführen. Glücklicherweise gibt es einige Möglichkeiten, um das Beste aus beiden Welten zu erhalten, ohne für jede Betriebssystem zu einem separaten Computer zu investieren.
In diesem Abschnitt erkundest du einige Möglichkeiten, wie man Linux auf einem Windows-Rechner verwenden kann. Einige von ihnen sind browserbasiert oder cloudbasiert und erfordern keine vorhergehende OS-Installation, um verwendet zu werden.
Option 1: „Dual-Boot“ Linux + Windows Mit einem Dual-Boot kannst du Linux neben Windows auf deinem Computer installieren, was dir erlaubt, zu Starten den gewünschten Betriebssystemen zu wählen.
Dies erfordert, dass du deinen Festplattencontroller partitionierst und Linux auf einer separaten Partition installierst. Mit diesem Ansatz kannst du nur ein Betriebssystem gleichzeitig verwenden.
Option 2: Verwendung des Windows Subsystems für Linux (WSL) Das Windows Subsystem für Linux stellt eine Kompatibilitätsschicht bereit, die es dir erlaubt, Linux-Binärexekutablen nativ auf Windows zu betreiben.
Die Verwendung von WSL bringt einige Vorteile mit sich. Die Einrichtung von WSL ist einfach und zeitunabhängig. Es ist leichter als Virtualisierung, wo du Ressourcen vom Host-Rechner verwalten musst. Du musst kein ISO-Image oder virtuelles Disketten Medium für Linux-Rechner herunterladen, die oft große Dateien sind. Du kannst Windows und Linux nebeneinander verwenden.
Wie WSL2 installieren
Zuerst aktiviere die Option für das Windows Subsystem für Linux in den Einstellungen.
-
Gehe zu Start und suche nach „Windows-Eigenschaften ein- oder ausschalten.“
-
Wähle die Option „Windows Subsystem für Linux“ aus, falls sie nicht bereits ausgewählt ist.
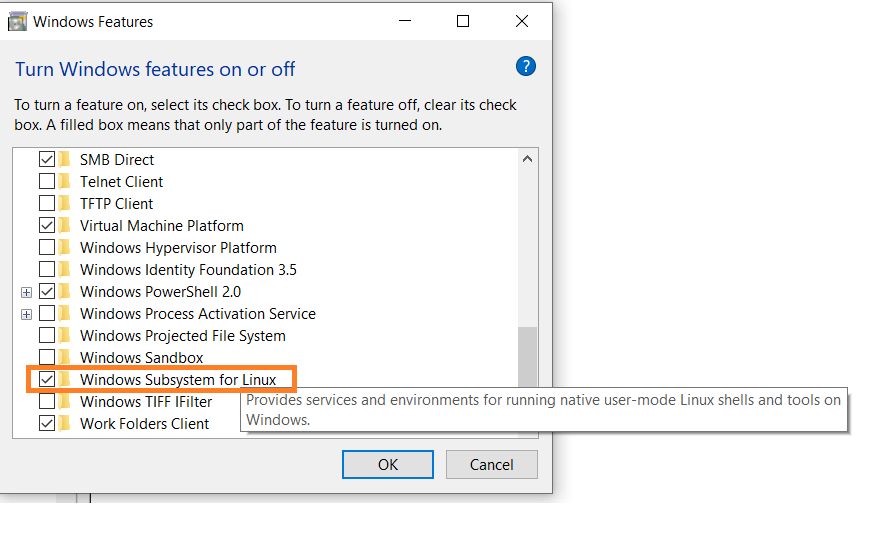
-
Danach öffne deinen Befehlszeilen-Prompt und gebe die Installationsbefehle ein.
-
als Administrator öffnen:

-
Führen Sie den untenstehenden Befehl aus:
wsl --install
Dies ist die Ausgabe:
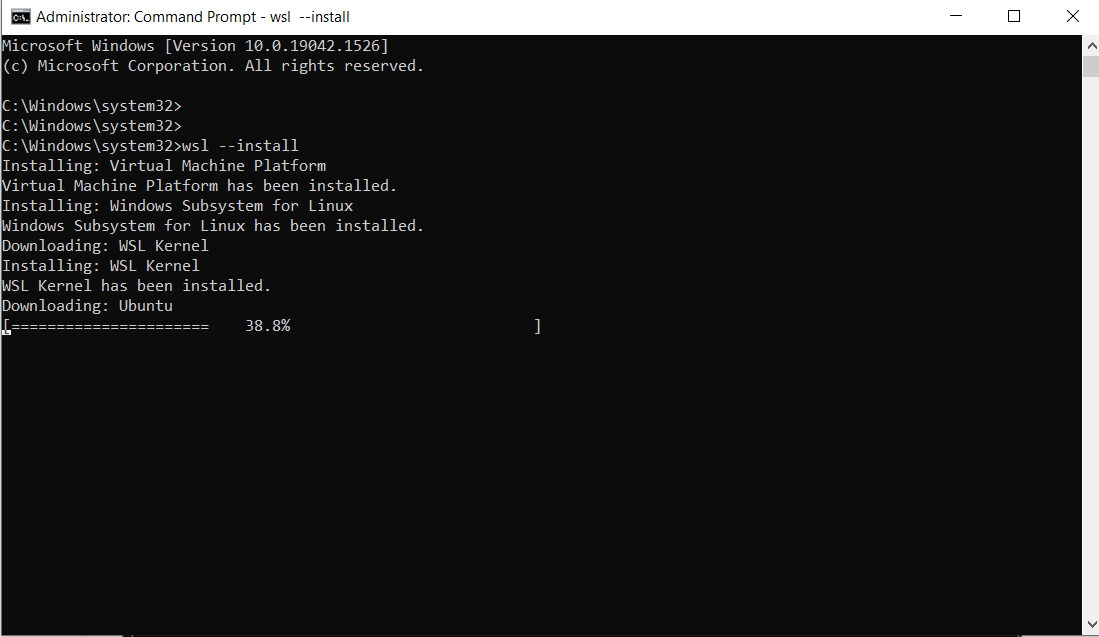
Hinweis: Standardmäßig wird Ubuntu installiert.
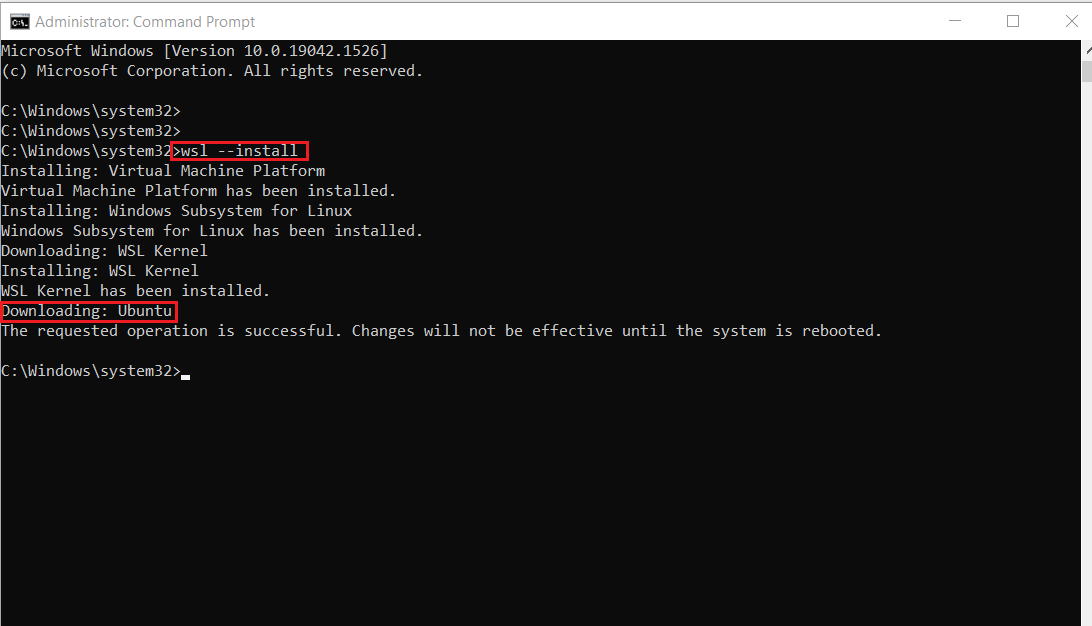
- Nach Abschluss der Installation müssen Sie Ihren Windows-Rechner neu starten. Starten Sie daher Ihren Windows-Rechner neu.
Nach dem Neustart sehen Sie vielleicht ein Fenster wie dieses:
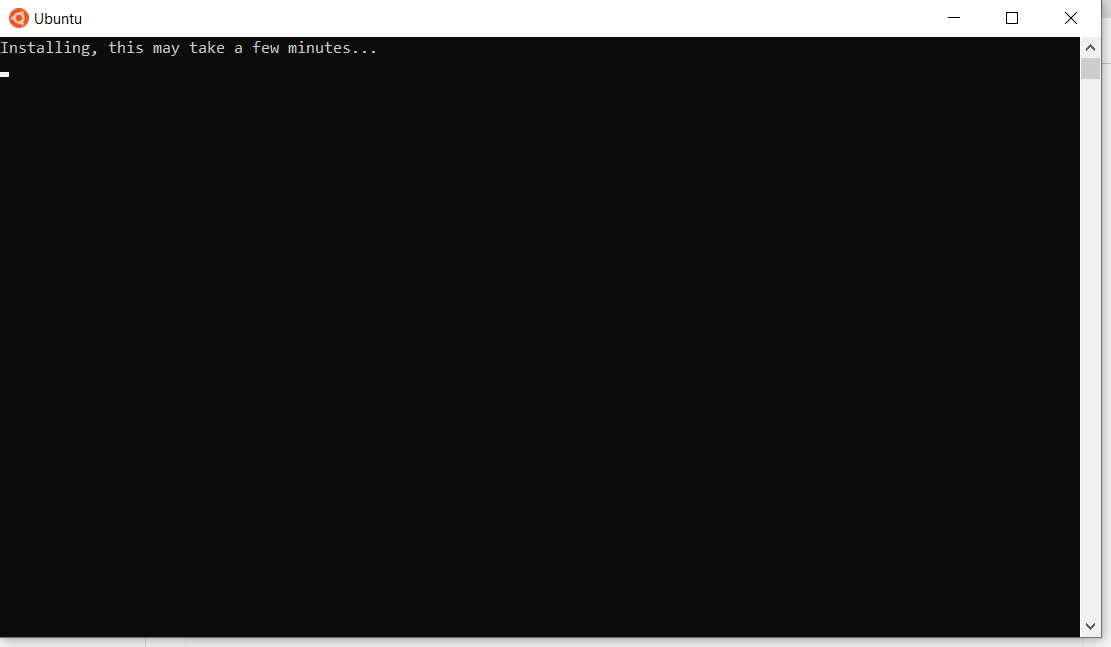
Nach Abschluss der Ubuntu-Installation werden Sie aufgefordert, Ihren Benutzernamen und Ihr Passwort einzugeben.

Und genau! Sie können Ubuntu verwenden.
Starten Sie Ubuntu über die Suchleiste im Startmenü.
Und hier haben Sie Ihre Ubuntu-Instanz gestartet.

Option 3: Verwenden Sie eine virtuelle Maschine (VM)
Eine virtuelle Maschine (VM) ist eine Software-Emulation eines physischen Computer Systems. Es ermöglicht es Ihnen, mehrere Betriebssysteme und Anwendungen gleichzeitig auf einem einzigen physischen Rechner zu betreiben.
Sie können virtuelles Software wie Oracle VirtualBox oder VMware verwenden, um eine virtuelle Maschine mit Linux innerhalb Ihrer Windows-Umgebung zu erstellen. Dies ermöglicht es Ihnen, Linux als Gastbetriebssystem neben Windows zu betreiben.
VM-Software bietet Optionen, um Hardware-Ressourcen für jede VM zu verwalten und zuzuweisen, einschließlich von CPU-Kernen, Speicher, Festplattenspeicher und Netzwerkbandbreite. Sie können diese Zuweisungen basierend auf den Anforderungen der Gastbetriebssysteme und Anwendungen anpassen.
Hier sind einige der häufig verfügbaren Optionen für Virtualisierung:
Option 4: Verwenden einer browserbasierten Lösung
Browserbasierte Lösungen sind besonders nützlich für schnelle Testungen, Lernen oder den Zugriff auf Linux-Umgebungen von Geräten, die Linux nicht installiert haben.
Sie können entweder Online-Code-Editoren oder webbasierte Terminals verwenden, um auf Linux zuzugreifen. Beachten Sie, dass Sie in solchen Fällen normalerweise keine vollen Administratorenschranken haben.
Online-Code-Editoren
Online-Code-Editoren bieten Editor mit integrierten Linux-Terminals. Obwohl ihre Hauptfunktion Codierung ist, können Sie auch das Linux-Terminal verwenden, um Befehle auszuführen und Aufgaben zu erledigen.
Replit ist ein Beispiel für ein Online-Code-Editor, wo Sie Iinen Code schreiben und gleichzeitig auf das Linux-Shell zugreifen können.
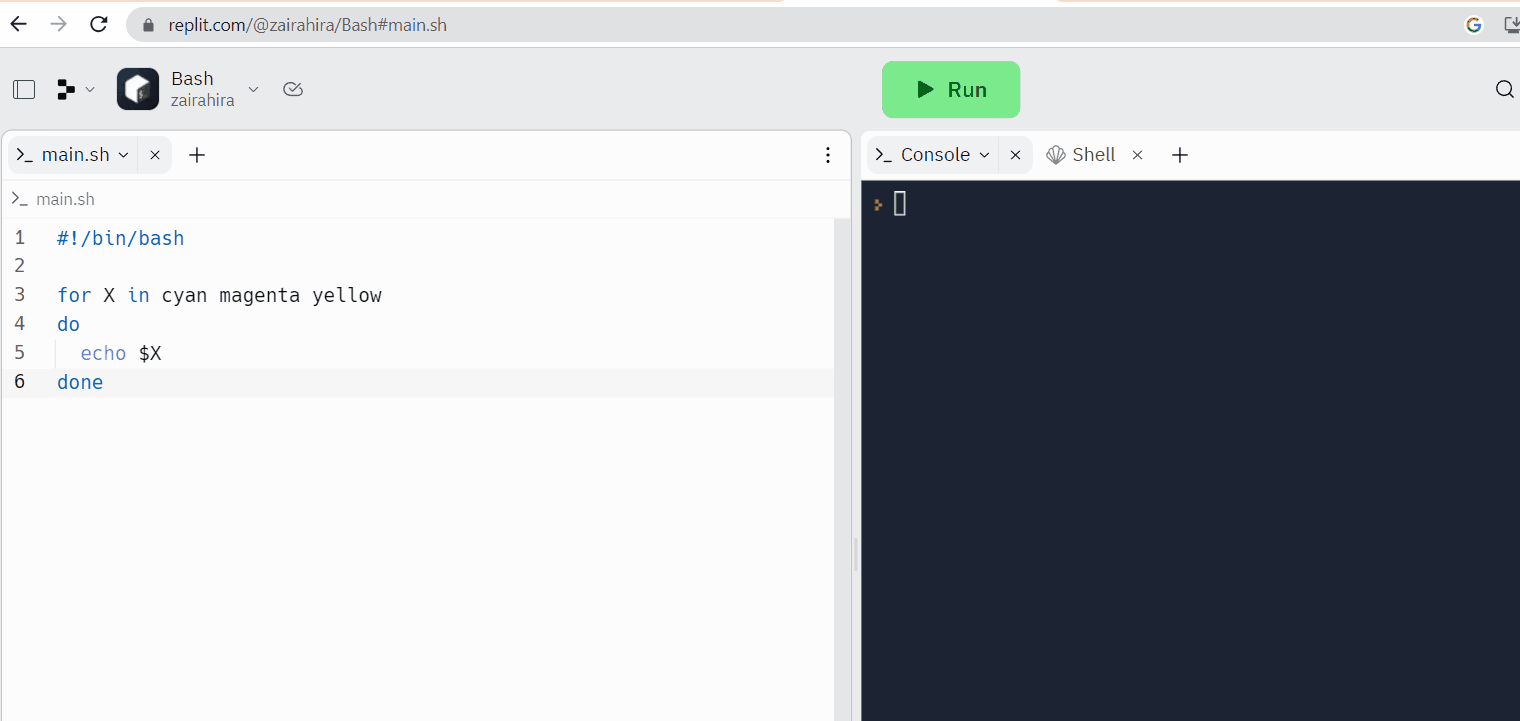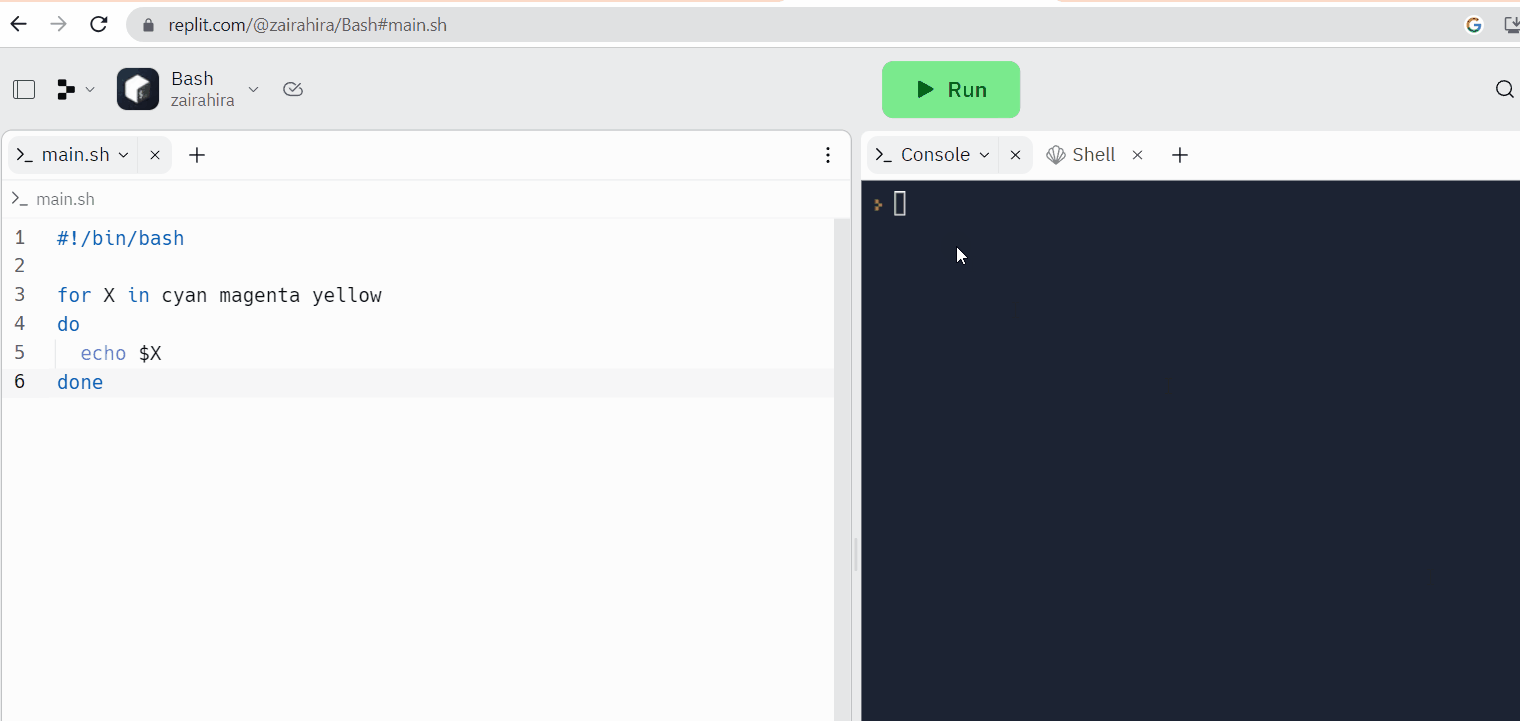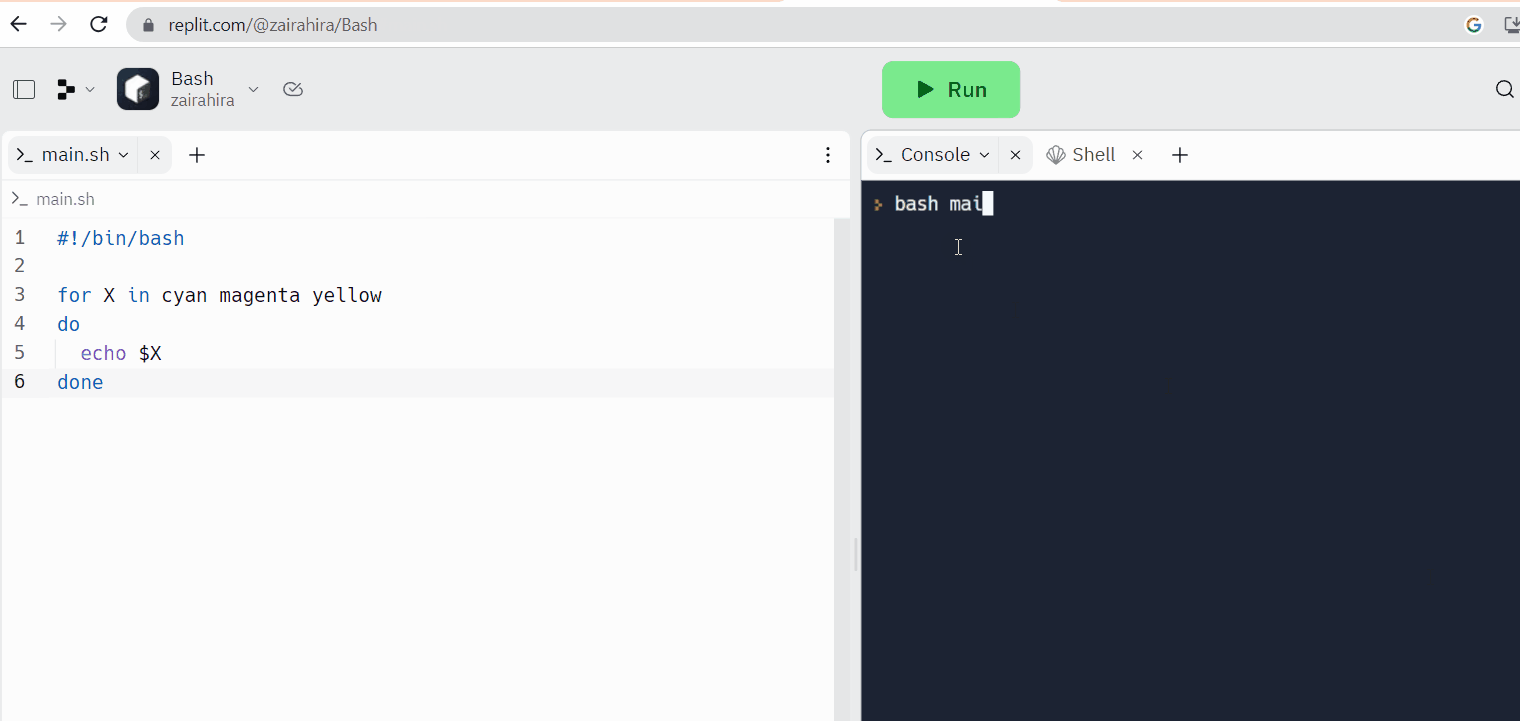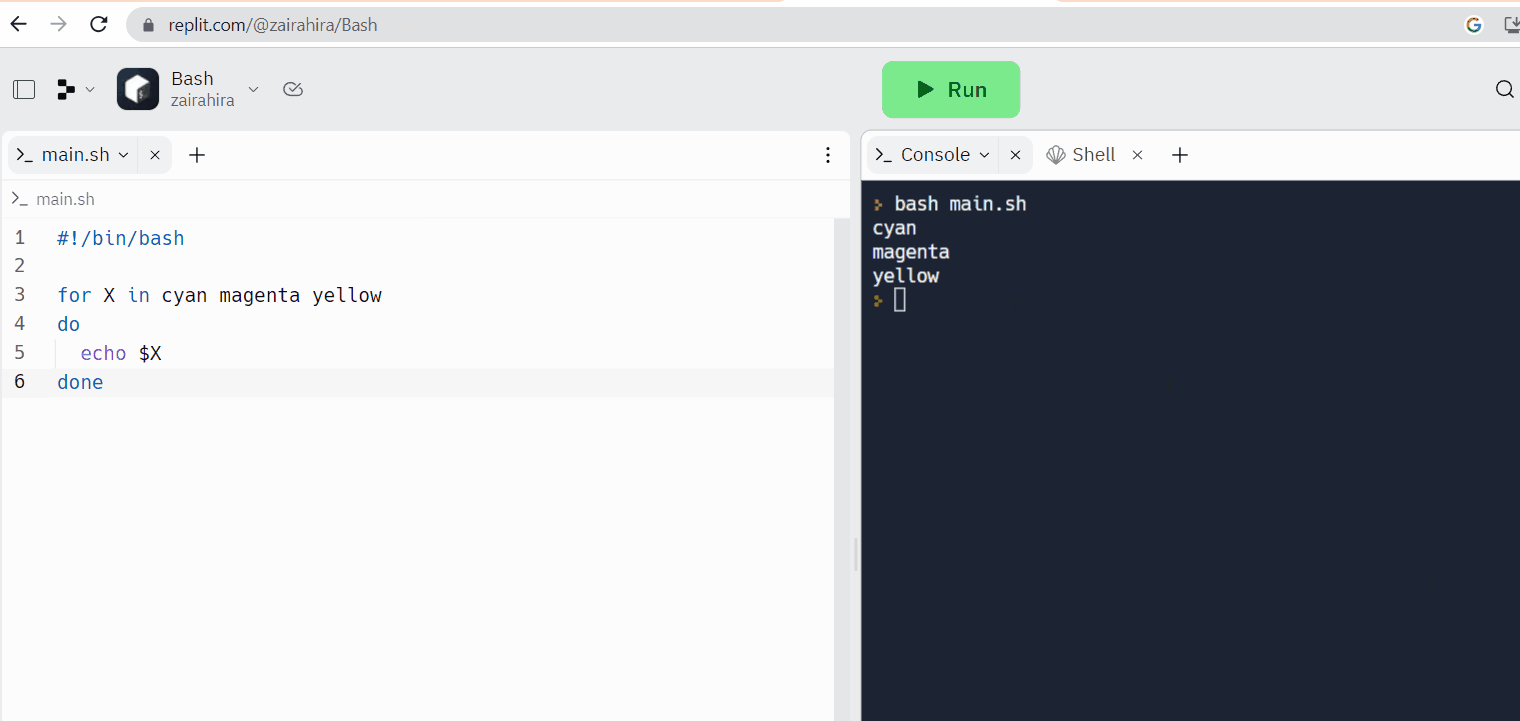
Webbasierte Linux-Terminals:
Online Linux-Terminals ermöglichen Ihnen direkt aus Ihrem Browser auf ein Linux-Kommandozeileninterface zuzugreifen. Diese Terminals bieten eine webbasierte Schnittstelle für eine Linux-Shell, die es Ihnen ermöglicht, Befehle auszuführen und mit Linux-Werkzeugen zu arbeiten.
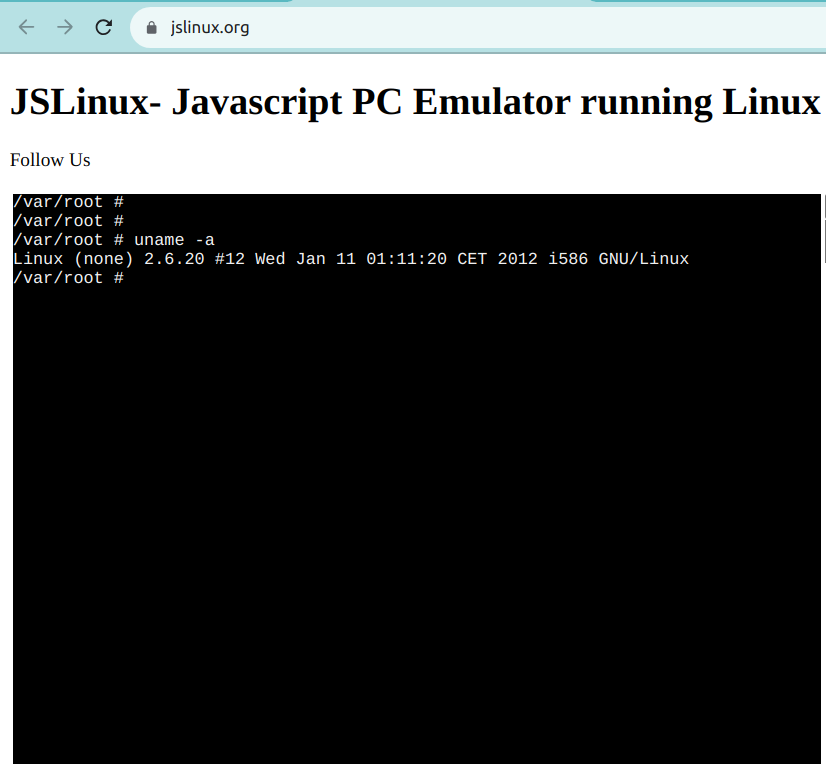
Ein solches Beispiel ist JSLinux. Die unten gezeigte Screenshot zeigt eine fertige Linux-Umgebung:
Option 5: Verwendung einer cloudbasierten Lösung
Anstatt Linux direkt auf Ihrem Windows-Rechner zu betreiben, können Sie erwägen, cloudbasierte Linux-Umgebungen oder virtuelle Private Server (VPS) zu verwenden, um远程 auf Linux zuzugreifen und zu arbeiten.
