













Im Teil 1 haben wir mehrere wichtige Themen behandelt. Ich empfehle Ihnen, es zu lesen, da dieser nächste Teil darauf aufbaut.
Zur schnellen Wiederholung, im Teil 1, haben wir unsere Daten aus der großen Perspektive betrachtet und zwischen Daten innen und Daten außen unterschieden. Wir haben auch Schemata und Datenverträge diskutiert und wie sie die Mittel bieten, um unsere Streams im Laufe der Zeit zu verhandeln, zu ändern und zu entwickeln. Schließlich haben wir die Ereignistypen Fakt (Zustand) und Delta behandelt. Fakt-Ereignisse sind am besten geeignet, um Zustände zu kommunizieren und Systeme zu entkoppeln, während Delta-Ereignisse eher für Daten innen verwendet werden, wie bei Event Sourcing und anderen eng gekoppelten Anwendungsfällen.
Normalisierte Tabellen erzeugen normalisierte Streams
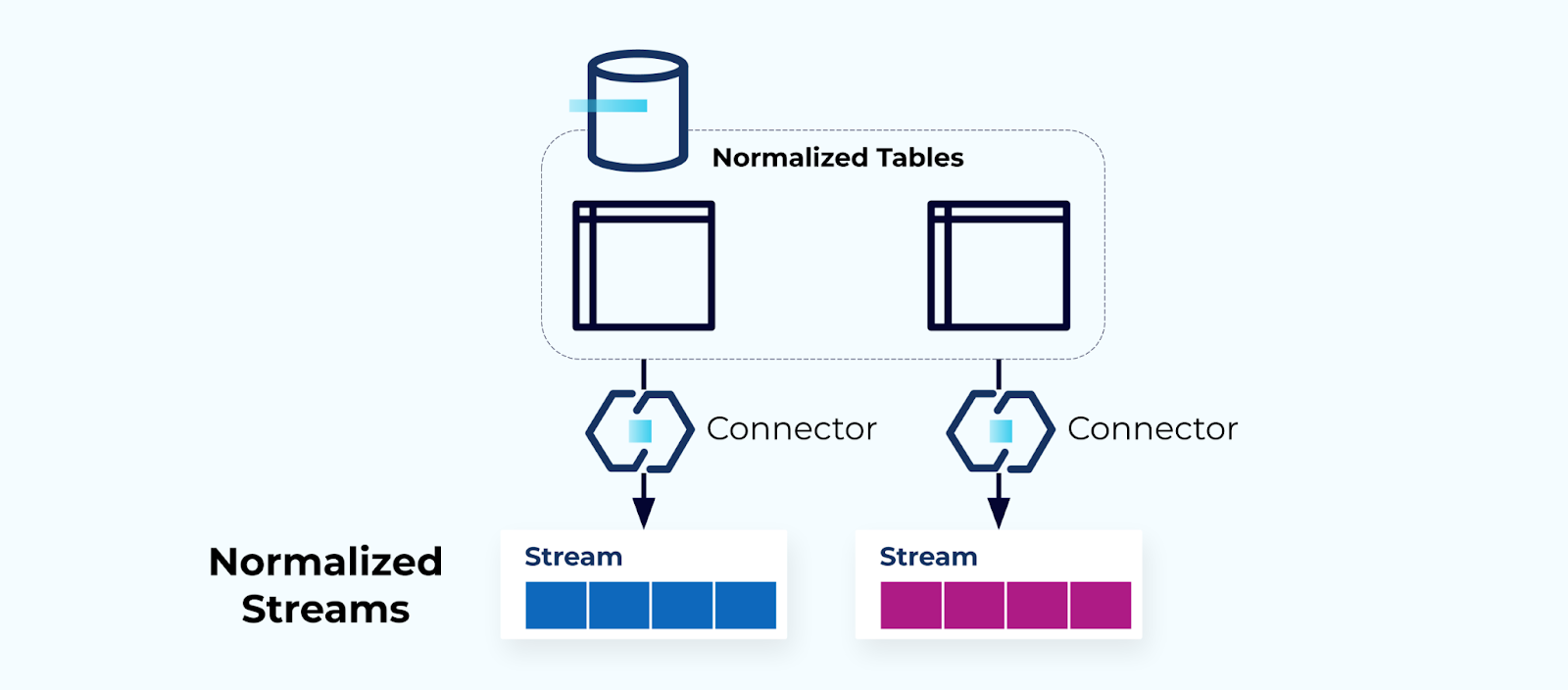
Normalisierte Tabellen führen zu normalisierten Ereignis-Streams. Konnektoren (z.B. CDC) ziehen Daten direkt aus der Datenbank in ein gespiegeltes Set von Ereignis-Streams. Dies ist nicht ideal, da es eine starke Kopplung zwischen den internen Datenbanktabellen und den externen Ereignis-Streams schafft.
Betrachten Sie ein einfaches E-Commerce-Item und dessen zugehörige Brand– und Steuerstatus-Tabellen.
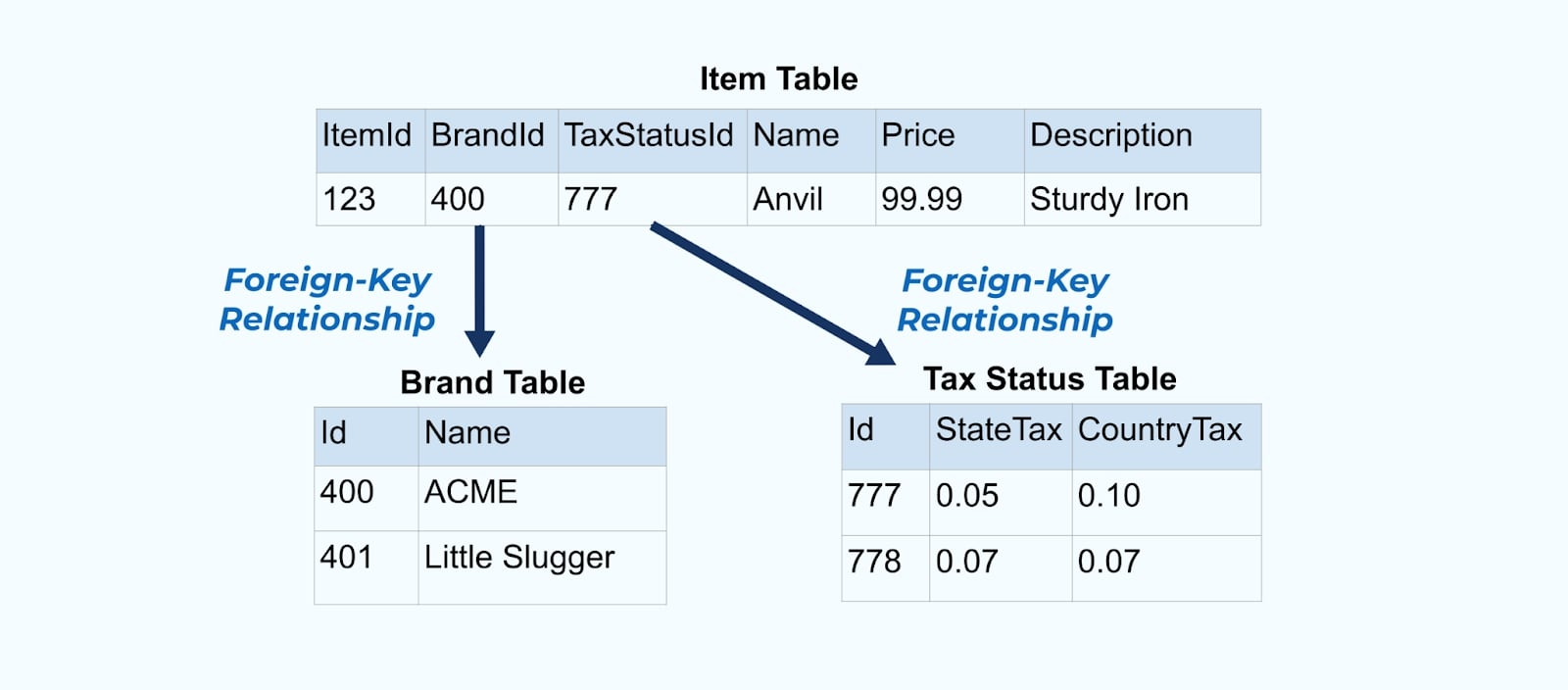
Die Brand– und Steuerstatus-Tabellen stehen in Beziehung zur Item-Tabelle über Fremdschlüsselbeziehungen. Während wir nur ein Item in der Tabelle zeigen, werden Sie wahrscheinlich Tausende (oder Millionen) haben, abhängig von den Produkten, die Sie verkaufen.
Es ist üblich, für jede Tabelle einen Connector einzurichten, die Daten aus der Tabelle herauszuholen, sie zu Ereignissen zu komponieren und jede Tabelle in einen dedizierten Ereignisstrom zu schreiben.
