













In modernem Systemdesign konzentriert sich die Event-Driven Architecture (EDA) darauf, Ereignisse innerhalb eines Systems zu erstellen, zu erkennen, zu verwenden und darauf zu reagieren. Ereignisse sind bedeutende Vorkommnisse, die die Hardware oder Software eines Systems beeinflussen können, wie Benutzeraktionen, Statusänderungen oder Datenaktualisierungen.
EDA ermöglicht es verschiedenen Teilen einer Anwendung, in entkoppelter Weise miteinander zu interagieren, indem sie über Ereignisse anstatt über direkte Aufrufe kommunizieren. Diese Einrichtung ermöglicht es Komponenten, unabhängig voneinander zu arbeiten, auf Ereignisse asynchron zu reagieren und sich an sich ändernde geschäftliche Anforderungen anzupassen, ohne dass eine umfangreiche Systemneukonfiguration erforderlich ist, was die Agilität fördert.
Neue und moderne Anwendungen verlassen sich nun stark auf die Echtzeit-Datenverarbeitung und Reaktionsfähigkeit. Die Bedeutung der EDA ist nicht zu unterschätzen, da sie das Rahmenwerk bereitstellt, das diese Anforderungen unterstützt. Durch die Verwendung von asynchroner Kommunikation und ereignisgesteuerten Interaktionen können Systeme hohe Transaktionsvolumina effizient verarbeiten und die Leistung bei instabilen Lasten aufrechterhalten. Diese Funktionen werden insbesondere in Umgebungen geschätzt, in denen Änderungen sehr spontan erfolgen, wie beispielsweise bei E-Commerce-Plattformen oder IoT-Anwendungen.
Einige Schlüsselkomponenten der EDA umfassen:
-
Ereignisquellen: Dies sind die Produzenten, die Ereignisse generieren, wenn bedeutende Aktionen im System stattfinden. Beispiele hierfür sind Benutzerinteraktionen oder Datenänderungen.
-
Listener: Dies sind Entitäten, die sich für bestimmte Ereignisse anmelden und reagieren, wenn diese eintreten. Listener ermöglichen es dem System, dynamisch auf Änderungen zu reagieren.
-
Handler: Diese sind dafür verantwortlich, die Ereignisse zu verarbeiten, sobald sie von den Listenern erkannt werden, und die notwendige Geschäftslogik oder Workflows auszuführen, die durch das Ereignis ausgelöst werden.
In diesem Artikel erfahren Sie, wie Sie die ereignisgesteuerte Datenverarbeitung mit Traefik, Kafka und Docker implementieren können.
Hier finden Sie eine einfache Anwendung auf GitHub, die Sie schnell ausführen können, um einen Überblick darüber zu erhalten, was Sie heute aufbauen werden.
Inhaltsverzeichnis
Hier ist, was wir behandeln werden:
Lass uns anfangen!
Voraussetzungen
Bevor Sie beginnen:
-
Stellen Sie eine Ubuntu 24.04-Instanz mit mindestens 4 GB RAM und einem Minimum von 20 GB freiem Speicherplatz bereit, um Docker-Images, Container und Kafka-Daten aufzunehmen.
-
Greifen Sie mit einem nicht-root-Benutzer mit sudo-Berechtigungen auf die Instanz zu.
-
Aktualisieren Sie den Paketindex.
sudo apt update
Verständnis der Technologien
Apache Kafka
Apache Kafka ist eine verteilte Ereignis-Streaming-Plattform, die für Datenpipelines mit hohem Durchsatz und Echtzeit-Streaming-Anwendungen entwickelt wurde. Es dient als Rückgrat für die Implementierung von EDA durch effizientes Verwalten großer Ereignisvolumina. Kafka verwendet ein Publish-Subscribe-Modell, bei dem Produzenten Ereignisse an Themen senden und Verbraucher sich diesen Themen abonnieren, um die Ereignisse zu empfangen.
Einige der wichtigsten Funktionen von Kafka sind:
-
Hoher Durchsatz: Kafka ist in der Lage, Millionen von Ereignissen pro Sekunde mit geringer Latenz zu verarbeiten, was es für Anwendungen mit hohem Volumen geeignet macht.