Dienste wie Amazon EC2, Microsoft Azure oder DigitalOcean stellen Ihnen Linux-Instanzen zur Verfügung, die Sie von Ihrem Windows-Computer aus verbinden können. Beachten Sie, dass einige dieser Dienste Free-Tiers anbieten, die in der langfristigen Sicht jedoch nicht kostenfrei sind.
Teil 2: Einführung in die Bash-Shell und Systembefehle
2.1. Erste Schritte mit der Bash-Shell
Einführung in die Bash-Shell
Die Linux-Kommandozeile wird durch ein Programm namens die Shell bereitgestellt. Im Verlauf der Jahre ist das Shell-Programm evolviert, um verschiedene Optionen anzubieten.
Unterschiedliche Benutzer können konfiguriert werden, um unterschiedliche Shells zu verwenden. Die meisten Benutzer jedoch bevorzugen, die aktuelle Standard-Shell beizubehalten. Die Standard-Shell für viele Linux-Distributionen ist die GNU Bourne-Again Shell (bash). Bash ist die Weiterentwicklung der Bourne-Shell (sh).
Um herauszufinden, in welcher Shell Sie sich befinden, öffnen Sie Ihren Terminal und geben Sie folgendes Kommando ein:
echo $SHELL
Kommando-Aufteilung:
-
Das
echo-Kommando wird verwendet, um auf dem Terminal zu drucken. -
Das
$SHELList eine spezielle Variable, die den Namen der aktuellen Shell aufnehmen kann.
In meiner Einstellung lautet der Ausgang /bin/bash. Dies bedeutet, dass ich die Bash-Shell verwende.
# Ausgabe
echo $SHELL
/bin/bash
Bash ist sehr leistungsfähig, da es bestimmte Operationen vereinfachen kann, die mit einer grafischen Benutzeroberfläche (GUI) effizient nicht erledigt werden können. Vergeben Sie daran, dass die meisten Server keine GUI haben und es am besten ist, die Fähigkeiten einer Kommandozeilenoberfläche (CLI) zu erlernen.
Terminal vs Shell
Die Begriffe „Terminal“ und „Shell“ werden oft synonym verwendet, verweisen jedoch auf verschiedene Teile der Kommandozeile.
Der Terminal ist die Schnittstelle, die Sie verwenden, um mit der Shell zu interagieren. Die Shell ist der Befehlsinterpreter, der Ihre Befehle verarbeitet und ausführt. Im 6. Teil des Handbuchs lernen Sie mehr über Shells.
Was ist ein Prompt?
Wenn eine Shell interaktiv verwendet wird, zeigt sie ein $ an, wenn Sie auf einen Befehl von dem Benutzer warten. Dies wird als Shell-Prompt bezeichnet.
[username@host ~]$
Wenn die Shell als root läuft (später erfahren Sie mehr über den root-Benutzer), ändert sich das Prompt in #.
[root@host ~]#
2.2. Kommandostruktur
Ein Kommando ist ein Programm, das eine bestimmte Operation durchführt. Sobald Sie Zugriff auf die Shell haben, können Sie jedes Kommando nach dem $-Zeichen eingeben und die Ausgabe am Terminal sehen.
Im Allgemeinen folgen Linux-Befehlen dieser Syntax:
command [options] [arguments]
Hier ist die Auflösung der oben genannten Syntax:
-
Befehl: Dies ist der Name des Befehls, den Sie ausführen möchten.ls(Liste),cp(Kopieren) undrm(Entfernen) sind häufige Linux-Befehle. -
[Optionen]: Optionen oder Schalter, die oft durch einen Bindestrich (-) oder doppelten Bindestrich (–) vorangestellt sind, ändern das Verhalten der Anweisung. Sie können dabei das Verhalten der Anweisung verändern. Zum Beispiel verwendet die Anweisung
ls -adie Option-a, um versteckte Dateien im aktuellen Verzeichnis anzuzeigen. -
Optionen und Argumente sind nicht für alle Befehle erforderlich. Einige Befehle können ohne Optionen oder Argumente ausgeführt werden, während andere eine oder beide benötigen, um korrekt zu funktionieren. Sie können immer auf die Handbuchseite des Befehls gehen, um die unterstützten Optionen und Argumente zu prüfen.
💡Tipp: Du kannst die Anleitung für einen Befehl mit dem Befehl man anzeigen.
Du kannst die Anleitungsseite für ls mit man ls aufrufen und sie wird so aussehen:

Anleitungsseiten sind eine großartige und schnelle Methode, um auf die Dokumentation zuzugreifen. Ich empfehle dringend, die man-Seiten der am meisten verwendeten Befehle durchzulesen.
2.3. Bash-Befehle und Tastenkürzel
Wenn du im Terminal bist, kannst du deine Aufgaben durch die Verwendung von Tastenkürzen beschleunigen.
Hier sind einige der am häufigsten verwendeten Terminal-Tastenkürzel:
| Aktion | Tastenkürzel |
| Den vorhergehenden Befehl suchen | Pfeil hoch |
| Zum Anfang des vorhergehenden Wortes springen | Strg+Pfeil links |
| Zeichen von der Cursorposition bis zum Ende der Befehlszeile löschen | Strg+K |
| Befehle, Dateinamen und Optionen abbruchslos einfüllen | Das Drücken des Tabulators |
| Zum Anfang der Befehlszeile springen | Strg+A |
| Zeigt die Liste der vorhergehenden Befehle an | history |
2.4. Selbstidentifizierung: Der Befehl whoami
Du kannst den Benutzernamen erhalten, mit dem du angemeldet bist, indem du den Befehl whoami verwendest. Dieser Befehl ist nützlich, wenn du zwischen verschiedenen Benutzern wechselst und die aktuelle Benutzerschaft bestätigen möchtest.
Unmittelbar nach dem $-Zeichen tippe whoami und drücke Enter.
whoami
Das ist die Ausgabe, die ich erhalten habe.
zaira@zaira-ThinkPad:~$ whoami
zaira
Teil 3: Verstehen Sie Ihr Linux-System
3.1. Entdecken Sie Ihre OS und Spezifikationen
Drucke Systeminformationen mit dem Befehl uname
Sie können detaillierte Systeminformationen mit dem Befehl uname erhalten.
Wenn Sie die Option -a angeben, werden alle Systeminformationen angezeigt.
uname -a
# Ausgabe
Linux zaira 6.5.0-21-generic #21~22.04.1-Ubuntu SMP PREEMPT_DYNAMIC Freitag, 9. Februar 13:32:52 UTC 2 x86_64 x86_64 x86_64 GNU/Linux
In der obenstehenden Ausgabe,
-
Linux: Zeigt das Betriebssystem an. -
zaira: steht für den Rechnernamen des Systems. -
6.5.0-21-generic #21~22.04.1-Ubuntu SMP PREEMPT_DYNAMIC Freitag, 9. Februar 13:32:52 UTC 2:提供了内核版本、编译日期以及其他一些详细信息。 -
x86_64 x86_64 x86_64: Zeigt die Architektur des Systems an. -
GNU/Linux: Steht für den Typ des Betriebssystems.
Finde Details zur CPU-Architektur mit dem lscpu-Befehl
Der lscpu-Befehl in Linux wird verwendet, um Informationen über die CPU-Architektur anzuzeigen. Wenn Sie lscpu im Terminal ausführen, erhalten Sie Details wie:
-
Die Architektur der CPU (zum Beispiel x86_64)
-
CPU-Modus/- Modi (zum Beispiel 32-bit, 64-bit)
-
Bytereihenfolge (zum Beispiel Little Endian)
-
CPU(s) (Anzahl der CPUs) usw.
Probieren wir es aus:
lscpu
# Ausgabe
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Address sizes: 48 bits physical, 48 bits virtual
Byte Order: Little Endian
CPU(s): 12
On-line CPU(s) list: 0-11
Vendor ID: AuthenticAMD
Model name: AMD Ryzen 5 5500U with Radeon Graphics
Thread(s) per core: 2
Core(s) per socket: 6
Socket(s): 1
Stepping: 1
CPU max MHz: 4056.0000
CPU min MHz: 400.0000
Das waren eine Menge Informationen, aber auch nützlich! Bedenken Sie, dass Sie immer mit bestimmten Schaltern die relevanten Informationen durchsehen können. Sehen Sie sich das Befehlshandbuch mit man lscpu an.
Teil 4: Dateien von der Kommandozeile verwalten
4.1. Die Linux-Dateisystemhierarchie
Alle Dateien in Linux sind in einem Dateisystem gespeichert. Es folgt einer umgekehrten baumartigen Struktur, weil der Ursprung oben liegt.
Das / ist das Stammverzeichnis und der Startpunkt des Dateisystems. Das Stammverzeichnis enthält alle anderen Verzeichnisse und Dateien auf dem System. Das /-Zeichen dient auch als Trennzeichen zwischen Pfadnamen. Zum Beispiel bildet /home/alice einen vollständigen Pfad.
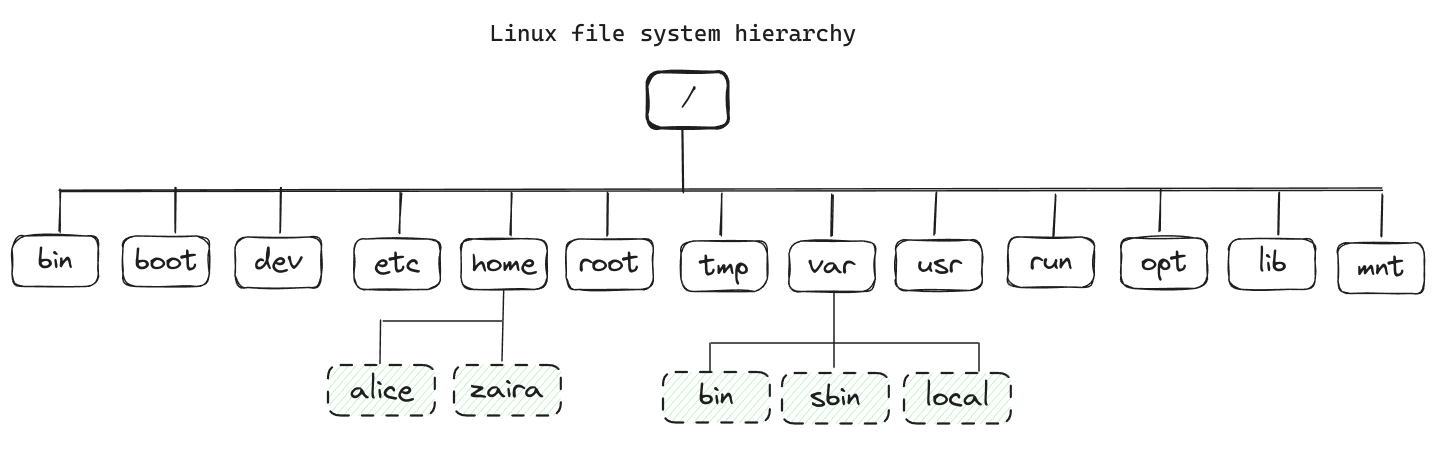
Das unten gezeigte Bild zeigt die komplette Dateisystem-Hierarchie. Jeder Verzeichnisdienstet eine bestimmte Aufgabe.
Beachten Sie, dass dies keine vollständige Liste ist und verschiedene Distributionen unterschiedliche Konfigurationen haben können.
Hier ist eine Tabelle, die die Aufgabe jedes Verzeichnisses aufzeigt:
| Ort | Aufgabe |
| /bin | Wichtige Befehlsbinärdateien |
| /boot | Statische Dateien des Bootloaders, die zum Start des Bootvorganges notwendig sind. |
| /etc | Hostspezifische Systemkonfiguration |
| /home | Benutzerhomeverzeichnisse |
| /root | Homeverzeichnis für den administrativen root-Benutzer |
| /lib | Wichtige gemeinsam genutzte Bibliotheken und Kernelmodule |
| /mnt | Mountpunkt für die vorübergehende Mount-Operation eines Dateisystems |
| /opt | Add-on-Anwendungssoftwarepakete |
| /usr | Installierte Software und gemeinsam genutzte Bibliotheken |
| /var | Variablen Daten, die auch zwischen den Bootvorgängen persistent sind |
| /tmp | Temporäre Dateien, die allen Benutzern zugänglich sind |
💡 Tipp: Sie können mehr über das Dateisystem mit dem Befehl man hier erfahren.
Sie können Ihr Dateisystem mit dem Befehl tree -d -L 1 überprüfen. Sie können den -L-Schalter verändern, um die Tiefe des Baums zu ändern.
tree -d -L 1
# Ausgabe
.
├── bin -> usr/bin
├── boot
├── cdrom
├── data
├── dev
├── etc
├── home
├── lib -> usr/lib
├── lib32 -> usr/lib32
├── lib64 -> usr/lib64
├── libx32 -> usr/libx32
├── lost+found
├── media
├── mnt
├── opt
├── proc
├── root
├── run
├── sbin -> usr/sbin
├── snap
├── srv
├── sys
├── tmp
├── usr
└── var
25 directories
Diese Liste ist nicht exakt und verschiedene Distributionen und Systeme könnten anders konfiguriert sein.
4.2 Navigation im Linux-Dateisystem
Absoluter Pfad vs relativer Pfad
Der absolute Pfad ist der vollständige Pfad vom Wurzelverzeichnis bis zur Datei oder dem Verzeichnis. Er beginnt immer mit einem /. Zum Beispiel /home/john/documents.
Der relative Pfad dagegen ist der Pfad von dem aktuellen Verzeichnis bis zur Zieldatei oder -verzeichnis. Er beginnt nicht mit einem /. Zum Beispiel documents/work/project.
Ausgeben des aktuellen Verzeichnisses mithilfe des pwd-Befehls
Es ist leicht, sich im Linux-Dateisystem zu verirren, insbesondere wenn man sich neu mit der Befehlszeile beschäftigt. Man kann das aktuelle Verzeichnis mithilfe des pwd-Befehls finden.
Hier ein Beispiel:
pwd
# Ausgabe
/home/zaira/scripts/python/free-mem.py
Wechseln des Verzeichnisses mit dem cd-Befehl
Der Befehl zum Wechseln von Verzeichnissen heißt cd und steht für „change directory“ (Verzeichnis ändern). Man kann den cd-Befehl verwenden, um zu einem anderen Verzeichnis zu navigieren.
Man kann einen relativen Pfad oder einen absoluten Pfad verwenden.
Zum Beispiel, wenn man die folgende Dateistruktur navigieren möchte (folgt den roten Linien):
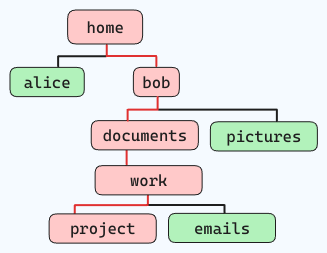
und man steht bei „home“, würde der Befehl so aussehen:
cd home/bob/documents/work/project
Einige andere häufig verwendete cd-Kürzel sind:
| Befehl | Beschreibung |
cd .. |
Zurück zu einem Verzeichnis |
cd ../.. |
Zwei Verzeichnisse zurückgehen |
cd oder cd ~ |
Zu dem Home-Verzeichnis gehen |
cd - |
Zum vorherigen Pfad gehen |
4.3. Verzeichnisse und Dateien verwalten
Beim Arbeiten mit Verzeichnissen und Dateien möchte man gelegentlich kopieren, verschieben, löschen und neue Dateien und Verzeichnisse erstellen. Hier sind einige Befehle, die Ihnen dabei helfen.
💡Tip: Man kann zwischen einer Datei und einem Ordner unterscheiden, indem man auf die erste Zeile in der Ausgabe von ls -l achten. Ein'-' steht für eine Datei und ein 'd' steht für ein Verzeichnis.
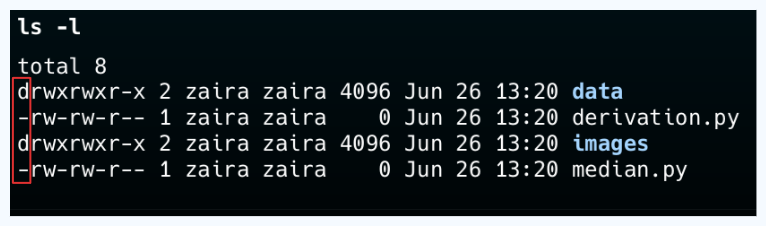
Erstellen von neuen Verzeichnissen mit dem Befehl mkdir
Mit dem Befehl mkdir kann man ein leeres Verzeichnis erstellen.
# erstellt ein leeres Verzeichnis namens "foo" im aktuellen Verzeichnis
mkdir foo
Sie können auch rekursiv Verzeichnisse mit der Option -p erstellen.
mkdir -p tools/index/helper-scripts
# Ausgabe von tree
.
└── tools
└── index
└── helper-scripts
3 directories, 0 files
Erstellen von neuen Dateien mit dem Befehl touch
Der Befehl touch erstellt eine leere Datei. Sie können ihn verwenden, wie folgt:
# erstellt leere Datei "file.txt" im aktuellen Verzeichnis
touch file.txt
Dateinamen können zusammengebunden werden, wenn Sie mehrere Dateien gleichzeitig in einem Befehl erstellen möchten.
# erstellt leere Dateien "file1.txt", "file2.txt" und "file3.txt" im aktuellen Ordner
touch file1.txt file2.txt file3.txt
Dateien und Ordner mit den Befehlen rm und rmdir entfernen
Sie können den Befehl rm verwenden, um sowohl Dateien als auch leere Ordner zu entfernen.
| Befehl | Beschreibung |
rm file.txt |
Entfernt die Datei file.txt |
rm -r directory |
Entfernt den Ordner directory und seinen Inhalt |
rm -f file.txt |
Entfernt die Datei file.txt ohne Bestätigung zu verlangen |
rmdir directory |
Entfernt einen leeren Ordner |
🛑 Beachten Sie, dass Sie die -f Flag mit Vorsicht verwenden sollten, da Sie nicht gefragt werden, bevor eine Datei gelöscht wird. Auch sollten Sie Vorsicht walten, wenn Sie rm Befehle im root Ordner ausführen, da dies zu Löschung wichtiger Systemdateien führen kann.
Dateien mit dem Befehl cp kopieren
Um Dateien in Linux zu kopieren, verwenden Sie den Befehl cp.
- Syntax zur Kopie von Dateien:
cp source_file destination_of_file
Dieser Befehl kopiert eine Datei namens file1.txt an eine neue Dateilocation /home/adam/logs.
cp file1.txt /home/adam/logs
Der Befehl cp erstellt auch eine Kopie einer Datei mit der angegebenen Bezeichnung.
Dieser Befehl kopiert eine Datei namens file1.txt in einen anderen Datei namens file2.txt im selben Verzeichnis.
cp file1.txt file2.txt
Dateien und Ordner verschieben und umbenennen mit dem Befehl mv
Der Befehl mv wird verwendet, um Dateien und Ordner von einem Verzeichnis in ein anderes zu verschieben.
Syntax zur Verschiebung von Dateien:mv source_file destination_directory
Beispiel: Verschiebe eine Datei namens file1.txt in ein Verzeichnis namens backup:
mv file1.txt backup/
Zum Verschieben eines Ordners und seines Inhalts:
mv dir1/ backup/
Dateien und Ordner in Linux können auch mit dem Befehl mv umbenannt werden.
Syntax zur Umbenennung von Dateien:mv alten_namen neuen_namen
Beispiel: Umbenenne eine Datei von file1.txt in file2.txt:
mv file1.txt file2.txt
Umbenenne ein Verzeichnis von dir1 in dir2:
mv dir1 dir2
4.4. Dateien und Ordner mit dem Befehl find suchen
Der Befehl find ermöglicht es Ihnen effizient nach Dateien, Ordnern und Zeichen- und Blockgeräten zu suchen.
Nachstehend ist die grundlegende Syntax des Befehls find:
find /path/ -type f -name file-to-search
Wobei,
-
/pathder Pfad ist, in dem die Datei erwartet wird gefunden zu werden. Dies ist der Startpunkt für die Suche nach Dateien. Der Pfad kann auch/oder.sein, was das Wurzelverzeichnis bzw. das aktuelle Verzeichnis repräsentiert. -
-typesteht für die Dateibeschreibungen. Sie können entweder von den folgenden Werten sein:
f– Reguläre Datei, wie Textdateien, Bilder und versteckte Dateien.
d– Verzeichnis. Diese sind die betrachteten Ordner.
l– Symbolischer Link. Symbolische Links zeigen auf Dateien und sind ähnlich wie Verknüpfungen.
c– Zeichengenossenschaft. Dateien, die zur Zugriff auf Zeichengenossenschaften verwendet werden, heißen Zeichengenossenschaftsdateien. Treiber kommunizieren mit Zeichengenossenschaften durch das Senden und Empfangen von einzelnen Zeichen (Byte, Oktette). Beispiele hierfür sind Tastaturen, Soundkarten und die Maus.
b– Blöckeinheit. Dateien, die zur Zugriff auf Blöckeinheiten verwendet werden, heißen Block Einheitsdateien. Treiber kommunizieren mit Blöckeinheiten durch das Senden und Empfangen von ganzen Datenblöcken. Beispiele hierfür sind USB-Geräte und CD-ROM-Laufwerke. -
-nameist der Name des Dateityps, den du suchen willst.
Wie man Dateien nach Name oder Erweiterung durchsucht
Stellen wir uns vor, wir müssen Dateien finden, die den Namen „style“ enthalten. Wir werden diesen Befehl verwenden:
find . -type f -name "style*"
#Ausgabe
./style.css
./styles.css
Nun sagen wir, wir möchten Dateien mit einer bestimmten Erweiterung wie .html finden. Wir ändern den Befehl wie folgt:
find . -type f -name "*.html"
#Ausgabe
./services.html
./blob.html
./index.html
Wie man versteckte Dateien durchsucht
Ein Punkt am Anfang des Dateinamens bedeutet versteckte Dateien. Normalerweise sind sie versteckt, können aber mit ls -a im aktuellen Verzeichnis angezeigt werden.
Wir können den find-Befehl wie unten gezeigt ändern, um nach versteckten Dateien zu suchen:
find . -type f -name ".*"
Liste und suche versteckte Dateien
ls -la
# Verzeichnisinhalt
total 5
drwxrwxr-x 2 zaira zaira 4096 Mar 26 14:17 .
drwxr-x--- 61 zaira zaira 4096 Mar 26 14:12 ..
-rw-rw-r-- 1 zaira zaira 0 Mar 26 14:17 .bash_history
-rw-rw-r-- 1 zaira zaira 0 Mar 26 14:17 .bash_logout
-rw-rw-r-- 1 zaira zaira 0 Mar 26 14:17 .bashrc
find . -type f -name ".*"
# find-Ausgabe
./.bash_logout
./.bashrc
./.bash_history
Oben sehen Sie eine Liste von versteckten Dateien in meinem Home-Verzeichnis.
Wie man Logdateien und Konfigurationsdateien durchsucht
Logdateien haben normalerweise die Extension .log und können wie folgt gefunden werden:
find . -type f -name "*.log"
Ähnlich können Sie Suchdateien wie folgt finden:
find . -type f -name "*.conf"
Wie man andere Dateitypen durchsucht
Wir können Dateien mit Zeichenblock-Dateityp durch Angabe von c zum -type-Parameter suchen:
find / -type c
Ähnlich können Sie Gerätedateien finden, indem Sie b verwenden:
find / -type b
Wie man Verzeichnisse durchsucht
In dem unteren Beispiel suchen wir Verzeichnisse mit dem -type d-Flag.
ls -l
# Liste Verzeichnisinhalt
drwxrwxr-x 2 zaira zaira 4096 Mar 26 14:22 hosts
-rw-rw-r-- 1 zaira zaira 0 Mar 26 14:23 hosts.txt
drwxrwxr-x 2 zaira zaira 4096 Mar 26 14:22 images
drwxrwxr-x 2 zaira zaira 4096 Mar 26 14:23 style
drwxrwxr-x 2 zaira zaira 4096 Mar 26 14:22 webp
find . -type d
# find Verzeichnisausgabe
.
./webp
./images
./style
./hosts
Wie man Dateien nach Größe durchsucht
Eine unglaublich hilfreiche Anwendung des find-Befehls ist die Liste von Dateien basierend auf einer bestimmten Größe.
find / -size +250M
Hier ist eine Liste von Dateien mit einer Größe von mehr als 250MB.
Andere Einheiten beinhalten:
-
G: GigaBytes. -
M: MegaBytes. -
K: KiloBytes -
c: bytes.
Nur Ersetzen Sie mit der jeweiligen Einheit.
find <directory> -type f -size +N<Unit Type>
Wie man Dateien nach der Änderungszeit durchsucht
Durch Verwendung des -mtime-Flags können Sie Dateien und Ordner aufgrund der Änderungszeit filtern.
find /path -name "*.txt" -mtime -10
Zum Beispiel,
-
-mtime +10 bedeutet, dass Sie eine 10 Tage alt geänderte Datei suchen.
-
-mtime -10 bedeutet weniger als 10 Tage.
-
-mtime 10 Wenn Sie + oder – auslassen, bedeutet das exakt 10 Tage.
4.5. Grundlegende Befehle zur Anzeige von Dateien
Verbinden und anzeigen von Dateien mit dem Befehl cat
Der Befehl cat in Linux wird verwendet, um den Inhalt einer Datei anzuzeigen. Er kann auch zur Verbindung von Dateien und zum Erstellen neuer Dateien verwendet werden.
Hier ist die grundlegende Syntax des Befehls cat:
cat [options] [file]
Der einfachste Weg, um cat zu verwenden, ist ohne Optionen oder Argumente. Dies wird den Inhalt der Datei im Terminal anzeigen.
Zum Beispiel, wenn Sie den Inhalt einer Datei namens file.txt anzeigen möchten, können Sie den folgenden Befehl verwenden:
cat file.txt
Dies zeigt den gesamten Inhalt der Datei auf einmal im Terminal an.
Textdateien interaktiv mit less und more ansehen
Während cat die gesamte Datei auf einmal anzeigt, ermöglichen less und more eine interaktive Ansicht des Dateiinhalts. Dies ist nützlich, wenn Sie durch eine große Datei blättern oder nach bestimmten Inhalten suchen möchten.
Die Syntax des less-Befehls ist:
less [options] [file]
Der more-Befehl ist ähnlich wie less, hat jedoch weniger Funktionen. Er wird verwendet, um den Inhalt einer Datei bildschirmweise anzuzeigen.
Die Syntax des more-Befehls ist:
more [options] [file]
Für beide Befehle können Sie die Leertaste verwenden, um eine Seite nach unten zu scrollen, die Enter-Taste, um eine Zeile nach unten zu scrollen, und die q-Taste, um den Viewer zu beenden.
Um rückwärts zu blättern, können Sie die b-Taste verwenden, und um vorwärts zu blättern, die f-Taste.
Den letzten Teil von Dateien mit tail anzeigen
Manchmal möchten Sie nur die letzten Zeilen einer Datei anstatt der gesamten Datei ansehen. Der tail-Befehl in Linux wird verwendet, um den letzten Teil einer Datei anzuzeigen.
Zum Beispiel zeigt tail file.txt standardmäßig die letzten 10 Zeilen der Datei file.txt an.
Wenn du eine andere Anzahl an Zeilen anzeigen willst, kannst du die Option -n verwenden, gefolgt von der Anzahl der zu anzeigenden Zeilen.
# Zeige die letzten 50 Zeilen des Dateis file.txt an
tail -n 50 file.txt
💡Tipp: Eine weitere Verwendung der tail-Option ist ihre Follow-Along-Funktion (-f). Diese Option ermöglicht es dir, den Inhalt einer Datei während der Schreibung anzuzeigen. Dies ist eine nützliche Werkzeug, um Logdateien in Echtzeit anzuzeigen und zu verfolgen.
Anzeigen des Anfangs von Dateien mit head
Genau wie tail den letzten Teil einer Datei anzeigt, kannst du das head-Kommando in Linux verwenden, um den Anfang einer Datei anzuzeigen.
Zum Beispiel wird head file.txt standardmäßig die ersten 10 Zeilen der Datei file.txt anzeigen.
Um die Anzahl der anzuzeigenden Zeilen zu ändern, kannst du die Option -n verwenden, gefolgt von der Anzahl der Zeilen, die du anzeigen möchtest.
Zählen von Wörtern, Zeilen und Zeichen mit wc
Du kannst mit dem wc-Kommando Wörter, Zeilen und Zeichen in einer Datei zählen.
