













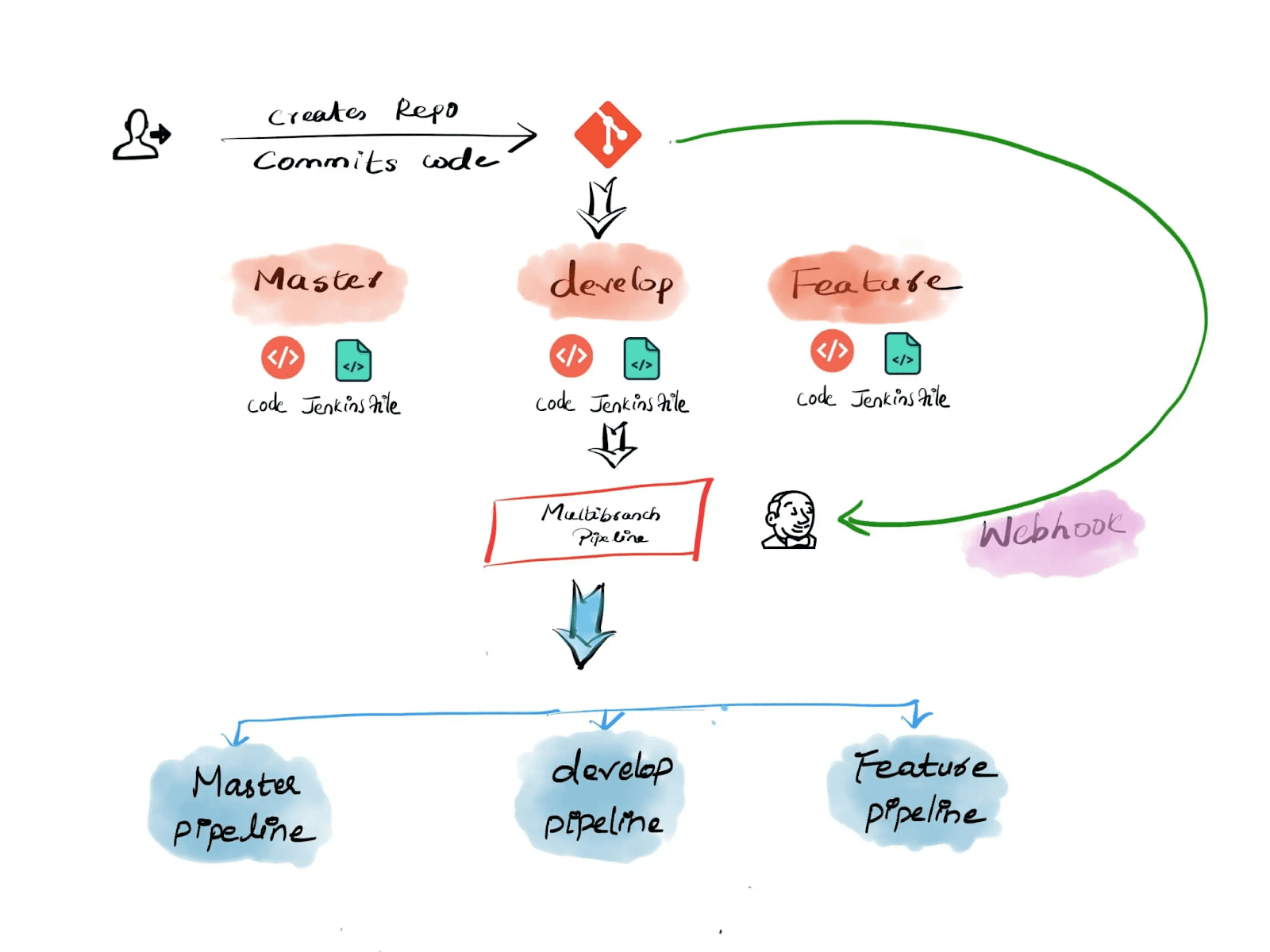
Es gab Zeiten, in denen wir Jenkins-Jobs ausschließlich über die Benutzeroberfläche erstellten. Später wurde die Idee einer Pipeline als Code vorgeschlagen, um die zunehmende Komplexität bei Build- und Deployments zu bewältigen. In Jenkins 2.0 führte das Jenkins-Team die Jenkinsfile ein, um eine Pipeline als Code zu realisieren. Wenn Sie eine automatisierte Pull-Request-basierte oder Branch-basierte Jenkins Continuous Integration and Continuous Delivery Pipeline erstellen möchten, ist die Jenkins Multibranch Pipeline der Weg, der Weg.