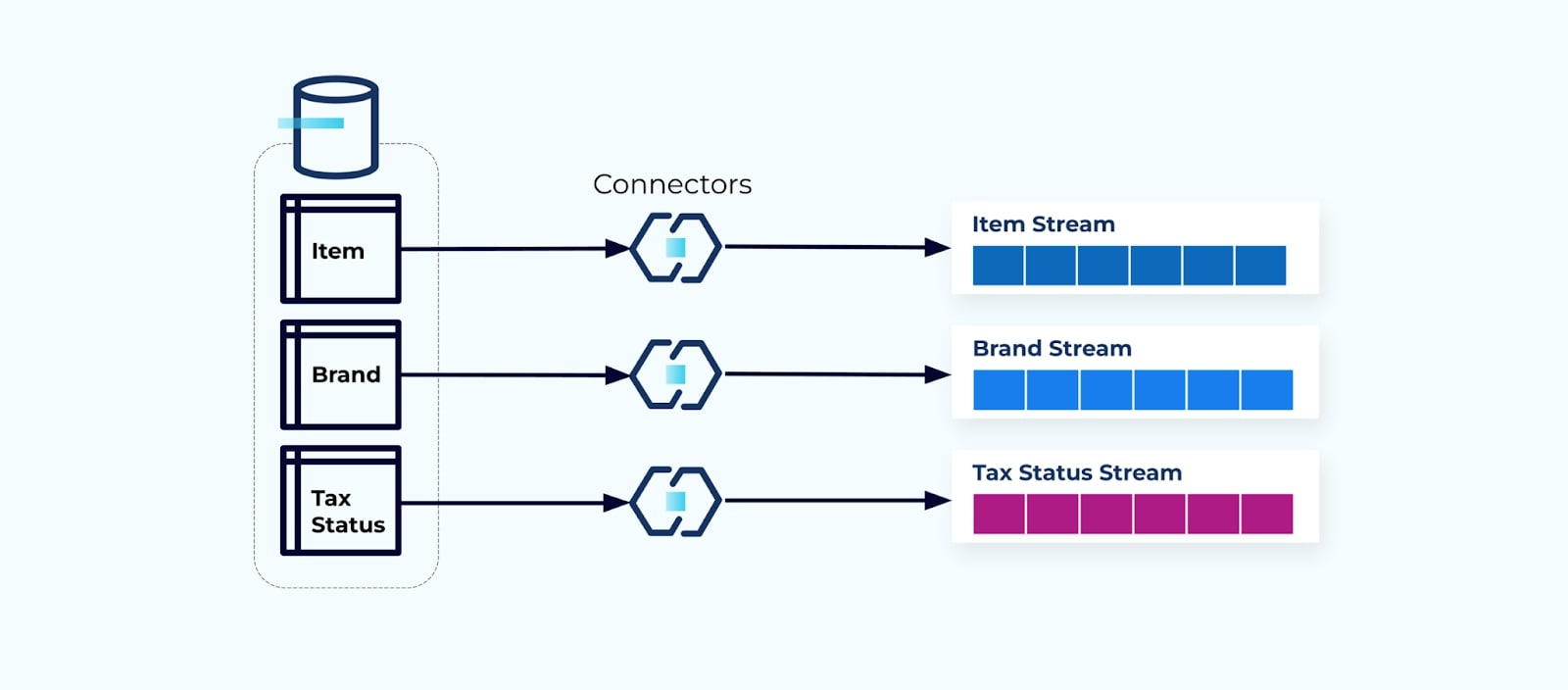
Das Offenlegen der zugrunde liegenden Tabellen in der Datenbank führt zu einem entsprechenden Ereignisstrom pro Tabelle. Während es auf diese Weise einfach ist, loszulegen, führt dies zu mehreren Problemen, die entweder als Kopplungs-Problem oder als Kost-Problem zusammengefasst werden können. Lassen Sie uns jedes betrachten.
Problem: Verbraucher koppeln am internen Modell
Das Offenlegen der Quelldatenbank Item so, wie sie ist, zwingt die Verbraucher, direkt daran zu koppeln. Änderungen am Datenmodell des Quellsystems wirken sich auf die nachgelagerten Verbraucher aus.
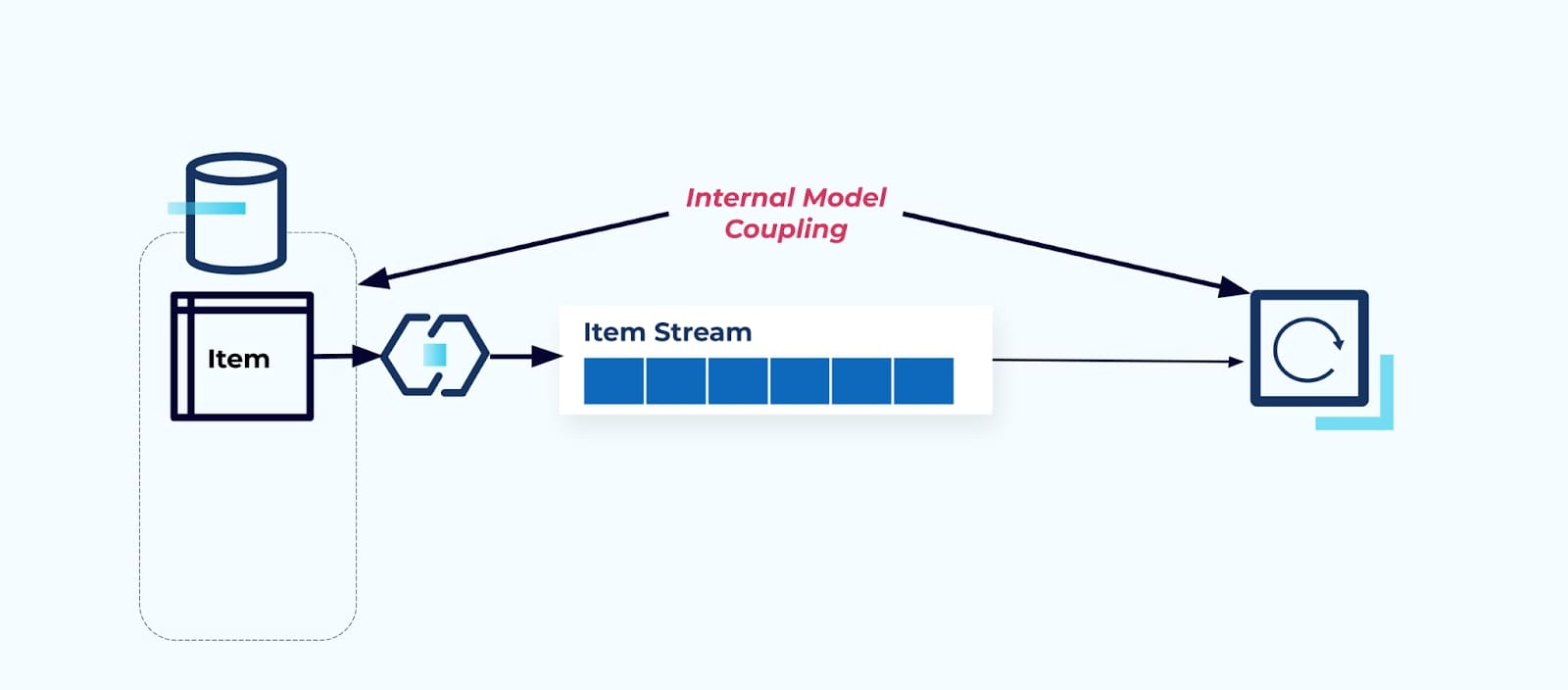
Nehmen wir an, wir refaktorisieren die Tabelle Item, um Pricing in eine eigene Tabelle zu extrahieren.
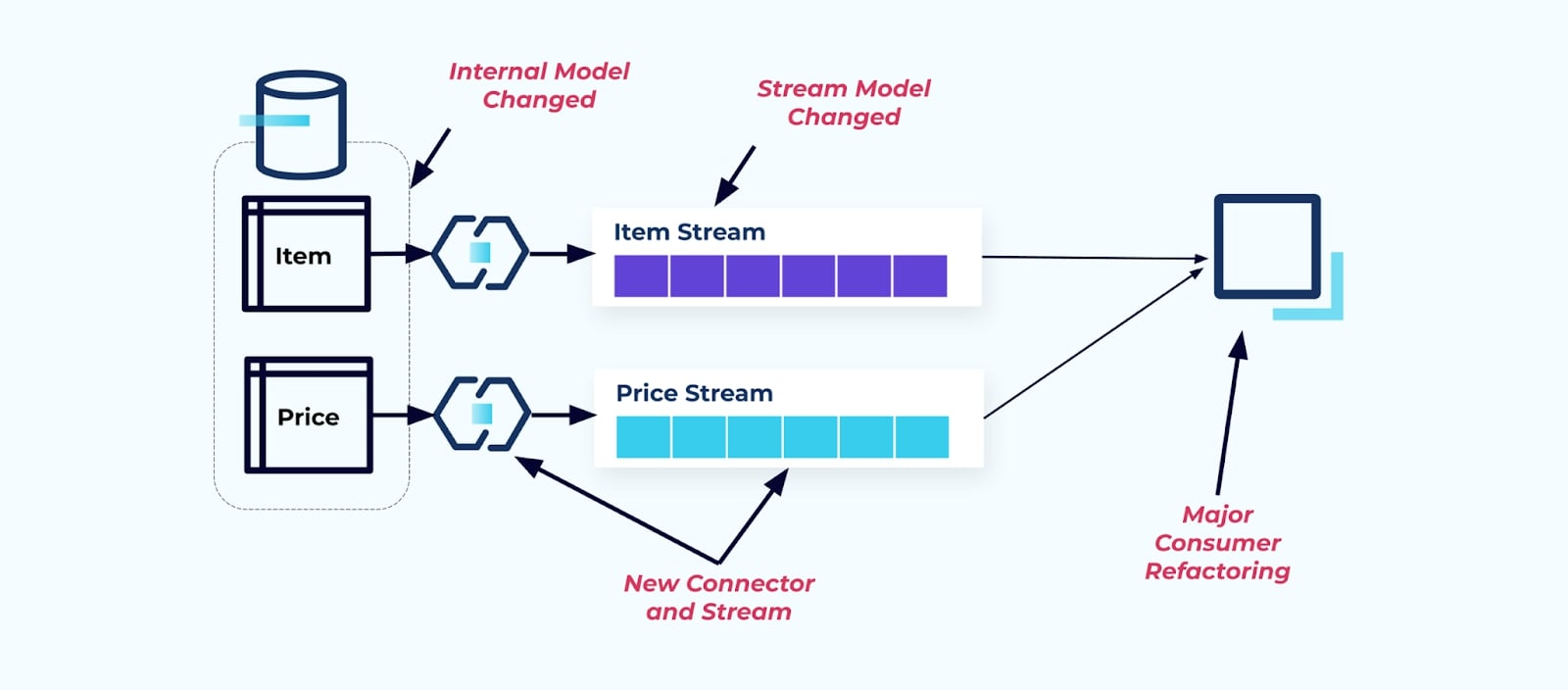
Das Refactoring der Quelletabellen führt zu einem gebrochenen Datenvertrag für den Elementstrom. Der Verbraucher erhält nicht mehr die gleichen Elementdaten, die ursprünglich erwartet wurden. Wir müssen auch einen neuen Connector erstellen — einen neuen Preis-Strom — und schließlich unsere Verbraucherlogik refaktorisieren, um ihn wieder zum Laufen zu bringen. Das Umbenennen von Spalten, das Ändern von Standardwerten und das Ändern von Spaltentypen sind weitere Formen von breaking changes, die durch enge Kopplung am internen Datenmodell eingeführt werden.