Zum Beispiel erhielt ich die folgende Ausgabe, wenn ich wc syslog.log ausführte:
1669 9623 64367 syslog.log
In der obenstehenden Ausgabe,
-
1669steht für die Anzahl der Zeilen in der Dateisyslog.log. -
9623steht für die Anzahl der Wörter in der Dateisyslog.log. -
64367steht für die Anzahl der Zeichen im Dateisyslog.log.
Also, der Befehl wc syslog.log zählte 1669 Zeilen, 9623 Wörter und 64367 Zeichen im Datei syslog.log.
Dateien Zeile für Zeile vergleichen mit diff
Den Unterschiede zwischen zwei Dateien nach Zeile zu Zeile zu suchen ist eine häufige Aufgabe in Linux. Sie können zwei Dateien direkt auf der Kommandozeile mit dem Befehl diff vergleichen.
Die grundlegende Syntax des diff-Befehls lautet:
diff [options] file1 file2
Hier sind zwei Dateien, hello.py und also-hello.py, die wir mit dem diff-Befehl vergleichen werden:
# Inhalt von hello.py
def greet(name):
return f"Hello, {name}!"
user = input("Enter your name: ")
print(greet(user))
# Inhalt von also-hello.py
more also-hello.py
def greet(name):
return fHello, {name}!
user = input(Enter your name: )
print(greet(user))
print("Nice to meet you")
- Prüfen, ob die Dateien gleich sind oder nicht
diff -q hello.py also-hello.py
# Ausgabe
Files hello.py and also-hello.py differ
- Sie sehen, wie die Dateien unterschiedlich sind. Um das zu sehen, können Sie das
-u-Flag verwenden, um eine vereinfachte Ausgabe zu erhalten:
diff -u hello.py also-hello.py
--- hello.py 2024-05-24 18:31:29.891690478 +0500
+++ also-hello.py 2024-05-24 18:32:17.207921795 +0500
@@ -3,4 +3,5 @@
user = input(Enter your name: )
print(greet(user))
+print("Nice to meet you")
— hello.py 2024-05-24 18:31:29.891690478 +0500
- Im obigen Ausgabestream:
--- hello.py 2024-05-24 18:31:29.891690478 +0500zeigt an, dass es sich um die zu vergleichende Datei und deren Zeitstempel handelt.+++ also-hello.py 2024-05-24 18:32:17.207921795 +0500zeigt an, dass es sich um die andere zu vergleichende Datei und deren Zeitstempel handelt.@@ -3,4 +3,5 @@zeigt die Zeilennummern an, an denen die Änderungen stattfinden. In diesem Fall zeigt es darauf hin, dass Zeilen 3 bis 4 in der Originaldatei auf Zeilen 3 bis 5 in der geänderten Datei geändert wurden.user = input(Enter your name: )ist eine Zeile aus der Originaldatei.print(greet(user))ist eine weitere Zeile aus der Originaldatei.
+print("Nice to meet you")ist die zusätzliche Zeile in der geänderten Datei.
diff -y hello.py also-hello.py
Um das Diff-Ergebnis in einem side-by-side-Format anzuzeigen, kannst du die -y Flaggen verwenden:
def greet(name): def greet(name):
return fHello, {name}! return fHello, {name}!
user = input(Enter your name: ) user = input(Enter your name: )
print(greet(user)) print(greet(user))
> print("Nice to meet you")
# Ausgabe
- In der Ausgabe:
- Die in beiden Dateien gleichen Zeilen werden nebeneinander angezeigt.
Unterschiedliche Zeilen werden mit einem Symbol > angezeigt, das anzeigt, dass die Zeile nur in einer der Dateien vorhanden ist.
Teil 5: Die Grundlagen des Textbearbeitens in Linux
Textbearbeitungskompetenzen mittels Befehlszeile sind eine der wichtigsten Fähigkeiten in Linux. In diesem Abschnitt lernst du, wie du zwei populäre Texteditor in Linux verwendest: Vim und Nano.
Ich empfehle dir, dass du eine Texteditor von deiner Wahl beherrsche und daran festhalten. Es wird dich Zeit sparen und dich produktiver machen. Vim und Nano sind sichere Wahl, da sie auf den meisten Linux-Distributionen enthalten sind.
5.1. Vim beherrschen: Der komplette Leitfaden
Einführung in Vim
- Vim ist ein populärer Textbearbeitungswerkzeug für die Befehlszeile. Vim hat seine Vorteile: Es ist kraftvoll, anpassbar und schnell. Hier sind einige Gründe, warum du Vim lernen solltest:
- Die meisten Server werden über eine CLI bedient, sodass du in der Systemadministration immer die Gunst einer GUI nicht hast. Aber Vim hast du auf deiner Seite – es wird immer da sein.
- Vim verwendet einen konzentrierten Keyboard- Ansatz, da es zu verwendend entwickelt wurde, ohne Maus, was die Bearbeitung von Bearbeitungstasks erheblich beschleunigen kann, sobald Sie die Tastenkürzel gelernt haben. Dies macht es auch schneller als GUI-Werkzeuge.
- Einige Linux-Werkzeuge, z.B. die Bearbeitung von Cron-Jobs, arbeiten mit demselben Bearbeitungsformat wie Vim.
Vim ist sowohl für Anfänger als auch für fortgeschrittene Benutzer geeignet. Vim unterstützt komplexe Zeichenketten suchen, Suchen mit Hervorhebung und vieles mehr. Durch Plugins bietet Vim erweiterte Fähigkeiten für Entwickler und Systemadministratoren an, die u.a. Code-Vervollständigung, Syntaxhervorhebung, Dateiverwaltung, Versionskontrolle und mehr beinhalten.
Vim gibt es in zwei Varianten: Vim (vim) und Vim tiny (vi). Vim tiny ist eine kleinere Version von Vim, die einige Features von Vim fehlt.
Wie beginnen Sie mit der Verwendung von vim
vim your-file.txt
Beginnen Sie mit der Verwendung von Vim mit diesem Befehl:
your-file.txt kann entweder eine neue Datei oder eine bestehende Datei sein, die Sie bearbeiten möchten.
Navigieren in Vim: Die Meisterung von Bewegungs- und Befehlsmodi
In den Anfängen der CLI gab es keine Pfeiltasten am Keyboard. Daher wurde die Navigation mittels der verfügbaren Tasten durchgeführt, unter anderem mit hjkl.
Da Vim auf das Keyboard zentriert ist, kann die Nutzung von hjkl-Tasten die Textbearbeitung erheblich beschleunigen.
Hinweis: Obwohl die Pfeiltasten völlig ausreichend funktionieren, können Sie sich trotzdem an die Nutzung von hjkl-Tasten für die Navigation versuchen. Einige Menschen finden diesen Navigationsweg effizient.

💡Tip: Um sich die hjkl-Reihenfolge zu merken, verwenden Sie diesen Trick: hängt links, jumpt runter, kickt hoch, legt vorwärts.
Die drei Vim-Modi
- Sie sollten die drei Betriebsmodi von Vim kennen und wissen, wie Sie zwischen ihnen wechseln können. Tastenanschläge verhalten sich in jedem Befehlsmodus unterschiedlich. Die drei Modi sind wie folgt:
- Befehlsmodus.
- Bearbeitungsmodus.
Visueller Modus.
Befehlsmodus. Wenn Sie Vim starten, befinden Sie sich standardmäßig im Befehlsmodus. In diesem Modus können Sie auf andere Modi zugreifen.
⚠ Um zu anderen Modi zu wechseln, müssen Sie zunächst im Befehlsmodus sein
Bearbeitungsmodus
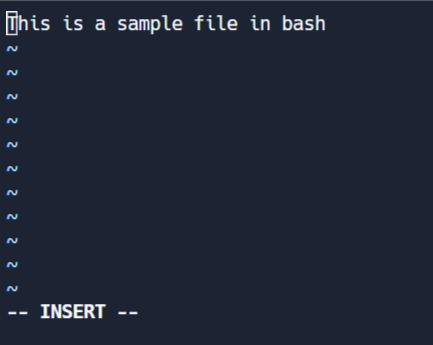
Dieser Modus ermöglicht es Ihnen, Änderungen an der Datei vorzunehmen. Um in den Bearbeitungsmodus zu gelangen, drücken Sie I, während Sie sich im Befehlsmodus befinden. Beachten Sie das '-- EINFÜGEN' am Ende des Bildschirms.
Visualmodus
- In diesem Modus kannst du auf einem einzigen Zeichen, einem Textblock oder Textzeilen arbeiten. Lass uns dies in einfache Schritte aufbrechen. Denken Sie daran, die untenstehenden Kombinationen während des Befehlsmodus zu verwenden.
Umschalt + V→ Mehrere Zeilen auswählen.Strg + V→ Blockmodus
V → Zeichenmodus
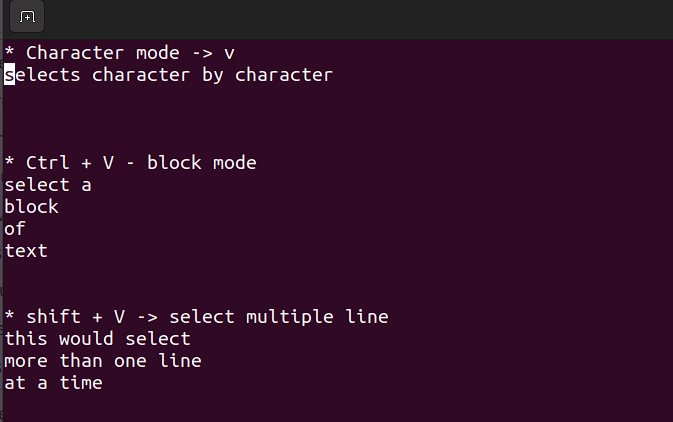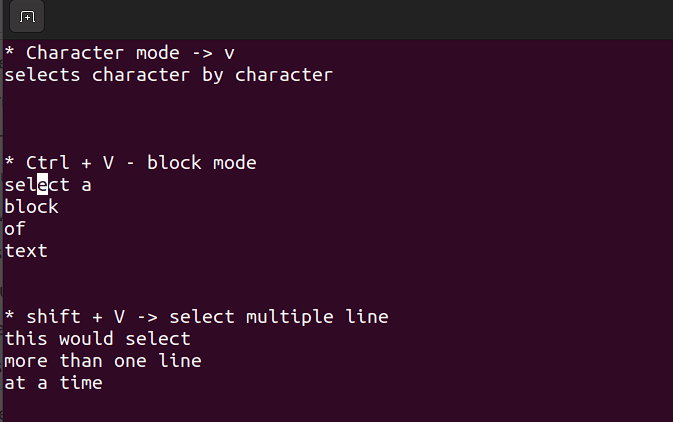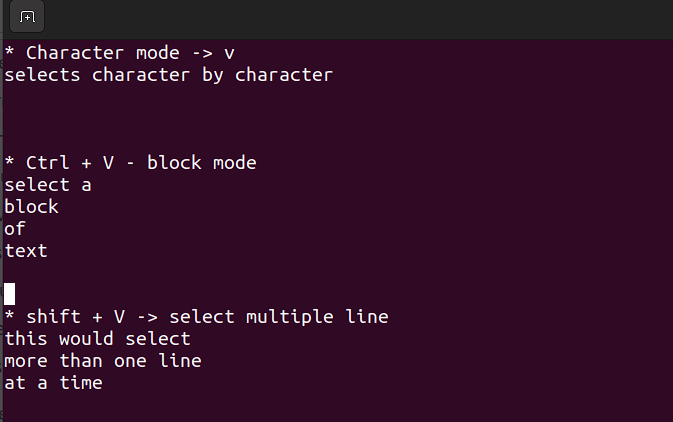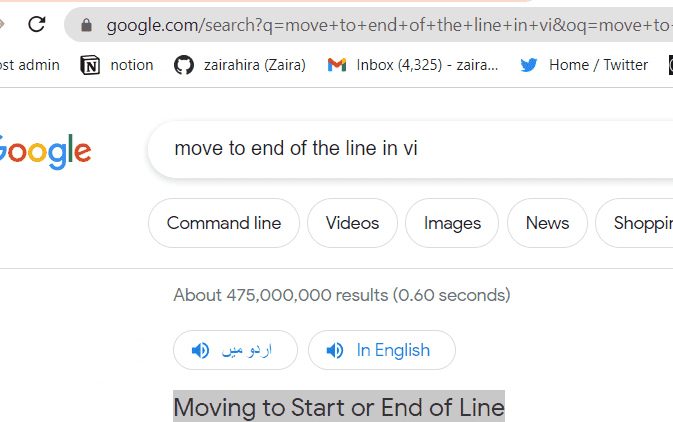
Der Visualmodus ist nützlich, wenn du kopieren, einfügen oder massenweise Bearbeiten von Zeilen benötigst.
Erweiterter Befehlsmodus.
Der erweiterte Befehlsmodus ermöglicht die Durchführung avancierter Operationen wie Suchen, Setzen von Zeilennummern und Hervorheben von Text. Wir behandeln den erweiterten Modus in der nächsten Abschnitt.
Wie bleibst du auf dem neuesten Stand? Wenn du dein aktuelles Modus vergisst, drück‘ ESC zweimal und du befindest dich wieder im Befehlsmodus.
Effiziente Bearbeitung in Vim: Kopieren, Einfügen und Suchen
1. Wie man in Vim kopiert und einfügt
- Kopieren und Einfügen heißt in Linux-Begriffen ‚yanken‘ und ‚putten‘. Um zu kopieren und einzufügen, folgen Sie diesen Schritten:
- Wählen Sie Text im Visualmodus aus.
- Drücken Sie
'y', um zu kopieren/auszuklinken.
Move your cursor to the required position and press 'p'.
2. Wie man Text in Vim sucht
Man kann jede Reihe von Zeichen in Vim mit dem /-Befehl im Kommandomodus suchen. Zum Suchen nutze /zu SUCHENDER Text.
Gehe im Kommandomodus ein und gib :set hls ein und drücke Enter. Nutze dann /zu SUCHENDER Text. Dadurch werden die Suchergebnisse hervorgehoben.
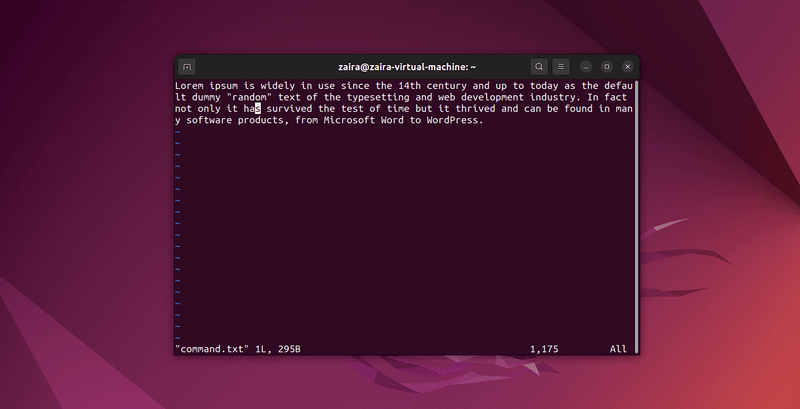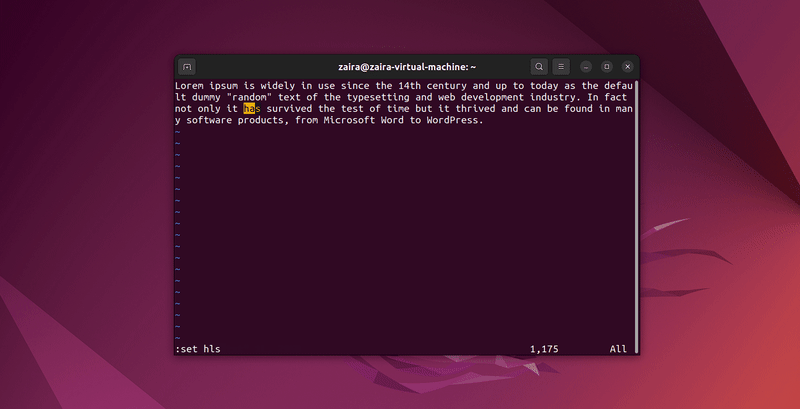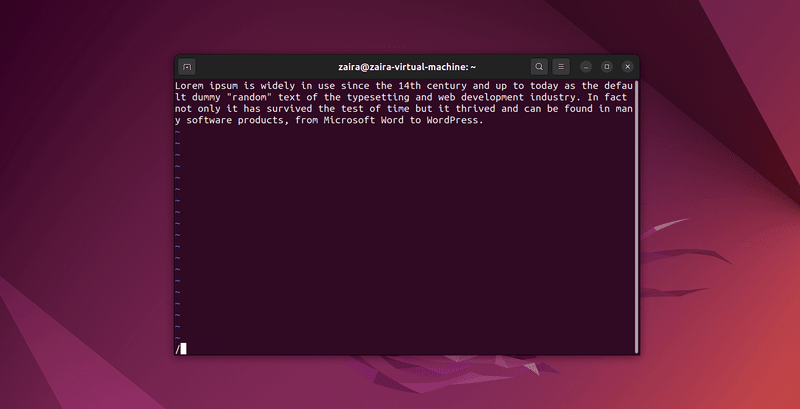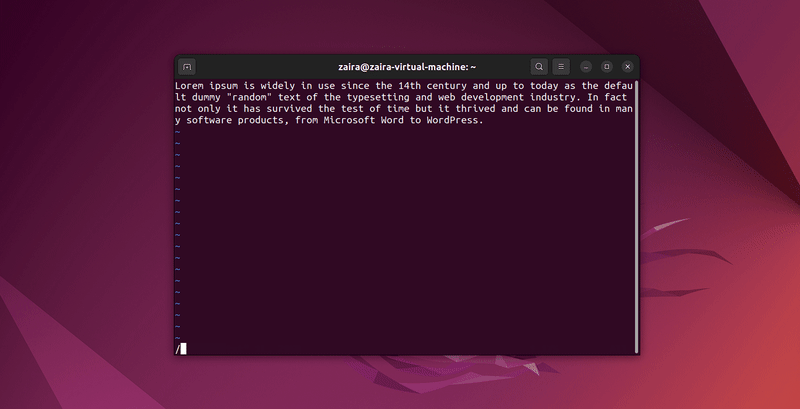
Lass uns einige Zeichenketten suchen:
3. Wie man Vim beendet
- Zuerst gehe in den Kommandomodus (durch zweimaliges Drücken der Escape-Taste) und nutze dann folgende Befehle:
- Beenden ohne zu speichern →
:q!
Beenden und speichern → :wq!
Tastenkürzel in Vim: Editieren schneller machen
- Hinweis: Alle diese Tastenkürzel funktionieren nur im Kommandomodus.
Ctrl+u: Halbseite hoch bewegenP: Den ziehenden Text oberhalb des Cursors platzieren:%s/old/new/g: Ersetze alle Vorkommnisse vonoldmitnewim Datei:q!: Ohne Speichern beenden
Strg+w gefolgt von h/j/k/l: Zwischen geteilten Fenstern navigieren
5.2. Nano masterieren
Erste Schritte mit Nano: Der userfreundliche Texteditor
Nano ist ein userfreundlicher Texteditor, der leicht zu verwenden ist und perfekt für Anfänger geeignet ist. Er ist auf den meisten Linux-Distributionen vorinstalliert.
nano
Um mit Nano ein neues Datei zu erstellen, verwendest du folgenden Befehl:
nano filename
Um mit Nano ein existierendes Datei zu bearbeiten, verwendest du folgenden Befehl:
Liste der Tastenkürzel in Nano
Lerne die wichtigsten Tastenkürzel in Nano kennen. Du verwendest die Tastenkürzel, um verschiedene Operationen wie Speichern, Beenden, Kopieren, Einfügen und mehr durchzuführen.
In eine Datei schreiben und speichern
Wenn Sie Nano mit dem Befehl nano öffnen, können Sie mit dem Schreiben von Text beginnen. Drücken Sie Strg+O, um die Datei zu speichern. Sie werden aufgefordert, einen Dateinamen einzugeben. Drücken Sie Enter, um die Datei zu speichern.
Verlassen von nano
Drücken Sie Strg+X, um Nano zu verlassen. Wenn Sie ungespeicherte Änderungen haben, fragt Nano, ob Sie die Änderungen vor dem Verlassen speichern möchten.
Kopieren und Einfügen
Verwenden Sie Alt+A, um einen Bereich auszuwählen. Es wird ein Marker angezeigt. Verwenden Sie die Pfeiltasten, um den Text auszuwählen. Sobald der Text ausgewählt ist, beenden Sie den Marker mit Alt+^.
Um den ausgewählten Text zu kopieren, drücken Sie Strg+K. Drücken Sie Strg+U, um den kopierten Text einzufügen.
ausschneiden und einfügen
Wählen Sie den Bereich mit Alt+A aus. Wenn Sie ihn ausgewählt haben, schneiden Sie den Text mit Strg+K aus. Drücken Sie Strg+U, um den ausgeschnittenen Text einzufügen.
Navigation
Verwenden Sie Alt \, um zum Anfang der Datei zu gelangen.
Verwenden Sie Alt /, um zum Ende der Datei zu gelangen.
Zeilennummern anzeigen
Wenn Sie eine Datei mit nano -l Dateiname öffnen, können Sie auf der linken Seite der Datei Zeilennummern sehen.
Suchen
Suchen Sie nach einer bestimmten Zeilennummer mit Alt + G. Geben Sie die Zeilennummer in den Prompt ein und drücken Sie Enter.
Sie können auch mit STRG + W eine Suchfunktion für eine Zeichenkette einleiten und mit Enter drücken, um die Suche zu starten. Wenn Sie rückwärts suchen möchten, können Sie nach dem Start der Suche mit ALT+W drücken.
- Zusammenfassung der Tastenkürzel in Nano
STRG+G: Hilfeinformation anzeigenStrg+J: Aktuellen Absatz ausrichtenStrg+V: Blätter unten um eine SeiteStrg+\: Suche und Ersetzen
Alt+E: Letzte rückgängig gemachte Operation wiederholen
Teil 6: Bash-Skripterstellung
6.1. Definition von Bash-Skripten
Ein Bash-Skript ist eine Datei, die eine Reihe von Befehlen enthält, die von dem Bash-Programm Zeile für Zeile ausgeführt werden. Es ermöglicht die Durchführung einer Reihe von Aktionen, wie dem Navigieren in eine bestimmte Verzeichnis, dem Erstellen eines Ordners und dem Starten eines Prozesses über die Befehlszeile.
Durch das Speichern von Befehlen in einem Skript können Sie die gleiche Abfolge von Schritten mehrfach wiederholen und sie durch Ausführen des Skripts ausführen.
6.2. Vorteile der Bash-Skripterstellung
Bash-Skripting ist ein leistungsstarkes und vielseitiges Werkzeug zur Automatisierung von Systemverwaltungsaufgaben, zur Verwaltung von Systemressourcen und zur Durchführung anderer Routineaufgaben in Unix/Linux-Systemen.
- Einige Vorteile der Shell-Skripterstellung sind:
- Automatisierung: Shell-Skripts ermöglichen es Ihnen, sich wiederholende Aufgaben und Prozesse zu automatisieren, wodurch Zeit gespart und das Risiko von Fehlern, die bei manueller Ausführung auftreten können, reduziert wird.
- Portabilität: Shell-Skripts können auf verschiedenen Plattformen und Betriebssystemen ausgeführt werden, einschließlich Unix, Linux, macOS und sogar Windows durch die Verwendung von Emulatoren oder virtuellen Maschinen.
- Flexibilität: Shellskripte sind sehr veränderbar und können leicht an bestimmte Anforderungen angepasst werden. Sie können auch mit anderen Programmiersprachen oder Werkzeugen kombiniert werden, um stärkere Skripte zu schaffen.
- Zugänglichkeit: Shellskripte sind einfach zu schreiben und erfordern keine speziellen Tools oder Software. Sie können mit jedem Texteditor bearbeitet werden, und die meisten Betriebssysteme verfügen über integrierte Shellinterpreter.
- Integration: Shellskripte können mit anderen Tools und Anwendungen integriert werden, wie z.B. Datenbanken, Web-Server und Cloud-Dienste, was komplexere Automatisierungs- und Systemverwaltungstätigkeiten ermöglicht.
Fehlerdiagnose: Shellskripte sind einfach zu debuggen, und die meisten Shells verfügen über integrierte Debugging- und Fehlerberichterstattungstools, die Hilfe bei der Identifizierung und Behebung von Problemen bieten können.
6.3. Übersicht über Bash Shell und Command Line Interface
Die Begriffe „Shell“ und „Bash“ werden oft synonym verwendet. Es gibt jedoch eine subtile Differenz zwischen den beiden.
Der Begriff „Shell“ bezieht sich auf ein Programm, das eine Kommandozeile für die Interaktion mit einem Betriebssystem bereitstellt. Bash (Bourne-Again SHell) ist eine der am meisten verwendeten Unix/Linux-Shells und die Standard-Shell in vielen Linux-Distributionen.
Bis jetzt wurden die von Ihnen eingegebenen Befehle im Prinzip in einer „Shell“ eingegeben.
Obwohl Bash ein Typ von Shell ist, gibt es auch andere Shells, wie z.B. die Korn-Shell (ksh), die C-Shell (csh) und die Z-Shell (zsh). Jede Shell hat ihre eigene Syntax und Features, aber sie alle teilen das gemeinsame Ziel, eine Kommandozeile für die Interaktion mit dem Betriebssystem bereitzustellen.
ps
# output:
PID TTY TIME CMD
20506 pts/0 00:00:00 bash <--- the shell type
20931 pts/0 00:00:00 ps
Sie können Ihren Shell-Typ mit dem Befehl ps ermitteln:
Zusammenfassend ist „Shell“ ein allgemeiner Begriff, der auf jedes Programm Bezug nimmt, das eine Kommandozeile bereitstellt, während „Bash“ ein bestimmter Shell-Typ ist, der in vielen Unix/Linux-Systemen verwendet wird.
Anmerkung: In diesem Abschnitt verwenden wir die „Bash“-Shell.
6.4. Wie man Bash-Skripte erstellt und ausführt
Skriptnamenskonventionen
Nach der Namenskonvention enden Bash-Skripte mit .sh. Allerdings funktionieren Bash-Skripte auch ohne die sh-Erweiterung perfekt.
Shebang hinzufügen
Bash-Skripte beginnen mit einem shebang. Shebang ist eine Kombination von bash # und bang !, gefolgt vom Pfad zur Bash-Umgebung. Dies ist die erste Zeile des Skripts. Shebang weist die Shell an, es über die Bash-Umgebung auszuführen. Shebang ist einfach der absolute Pfad zum Bash-Interpreter.
#!/bin/bash
Unten ist ein Beispiel für die Shebang-Anweisung.
which bash
Du kannst deinen Bash-Shell-Pfad (der sich von oben unterscheiden kann) mit dem Befehl finden:
Erstellen deines ersten Bash-Skripts
Unser erstes Skript fordert den Benutzer auf, einen Pfad einzugeben. Im Gegenzug wird dessen Inhalt aufgelistet.
vim run_all.sh
Erstelle mit deinem favorisierten Editor einen Datei mit dem Namen run_all.sh.
#!/bin/bash
echo "Today is " `date`
echo -e "\nenter the path to directory"
read the_path
echo -e "\n you path has the following files and folders: "
ls $the_path
Füge die folgenden Befehle in deine Datei hinzu und speichere sie:
1 Lass uns das Skript einzelne Zeilen aufclose. Ich zeige das gleiche Skript erneut an, diesmal mit Zeilennummern.
2 echo "Today is " `date`
3
4 echo -e "\nenter the path to directory"
5 read the_path
6
7 echo -e "\n you path has the following files and folders: "
8 ls $the_path
- #!/bin/bash
- Zeile #1: Der shebang (
#!/bin/bash) zeigt auf den Pfad der Bash-Umgebung hin. - Zeile #2: Der
echo-Befehl zeigt die aktuelle Datums- und Uhrzeit auf der Konsole an. Beachte, dassdatein Backticks steht. - Zeile #4: Wir möchten, dass der Benutzer einen gültigen Pfad eingibt.
- Zeile #5: Der Befehl
readliest die Eingabe ein und speichert sie in der Variablethe_path.
Zeile #8: Der Befehl ls nimmt die Variable mit dem gespeicherten Pfad und zeigt die aktuellen Dateien und Ordner an.
Ausführen des Bash-Skripts
chmod u+x run_all.sh
Um das Skript ausführbar zu machen, geben Sie dem Skript mit dem folgenden Befehl Ausführungsrechte für Ihren Benutzer zu:
- Hier,
chmodändert den Besitzer einer Datei für den aktuellen Benutzer :u.+xfügt dem aktuellen Benutzer Ausführungsrechte hinzu. Dies bedeutet, dass der Benutzer, der Besitzer der Datei ist, nun das Skript ausführen kann.
run_all.sh ist die Datei, die wir ausführen möchten.