Da die Jenkins Multibranch Pipeline vollständig eine git-basierte Pipeline als Code ist, können Sie Ihre CI/CD-Workflows aufbauen. Pipeline als Code (PaaC) erleichtert es, die Vorteile der Automatisierung und der Cloud-Portabilität für Ihr Selenium zu nutzen. Sie können das Multibranch-Pipeline-Modell verwenden, um schnell und zuverlässig Ihre Selenium-Tests zu erstellen, testen, bereitstellen, überwachen, berichten und verwalten, und vieles mehr. In diesem Jenkins-Tutorial werfen wir einen Blick darauf, wie man eine Jenkins Multibranch Pipeline erstellt und die wichtigsten Konzepte bei der Konfiguration einer Jenkins Multibranch Pipeline für die Selenium-Automatisierungstests.
Fangen wir an.
Was ist eine Jenkins Multibranch Pipeline?
Laut der offiziellen Dokumentation ermöglicht eine Multibranch Pipeline-Job-Art, dass Sie einen Job definieren, bei dem aus einem einzigen git-Repository Jenkins mehrere Zweige erkennt und geschachtelte Jobs erstellt, wenn es eine Jenkinsfile findet.
Aus der obigen Definition können wir verstehen, dass Jenkins Git-Repositories nach Jenkinsfiles durchsuchen und automatisch Jobs erstellen kann. Alles, was es von uns benötigt, sind die Details des Git-Repositories. In diesem Artikel verwenden wir ein Beispiel-GitHub-Repository. Unser Beispiel-GitHub-Repo enthält ein Beispiel-Spring-Boot-Projekt, das auf Tomcat bereitgestellt werden kann.
Im Stammverzeichnis des Projekts befindet sich die Jenkinsfile. Wir haben die Jenkins Declarative Pipeline-Syntax verwendet, um diese Jenkinsfile zu erstellen. Wenn Sie neu in Jenkins Declarative Pipeline sind, lesen Sie bitte unser ausführliches Artikel hier.
Beispiel-Jenkinsfile
pipeline {
agent any
stages {
stage('Build Code') {
steps {
sh """
echo "Building Artifact"
"""
}
}
stage('Deploy Code') {
steps {
sh """
echo "Deploying Code"
"""
}
}
}
}Wir haben in unserer Jenkinsfile zwei Stages „Build Code“ und „Deploy Code“ erstellt, die jeweils so konfiguriert sind, dass sie entsprechende Nachrichten drucken. Nun haben wir das Git-Repo mit der Jenkinsfile bereit.
Lassen Sie uns eine Jenkins Multibranch Pipeline auf dem Jenkins-Server erstellen.
Jenkins Pipeline vs. Multibranch Pipeline
Die Jenkins Pipeline ist die neue Trendwende, aber sie ist nicht für jeden geeignet. Und Multibranch Pipelines sind immer noch großartig. In diesem Abschnitt des Tutorials zur Jenkins Multibranch Pipeline verstehen wir die idealen Anwendungsfälle für Jenkins Pipeline und Multibranch Pipeline durch diese Vergleichsstudie von Jenkins Pipeline vs. Multibranch Pipeline.
Die Jenkins-Pipeline ist ein Konfigurationssystem für Jobs, das es Ihnen ermöglicht, eine Pipeline von Jobs zu konfigurieren, die automatisch auf Ihre Anweisung ausgeführt werden. Eine Jenkins-Pipeline kann mehrere Stufen haben, und jede Stufe wird von einem einzelnen Agenten ausgeführt, der auf einer einzelnen Maschine oder mehreren Maschinen läuft. Eine Pipeline wird normalerweise für einen bestimmten Branch des Quellcodes erstellt. Wenn Sie einen neuen Job erstellen, haben Sie die Möglichkeit, das Quellcode-Repository und den Branch auszuwählen. Sie können auch eine frische Pipeline für ein neues Projekt oder eine neue Funktion eines bestehenden Projekts erstellen.
Die Jenkins-Pipeline ermöglicht Ihnen eine flexible Jenkinsfile mit Stufen für Ihren Build. So können Sie eine erste Stufe haben, in der Sie Linting, Tests usw. ausführen, und dann separate Stufen für das Erstellen von Artefakten oder das Bereitstellen. Dies ist sehr nützlich, wenn Sie in Ihrer Pipeline mehrere Dinge tun möchten.
Was ist, wenn Sie nur eine Sache tun müssen? Oder wenn alle Dinge, die Sie tun möchten, je nach einer Konfiguration unterschiedlich sind? Macht es Sinn, hier eine Jenkins-Pipeline zu verwenden?
