













Status: Veraltet
Dieser Artikel ist veraltet und wird nicht mehr gewartet.
Grund
Die Schritte in diesem Tutorial funktionieren immer noch, führen jedoch zu einer Konfiguration, die jetzt unnötig schwierig zu pflegen ist.
Anstatt dessen siehe
Dieser Artikel kann immer noch als Referenz nützlich sein, entspricht jedoch möglicherweise nicht den besten Praktiken. Wir empfehlen dringend, einen aktuelleren Artikel zu verwenden.
Einführung
Zusammen mit Tracing und Protokollierung sind Überwachung und Alarmierung wesentliche Komponenten eines Kubernetes-Beobachtungsstapels. Die Einrichtung der Überwachung für Ihren DigitalOcean Kubernetes-Cluster ermöglicht es Ihnen, Ihre Ressourcennutzung zu verfolgen und Anwendungsfehler zu analysieren und zu debuggen.
A monitoring system usually consists of a time-series database that houses metric data and a visualization layer. In addition, an alerting layer creates and manages alerts, handing them off to integrations and external services as necessary. Finally, one or more components generate or expose the metric data that will be stored, visualized, and processed for alerts by the stack.
Eine beliebte Überwachungslösung ist der Open-Source-Stack Prometheus, Grafana und Alertmanager, der zusammen mit kube-state-metrics und node_exporter bereitgestellt wird, um Kubernetes-Objektmetriken auf Cluster-Ebene sowie Maschinenmetriken wie CPU- und Speicherauslastung freizugeben.
Die Einführung dieses Überwachungsstapels auf einem Kubernetes-Cluster erfordert die Konfiguration einzelner Komponenten, Manifeste, Prometheus-Metriken und Grafana-Dashboards, was einige Zeit in Anspruch nehmen kann. Der DigitalOcean Kubernetes Cluster Monitoring Quickstart, veröffentlicht vom DigitalOcean Community Developer Education Team, enthält vollständig definierte Manifeste für einen Prometheus-Grafana-Alertmanager-Clusterüberwachungsstapel sowie eine Reihe von vordefinierten Warnmeldungen und Grafana-Dashboards. Es kann Ihnen helfen, schnell einsatzbereit zu sein, und bildet eine solide Grundlage, auf der Sie Ihren Beobachtungsstapel aufbauen können.
In diesem Tutorial werden wir diesen vordefinierten Stapel auf DigitalOcean Kubernetes bereitstellen, auf die Prometheus-, Grafana- und Alertmanager-Schnittstellen zugreifen und beschreiben, wie Sie ihn anpassen können.
Voraussetzungen
Bevor Sie beginnen, benötigen Sie einen verfügbaren DigitalOcean Kubernetes-Cluster und die folgenden Tools in Ihrer lokalen Entwicklungsumgebung installiert:
- Das Befehlszeilen-Tool
kubectlmuss auf Ihrem lokalen Rechner installiert und konfiguriert sein, um eine Verbindung zu Ihrem Cluster herzustellen. Weitere Informationen zur Installation und Konfiguration vonkubectlfinden Sie in der offiziellen Dokumentation. - Das Versionskontrollsystem git muss auf Ihrem lokalen Rechner installiert sein. Informationen zur Installation von git unter Ubuntu 18.04 finden Sie unter Anleitung zur Installation von Git unter Ubuntu 18.04.
- Das Coreutils-Tool base64 muss auf Ihrem lokalen Rechner installiert sein. Auf einem Linux-Rechner ist dies höchstwahrscheinlich bereits installiert. Wenn Sie OS X verwenden, können Sie
openssl base64verwenden, das standardmäßig installiert ist.
<$>[note]
Hinweis: Der Cluster Monitoring Quickstart wurde nur auf DigitalOcean Kubernetes-Clustern getestet. Um den Quickstart mit anderen Kubernetes-Clustern zu verwenden, sind möglicherweise Anpassungen an den Manifestdateien erforderlich.
<$>
Schritt 1 — Klonen des GitHub-Repositorys und Konfigurieren von Umgebungsvariablen
Um zu beginnen, klonen Sie das DigitalOcean Kubernetes Cluster Monitoring GitHub-Repository auf Ihren lokalen Rechner mit git:
Dann wechseln Sie in das Repository:
Sie sollten die folgende Verzeichnisstruktur sehen:
OutputLICENSE
README.md
changes.txt
manifest
Das manifest-Verzeichnis enthält Kubernetes-Manifeste für alle Komponenten des Überwachungsstapels, einschließlich Service-Accounts, Deployments, StatefulSets, ConfigMaps usw. Um mehr über diese Manifestdateien und deren Konfiguration zu erfahren, springen Sie weiter zu Konfigurieren des Überwachungsstapels.
Wenn Sie nur schnell starten möchten, beginnen Sie mit dem Setzen der Umgebungsvariablen APP_INSTANCE_NAME und NAMESPACE, die verwendet werden, um einen eindeutigen Namen für die Komponenten des Stapels zu konfigurieren und den Namespace zu konfigurieren, in den der Stapel bereitgestellt wird:
In diesem Tutorial setzen wir APP_INSTANCE_NAME auf sammy-cluster-monitoring, was allen Namen der Überwachungsstapel Kubernetes-Objekte vorangestellt wird. Sie sollten einen eindeutigen beschreibenden Präfix für Ihren Überwachungsstapel verwenden. Wir setzen auch den Namespace auf default. Wenn Sie den Überwachungsstapel in einen Namespace andere als default bereitstellen möchten, stellen Sie sicher, dass Sie ihn zuerst in Ihrem Cluster erstellen:
Sie sollten die folgende Ausgabe sehen:
Outputnamespace/sammy created
In diesem Fall wurde die Umgebungsvariable NAMESPACE auf sammy gesetzt. Im weiteren Verlauf des Tutorials gehen wir davon aus, dass NAMESPACE auf default gesetzt wurde.