-
Fehlertoleranz: Die verteilte Architektur von Kafka stellt die Datenbeständigkeit und -verfügbarkeit auch bei Serverausfällen sicher. Sie repliziert Daten über mehrere Broker innerhalb eines Clusters.
-
Skalierbarkeit: Kafka kann einfach horizontal skaliert werden, indem mehr Broker zum Cluster oder Partitionen zu Themen hinzugefügt werden, um wachsende Datenanforderungen ohne wesentliche Neukonfiguration zu bewältigen.
Traefik
Traefik ist ein moderner HTTP-Reverse-Proxy und Lastenausgleicher, der speziell für Mikroservices-Architekturen entwickelt wurde. Er entdeckt automatisch Dienste, die in Ihrer Infrastruktur ausgeführt werden, und leitet den Datenverkehr entsprechend weiter. Traefik vereinfacht das Management von Mikroservices, indem es dynamische Routingfähigkeiten basierend auf den Servicemetadaten bietet.
Zu den wichtigsten Funktionen von Traefik gehören:
-
Dynamische Konfiguration: Traefik aktualisiert automatisch seine Routingkonfiguration, wenn Dienste hinzugefügt oder entfernt werden, und eliminiert damit manuelle Eingriffe.
-
Load Balancing: Es verteilt eingehende Anfragen effizient auf mehrere Dienstinstanzen und verbessert Leistung und Zuverlässigkeit.
-
Integriertes Dashboard: Traefik bietet ein benutzerfreundliches Dashboard zur Überwachung des Datenverkehrs und des Zustands der Dienste in Echtzeit.
Indem Sie Kafka und Traefik in einer ereignisgesteuerten Architektur verwenden, können Sie reaktionsfähige Systeme aufbauen, die Echtzeit-Datenverarbeitung effizient bewältigen und gleichzeitig eine hohe Verfügbarkeit und Skalierbarkeit gewährleisten.
So richten Sie die Umgebung ein
So installieren Sie Docker unter Ubuntu 24.04
- Installieren Sie die erforderlichen Pakete.
sudo apt install ca-certificates curl gnupg lsb-release
- Fügen Sie den offiziellen GPG-Schlüssel von Docker hinzu.
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo gpg --dearmor -o /etc/apt/keyrings/docker.gpg
- Fügen Sie das Docker-Repository Ihren APT-Quellen hinzu.
echo "deb [arch=$(dpkg --print-architecture) signed-by=/etc/apt/keyrings/docker.gpg] https://download.docker.com/linux/ubuntu $(lsb_release -cs) stable" | sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
- Aktualisieren Sie den Paketindex erneut und installieren Sie Docker Engine mit dem Docker Compose-Plugin.
sudo apt update
sudo apt install docker-ce docker-ce-cli containerd.io docker-compose-plugin
- Überprüfen Sie die Installation.
sudo docker run hello-world
Erwartete Ausgabe:
Unable to find image 'hello-world:latest' locally
latest: Pulling from library/hello-world
c1ec31eb5944: Pull complete
Digest: sha256:305243c734571da2d100c8c8b3c3167a098cab6049c9a5b066b6021a60fcb966
Status: Downloaded newer image for hello-world:latest
Hello from Docker!
This message shows that your installation appears to be working correctly.
So konfigurieren Sie Docker Compose
Docker Compose vereinfacht das Management von Multi-Container-Anwendungen, indem Sie Dienste in einer einzigen Datei definieren und ausführen können.