Die Multibranch-Pipeline ist ein alternatives Verfahren, das in diesen Fällen möglicherweise besser geeignet ist. Die Multibranch-Pipeline ermöglicht es Ihnen, Aufgaben in Branches aufzuteilen und sie später zusammenzuführen. Dies ähnelt sehr der Art und Weise, wie Git-Branching funktioniert.
A multibranch pipeline is a pipeline that has multiple branches. The main advantage of using a multibranch pipeline is to build and deploy multiple branches from a single repository. Having a multibranch pipeline also allows you to have different environments for different branches. However, it is not recommended to use a multibranch pipeline if you do not have a standard branching and CI/CD strategy.
Nun, da Sie den Vergleich zwischen Jenkins-Pipeline und Multibranch-Pipeline gesehen haben, gehen wir durch die Schritte zur Erstellung einer Jenkins-Multibranch-Pipeline.
Erstellen einer Jenkins-Multibranch-Pipeline
Schritt 1
Öffnen Sie die Jenkins-Startseite (http://localhost:8080 lokal) und klicken Sie im linken Menü auf „Neues Element“.
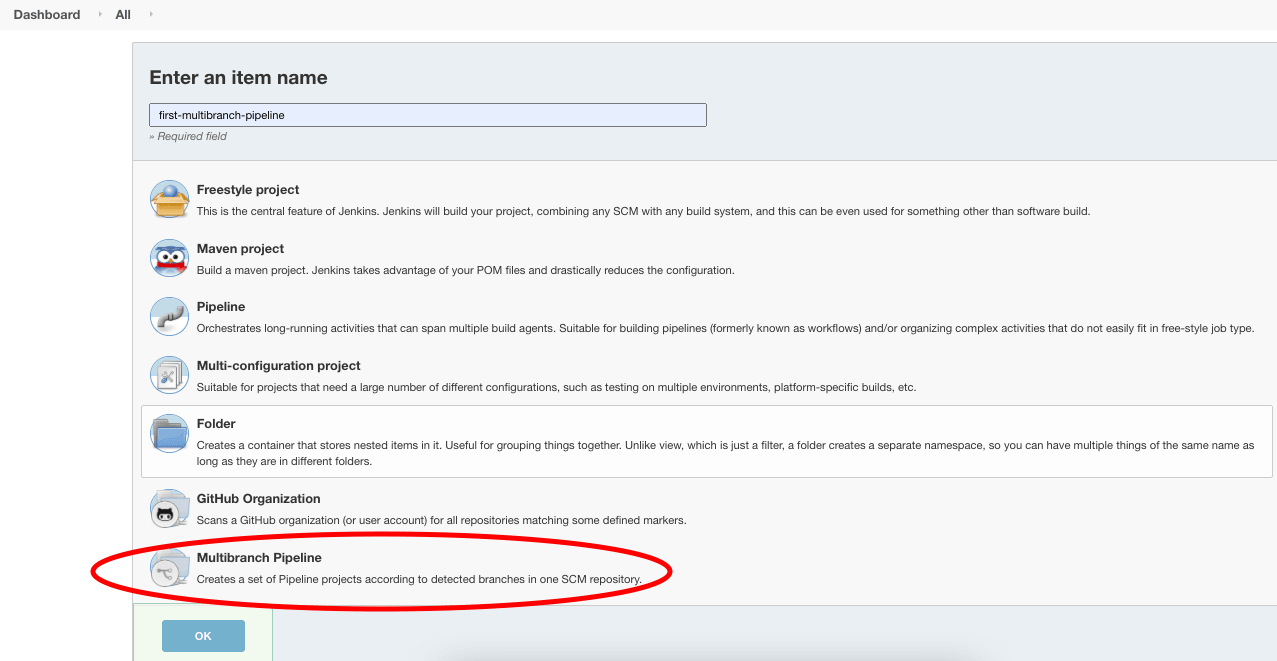
Schritt 2
Geben Sie den Jenkins-Jobnamen ein, wählen Sie den Stil als “Multibranch-Pipeline,” und klicken Sie auf “OK.”