Verwenden Sie nun das base64-Befehl, um ein sicheres Grafana-Passwort zu base64-kodieren. Stellen Sie sicher, dass Sie ein Passwort Ihrer Wahl für Ihr_Grafana_Passwort einsetzen:
Wenn Sie macOS verwenden, können Sie den Befehl openssl base64 verwenden, der standardmäßig installiert ist.
An diesem Punkt haben Sie die Kubernetes-Manifeste des Stapels abgerufen und die erforderlichen Umgebungsvariablen konfiguriert. Sie sind nun bereit, die konfigurierten Variablen in die Kubernetes-Manifestdateien einzusetzen und den Stapel in Ihrem Kubernetes-Cluster zu erstellen.
Schritt 2 — Erstellen des Überwachungsstapels
Das DigitalOcean Kubernetes Monitoring Quickstart-Repo enthält Manifeste für die folgenden Überwachungs-, Scraping- und Visualisierungskomponenten:
- Prometheus ist eine Zeitreihendatenbank und ein Überwachungstool, das funktioniert, indem es Metrik-Endpunkte abfragt und die von diesen Endpunkten freigegebenen Daten sammelt und verarbeitet. Es ermöglicht Ihnen, diese Daten mithilfe von PromQL, einer Abfragesprache für Zeitreihendaten, abzufragen. Prometheus wird im Cluster als StatefulSet mit 2 Replikaten bereitgestellt, die Persistent Volumes mit DigitalOcean Block Storage verwendet. Darüber hinaus werden ein vorkonfigurierter Satz von Prometheus-Benachrichtigungen, Regeln und Jobs als ConfigMap gespeichert. Um mehr darüber zu erfahren, springen Sie weiter zum Abschnitt Prometheus der Konfiguration des Überwachungsstapels.
- Alertmanager, normalerweise zusammen mit Prometheus bereitgestellt, bildet die Alarmierungsschicht des Stapels, die Alarme verarbeitet, die von Prometheus generiert und dedupliziert, gruppiert und an Integrationen wie E-Mail oder PagerDuty geroutet werden. Alertmanager wird als StatefulSet mit 2 Replikaten installiert. Weitere Informationen zu Alertmanager finden Sie in der Alarmierung der Prometheus-Dokumentation.
- Grafana ist ein Datenvisualisierungs- und Analysetool, mit dem Sie Dashboards und Grafiken für Ihre Metriken erstellen können. Grafana wird als StatefulSet mit einer Replik installiert. Darüber hinaus werden ein vorab konfigurierter Satz von Dashboards, die von kubernetes-mixin generiert wurden, als ConfigMap gespeichert.
- kube-state-metrics ist ein Zusatzagent, der auf den Kubernetes-API-Server hört und Metriken zum Zustand von Kubernetes-Objekten wie Deployments und Pods generiert. Diese Metriken werden als Klartext an HTTP-Endpunkten bereitgestellt und von Prometheus konsumiert. kube-state-metrics wird als automatisch skalierbarer Deployment mit einer Replik installiert.
- node-exporter, ein Prometheus-Exporter, der auf Clusterknoten läuft und Betriebssystem- und Hardwaremetriken wie CPU- und Speicherauslastung an Prometheus bereitstellt. Diese Metriken werden ebenfalls als Klartext an HTTP-Endpunkten bereitgestellt und von Prometheus konsumiert. node-exporter wird als DaemonSet installiert.
Standardmäßig wird Prometheus neben dem Abrufen von Metriken, die von node-exporter, kube-state-metrics und den oben aufgeführten Komponenten generiert wurden, so konfiguriert sein, dass es Metriken von den folgenden Komponenten abruft:
- kube-apiserver, dem Kubernetes-API-Server.
- kubelet, dem primären Knoten-Agenten, der mit kube-apiserver interagiert, um Pods und Container auf einem Knoten zu verwalten.
- cAdvisor, ein Knoten-Agent, der laufende Container erkennt und deren CPU-, Speicher-, Dateisystem- und Netzwerknutzungsmetriken sammelt.
Um mehr über die Konfiguration dieser Komponenten und Prometheus-Scraping-Jobs zu erfahren, springen Sie vor zum Abschnitt Konfigurieren des Überwachungsstapels. Jetzt werden wir die Umgebungsvariablen, die im vorherigen Schritt definiert wurden, in die Manifestdateien des Repos substituieren und die einzelnen Manifeste zu einer einzigen Masterdatei zusammenfügen.
Beginnen Sie mit der Verwendung von awk und envsubst, um die Variablen APP_INSTANCE_NAME, NAMESPACE und GRAFANA_GENERATED_PASSWORD in den Manifestdateien des Repositorys zu füllen. Nach dem Ersetzen der Variablenwerte werden die Dateien kombiniert und in einer Master-Manifestdatei namens sammy-cluster-monitoring_manifest.yaml gespeichert.
