













Apache Kafka unterstützt verschiedene Sicherheitsprotokolle und Authentifizierungsworkflows, um sicherzustellen, dass nur autorisierte Mitarbeiter und Anwendungen eine Verbindung zum Cluster herstellen können. In der Standardkonfiguration ermöglicht Kafka den Zugriff für alle, hat jedoch keine Sicherheitsprüfungen aktiviert. Während das für das Erkunden und Entwickeln nützlich ist, müssen Produktionsumgebungen vor der Exposition an die Außenwelt ordnungsgemäß gesichert werden. Auch müssen solche Umgebungen überwacht werden, um einen reibungslosen Betrieb zu gewährleisten und mögliche Ausfälle zu verhindern.
In diesem Tutorial werden Sie Ihre Kafka-Installation durch die Konfiguration von TLS-Trafikverschlüsselung und SASL-Authentifizierung stärken, um einen Standard- Benutzername-und-Passwort-Login-Fluss bereitzustellen. Sie werden sehen, wie Sie die bereitgestellten Producer- und Consumer-Skripte konfigurieren, um eine Verbindung zu einem gesicherten Cluster herzustellen. Dann werden Sie erfahren, wie Sie Kafka-Metriken exportieren und in Grafana visualisieren. Sie lernen auch, wie Sie auf die Knoten und Themen Ihres Clusters über eine benutzerfreundliche, webbasierte Oberfläche zugreifen können, die von AKHQ bereitgestellt wird.
Um dieses Tutorial abzuschließen, benötigen Sie:
- Ein Droplet mit mindestens 4GB RAM und 2 CPUs. Bei einem Ubuntu-Server folgen Sie den Ersten Server-Einrichtungsschritten für die Einrichtungsanweisungen.
- Apache Kafka ist auf Ihrem Droplet installiert und konfiguriert. Für die Einrichtungsanweisungen folgen Sie dem Tutorial Einführung in Kafka. Sie müssen nur Schritt 1 und Schritt 2 ausführen.
- Ein Verständnis davon, wie Java Schlüssel und Zertifikate verarbeitet. Weitere Informationen finden Sie im Tutorial Java Keytool Essentials: Arbeiten mit Java-Schlüssel dépots.
- Grafana auf Ihrem Server oder lokalen Rechner installiert. Bitte besuchen Sie das Tutorial So installieren und sichern Sie Grafana auf Ubuntu für die Anweisungen. Sie müssen nur die ersten vier Schritte ausführen.
- Ein vollständig registrierter Domänencode wird auf Ihr Droplet verwiesen. Dieses Tutorial verwendet
Ihre_Domaindurchgängig und bezieht sich auf die gleiche Domäne wie die Grafana-Voraussetzung. Sie können einen Domänennamen bei Namecheap kaufen, einen kostenlos bei Freenom erhalten oder Ihren bevorzugten Domain-Registrar verwenden.
Schritt 1 – Konfigurieren der Kafka-Sicherheitsprotokolle
In seiner Standardeinstellung erlaubt Kafka allen, sich ohne Prüfung der Herkunft der Anfrage mit ihm zu verbinden. Dies bedeutet, dass Ihr Cluster standardmäßig für jeden zugänglich ist. Während das für die Testung in Frage steht, da es die Wartungsarbeit auf lokalen Maschinen und privaten Installationen reduziert, müssen Produktions- und öffentlich zugängliche Kafka-Installationen Sicherheitseigenschaften aktivieren, um unautorisierte Zugriffe zu vermeiden.
In diesem Schritt werden Sie Ihren Kafka-Broker so einstellen, dass er TLS-Verschlüsselung für den Datenverkehr zwischen dem Broker und den Konsumenten verwendet. Sie werden auch SASL als Authentifizierungsframework einrichten, um Zugangsdaten beim Verbinden mit dem Cluster zu prüfen.
Generierung von TLS-Zertifikaten und -Speichern
Um die für die Einrichtung von TLS erforderlichen Zertifikate und Schlüssel zu generieren, werden Sie das Skript aus dem Confluent Platform Security Tools-Repository verwenden. Erstellen Sie zunächst einen Klon in Ihrem Home-Verzeichnis, indem Sie den folgenden Befehl ausführen:
Navigieren Sie zu ihm:
Die Skript, das du verwenden wirst, heißt kafka-generate-ssl-automatic.sh, und es erfordert, dass du dein Land, dein Staat, deine Organisation und deine Stadt als Umgebungsvariablen bereitstellen. Diese Parameter werden verwendet, um Zertifikate zu erzeugen, aber ihre Inhalte sind unimportiert. Du musst auch ein Passwort bereitstellen, das zum Schutz des Java-Vertrauens- und Schlüsselgeschäfts genutzt wird, das erstellt wird.
Führe die folgenden Befehle aus, um die erforderlichen Umgebungsvariablen einzurichten, und ersetze your_tls_password mit deinem gewünschten Wert:
Beachte, dass das PASSWORD mindestens sechs Zeichen lang sein muss.
Gib dem Skript ausführbare Berechtigungen durch Ausführung:
Dann führe es aus, um die erforderlichen Dateien zu generieren:
Es wird viel Ausgabe geben. Wenn es fertig ist, liste die Dateien im Verzeichnis auf:
Die Ausgabe sollte etwa wie folgt aussehen:
Du erkennst, dass das Zertifikat, das Vertrauens- und Schlüsselgeschäft erfolgreich erstellt wurden.
Kafka für TLS- und SASL-Authentifizierung einrichten
Nun, da du die notwendigen Dateien zum Aktivieren der TLS-Verschlüsselung hast, konfiguriere Kafka, um sie zu verwenden und Benutzer mittels SASL zu authentifizieren.