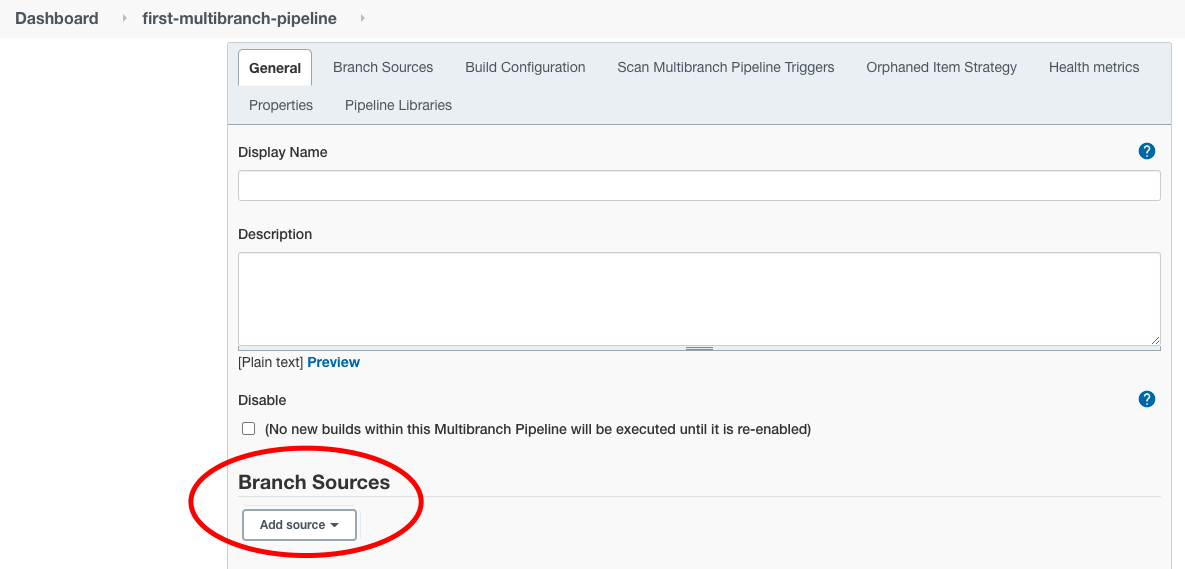
Schritt 3
Auf der “Konfigurieren”-Seite müssen wir nur eine Sache konfigurieren: Die Git-Repo-Quelle.
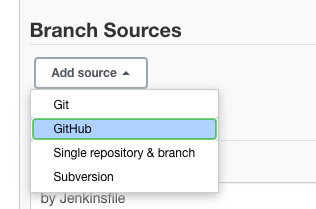
Scrollen Sie zum Abschnitt “Branch-Quellen” und klicken Sie auf das Dropdown-Menü “Quelle hinzufügen”.
Wählen Sie “GitHub” als Quelle, da unser Beispiel-GitHub-Repo dort gehostet wird.
Schritt 4
Geben Sie die Repository-HTTPS-URL als https://github.com/iamvickyav/spring-boot-h2-war-tomcat.git ein und klicken Sie auf “Überprüfen.”
Da unser GitHub-Repo als öffentliches Repo gehostet wird, müssen wir keine Anmeldeinformationen zur Verfügung stellen, um auf es zuzugreifen. Für Unternehmens-/privaten Repos können wir möglicherweise Anmeldeinformationen benötigen, um auf sie zuzugreifen.

Die Meldung “Anmeldeinformationen in Ordnung” zeigt an, dass die Verbindung zwischen dem Jenkins-Server und dem Git-Repo erfolgreich hergestellt wurde.
Schritt 5
Lassen Sie den Rest der Konfigurationsabschnitte vorerst so und klicken Sie auf die Schaltfläche “Speichern” ganz unten.
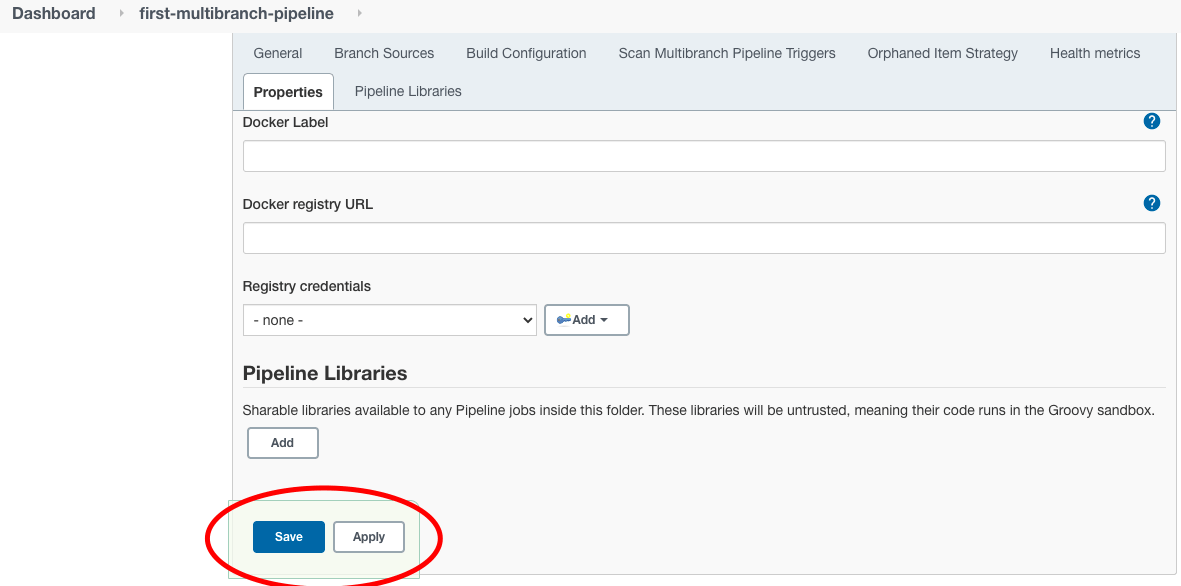
Beim Speichern führt Jenkins die folgenden Schritte automatisch aus:
Repository-Scanschritt
- Scanne das konfigurierte Git-Repo.