Sie sollten in Betracht ziehen, diese Datei in der Versionskontrolle zu speichern, damit Sie Änderungen am Überwachungsstapel verfolgen und zu früheren Versionen zurückkehren können. Wenn Sie dies tun, stellen Sie sicher, dass Sie die Variable admin-password aus der Datei entfernen, damit Sie Ihr Grafana-Passwort nicht in der Versionskontrolle speichern.
Nachdem Sie die Master-Manifestdatei generiert haben, verwenden Sie kubectl apply -f, um das Manifest anzuwenden und den Stapel im konfigurierten Namespace zu erstellen:
Sie sollten eine Ausgabe ähnlich der folgenden sehen:
Outputserviceaccount/alertmanager created
configmap/sammy-cluster-monitoring-alertmanager-config created
service/sammy-cluster-monitoring-alertmanager-operated created
service/sammy-cluster-monitoring-alertmanager created
. . .
clusterrolebinding.rbac.authorization.k8s.io/prometheus created
configmap/sammy-cluster-monitoring-prometheus-config created
service/sammy-cluster-monitoring-prometheus created
statefulset.apps/sammy-cluster-monitoring-prometheus created
Sie können den Fortschritt der Bereitstellung des Stapels mithilfe von kubectl get all verfolgen. Sobald alle Komponenten des Stapels RUNNING sind, können Sie auf die vorab konfigurierten Grafana-Dashboards über die Grafana-Webbenutzeroberfläche zugreifen.
Schritt 3 — Zugriff auf Grafana und Erkunden von Metriken-Daten
Der Grafana-Service-Manifest stellt Grafana als einen ClusterIP-Dienst zur Verfügung, was bedeutet, dass er nur über eine Cluster-interne IP-Adresse erreichbar ist. Um auf Grafana außerhalb Ihres Kubernetes-Clusters zuzugreifen, können Sie entweder kubectl patch verwenden, um den Dienst vor Ort auf einen öffentlich zugänglichen Typ wie NodePort oder LoadBalancer zu aktualisieren, oder kubectl port-forward, um einen lokalen Port auf einen Grafana-Pod-Port weiterzuleiten. In diesem Tutorial werden wir Ports weiterleiten, sodass Sie direkt zu Weiterleitung eines lokalen Ports zum Zugriff auf den Grafana-Service springen können. Der folgende Abschnitt zur externen Bereitstellung von Grafana dient nur zu Referenzzwecken.
Bereitstellen des Grafana-Dienstes mithilfe eines Lastenausgleichs (optional)
Wenn Sie einen DigitalOcean-Lastenausgleich für Grafana mit einer externen öffentlichen IP-Adresse erstellen möchten, verwenden Sie kubectl patch, um den bestehenden Grafana-Dienst vor Ort auf den Diensttyp LoadBalancer zu aktualisieren:
Der patch-Befehl von kubectl ermöglicht es Ihnen, Kubernetes-Objekte direkt zu aktualisieren, um Änderungen vorzunehmen, ohne die Objekte erneut bereitstellen zu müssen. Sie können auch die Master-Manifestdatei direkt ändern und einen type: LoadBalancer-Parameter zur Grafana Service-Spezifikation hinzufügen. Um mehr über kubectl patch und die Arten von Kubernetes-Diensten zu erfahren, können Sie die Ressourcen Update API-Objekte direkt mit kubectl patch und Dienste in der offiziellen Kubernetes-Dokumentation konsultieren.
Nach Ausführung des obigen Befehls sollten Sie Folgendes sehen:
Outputservice/sammy-cluster-monitoring-grafana patched
Es kann einige Minuten dauern, um den Lastenausgleicher zu erstellen und ihm eine öffentliche IP zuzuweisen. Sie können seinen Fortschritt mit dem folgenden Befehl und dem -w-Flag verfolgen, um Änderungen zu beobachten:
Nachdem der DigitalOcean-Lastenausgleicher erstellt und ihm eine externe IP-Adresse zugewiesen wurde, können Sie seine externe IP mit den folgenden Befehlen abrufen:
Sie können jetzt auf die Grafana-Benutzeroberfläche zugreifen, indem Sie zu http://SERVICE_IP/ navigieren.
Weiterleitung eines lokalen Ports zum Zugriff auf den Grafana-Dienst
Wenn Sie den Grafana-Dienst nicht extern freigeben möchten, können Sie auch den lokalen Port 3000 direkt in das Cluster auf einen Grafana-Pod weiterleiten, indem Sie kubectl port-forward verwenden.
Sie sollten die folgende Ausgabe sehen:
OutputForwarding from 127.0.0.1:3000 -> 3000
Forwarding from [::1]:3000 -> 3000
Dies leitet den lokalen Port 3000 an den containerPort 3000 des Grafana-Pods sammy-cluster-monitoring-grafana-0 weiter. Um mehr über die Weiterleitung von Ports in ein Kubernetes-Cluster zu erfahren, konsultieren Sie Verwenden von Portweiterleitung zum Zugriff auf Anwendungen in einem Cluster.
Öffnen Sie http://localhost:3000 in Ihrem Webbrowser. Sie sollten die folgende Grafana-Anmeldeseite sehen:

Verwenden Sie zum Anmelden den Standardbenutzernamen admin (falls Sie den Parameter admin-user nicht geändert haben) und das Passwort, das Sie in Schritt 1 konfiguriert haben.