- Sie können das Skript mit jedem der genannten Methoden ausführen:
sh run_all.shbash run_all.sh
./run_all.sh
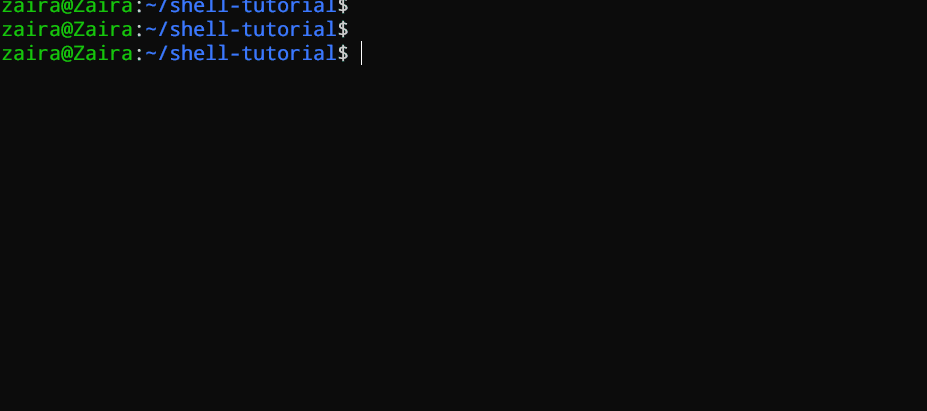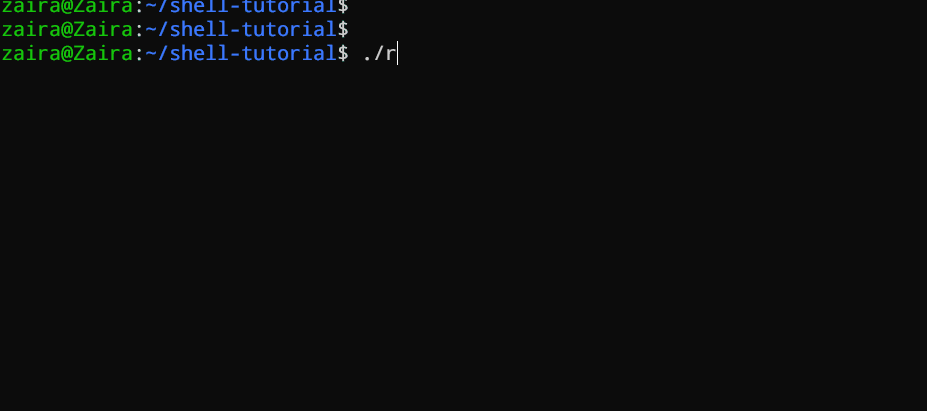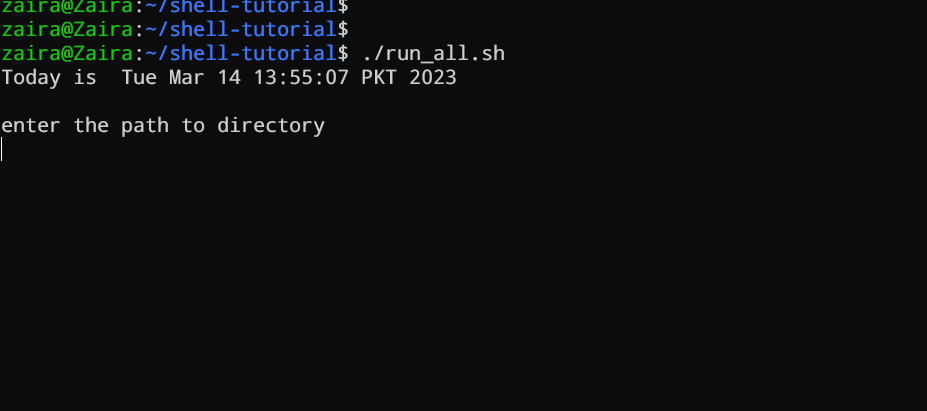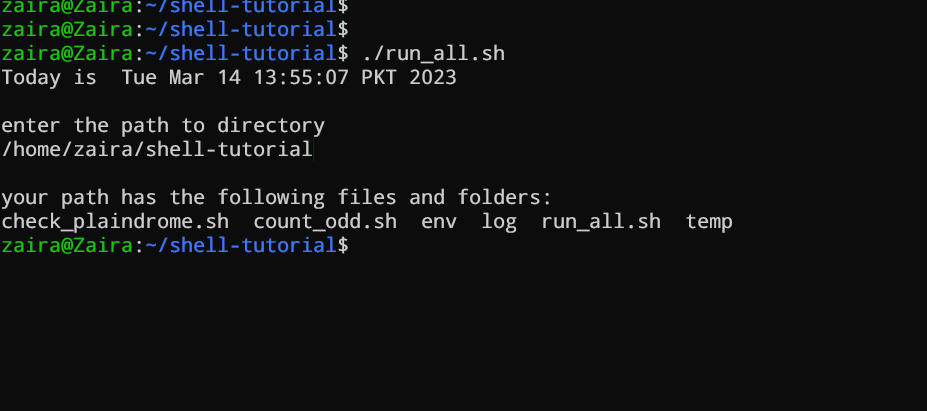
Lassen Sie uns es in Aktion sehen 🚀
6.5. Grundlagen der Bash-Skriptierung
Kommentare in Bash-Skripten
Kommentare beginnen in Bash-Skripten mit einem #. Dies bedeutet, dass jeder Zeile, die mit einem # beginnt, ein Kommentar ist und von dem Interpreter ignoriert wird.
Kommentare sind sehr hilfreich zur Dokumentation des Codes und es ist eine gute Praxis, sie hinzuzufügen, um anderen das Verständnis des Codes zu erleichtern.
Dies sind Beispiele für Kommentare:
# Dies ist ein Beispielkommentar
# Beide diese Zeilen werden vom Interpreter ignoriert
Variablen und Datentypen in Bash
Variablen ermöglichen es Ihnen, Daten zu speichern. Sie können Variablen verwenden, um Daten während Ihres Skripts zu lesen, zuzugreifen und zu verarbeiten.
Es gibt keine Datentypen in Bash. In Bash kann eine Variable Datenwerten von numerischen Werten, einzelnen Zeichen oder Zeichenketten speichern.
- In Bash können Sie Variablenwerte auf folgige Weise verwenden und setzen:
country=Netherlands
Zuweisen des Werts direkt:
same_country=$country
2. Zuweisen des Werts anhand der Ausgabe, die von einem Programm oder Befehl erhalten wird, durch Verwendung der Kommandoersetzung. Beachten Sie, dass ein $ erforderlich ist, um den Wert einer vorhandenen Variable zuzugreifen.
Dies weist den Wert von country der neuen Variable same_country zu.
country=Netherlands
echo $country
Um auf den Wert der Variable zuzugreifen, fügen Sie $ an das Namen der Variable an.
Netherlands
new_country=$country
echo $new_country
# Ausgabe
Netherlands
# Ausgabe
oben kannst du ein Beispiel der Zuweisung und Ausgabe von Variablenwertern sehen.
Variablenamenkonventionen
- In Bash-Skripten gelten folgende Variablenamenkonventionen:
- Variablenamen sollten mit einem Buchstaben oder einem Unterstrich (
_) beginnen. - Variablenamen können Buchstaben, Zahlen und Unterstriche (
_) enthalten. - Variablenamen sind kaschsensitive.
- Variablenamen sollten keine Leerzeichen oder Sonderzeichen enthalten.
- Verwende deskriptive Namen, die den Zweck der Variable widerspiegeln.
Verwende keine reservierten Keywords wie if, then, else, fi und so weiter als Variablennamen.
name
count
_var
myVar
MY_VAR
Hier sind einige Beispiele gültiger Variablenamen in Bash:
Und hier sind einige Beispiele ungültiger Variablenamen:
2ndvar (variable name starts with a number)
my var (variable name contains a space)
my-var (variable name contains a hyphen)
# ungültige Variablen Namen
Befolgen dieser Namenskonventionen hilft, um Bash-Skripte lesbarer und einfacher zuwartbar zu machen.
Eingabe und Ausgabe in Bash-Skripten
Eingabe abrufen
- In diesem Abschnitt werden wir einige Methoden diskutieren, um Eingaben in unseren Skripten bereitzustellen.
Lesen der Benutzereingabe und Speichern in einer Variable
#!/bin/bash
echo "What's your name?"
read entered_name
echo -e "\nWelcome to bash tutorial" $entered_name
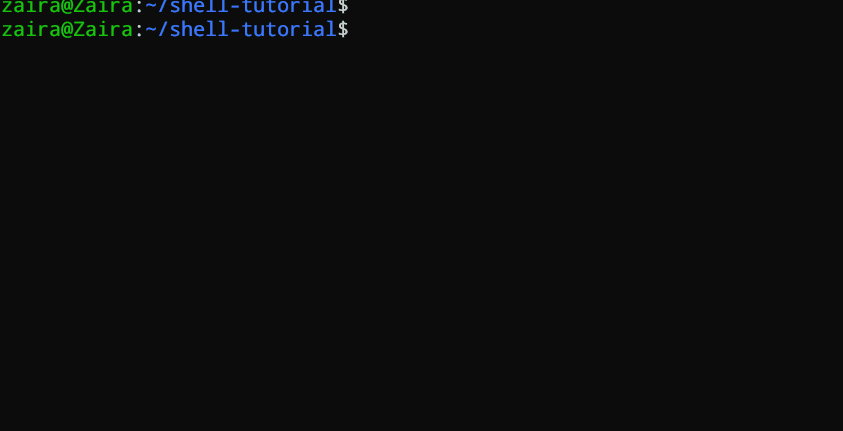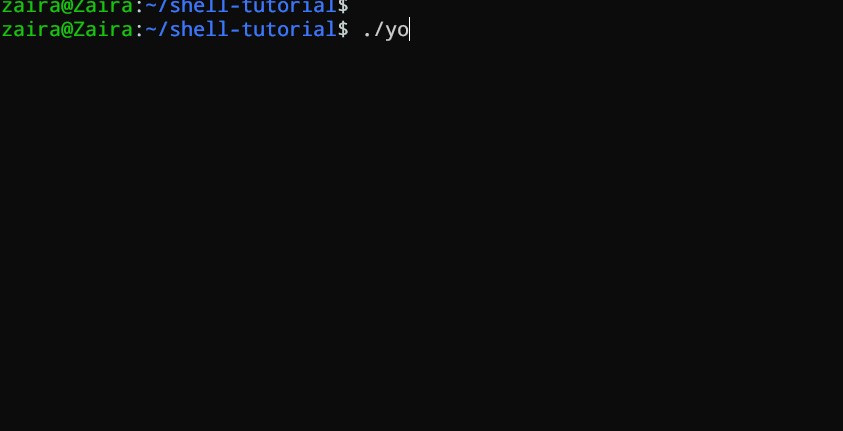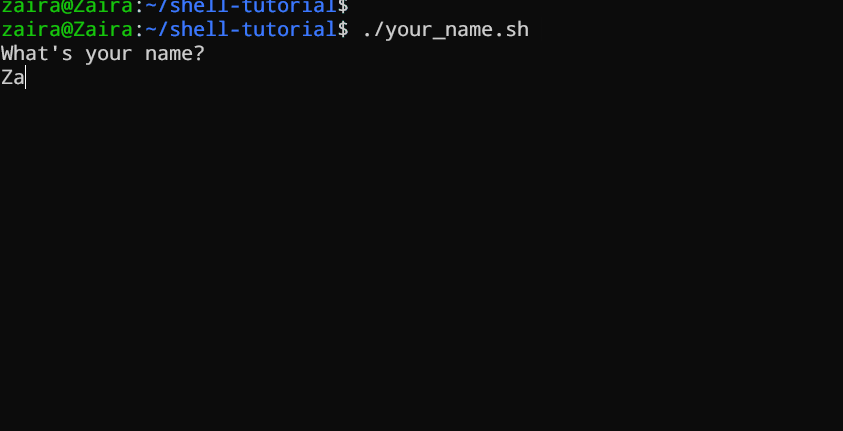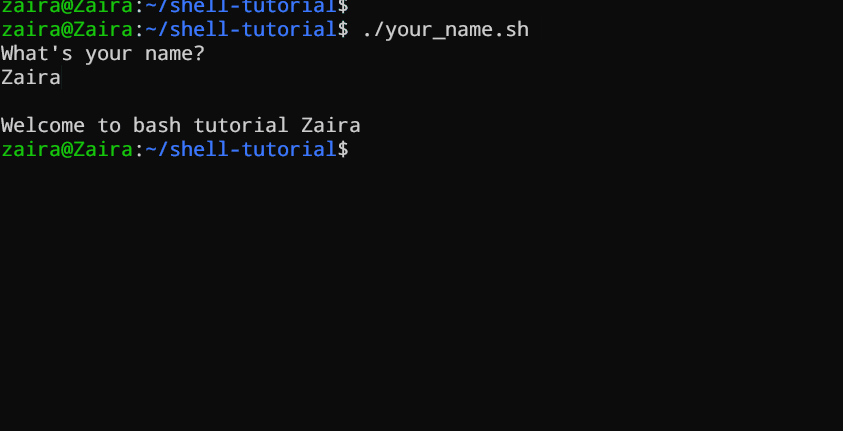
Wir können die Benutzereingabe mit dem Befehl read abrufen.
2. Einlesen aus einer Datei
while read line
do
echo $line
done < input.txt
Dieser Code liest jede Zeile aus einer Datei mit dem Namen input.txt und gibt sie an die Konsole aus. Wir werden while-Schleifen in diesem Abschnitt näher untersuchen.
3. Kommandozeilenargumente
In einem Bash-Skript oder -Funktion bezeichnet $1 das erste Argument, das $2 das zweite Argument usw. übergeben wurde.
#!/bin/bash
echo "Hello, $1!"
Dieses Skript nimmt einen Namen als Kommandozeilenargument an und gibt eine personalisierte Grüße aus.
Wir haben Zaira als unser Argument für das Skript bereitgestellt.
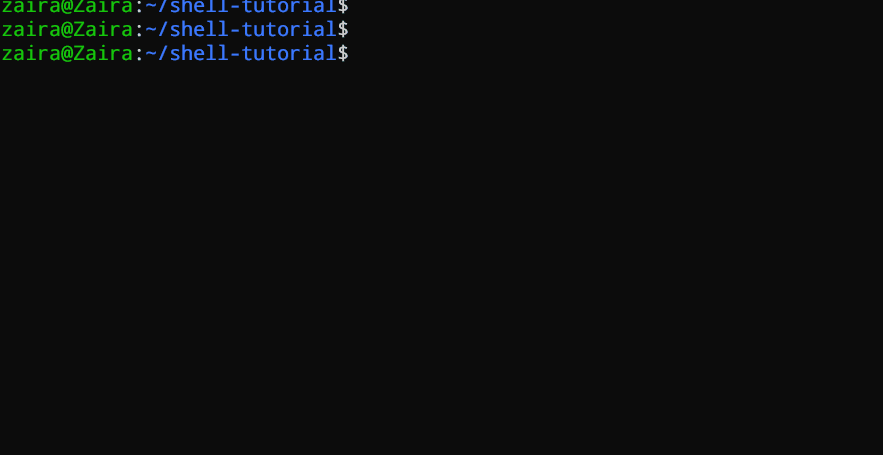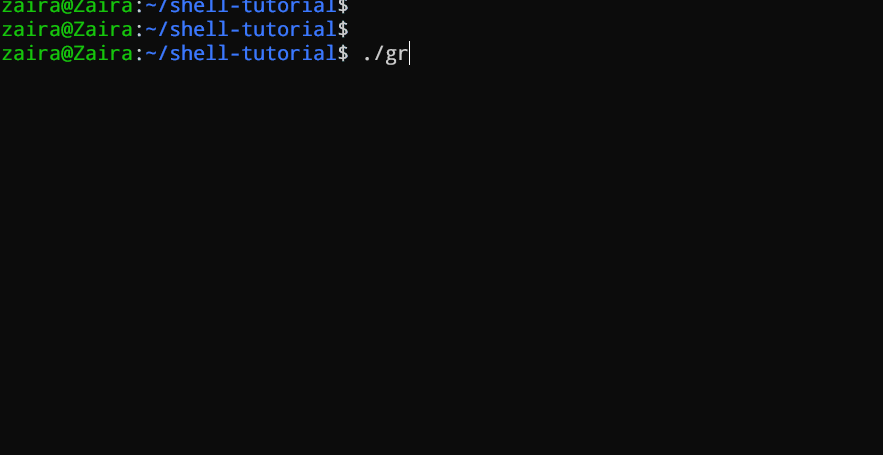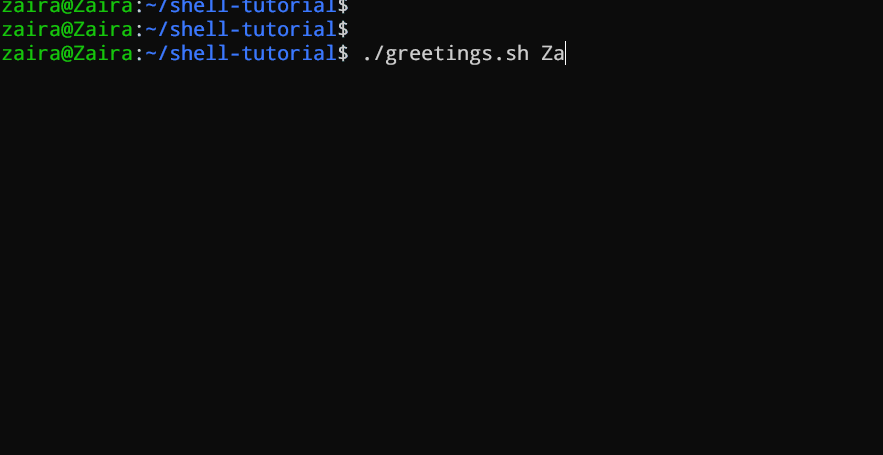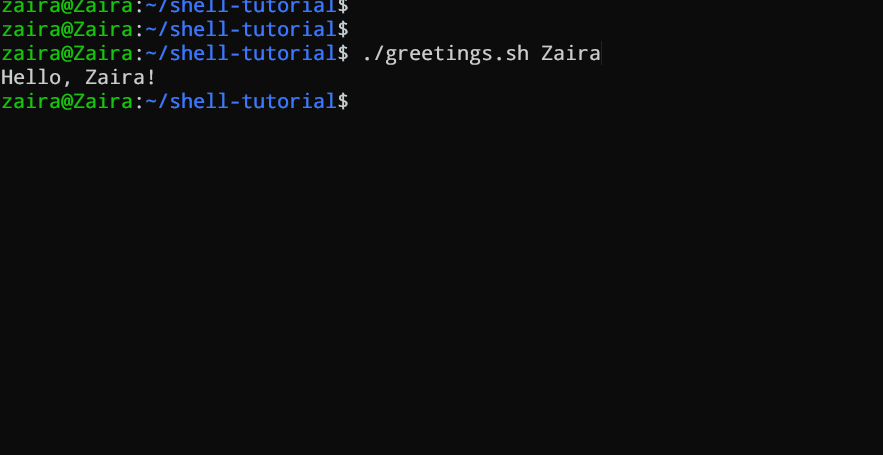
Ausgabe:
Ausgabe
- Hier diskutieren wir einige Methoden, um die Ausgabe der Skripte zu erhalten.
echo "Hello, World!"
Ausgabe auf der Konsole:
Dies gibt die Textzeile „Hallo, Welt!“ an die Konsole aus.
echo "This is some text." > output.txt
2. Schreiben in eine Datei:
Dies schreibt die Textzeile „Dies ist einige Text.“ in eine Datei mit dem Namen output.txt. Beachten Sie, dass das >-Operator eine Datei überschreibt, wenn sie bereits Inhalt hat.
echo "More text." >> output.txt
3. Anhängen zu einer Datei:
Diese Anweisung fügt dem Text „Mehr Text.“ am Ende der Datei output.txt hinzu.
ls > files.txt
4. Ausgabenumleitung:
Dies listet die Dateien im aktuellen Verzeichnis auf und schreibt die Ausgabe in eine Datei mit dem Namen files.txt ein. Sie können die Ausgabe jedes Befehls auf diese Weise in eine Datei umleiten.
Sie lernen detailliert über die Ausgabenumleitung in Abschnitt 8.5.
Bedingte Anweisungen (if/else)
Ausdrücke, die ein boolesches Ergebnis hervorrufen, entweder wahr (true) oder falsch (false), heißen Bedingungen. Es gibt mehrere Möglichkeiten, Bedingungen auszuschließen, einschließlich if, if-else, if-elif-else und verschachtelter Bedingungen.
if [[ condition ]];
then
statement
elif [[ condition ]]; then
statement
else
do this by default
fi
Syntax:
Syntax von Bash-Bedingungen
if [ $a -gt 60 -a $b -lt 100 ]
Wir können logische Operatoren wie UND -a und ODER -o verwenden, um bedeutendere Vergleiche durchzuführen.
Diese Anweisung prüft, ob beide Bedingungen gleichzeitig true sind: a ist größer als 60 UND b ist kleiner als 100.
#!/bin/bash
Sehen wir ein Beispiel für ein Bash-Skript, das if, if-else und if-elif-else-Anweisungen verwendet, um festzustellen, ob eine von der Benutzereingabe angegebene Zahl positive, negative oder null ist:
echo "Please enter a number: "
read num
if [ $num -gt 0 ]; then
echo "$num is positive"
elif [ $num -lt 0 ]; then
echo "$num is negative"
else
echo "$num is zero"
fi
# Skript, um festzustellen, ob eine Zahl positive, negative oder null ist
Der Skript startet damit, den Benutzer zu bitten, eine Zahl einzugeben. Anschließend verwendet es einen if-Ausdruck, um zu prüfen, ob die Zahl größer als 0 ist. Wenn dies der Fall ist, gibt das Skript aus, dass die Zahl positive ist. Wenn die Zahl nicht größer als 0 ist, springt das Skript zum nächsten Ausdruck über, der ein if-elif-Ausdruck ist.
Hier prüft das Skript, ob die Zahl kleiner als 0 ist. Wenn dies der Fall ist, gibt das Skript aus, dass die Zahl negative ist.
Abschließend verwendet das Skript einen else-Ausdruck, um auszugeben, dass die Zahl null ist, wenn die Zahl weder größer als 0 noch kleiner als 0 ist.
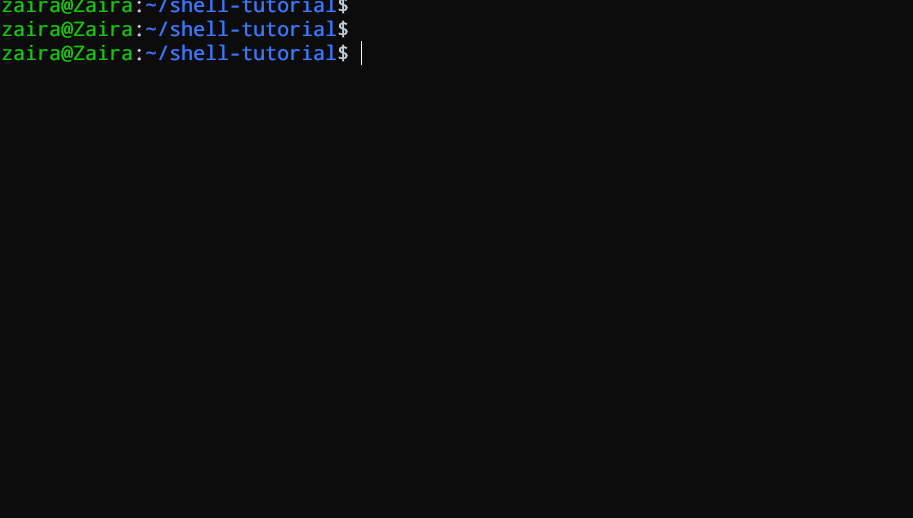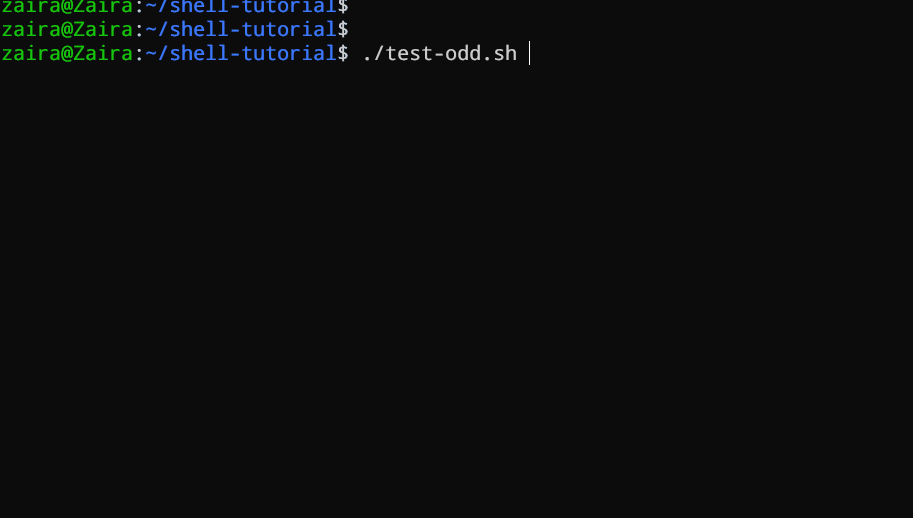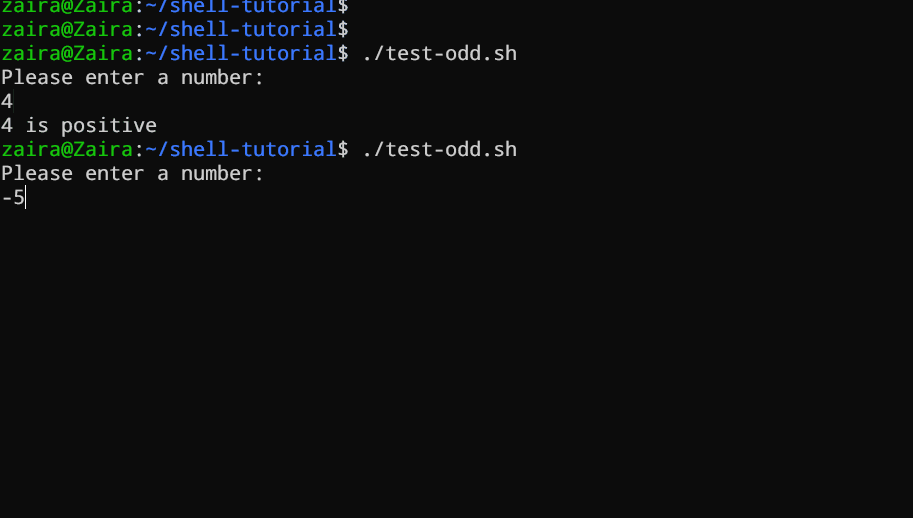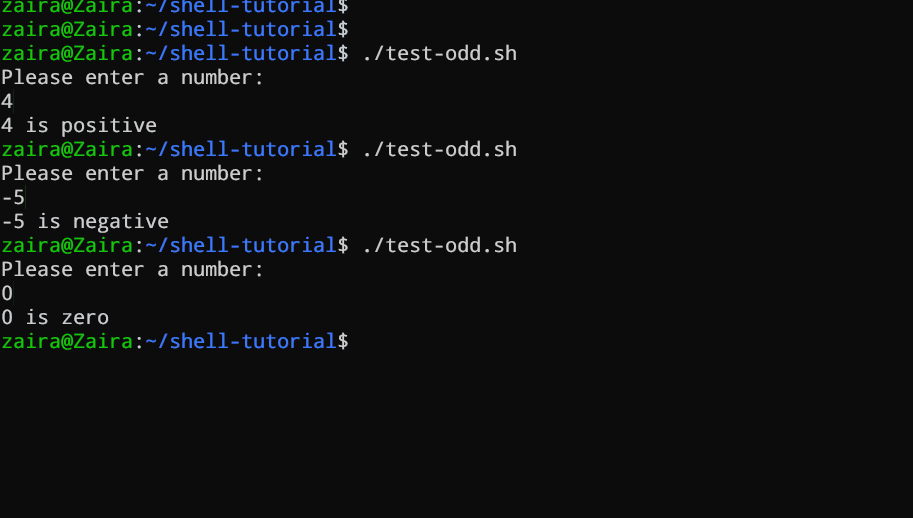
Sehen Sie es selbst in Aktion 🚀
Schleifen und Abzweigungen in Bash
Während-Schleife
Während-Schleifen prüfen eine Bedingung und führen den Loop aus, bis die Bedingung wahr bleibt. Wir müssen einen Zählerausdruck bereitstellen, der den Zähler inkrementiert, um das Ausführen des Loops zu steuern.
#!/bin/bash
i=1
while [[ $i -le 10 ]] ; do
echo "$i"
(( i += 1 ))
done
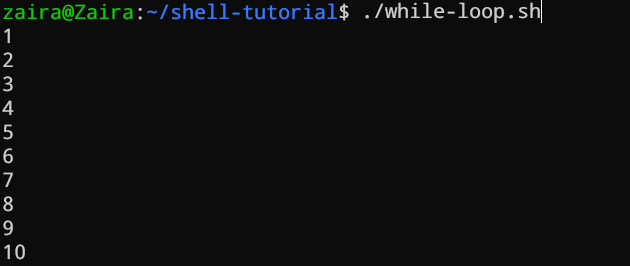
In dem Beispiel unten ist (( i += 1 )) der Zählerausdruck, der den Wert von i inkrementiert. Die Schleife wird genau 10 Mal ausgeführt.