Problem: Streaming-Joins sind (normalerweise) teuer
Relationale Datenbanken sind speziell dafür ausgelegt, Joins schnell und kostengünstig aufzulösen. Streaming-Joins hingegen leider nicht.
Betrachten wir zwei Dienste, die Zugriff auf ein Element, seine Steuer und seine Marke-Informationen wünschen. Wenn die Daten bereits in den entsprechenden Strom geschrieben wurden, muss jeder Verbraucher (rechts im untenstehenden Bild) die gleichen Joins berechnen, um Item, Brand und Tax zu denormalisieren.
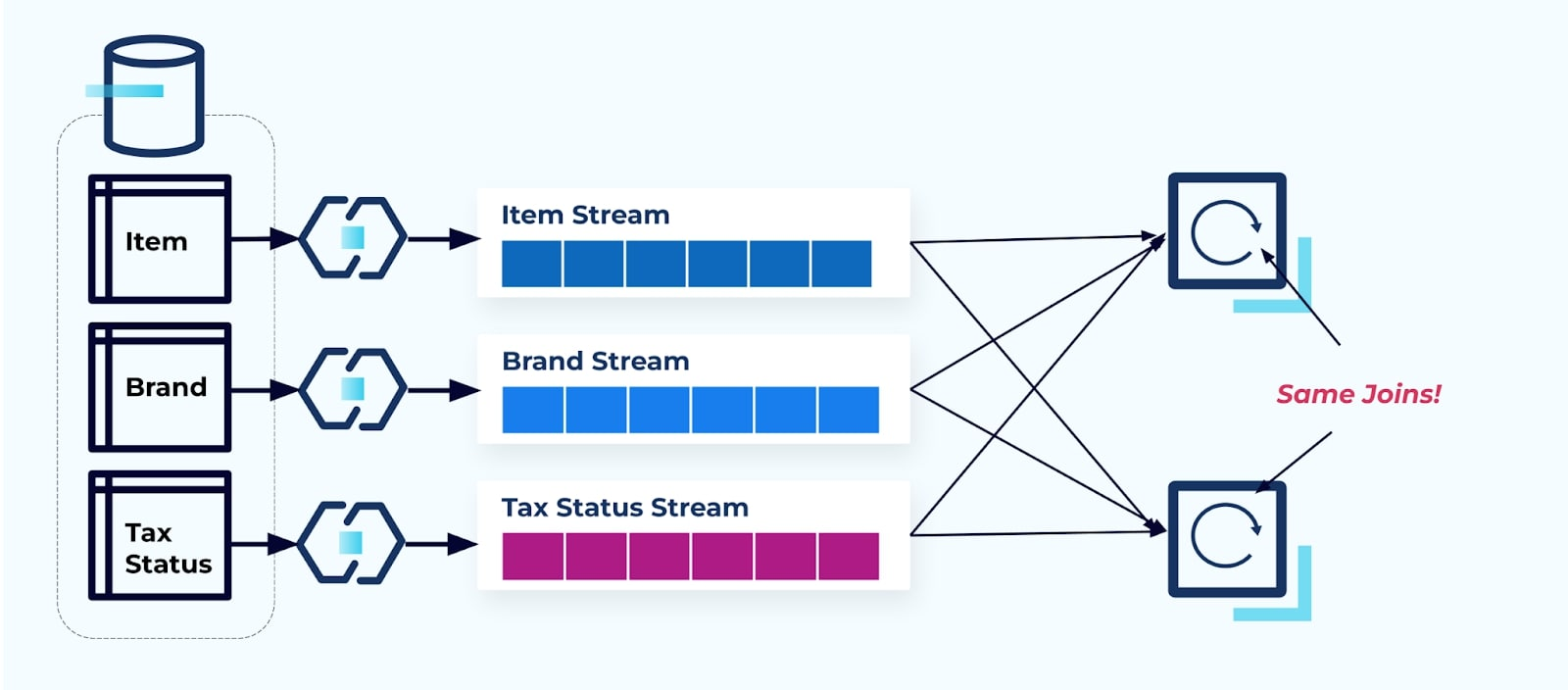
Diese Strategie kann hohe Kosten verursachen, sowohl in Entwicklungsstunden für das Schreiben der Anwendungen als auch in Serverkosten für die Berechnung der Joins. Das Auflösen von Streaming-Joins im großen Maßstab kann zu viel Datenumlagerung führen, was Verarbeitungskraft, Netzwerk- und Speicherkosten verursacht. Außerdem unterstützen nicht alle Stream-Verarbeitungsframeworks Joins, insbesondere nicht auf Fremdschlüsseln. Von denen, die dies tun, wie Flink, Spark, KSQL oder Kafka Streams (zum Beispiel), sind Sie auf eine Untermenge von Programmiersprachen beschränkt (Java, Scala, Python).
Lösung: Denormalisierte Daten bereitstellen ist am besten
Als Prinzip sollten Sie Event-Streams benutzerfreundlich für Ihre Verbraucher gestalten. Denormalisieren Sie die Daten, bevor Sie sie den Verbrauchern über eine Abstraktionsschicht zur Verfügung stellen, und erstellen Sie ein explizites externes Modell Datenvertrag (Daten nach außen) für die Verbraucher, um sich daran zu koppeln.
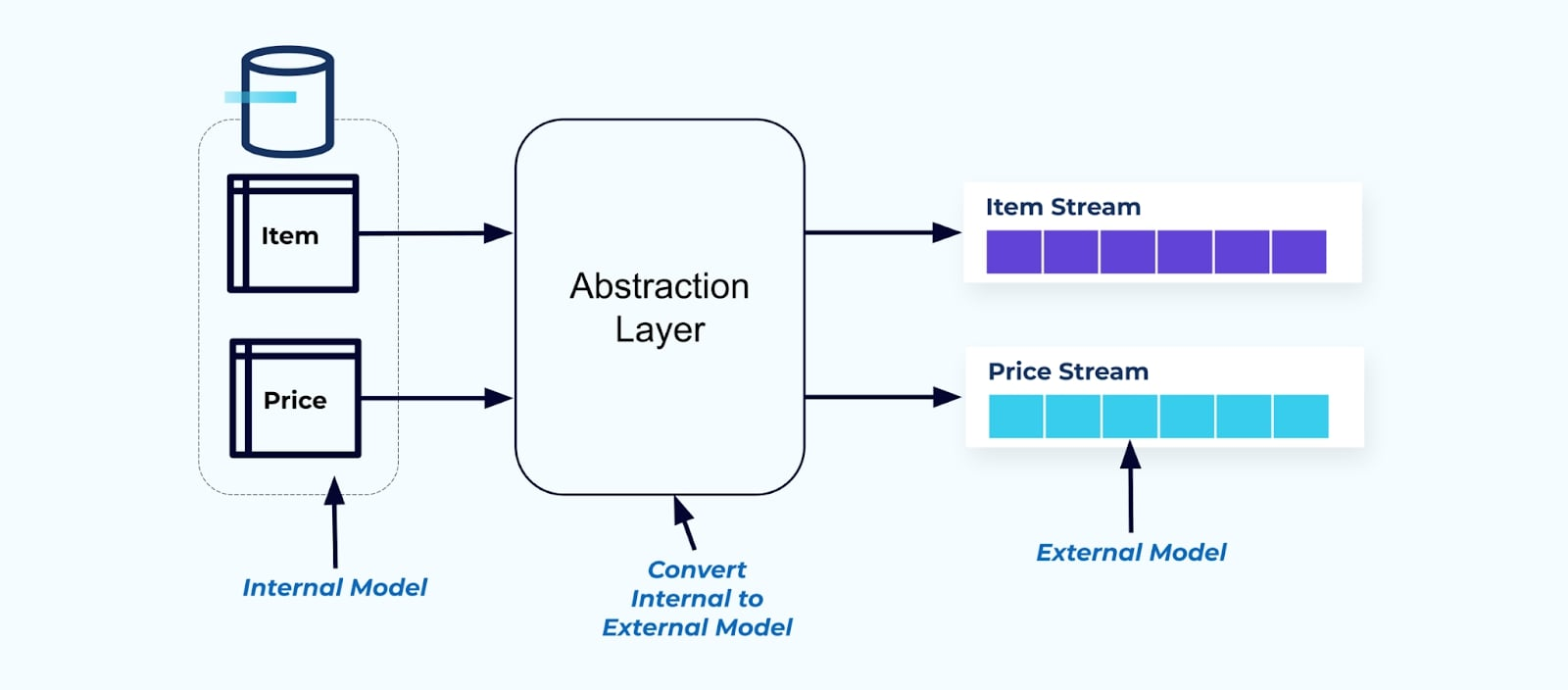
Änderungen am internen Modell bleiben in den Quellsystemen isoliert. Verbraucher erhalten einen gut definierten Datenvertrag, um sich daran zu koppeln. Änderungen am Quellmodell können ungehindert fortgesetzt werden, solange das Quellsystem den Datenvertrag für die Verbraucher aufrechterhält.