Sie bearbeiten die Datei server.properties im Verzeichnis config/kraft im Installationsverzeichnis. Sie haben sie als Teil der Vorbedingungen im Ihren Home-Verzeichnis unter kafka installiert. Navigieren Sie zu ihr mit dem Befehl:
Öffnen Sie die Hauptkonfigurationsdatei für die Bearbeitung:
nano config/kraft/server.properties
Suchen Sie nach den folgenden Zeilen:
Bearbeiten Sie sie so, dass sie wie folgt aussehen undersetzen Sie PLAINTEXT mit BROKER:
Dann suchen Sie die Zeile listener.security.protocol.map:
Kartieren Sie BROKER mit SASL_SSL indem Sie die Definition dem Wert voranstellen:
Hier haben Sie die Definition für den Alias BROKER hinzugefügt, den Sie in den Listenern verwendet haben und verknüpft Sie mit SASL_SSL, was bedeutet, dass sowohl SSL (ein früherer Name für TLS) als auch SASL verwendet werden sollen.
Weiter gehen Sie zum Ende des Dateis und fügen die folgenden Zeilen hinzu:
Sie definieren zunächst den Pfad und das Passwort für die generierten Vertrauens- und Schlüsselstores. Sie setzen den Parameter ssl.client.auth auf required, was Kafka anweist, Verbindungen, die kein gültiges TLS-Zertifikat aufweisen, zu untersagen. Dann setzen Sie das SASL-Verfahren auf PLAIN, was es aktiviert. PLAIN unterscheidet sich von PLAINTEXT, da es die Verwendung einer verschlüsselten Verbindung verlangt und beide auf eine Kombination aus Benutzernamen und Passwort verlassen.
Schließlich setzen Sie StandardAuthorizer als Autorisierungs-Klasse, die die Anmeldeinformationen gegen eine Konfigurationsdatei prüft, die Sie gleich erstellen werden. Dann setzen Sie den Parameter allow.everyone.if.no.acl.found auf false, was den Zugriff für Verbindungen mit unangemessenen Anmeldeinformationen beschränkt. Sie bezeichnen den Benutzer admin auch als Superuser, da es mindestens einen für die Durchführung administrativer Aufgaben im Cluster geben muss.
Denken Sie daran, your_tls_password mit dem Passwort zu ersetzen, das Sie im letzten Abschnitt dem Skript übergeben haben, und speichern Sie dann die Datei und schließen Sie sie.
Nachdem Sie Kafka konfiguriert haben, müssen Sie eine Datei erstellen, die die zulässigen Anmeldeinformationen zum Verbinden definiert. Kafka unterstützt das Java Authentication and Authorization Service (JAAS), ein Framework zur Implementierung von Authentifizierungsworkflows, und akzeptiert Anmeldeinformationen in dem JAAS-Format.
Speichern Sie diese in einer Datei namens kafka-server-jaas.conf unter config/kraft. Erstellen und öffnen Sie diese zum Bearbeiten mit folgendem Befehl:
Fügen Sie die folgenden Zeilen hinzu:
Die username und password definieren die Hauptanmeldeinformationen, die für die Kommunikation zwischen Brokern im Cluster verwendet werden, wenn mehrere Knoten vorhanden sind. Die Zeile user_admin definiert einen Benutzer mit dem Benutzernamen admin und dem Passwort admin, der sich vom Außenrand mit dem Broker verbinden kann. Speichern Sie die Datei und schließen Sie sie, wenn Sie fertig sind.
Kafka muss sich der Datei kafka-server-jaas.conf bewusst sein, da sie die Hauptkonfiguration vervollständigt. Sie müssen die Konfiguration des kafka-Systemd-Dienstes anpassen und eine Referenz darauf übergeben. Führen Sie den folgenden Befehl aus, um den Dienst zum Bearbeiten zu öffnen:
Indem Sie --full übergeben, erhalten Sie Zugriff auf den vollständigen Inhalt des Dienstes. Suchen Sie die Zeile ExecStart:
Fügen Sie die folgende Zeile darüber hinzu, sodass es wie folgt aussieht:
Mit diesem Schritt setzen Sie den Parameter java.security.auth.login.config in der Konfiguration auf den Pfad zur JAAS-Konfigurationsdatei, indem Sie ihn von der Haupt-Kafka-Konfiguration abkoppeln. Wenn Sie fertig sind, speichern und schließen Sie die Datei. Laden Sie die Dienstdefinition neu, indem Sie laufen:
Starten Sie dann Kafka neu:
Sie haben nun sowohl TLS-Verschlüsselung als auch SASL-Authentifizierung für Ihre Kafka-Installation eingerichtet. Jetzt lernen Sie, wie Sie mit den bereitgestellten Konsoleinstellungenscripts zu ihr verbunden werden.
Schritt 2 – Verbindung mit einem verschlüsselten Cluster
In diesem Schritt erfahren Sie, wie Sie mit Hilfe von JAAS-Konfigurationsdateien, die Sie erhalten haben, zu einem verschlüsselten Kafka-Cluster verbunden werden.
Die bereitgestellten Skripte zum Manipulieren von Themen, die Nachrichten produzieren und verarbeiten, verwenden intern auch Java und akzeptieren somit eine JAAS-Konfiguration, die die Trust- und Key-Store-Positionen sowie die SASL-Anmeldeinformationen aufzeichnet.