- Erstellen Sie ein Projektverzeichnis
mkdir ~/kafka-traefik-setup && cd ~/kafka-traefik-setup
- Erstellen Sie eine
docker-compose.yml-Datei.
nano docker-compose.yml
- Fügen Sie die folgende Konfiguration zur Datei hinzu, um Ihre Dienste zu definieren.
version: '3.8'
services:
kafka:
image: wurstmeister/kafka:latest
ports:
- "9092:9092"
environment:
KAFKA_ADVERTISED_LISTENERS: INSIDE://kafka:9092,OUTSIDE://localhost:9092
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: INSIDE:PLAINTEXT,OUTSIDE:PLAINTEXT
KAFKA_LISTENERS: INSIDE://0.0.0.0:9092,OUTSIDE://0.0.0.0:9092
KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181
zookeeper:
image: wurstmeister/zookeeper:latest
ports:
- "2181:2181"
traefik:
image: traefik:v2.9
ports:
- "80:80" # HTTP-Verkehr
- "8080:8080" # Traefik-Dashboard (unsicher)
command:
- "--api.insecure=true"
- "--providers.docker=true"
volumes:
- "/var/run/docker.sock:/var/run/docker.sock"
Speichern Sie Ihre Änderungen mit Strg + o und beenden Sie dann mit Strg + x.
- Starten Sie Ihre Dienste.
docker compose up -d
Erwartete Ausgabe:
[+] Running 4/4
✔ Network kafka-traefik-setup_default Created 0.2s
✔ Container kafka-traefik-setup-zookeeper-1 Started 1.9s
✔ Container kafka-traefik-setup-traefik-1 Started 1.9s
✔ Container kafka-traefik-setup-kafka-1 Started 1.9s
Wie man das ereignisgesteuerte System erstellt
Wie man Ereignisproduzenten erstellt
Um Ereignisse in Kafka zu produzieren, müssen Sie einen Kafka-Produzenten implementieren. Hier ist ein Beispiel mit Java.
- Erstellen Sie eine Datei
kafka-producer.java.
nano kafka-producer.java
- Fügen Sie die folgende Konfiguration für einen Kafka-Produzenten hinzu.
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
import java.util.Properties;
public class SimpleProducer {
public static void main(String[] args) {
// Producer-Eigenschaften einrichten
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
// Produzent erstellen
KafkaProducer<String, String> producer = new KafkaProducer<>(props);
try {
// Nachricht an das Thema "mein-thema" senden
ProducerRecord<String, String> record = new ProducerRecord<>("my-topic", "key1", "Hello, Kafka!");
RecordMetadata metadata = producer.send(record).get(); // Synchrones Senden
System.out.printf("Sent message with key %s to partition %d with offset %d%n",
record.key(), metadata.partition(), metadata.offset());
} catch (Exception e) {
e.printStackTrace();
} finally {
// Produzent schließen
producer.close();
}
}
}
Speichern Sie Ihre Änderungen mit Strg + o und beenden Sie dann mit Strg + x.
In der obigen Konfiguration sendet der Produzent eine Nachricht mit dem Schlüssel „key1“ und dem Wert „Hallo, Kafka!“ an das Thema „mein-thema“.
Wie man Kafka-Themen einrichtet
Vor dem Produzieren oder Konsumieren von Nachrichten müssen Sie Themen in Kafka erstellen.
- Verwenden Sie das Skript
kafka-topics.sh, das mit Ihrer Kafka-Installation geliefert wird, um ein Thema zu erstellen.
kafka-topics.sh --bootstrap-server localhost:9092 --create --topic <TopicName> --partitions <NumberOfPartitions> --replication-factor <ReplicationFactor>
Zum Beispiel, wenn Sie ein Thema mit dem Namen my-topic mit 3 Partitionen und einem Replikationsfaktor von 1 erstellen möchten, führen Sie aus:
docker exec <Kafka Container ID> /opt/kafka/bin/kafka-topics.sh --bootstrap-server localhost:9092 --create --topic my-topic --partitions 3 --replication-factor 1
Erwartete Ausgabe:
Created topic my-topic.
- Überprüfen Sie, ob das Thema erfolgreich erstellt wurde.
docker exec -it kafka-traefik-setup-kafka-1 /opt/kafka/bin/kafka-topics.sh --bootstrap-server localhost:9092 --list
Erwartete Ausgabe:
my-topic
Wie man Event-Verbraucher erstellt
Nachdem Sie Ihre Produzenten und Themen erstellt haben, können Sie Verbraucher erstellen, um Nachrichten von diesen Themen zu lesen.
- Erstellen Sie eine Datei
kafka-consumer.java.
nano kafka-consumer.java
- Fügen Sie die folgende Konfiguration für einen Kafka-Verbraucher hinzu.