Aber wo denormalisieren wir? Zwei Optionen:
- Rekonstruktion außerhalb des Quellsystems über einen speziell entwickelten Joiner-Dienst.
- Während der Ereigniserstellung im Quellsystem unter Verwendung des Transactional Outbox-Musters.
Werfen wir einen Blick auf jede Lösung einzeln.
Option 1: Denormalisierung mit einem speziell entwickelten Joiner-Dienst
In diesem Beispiel spiegeln die Streams auf der linken Seite die Tabellen wider, aus denen sie in der Datenbank stammen.
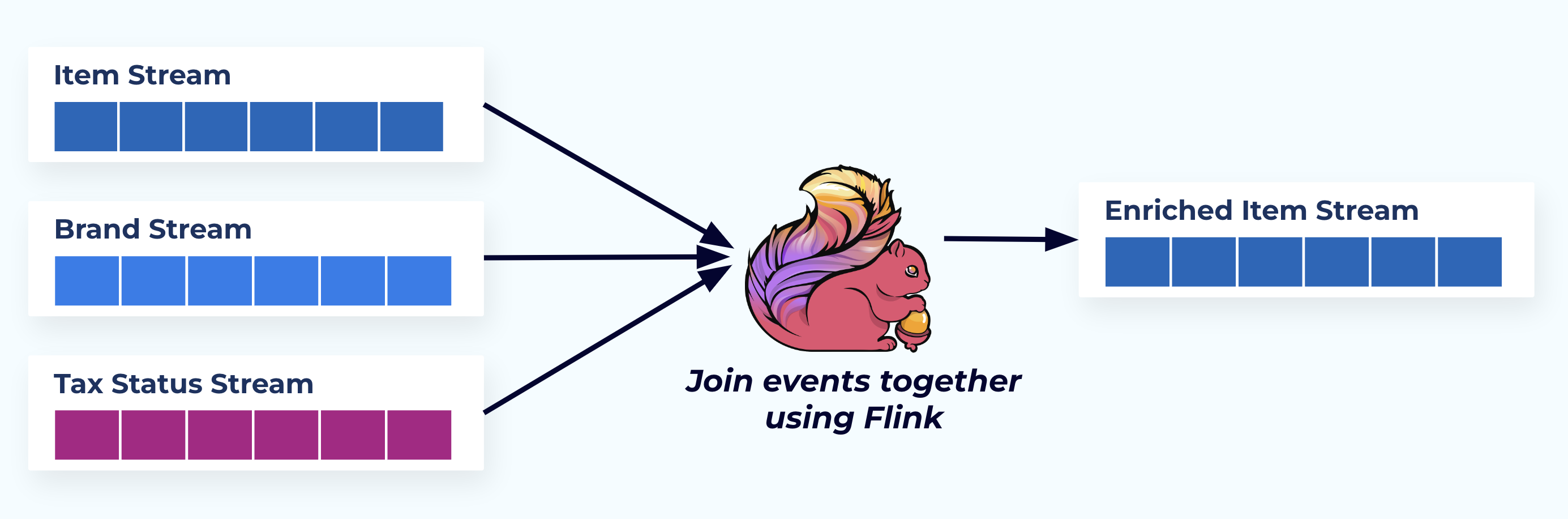
Wir verknüpfen die Ereignisse mit einer speziell entwickelten Anwendung (oder einer Streaming-SQL-Abfrage), die auf den Fremdschlüsselbeziehungen basiert, und geben einen einzigen angereicherten Elementstrom aus.

Logisch gesehen lösen wir die Beziehungen auf und reduzieren die Daten auf eine einzelne denormalisierte Zeile.
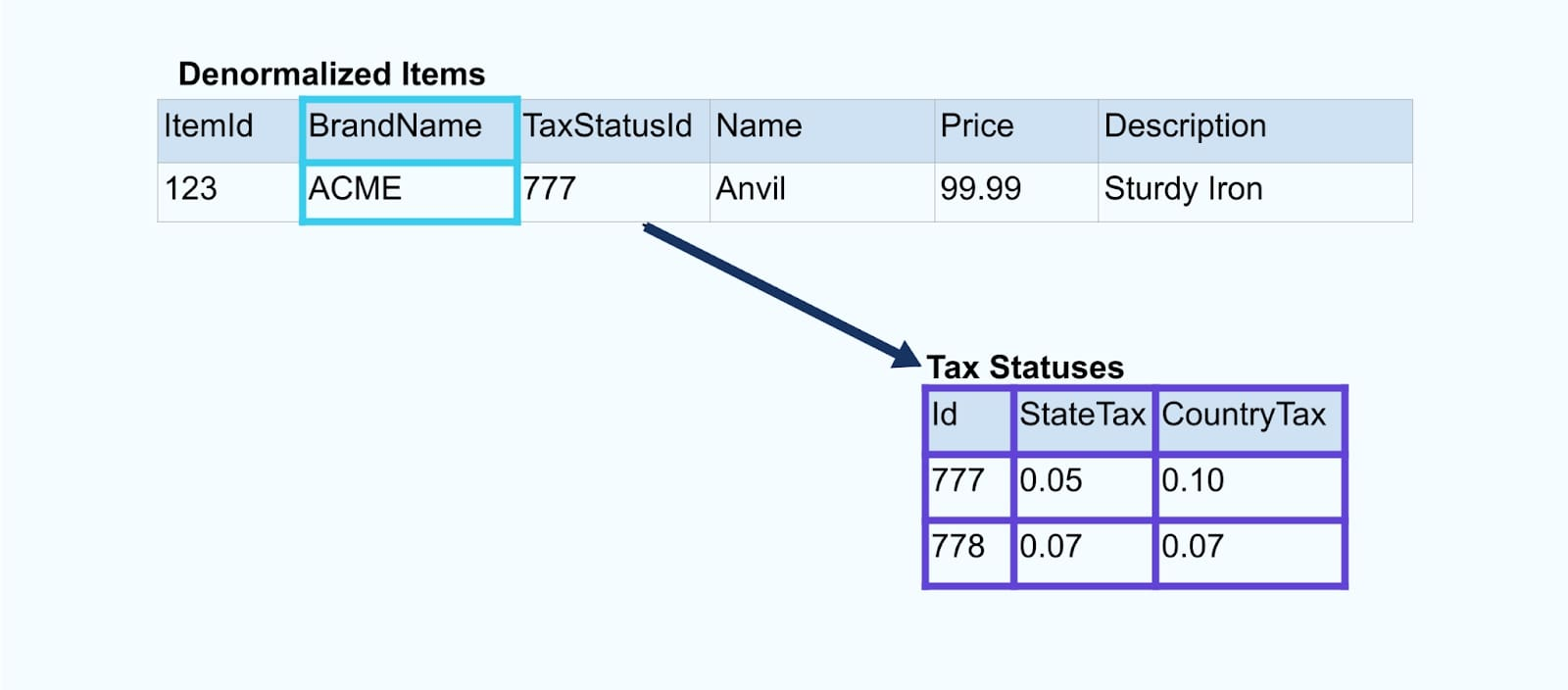
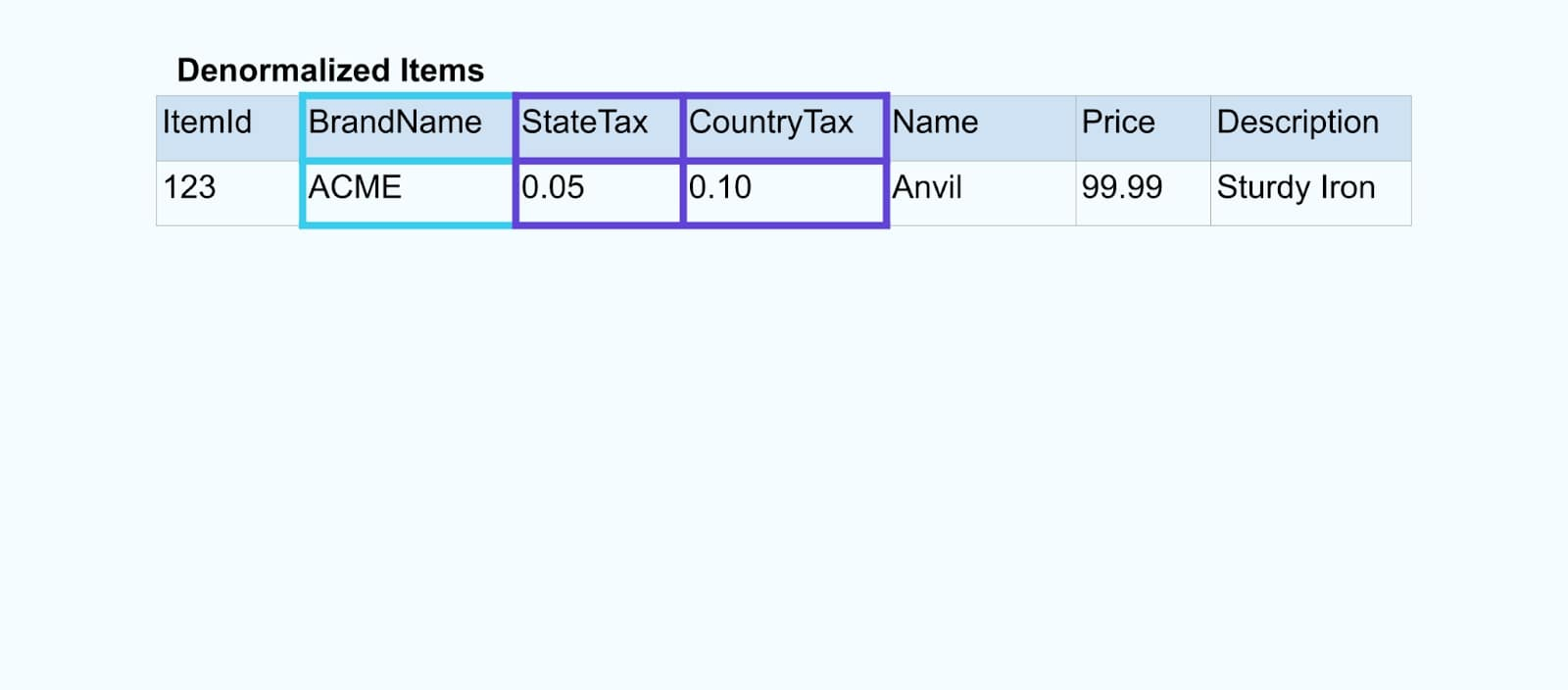
Speziell entwickelte Joiner verlassen sich auf Stream-Verarbeitungsframeworks wie Apache Kafka Streams und Apache Flink, um sowohl Primärschlüssel- als auch Fremdschlüssel-Joins zu lösen. Sie materialisieren die Stream-Daten in dauerhafte interne Tabellenformate, was es der Joiner-Anwendung ermöglicht, Ereignisse über beliebige Zeiträume zu verknüpfen – nicht nur solche, die durch ein zeitlich begrenztes Fenster eingeschränkt sind.
