













Was ist Elasticsearch?
Elasticsearch ist ein hoch skalierbarer und verteilter Such- und Analyseteil, der auf der Apache Lucene Suchbibliothek aufbaut. Es ist dafür konzipiert, große Mengen an strukturierten, halbstrukturierten und unstrukturierten Daten zu verarbeiten, wodurch es für eine Vielzahl von Anwendungsfällen geeignet ist, einschließlich Suchmaschinen, Protokollanalyse, E-Commerce und Sicherheitsanalysen.
Elasticsearch verwendet eine verteilte Architektur, die es ermöglicht, große Datenmengen auf mehrere Knoten in einem Cluster zu verteilen. Daten werden in Fragmenten indiziert und gespeichert, die für verbesserte Skalierbarkeit und Fehlertoleranz auf Knoten verteilt werden. Elasticsearch unterstützt auch Echtzeit-Suche und -Analyse, sodass Benutzer Daten in nahezu Echtzeit abfragen und analysieren können.
Eine der Schlüsselmerkmale von Elasticsearch sind seine leistungsstarken Suchfunktionen. Es unterstützt eine Vielzahl von Suchabfragen, einschließlich Volltextsuche, räumliche Suche usw. Es bietet auch Unterstützung für fortgeschrittene Analysefunktionen wie Aggregationen, Metriken und Datenvisualisierung.
Elasticsearch wird häufig in Kombination mit anderen Tools im Elastic Stack verwendet, einschließlich Logstash zur Datensammlung und -verarbeitung und Kibana zur Datenvisualisierung und -analyse. Zusammen bieten diese Tools eine umfassende Lösung für Such- und Analyseanwendungen, die für eine Vielzahl von Anwendungen und Anwendungsfällen verwendet werden können.
Was ist Apache Lucene?
Apache Lucene ist eine Open-Source-Suchbibliothek, die leistungsfähige Texterschließungs- und Indizierungskapazitäten bietet. Sie wird von Entwicklern und Organisationen häufig genutzt, um Suchanwendungen zu erstellen, von Suchmaschinen bis hin zu E-Commerce-Plattformen.
Lucene funktioniert, indem es den Textinhalt von Dokumenten indiziert und den Index in einer strukturierten Form speichert, die effizient durchsucht werden kann. Der Index besteht aus einer Reihe von invertierten Listen, die Abbildungen zwischen Begriffen und den Dokumenten liefern, die sie enthalten. Wenn eine Suchanfrage eingegeben wird, nutzt Lucene den Index, um schnell die Dokumente zu ermitteln, die der Anfrage entsprechen.
Zusätzlich zu seinen Kernfunktionen in Sachen Such- und Indizierungskapazitäten bietet Lucene eine Reihe von fortgeschrittenen Funktionen, einschließlich Unterstützung für unscharfe Suche und räumliche Suche. Es stellt auch Werkzeuge für die Hervorhebung von Suchergebnissen und die Bewertung von Suchergebnissen basierend auf Relevanz bereit.
Lucene wird von einer Vielzahl von Organisationen und Projekten, einschließlich Elasticsearch, genutzt. Seine umfangreichen Funktionen, Flexibilität und Erweiterbarkeit machen es zu einer beliebten Wahl für das Erstellen von Suchanwendungen aller Art.
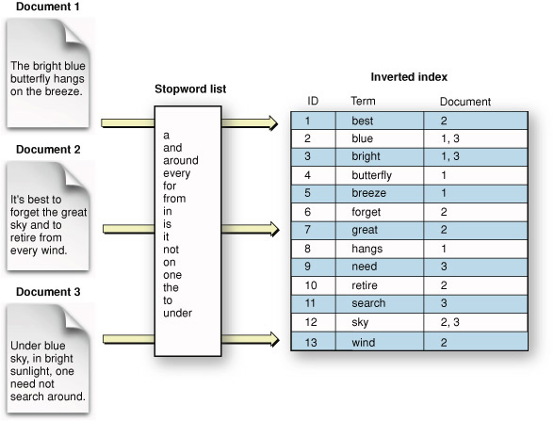
Was ist ein Invertierter Index?
Lucene’s Invertierter Index ist eine Datenstruktur, die zur effizienten Suche und Wiedergewinnung von Textdaten aus einer Sammlung von Dokumenten verwendet wird. Der Invertierte Index ist ein zentrales Merkmal von Lucene und wird verwendet, um die Begriffe und die ihnen zugeordneten Dokumente, die den Index ausmachen, zu speichern.
