













Big Data hat sich seit seiner Entstehung in den späten 2000er Jahren erheblich weiterentwickelt. Viele Organisationen passten sich schnell dem Trend an und bauten ihre Big Data-Plattformen mit Open-Source-Tools wie Apache Hadoop auf. Später begannen diese Unternehmen, Schwierigkeiten bei der Verwaltung der sich schnell entwickelnden Anforderungen an die Datenverarbeitung zu haben. Sie standen vor Herausforderungen beim Umgang mit Änderungen auf Schema-Ebene, der Evolution von Partitionierungsschemata und dem Zurückblicken auf die Daten.
Ich hatte ähnliche Herausforderungen, als ich in den 2010er Jahren groß angelegte verteilte Systeme für ein großes Technologieunternehmen und einen Gesundheitskunden entwarf. Einige Branchen benötigen diese Fähigkeiten, um den Vorschriften im Bankwesen, Finanzwesen und im Gesundheitswesen gerecht zu werden. Datengetriebene Unternehmen wie Netflix standen ebenfalls vor ähnlichen Herausforderungen. Sie erfanden ein Tabellenformat namens „Iceberg“, das über den bestehenden Datendateien sitzt und wichtige Funktionen durch die Nutzung seiner Architektur bereitstellt. Dies ist schnell zum führenden ASF-Projekt geworden, da es in der Daten-Community schnell Interesse geweckt hat. In diesem Artikel werde ich die 5 wichtigsten Apache Iceberg Funktionen mit Beispielen und Diagrammen erkunden.
1. Zeitreise

Abbildung 1: Zeitreise im Apache Iceberg Tabellenformat (Bild erstellt vom Autor)
Dieses Feature ermöglicht es Ihnen, Ihre Daten zu einem beliebigen Zeitpunkt abzufragen. Dies eröffnet neue Möglichkeiten für Daten- und Business-Analysten, um Trends zu verstehen und wie sich die Daten im Laufe der Zeit entwickelt haben. Sie können mühelos zu einem vorherigen Zustand zurückkehren, falls Fehler auftreten. Dieses Feature erleichtert auch Prüfungen, indem es Ihnen erlaubt, die Daten zu einem bestimmten Zeitpunkt zu analysieren.
-- time travel to October 5th, 1978 at 07:00:00
SELECT * FROM prod.retail.cusotmers TIMESTAMP AS OF '1978-10-05 07:00:00';
-- time travel using a specific snapshot ID:
SELECT * FROM prod.retail.customers VERSON AS OF 949530903748831869;
2. Schema-Evolution
Die Schema-Evolution von Apache Iceberg ermöglicht Änderungen an Ihrem Schema ohne großen Aufwand oder kostspielige Migrationen. Wenn sich Ihre Geschäftsanforderungen weiterentwickeln, können Sie:
- Spalten hinzufügen und entfernen, ohne Ausfallzeiten oder Tabellen-Neuschreibungen.
- Die Spalte aktualisieren (Erweiterung).
- Die Reihenfolge der Spalten ändern.
- Eine vorhandene Spalte umbenennen.
Diese Änderungen werden auf der Metadatenebene verarbeitet, ohne dass die zugrunde liegenden Daten neu geschrieben werden müssen.
-- add a new column to the table
ALTER TABLE prod.retail.customers ADD COLUMNS (email_address STRING);
-- remove an existing column from the table
ALTER TABLE prod.retail.customers DROP COLUMN num_of_years;
-- rename an existing column
ALTER TABLE prod.retail.customers RENAME COLUMN email_address TO email;
-- iceberg allows updating column types from int to bigint, float to double
ALTER TABLE prod.retail.customers ALTER COLUMN customer_id TYPE bigint;
3. Partitionsevolution
Mit dem Apache Iceberg-Tabellenformat können Sie die Partitionierungsstrategie der Tabelle ändern, ohne die zugrunde liegende Tabelle neu zu schreiben oder die Daten in eine neue Tabelle zu migrieren. Dies wird ermöglicht, da Abfragen die Partitionierungswerte nicht direkt wie in Apache Hadoop referenzieren. Iceberg hält Metainformationen für jede Partition-Version separat. Dies erleichtert es, die Splits beim Abfragen der Daten zu erhalten. Zum Beispiel wird eine Tabelle basierend auf dem Datumsbereich abgefragt, während die Tabelle den Monat als Partitionierungsspalte (vorher) als einen Split und den Tag als neue Partitionierungsspalte (nachher) als einen weiteren Split verwendet. Dies wird als Split-Planung bezeichnet. Siehe das Beispiel unten.