Sie werden zum folgenden Startdashboard weitergeleitet:
Wählen Sie in der linken Navigationsleiste die Dashboards -Schaltfläche aus und klicken Sie dann auf Verwalten :
Sie gelangen zu der folgenden Dashboard-Verwaltungsschnittstelle, die die in der dashboards-configmap.yaml Manifest konfigurierten Dashboards auflistet:
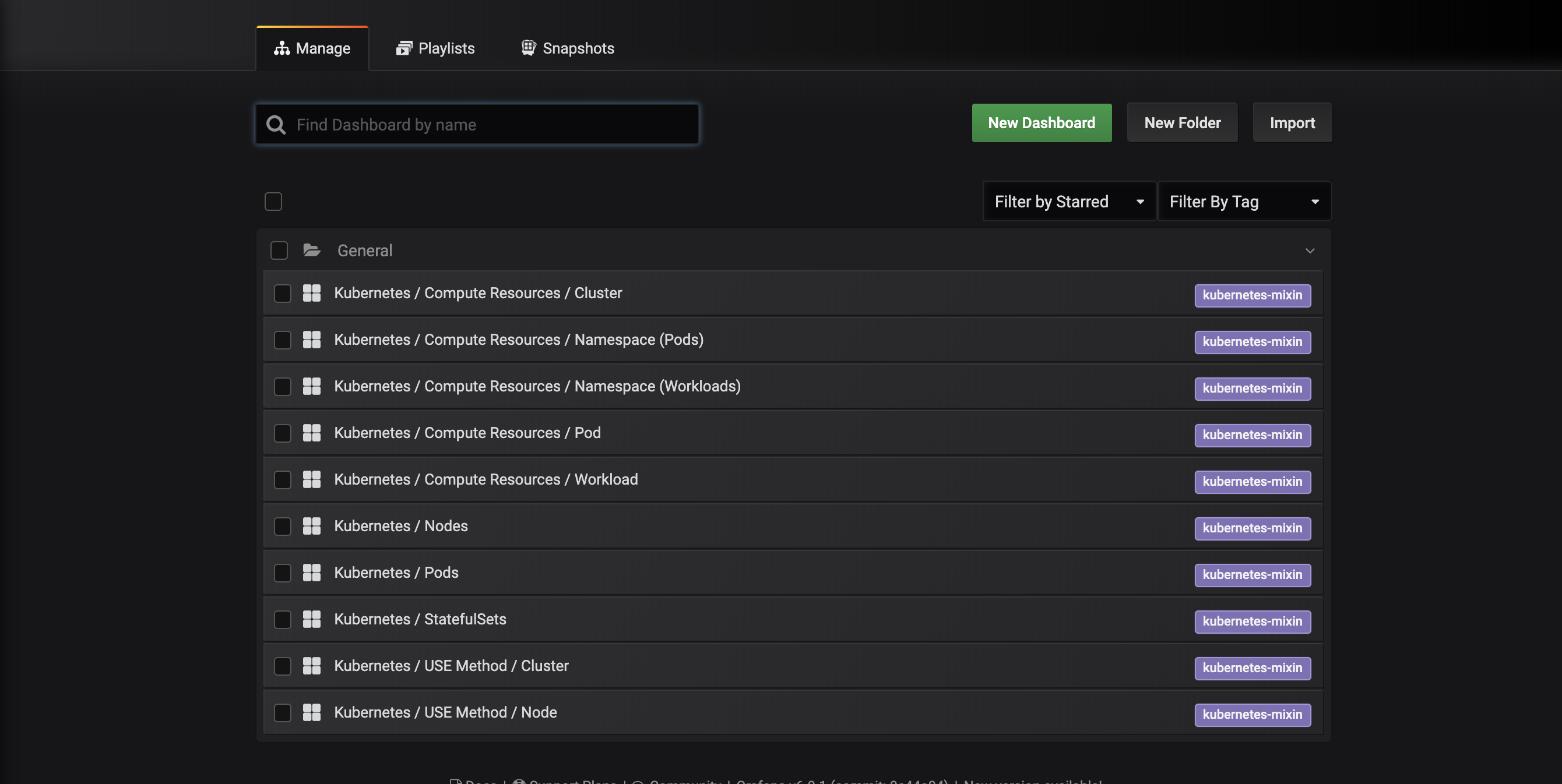
Diese Dashboards werden von kubernetes-mixin generiert, einem Open-Source-Projekt, das es Ihnen ermöglicht, einen standardisierten Satz von Cluster-Überwachungs-Grafana-Dashboards und Prometheus-Warnungen zu erstellen. Um mehr zu erfahren, konsultieren Sie das kubernetes-mixin GitHub-Repo.