Der Umgekehrte Index bietet mehrere Vorteile gegenüber anderen Suchstrategien. Erstens ermöglicht er eine schnelle und effiziente Abfrage von Dokumenten basierend auf Suchbegriffen. Zweitens kann er mit einer großen Menge an Textdaten umgehen, was ihn ideal für Anwendungsfälle mit großen Dokumentensammlungen macht. Schließlich unterstützt er eine Vielzahl von fortgeschrittenen Suchfunktionen, wie z.B. unscharfes Matching und Stemming, die die Genauigkeit und Relevanz der Suchergebnisse verbessern können.
Warum Elasticsearch?
Es gibt mehrere Gründe, warum Elasticsearch eine beliebte Wahl für die Erstellung von Such- und Analyseanwendungen ist:
Leicht skalierbar (Verteilt): Elasticsearch ist von Grund auf für horizontale Skalierung konzipiert. Sobald mehr Kapazität benötigt wird, fügen Sie einfach weitere Knoten hinzu, und lassen Sie den Cluster sich selbst neuorganisieren, um die zusätzlichen Hardwareressourcen zu nutzen.
Ein Server kann ein oder mehrere Teile eines oder mehrerer Indizes enthalten, und wenn neue Knoten dem Cluster hinzugefügt werden, werden sie einfach der Party hinzugefügt. Jeder solche Index oder Teil davon wird als Shard bezeichnet, und Elasticsearch-Shards können sehr einfach im Cluster verschoben werden.
Alles ist eine JSON-Anfrage entfernt (RESTful API): Elasticsearch wird von APIs angetrieben. Fast jede Aktion kann mithilfe einer einfachen RESTful API unter Verwendung von JSON über HTTP ausgeführt werden. Antworten sind immer im JSON-Format.
Ungezügelte Macht von Lucene im Hintergrund: Elasticsearch nutzt intern Lucene, um seine herausragenden verteilten Such- und Analysefähigkeiten aufzubauen. Da Lucene eine stabile, bewährte Technologie ist und kontinuierlich mit weiteren Funktionen und Best Practices ergänzt wird, ist Lucene als unterliegende Engine, die Elasticsearch antreibt, von großem Vorteil.
Ausgezeichnetes Query DSL: Die REST-API bietet ein sehr komplexes und leistungsfähiges Query-DSL, das sehr einfach zu bedienen ist. Jede Abfrage ist lediglich ein JSON-Objekt, das praktisch jede Art von Abfrage oder sogar mehrere kombinierte enthalten kann. Durch das Verwenden von gefilterten Abfragen, bei denen einige Abfragen als Lucene-Filter ausgedrückt werden, kann die Caching-Funktion genutzt und damit häufige oder komplexe Abfragen, deren Teile wiederverwendet werden können, beschleunigt werden.
Multi-Tenancy: Mehrere Indizes können in einer Elasticsearch-Installation – Knoten oder Cluster – gespeichert werden. Das Schöne daran ist, dass man mehrere Indizes mit einer einfachen Abfrage durchsuchen kann.
Unterstützung für fortgeschrittene Suchfunktionen (Volltext): Elasticsearch nutzt unter der Haube Lucene, um die leistungsfähigsten Volltext-Suchfähigkeiten, die in irgendeinem Open-Source-Produkt verfügbar sind, bereitzustellen. Die Suche bietet Mehrsprachunterstützung, ein leistungsfähiges Abfragesprache, Unterstützung für Geolokation, kontextbezogene „Haben Sie das gemeint“-Vorschläge, Autovervollständigung und Suchzusammenfassungen. Skriptunterstützung in Filtern und Bewertern.
Konfigurierbar und Erweiterbar: Viele Elasticsearch-Konfigurationen können geändert werden, während Elasticsearch läuft, aber einige erfordern einen Neustart (und in einigen Fällen eine Neuindizierung). Die meisten Konfigurationen können auch mithilfe der REST-API geändert werden.
Dokumentenorientiert: Speichern Sie komplexe reale Weltentitäten in Elasticsearch als strukturierte JSON-Dokumente. Alle Felder werden standardmäßig indiziert und alle Indizes können in einer einzigen Abfrage verwendet werden, um Ergebnisse mit atemberaubender Geschwindigkeit zurückzugeben.