- Suchen Sie nach der Liste der im Git-Repo verfügbaren Zweige.
- Wählen Sie die Zweige aus, die ein Jenkinsfile haben.
Ausführung des Build-Schritts
- Führe für jede der in der vorherigen Schritt gefundenen Branches den in der Jenkinsfile genannten Aufbau durch.
Aus dem Abschnitt „Scan Repository Log“ können wir erkennen, was während des Schritts zum Scannen des Repositorys passiert ist.
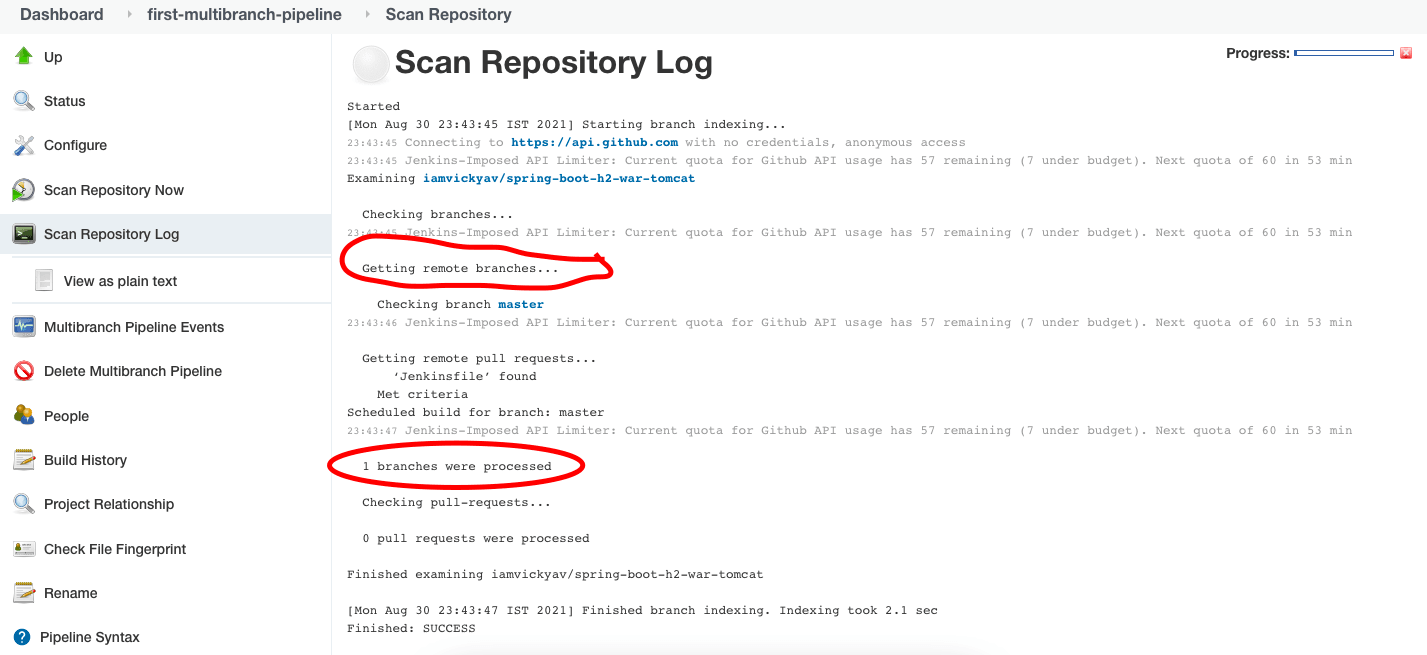
Da wir in unserem Git-Repo nur eine master branch haben, besagt das Scan Repository Log „1 branches were processed.“
Nach Abschluss des Scans wird Jenkins für jede verarbeitete Branch einen Build-Auftrag erstellen und ausführen.