Joiner, die Flink oder Kafka Streams verwenden, sind auch bemerkenswert skalierbar — sie können mit der Last skalieren und massive Datenmengen bewältigen.
Ein Tipp: Fügen Sie keine Geschäftslogik in den Joiner ein. Um in diesem Muster erfolgreich zu sein, muss die verknüpften Daten die Quelle genau als denormalisiertes Ergebnis darstellen. Lassen Sie die downstream-Konsumenten ihre eigene Geschäftslogik anwenden, indem sie die denormalisierten Daten als einzige Quelle der Wahrheit verwenden.
Wenn Sie keinen downstream-Joiner verwenden möchten, gibt es andere Optionen. Lassen Sie uns im nächsten Schritt das Transaktions-Outbox-Muster betrachten.
Option 2: Transaktions-Outbox-Muster
Zuerst erstellen Sie eine dedizierte Outbox-Tabelle zum Schreiben von Ereignissen in den Stream.
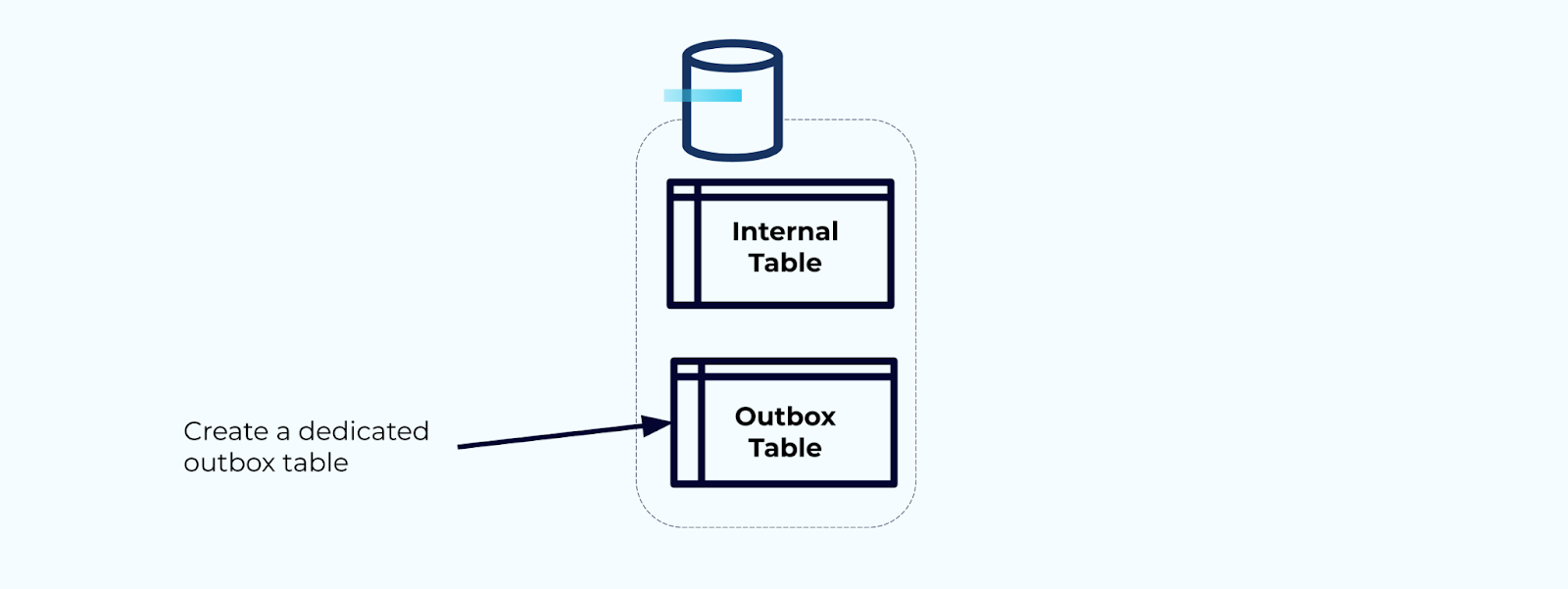
Zweitens, schließen Sie alle notwendigen internen Tabellenaktualisierungen in eine Transaktion ein. Transaktionen garantieren, dass alle Aktualisierungen, die an der internen Tabelle vorgenommen werden, auch in die Outbox-Tabelle geschrieben werden.
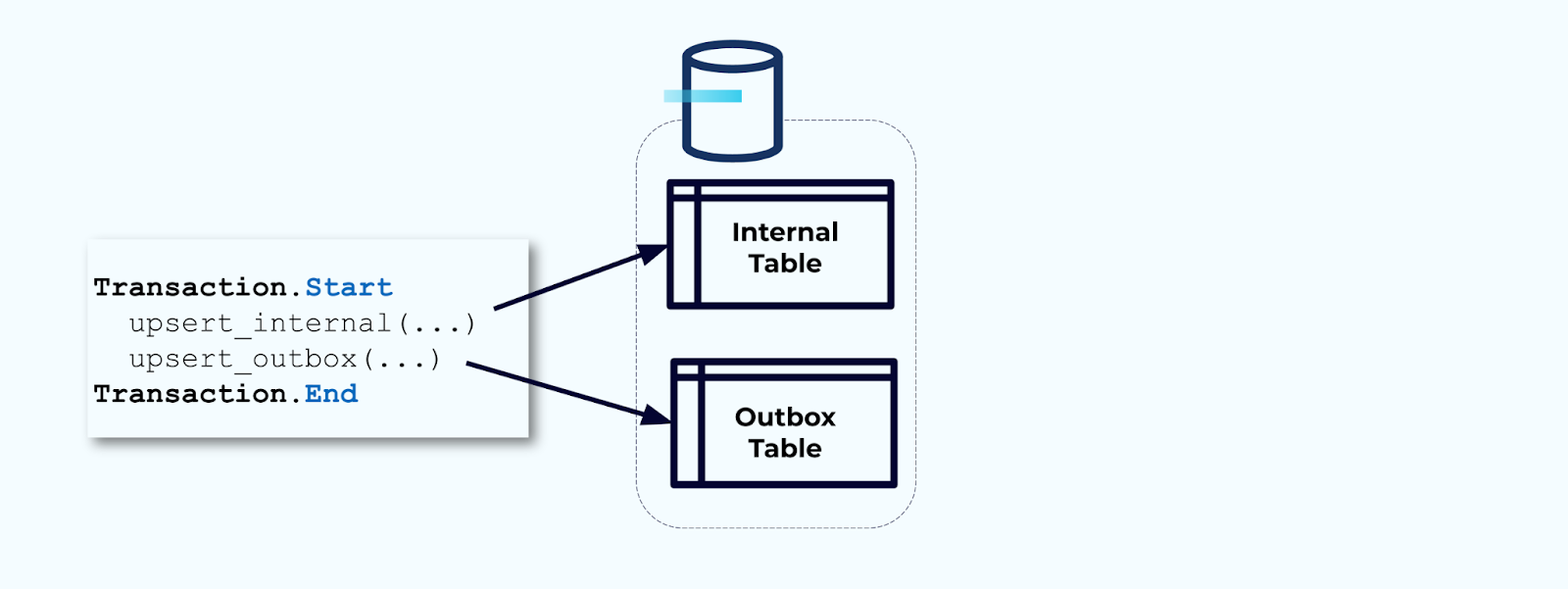
Die Outbox ermöglicht es Ihnen, das interne Datenmodell zu isolieren, da Sie die Daten vor dem Schreiben in Ihre Outbox verknüpfen und transformieren können. Die Outbox fungiert als Abstraktionsschicht zwischen Ihren Daten innen und den Daten außen und dient als Datenvertrag für Ihre Verbraucher.