Sie speichern diese Konfiguration in einer Datei namens client-jaas.conf im Ihren Home-Verzeichnis. Erstellen und öffnen Sie diese Datei zum Bearbeiten:
Fügen Sie die folgenden Zeilen hinzu:
Wie zuvor können Sie das Protokoll auf SASL_SSL setzen und den Pfad sowie das Passwort für die erstellten Schlüssel- und Vertrauensspeicher angeben. Danach legen Sie das SASL-Verfahren auf PLAIN fest und stellen Sie die Anmeldeinformationen für den Benutzer admin bereit. Sie setzen das Parameter ssl.endpoint.identification.algorithm explizit auf `null`, um Verbindungsprobleme zu vermeiden, da die initialen Skripte den Hostnamen der Maschine, auf der sie ausgeführt werden, als Zertifikatendpunkt festlegen, was möglicherweise nicht korrekt ist.
Ersetzen Sie your_tls_password mit der richtigen Values und speichern und schließen Sie die Datei anschließend.
Um diese Datei an die Skripte weiterzugeben, können Sie den Parameter --command-config verwenden. Versuchen Sie mit dem folgenden Befehl einen neuen Kanal im Cluster zu erstellen:
Der Befehl sollte erfolgreich ausgeführt werden:
Um zu überprüfen, ob er erstellt wurde, führen Sie den folgenden Befehl aus, um alle Kanäle im Cluster aufzulisten:
Die Ausgabe zeigt, dass new_topic vorhanden ist:
In diesem Abschnitt haben Sie Ihre Kafka-Installation so eingerichtet, dass sie TLS-Verschlüsselung für den Datenverkehr und SASL für die Authentifizierung mit Kombinationen von Benutzernamen und Passwörtern verwendet. Jetzt lernen Sie, wie Sie verschiedene Kafka-Metriken über JMX mit Prometheus exportieren können.
Schritt 3 – Überwachen von Kafka JMX-Metrik mit Prometheus
In diesem Abschnitt werden Sie Prometheus verwenden, um Kafka-Metriken zu sammeln und sie in Grafana abzufragen. Dies umfasst das Setzen des JMX-Exporters für Kafka und die Verbindung mit Prometheus.
[Java Management Extensions (JMX) ist ein Framework für Java-Anwendungen, das Entwicklern erlaubt, allgemeine und benutzerdefinierte Metriken über die Laufzeit der Anwendung in einer standardisierten Formate zu erfassen. Da Kafka in Java geschrieben ist, unterstützt es das JMX-Protokoll und exposeiert seine benutzerdefinierten Metriken über dieses, wie z.B. der Status von Themen und Kommunikationspartnern.
Kafka und Prometheus einrichten
Bevor Sie fortfahren, müssen Sie Prometheus installieren. Auf Ubuntu-Maschinen können Sie apt verwenden. Aktualisieren Sie seine Repositories, indem Sie den Befehl ausführen:
Installieren Sie anschließend Prometheus:
Für andere Plattformen folgen Sie bitte den Installationsanweisungen auf der offiziellen Website.
Sobald Sie es installiert haben, müssen Sie die JMX-Exporter-Bibliothek für Prometheus Ihrer Kafka-Installation hinzufügen. Navigieren Sie zu der Veröffentlichungsseite und wählen Sie die neueste Veröffentlichung mit javaagent im Namen aus. Zum Zeitpunkt der Schreibung der neuesten verfügbaren Version war 0.20.0. Verwenden Sie den folgenden Befehl, um es in das libs/ Verzeichnis herunterzuladen, wo Kafka installiert ist:
Die JMX-Exporter-Bibliothek wird nun von Kafka automatisch verwendet.
Bevor Sie den Exporter aktivieren, müssen Sie definieren, welche Metriken er an Prometheus melden wird, und Sie sollten diese Konfiguration in einer Datei namens jmx-exporter.yml unterhalb von config/ Ihrer Kafka-Installation speichern. Das JMX-Exporter-Projekt stellt eine geeignete Standardkonfiguration bereit, so dass Sie den folgenden Befehl ausführen können, um sie als jmx-exporter.yml unterhalb von config/ Ihrer Kafka-Installation zu speichern:
Nächstes, um den Exporter zu aktivieren, müssen Sie die Kafka-Systemd-Dienstdatei ändern. Sie müssen die KAFKA_OPTS Umgebungsvariable verändern, um den Exporter sowie seine Konfiguration einzubinden. Führen Sie den folgenden Befehl aus, um den Dienst zu bearbeiten:
Ändern Sie die Environment-Zeile so:
Hier verwenden Sie das -javaagent Argument, um den JMX-Exporter mit seiner Konfiguration zu initialisieren.
Wenn Sie fertig sind, speichern und schließen Sie die Datei, und starten Sie Kafka erneut, indem Sie:
Nach einer Minute verifizieren Sie, ob der JMX-Exporter laufend ist, indem Sie prüfen, ob der Port 7075 verwendet wird:
Diese Zeile zeigt, dass der Port 7075 von einem Java-Prozess verwendet wird, der vom Kafka-Dienst gestartet wird, was sich auf den JMX-Exporter bezieht.
Sie konfigurieren nun Prometheus, um die exportierten JMX-Metriken zu überwachen. Die Hauptkonfigurationsdatei befindet sich unter /etc/prometheus/prometheus.yml, öffnen Sie diese also zum Bearbeiten:
Finden Sie die folgenden Zeilen:
Unter scrape_configs, das festlegt, welche Endpunkte Prometheus überwachen soll, fügen Sie einen neuen Abschnitt für das Abtasten von Kafka-Metriken hinzu:
Der Job kafka hat einen Zielpunkt, der auf den JMX-Exporter-Endpunkt zeigt.