-- create customers table partitioned by month of the create_date initially
CREATE TABLE local.retail.customer (
id BIGINT,
name STRING,
street STRING,
city STRING,
state STRING,
create_date DATE
USING iceberg
PARTITIONED BY (month(create_date));
-- insert some data into the table
INSERT INTO local.retail.customer VALUES
(1, 'Alice', '123 Maple St', 'Springfield', 'IL', DATE('2024-01-10')),
(2, 'Bob', '456 Oak St', 'Salem', 'OR', DATE('2024-02-15')),
(3, 'Charlie', '789 Pine St', 'Austin', 'TX', DATE('2024-02-20'));
-- change the partition scheme from month to date
ALTER TABLE local.retail.customer
REPLACE PARTITION FIELD month(create_date) WITH days(create_date);
-- insert couple more records
INSERT INTO local.retail.customer VALUES
(4, 'David', '987 Elm St', 'Portland', 'ME', DATE('2024-03-01')),
(5, 'Eve', '654 Birch St', 'Miami', 'FL', DATE('2024-03-02'));
-- select all columns from the table
SELECT * FROM local.retail.customer
WHERE create_date BETWEEN DATE('2024-01-01') AND DATE('2024-03-31');
-- output
1 Alice 123 Maple St Springfield IL 2024-01-10
5 Eve 654 Birch St Miami FL 2024-03-02
4 David 987 Elm St Portland ME 2024-03-01
2 Bob 456 Oak St Salem OR 2024-02-15
3 Charlie 789 Pine St Austin TX 2024-02-20
-- View parition details
SELECT partition, file_path, record_count
FROM local.retail.customer.files;
-- output
{"create_date_month":null,"create_date_day":2024-03-02} /Users/rellaturi/warehouse/retail/customer/data/create_date_day=2024-03-02/00000-6-ae2fdf0d-5567-4c77-9bd1-a5d9f6c83dfe-0-00002.parquet 1
{"create_date_month":null,"create_date_day":2024-03-01} /Users/rvellaturi/warehouse/retail/customer/data/create_date_day=2024-03-01/00000-6-ae2fdf0d-5567-4c77-9bd1-a5d9f6c83dfe-0-00001.parquet 1
{"create_date_month":648,"create_date_day":null} /Users/rvellaturi/warehouse/retail/customer/data/create_date_month=2024-01/00000-3-64c8b711-f757-45b4-828f-553ae9779d14-0-00001.parquet 1
{"create_date_month":649,"create_date_day":null} /Users/rvellaturi/warehouse/retail/customer/data/create_date_month=2024-02/00000-3-64c8b711-f757-45b4-828f-553ae9779d14-0-00002.parquet 2
4. ACID-Transaktionen
Iceberg bietet eine robuste Unterstützung für Transaktionen in Bezug auf Atomarität, Konsistenz, Isolation und Dauerhaftigkeit (ACID). Es ermöglicht mehrere gleichzeitige Schreibvorgänge, was eine hohe Durchsatzrate bei datenintensiven Aufgaben ermöglicht, ohne die Datenkonsistenz zu gefährden.
-- Start a transaction
START TRANSACTION;
-- Insert new records
INSERT INTO customers VALUES (1, 'John'), (2, 'Mike');
-- Update existing records
UPDATE customers SET column1 = 'Josh' WHERE id = 1;
-- Delete records
DELETE FROM customers WHERE id = 2;
-- Commit the transaction
COMMIT;
Alle Vorgänge in Iceberg sind transaktional, was bedeutet, dass die Daten trotz Ausfällen oder Änderungen an den Daten gleichzeitig konsistent bleiben.
-- Atomic update across multiple tables
START TRANSACTION;
UPDATE orders SET status = 'processed' WHERE order_id = 100;
INSERT INTO orders_processed SELECT * FROM orders WHERE order_id = 100;
COMMIT;
Es unterstützt auch verschiedene Isolationsstufen, die es Ihnen ermöglichen, Leistung und Konsistenz je nach Anforderungen auszubalancieren.
-- Set isolation level (syntax may vary depending on the query engine)
SET TRANSACTION ISOLATION LEVEL SERIALIZABLE;
-- Perform operations
SELECT * FROM customers WHERE id = 1;
UPDATE customers SET rec_status= 'updated' WHERE id = 1;
COMMIT;
Hier ist eine Zusammenfassung, die zeigt, wie Iceberg zeilenweise Aktualisierungen und Löschungen behandelt.