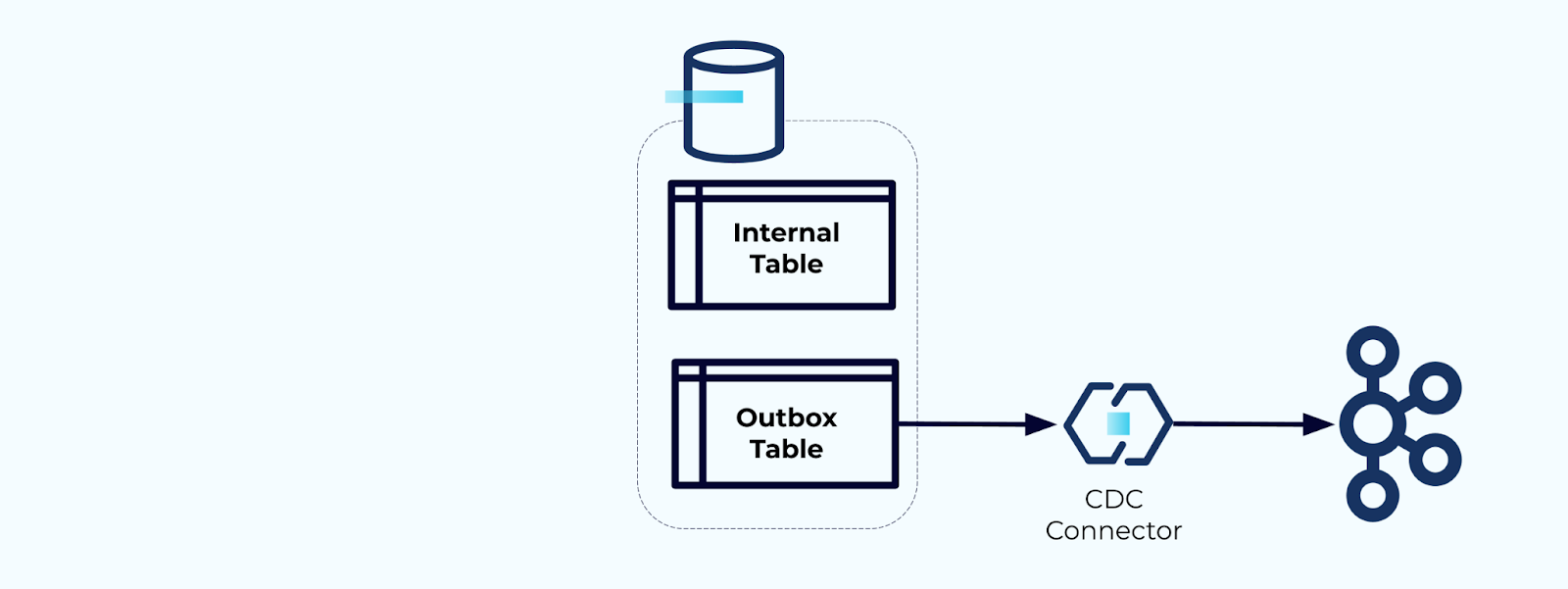
Schließlich können Sie einen Connector verwenden, um die Daten aus der Outbox in Kafka zu übertragen.
Sie müssen sicherstellen, dass die Outbox nicht unendlich wächst – entweder löschen Sie die Daten nach deren Erfassung durch die CDC oder regelmäßig mit einem geplanten Job.
Beispiel: Denormalisieren von Benutzerverhaltens-Tracking-Ereignissen
Das Tracking des Benutzerverhaltens auf Ihren Webseiten und Anwendungen ist eine häufige Quelle für normalisierte Ereignisse – denken Sie an Google Analytics oder ersteigige In-House-Optionen. Aber wir fügen nicht alle Informationen in das Ereignis ein; stattdessen beschränken wir es auf Identifier (schneller, kleiner, günstiger) und denormalisieren nach der Erstellung der Fakten.
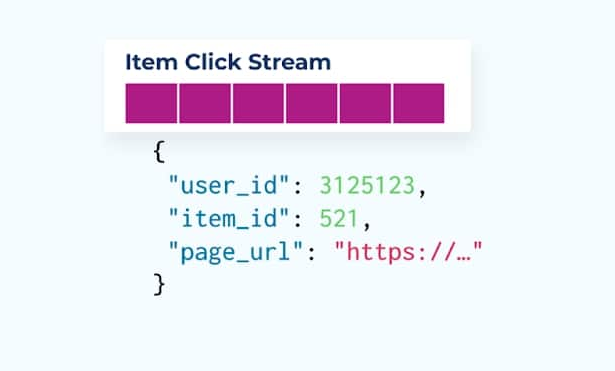
Betrachten Sie einen Strom von Artikel-Klick-Ereignissen, die darlegen, wann ein Benutzer auf einen Artikel beim Durchsuchen von E-Commerce-Artikeln geklickt hat. Beachten Sie, dass dieses Artikel-Klick-Ereignis keine reichhaltigeren Artikelinformationen wie Name, Preis und Beschreibung enthält, sondern nur grundlegende ids.
Das Erste, was viele Click-Stream-Nutzer tun, ist, es mit dem Artikel-Faktenstrom zu verbinden. Und da Sie es mit vielen Klickereignissen zu tun haben, stellen Sie fest, dass es eine große Menge an Rechenressourcen in Anspruch nimmt. Eine speziell entwickelte Flink-Anwendung kann die Artikelklicks mit den detaillierten Artikeldaten verbinden und diese in einen angereicherten Artikelklickstrom ausgeben.
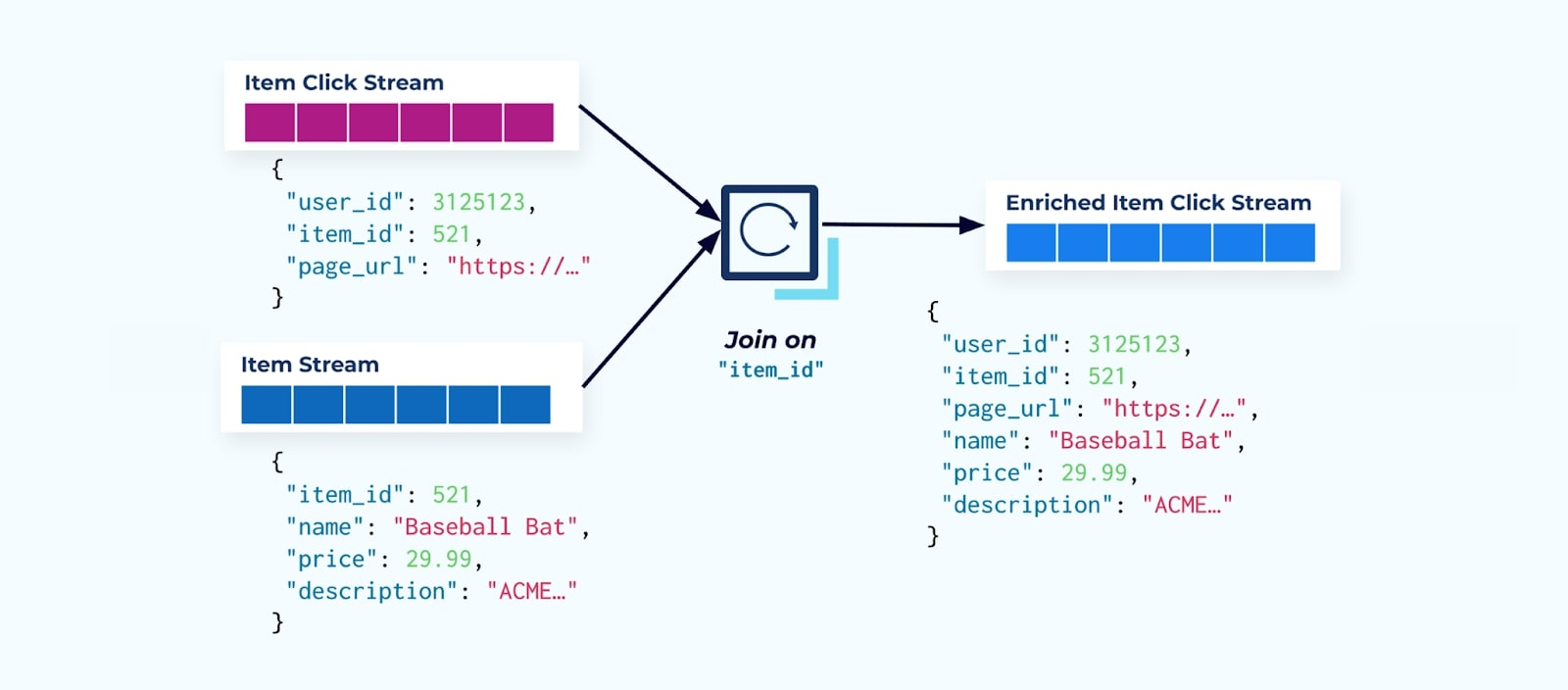
Größere Unternehmen mit mehreren Abteilungen (und Systemen) werden wahrscheinlich sehen, dass ihre Daten aus verschiedenen Quellen stammen, und die Verbindung im Nachhinein mit einem Stream-Joiner ist das wahrscheinlichste Ergebnis.