Denken Sie daran, your_domain mit Ihrem Domainnamen zu ersetzen, dann speichern und die Datei zu schließen. Starten Sie anschließend Prometheus neu, indem Sie laufen:
Öffnen Sie in Ihrem Browser die Seite auf Port 9090 Ihres Domains. Sie werden auf die Prometheus-Benutzeroberfläche zugreifen. Klicken Sie unter Status auf Ziele, um die Jobs aufzulisten:
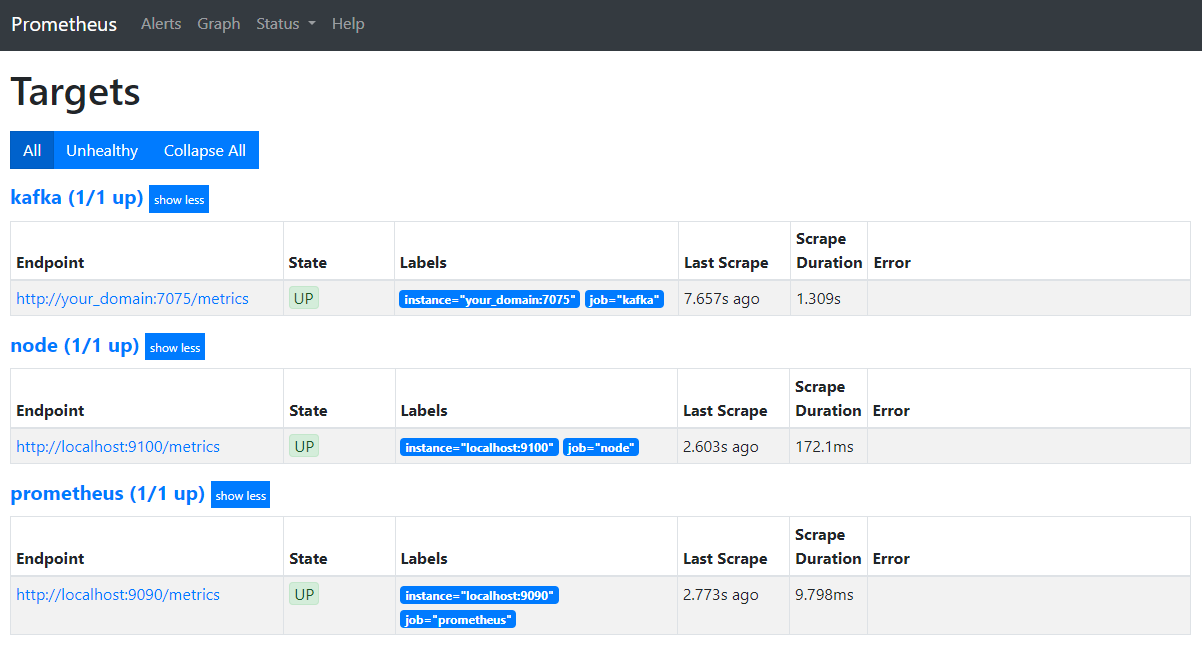
Beachten Sie, dass Prometheus den Job kafka akzeptiert und die Metriken begann abzurufen. Jetzt lernen Sie, wie Sie auf sie in Grafana zugreifen.
Metriken in Grafana abfragen
Als Teil der Voraussetzungen haben Sie Grafana auf Ihrem Droplet installiert und es unter your_domain暴露ed. Blättern Sie in Ihrem Browser dorthin und klicken Sie unter Verbindungen in der Seitenleiste auf Neue Verbindung hinzufügen, dann geben Sie Prometheus im Suchfeld ein.
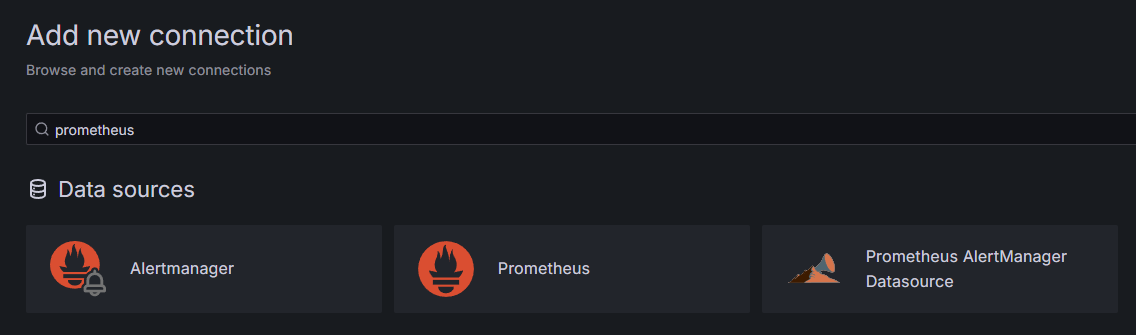
Klicken Sie auf Prometheus, dann auf den Knopf Neue Datenquelle hinzufügen oben rechts. Sie werden gebeten, die Adresse einer Prometheus-Instanz einzugeben:
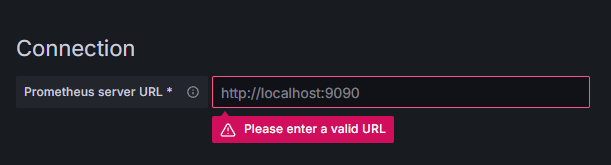
Geben Sie http://your_domain_name:9090 ein, ersetzen Sie dies mit Ihrem tatsächlichen Domänennamen, und klicken Sie dann unten scrollen und auf Speichern & Testen klicken. Sie sollten eine Erfolgsmeldung erhalten:

Die Prometheus-Verbindung wurde zu Grafana hinzugefügt. Klicken Sie auf Explorieren in der Seitenleiste, und Sie werden dazu aufgefordert, einen Metrik auszuwählen. Sie können kafka_ eingeben, um alle Metriken auflisten, die mit dem Cluster verknüpft sind, wie gezeigt:
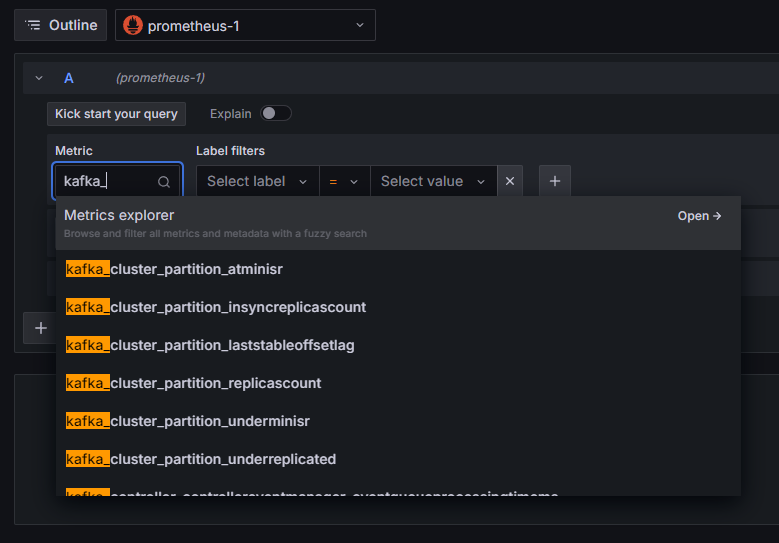
Zum Beispiel wählen Sie die Metrik kafka_log_log_size aus, die anzeigt, wie groß der interne Logdatei auf der Festplatte pro Partition ist, und klicken Sie dann auf Abfrage ausführen oben rechts. Sie sehen die resultierenden Größen im Verlauf für jede verfügbare Thema:
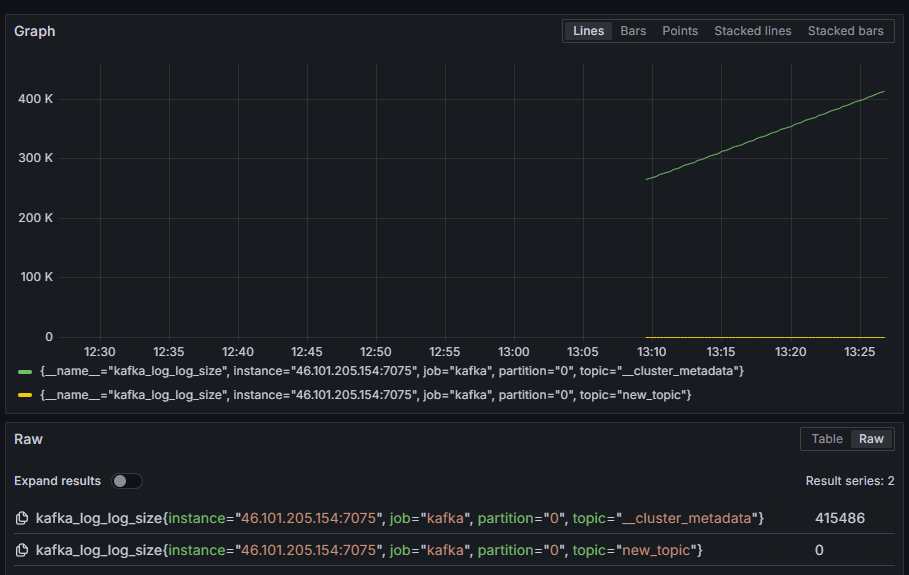