Für-Schleife
Die for-Schleife erlaubt es ebenso wie die while-Schleife, Ausdrücke bestimmter Anzahl von Malen auszuführen. Jeder Schleifenzyklus unterscheidet sich in seiner Syntax und seiner Verwendung.
#!/bin/bash
for i in {1..5}
do
echo $i
done

In dem Beispiel unten wird die Schleife 5 Mal durchlaufen.
Fallunterscheidung
case expression in
pattern1)
In Bash verwendet man Fallunterscheidungen, um einen gegebenen Wert gegen eine Liste von Musterpattern abzuvergleichen und einen Block von Code basierend auf dem ersten passenden Musterpattern auszuführen. Die Syntax für einen Fallunterscheidungsausdruck in Bash lautet wie folgt:
;;
pattern2)
# Code, der ausgeführt wird, wenn der Ausdruck dem Musterpattern1 entspricht
;;
pattern3)
# Code, der ausgeführt wird, wenn der Ausdruck dem Musterpattern2 entspricht
;;
*)
# Code, der ausgeführt wird, wenn der Ausdruck dem Musterpattern3 entspricht
;;
esac
# Code, der ausgeführt wird, wenn keines der oben genannten Musterpattern den Ausdruck entspricht
Hier ist „Ausdruck“ der Wert, den wir vergleichen wollen, und „Musterpattern1“, „Musterpattern2“, „Musterpattern3“ usw. sind die Muster, die wir vergleichen wollen.
Das Doppelpunkt „;;“ trennt jeden Codeblock, der für jedes Musterpattern ausgeführt wird. Das Sternchen „*“ steht für den Standardfall, der ausgeführt wird, wenn keines der angegebenen Musterpattern den Ausdruck entspricht.
fruit="apple"
case $fruit in
"apple")
echo "This is a red fruit."
;;
"banana")
echo "This is a yellow fruit."
;;
"orange")
echo "This is an orange fruit."
;;
*)
echo "Unknown fruit."
;;
esac
Sehen wir ein Beispiel:
In diesem Beispiel passt der Wert von fruit aufgrund von apple zum ersten Muster, und der Block von Code, der This is a red fruit. ausgibt, wird ausgeführt. Wenn der Wert von fruit stattdessen banana wäre, passt das zweite Muster und der Block von Code, der This is a yellow fruit. ausgibt, wird ausgeführt, und so weiter.
Wenn der Wert von fruit keinem der angegebenen Muster entspricht, wird der Standardfall ausgeführt, der Unknown fruit. ausgibt.
Teil 7: Softwarepaketverwaltung unter Linux
Linux kommt mit mehreren integrierten Programmen. Aber Sie müssen eventuell neue Programme basierend auf Ihren Bedürfnissen installieren. Sie müssen auch die bestehenden Anwendungen aktualisieren könnten.
7.1 Pakete und Paketverwaltung
Was ist ein Paket?
Ein Paket ist eine Sammlung von Dateien, die zusammengefasst sind. Diese Dateien sind essentiell, um ein bestimmtes Programm zu betreiben. Diese Dateien beinhalten die ausführbaren Dateien des Programms, Bibliotheken und andere Ressourcen.
Neben den Dateien, die für den Programmablauf erforderlich sind, enthalten Pakete auch Installationsskripte, die die Dateien an die richtige Stelle kopieren. Ein Programm kann viele Dateien und Abhängigkeiten enthalten. Mit Paketen ist es einfacher, alle Dateien und Abhängigkeiten auf einmal zu verwalten.
Wie unterscheidet man Source und Binary?
Programmierer schreiben Quellcode in einer Programmiersprache. Dieser Quellcode wird dann in Maschinecode kompiliert, der vom Computer verstanden werden kann. Der kompilierte Code wird als Binary-Code bezeichnet.
Wenn Sie ein Paket herunterladen, können Sie entweder den Quellcode oder den Binary-Code erhalten. Der Quellcode ist der lesbare Code, der in Binary-Code kompiliert werden kann. Der Binary-Code ist der kompilierte Code, der vom Computer verstanden wird.
Quellpakete können mit jedem Typ von Maschine verwendet werden, sofern der Quellcode korrekt kompiliert wird. Anderseits ist Binary kompiliertes Code, der speziell für einen bestimmten Typ von Maschine oder Architektur ist.
uname -m
Sie können die Architektur Ihrer Maschine mit dem Befehl uname -m finden.
x86_64
# Ausgabe
Paketabhängigkeiten
Programme teilen oft Dateien. Anstatt diese Dateien in jedem Paket einzubehalten, kann ein separates Paket sie für alle Programme bereitstellen.
Um ein Programm zu installieren, das diese Dateien braucht, müssen Sie auch das Paket installieren, das sie enthält. Dies wird als Paketabhängigkeit bezeichnet. Die Angabe von Abhängigkeiten macht Pakete kleiner und einfacher, indem Duplikate reduziert werden.
Wenn Sie ein Programm installieren, müssen auch其Abhängigkeiten installiert werden. Die meisten notwendigen Abhängigkeiten sind normalerweise bereits installiert, aber ein paar zusätzliche könnten erforderlich sein. Daher sollten Sie sich nicht wundern, wenn mehrere andere Pakete zusätzlich zu Ihrem gewählten Paket installiert werden. Diese sind die notwendigen Abhängigkeiten.
Paketmanager
Linux bietet ein umfassendes Paketmanagementsystem für die Installation, Aktualisierung, Konfiguration und Entfernung von Software.
Mit dem Paketmanagement können Sie auf eine organisierte Basis von Tausenden von Softwarepaketen zugreifen und die Fähigkeit haben, Abhängigkeiten aufzulösen und auf Softwareupdates zu prüfen.
Pakete können mit entweder command-line-Utilities verwaltet werden, die von Systemadministratoren leicht automatisiert werden können oder durch eine grafische Oberfläche.
Software-Kanäle/Repositorys
⚠️ Paketmanagement ist für verschiedene Distributionen unterschiedlich. Hier verwenden wir Ubuntu.
Die Softwareinstallation in Linux ist etwas anders als in Windows und Mac.
Linux verwendet Repositories, um Softwarepakete aufzuladen. Ein Repository ist eine Sammlung von Softwarepaketen, die per Paketmanager installiert werden können.
Ein Paketmanager speichert auch einen Index aller Pakete, die aus einem Repo verfügbar sind. Manchmal wird der Index neu aufgebaut, um sicherzustellen, dass er aktuell ist und zu wissen, welche Pakete seit der letzten Überprüfung im Kanal aktualisiert oder hinzugefügt wurden.
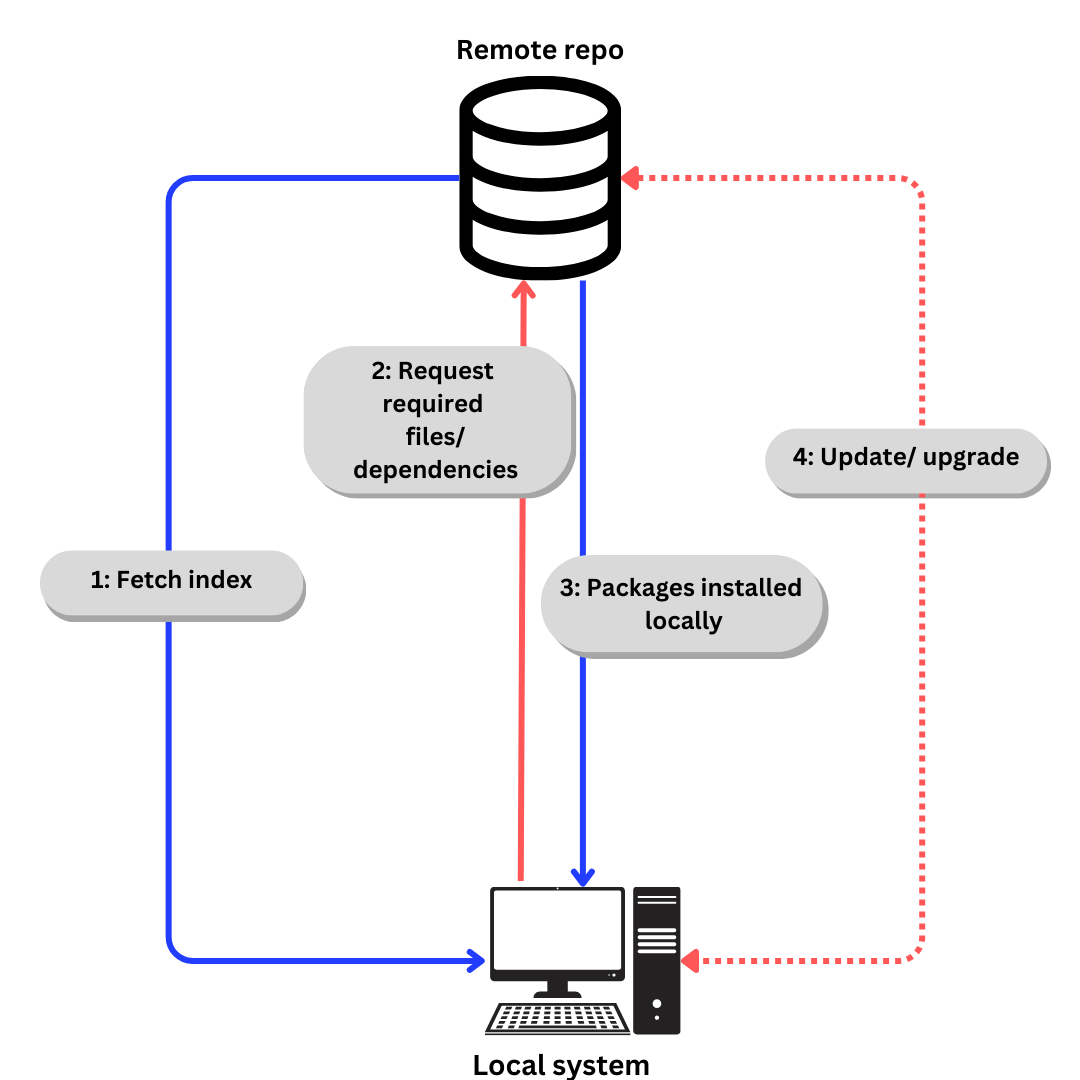
Der allgemeine Prozess des Herunterladens von Software aus einem Repo sieht ungefähr so aus:
- Wenn wir speziell von Ubuntu sprechen,
- Der Index wird mit
apt updateabgerufen. (aptwird in der nächsten Sektion erklärt). - Erforderliche Dateien/Abhängigkeiten werden gemäß dem Index mit
apt installangefordert. - Pakete und Abhängigkeiten werden lokal installiert.
Abhängigkeiten und Pakete bei Bedarf mit apt update und apt upgrade aktualisieren.
Auf Debian-basierten Distros kannst du die Liste der Repos (Repositorys) in /etc/apt/sources.list einsehen.
7.2. Installation eines Pakets via Kommandozeile
Der Befehl apt ist ein leistungsfähiges Kommandozeilenwerkzeug, das mit der „Advanced Packaging Tool (APT)“ von Ubuntu funktioniert.
apt, zusammen mit den dazu gehörigen Befehlen, stellt die Möglichkeiten bereit, neue Softwarepakete zu installieren, bestehende Softwarepakete zu aktualisieren, den Paketlistenindex zu aktualisieren und sogar das gesamte Ubuntu-System zu aktualisieren.
Um die Protokolle der Installation mit apt anzuzeigen, kann Sie die Datei /var/log/dpkg.log anschauen.
Folgende sind die Anwendungen des Befehls apt:
Installieren von Paketen
sudo apt install htop
Zum Beispiel, um das Paket htop zu installieren, kann Sie den folgenden Befehl verwenden:
Aktualisieren des Paketlistenindex
sudo apt update
Der Paketlistenindex ist eine Liste aller verfügbaren Pakete in den Repositories. Um den lokalen Paketlistenindex zu aktualisieren, kann Sie den folgenden Befehl verwenden:
Aktualisieren der Pakete
Installierte Pakete auf Ihrem System können Updates enthalten, die Fehlerkorrekturen, Sicherheitspatches und neue Funktionen beinhalten.
sudo apt upgrade
Um die Pakete zu aktualisieren, kann Sie den folgenden Befehl verwenden:
Entfernen von Paketen
sudo apt remove htop
Um ein Paket, wie z.B. htop, zu entfernen, kann Sie den folgenden Befehl verwenden:
7.3. Installieren eines Pakets über ein fortschrittliches Grafisches Verfahren – Synaptic
Wenn Sie sich nicht mit der Befehlszeile behaupten, können Sie eine grafische Benutzeroberfläche verwenden, um Pakete zu installieren. Sie können die gleichen Ergebnisse wie mit der Befehlszeile erzielen, jedoch mit einer grafischen Oberfläche.
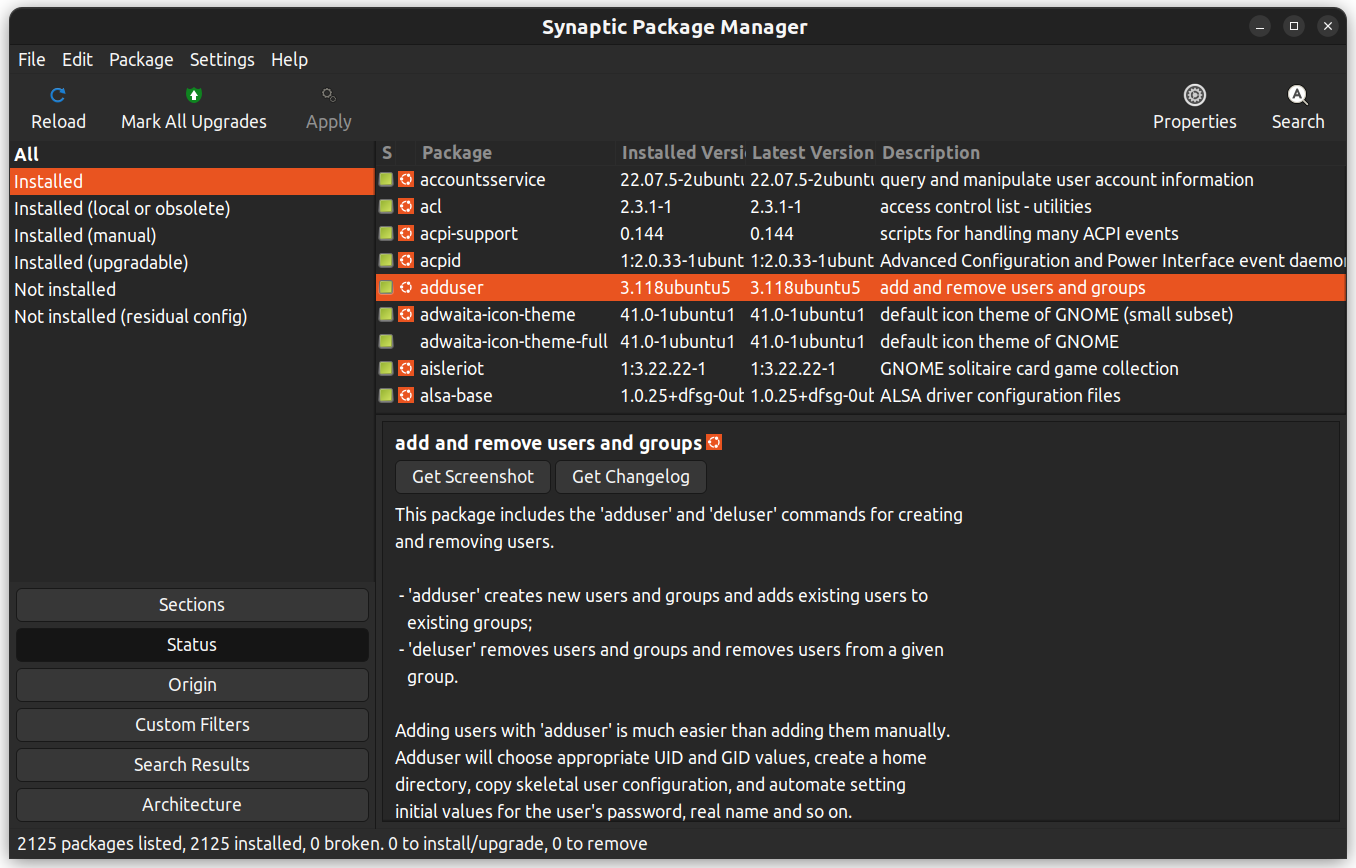
Synaptic ist ein GUI-Paketmanagement, das hilft,sucht.
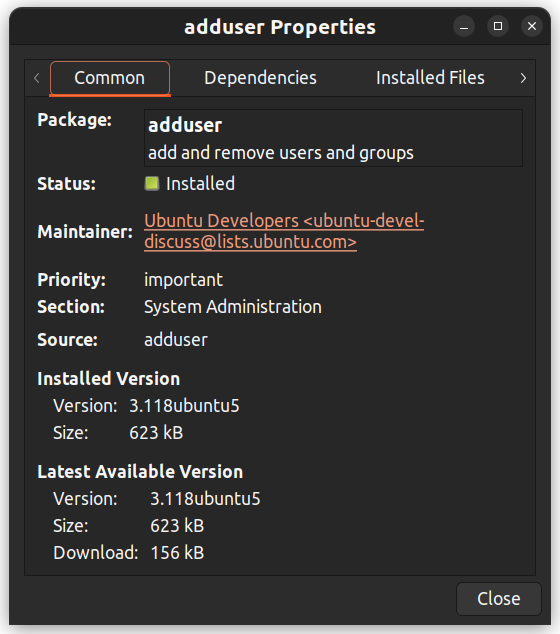
Sie können auch mit der rechten Maustaste auf ein Paket klicken und weitere Details anschauen, wie z.B. Abhängigkeiten, Verwalter, Größe und installierte Dateien.
7.4. Installieren von heruntergeladenen Paketen von einer Webseite
Möglicherweise möchten Sie ein Paket installieren, das Sie von einer Webseite heruntergeladen haben, anstatt aus einem Software-Repository. Diese Pakete heißen .deb-Dateien.
cd directory
sudo dpkg -i package_name.deb
Verwendendpkgzum Installieren von Paketen:dpkg ist ein Kommandozeilenwerkzeug, das zum Installieren von Paketen verwendet wird. Um ein Paket mit dpkg zu installieren, öffnen Sie den Terminal und tippen Sie folgendes ein:
Hinweis: Ersetzen Sie „Verzeichnis“ durch das Verzeichnis, in dem das Paket gespeichert ist, und „Paketname“ durch den Dateinamen des Pakets.
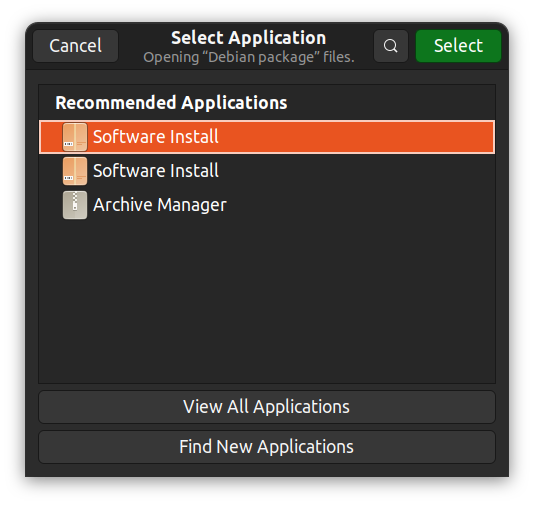
Alternativ können Sie mit der rechten Maustaste klicken, „Mit anderer Anwendung öffnen“ auswählen und eine beliebige GUI-Anwendung auswählen.
💡 Tipp: In Ubuntu können Sie mit dpkg --list eine Liste der installierten Pakete anzeigen.
Teil 8: Fortgeschrittene Linux-Themen
8.1. Benutzerverwaltung
Es kann mehrere Benutzer mit unterschiedlichen Zugriffsgraden in einem System geben. In Linux hat der root-Benutzer den höchsten Zugriffsgrad und kann jede Operation am System durchführen. Regular users haben begrenzten Zugriff und können nur Operationen durchführen, die ihnen die Berechtigung erteilt wurde.
Was ist ein Benutzer?
Ein Benutzerkonto stellt eine Trennung zwischen verschiedenen Personen und Programmen, die Befehle ausführen können, bereit.
Menschen erkennen Benutzer anhand eines Namens, da Namen einfach zu verwenden sind. Aber das System erkennt Benutzer anhand einer eindeutigen Zahl namens Benutzer-ID (UID).
Wenn menschliche Benutzer sich mit dem bereitgestellten Benutzernamen einloggen, müssen sie ein Passwort verwenden, um sich authorisieren zu lassen.
Benutzerkonten bilden die Grundlage der Systemsicherheit. Datei-Eigentum ist auch mit Benutzerkonten verknüpft und stellt den Zugriff auf die Dateien durch Access Control dar. Jeder Prozess hat ein mit ihm verbundenes Benutzerkonto, das den Administratoren eine Steuerungs Ebene bietet.
- Es gibt drei Haupttypen von Benutzerkonten:
- Superbenutzer: Der Superbenutzer hat vollständigen Zugriff auf das System. Der Name des Superbenutzers lautet
root. Er hat eineUIDvon 0. - Systembenutzer: Der Systembenutzer hat Benutzerkonten, die zum Ausführen von Systemdienstleistungen verwendet werden. Diese Konten werden verwendet, um Systemdienstleistungen zu betreiben und sind nicht für menschliche Interaktion gedacht.
Normaler Benutzer: Normalbenutzer sind menschliche Benutzer, die Zugriff auf das System haben.
id
uid=1000(john) gid=1000(john) groups=1000(john),4(adm),24(cdrom),27(sudo),30(dip)... output truncated
Der id Befehl zeigt die Benutzer-ID und Gruppen-ID des aktuellen Benutzers an.
id username
Um die grundlegenden Informationen eines anderen Benutzers anzuzeigen, geben Sie den Benutzernamen als Argument für den id Befehl ein.
ps -u
Um Informationen zu Benutzern für Prozesse anzuzeigen, verwendet man den Befehl ps mit der Option -u.
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
root 1 0.0 0.1 16968 3920 ? Ss 18:45 0:00 /sbin/init splash
root 2 0.0 0.0 0 0 ? S 18:45 0:00 [kthreadd]
# Ausgabe
Standardmäßig verwendet das System die Datei /etc/passwd zur Speicherung von Benutzerinformationen.
root:x:0:0:root:/root:/bin/bash
Hier ist eine Zeile aus der Datei /etc/passwd:
- Die Datei
/etc/passwdenthält folgende Informationen über jeden Benutzer: - Benutzername:
root– Der Benutzername der Benutzerkonto. - Passwort:
x– Das verschlüsselte Passwort für das Benutzerkonto, das aus Sicherheitsgründen im Datei/etc/shadowgespeichert ist. - Benutzer-ID (UID):
0– Die eindeutige numerische Kennung für das Benutzerkonto. - Gruppen-ID (GID):
0– Die primäre Kennung der Benutzergruppe. - Benutzerinfo:
root– Der tatsächliche Name für das Benutzerkonto. - Homeverzeichnis:
/root– Das Homeverzeichnis für das Benutzerkonto.
Shell: /bin/bash – Die Standard-Shell für das Benutzerkonto. Ein Systembenutzer könnte /sbin/nologin verwenden, wenn interaktive Anmeldungen für diesen Benutzer nicht zulässig sind.
Was ist eine Gruppe?
Eine Gruppe ist eine Sammlung von Benutzerkonten, die Zugriff und Ressourcen teilen. Gruppen haben Gruppennamen, um sie zu identifizieren. Das System identifiziert Gruppen anhand einer eindeutigen Zahl, der Gruppen-ID (GID).
Standardmäßig werden Informationen über Gruppen in der Datei /etc/group gespeichert.
adm:x:4:syslog,john
Hier ist ein Eintrag aus der Datei /etc/group:
- Hier ist die Auflistung der Felder im gegebenen Eintrag:
- Gruppenname:
adm– Der Name der Gruppe. - Passwort:
x– Das Passwort für die Gruppe ist aus Sicherheitsgründen in der Datei/etc/gshadowgespeichert. Das Passwort ist optional und leer, wenn es nicht festgelegt ist. - Gruppen-ID (GID):
4– Die eindeutige numerische Kennung für die Gruppe.
Gruppenmitglieder: syslog,john – Die Liste der Benutzernamen, die Mitglieder der Gruppe sind. In diesem Fall hat die Gruppe adm zwei Mitglieder: syslog und john.
In diesem konkreten Eintrag lautet der Gruppenname adm, die Gruppen-ID ist 4 und die Gruppe hat zwei Mitglieder: syslog und john. Das Passwortfeld ist typischerweise mit x belegt, um anzuzeigen, dass das Gruppennachname im Datei /etc/gshadow gespeichert ist.
- Die Gruppen werden weiterhin in ‚primäre‘ und ‚zusätzliche‘ Gruppen unterteilt.
- Primäre Gruppe: Jeder Benutzer ist standardmäßig einer primären Gruppe zugewiesen. Diese Gruppe hat normalerweise denselben Namen wie der Benutzer und wird beim Erstellen des Benutzerkontos erstellt. Dateien und Verzeichnisse, die vom Benutzer erstellt werden, gehören typischerweise zu dieser primären Gruppe.
Zusätzliche Gruppen: Diese sind zusätzliche Gruppen, die ein Benutzer neben seiner primären Gruppe angehören kann. Benutzer können Mitglieder mehrerer zusätzlicher Gruppen sein. Diese Gruppen ermöglichen es einem Benutzer, Rechte für Ressourcen zu erhalten, die zwischen diesen Gruppen geteilt sind. Sie helfen dabei, Zugriff auf gemeinsam verwendete Ressourcen ohne das Dateiverzeichnis zu beeinflussen und die Sicherheit zu wahren. Während ein Benutzer einer primären Gruppe angehören muss, ist die Zugehörigkeit zu zusätzlichen Gruppen optional.
Zugriffssteuerung: das Finden und Verstehen von Dateibenutzungsrechten
Die Dateibesitzer können mit dem Befehl ls -l angezeigt werden. Die erste Spalte in der Ausgabe des Befehls ls -l zeigt die Dateibenutzungsrechte an. Andere Spalten zeigen den Besitzer der Datei und die Gruppe an, der die Datei angehört.

Lassen Sie uns die Modus Spalte näher anschauen:
- Modus definiert zwei Dinge:
- Dateityp: Der Dateityp definiert den Typ der Datei. Für reguläre Dateien, die einfache Daten enthalten, ist er leer
-. Für andere spezielle Dateitypen ist das Symbol unterschiedlich. Für ein Verzeichnis, das ein spezielles Datei ist, ist esd. Spezielle Dateien werden vom Betriebssystem anders behandelt.
Berechtigungsklassen: Die nächste Reihe von Zeichen definiert die Berechtigungen für den Benutzer, die Gruppe und andere jeweils.
– Benutzer: Dies ist der Besitzer einer Datei und der Besitzer der Datei gehört zu dieser Klasse.
– Gruppe: Die Mitglieder der Dateigruppe gehören zu dieser Klasse
– Andere: Alle Benutzer, die nicht zu den Benutzer- oder Gruppeklassen gehören, gehören zu dieser Klasse.
💡Tipp: Verzeichnisbesitzer können mit dem Befehl ls -ld angezeigt werden.
Wie man symbolische Berechtigungen oder die rwx-Berechtigungen lesen
- Die
rwx-Darstellung ist die symbolische Darstellung der Berechtigungen. In der Berechtigungssatz, - lesen. Es wird durch das erste Zeichen der Triade angezeigt.
wsteht für schreiben. Es wird im zweiten Zeichen der Triade angezeigt.
x steht für Ausführung. Es wird im dritten Zeichen der Triade angezeigt.
Lesen:
Bei regulären Dateien erlauben Leseberechtigungen nur das Öffnen und Lesen der Datei. Benutzer können die Datei nicht verändern.
Bei Verzeichnissen erlauben Leseberechtigungen die Auflistung des Inhalts ohne jegliche Änderungen im Verzeichnis.
Schreiben:
Wenn Dateien Schreibberechtigungen haben, kann der Benutzer die Datei verändern (bearbeiten, löschen) und speichern.
Bei Ordnern ermöglichen Schreibberechtigungen einem Benutzer, ihren Inhalt zu verändern (erstellen, löschen und umbenennen der Dateien darin) und die Inhalte von Dateien zu verändern, für die der Benutzer Schreibberechtigungen hat.
Beispiele für Berechtigungen in Linux
- Nun, da wir wissen, wie wir Berechtigungen lesen, schauen wir uns einige Beispiele an.
-
-rw-rw-r--: Ein Datei, die von ihrem Besitzer und Gruppe geändert werden kann, aber nicht von Anderen.
drwxrwx---: Ein Verzeichnis, das von seinem Besitzer und Gruppe verändert werden kann.