In unserem Fall hatten wir nur eine Branch namens master. Daher wird der Build nur für unsere master Branch ausgeführt. Wir können dies überprüfen, indem wir auf „Status“ im Menü auf der linken Seite klicken.
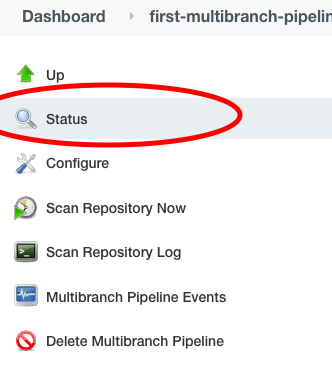
Wir können im Statusabschnitt einen Build-Auftrag für die master Branch sehen.
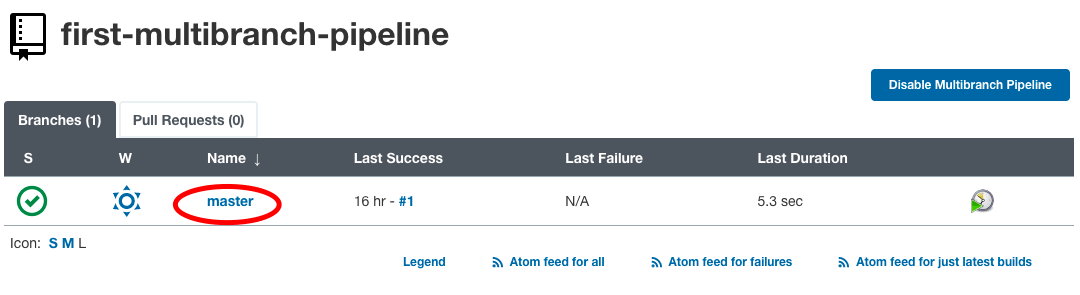
Klicken Sie auf den Branch-Namen, um den Build-Auftrags-Log und den Status zu sehen.
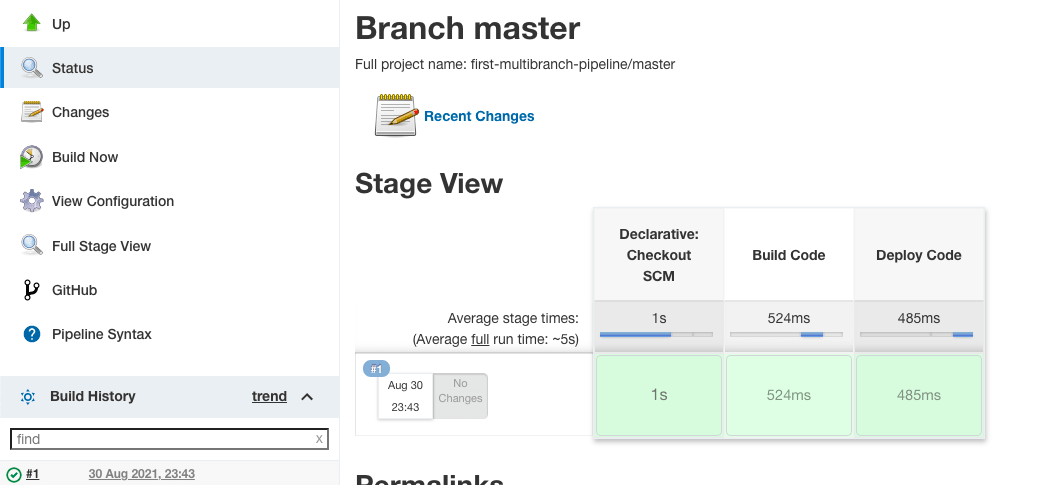
„Stage View“ bietet eine visuelle Darstellung, wie viel Zeit jeder Stage zum Ausführen benötigte und den Status des Build-Auftrags.
Zugriff auf Build-Job-Laufprotokolle
Schritt 1
Klicken Sie auf die „Build-Nummer“ im Abschnitt „Build-Geschichte“.