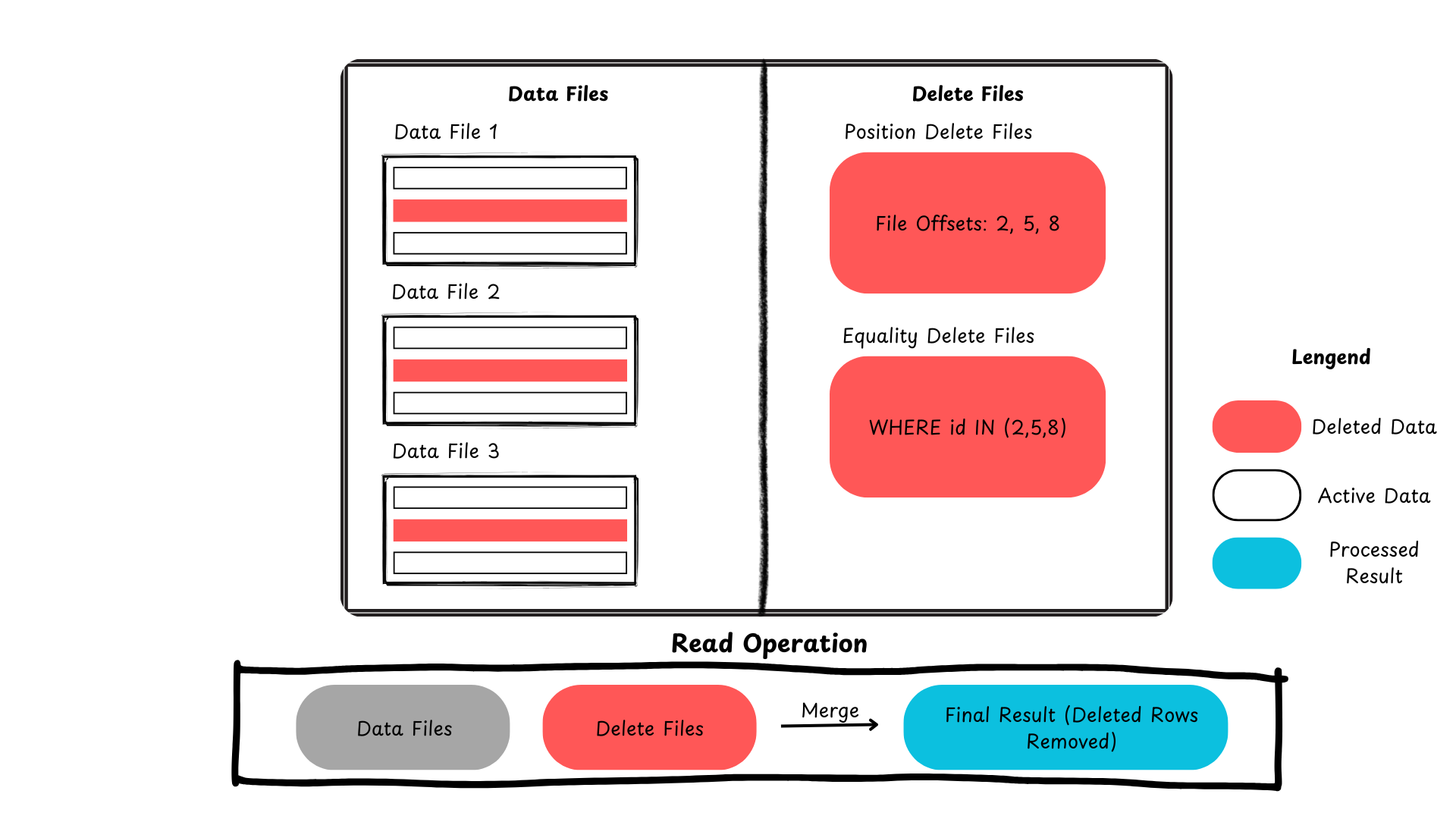
Abbildung 2: Löschvorgang von Datensätzen in Apache Iceberg (Bild erstellt vom Autor)
5. Erweiterte Tabellenoperationen
Iceberg unterstützt erweiterte Tabellenoperationen wie:
- Erstellen/Verwalten von Tabellenschnappschüssen: Dies ermöglicht eine robuste Versionskontrolle.
- Schnelle Abfrageplanung und -ausführung mit hochoptimierten Metadaten
- Integrierte Werkzeuge für die Tabellenwartung, wie Kompaktierung und Bereinigung von verwaisten Dateien
Iceberg ist darauf ausgelegt, mit allen großen Cloud-Speichern zu arbeiten, wie AWS S3, GCS und Azure Blob Storage. Außerdem lässt sich Iceberg problemlos mit Datenverarbeitungs-Engines wie Spark, Presto, Trino und Hive integrieren.
Abschließende Gedanken
Diese hervorgehobenen Funktionen ermöglichen es Unternehmen, moderne, flexible, skalierbare und effiziente Datenseen zu erstellen, die Zeitreisen ermöglichen, Schemaänderungen problemlos handhaben, ACID-Transaktionen unterstützen und eine Partitionsevolution bieten.
Source:
https://dzone.com/articles/key-features-of-apache-iceberg-for-data-lakes