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import java.time.Duration;
import java.util.Collections;
import java.util.Properties;
public class SimpleConsumer {
public static void main(String[] args) {
// Verbrauchereigenschaften einrichten
Properties props = new Properties();
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
props.put(ConsumerConfig.GROUP_ID_CONFIG, "my-group");
props.put(ConsumerConfig.KEY_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer");
props.put(ConsumerConfig.VALUE_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer");
// Verbraucher erstellen
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
// Für das Thema abonnieren
consumer.subscribe(Collections.singletonList("my-topic"));
try {
while (true) {
// Auf neue Datensätze abfragen
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord<String, String> record : records) {
System.out.printf("Consumed message with key %s and value %s from partition %d at offset %d%n",
record.key(), record.value(), record.partition(), record.offset());
}
}
} finally {
// Verbraucher schließen
consumer.close();
}
}
}
Ihre Änderungen mit Strg + o speichern und mit Strg + x beenden.
In der obigen Konfiguration abonniert der Verbraucher my-topic und fragt kontinuierlich nach neuen Nachrichten. Wenn Nachrichten empfangen werden, gibt er deren Schlüssel und Werte sowie Informationen zur Partition und zum Offset aus.
Wie man Traefik mit Kafka integriert
Konfigurieren Sie Traefik als Reverse Proxy.
Die Integration von Traefik als Reverse Proxy für Kafka ermöglicht es Ihnen, den eingehenden Traffic effizient zu verwalten und Funktionen wie dynamisches Routing und SSL-Terminierung bereitzustellen.
- Aktualisieren Sie die Datei
docker-compose.yml.
version: '3.8'
services:
kafka:
image: wurstmeister/kafka:latest
ports:
- "9092:9092"
environment:
KAFKA_ADVERTISED_LISTENERS: INSIDE://kafka:9092,OUTSIDE://localhost:9092
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: INSIDE:PLAINTEXT,OUTSIDE:PLAINTEXT
KAFKA_LISTENERS: INSIDE://0.0.0.0:9092,OUTSIDE://0.0.0.0:9092
KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181
labels:
- "traefik.enable=true"
- "traefik.http.routers.kafka.rule=Host(`kafka.example.com`)"
- "traefik.http.services.kafka.loadbalancer.server.port=9092"
zookeeper:
image: wurstmeister/zookeeper:latest
ports:
- "2181:2181"
traefik:
image: traefik:v2.9
ports:
- "80:80" # HTTP-Traffic
- "8080:8080" # Traefik-Dashboard (unsicher)
command:
- "--api.insecure=true"
- "--providers.docker=true"
volumes:
- "/var/run/docker.sock:/var/run/docker.sock"
In dieser Konfiguration ersetzen Sie kafka.example.com durch Ihren tatsächlichen Domainnamen. Die Labels definieren die Routing-Regeln, die Traefik verwenden wird, um den Traffic zum Kafka-Dienst zu leiten.
- Starten Sie Ihre Dienste neu.