Ausführen:
Für Dateien erlauben die Ausführungsberechtigungen dem Benutzer, eine ausführbare Skript zu starten. Für Verzeichnisse erlauben die Ausführungsberechtigungen dem Benutzer, auf sie zuzugreifen und Details über Dateien im Verzeichnis zu erhalten.
Wie man Dateiberechtigungen und Besitzerchaft in Linux mit chmod und chown ändert
Nun, da wir die Grundlagen von Besitzern und Berechtigungen kennen, sehen wir, wie man Berechtigungen mit dem Befehl chmod ändern kann.
chmod permissions filename
Syntax vonchmod:
- Wo,
Berechtigungenkönnen lesen, schreiben, ausführen oder eine Kombination davon sein.
Dateiname ist der Name der Datei, für die die Berechtigungen geändert werden müssen. Dieser Parameter kann auch eine Liste von Dateien sein, wenn Berechtigungen in Bulk geändert werden sollen.
- Wir können Berechtigungen mit zwei Modi ändern:
- Symbolischer Modus: Diese Methode verwendet Symbole wie
u,g,oum Benutzer, Gruppen und Andere zu repräsentieren. Berechtigungen werden durchr, w, xfür Lesen, Schreiben und Ausführen dargestellt. Sie können Berechtigungen mit +, – und = ändern.
Absoluter Modus: Diese Methode repräsentiert Berechtigungen durch dreistellige oktale Zahlen von 0-7.
Jetzt werden wir sie im Detail anschauen.
Wie ändere ich Berechtigungen im symbolischen Modus?
| Die untenstehende Tabelle fasst die Benutzerrepräsentation zusammen: | BENUTZERREPRESENTATION |
| u | BEZEICHNUNG |
| g | Benutzer/Inhaber |
| o | Gruppe |
Andere
| Wir können mathematische Operatoren verwenden, um Berechtigungen hinzuzufügen, zu entfernen und zuzuweisen. Die untenstehende Tabelle zeigt eine Zusammenfassung: | OPERATOR |
| BEZEICHNUNG | + |
| Fügt eine Berechtigung zu einer Datei oder einem Verzeichnis hinzu | – |
| Entfernt die Berechtigung | \= |
Legt die Berechtigungen fest, falls sie nicht vorhanden sind. Überschreibt auch die Berechtigungen, wenn sie zuvor festgelegt wurden.
Beispiel:
Suppose I have a script and I want to make it executable for the owner of the file zaira.

Current file permissions are as follows:
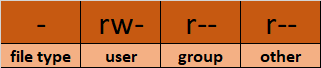
Let’s split the permissions like this:
chmod u+x mymotd.sh
To add execution rights (x) to owner (u) using symbolic mode, we can use the command below:
Output:
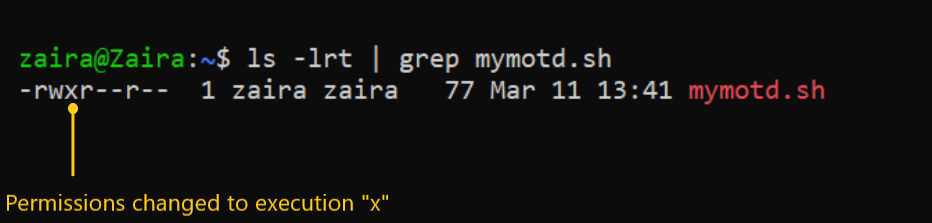
Now, we can see that the execution permissions have been added for owner zaira.
- Additional examples for changing permissions via symbolic method:
- Entfernen von
lesenundschreibenRechten fürGruppeundAndere:chmod go-rw. - Entfernen von
lesenRechten fürAndere:chmod o-r.
Zuweisen von schreiben Rechten an Gruppe und Überschreiben bestehender Rechte: chmod g=w.
How to Change Permissions using Absolute Mode
Absoluter Modus verwendet Zahlen, um Zugriffsrechte zu repräsentieren und mathematische Operatoren, um diese zu verändern.
| Die untere Tabelle zeigt, wie wir entsprechende Zugriffsrechte zuweisen können: | ZUGRIFFSRECHT |
| ZUWEISEN | lesen |
| add 4 | schreiben |
| add 2 | ausführen |
add 1
| Zugriffsrechte können mit Subtraktion widerrufen werden. Die untere Tabelle zeigt, wie Sie entsprechende Zugriffsrechte entfernen können. | ZUGRIFFSRECHT |
| WIDERRUFEN | lesen |
| subtrakt 4 | schreiben |
| subtrakt 2 | ausführen |
subtrakt 1
- Beispiel:
Setzen lesen (add 4) für user, lesen (add 4) und ausführen (add 1) für Gruppe und nur ausführen (add 1) für Andere.
chmod 451 dateiname
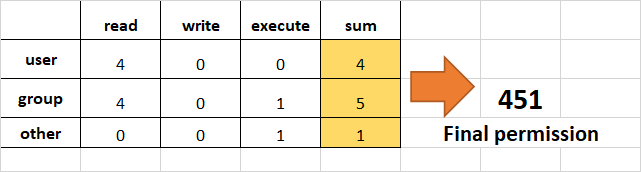
So führen wir die Berechnung durch:
- Beachten Sie, dass dies das gleiche ist wie
r--r-x--x.
Entfernen Sie die Ausführungsrechte von other und group.
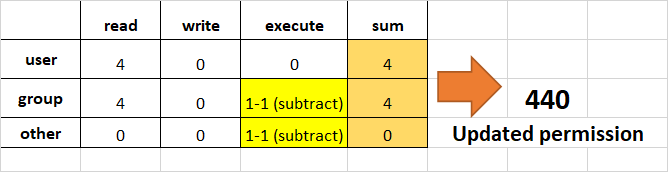
- Um die Ausführungsrechte von
otherundgroupzu entfernen, subtrahieren Sie 1 vom Ausführungs Teil der letzten 2 Bytes.
Geben Sie lesen, schreiben und ausführen dem Benutzer zu, lesen und ausführen der Gruppe und nur lesen den Anderen.

Das wäre das gleiche wie rwxr-xr--.
Wie man den Besitzer mit dem chown-Befehl ändert
Nächstes, lernen wir, wie man den Besitzer einer Datei ändert. Man kann den Besitzer einer Datei oder eines Ordners mit dem chown-Befehl ändern. In manchen Fällen erfordert das Ändern des Besitzers sudo-Berechtigungen.
chown user filename
Syntax von chown:
Wie man den Benutzerbesitzer mit chown ändert
Lassen Sie uns den Besitzer von Benutzer zaira auf Benutzer news übertragen.

chown news mymotd.sh
Befehl zum Ändern des Besitzers: sudo chown news mymotd.sh.

Ausgabe:
Wie man gleichzeitig den Benutzer- und die Gruppeneigentümer ändert
chown user:group filename
Wir können auch chown verwenden, um Benutzer und Gruppeneigentümer gleichzeitig zu ändern.
Wie man den Ordnerbesitzer ändert
chown -R admin /opt/script
Sie können den Besitzer rekursiv für die Inhalte eines Ordners ändern. Der folgende Befehl ändert den Besitzer des Ordners /opt/script, um dem Benutzer admin Zugriff zu gestatten.
Wie man die Gruppeneigentümerschaft ändert
chown :admins /opt/script
Falls wir nur die Gruppeneigentümer ändern müssen, können wir chown verwenden, indem wir den Gruppennamen durch ein Doppelpunkt : trennen.
Wie man zwischen Benutzern wechseln kann
[user01@host ~]$ su user02
Password:
[user02@host ~]$
Sie können zwischen Benutzern mit dem Befehl su wechseln.
Wie man Superuser-Zugriff erlangt
Der Superuser oder der Root-Benutzer hat die höchste Zugriffsstufe auf einem Linux-System. Der Root-Benutzer kann jede Operation auf dem System durchführen. Der Root-Benutzer kann alle Dateien und Verzeichnisse aufrufen, Software installieren und entfernen sowie Systemeinstellungen ändern oder überschreiben.
Mit großem Macht kommt große Verantwortung. Wenn der Root-Benutzer kompromittiert wird, kann jemand vollständige Kontrolle über das System erlangen. Es ist ratsam, den Root-Benutzer nur dann zu verwenden, wenn es notwendig ist.
[user01@host ~]$ su
Password:
[root@host ~]Wenn Sie den Benutzernamen weglassen, wechselt der su-Befehl standardmäßig in das Root-Benutzerkonto.
#
Eine andere Variante des su-Befehls ist der su --Befehl. Der su-Befehl wechselt in das Root-Benutzerkonto, ändert jedoch die Umgebungsvariablen nicht. Der su --Befehl wechselt in das Root-Benutzerkonto und ändert die Umgebungsvariablen auf die des Zielbenutzers.
Befehle mit sudo ausführen
Um Befehle als root-Benutzer auszuführen, ohne in das root-Benutzerkonto zu wechseln, kann Sie den Befehl sudo verwenden. Der sudo-Befehl ermöglicht es Ihnen, Befehle mit erhöhten Rechten auszuführen.
Das Ausführen von Befehlen mit sudo ist eine sicherere Option als das Ausführen von Befehlen als root-Benutzer. Dies liegt daran, dass nur ein bestimmter Benutzerstamm Berechtigungen erhalten kann, um mit sudo Befehle auszuführen. Dies ist in der Datei /etc/sudoers definiert.
Auch sudo protokolliert alle Befehle, die mit ihm ausgeführt werden, und stellt so eine Audit-Spur bereit, die zeigt, wer welche Befehle ausgeführt und wann.
cat /var/log/auth.log | grep sudo
In Ubuntu kann man die Audit-Logs hier finden:
user01 is not in the sudoers file. This incident will be reported.
Für einen Benutzer, der keinen Zugriff auf sudo hat, wird das in den Logs markiert und es wird einMessage wie dieses angezeigt:
Verwaltung lokaler Benutzerkonten
Erstellen von Benutzern von der Kommandozeile aus
sudo useradd username
Der Befehl, um einen neuen Benutzer hinzuzufügen, lautet:
Dieser Befehl richtet ein Home-Verzeichnis für den Benutzer ein und erstellt eine private Gruppe, die durch den Benutzernamen des Benutzers bezeichnet wird. Momentan fehlt dem Konto ein gültiges Passwort, was den Benutzer daran hindert, sich anzumelden, bis ein Passwort erstellt wird.
Ändern vorhandener Benutzer
Der Befehl usermod wird verwendet, um vorhandene Benutzer zu ändern. Hier sind einige der häufig verwendeten Optionen mit dem usermod-Befehl:
- Hier sind einige Beispiele des
usermod-Befehls in Linux: - Ändern des Benutzernamens eines Benutzers:
- Ändern Sie das Home-Verzeichnis eines Benutzers:
- Fügen Sie einem Benutzer einer Zusatzgruppe hinzu:
- Ändern Sie die Shell eines Benutzers:
- Sperren Sie das Konto eines Benutzers:
- Konto eines Benutzers freischalten:
- Festlegen eines Ablaufdatums für ein Benutzerkonto:
- Ändern der Benutzerkennung (UID) eines Benutzers:
- Ändern der primären Gruppe eines Benutzers:
einen Benutzer aus einer Zusatzgruppe entfernen:
Benutzer löschen
- Der Befehl
userdelwird verwendet, um ein Benutzerkonto und zugehörige Dateien vom System zu löschen. sudo userdel username: entfernt die Daten des Benutzers aus/etc/passwdaber behält das Heimatverzeichnis des Benutzers.
Der Befehl sudo userdel -r username entfernt die Daten des Benutzers aus /etc/passwd und löscht auch das Heimatverzeichnis des Benutzers.
Passwörter von Benutzern ändern
- Der Befehl
passwdwird verwendet, um ein Benutzerpasswort zu ändern.
sudo passwd username: setzt das anfängliche Passwort oder ändert das bestehende Passwort von username. Es wird auch verwendet, um das Passwort des aktuell angemeldeten Benutzers zu ändern.
8.2 Verbinden mit Remote-Server über SSH
Der Zugriff auf entfernte Server ist eine der grundlegenden Aufgaben für Systemadministratoren. Man kann über seine lokale Maschine auf verschiedene Server oder Datenbanken zugreifen und Befehle ausführen, alles mittels SSH.
Was ist das SSH-Protokoll?
SSH steht für Secure Shell. Es ist ein kryptographisches Netzwerkprotokoll, das eine sichere Kommunikation zwischen zwei Systemen ermöglicht.
Der Standardport für SSH ist 22.
- Die beiden Teilnehmer während der Kommunikation über SSH sind:
- Der Server: die Maschine, auf die du Zugriff haben möchtest.
Der Client: Das System, von dem du auf den Server zugreifst.
- Der Zugriff auf einen Server folgt diesen Schritten:
- Verbindungsinitiierung: Der Client sendet einen Verbindungsanfrage an den Server.
- Schlüsselaustausch: Der Server sendet seinen öffentlichen Schlüssel an den Client. Beide vereinbaren die zu verwendenden Verschlüsselungsmethoden.
- Session-Schlüsselgenerierung: Der Client und der Server verwenden den Diffie-Hellman-Schlüsselausgleich, um einen gemeinsamen Session-Schlüssel zu generieren.
- Clientenauthentifizierung: Der Client loggt sich beim Server mit einem Passwort, einem privaten Schlüssel oder einem anderen Verfahren ein.
Sichere Kommunikation: Nach der Authentifizierung kommunizieren Client und Server verschlüsselt.
Wie verbinde man sich mit einem entfernten Server mittels SSH?
Das ssh-Kommando ist eine integrierte Utility in Linux und auch die Voreinstellung. Es macht den Zugriff auf Server sehr einfach und sicher.
Hier geht es darum, wie der Client eine Verbindung zum Server herstellt.
- Bevor Sie sich mit einem Server verbinden, müssen Sie folgende Informationen haben:
- Die IP-Adresse oder der Domänenname des Servers.
- Das Benutzerkonto und das Passwort des Servers.
Die Portnummer, auf die Sie im Server zugreifen können.
ssh username@server_ip
Die grundlegende Syntax des ssh-Befehls lautet:
ssh [email protected]
Zum Beispiel, wenn Ihr Benutzername john ist und die Server-IP 192.168.1.10 ist, lautet der Befehl:
[email protected]'s password:
Welcome to Ubuntu 20.04.2 LTS (GNU/Linux 5.4.0-70-generic x86_64)
* Documentation: https://help.ubuntu.com
* Management: https://landscape.canonical.com
* Support: https://ubuntu.com/advantage
System information as of Fri Jun 5 10:17:32 UTC 2024
System load: 0.08 Processes: 122
Usage of /: 12.3% of 19.56GB Users logged in: 1
Memory usage: 53% IP address for eth0: 192.168.1.10
Swap usage: 0%
Last login: Fri Jun 5 09:34:56 2024 from 192.168.1.2
john@hostname:~$ Dann werden Sie aufgefordert, das geheime Passwort einzugeben. Ihr Bildschirm wird etwa wie folgt aussehen:
# Starte die Eingabe von Befehlen
Nun kannst du auf dem Server 192.168.1.10 die entsprechenden Befehle ausführen.
ssh -p port_number username@server_ip
⚠️ Der Standardport für SSH ist 22, aber er ist auch anfällig, da黑客 hier zuerst versuchen werden. Ihr Server kann einen anderen Port exponieren und Ihnen den Zugriff teilen. Um zu einem anderen Port zu verbinden, verwende das Flag -p.
8.3. Erweiterte Protokollauswertung und -analyse
Protokolle, wenn konfiguriert, werden Ihrem System aus verschiedenen nützlichen Gründen generiert. Sie können zur Verfolgung von Systemereignissen, Überwachung der Systemleistung und Problembehandlung verwendet werden. Sie sind insbesondere für Systemadministratoren nützlich, wo sie auf Application-Fehler, Netzeevents und Benutzeraktivität zugreifen können.
Hier ist ein Beispiel für ein Protokolldatei:
2024-04-25 09:00:00 INFO Startup: Application starting
2024-04-25 09:01:00 INFO Config: Configuration loaded successfully
2024-04-25 09:02:00 DEBUG Database: Database connection established
2024-04-25 09:03:00 INFO User: New user registered (UserID: 1001)
2024-04-25 09:04:00 WARN Security: Attempted login with incorrect credentials (UserID: 1001)
2024-04-25 09:05:00 ERROR Network: Network timeout on request (ReqID: 456)
2024-04-25 09:06:00 INFO Email: Notification email sent (UserID: 1001)
2024-04-25 09:07:00 DEBUG API: API call with response time over threshold (Duration: 350ms)
2024-04-25 09:08:00 INFO Session: User session ended (UserID: 1001)
2024-04-25 09:09:00 INFO Shutdown: Application shutdown initiated
# Beispielprotokolldatei
- Eine Protokolldatei enthält normalerweise die folgenden Spalten:
- Zeitstempel: Der Tag und die Uhrzeit, an dem das Ereignis passierte.
- Protokollebene: Die Schwere des Ereignisses (INFO, DEBUG, WARN, FEHLER).
- Komponente: Die Systemkomponente, die das Ereignis ausgelöst hat (Startup, Config, Datenbank, Benutzer, Sicherheit, Netzwerk, E-Mail, API, Session, Herunterfahren).
- Nachricht: Eine Beschreibung des aufgetretenen Ereignisses.
Zusätzliche Informationen: Zusätzliche Informationen, die mit dem Ereignis in Verbindung stehen.
In Echtzeit-Systemen sind Logdateien oft mehrere tausend Zeilen lang und erzeugt jede Sekunde. Sie können je nach Konfiguration sehr langatmig sein. Jede Spalte in einer Logdatei ist ein Stück Information, das verwendet werden kann, um Probleme aufzuklären. Dies macht Logdateien schwer lesbar und zu verstehen.
Hier kommt die Log-Verarbeitung ins Spiel. Die Log-Verarbeitung besteht darin, nutzbare Informationen aus Logdateien herauszukriegen. Es umfasst das Zerlegen der Logdateien in kleinere, einfacher zu bewältigende Teile und den Extrahieren der relevanten Informationen.
Die gefilterten Informationen können auch für das Erstellen von Alarmmeldungen, Berichten und Dashboards nützlich sein.
In diesem Abschnitt werden Sie einige Techniken zum Parsen von Logdateien in Linux erkunden.
Text Extraktion mit grep
Grep ist ein integriertes Bash-Werkzeug. Es steht für „global regular expression print“ (globaler regulärer Ausdruck drucken). Grep wird verwendet, um Zeichenfolgen in Dateien abzusuchen.
- Hier sind einige allgemeine Verwendungen von
grep: - Dieser Befehl sucht nach der Zeichenkette „search_string“ in der Datei mit dem Namen
filename. - Dieser Befehl sucht nach der Zeichenkette „
search_string“ in allen Dateien innerhalb des angegebenen Verzeichnisses und seiner Unterverzeichnisse. - Dieser Befehl führt eine Groß-/Kleinschreibungslosigkeitssuche für „search_string“ in der Datei mit dem Namen
filenamedurch. - Dieser Befehl zeigt die Zeilennummern zusammen mit den passenden Zeilen im Dateinamen
filenamean. - Dieser Befehl zählt die Anzahl der Zeilen, die „search_string“ in dem Dateinamen
filenameenthalten. - Dieser Befehl zeigt alle Zeilen an, die „search_string“ in der Datei mit dem Namen
filenamenicht enthalten. - Dieser Befehl sucht das ganze Wort „Wort“ in der Datei mit dem Namen
filename.
Dieser Befehl ermöglicht die Nutzung von erweiterten regulären Ausdrücken für komplexere Mustermatching in der Datei mit dem Namen filename.
💡 Tipp: Wenn es mehrere Dateien in einem Ordner gibt, können Sie den folgenden Befehl verwenden, um die Liste der Dateien zu finden, die die gewünschten Zeichenfolgen enthalten.
grep -l "String to Match" /path/to/directory
# Finde die Liste der Dateien, die die gewünschten Zeichenfolgen enthalten
Text Extraktion mit sed
sed steht für „stream editor“. Es verarbeitet Daten zeilenweise, was bedeutet, es liest Daten Zeile für Zeile. sed ermöglicht es Ihnen, nach Mustern zu suchen und Aktionen auf die zutreffenden Zeilen durchzuführen.
Basierender Syntax vonsed:
sed [options] 'command' file_name
Der grundlegende Syntax von sed lautet wie folgt:
Hierbei ist Befehl der verwendete Befehl, um Operationen wie Substitution, Löschung, Einfügen usw. auf Textdaten durchzuführen. Der Dateiname ist der Name der Datei, die Sie verarbeiten wollen.
sedVerwendung:
1. Substitution:
sed 's/old-text/new-text/' filename
Das s-Zeichen wird verwendet, um Text zu ersetzen. Der alte-Text wird mit neuer-Text ersetzt:
sed 's/error/warning/' system.log
Zum Beispiel, um alle Vorkommen von „error“ in der Logdatei system.log auf „warning“ zu ändern:
2. Zeilen mit bestimmtem Muster drucken:
sed -n '/pattern/p' filename
Verwendung von sed, um Zeilen zu filtern und anzuzeigen, die einem bestimmten Muster entsprechen:
sed -n '/ERROR/p' system.log
Zum Beispiel, um alle Zeilen mit „ERROR“ zu finden:
3. Zeilen mit bestimmtem Muster löschen:
sed '/pattern/d' filename
Sie können Zeilen aus dem Ausgabestream löschen, die einem bestimmten Muster entsprechen:
sed '/DEBUG/d' system.log
Zum Beispiel, um alle Zeilen mit „DEBUG“ zu entfernen:
4. Auswählen bestimmter Felder aus einer Logzeile:
sed -n 's/^\([0-9]\{4\}-[0-9]\{2\}-[0-9]\{2\}\).*/\1/p' system.log
Sie können reguläre Ausdrücke verwenden, um Teile von Zeilen zu extrahieren. Nehmen wir an, jeder Protokollzeile beginnt mit einem Datum im Format „JJJJ-MM-TT“. Sie könnten aus jeder Zeile nur das Datum extrahieren:
Textverarbeitung mit awk
awk verfügt über die Fähigkeit, jede Zeile in Felder aufzuteilen. Es ist gut geeignet für die Verarbeitung strukturierter Texte wie Protokolldateien.
Basis Syntax vonawk
awk 'pattern { action }' file_name
Die grundlegende Syntax von awk lautet:
Hier ist Muster ein Kriterium, das erfüllt werden muss, damit die Aktion durchgeführt wird. Wenn das Muster weggelassen wird, wird die Aktion auf jeder Zeile durchgeführt.
2024-04-25 09:00:00 INFO Startup: Application starting
2024-04-25 09:01:00 INFO Config: Configuration loaded successfully
2024-04-25 09:02:00 INFO Database: Database connection established
2024-04-25 09:03:00 INFO User: New user registered (UserID: 1001)
2024-04-25 09:04:00 INFO Security: Attempted login with incorrect credentials (UserID: 1001)
2024-04-25 09:05:00 INFO Network: Network timeout on request (ReqID: 456)
2024-04-25 09:06:00 INFO Email: Notification email sent (UserID: 1001)
2024-04-25 09:07:00 INFO API: API call with response time over threshold (Duration: 350ms)
2024-04-25 09:08:00 INFO Session: User session ended (UserID: 1001)
2024-04-25 09:09:00 INFO Shutdown: Application shutdown initiated
INFO
- In den folgenden Beispielen verwenden Sie diese Protokolldatei als Beispiel:
Spalten zugänglich machen mitawk
zaira@zaira-ThinkPad:~$ awk '{ print $1 }' sample.log
Die Felder in awk (standardmäßig durch Leerzeichen getrennt) können mit $1, $2, $3 usw. aufgerufen werden.
2024-04-25
2024-04-25
2024-04-25
2024-04-25
2024-04-25
2024-04-25
2024-04-25
2024-04-25
2024-04-25
2024-04-25
zaira@zaira-ThinkPad:~$ awk '{ print $2 }' sample.log
# Ausgabe
09:00:00
09:01:00
09:02:00
09:03:00
09:04:00
09:05:00
09:06:00
09:07:00
09:08:00
09:09:00
- # Ausgabe
awk '/ERROR/ { print $0 }' logfile.log
Drucke Zeilen, die ein bestimmtes Muster enthalten (z.B. ERROR)
2024-04-25 09:05:00 ERROR Network: Network timeout on request (ReqID: 456)
# Ausgabe
- Dies druckt alle Zeilen, die den Worten „ERROR“ enthalten.
awk '{ print $1, $2 }' logfile.log
Extrahiere das erste Feld (Datum und Zeit)
2024-04-25 09:00:00
2024-04-25 09:01:00
2024-04-25 09:02:00
2024-04-25 09:03:00
2024-04-25 09:04:00
2024-04-25 09:05:00
2024-04-25 09:06:00
2024-04-25 09:07:00
2024-04-25 09:08:007
2024-04-25 09:09:00
# Ausgabe
- Dadurch wird das erste und zweite Feld von jeder Zeile extrahiert, was in diesem Fall das Datum und die Uhrzeit sein würde.
awk '{ count[$3]++ } END { for (level in count) print level, count[level] }' logfile.log
Zusammenfassung der Auftritte jedes Log-Levels
1
WARN 1
ERROR 1
DEBUG 2
INFO 6
# Ausgabe
- Die Ausgabe wird eine Zusammenfassung der Häufigkeit der jeweiligen Log-Ebene sein.
awk '{ $3="INFO"; print }' sample.log
Filtert bestimmte Felder aus (z.B., wenn das dritte Feld INFO ist)
2024-04-25 09:00:00 INFO Startup: Application starting
2024-04-25 09:01:00 INFO Config: Configuration loaded successfully
2024-04-25 09:02:00 INFO Database: Database connection established
2024-04-25 09:03:00 INFO User: New user registered (UserID: 1001)
2024-04-25 09:04:00 INFO Security: Attempted login with incorrect credentials (UserID: 1001)
2024-04-25 09:05:00 INFO Network: Network timeout on request (ReqID: 456)
2024-04-25 09:06:00 INFO Email: Notification email sent (UserID: 1001)
2024-04-25 09:07:00 INFO API: API call with response time over threshold (Duration: 350ms)
2024-04-25 09:08:00 INFO Session: User session ended (UserID: 1001)
2024-04-25 09:09:00 INFO Shutdown: Application shutdown initiated
INFO
# Ausgabe
Dieser Befehl wird alle Zeilen提取, in denen das dritte Feld „INFO“ ist.
💡 Tipp: Der Standard-Trennzeichen in awk ist ein Leerzeichen. Wenn Ihr Log-Datei ein anderes Trennzeichen verwendet, können Sie es mit der -F Option angeben. Zum Beispiel, wenn Ihre Log-Datei ein Doppelpunkt als Trennzeichen verwendet, können Sie awk -F: '{ print $1 }' logfile.log verwenden, um das erste Feld zu extrahieren.
Log-Dateien mit cut parsen
Der cut Befehl ist ein einfaches yet kraftvolles Kommando, das zum Extraktion von Abschnitten Text jedes Eingabestroms verwendet. Da Log-Dateien strukturiert sind und jedes Feld durch ein bestimmtes Zeichen getrennt ist, z.B. ein Leerzeichen, Tabulator oder ein benutzerdefiniertes Trennzeichen, ist cut sehr gut, um diese bestimmten Felder zu extrahieren.
cut [options] [file]
Die grundlegende Syntax des cut-Befehls lautet:
- Einige häufig verwendete Optionen für den cut-Befehl:
-d: Spezifiziert ein Trennzeichen, das als Feldtrenner verwendet wird.-f: Wählt die anzuzeigenden Felder aus.
-c : Gibt Zeichenpositionen an.
cut -d ' ' -f 1 logfile.log
Das folgende Kommando extrahiert beispielsweise das erste Feld (getrennt durch einen Leerzeichen) aus jeder Zeile der Logdatei:
Beispiele für die Verwendung voncutbei der Log-Parsing
2024-04-25 08:23:01 INFO 192.168.1.10 User logged in successfully.
2024-04-25 08:24:15 WARNING 192.168.1.10 Disk usage exceeds 90%.
2024-04-25 08:25:02 ERROR 10.0.0.5 Connection timed out.
...
Angenommen, Sie haben eine Logdatei mit folgender Struktur, wo die Felder durch Leerzeichen getrennt sind:
cutkann auf folgende Weise verwendet werden:
cut -d ' ' -f 2 system.log
Extrahieren der Zeit aus jedem Logeintrag:
08:23:01
08:24:15
08:25:02
...
# Ausgabe
- Dieses Kommando verwendet ein Leerzeichen als Trennzeichen und wählt das zweite Feld aus, was dem Zeitbestandteil jedes Logeintrags entspricht.
cut -d ' ' -f 4 system.log
Extrahieren der IP-Adressen aus den Logs:
192.168.1.10
192.168.1.10
10.0.0.5
# Ausgabe
- Dieses Kommando extrahiert das vierte Feld, das die IP-Adresse von jedem Logeintrag enthält.
cut -d ' ' -f 3 system.log
Extrahieren von Log-Leveln (INFO, WARNING, ERROR):
INFO
WARNING
ERROR
# Ausgabe
- Dies extrahiert das dritte Feld, das den Log-Level enthält.