In diesem Schritt haben Sie die Exportierung von JMX-Metriken, die Kafka bereitstellt, eingerichtet und Prometheus konfiguriert, um diese abzurufen. Anschließend haben Sie sich von innerhalb von Grafana verbunden und eine Abfrage auf die Kafka-Metriken durchgeführt. Sie werden jetzt lernen, wie Sie einen Kafka-Cluster über eine Web-Oberfläche verwalten.
Schritt 4 – Verwaltung von Kafka-Clustern mit AKHQ
In diesem Schritt erfahren Sie, wie Sie AKHQ einrichten und verwenden, eine Web-App zur Verwaltung von Kafka-Clustern. Sie ermöglicht es Ihnen, Themen, Partitionen, Verbrauchergruppen und Konfigurationsparameter anzuzeigen und zu manipulieren, sowie Nachrichten aus Themen auf einer einzigen Plattform zu erstellen und zu konsumieren.
Sie speichern das ausführbare Programm und seine Konfiguration in einem Verzeichnis namens akhq. Erstellen Sie es in Ihrem Heimverzeichnis, indem Sie Folgendes ausführen:
Navigieren Sie zu ihm:
Öffnen Sie in Ihrem Browser die Seite mit den offiziellen Veröffentlichungen und kopieren Sie den Link zur JAR-Datei der neuesten Version. Zum Zeitpunkt der Verfassung dieser Anleitung war die neueste Version 0.24.0. Führen Sie den folgenden Befehl aus, um es in Ihr Heimverzeichnis herunterzuladen:
Sie haben nun AKHQ heruntergeladen und sind bereit, seine Konfiguration zur Verbindung mit Ihrem Cluster zu definieren. Sie speichern diese in einer Datei namens akhq-config.yml. Erstellen und öffnen Sie sie zum Bearbeiten, indem Sie Folgendes ausführen:
Fügen Sie die folgenden Zeilen hinzu:
Dies ist eine grundlegende AKHQ-Konfiguration, bei der ein Cluster unter localhost:9092 mit den zugehörigen SASL- und TLS-Parametern angegeben wird. Es wird auch die gleichzeitige Verwendung mehrerer Cluster unterstützt, da Sie so viele Verbindungen definieren können, wie Sie möchten. Dies macht AKHQ vielseitig für die Verwaltung von Kafka. Wenn Sie fertig sind, speichern Sie die Datei und schließen Sie sie.