Schemalos: Elasticsearch ermöglicht Ihnen, sich leicht zu starten. Senden Sie ein JSON-Dokument, und es wird versuchen, die Datenstruktur zu erkennen, die Daten zu indizieren und sie durchsuchbar zu machen.
Konfliktmanagement: Optimistische Versionskontrolle kann dort verwendet werden, wo sie benötigt wird, um sicherzustellen, dass Daten aufgrund von konfliktären Änderungen aus mehreren Prozessen niemals verloren gehen.
Aktive Community: Die Community, neben dem Erstellen schöner Tools und Plugins, ist sehr hilfsbereit und unterstützend. Die allgemeine Stimmung ist großartig, und dies ist ein wichtiger Indikator für jedes OSS-Projekt. Es werden auch einige Bücher von Community-Mitgliedern geschrieben und viele Blog-Beiträge im Netz, in denen Erfahrungen und Wissen geteilt werden.
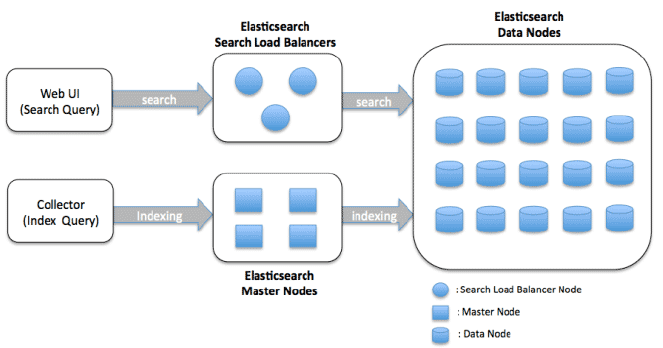
Elasticsearch-Architektur
Die Hauptkomponenten der Elasticsearch-Architektur sind:
Knoten: Ein Knoten ist eine Instanz von Elasticsearch, die Daten speichert und Such- und Indizierungsfähigkeiten bereitstellt. Knoten können konfiguriert werden, um entweder ein Master-Knoten oder ein Datenknoten oder beides zu sein. Master-Knoten sind für die Cluster-weite Verwaltung verantwortlich, während Datenknoten die Daten speichern und Suchoperationen durchführen.
Cluster: Ein Cluster ist eine Gruppe von einem oder mehreren Knoten, die zusammenarbeiten, um Daten zu speichern und zu verarbeiten. Ein Cluster kann mehrere Indizes (Sammlungen von Dokumenten) und Shards (ein Weg, um Daten auf mehrere Knoten zu verteilen) enthalten.
Index: Ein Index ist eine Sammlung von Dokumenten, die eine ähnliche Struktur teilen. Jedes Dokument wird als JSON-Objekt dargestellt und enthält einen oder mehrere Felder. Elasticsearch indexiert standardmäßig alle Felder, was das Suchen und Analysieren von Daten erleichtert.
Shards: Ein Index kann in mehrere Shards aufgeteilt werden, die im Wesentlichen kleinere Teilmengen des Indexes sind. Sharding ermöglicht die parallele Verarbeitung von Daten und verteilt die Speicherung über mehrere Knoten.
Replicas: Elasticsearch kann Replikate jedes Shards erstellen, um Fehlertoleranz und hohe Verfügbarkeit zu gewährleisten. Replikate sind Kopien des ursprünglichen Shards und können sich auf verschiedenen Knoten befinden.
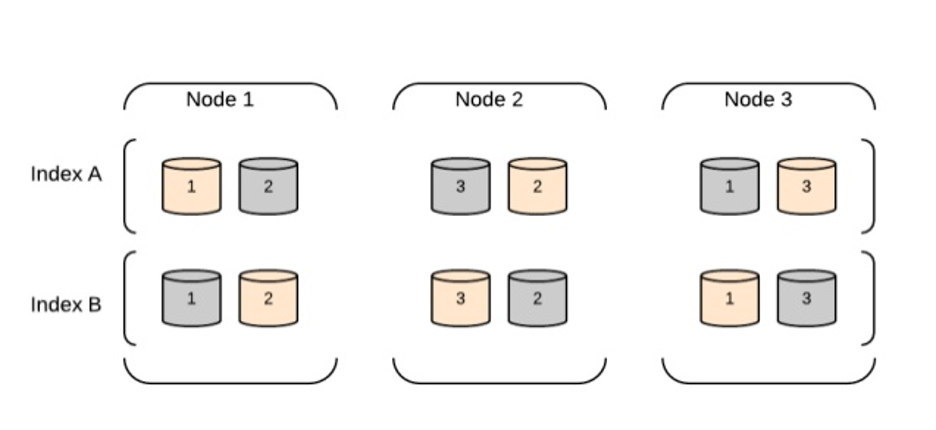
Datenknoten-Clusterarchitektur
Datenknoten sind dafür verantwortlich, Daten zu speichern und zu indizieren, sowie Such- und Aggregationsoperationen durchzuführen. Die Architektur ist so konzipiert, dass sie skalierbar und verteilt ist, was das horizontale Skalieren ermöglicht, indem weitere Knoten zum Cluster hinzugefügt werden.