Klicken Sie auf das Kubernetes / Nodes-Dashboard, das die CPU-, Speicher-, Festplatten- und Netzwerknutzung für einen bestimmten Knoten visualisiert:
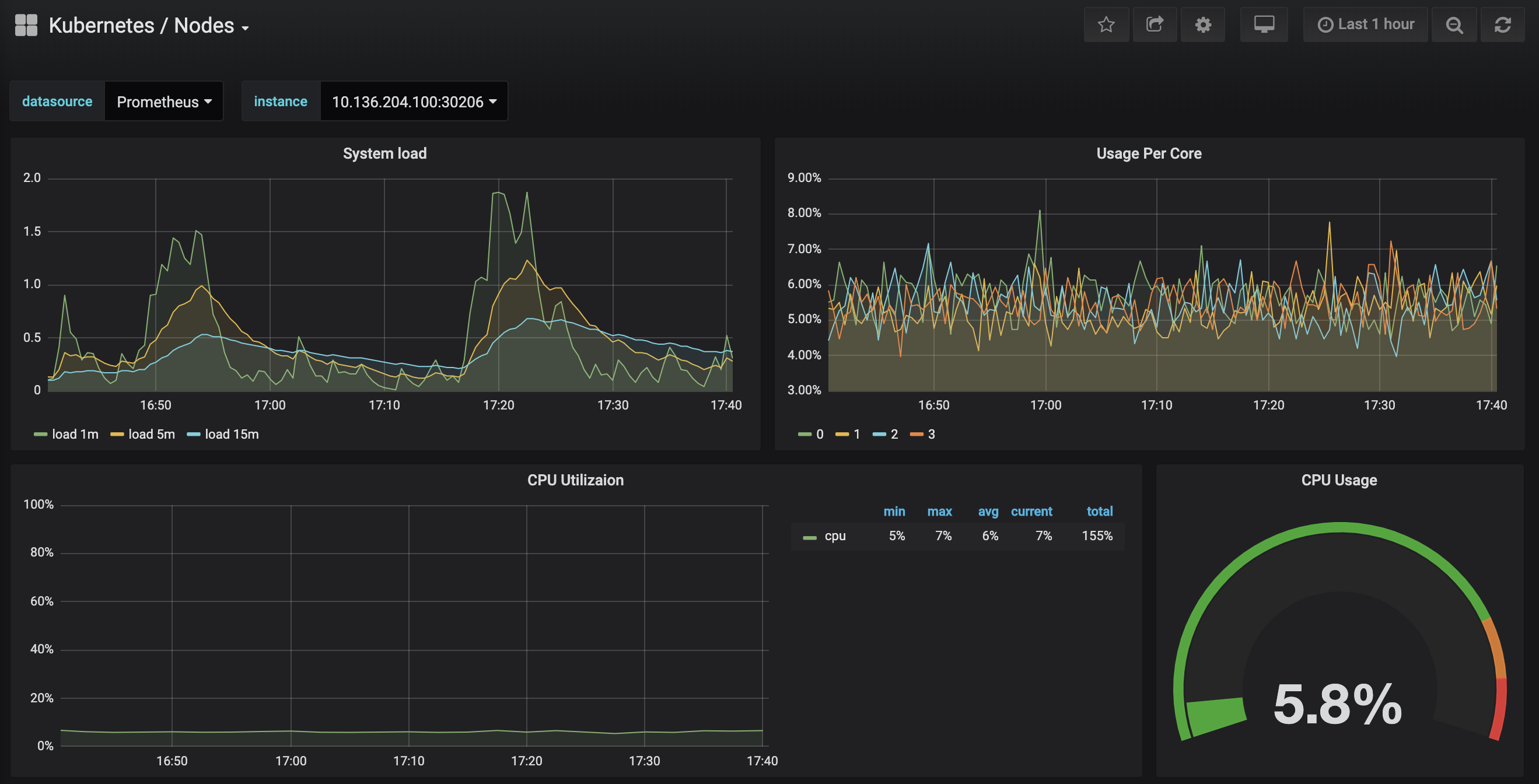
Die Beschreibung der Verwendung dieser Dashboards liegt außerhalb des Umfangs dieses Tutorials, aber Sie können die folgenden Ressourcen konsultieren, um mehr zu erfahren:
- Um mehr über die USE-Methode zur Analyse der Leistung eines Systems zu erfahren, können Sie Brendan Greggs Die Utilization Saturation and Errors (USE) Method-Seite konsultieren.
- Das SRE-Buch von Google ist eine weitere hilfreiche Ressource, insbesondere Kapitel 6: Überwachung verteilter Systeme.
- Um zu lernen, wie Sie Ihre eigenen Grafana-Dashboards erstellen können, werfen Sie einen Blick auf die Getting Started-Seite von Grafana.
Im nächsten Schritt werden wir einen ähnlichen Prozess durchführen, um eine Verbindung zum Prometheus-Überwachungssystem herzustellen und es zu erkunden.
Schritt 4 — Zugriff auf Prometheus und Alertmanager
Um eine Verbindung zu den Prometheus-Pods herzustellen, können wir kubectl port-forward verwenden, um einen lokalen Port weiterzuleiten. Wenn Sie mit der Erkundung von Grafana fertig sind, können Sie den Port-Forward-Tunnel durch Drücken von STRG-C schließen. Alternativ können Sie eine neue Shell öffnen und eine neue Port-Forward-Verbindung erstellen.
Beginnen Sie damit, die ausgeführten Pods im default-Namespace aufzulisten:
Sie sollten die folgenden Pods sehen:
Outputsammy-cluster-monitoring-alertmanager-0 1/1 Running 0 17m
sammy-cluster-monitoring-alertmanager-1 1/1 Running 0 15m
sammy-cluster-monitoring-grafana-0 1/1 Running 0 16m
sammy-cluster-monitoring-kube-state-metrics-d68bb884-gmgxt 2/2 Running 0 16m
sammy-cluster-monitoring-node-exporter-7hvb7 1/1 Running 0 16m
sammy-cluster-monitoring-node-exporter-c2rvj 1/1 Running 0 16m
sammy-cluster-monitoring-node-exporter-w8j74 1/1 Running 0 16m
sammy-cluster-monitoring-prometheus-0 1/1 Running 0 16m
sammy-cluster-monitoring-prometheus-1 1/1 Running 0 16m
Wir leiten den lokalen Port 9090 auf den Port 9090 des Pods sammy-cluster-monitoring-prometheus-0 weiter:
Sie sollten die folgende Ausgabe sehen:
OutputForwarding from 127.0.0.1:9090 -> 9090
Forwarding from [::1]:9090 -> 9090
Dies zeigt an, dass der lokale Port 9090 erfolgreich zum Prometheus-Pod weitergeleitet wird.