Als nächstes müssen Sie einen systemd-Dienst definieren, um AKHQ im Hintergrund auszuführen. systemd-Dienste können konsistent gestartet, gestoppt und neu gestartet werden.
Sie speichern die Dienstkonfiguration in einer Datei namens code-server.service im Verzeichnis /lib/systemd/system, in dem systemd seine Dienste speichert. Erstellen Sie sie mit Ihrem Texteditor:
Fügen Sie die folgenden Zeilen hinzu:
Sie geben zuerst die Beschreibung des Diensts an. Dann definieren Sie im Abschnitt [Service] den Typ des Diensts (simple bedeutet, dass der Befehl einfach ausgeführt werden soll) und geben den auszuführenden Befehl an. Sie geben auch an, dass der Dienst unter dem Benutzer kafka ausgeführt wird und dass der Dienst bei Beenden automatisch neu gestartet werden soll.
Der Abschnitt [Install] weist systemd an, diesen Dienst beim Anmelden auf Ihrem Server zu starten. Speichern und schließen Sie die Datei, wenn Sie fertig sind.
Laden Sie die Dienstkonfiguration, indem Sie ausführen:
Starten Sie den AKHQ-Dienst, indem Sie den folgenden Befehl ausführen:
Dann überprüfen Sie, ob er korrekt gestartet wurde, indem Sie seinen Status beobachten:
Die Ausgabe sollte wie folgt aussehen:
AKHQ läuft nun im Hintergrund. Standardmäßig ist es über Port 8080 sichtbar. Navigieren Sie in Ihrem Browser zu Ihrem Domainnamen mit diesem Port, um auf es zuzugreifen. Sie sehen die Standardansicht, die die Liste der Themen anzeigt:
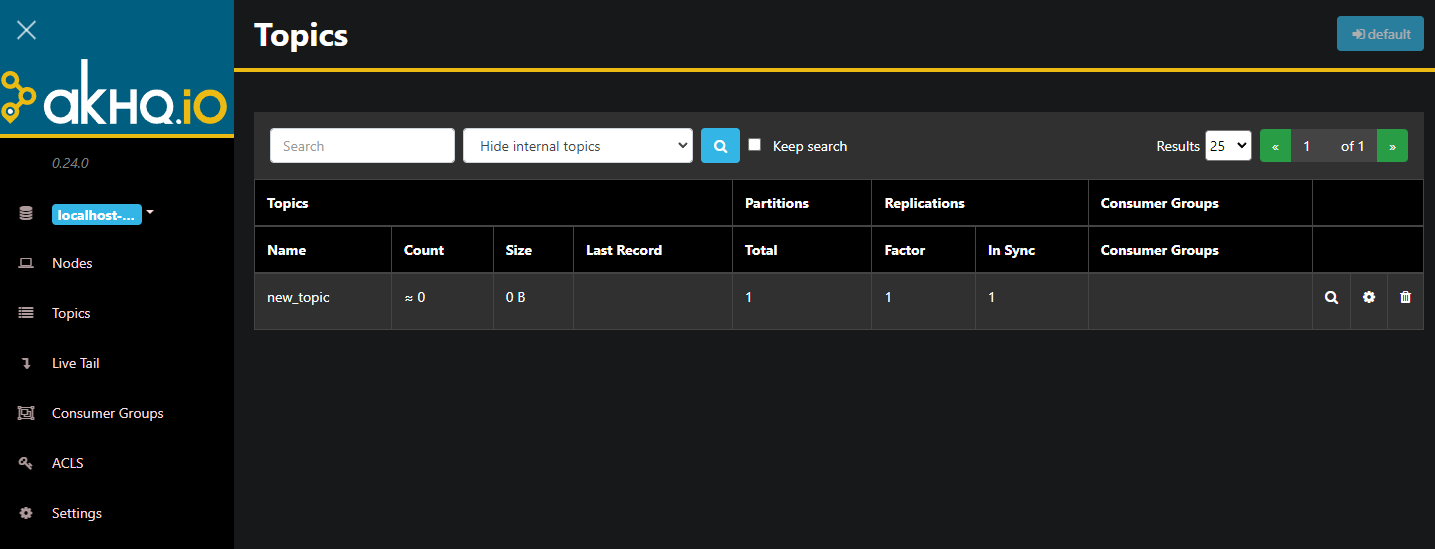
Sie können doppelt klicken auf die zugehörige Zeile eines Themas in der Tabelle, um zu diesem zuzugreifen und eine detaillierte Ansicht zu erhalten:
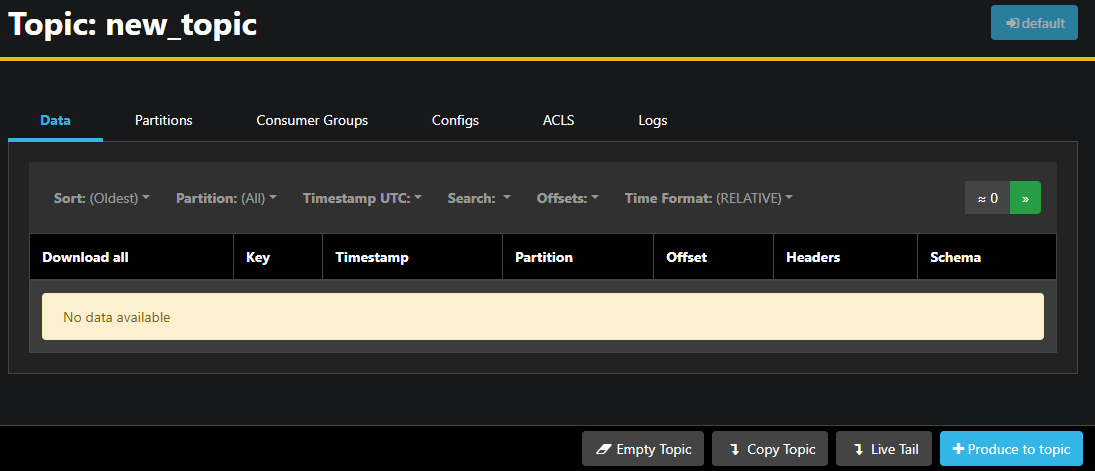
AKHQ ermöglicht Ihnen, die Nachrichten in der Thema anzuzeigen, sowie Partitionen, Konsumentengruppen und ihre Konfiguration. Sie können das Thema auch leeren oder kopieren, indem Sie die Schaltflächen in der rechten unteren Ecke verwenden.