docker compose up -d
-
Greifen Sie auf Ihr Traefik-Dashboard zu, indem Sie
http://localhost:8080in Ihrem Webbrowser aufrufen.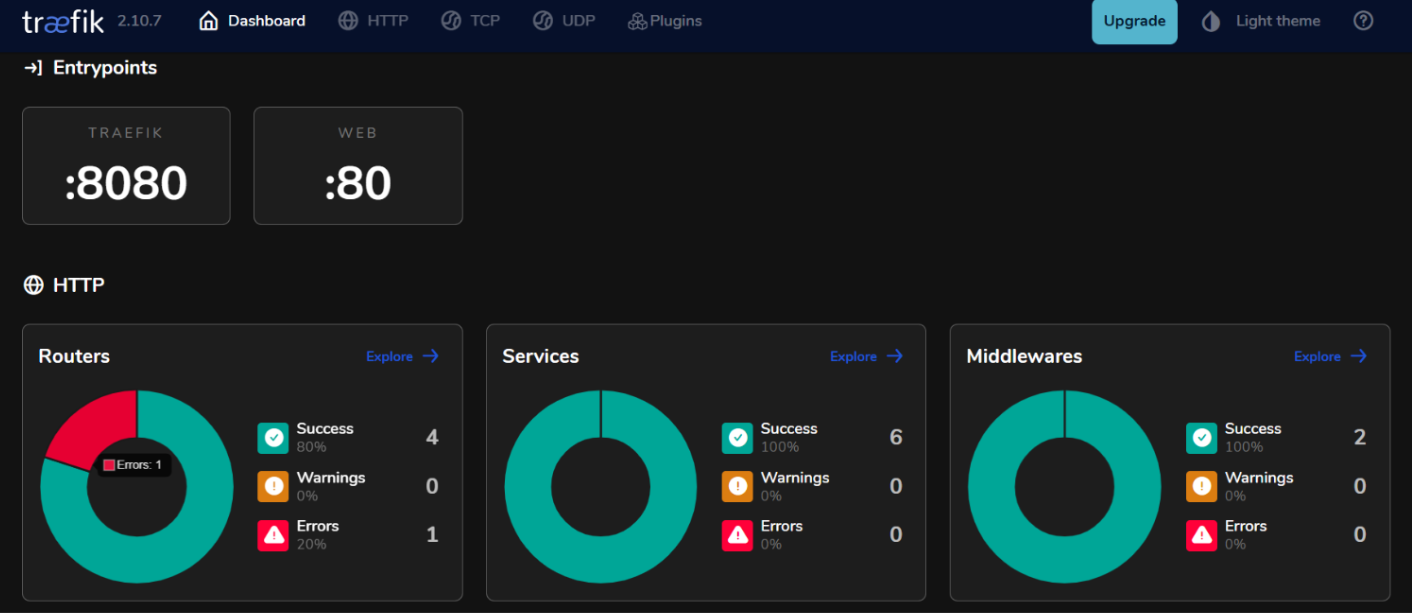
Lastenausgleich mit Traefik
Traefik bietet eingebaute Lastenausgleichsfunktionen, die helfen können, Anfragen auf mehrere Instanzen Ihrer Kafka-Produzenten und -Verbraucher zu verteilen.
Strategien für den Lastenausgleich bei ereignisgesteuerten Microservices
- Round Robin:
Standardmäßig verwendet Traefik eine Round-Robin-Strategie, um eingehende Anfragen gleichmäßig auf alle verfügbaren Instanzen eines Dienstes zu verteilen. Dies ist effektiv zur Lastenverteilung, wenn mehrere Instanzen von Kafka-Produzenten oder -Verbrauchern ausgeführt werden.
- Sticky Sessions:
Wenn Sie benötigen, dass Anfragen eines bestimmten Clients immer zur gleichen Instanz gehen (zum Beispiel zur Aufrechterhaltung des Sitzungszustands), können Sie in Traefik klebrige Sitzungen mit Cookies oder Headern konfigurieren.
- Health Checks:
Konfigurieren Sie Gesundheitsprüfungen in Traefik, um sicherzustellen, dass der Datenverkehr nur zu gesunden Instanzen Ihrer Kafka-Dienste geroutet wird. Dies können Sie durch das Hinzufügen von Gesundheitsprüfungsparametern in den Servicedefinitionen in Ihrer docker-compose.yml-Datei erreichen:
labels:
- "traefik.http.services.kafka.loadbalancer.healthcheck.path=/health"
- "traefik.http.services.kafka.loadbalancer.healthcheck.interval=10s"
- "traefik.http.services.kafka.loadbalancer.healthcheck.timeout=3s"
Testen des Setups
Überprüfen der Ereignisproduktion und -verbrauch
- Kafka bietet integrierte Befehlszeilentools für Tests. Starten Sie einen Konsolenproduzenten.
docker exec -it kafka-traefik-setup-kafka-1 /opt/kafka/bin/kafka-console-producer.sh --broker-list localhost:9092 --topic my-topic
Nach Ausführung dieses Befehls können Sie Nachrichten in das Terminal eingeben, die an das angegebene Kafka-Thema gesendet werden.