Öffnen Sie http://localhost:9090 in Ihrem Webbrowser. Sie sollten die folgende Prometheus-Grafik-Seite sehen:

Von hier aus können Sie PromQL, die Prometheus-Abfragesprache, verwenden, um Zeitreihenmetriken auszuwählen und zu aggregieren, die in ihrer Datenbank gespeichert sind. Um mehr über PromQL zu erfahren, konsultieren Sie Abfragen von Prometheus in der offiziellen Prometheus-Dokumentation.
Im Ausdruck-Feld, geben Sie kubelet_node_name ein und klicken Sie auf Ausführen. Sie sollten eine Liste von Zeitreihen mit der Metrik kubelet_node_name sehen, die die Knoten in Ihrem Kubernetes-Cluster meldet. Sie können sehen, welcher Knoten die Metrik generiert hat und welcher Job die Metrik abgerufen hat, in den Metriklabels:

Zum Schluss klicken Sie in der oberen Navigationsleiste auf Status und dann auf Ziele, um die Liste der Ziele zu sehen, die Prometheus konfiguriert wurde, um sie abzurufen. Sie sollten eine Liste von Zielen sehen, die der Liste der Überwachungsendpunkte entsprechen, die zu Beginn von Schritt 2 beschrieben wurden.
Weitere Informationen zu Prometheus und zum Abfragen Ihrer Cluster-Metriken finden Sie in der offiziellen Prometheus-Dokumentation.
Um eine Verbindung zu Alertmanager herzustellen, der die von Prometheus generierten Alarme verwaltet, folgen wir einem ähnlichen Prozess wie beim Verbinden mit Prometheus. Im Allgemeinen können Sie Alertmanager-Alarme erkunden, indem Sie auf Alarme in der oberen Navigationsleiste von Prometheus klicken.
Um eine Verbindung zu den Alertmanager-Pods herzustellen, verwenden wir erneut kubectl port-forward, um einen lokalen Port weiterzuleiten. Wenn Sie mit der Erkundung von Prometheus fertig sind, können Sie den Port-Forward-Tunnel durch Drücken von STRG-C schließen oder eine neue Shell öffnen, um eine neue Verbindung herzustellen.
Wir werden den lokalen Port 9093 auf den Port 9093 des Pods sammy-cluster-monitoring-alertmanager-0 weiterleiten:
Sie sollten die folgende Ausgabe sehen:
OutputForwarding from 127.0.0.1:9093 -> 9093
Forwarding from [::1]:9093 -> 9093
Dies zeigt an, dass der lokale Port 9093 erfolgreich an einen Alertmanager-Pod weitergeleitet wird.
Besuchen Sie http://localhost:9093 in Ihrem Webbrowser. Sie sollten die folgende Alertmanager Warnmeldungen-Seite sehen:
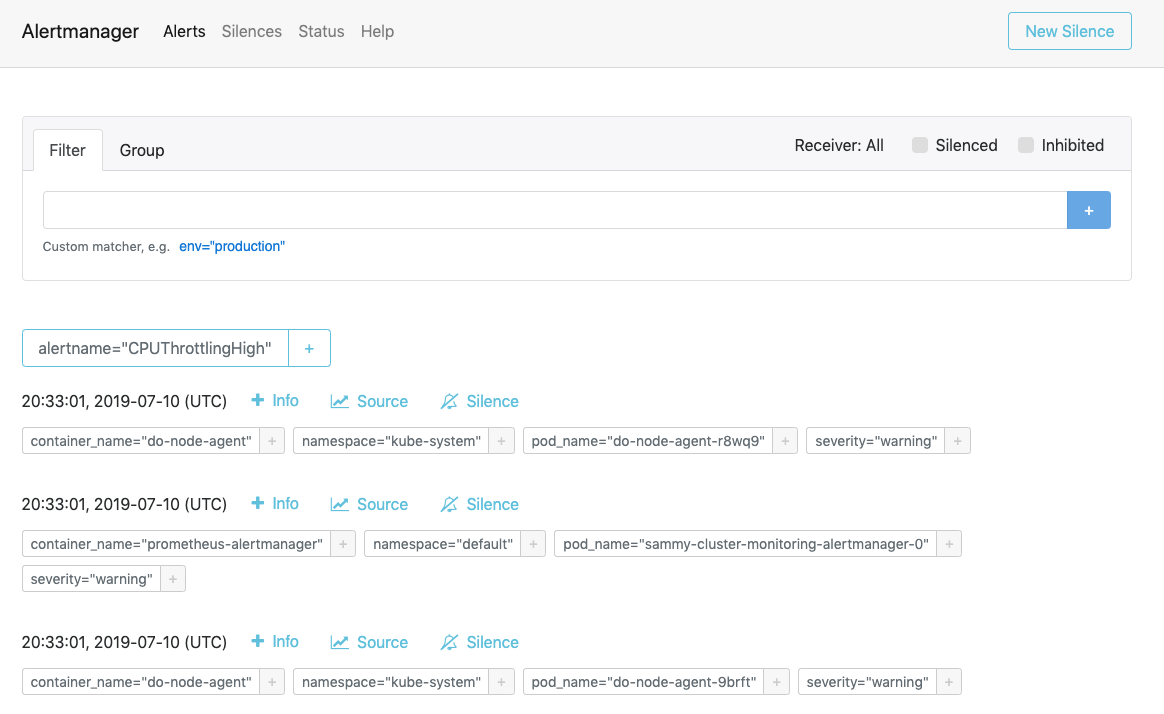
Von hier aus können Sie Warnmeldungen auslösen und sie optional stummschalten. Um mehr über Alertmanager zu erfahren, konsultieren Sie die offizielle Alertmanager-Dokumentation.