Da das new_topic-Thema leer ist, drücken Sie die Schaltfläche Nachricht an Thema senden, die das Interface zum Auswählen der Parameter der neuen Nachricht öffnet:
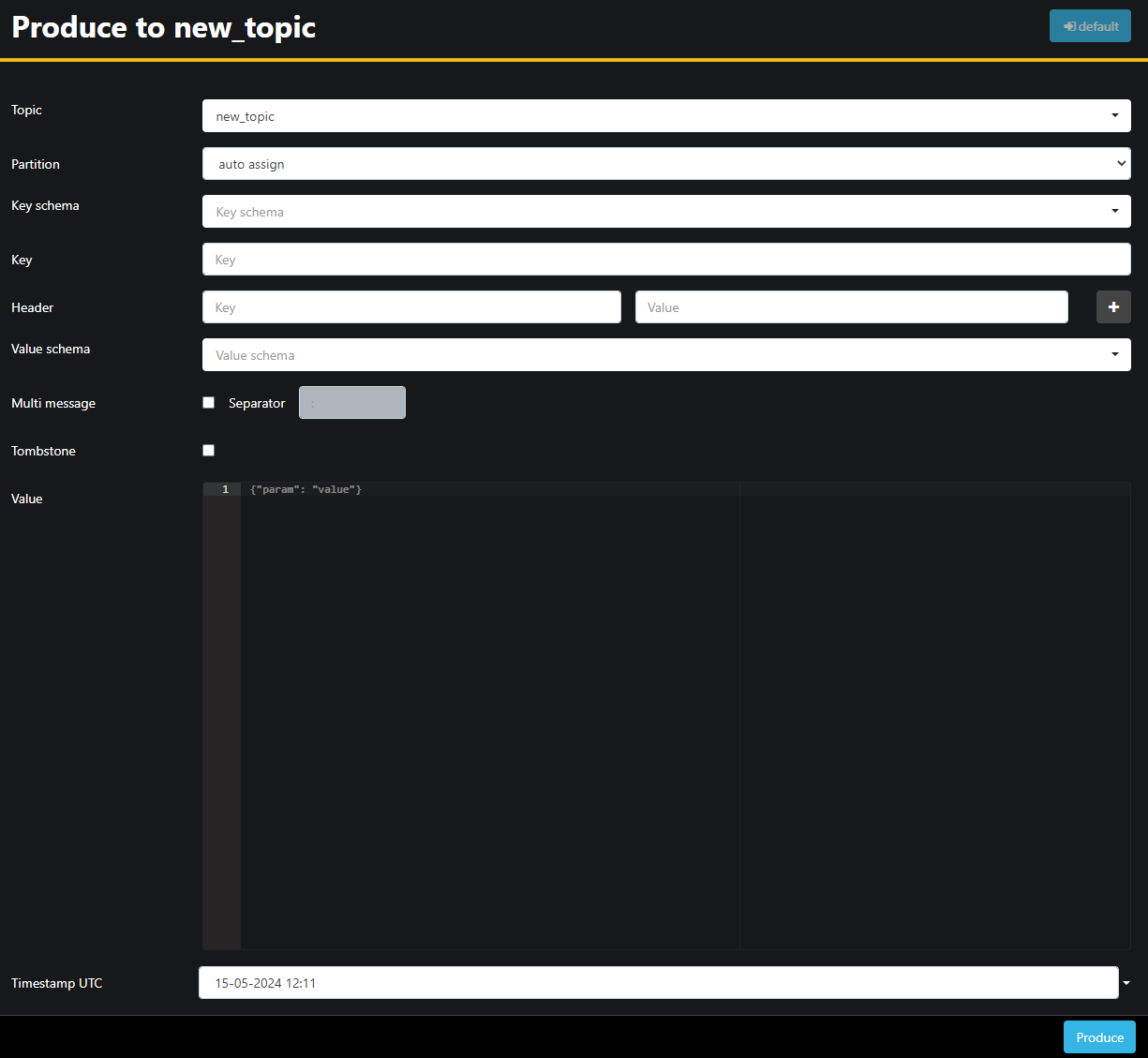
AKHQ füllt automatisch den Themenamen für Sie aus. im Wert-Feld geben Sie Hello World! ein, und drücken Sie dann Senden. Die Nachricht wird an Kafka gesendet, und Sie sehen sie im Daten-Tab:
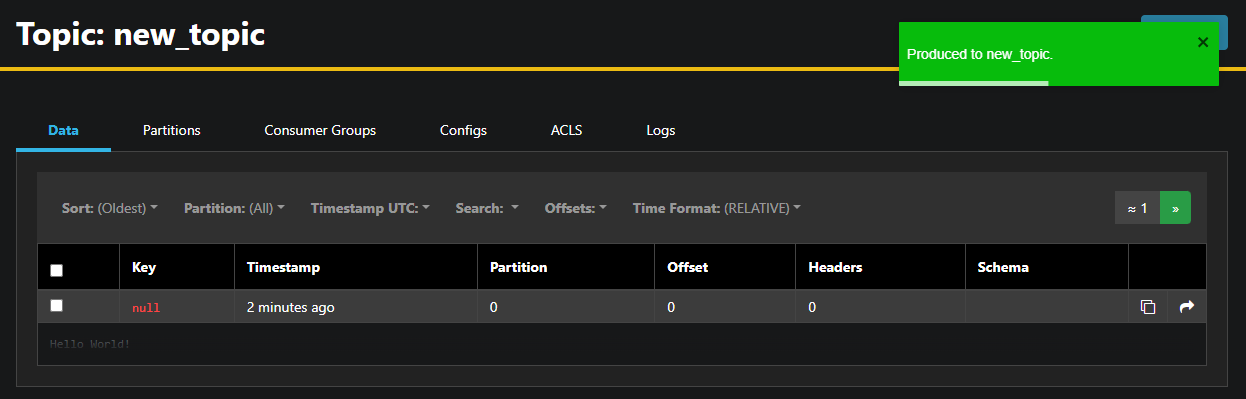
Da der Inhalt einer Nachricht sehr groß sein kann, zeigt AKHQ nur die erste Zeile an. Um die komplete Nachricht anzuzeigen, klicken Sie auf die dunkle Stelle nach der Zeile, um sie zu öffnen.
Im linken Seitenleiste können Sie auch die Knoten im Cluster aufrufen, indem Sie auf Knoten klicken. Derzeit besteht der Cluster aus nur einem Knoten:

Doppelklicken Sie auf einen Knoten, um seine Konfiguration zu öffnen und远程 bearbeiten Sie irgendeine der Einstellungen:
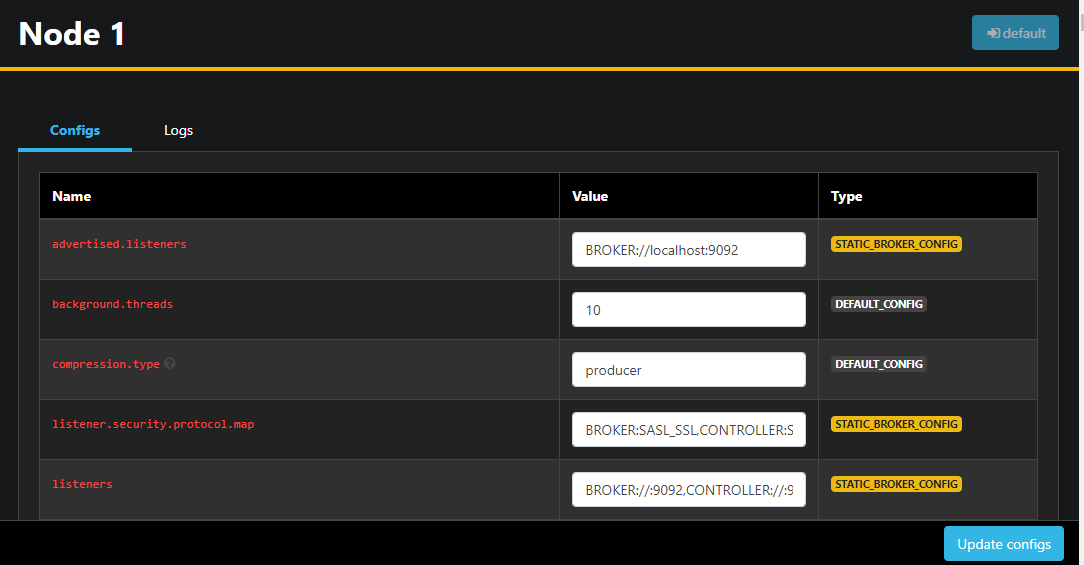
Sobald Sie Änderungen vorgenommen haben, können Sie diese anwenden, indem Sie auf die Schaltfläche Aktualisiere Konfigurationen in der unteren rechten Ecke klicken. Auf ähnliche Weise können Sie die Konfiguration jeder der Themen anzeigen und ändern, indem Sie darauf zugreifen und zum Konfigurationen-Tab wechseln.
In diesem Abschnitt haben Sie AKHQ eingerichtet, eine Web-App, die eine benutzerfreundliche Benutzeroberfläche zum Remote-Management und -Überwachen von Kafka-Knoten und -Themen bietet. Sie ermöglicht es Ihnen, Nachrichten in Themen zu erstellen und zu konsumieren und die Konfigurationsparameter sowohl der Themen als auch der Knoten on-the-fly zu aktualisieren.
Schlussfolgerung
In dieser Anleitung haben Sie Ihre Kafka-Installation durch die Konfiguration von TLS für die Verschlüsselung und SASL für die Benutzerauthentifizierung gesichert. Sie haben auch die Metrik-Exportierung mit Prometheus eingerichtet und in Grafana visualisiert. Anschließend haben Sie gelernt, wie Sie AKHQ, eine Web-App zum Verwalten von Kafka-Clustern, verwenden.
Der Autor hat die Apache Software Foundation ausgewählt, um eine Spende im Rahmen des Programms Schreibe für Spenden zu erhalten.
Source:
https://www.digitalocean.com/community/developer-center/how-to-secure-and-monitor-kafka