Kombinieren voncutmit anderen Befehlen:
grep "ERROR" system.log | cut -d ' ' -f 1,2
Die Ausgabe anderer Befehle kann an den cut-Befehl weitergeleitet werden. Angenommen, Sie möchten Logs filtern, bevor Sie sie zerschneiden. Sie können grep verwenden, um Zeilen zu extrahieren, die "ERROR" enthalten, und dann cut, um bestimmte Informationen aus diesen Zeilen zu erhalten:
2024-04-25 08:25:02
# Ausgabe
- Dieser Befehl filtert zunächst die Zeilen, die den Wert „ERROR“ enthalten, und extrahiert dann die Daten und Uhrzeit aus diesen Zeilen.
Mehrere Felder extrahieren:
cut -d ' ' -f 1,2,3 system.log`
Es ist möglich, mehrere Felder gleichzeitig zu extrahieren, indem ein Bereich oder eine durch Kommas getrennte Liste von Feldern angegeben wird:
2024-04-25 08:23:01 INFO
2024-04-25 08:24:15 WARNING
2024-04-25 08:25:02 ERROR
...
# Ausgabe
Der oben genannte Befehl extrahiert die ersten drei Felder von jedem Protokoll-Eintrag, die Datum, Uhrzeit und Protokoll-Stufe sind.
Protokolldateien mit sort und uniq parsen
Sortieren und Duplikate entfernen sind häufige Operationen, wenn man mit Protokolldateien arbeitet. Die Befehle sort und uniq sind mächtige Befehle, die zum Sortieren und Entfernen von Duplikaten aus der Eingabe verwendet werden können.
Basis-Syntax von sort
sort [options] [file]
Der Befehl sort ordnet Textzeilen alphabetisch oder numerisch auf.
- Einige wichtige Optionen für den sort-Befehl:
-n: Sortiert die Datei unter der Annahme, dass der Inhalt numerisch ist.-r: Kehrt die Reihenfolge des Sorts um.-k: Gibt einen Schlüssel oder Spaltennummer an, nach der sortiert werden soll.
-u: Sortiert und entfernt gleiche Zeilen.
Der Befehl `uniq` wird verwendet, um in einer Datei gefilterte oder zählte und gemeldete wiederholte Zeilen auszugeben.
uniq [options] [input_file] [output_file]
Die Syntax von `uniq` lautet:
- Einige wichtige Optionen für den Befehl `uniq` sind:
-c: Fügt Zeilen durch die Anzahl der Vorkommen vor.-d: Gibt nur doppelte Zeilen aus.
-u: Gibt nur eindeutige Zeilen aus.
Beispiele der Verwendung von `sort` und `uniq` zusammen für die Protokollauswertung
2024-04-25 INFO User logged in successfully.
2024-04-25 WARNING Disk usage exceeds 90%.
2024-04-26 ERROR Connection timed out.
2024-04-25 INFO User logged in successfully.
2024-04-26 INFO Scheduled maintenance.
2024-04-26 ERROR Connection timed out.
- Nehmen wir an, die folgenden Beispielprotokoll-Einträge für diese Demonstrationen:
sort system.log
Sortieren von Protokoll-Einträgen nach Datum:
2024-04-25 INFO User logged in successfully.
2024-04-25 INFO User logged in successfully.
2024-04-25 WARNING Disk usage exceeds 90%.
2024-04-26 ERROR Connection timed out.
2024-04-26 ERROR Connection timed out.
2024-04-26 INFO Scheduled maintenance.
# Ausgabe
- Dies sortiert die Protokoll-Einträge alphabetisch, was effektiv das Sortieren nach Datum bedeutet, wenn das Datum der erste Feld ist.
sort system.log | uniq
Sortieren und Entfernen von Doppelungen:
2024-04-25 INFO User logged in successfully.
2024-04-25 WARNING Disk usage exceeds 90%.
2024-04-26 ERROR Connection timed out.
2024-04-26 INFO Scheduled maintenance.
# Ausgabe
- Dieser Befehl sortiert die Protokolldatei und leitet sie an `uniq` weiter, entfernt Doppelungen.
sort system.log | uniq -c
Zählen der Vorkommen jeder Zeile:
2 2024-04-25 INFO User logged in successfully.
1 2024-04-25 WARNING Disk usage exceeds 90%.
2 2024-04-26 ERROR Connection timed out.
1 2024-04-26 INFO Scheduled maintenance.
# Ausgabe
- Sortiert die Protokoll-Einträge und zählt dann jede eindeutige Zeile. Gemäß der Ausgabe ist die Zeile
'2024-04-25 INFO User logged in successfully.'2 Mal in der Datei enthalten.
sort system.log | uniq -u
Unique Log Einträge identifizieren:
2024-04-25 WARNING Disk usage exceeds 90%.
2024-04-26 INFO Scheduled maintenance.
# Ausgabe
- Dieser Befehl zeigt einzigartige Zeilen an.
sort -k2 system.log
nach Log-Level sortieren:
2024-04-26 ERROR Connection timed out.
2024-04-26 ERROR Connection timed out.
2024-04-25 INFO User logged in successfully.
2024-04-25 INFO User logged in successfully.
2024-04-26 INFO Scheduled maintenance.
2024-04-25 WARNING Disk usage exceeds 90%.
# Ausgabe
Einträge werden aufgrund des zweiten Feldes sortiert, das das Log-Level ist.
8.4. Linux-Prozesse über die Befehlszeile verwalten
- Ein Prozess ist eine laufende Instanz eines Programms. Ein Prozess besteht aus:
- Einem Adressraum des zugewiesenen Speichers.
- Prozesszuständen.
Eigenschaften wie Besitz, Sicherheitseigenschaften und Ressourcenverwendung.
- Ein Prozess hat auch ein Umgebungsfeld, das besteht aus:
- Lokalen und globalen Variablen
- Dem aktuellen Scheduling-Kontext
Zugewiesenen Systemressourcen, wie z.B. Netzwerkports oder Dateideskriptoren.
Wenn Sie den Befehl ls -l ausführen, erzeugt das Betriebssystem einen neuen Prozess, um den Befehl auszuführen. Der Prozess hat eine ID, einen Zustand und läuft, bis der Befehl beendet ist.
Verstehen Sie die Prozesserzeugung und den Lebenszyklus.
In Ubuntu starten alle Prozesse von dem ursprünglichen Systemprozess namens systemd, der beim Booten durch den Kernel als erstester Prozess initialisiert wird.
Der Prozess systemd hat eine Prozesskennung (PID) von 1 und ist verantwortlich für die Systeminitialisierung, das Starten und die Verwaltung anderer Prozesse sowie die Handhabung von Systemdiensten. Alle anderen Prozesse auf dem System sind Nachkommen von systemd.
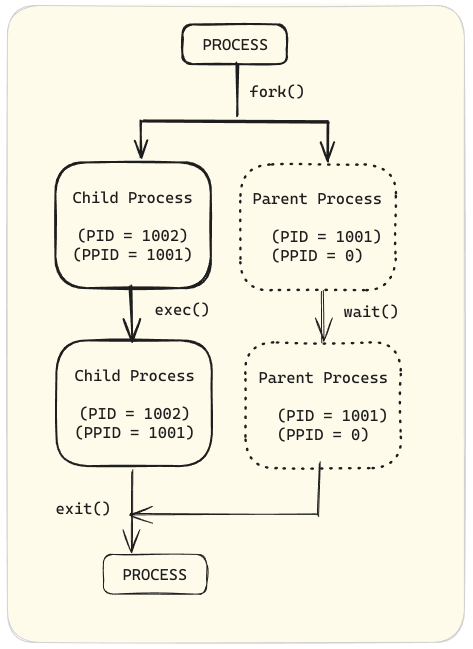
Ein Elternprozess dupliziert seinen eigenen Adressraum (fork) um eine neue (kindliche) Prozessstruktur zu schaffen. Jedem neuen Prozess wird eine eindeutige Prozesskennung (PID) zugewiesen, um ihn zu verfolgen und zu schützen. Die PID und die PID des Elternprozesses (PPID) gehören zum Umfeld des neuen Prozesses. Jeder Prozess kann einen Kindprozess erzeugen.
Durch die Fork-Routine erbt ein Kindprozess Sicherheitsidentitäten, vorherige und aktuelle Dateideskriptoren, Port- und Ressourcenberechtigungen, Umgebungsvariablen und Programmcode. Ein Kindprozess kann dann seinen eigenen Programmcode ausführen.
Normalerweise schläft ein Elternprozess während der Ausführung des Kindprozesses und setzt einen Antrag (wait), um informiert zu werden, wenn das Kind fertig ist.
Beim Verlassen des Kindprozesses wurde bereits seine Ressourcen geschlossen oder verworfen und sein Umfeld. Die einzige verbleibende Ressource, die als Zombie bezeichnet wird, ist eine Eintragung in die Prozessliste. Der Elternprozess wird signalisiert, dass er aufgewacht ist, als das Kind existiert und bereinigt die Prozessliste von den Einträgen des Kindprozesses, sodass die letzte Ressource des Kindprozesses freigegeben wird. Der Elternprozess führt dann seinen eigenen Programmcode fort.
Der Verständnis der Prozesszustände

Prozesse in Linux gehen während ihres Lebenszyklus durch verschiedene Zustände. Der Zustand eines Prozesses zeigt an, was der Prozess derzeit tätig ist und wie er mit dem System interagiert. Die Prozesse wechseln zwischen Zuständen basierend auf ihrem Ausführungsstatus und dem Scheduling-Algorithmus des Systems.
| Die Prozesse in einem Linux-System können sich in einem der folgenden Zustände befinden: | Zustand |
| Beschreibung | (neu) |
| Anfänglicher Zustand, wenn ein Prozess über einen Fork-Systemaufruf erstellt wird. | Ausführbar (bereit) (R) |
| Prozess ist bereit zu laufen und wartet auf die Planung auf einen CPU. | Ausführend (benutzer) (R) |
| Prozess führt Anwendungen im Benutzermodus aus. | Ausführend (kernel) (R) |
| Prozess führt im Kernelmodus Systemaufrufe oder Hardware-Interrupts aus. | Schlafend (S) |
| Prozess wartet auf einen Ereignis (z.B. Ein-/Ausgabearbeitung) abzuschließen und kann leicht erwacht werden. | Schlafend (ununterbrochen) (D) |
| Prozess befindet sich in einem ununterbrochenen Schlafzustand und wartet auf eine bestimmte Bedingung (üblicherweise Ein-/Ausgabearbeitung) abzuschließen; er kann durch Signale nicht unterbrochen werden. | Schlafend ( Festplatten Schlaf) (K) |
| Prozess wartet auf die Vollendung von Festplatten Ein-/Ausgabearbeitungen. | Schlafend (leer) (I) |
| Prozess ist leer, führt keine Arbeit aus und wartet auf ein Ereignis. | Beendet (T) |
| Der Prozess wurde durch einen Signal abgebrochen und kann später fortgesetzt werden. | Zombie (Z) |
Der Prozess hat seine Ausführung beendet, hat jedoch im Prozess-Tabellen eine Eintragung und wartet darauf, dass sein Elternprozess seine Beendigungssatus lesen kann.
| Die Prozesse wechseln zwischen diesen Zuständen auf folgende Weise: | Übergang |
| Beschreibung | Fork |
| Erzeugt aus einem Elternprozess einen neuen Prozess, wechselnd von (neu) in den Laufbar-(bereit) Zustand (R). | Planen |
| Der Planer wählt einen lauffähigen Prozess aus und wechselt ihn in den laufenden (benutzerdefiniert) oder laufenden (Kernel) Zustand. | Ausführen |
| Prozess wechselt von lauffähig (bereit) (R) in den laufenden (Kernel) (R) Zustand, wenn er für die Ausführung gewählt wird. | Vorrang oder Neuplanung |
| Prozess kann vorrangig oder neu Planned werden, versetzt ihn in den lauffähig (bereit) (R) Zustand. | Systemaufruf |
| Prozess führt einen Systemaufruf aus, wechselnd von laufend (benutzerdefiniert) (R) in den laufenden (Kernel) (R) Zustand. | Rückkehr |
| Prozess beendet einen Systemaufruf und kehrt zu laufend (benutzerdefiniert) (R) zurück. | Warten |
| Prozess wartet auf ein Ereignis und wechselt von laufend (Kernel) (R) in einen der Schlafzustände (S, D, K oder I) über. | Ereignis oder Signal |
| Der Prozess wird durch ein Ereignis oder Signal geweckt und wechselt von einem Träumestatus in den Bereitstellungsstatus (R) zurück. | Ausführen abbrechen |
| Der Prozess wird unterbrochen, wenn er im Betrieb (Kernel) oder im Bereitstellungsstatus (fertig) ist, und wechselt in den Beendigungsstatus (T). | Fortsetzen |
| Der Prozess wird fortgesetzt und wechselt von dem Beendigungsstatus (T) in den Bereitstellungsstatus (fertig) (R) zurück. | Beenden |
| Der Prozess wird beendet und wechselt vom Betrieb (benutzer) oder vom Betrieb (Kernel) in den Zombie-Status (Z). | Zombie-Prozess auflösen |
Der Elternprozess liest das Beenden-Ergebnis des Zombie-Prozesses und entfernt ihn aus der Prozess-Tabelle.
Wie man Prozesse anzeigt
zaira@zaira:~$ ps aux
Du kannst die ps-Anweisung verwenden und Kombinationen von Optionen, um Prozesse auf einem Linux-System anzuzeigen. Die ps-Anweisung wird verwendet, um Informationen über eine Auswahl von aktiven Prozessen anzuzeigen. Zum Beispiel zeigt ps aux alle Prozesse an, die auf dem System laufen.
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
root 1 0.0 0.0 168140 11352 ? Ss May21 0:18 /sbin/init splash
root 2 0.0 0.0 0 0 ? S May21 0:00 [kthreadd]
root 3 0.0 0.0 0 0 ? I< May21 0:00 [rcu_gp]
root 4 0.0 0.0 0 0 ? I< May21 0:00 [rcu_par_gp]
root 5 0.0 0.0 0 0 ? I< May21 0:00 [slub_flushwq]
root 6 0.0 0.0 0 0 ? I< May21 0:00 [netns]
root 11 0.0 0.0 0 0 ? I< May21 0:00 [mm_percpu_wq]
root 12 0.0 0.0 0 0 ? I May21 0:00 [rcu_tasks_kthread]
root 13 0.0 0.0 0 0 ? I May21 0:00 [rcu_tasks_rude_kthread]
*... output truncated ....*
# Ausgabe
- Die obenstehende Ausgabe zeigt ein snapshot der laufenden Prozesse auf dem System. Jede Zeile steht für einen Prozess mit den folgenden Spalten:
USER: Der Benutzer, der den Prozess besitzt.PID: Die Prozess-ID.%CPU: Der CPU-Verbrauch des Prozesses.%MEM: Der Speicherverbrauch des Prozesses.VSZ: Die Größe des virtuellen Speicheradressraums des Prozesses.RSS: Die Größe der adjacen Speicherseite, d.h. der nicht getauschten physischen Speicher, der von einer Aufgabe verwendet wurde.TTY: Das Steuerterminal des Prozesses. Ein?zeigt an, dass kein Steuerterminal vorhanden ist.Ss: Sitzungsleiter. Dies ist ein Prozess, der eine Sitzung启动, und er ist der Anführer eines Prozessgruppen und kann Terminal-Signale kontrollieren. Der ersteSweist auf den Schlafzustand hin, und der zweiteszeigt an, dass es ein Sitzungsleiter ist.START: Der Startzeitpunkt oder -datum des Prozesses.TIME: Die kumulierte CPU-Zeit.
BEFEHL: Der Befehl, der den Prozess gestartet hat.
Hintergrund- und Vordergrundprozesse
In diesem Abschnitt lernen Sie, wie Sie Prozesse steuern können, indem Sie sie im Hintergrund oder Vordergrund ausführen.
Ein Job ist ein Prozess, der von einer Shell gestartet wird. Wenn Sie einen Befehl im Terminal ausführen, gilt er als Job. Ein Job kann im Vordergrund oder im Hintergrund laufen.
- Um Steuerung zu demonstrieren, erstellen Sie zunächst 3 Prozesse und führen Sie sie dann im Hintergrund aus. Anschließend werden Sie die Prozesse auflisten und zwischen Vordergrund und Hintergrund wechseln. Sie werden sehen, wie Sie sie schlafen legen oder komplett beenden können.
Erstellen Sie drei Prozesse
Öffnen Sie ein Terminal und starten Sie drei langfristige Prozesse. Verwenden Sie den sleep-Befehl, der den Prozess für eine bestimmte Anzahl von Sekunden laufen lässt.
sleep 300 &
sleep 400 &
sleep 500 &
# Führen Sie den Sleep-Befehl für 300, 400 und 500 Sekunden aus
- Das
&am Ende jedes Befehls sorgt dafür, dass der Prozess in den Hintergrund verschoben wird.
Anzeige von Hintergrundjobs
jobs
Verwenden Sie den jobs-Befehl, um die Liste der Hintergrundjobs anzuzeigen.
jobs
[1] Running sleep 300 &
[2]- Running sleep 400 &
[3]+ Running sleep 500 &
- Der Ausgabestring sollte etwa folgendermaßen aussehen:
Hintergrundjob in den Vordergrund bringen
fg %1
Um einen Hintergrundjob in den Vordergrund zu bringen, verwenden Sie den fg-Befehl gefolgt vom Jobnummer. Zum Beispiel, um den ersten Job (sleep 300) in den Vordergrund zu bringen:
- Dies bringt Job
1in den Vordergrund.
Den Vordergrundjob wieder ins Hintergrund bringen
Während die Aufgabe im Vordergrund abläuft, kannst du sie anhalten und in den Hintergrund verschieben, indem du Ctrl+Z drückst, um die Aufgabe anzuhalten.
zaira@zaira:~$ fg %1
sleep 300
^Z
[1]+ Stopped sleep 300
zaira@zaira:~$ jobs
Eine angehaltene Aufgabe sieht so aus:
[1]+ Stopped sleep 300
[2] Running sleep 400 &
[3]- Running sleep 500 &
# angehalte Aufgabe
Verwende nun den Befehl bg, um die mit ID 1 versehene Aufgabe im Hintergrund fortzusetzen.
# Drücke Ctrl+Z, um die Vordergrundaufgabe anzuhalten
bg %1
- # und führe sie anschließend im Hintergrund fort
jobs
[1] Running sleep 300 &
[2]- Running sleep 400 &
[3]+ Running sleep 500 &
Zeige die Aufgaben erneut an
- In diesem Übungsblatt hast du Folgendes erledigt:
- Drei Hintergrundprozesse mit Sleep-Befehlen gestartet.
- Verwendet ‚jobs‘ um die Liste der Hintergrundaufgaben anzuzeigen.
- Hat eine Aufgabe in den Vordergrund mit
fg %job_numbergebracht. - Aufgabe mit
Ctrl+Zangehalten und in den Hintergrund mitbg %job_numberverschoben.
Verwendet ‚jobs‘ erneut, um das Statuszeichen der Hintergrundaufgaben zu überprüfen.
Jetzt kannst du wie Aufgaben kontrolliert werden.
Prozessvernichtung
Es ist möglich, einen unresponsiven oder nicht gewünschten Prozess mit dem Befehl kill zu beenden. Der Befehl kill sendet ein Signal an eine Prozesskennung (PID), um ihn zu beenden.
Mit dem kill-Befehl stehen mehrere Optionen zur Verfügung.
kill -l
1) SIGHUP 2) SIGINT 3) SIGQUIT 4) SIGILL 5) SIGTRAP
6) SIGABRT 7) SIGBUS 8) SIGFPE 9) SIGKILL 10) SIGUSR1
11) SIGSEGV 12) SIGUSR2 13) SIGPIPE 14) SIGALRM 15) SIGTERM
16) SIGSTKFLT 17) SIGCHLD 18) SIGCONT 19) SIGSTOP 20) SIGTSTP
21) SIGTTIN 22) SIGTTOU 23) SIGURG 24)
...terminated
# Mit dem kill-Befehl verfügbare Optionen
- Hier sind einige Beispiele des
kill-Befehls in Linux: - Dieser Befehl sendet das Standard-Signal
SIGTERMan den Prozess mit der PID 1234, um ihn zu beenden. - Dieser Befehl sendet das Standard-Signal
SIGTERMan alle Prozesse mit der angegebenen Bezeichnung. - Dieser Befehl sendet das Signal
SIGKILLan den Prozess mit der PID 1234, beendet ihn gewaltsam. - Dieser Befehl sendet das Signal
SIGSTOPan den Prozess mit der PID 1234, stoppt ihn.
Dieser Befehl sendet das Standard-Signal SIGTERM an alle Prozesse des angegebenen Benutzers.
Diese Beispiele zeigen verschiedene Arten, den Befehl `kill` zu verwenden, um Prozesse in einem Linux-Umfeld zu verwalten.
| Hier ist die Information über die Optionen und Signale des Befehls `kill` in tabellarischer Form: Diese Tabelle zusammenfasset die am häufigsten verwendeten Optionen und Signale des `kill`-Befehls in Linux für die Prozessverwaltung. | Befehl / Option | Signal |
| Beschreibung | kill <pid> |
SIGTERM |
| Verlangt an den Prozess, gräzlich zu beenden (Standardsignal). | kill -9 <pid> |
SIGKILL |
| Zwingt den Prozess zum sofortigen Beenden ohne Aufräumarbeiten. | kill -SIGKILL <pid> |
SIGKILL |
| Zwingt den Prozess zum sofortigen Beenden ohne Aufräumarbeiten. | kill -15 <pid> |
SIGTERM |
Explizit sendet das Signal SIGTERM, um einen gräzlichen Beendigung zu verlangen. |
kill -SIGTERM <pid> |
SIGTERM |
Explizit sendet das Signal SIGTERM, um einen gräzlichen Beendigung zu verlangen. |
kill -1 <pid> |
SIGHUP |
| Traditionell bedeutet „hängen“; kann verwendet werden, um Konfigurationsdateien neu zu laden. | kill -SIGHUP <pid> |
SIGHUP |
| Traditionell bedeutet „hängen“; kann verwendet werden, um Konfigurationsdateien neu zu laden. | kill -2 <pid> |
SIGINT |
Verlangt das Beenden des Prozesses (ähnlich wie das Drücken von Ctrl+C im Terminal). |
kill -SIGINT <pid> |
SIGINT |
Verlangt das Beenden des Prozesses (ähnlich wie das Drücken von Ctrl+C im Terminal). |
kill -3 <pid> |
SIGQUIT |
| Veranlasst das Beenden des Prozesses und erzeugt einen Core- Dump zur Fehlersuche. | kill -SIGQUIT <pid> |
SIGQUIT |
| Veranlasst das Beenden des Prozesses und erzeugt einen Core- Dump zur Fehlersuche. | kill -19 <pid> |
SIGSTOP |
| Pausiert den Prozess. | kill -SIGSTOP <pid> |
SIGSTOP |
| Pausiert den Prozess. | kill -18 <pid> |
SIGCONT |
| Setzt einen pausierten Prozess fort. | kill -SIGCONT <pid> |
SIGCONT |
| Setzt einen pausierten Prozess fort. | killall <name> |
Varies |
| Sendet ein Signal an alle Prozesse mit der gegebenen Bezeichnung. | killall -9 <name> |
SIGKILL |
| Alle Prozesse mit dem gegebenen Namen werden abgeschaltet. | pkill |
Varies |
| Sendet ein Signal an Prozesse auf Basis eines Musterkompatibilitätsprinzips. | pkill -9 |
SIGKILL |
| Forciert den Absturz aller Prozesse, die dem Muster entsprechen. | xkill |
SIGKILL |
Grafische Anwendung, die es ermöglicht, auf ein Fenster zu klicken, um den entsprechenden Prozess zu beenden.
8.5. Standardeingabe- und Ausgabestroms in Linux
- Lesen einer Eingabe und Schreiben einer Ausgabe ist ein grundlegender Bestandteil des Verständnisses der Kommandozeile und der Shell-Skripte. In Linux hat jedes Programm drei Standardströme:
- Der Dateifilter für
stdinist0. - Standardausgabe (
stdout): Dies ist der Standard-Ausgabestrom, in dem ein Prozess seine Ausgabe schreibt. Standardmäßig ist die Standardausgabe das Terminal. Die Ausgabe kann auch in eine Datei oder ein anderes Programm umgeleitet werden. Der Dateideskriptor fürstdoutist1.
Standardfehler (stderr): Dies ist der Standard-Fehlerstrom, in dem ein Prozess seine Fehlermeldungen schreibt. Standardmäßig ist der Standardfehler das Terminal, sodass Fehlermeldungen auch dann gesehen werden können, wenn stdout umgeleitet ist. Der Dateideskriptor für stderr ist 2.
Umleitung und Pipelines
Umleitung: Sie können die Fehler- und Ausgabestrome in Dateien oder andere Befehle umleiten. Zum Beispiel:
ls > output.txt
# Leitet stdout in eine Datei um
ls non_existent_directory 2> error.txt
# Leitet stderr in eine Datei um
ls non_existent_directory > all_output.txt 2>&1
# Leitet sowohl stdout als auch stderr in eine Datei um
- Im letzten Befehl,
ls non_existent_directory: zeigt den Inhalt eines Verzeichnisses mit dem Namen non_existent_directory an. Da dieses Verzeichnis nicht existiert, generiert `ls` eine Fehlermeldung.> all_output.txt: Der Operator>leitet die Standardausgabe (stdout) des `ls`-Befehls in das Fileall_output.txtweiter. Wenn das File nicht existiert, wird es erstellt. Existiert es bereits, wird dessen Inhalt überschrieben.
2>&1: Hierbei steht 2 für das File-Deskriptor für die Standardfehlerausgabe (stderr). &1 steht für das File-Deskriptor für die Standardausgabe (stdout). Das &-Zeichen wird verwendet, um anzuzeigen, dass 1 nicht der Dateiname, sondern ein File-Deskriptor ist.
Also, 2>&1 bedeutet „fehlerhafte Ausgabe (2) an das gleiche Ort weiterleiten, wo standardmäßige Ausgabe (1) geleitet wird,“ was in diesem Fall das Datei all_output.txt ist. Daher werden sowohl die Ausgabe (falls vorhanden) als auch die Fehlermeldung von ls in all_output.txt geschrieben.
Pipelines:
ls | grep image
Sie können Pipes (|) verwenden, um die Ausgabe eines Befehls als Eingabe für einen anderen zu leiten:
image-10.png
image-11.png
image-12.png
image-13.png
... Output truncated ...
# Ausgabe
8.6 Automatisierung in Linux – Aufgaben mit Cron-Jobs automatisieren
Cron ist eine leistungsstarke Anwendung für die Planung von Aufgaben, die in Unix-ähnlichen Betriebssystemen verfügbar ist. Durch die Konfiguration von cron können automatisierte Jobs für die tägliche, wöchentliche, monatliche oder andere bestimmte Zeitbasis eingerichtet werden. Die automatisierungsfähigen Fähigkeiten von cron spielen eine entscheidende Rolle in der Linux-Systemadministration.
Der crond-Dienst (ein Art Computerprogramm, das im Hintergrund läuft) ermöglicht die cron-Funktionalität. Der cron liest die crontab (cron-Tabellen) für die Ausführung vordefinierter Skripte.
Durch die Verwendung einer bestimmten Syntax können cron-Jobs für Skripte oder andere Befehle automatisch eingestellt werden.
Was sind cron jobs in Linux?
Jeder Auftrag, der über crons geplant wird, wird als cron job bezeichnet.
Nun sehen wir, wie cron jobs funktionieren.
Wie die Zugriffssteuerung auf crons kontrolliert werden kann
Um cron jobs verwenden zu können, muss ein Admin cron jobs für Benutzer in der Datei /etc/cron.allow zulassen.
Wenn du einen wie diesen Hinweis erhältst, bedeutet das, dass du keine Berechtigung für den cron-Dienst hast.
![]()
Um John Berechtigungen für den cron-Dienst zu gewähren, musst du seinen Namen in /etc/cron.allow aufnehmen. Erstelle die Datei, falls sie nicht existiert. Dies wird John erlauben, cron-Jobs zu erstellen und zu bearbeiten.
Benutzer können auch Zugriff auf cron-Jobs verweigert werden, indem ihr Benutzername in der Datei /etc/cron.d/cron.deny eingetragen wird.
Wie man cron-Jobs in Linux hinzufügt
Zuerst musst du den Status des cron-Dienstes überprüfen, um cron-Jobs verwenden zu können. Wenn cron nicht installiert ist, kannst du ihn leicht über das Paketmanager herunterladen. Nutze dies nur, um zu überprüfen:
sudo systemctl status cron.service
# Überprüfe den cron-Dienst auf einem Linux-System
Cron-Job-Syntax
- Crontabs verwenden die folgenden Schalter, um cron-Jobs hinzuzufügen und aufzulisten:
crontab -e: bearbeitet crontab-Einträge, um cron-Jobs hinzuzufügen, zu löschen oder zu bearbeiten.crontab -l: listet alle cron-Jobs für den aktuellen Benutzer auf.crontab -u username -l: listet die cron-Jobs eines anderen Benutzers auf.
crontab -u username -e: bearbeitet die cron-Jobs eines anderen Benutzers.