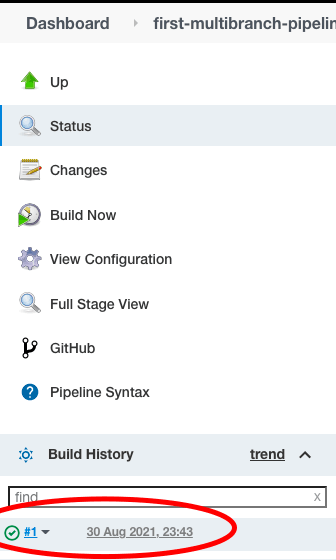
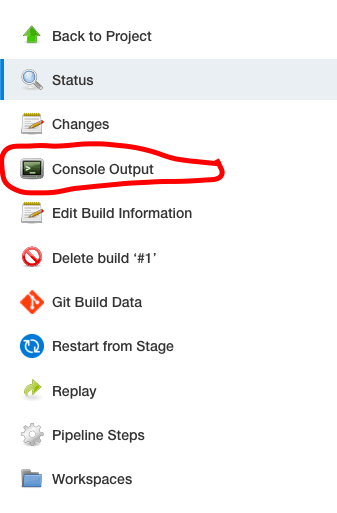
Schritt 2
Wählen Sie als Nächstes „Console Output“ im Menü auf der linken Seite, um die Protokolle zu sehen.
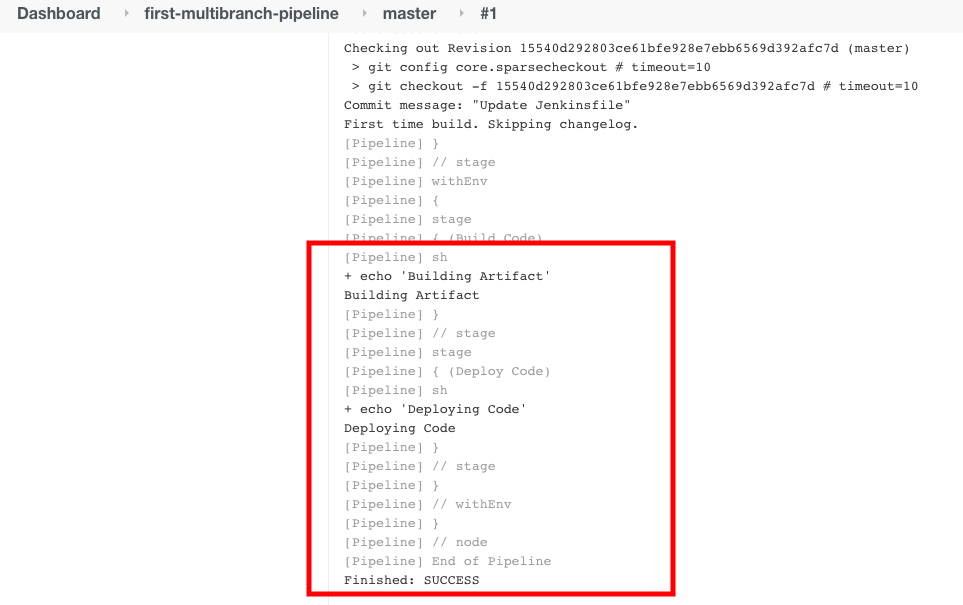
Was passiert, wenn wir in unserem Git-Repo mehr als eine Branch haben? Schauen wir uns das jetzt an.
In dem Git-Repo wird eine neue Branch namens „develop“ erstellt.
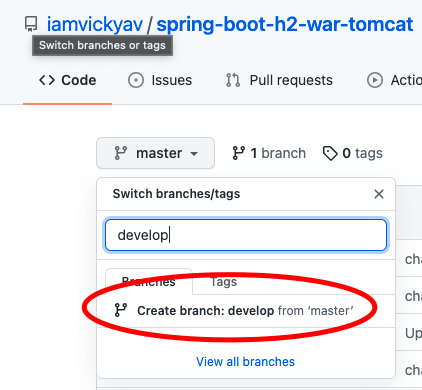
Um den „entwickeln“-Branch-Build zu unterscheiden, haben wir kleine Änderungen in den Echo-Befehlen im Jenkinsfile vorgenommen.
Jenkinsfile im Master-Branch
pipeline {
agent any
stages {
stage('Build Code') {
steps {
sh """
echo "Building Artifact"
"""
}
}
stage('Deploy Code') {
steps {
sh """
echo "Deploying Code"
"""
}
}
}
}Jenkinsfile im Develop-Branch
pipeline {
agent any
stages {
stage('Build Code') {
steps {
sh """
echo "Building Artifact from Develop Branch"
"""
}
}
stage('Deploy Code') {
steps {
sh """
echo "Deploying Code from Develop Branch"
"""
}
}
}
}Jetzt haben wir zwei Jenkinsfiles in zwei verschiedenen Branches. Lassen Sie uns den Repository-Scan in Jenkins erneut ausführen, um das Verhalten zu sehen.