Überlegungen zu langsam sich ändernden Dimensionen
Wir haben bereits die Leistungsüberlegungen beim Schreiben von Ereignissen mit großen Datensätzen (z. B. große Textblobs) und Datenbereichen, die sich häufig ändern (z. B. Artikelinventar), besprochen. Nun werden wir uns langsam ändernden Dimensionen (SCDs) zuwenden, die häufig über eine Fremdschlüsselbeziehung angezeigt werden, da diese eine weitere Quelle für erhebliche Datenmengen sein können.
Lassen Sie uns wieder zu unserem Artikelbeispiel zurückkehren. Angenommen, Sie haben einen Vorgang, der die Artikel-Tabelle aktualisiert. Wir werden den Artikel von Amboss in Eisenamboss umbenennen.
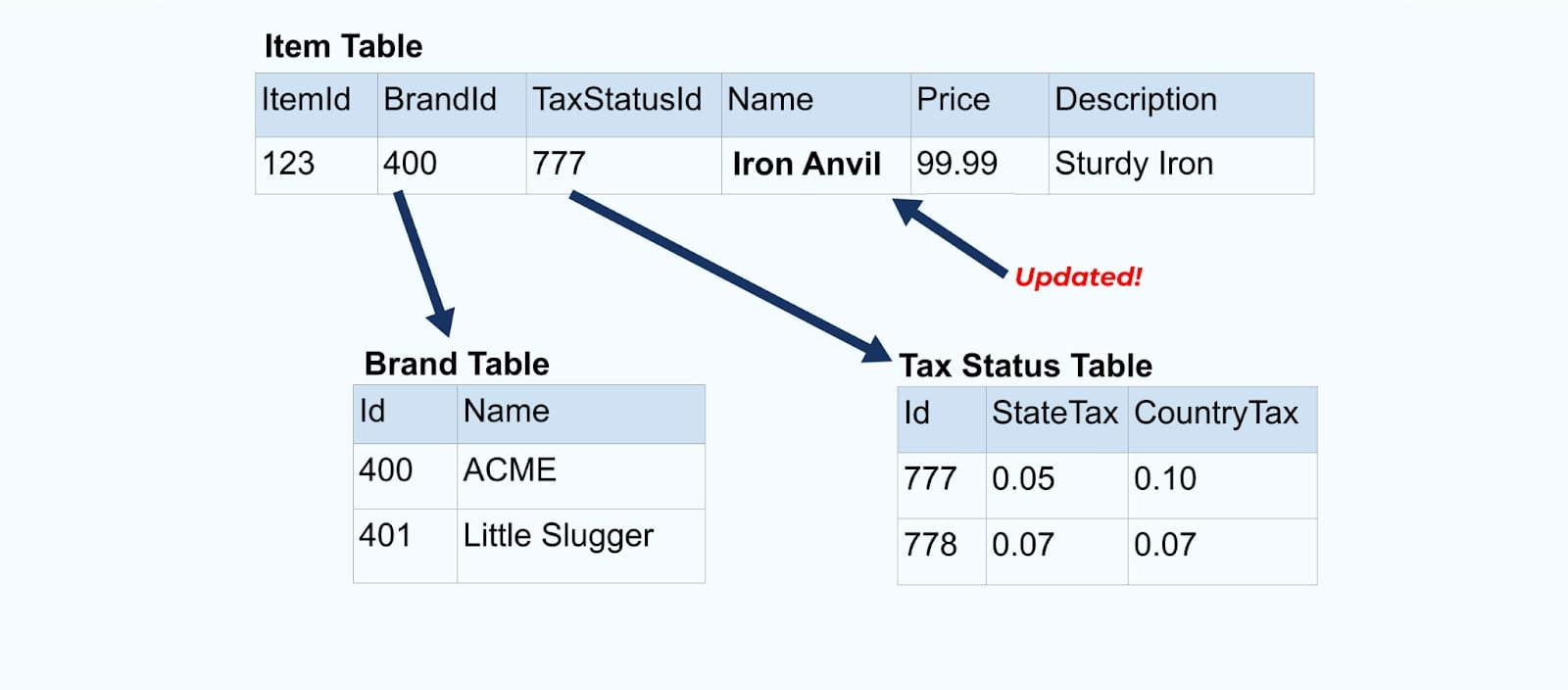
Bei der Aktualisierung der Daten in der Datenbank geben wir auch den aktualisierten Artikel (sagen wir über das Outbox-Muster) aus, einschließlich des denormalisierten Steuerstatus und der Markentabelle.
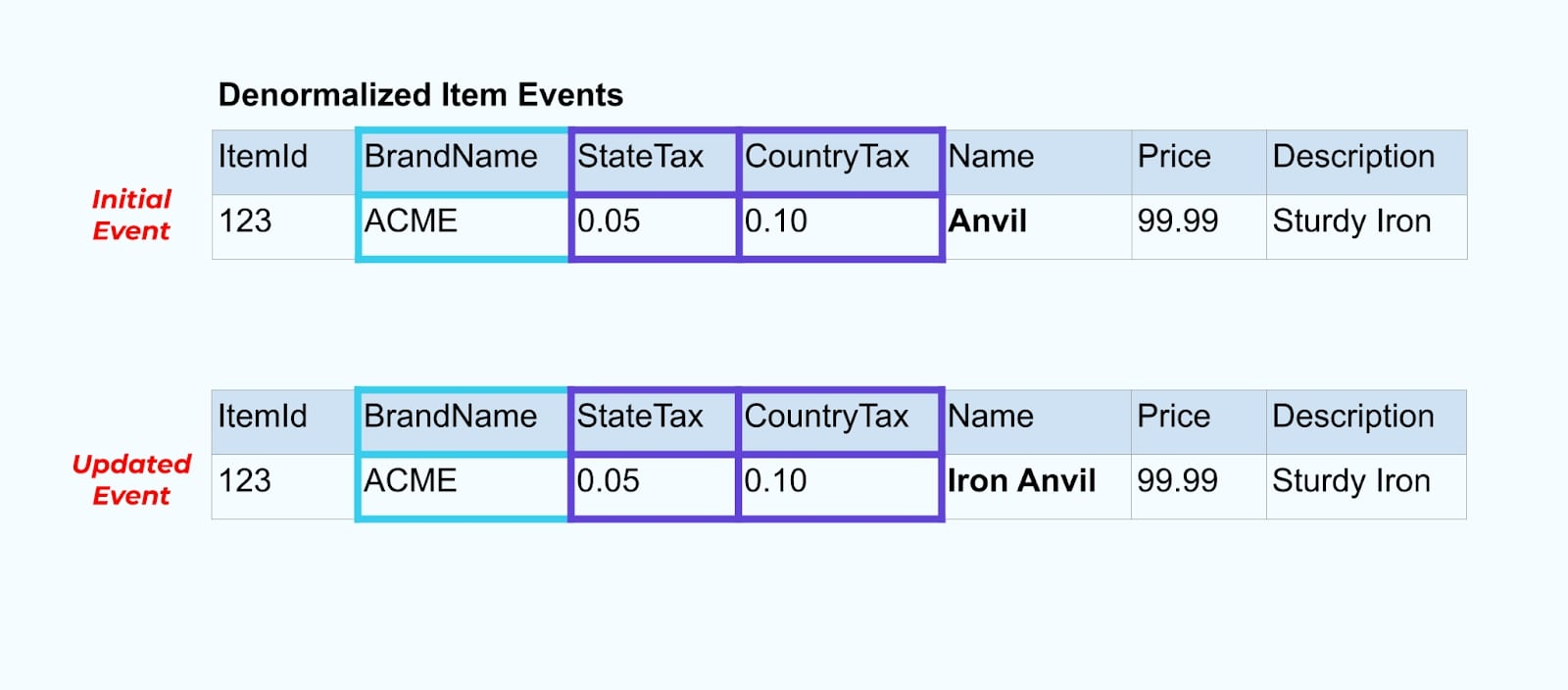
Wir müssen jedoch auch berücksichtigen, was passiert, wenn wir Werte in den Marken- oder Steuertabellen ändern. Die Aktualisierung einer dieser langsam sich ändernden Dimensionen kann zu einer erheblich großen Anzahl von Aktualisierungen für alle betroffenen Artikel führen.