Wenn du die cron-Jobs auflistest und sie existieren, siehst du etwas wie das folgende:
* * * * * sh /path/to/script.sh
Beispiel für einen Cron-Job
- In dem obigen Beispiel,
* steht für Minute(n), Stunde(n), Tag(e), Monat(e) und Wochentag(e). Hier die Details zu diesen Werten: |
WERT | |
| BESCHREIBUNG | Minuten | 0-59 |
| Der Befehl wird in der angegebenen Minute ausgeführt. | Stunden | 0-23 |
| Der Befehl wird in der angegebenen Stunde ausgeführt. | Tage | 1-31 |
| Befehle werden an diesen Tagen des Monats ausgeführt. | Monate | 1-12 |
| Der Monat, in dem die Aufgaben ausgeführt werden sollen. | Wochentage | 0-6 |
- Die Wochentage, an denen die Befehle laufen. Hier ist 0 Sonntag.
shbedeutet, dass das Skript ein Bash-Skript ist und von/bin/bashausgeführt werden sollte.
/pfad/zum/skript.sh gibt den Pfad zum Skript an.
* * * * * sh /path/to/script/script.sh
| | | | | |
| | | | | Command or Script to Execute
| | | | |
| | | | |
| | | | |
| | | | Day of the Week(0-6)
| | | |
| | | Month of the Year(1-12)
| | |
| | Day of the Month(1-31)
| |
| Hour(0-23)
|
Min(0-59)
Unten ist eine Zusammenfassung der Cron-Job-Syntax:
Beispiele für Cron-Jobs
| Unten einige Beispiele für die Planung von Cron-Jobs. | ZEITPLAN |
| GEPLANTE WERT | 5 0 * 8 * |
| Am 5. August um 00:05. | 5 4 * * 6 |
| Am Samstag um 04:05. | 0 22 * * 1-5 |
Am Abend um 22:00 jeden Tag von Montag bis Freitag.
Es ist in Ordnung, wenn du alles nicht auf einmal verstehst. Du kannst auf der crontab guru Website cron-Zeiten praktizieren und generieren.
Wie du einen cron Job einrichtest
- In diesem Abschnitt werden wir ein Beispiel anschauen, wie man mit einem cron Job einen einfachen Skript planen kann.
#!/bin/bash
echo `date` >> date-out.txt
Erstelle ein Skript namens date-script.sh, das das Systemdatum und -uhrzeit ausgibt und es in eine Datei anfügt. Das Skript ist unten angegeben:
chmod 775 date-script.sh
2. Gebe dem Skript ausführungsrechte durch das Setzen von Exec-Rechten.
3. Füge das Skript in die crontab hinzu, indem du crontab -e verwendest.
*/1 * * * * /bin/sh /root/date-script.sh
Hier haben wir es so eingestellt, dass es jeden Minute ausgeführt wird.
cat date-out.txt
4. Überprüfe die Ausgabe der Datei date-out.txt. Laut dem Skript sollte die Systemdatum und -uhrzeit jeden Minute in diese Datei geschrieben werden.
Wed 26 Jun 16:59:33 PKT 2024
Wed 26 Jun 17:00:01 PKT 2024
Wed 26 Jun 17:01:01 PKT 2024
Wed 26 Jun 17:02:01 PKT 2024
Wed 26 Jun 17:03:01 PKT 2024
Wed 26 Jun 17:04:01 PKT 2024
Wed 26 Jun 17:05:01 PKT 2024
Wed 26 Jun 17:06:01 PKT 2024
Wed 26 Jun 17:07:01 PKT 2024
# Ausgabe
Wie man crons diagnostiziert
Crons sind sehr hilfreich, arbeiten jedoch nicht immer wie gewünscht. Glücklicherweise gibt es einige wirkungsvolle Methoden, die du verwenden kannst, um sie zu diagnostizieren.
1. Prüfe die Planung.
Erstens kannst du versuchen, die für den cron Job eingestellte Planung zu überprüfen. Du kannst das mit der Syntax tun, die du in den obigen Abschnitten gesehen hast.
2. Prüfe cron-Protokolle.
Zunächst müssen Sie überprüfen, ob der cron-Job zu der vorgesehenen Zeit ausgeführt wurde. In Ubuntu können Sie dies aus den cron-Protokollen in /var/log/syslog überprüfen.
Wenn in diesen Protokollen eine Eintragung zu der richtigen Zeit existiert, bedeutet das, dass der cron-Job gemäß Ihrer Planung ausgeführt wurde.
1 Jun 26 17:02:01 zaira-ThinkPad CRON[27834]: (zaira) CMD (/bin/sh /home/zaira/date-script.sh)
2 Jun 26 17:02:02 zaira-ThinkPad systemd[2094]: Started Tracker metadata extractor.
3 Jun 26 17:03:01 zaira-ThinkPad CRON[28255]: (zaira) CMD (/bin/sh /home/zaira/date-script.sh)
4 Jun 26 17:03:02 zaira-ThinkPad systemd[2094]: Started Tracker metadata extractor.
5 Jun 26 17:04:01 zaira-ThinkPad CRON[28538]: (zaira) CMD (/bin/sh /home/zaira/date-script.sh)
Nachfolgend sehen Sie die Protokolle unseres cron-Beispiels. Beachten Sie die erste Spalte, die das Zeitstempel anzeigt. Der Pfad des Skripts wird auch am Ende der Zeile angegeben. Die Linien 1, 3 und 5 zeigen an, dass das Skript wie gewünscht ausgeführt wurde.
3. Leite das cron-Ausgaben in eine Datei weiter.
Sie können die Ausgabe eines cron-Jobs in eine Datei weiterleiten und die Datei auf mögliche Fehler durchsuchen.
* * * * * sh /path/to/script.sh &> log_file.log
# Leite die cron-Ausgaben in eine Datei weiter
8.7. Grundlagen der Linux-Netzwerktechnik
Linux bietet eine Reihe von Befehlen an, um Informationen zu Netzwerken anzuzeigen. In diesem Abschnitt werden wir einige dieser Befehle kurz diskutieren.
Anzeige von Netzwerkinterfaces mit ifconfig
ifconfig
Der Befehl ifconfig gibt Informationen über Netzwerkinterfaces aus. Hier ist ein Beispielausgabe:
eth0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 192.168.1.100 netmask 255.255.255.0 broadcast 192.168.1.255
inet6 fe80::a00:27ff:fe4e:66a1 prefixlen 64 scopeid 0x20<link>
ether 08:00:27:4e:66:a1 txqueuelen 1000 (Ethernet)
RX packets 1024 bytes 654321 (654.3 KB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 512 bytes 123456 (123.4 KB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
lo: flags=73<UP,LOOPBACK,RUNNING> mtu 65536
inet 127.0.0.1 netmask 255.0.0.0
inet6 ::1 prefixlen 128 scopeid 0x10<host>
loop txqueuelen 1000 (Local Loopback)
RX packets 256 bytes 20480 (20.4 KB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 256 bytes 20480 (20.4 KB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
# Ausgabe
Die Ausgabe des Befehls ifconfig zeigt die im System konfigurierten Netzwerkinterfaces auf, zusammen mit Details wie IP-Adressen, MAC-Adressen, Paketstatistiken und mehr.
Diese Interfaces können physische oder virtuelle Geräte sein.
Um IPv4- und IPv6-Adressen herauszuziehen, können Sie ip -4 addr und ip -6 addr verwenden, respectively.
Netzwerkaktivität anzeigen mitnetstat
Der Befehl netstat zeigt Netzwerkaktivität und -statistiken an, indem er folgende Informationen liefert:
- Hier sind einige Beispiele für die Verwendung des
netstat-Befehls in der Kommandozeile: - Alle hörenden und nicht hörenden Sockets anzeigen:
- Nur hörende Ports anzeigen:
- Netzwerkstatistiken anzeigen:
- Routing-Tabelle anzeigen:
- TCP-Verbindungen anzeigen:
- UDP-Verbindungen anzeigen:
- Netzwerkschnittstellen anzeigen:
- Anzeige der PIDs und Programmnamen für Verbindungen:
- Statistiken für ein bestimmtes Protokoll anzeigen (z.B. TCP):
Zeige erweiterte Informationen:
Prüfe die Netzwerkverbindung zwischen zwei Geräten mit ping
ping google.com
ping wird verwendet, um die Netzwerkverbindung zwischen zwei Geräten zu testen. Es sendet ICMP-Pakete an das Zielgerät und wartet auf eine Antwort.
ping google.com
PING google.com (142.250.181.46) 56(84) bytes of data.
64 bytes from fjr04s06-in-f14.1e100.net (142.250.181.46): icmp_seq=1 ttl=60 time=78.3 ms
64 bytes from fjr04s06-in-f14.1e100.net (142.250.181.46): icmp_seq=2 ttl=60 time=141 ms
64 bytes from fjr04s06-in-f14.1e100.net (142.250.181.46): icmp_seq=3 ttl=60 time=205 ms
64 bytes from fjr04s06-in-f14.1e100.net (142.250.181.46): icmp_seq=4 ttl=60 time=100 ms
^C
--- google.com ping statistics ---
4 packets transmitted, 4 received, 0% packet loss, time 3001ms
rtt min/avg/max/mdev = 78.308/131.053/204.783/48.152 ms
ping testet, ob Sie eine Antwort ohne Timeout erhalten.
— google.com ping Statistiken —
Sie können die Antwort mit Strg + C stoppen.
Teste Endpunkte mit der curl-Befehl
- Der Befehl
curlsteht für „Client URL“. Er wird verwendet, um Daten zu versenden oder von Servern zu empfangen. Er kann auch verwendet werden, um API-Endpunkte zu testen, die bei der Fehlersuche im System und in Anwendungen hilfreich sind.
curl http://www.official-joke-api.appspot.com/random_joke
{"type":"general",
"setup":"What did the fish say when it hit the wall?","punchline":"Dam.","id":1}
- Als Beispiel können Sie
http://www.official-joke-api.appspot.com/verwenden, um mit demcurl-Befehl zu experimentieren.
curl -o random_joke.json http://www.official-joke-api.appspot.com/random_joke
Der curl-Befehl ohne jegliche Optionen verwendet standardmäßig den GET-Methode.
curl -ospeichert die Ausgabe in der angegeben Datei.
curl -I http://www.official-joke-api.appspot.com/random_joke
HTTP/1.1 200 OK
Content-Type: application/json; charset=utf-8
Vary: Accept-Encoding
X-Powered-By: Express
Access-Control-Allow-Origin: *
ETag: W/"71-NaOSpKuq8ChoxdHD24M0lrA+JXA"
X-Cloud-Trace-Context: 2653a86b36b8b131df37716f8b2dd44f
Content-Length: 113
Date: Thu, 06 Jun 2024 10:11:50 GMT
Server: Google Frontend
# speichert die Ausgabe in random_joke.json
curl -I holt nur die Kopfzeilen.
8.8. Linux Fehlerbehebung: Tools und Techniken
Systemaktivitätsbericht mit sar
Der sar-Befehl in Linux ist ein leistungsstarkes Werkzeug zur Sammlung, Darstellung und Speicherung von Systemaktivitätsinformationen. Er ist Teil des sysstat-Pakets und wird häufig zur Überwachung der Systemleistung im Verlauf genutzt.
Um sar zu verwenden, müssen Sie zunächst sysstat installieren, indem Sie sudo apt install sysstat verwenden.
Nach der Installation sollten Sie den Dienst mit sudo systemctl start sysstat starten.
Den Status können Sie mit sudo systemctl status sysstat überprüfen.
sar [options] [interval] [count]
Sobald der Status aktiv ist, beginnt das System die verschiedenen Statistiken zu sammeln, die Sie verwenden können, um auf historische Daten zuzugreifen und zu analysieren. Wir werden das in aller Detail anschließend sehen.
sar -u 1 3
Die Syntax des Befehls sar lautet wie folgt:
Linux 6.5.0-28-generic (zaira-ThinkPad) 04/06/24 _x86_64_ (12 CPU)
19:09:26 CPU %user %nice %system %iowait %steal %idle
19:09:27 all 3.78 0.00 2.18 0.08 0.00 93.96
19:09:28 all 4.02 0.00 2.01 0.08 0.00 93.89
19:09:29 all 6.89 0.00 2.10 0.00 0.00 91.01
Average: all 4.89 0.00 2.10 0.06 0.00 92.95
Zum Beispiel wird der Befehl sar -u 1 3 CPU-Nutzungsstatistiken jedes Sekunden für drei Mal anzeigen.
# Ausgabe
Hier sind einige allgemeine Anwendungsfälle und Beispiele, wie Sie den sar-Befehl verwenden können.
Der sar-Befehl kann für eine Vielzahl von Zwecken verwendet werden:
sar -r 1 3
Linux 6.5.0-28-generic (zaira-ThinkPad) 04/06/24 _x86_64_ (12 CPU)
19:10:46 kbmemfree kbavail kbmemused %memused kbbuffers kbcached kbcommit %commit kbactive kbinact kbdirty
19:10:47 4600104 8934352 5502124 36.32 375844 4158352 15532012 65.99 6830564 2481260 264
19:10:48 4644668 8978940 5450252 35.98 375852 4165648 15549184 66.06 6776388 2481284 36
19:10:49 4646548 8980860 5448328 35.97 375860 4165648 15549224 66.06 6774368 2481292 116
Average: 4630440 8964717 5466901 36.09 375852 4163216 15543473 66.04 6793773 2481279 139
1. Speichernutzung
Um die Speichernutzung (frei und belegt) zu überprüfen, verwenden Sie:
Dieser Befehl zeigt jede Sekunde drei mal Speicherstatistiken an.
sar -S 1 3
sar -S 1 3
Linux 6.5.0-28-generic (zaira-ThinkPad) 04/06/24 _x86_64_ (12 CPU)
19:11:20 kbswpfree kbswpused %swpused kbswpcad %swpcad
19:11:21 8388604 0 0.00 0 0.00
19:11:22 8388604 0 0.00 0 0.00
19:11:23 8388604 0 0.00 0 0.00
Average: 8388604 0 0.00 0 0.00
2. Swap-Speicherbelegung
Um Swap-Speicherbelegungsstatistiken anzuzeigen, verwenden Sie:.
Dieser Befehl hilft dabei, den Swap-Speicherverbrauch zu überwachen, was für Systeme entscheidend ist, die außerhalb des physischen Arbeitsspeichers arbeiten.
sar -d 1 3
3. Ein-/Ausgabegerätelast
Um Aktivität für Blockgeräte und Blockgerätepartitionen zu melden:
Dieser Befehl stellt detaillierte Statistiken über Datenübertragungen zwischen Blockgeräten und darüber, was hinein und hinaus getätigt wird, bereit und ist nützlich zur Diagnose von I/O-Bottlenecks.
sar -n DEV 1 3
5. Netzwerkstatistiken
sar -n DEV 1 3
Linux 6.5.0-28-generic (zaira-ThinkPad) 04/06/24 _x86_64_ (12 CPU)
19:12:47 IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s %ifutil
19:12:48 lo 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
19:12:48 enp2s0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
19:12:48 wlp3s0 10.00 3.00 1.83 0.37 0.00 0.00 0.00 0.00
19:12:48 br-5129d04f972f 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
.
.
.
Average: IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s %ifutil
Average: lo 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
Average: enp2s0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
...output truncated...
Um Netzwerkstatistiken anzuzeigen, wie z.B. die Anzahl der empfangenen (gesendeten) Pakete pro Netzwerkschnittstelle:
# -n DEV leitet sar darauf hin, Netzwerkschnittstellen von Geräten zu berichten
Dies zeigt Netzwerkstatistiken alle Sekunden für drei Sekunden an, was der Überwachung des Netzwerkverkehrs hilft.
- 6. Historische Daten
- # sind „true“ und „false“. Bitte legen Sie keine anderen Werte fest, da
- Intervall für Datenerfassung einrichten: Bearbeiten Sie die Cron-Job-Konfiguration, um das Intervall für Datenerfassung einzustellen.
sar -u -f /var/log/sysstat/sa04
Linux 6.5.0-28-generic (zaira-ThinkPad) 04/06/24 _x86_64_ (12 CPU)
15:20:49 LINUX RESTART (12 CPU)
16:13:30 LINUX RESTART (12 CPU)
18:16:00 CPU %user %nice %system %iowait %steal %idle
18:16:01 all 0.25 0.00 0.67 0.08 0.00 99.00
Average: all 0.25 0.00 0.67 0.08 0.00 99.00
Ersetzen Sie <TT> mit dem Tag des Monats, für den Sie Daten anzeigen möchten.
In dem folgenden Befehl zeigt /var/log/sysstat/sa04 Statistiken für den vierten Tag des aktuellen Monats auf.
sar -I SUM 1 3
7. Echtzeit-CPU-Interruptionen
Linux 6.5.0-28-generic (zaira-ThinkPad) 04/06/24 _x86_64_ (12 CPU)
19:14:22 INTR intr/s
19:14:23 sum 5784.00
19:14:24 sum 5694.00
19:14:25 sum 5795.00
Average: sum 5757.67
Um Echtzeit-Interrupts pro Sekunde, die vom CPU abgewickelt werden, anzuzeigen, verwenden Sie diesen Befehl:
# Ausgabe
Dieser Befehl hilft dabei, zu überwachen, wie oft die CPU Interrupts behandelt, was für die Optimierung der Echtzeit-Leistung wichtig sein kann.
Diese Beispiele zeigen, wie Sie sar verwenden können, um verschiedene Aspekte der Systemleistung zu überwachen. Die regelmäßige Nutzung von sar kann helfen, Systemengpässe zu erkennen und sicherzustellen, dass Anwendungen effizient weiterlaufen.
8.9. Allgemeine Troubleshooting-Strategie für Server
Warum müssen wir Überwachung verstehen?
Systemüberwachung ist ein wichtiger Aspekt der Systemadministration. Kritische Anwendungen erfordern ein hohes Maß an Proaktivität, um Ausfälle zu vermeiden und die Ausfallwirkung zu verringern.
Linux bietet sehr leistungsfähige Tools, um den Systemzustand zu überprüfen. In diesem Abschnitt erfahren Sie mehr über die verschiedenen Methoden, die Ihnen zur Verfügung stehen, um den Zustand Ihres Systems zu überprüfen und Engpässe zu erkennen.
[user@host ~]$ uptime 19:15:00 up 1:04, 0 users, load average: 2.92, 4.48, 5.20
Belastungsdurchschnitt und Systembetriebszeit finden
Systemneustarts können vorkommen, die manchmal einige Konfigurationen durcheinander bringen. Um zu überprüfen, wie lange die Maschine bereits läuft, verwenden Sie den Befehl: uptime. Neben der Betriebszeit zeigt der Befehl auch den Belastungsdurchschnitt an.
Der Belastungsdurchschnitt ist die Systembelastung der letzten 1, 5 und 15 Minuten. Ein kurzer Blick kann anzeigen, ob die Systembelastung im Laufe der Zeit zu steigen oder zu fallen scheint.
Hinweis: Idealer CPU-Warteschlange ist 0. Dies ist nur möglich, wenn es keine Warteschlangen für die CPU gibt.
lscpu
Die CPU-basierte Belastung kann berechnet werden, indem der Belastungsdurchschnitt durch die Gesamtanzahl der verfügbaren CPUs dividiert wird.
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Address sizes: 48 bits physical, 48 bits virtual
Byte Order: Little Endian
CPU(s): 12
On-line CPU(s) list: 0-11
.
.
.
output omitted
Um die Anzahl der CPUs zu ermitteln, verwenden Sie den Befehl lscpu.
# Ausgabe
Wenn die Lastdarstellung zunimmt und nicht abfällt, sind die CPUs überlastet. Ein Prozess kann blockiert sein oder es besteht ein Speicherleck.
free -mh
Berechnung freier Speicher
total used free shared buff/cache available
Mem: 14Gi 3.5Gi 7.7Gi 109Mi 3.2Gi 10Gi
Swap: 8.0Gi 0B 8.0Gi
Manchmal kann eine hohe Speichernutzung Probleme verursachen. Um den verfügbaren Speicher und den in Verwendung befindlichen Speicher zu überprüfen, kann der Befehl free verwendet werden.
# Ausgabe
Berechnung der Festplattenfläche
df -h
Filesystem Size Used Avail Use% Mounted on
tmpfs 1.5G 2.4M 1.5G 1% /run
/dev/nvme0n1p2 103G 34G 65G 35% /
tmpfs 7.3G 42M 7.2G 1% /dev/shm
tmpfs 5.0M 4.0K 5.0M 1% /run/lock
efivarfs 246K 93K 149K 39% /sys/firmware/efi/efivars
/dev/nvme0n1p3 130G 47G 77G 39% /home
/dev/nvme0n1p1 511M 6.1M 505M 2% /boot/efi
tmpfs 1.5G 140K 1.5G 1% /run/user/1000
Um das System gesund zu halten, sollten Sie sich auch um die Festplattenfläche kümmern. Um alle verfügbaren Mount-Punkte und ihre jeweiligen verwendeten Prozente aufzulisten, kann der folgende Befehl verwendet werden. Idealerweise sollten die verwendeten Festplattenflächen nicht über 80% hinausgehen.
Der Befehl df stellt detaillierte Festplattenflächen bereit.
Bestimmung der Prozesszustände
[user@host ~]$ ps aux
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
runner 1 0.1 0.0 1535464 15576 ? S 19:18 0:00 /inject/init
runner 14 0.0 0.0 21484 3836 pts/0 S 19:21 0:00 bash --norc
runner 22 0.0 0.0 37380 3176 pts/0 R+ 19:23 0:00 ps aux
Prozesszustände können verwaltet werden, um herauszufinden, ob ein Prozess mit hoher Speicher- oder CPU-Nutzung blockiert ist.
Wir haben zuvor gesehen, dass der Befehl ps nützliche Informationen über ein Prozess bereitstellt. Schauen Sie auf die Spalten CPU und MEM ein.
Echtzeitüberwachung des Systems
Echtzeitüberwachung bietet einen Einblick in den aktuellen Zustand des Systems.
Ein für diesen Zweck verwendbares Werkzeug ist der Befehl top.
Der Befehl top zeigt eine dynamische Ansicht der Prozesse des Systems, beginnend mit einer Zusammenfassungstabelle gefolgt von einer Liste der Prozesse oder Threads. Im Gegensatz zu seiner statischen Variante ps aktualisiert top die Systemstatistiken kontinuierlich.
Mit top kann man in einer kompakten Fensterstruktur gut organisierte Details anschauen. Es gibt eine Reihe von Flags,快捷方式和 Hervorhebungsmethoden, die mit top kombiniert werden können.
Sie können auch Prozesse mit top beenden. Dafür müssen Sie die Taste k drücken und dann die Prozess-ID eingeben.
Protokollauswertung
System- und Anwendungsp Protokolle führen eine Menge Informationen über das System auf. Sie enthalten nützliche Informationen und Fehlernummern, die auf Fehler hinweisen. Wenn Sie nach Fehlernummern in Protokollen suchen, kann die Problemidentifizierung und die Zeit bis zur Korrektur stark reduziert werden.
Netzwerkportsanalyse
Der Netzwerkaspekt sollte nicht vernachlässigt werden, da Netzwerkschwierigkeiten häufig vorkommen und das System und den Datenverkehr beeinträchtigen können. Common Netzwerkprobleme einschließlich Portauslösung, Portblockaden, unveröffentlichten Ressourcen usw.
| Um solche Probleme zu identifizieren, müssen Sie Portzustände verstehen. | Einige der Portzustände werden hier kurz erklärt: |
| Zustand | Beschreibung |
| LISTEN | Stellt Ports dar, die auf eine Verbindungsanfrage von irgendeinem entfernten TCP- und Port warten. |
| ESTABLISHED | Stellt offene Verbindungen dar, bei denen Daten empfangen werden können, die an die Zieladresse geliefert werden können. |
| TIME WAIT | Stellt die Wartezeit dar, um sicherzustellen, dass die Anfrage zur Bestätigung ihrer Verbindungsbeendigung abgegeben wird. |
FIN WAIT2
Stellt die Wartezeit dar, bis ein Verbindungsabbau von dem entfernten TCP angefordert wird.
[user@host ~]$ /sbin/sysctl net.ipv4.ip_local_port_range
net.ipv4.ip_local_port_range = 15000 65000
Erkunden wir, wie wir in Linux auf Port-bezogene Informationen zugreifen können.
Portbereiche: Portbereiche werden im System definiert und können entsprechend erhöht oder verringert werden. In dem untenstehenden Auszug ist der Bereich von 15000 bis 65000, was einen insgesamt von 50000 (65000 – 15000) Ports bedeutet. Wenn die verwendeten Ports dieses Limit erreichen oder überschreitet, handelt es sich um ein Problem.
Der in solchen Fällen im Log erfasste Fehler kann Fehler beim Binden an Port oder Zu viele Verbindungen sein.
Erkennung von Paketverlust
Bei der Systemüberwachung müssen wir sicherstellen, dass die Ausgangs- und Eingangsverbindung intakt ist.
[user@host ~]$ ping 10.13.6.113
PING 10.13.6.141 (10.13.6.141) 56(84) bytes of data.
64 bytes from 10.13.6.113: icmp_seq=1 ttl=128 time=0.652 ms
64 bytes from 10.13.6.113: icmp_seq=2 ttl=128 time=0.593 ms
64 bytes from 10.13.6.113: icmp_seq=3 ttl=128 time=0.478 ms
64 bytes from 10.13.6.113: icmp_seq=4 ttl=128 time=0.384 ms
64 bytes from 10.13.6.113: icmp_seq=5 ttl=128 time=0.432 ms
64 bytes from 10.13.6.113: icmp_seq=6 ttl=128 time=0.747 ms
64 bytes from 10.13.6.113: icmp_seq=7 ttl=128 time=0.379 ms
^C
--- 10.13.6.113 ping statistics ---
7 packets transmitted, 7 received,0% packet loss, time 6001ms
rtt min/avg/max/mdev = 0.379/0.523/0.747/0.134 ms
Ein hilfreiches Kommando ist ping. ping schlägt das Zielsystem an und bringt die Antwort zurück. Beachten Sie die letzten paar Zeilen der Statistik, die den Prozentsatz des Paketverlusts und die Zeit angeben.
# ping Ziel-IP
Pakete können auch zur Laufzeit mit tcpdump erfasst werden. Wir werden dazu später schauen.
Sammeln von Statistiken für die Ursachenuntersuchung nach einem Problem
- Es ist immer eine gute Praxis, bestimmte Statistiken zu sammeln, die später hilfreich sein können, um die Ursache zu identifizieren. Normalerweise verlieren wir nach einem Systemneustart oder der Neustart von Dienstleistungen die vorhergehenden Systemsnapshots und Logs.
Nachfolgend sind einige der Methoden zu beschreiben, mit denen man ein System-Snapshot erstellt.
- Logs-Backup
Bevor Sie jederzeit Änderungen vornehmen, sollten Sie die Protokolldateien in eine andere Datenbank kopieren. Dies ist entscheidend, um zu verstehen, in welcher Verfassung das System zum Zeitpunkt des Vorfalls war. Manchmal sind die Protokolldateien die einzige Sicht auf die Vergangenheit des Systems, da andere Laufzeitstatistiken verloren gehen.
sudo tcpdump -i any -w
TCP Dump
Tcpdump ist ein Kommandozeilenwerkzeug, das es Ihnen ermöglicht, eingehende und ausgehende Netzwerkverkehr aufzunehmen und zu analysieren. Es wird hauptsächlich verwendet, um Netzwerkprobleme zu beheben. Wenn Sie denken, dass das Systemverkehr beeinträchtigt wird, führen Sie wie folgt tcpdump aus:
# Wobei,
# -i any Verkehr von allen Schnittstellen aufnimmt
# -w gibt den Dateinamen für die Ausgabe an
# Beenden Sie das Kommando nach ein paar Minuten, da die Dateigröße zunehmen kann
# Verwenden Sie die Dateiendung .pcap
Sobald Sie tcpdump aufgenommen haben, können Sie Werkzeuge wie Wireshark verwenden, um den Verkehr visuell zu analysieren.
Schlussfolgerung
Danke, dass Sie das Buch bis zum Ende gelesen haben. Wenn es Ihnen behilflich war, erwägen Sie, es mit anderen zu teilen.
Dieses Buch endet hier jedoch nicht. Ich werde es kontinuierlich verbessern und zukünftig neue Inhalte hinzufügen. Wenn Sie irgendwelche Probleme gefunden haben oder Verbesserungsvorschläge haben, nehmen Sie es mir frei, ein PR/Issue zu öffnen.
- Bleiben Sie mit uns verbunden und fahren Sie Ihren Lernprozess fort!
-
LinkedIn: Ich teile Artikel und Beiträge zu Technik dort. Hinterlassen Sie eine Empfehlung auf LinkedIn und bestätigen Sie meine relevanten Fähigkeiten.
Erhalte Zugang zu exklusivem Inhalt: Für individuelle Hilfe und exklusiven Inhalt gehe hier.
Erhalte Zugang zu exklusivem Inhalt: Für individuelle Hilfe und exklusiven Inhalt gehe hier.
Source:
https://www.freecodecamp.org/news/learn-linux-for-beginners-book-basic-to-advanced/