Hier sind die Hauptbestandteile einer Elasticsearch-Datenknoten-Clusterarchitektur:
Datenknoten: Ein Knoten ist eine Instanz von Elasticsearch, die Daten speichert und Such- und Indizierungskapazitäten bietet. In einem Datenknoten-Cluster ist jeder Knoten dafür verantwortlich, einen Teil der Indexdaten zu speichern und Suchabfragen gegen diese Daten zu bearbeiten.
Clusterzustand: Der Clusterzustand ist eine Datenstruktur, die Informationen über den Cluster enthält, einschließlich der Liste der Knoten, Indizes, Shards und ihrer Standorte. Der Master-Knoten ist dafür verantwortlich, den Clusterzustand zu pflegen und ihn an alle anderen Knoten im Cluster zu verteilen.
Entdeckung und Transport: Knoten in einem Elasticsearch-Cluster kommunizieren miteinander mithilfe zweier Protokolle: Entdeckung und Transport. Das Entdeckungsprotokoll ist dafür zuständig, neue Knoten, die dem Cluster beitreten, oder Knoten, die den Cluster verlassen haben, zu entdecken. Das Transportprotokoll ist dafür zuständig, Daten zwischen den Knoten zu senden und zu empfangen.
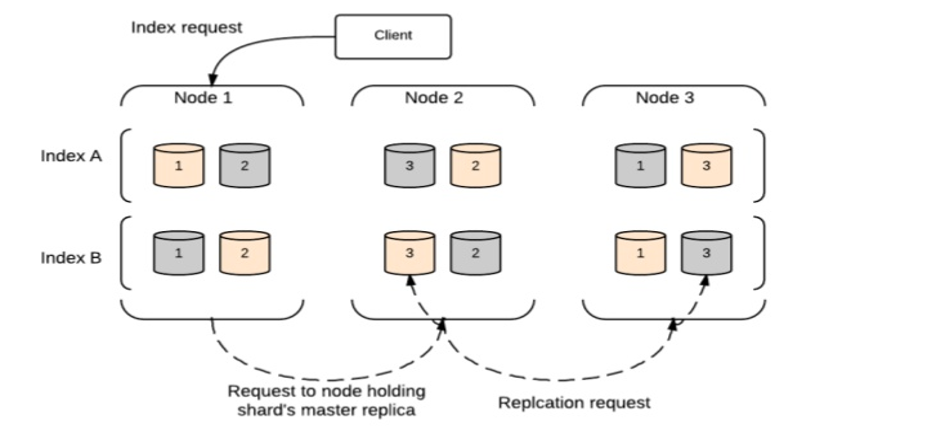
Index-Anfrage
Eine Index-Anfrage wird in Elasticsearch nach folgendem Blockdiagramm ausgeführt.
Wer verwendet Elasticsearch?
Einige Unternehmen und Organisationen, die Elasticsearch verwenden:
Netflix: Netflix nutzt Elasticsearch, um sein Such- und Empfehlungssystem zu betreiben, das Benutzern ermöglicht, schnell Inhalte zum Anschauen zu finden.
GitHub: GitHub verwendet Elasticsearch, um schnelle und effiziente Suchfunktionen für ihre Code-Repositories, Probleme und Pull-Anfragen bereitzustellen.
Uber: Uber nutzt Elasticsearch, um ihre Echtzeit-Analyseplattform zu betreiben, die es ihnen ermöglicht, Daten ihres Fahrdienstes in Echtzeit zu verfolgen und zu analysieren.
Wikipedia: Wikipedia verwendet Elasticsearch, um ihren Suchmaschinenbetrieb zu unterstützen und Benutzern schnelle und genaue Suchergebnisse zur Verfügung zu stellen.
Source:
https://dzone.com/articles/introduction-to-elasticsearch-1