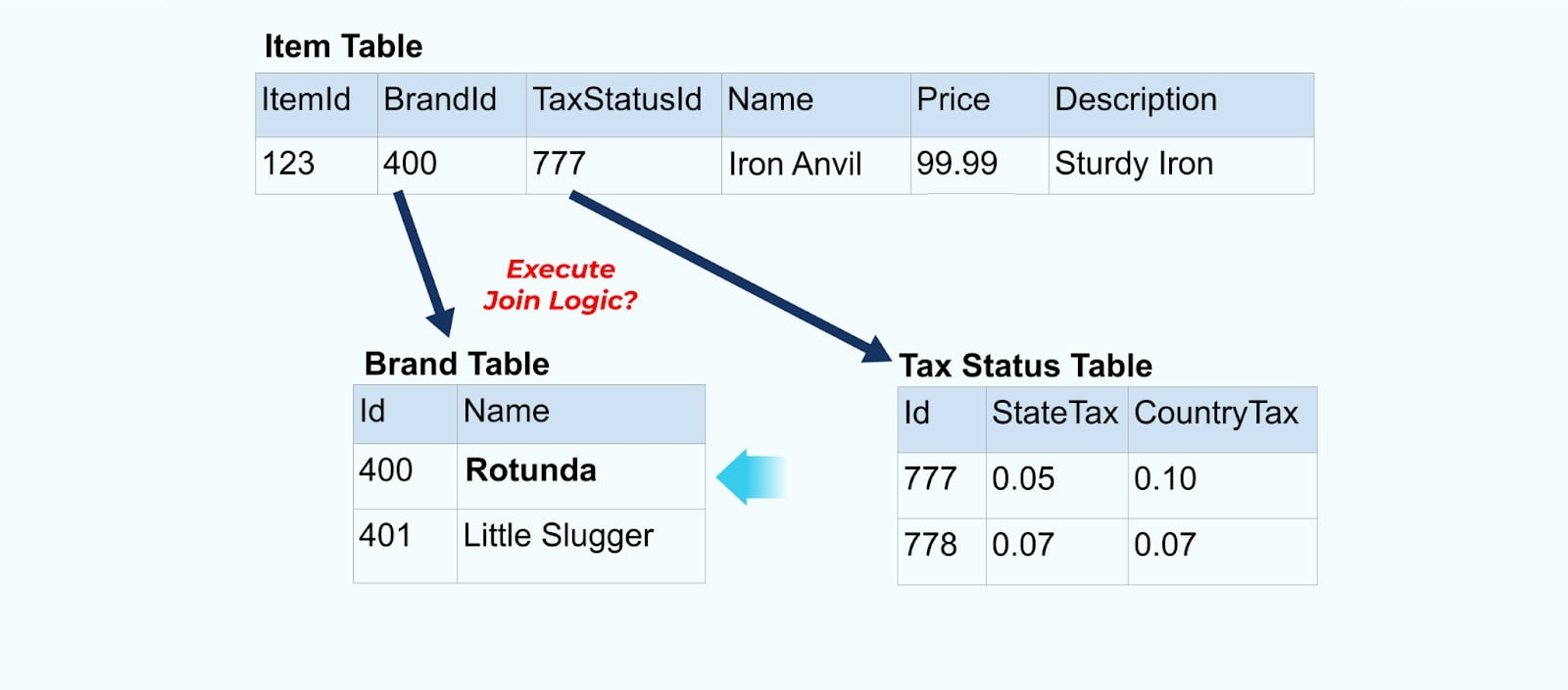
Zum Beispiel unterzieht sich das Unternehmen ACME einer Neupositionierung und kommt auf einen neuen Markennamen, wechselt von ACME zu Rotunda. Wir produzieren ein weiteres Ereignis für ItemId=123.
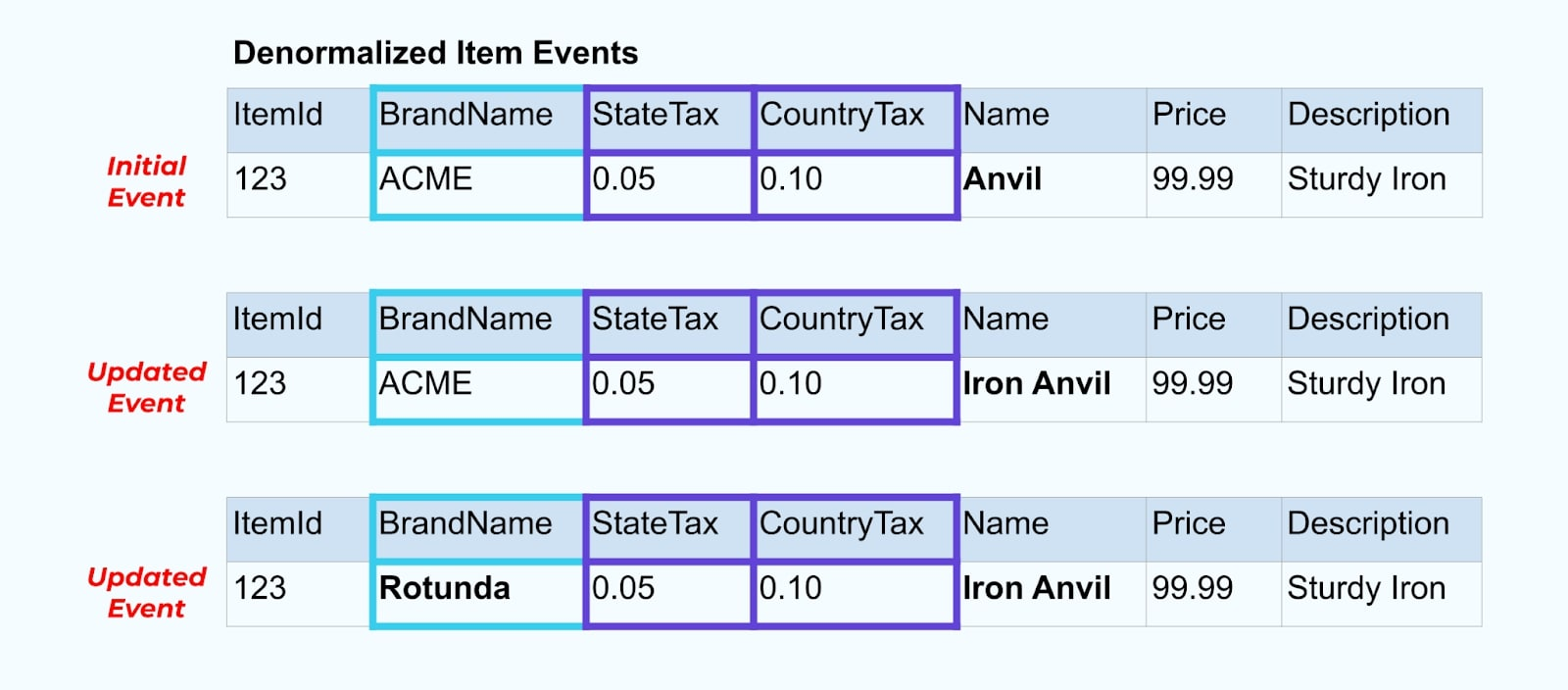
Rotunda (ehemals ACME) hat jedoch wahrscheinlich viele hundert (oder tausend) Artikel, die durch diese Änderung ebenfalls aktualisiert werden, was zu einer entsprechenden Anzahl von aktualisierten angereicherten Ereignissen führt.
Beim Denormalisieren von SCDs und Fremdschlüsselbeziehungen sollten Sie berücksichtigen, welche Auswirkungen eine Änderung des SCD auf den Ereignisstrom insgesamt haben könnte. Sie können sich dafür entscheiden, auf die Denormalisierung zu verzichten und es dem Verbraucher zu überlassen, falls eine Änderung des SCD zu Millionen oder Milliarden von aktualisierten Ereignissen führt.
Zusammenfassung
Die Denormalisierung erleichtert es Verbrauchern, Daten zu nutzen, geht jedoch auf Kosten einer aufwendigeren Vorverarbeitung und einer sorgfältigen Auswahl der zu inkludierenden Daten. Verbraucher können mit einem breiteren Spektrum von Technologien arbeiten, einschließlich solcher, die Streaming-Joins nicht nativ unterstützen.
Die Normalisierung von Daten stromaufwärts funktioniert gut, wenn die Daten klein sind und selten aktualisiert werden. Größere Ereignisgrößen, häufige Aktualisierungen und SCDs sind alles Faktoren, die beachtet werden sollten, wenn festgelegt wird, was stromaufwärts denormalisiert werden soll und was den Verbrauchern überlassen werden soll.
Letztendlich ist die Auswahl der Daten, die in ein Ereignis aufgenommen werden sollen, und was ausgelassen werden soll, ein Balanceakt zwischen den Bedürfnissen der Verbraucher, den Fähigkeiten des Produzenten und den einzigartigen Datenmodellbeziehungen. Der beste Ausgangspunkt besteht darin, die Bedürfnisse Ihrer Verbraucher zu verstehen und die Isolierung des internen Datenmodells Ihres Quellsystems zu berücksichtigen.
Source:
https://dzone.com/articles/how-to-design-event-streams-part-2