Im nächsten Schritt erfahren Sie, wie Sie einige der Komponenten des Überwachungsstapels optional konfigurieren und skalieren können.
Schritt 6 — Konfigurieren des Überwachungsstapels (optional)
Die in der DigitalOcean Kubernetes Cluster Monitoring Quickstart-Repository enthaltenen Manifeste können so geändert werden, dass sie unterschiedliche Container-Images, unterschiedliche Anzahlen von Pod-Replikaten, verschiedene Ports und individuelle Konfigurationsdateien verwenden.
In diesem Schritt geben wir einen Überblick über den Zweck jedes Manifests und zeigen dann, wie Prometheus durch Ändern der Master-Manifestdatei auf 3 Repliken skaliert werden kann.
Um zu beginnen, navigieren Sie in das manifests Unterverzeichnis im Repo und listen Sie den Inhalt des Verzeichnisses auf:
Outputalertmanager-0serviceaccount.yaml
alertmanager-configmap.yaml
alertmanager-operated-service.yaml
alertmanager-service.yaml
. . .
node-exporter-ds.yaml
prometheus-0serviceaccount.yaml
prometheus-configmap.yaml
prometheus-service.yaml
prometheus-statefulset.yaml
Hier finden Sie Manifeste für die verschiedenen Überwachungsstack-Komponenten. Um mehr über spezifische Parameter in den Manifesten zu erfahren, klicken Sie auf die Links und konsultieren Sie die enthaltenen Kommentare in den YAML-Dateien:
Alertmanager
-
alertmanager-0serviceaccount.yaml: Das Alertmanager-Servicekonto wird verwendet, um den Alertmanager-Pods eine Kubernetes-Identität zu geben. Um mehr über Servicekonten zu erfahren, konsultieren Sie Konfigurieren von Servicekonten für Pods. -
alertmanager-configmap.yaml: Ein ConfigMap, die eine minimale Alertmanager-Konfigurationsdatei namensalertmanager.ymlenthält. Die Konfiguration des Alertmanagers liegt außerhalb des Rahmens dieses Tutorials, aber Sie können mehr erfahren, indem Sie den Konfigurations-Abschnitt der Alertmanager-Dokumentation konsultieren. -
alertmanager-operated-service.yaml: Der Alertmanagermesh-Dienst, der zum Routen von Anfragen zwischen Alertmanager-Pods in der aktuellen Hochverfügbarkeitskonfiguration mit 2 Replikaten verwendet wird. -
alertmanager-service.yaml: Der AlertmanagerwebService, der verwendet wird, um auf die Alertmanager-Webbenutzeroberfläche zuzugreifen, was Sie möglicherweise im vorherigen Schritt durchgeführt haben. -
alertmanager-statefulset.yaml: Der Alertmanager StatefulSet, konfiguriert mit 2 Replikaten.
Grafana
-
dashboards-configmap.yaml: Ein ConfigMap, der die vordefinierten JSON Grafana Überwachungs-Dashboards enthält. Das Generieren eines neuen Satzes von Dashboards und Warnungen von Grund auf geht über den Umfang dieses Tutorials hinaus, aber um mehr zu erfahren, können Sie das kubernetes-mixin GitHub-Repo konsultieren. -
grafana-0serviceaccount.yaml: Der Grafana Service Account. -
grafana-configmap.yaml: Ein ConfigMap, der einen Standardsatz minimaler Konfigurationsdateien für Grafana enthält. -
grafana-secret.yaml: Ein Kubernetes-Secret, das den Grafana-Administratorbenutzer und das Passwort enthält. Um mehr über Kubernetes-Secrets zu erfahren, konsultieren Sie Secrets. -
grafana-service.yaml: Das Manifest, das den Grafana-Dienst definiert. -
grafana-statefulset.yaml: Der Grafana StatefulSet ist konfiguriert mit 1 Replikat, das nicht skalierbar ist. Das Skalieren von Grafana ist über den Umfang dieses Tutorials hinaus. Um zu erfahren, wie man ein hochverfügbares Grafana-Setup erstellt, können Sie Wie man Grafana für hohe Verfügbarkeit einrichtet in der offiziellen Grafana-Dokumentation konsultieren.
kube-state-metrics
-
kube-state-metrics-0serviceaccount.yaml: Das Service-Konto und die ClusterRole für kube-state-metrics. Um mehr über ClusterRoles zu erfahren, konsultieren Sie Rolle und ClusterRole in der Kubernetes-Dokumentation. -
kube-state-metrics-deployment.yaml: Das Hauptmanifest für die kube-state-metrics-Bereitstellung, konfiguriert mit 1 dynamisch skalierbaren Replikat unter Verwendung vonaddon-resizer. -
kube-state-metrics-service.yaml: Der Service, der die Bereitstellung vonkube-state-metricsfreigibt.
node-exporter
-
node-exporter-0serviceaccount.yaml: Der Service-Account von node-exporter. -
node-exporter-ds.yaml: Das Manifest für den DaemonSet von node-exporter. Da node-exporter ein DaemonSet ist, läuft ein node-exporter-Pod auf jedem Knoten im Cluster.