- Starten Sie eine weitere Terminal-Sitzung und starten Sie einen Konsolen-Verbraucher.
docker exec -it kafka-traefik-setup-kafka-1 /opt/kafka/bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic my-topic --from-beginning
Dieser Befehl zeigt alle Nachrichten im my-topic an, einschließlich derer, die vor dem Start des Verbrauchers produziert wurden.
- Um zu sehen, wie gut Ihre Verbraucher mit den Produzenten mithalten, können Sie den folgenden Befehl ausführen, um den Rückstand für eine spezifische Verbrauchergruppe zu überprüfen.
docker exec -it kafka-traefik-setup-kafka-1 /opt/kafka/bin/kafka-consumer-groups.sh --bootstrap-server localhost:9092 --describe --group <your-consumer-group>
Überwachung und Protokollierung
- Kafka-Metriken:
Kafka stellt zahlreiche Metriken bereit, die mithilfe von JMX (Java Management Extensions) überwacht werden können. Sie können JMX konfigurieren, um diese Metriken an Überwachungssysteme wie Prometheus oder Grafana zu exportieren. Zu überwachende Schlüsselmetriken umfassen:
-
Nachrichtendurchsatz: Die Rate der produzierten und konsumierten Nachrichten.
-
Verbraucherrückstand: Der Unterschied zwischen dem Offset der zuletzt produzierten Nachricht und dem Offset der zuletzt konsumierten Nachricht.
-
Broker-Gesundheit: Metriken im Zusammenhang mit der Leistung des Brokers, wie Anforderungsraten und Fehlerquoten.
- Prometheus- und Grafana-Integration:
Um Kafka-Metriken zu visualisieren, können Sie Prometheus einrichten, um Metriken von Ihren Kafka-Brokern abzurufen. Befolgen Sie diese Schritte:
-
Aktivieren Sie den JMX Exporter auf Ihren Kafka-Brokern, indem Sie ihn als Java-Agent in Ihrer Broker-Konfiguration hinzufügen.
-
Konfigurieren Sie Prometheus, indem Sie einen Scrape-Job in der Konfigurationsdatei (
prometheus.yml) hinzufügen, der auf Ihren JMX Exporter-Endpunkt verweist. -
Verwenden Sie Grafana, um Dashboards zu erstellen, die diese Metriken in Echtzeit visualisieren.
Wie implementiert man Monitoring für Traefik
- Traefik Metrics Endpoint.
Traefik bietet eine integrierte Unterstützung für das Exportieren von Metriken über Prometheus. Um diese Funktion zu aktivieren, fügen Sie die folgende Konfiguration in Ihre Traefik-Service-Definition in der Datei docker-compose.yml hinzu:
command:
- "--metrics.prometheus=true"
- "--metrics.prometheus.addservice=true"
- Visualisieren von Traefik-Metriken mit Grafana.
Sobald Prometheus Traefik-Metriken abruft, können Sie sie mithilfe von Grafana visualisieren:
-
Erstellen Sie ein neues Dashboard in Grafana und fügen Sie Panels hinzu, die wichtige Traefik-Metriken wie anzeigen:
-
traefik_entrypoint_requests_total: Gesamtzahl der empfangenen Anfragen.
-
traefik_backend_request_duration_seconds: Antwortzeiten von Backend-Services.
-
traefik_service_requests_total: Gesamtanzahl der Anfragen, die an Backend-Services weitergeleitet wurden.
- Einrichten von Warnmeldungen.
Konfigurieren Sie Warnmeldungen in Prometheus oder Grafana basierend auf spezifischen Schwellenwerten (z. B. hohe Verzögerung bei der Verbraucherdatenverarbeitung oder erhöhte Fehlerquoten).
Schlussfolgerung
In diesem Leitfaden haben Sie erfolgreich die ereignisgesteuerte Architektur (EDA) unter Verwendung von Kafka und Traefik in der Ubuntu 24.04-Umgebung implementiert.
Zusätzliche Ressourcen
Um mehr zu erfahren, können Sie besuchen:
-
Vultr-Anleitung für die Einrichtung des Traefik-Proxy auf Ubuntu 24.04
Source:
https://www.freecodecamp.org/news/how-to-implement-event-driven-data-processing/