###Prometheus
-
prometheus-0serviceaccount.yaml: Der Service-Account, ClusterRole und ClusterRoleBinding von Prometheus. -
prometheus-configmap.yaml: Eine ConfigMap, die drei Konfigurationsdateien enthält:alerts.yaml: Enthält eine vorkonfigurierte Menge von Alarmen, die vonkubernetes-mixingeneriert wurden (das auch für die Grafana-Dashboards verwendet wurde). Weitere Informationen zur Konfiguration von Alarmregeln finden Sie unter Alerting Rules in der Prometheus-Dokumentation.prometheus.yaml: Die Hauptkonfigurationsdatei von Prometheus. Prometheus wurde vorkonfiguriert, um alle im Schritt 2 aufgeführten Komponenten zu scrapen. Die Konfiguration von Prometheus geht über den Umfang dieses Artikels hinaus, aber weitere Informationen finden Sie unter Configuration in der offiziellen Prometheus-Dokumentation.rules.yaml: Eine Menge von Prometheus-Aufzeichnungsvorschriften, die Prometheus berechtigen, häufig benötigte oder rechenintensive Ausdrücke zu berechnen und deren Ergebnisse als neue Menge von Zeitreihen zu speichern. Diese werden ebenfalls vonkubernetes-mixingeneriert, und ihre Konfiguration geht über den Umfang dieses Artikels hinaus. Weitere Informationen finden Sie unter Recording Rules in der offiziellen Prometheus-Dokumentation.
-
prometheus-service.yaml: Der Service, der den Prometheus StatefulSet freigibt. -
prometheus-statefulset.yaml: Der Prometheus StatefulSet, konfiguriert mit 2 Replikaten. Dieser Parameter kann je nach Bedarf skaliert werden.
Beispiel: Skalierung von Prometheus
Um zu zeigen, wie man den Überwachungsstack modifiziert, skalieren wir die Anzahl der Prometheus-Replikate von 2 auf 3.
Öffnen Sie die Master-Manifestdatei sammy-cluster-monitoring_manifest.yaml mit Ihrem bevorzugten Editor:
Scrollen Sie zum Abschnitt Prometheus StatefulSet des Manifests herunter:
Output. . .
apiVersion: apps/v1beta2
kind: StatefulSet
metadata:
name: sammy-cluster-monitoring-prometheus
labels: &Labels
k8s-app: prometheus
app.kubernetes.io/name: sammy-cluster-monitoring
app.kubernetes.io/component: prometheus
spec:
serviceName: "sammy-cluster-monitoring-prometheus"
replicas: 2
podManagementPolicy: "Parallel"
updateStrategy:
type: "RollingUpdate"
selector:
matchLabels: *Labels
template:
metadata:
labels: *Labels
spec:
. . .
Ändern Sie die Anzahl der Replikate von 2 auf 3:
Output. . .
apiVersion: apps/v1beta2
kind: StatefulSet
metadata:
name: sammy-cluster-monitoring-prometheus
labels: &Labels
k8s-app: prometheus
app.kubernetes.io/name: sammy-cluster-monitoring
app.kubernetes.io/component: prometheus
spec:
serviceName: "sammy-cluster-monitoring-prometheus"
replicas: 3
podManagementPolicy: "Parallel"
updateStrategy:
type: "RollingUpdate"
selector:
matchLabels: *Labels
template:
metadata:
labels: *Labels
spec:
. . .
Wenn Sie fertig sind, speichern und schließen Sie die Datei.
Wenden Sie die Änderungen mit kubectl apply -f an:
Sie können den Fortschritt mithilfe von kubectl get pods verfolgen. Mit dieser Technik können Sie viele der Kubernetes-Parameter und einen Großteil der Konfiguration für diesen Beobachtungsstack aktualisieren.
Abschluss
In diesem Tutorial haben Sie einen Prometheus-, Grafana- und Alertmanager-Monitoring-Stack in Ihren DigitalOcean Kubernetes-Cluster mit einem Standardset von Dashboards, Prometheus-Regeln und Warnungen installiert.
Sie können diesen Überwachungsstack auch mithilfe des Helm-Kubernetes-Paketmanagers bereitstellen. Um mehr zu erfahren, konsultieren Sie So richten Sie das Überwachungssystem für DigitalOcean Kubernetes-Cluster mit Helm und Prometheus ein. Eine alternative Möglichkeit, einen ähnlichen Stack in Betrieb zu nehmen, ist die Verwendung der DigitalOcean Marketplace Kubernetes Monitoring Stack-Lösung, die derzeit in der Beta-Phase ist.
Das DigitalOcean Kubernetes Cluster Monitoring Quickstart-Repository basiert stark auf und wurde modifiziert von der Lösung „Click-to-Deploy Prometheus“ von der Google Cloud Platform. Eine vollständige Übersicht der Modifikationen und Änderungen gegenüber dem Original-Repository finden Sie in der Datei changes.md im Quickstart-Repo.