Wir können sehen, dass der neue Branch (Develop-Branch) von Jenkins erkannt wurde. Daher wurde ein neuer Job separat für den Develop-Branch erstellt.
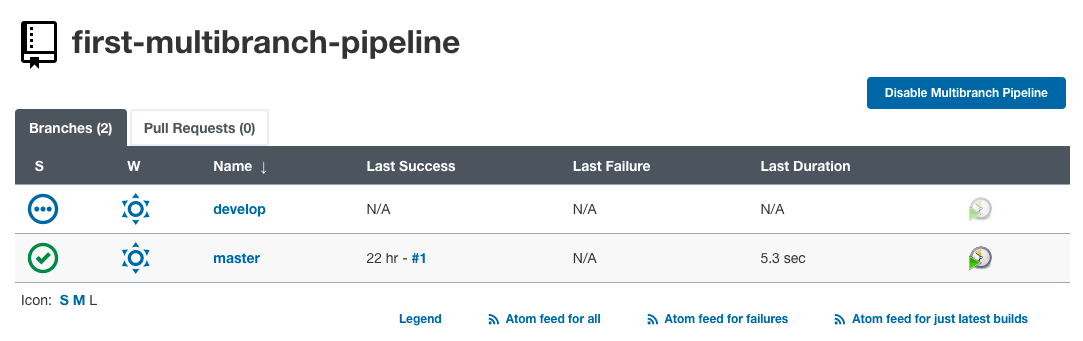
Beim Klicken auf „entwickeln“ können wir die Logdatei für den Build-Job des Develop-Branches sehen.
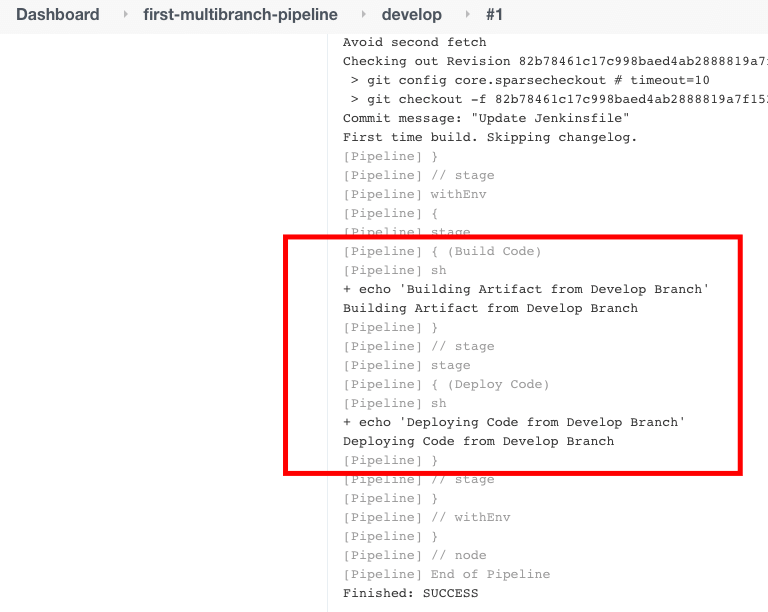
In dem vorherigen Beispiel haben wir unterschiedliche Inhalte für das Jenkinsfile im Master- und Develop-Branch beibehalten. Aber so machen wir es in der Praxis nicht. Wir nutzen die when-Blöcke innerhalb des stage-Blocks, um den Branch zu überprüfen.
Hier ist ein Beispiel mit kombinierten Schritten für den Master- und Develop-Branch. Dieser gleiche Inhalt wird sowohl im Master- als auch im Develop-Branch-Jenkinsfile platziert.
pipeline {
agent any
stages {
stage('Master Branch Deploy Code') {
when {
branch 'master'
}
steps {
sh """
echo "Building Artifact from Master branch"
"""
sh """
echo "Deploying Code from Master branch"
"""
}
}
stage('Develop Branch Deploy Code') {
when {
branch 'develop'
}
steps {
sh """
echo "Building Artifact from Develop branch"
"""
sh """
echo "Deploying Code from Develop branch"
"""
}
}
}
}Schritt 3
Klicken Sie auf „Repository-Scan“ im linken Menü, damit Jenkins die neuen Änderungen aus dem Git-Repo erkennt.
Inzwischen hätten Sie vielleicht bemerkt, dass wir den Repository-Scan jedes Mal verwenden, wenn wir wollen, dass Jenkins Änderungen aus dem Repo erkennt.
Wie wäre es, diesen Schritt zu automatisieren?
Periodischer Trigger für den Jenkins Multibranch Pipeline Scan
Schritt 1
Klicken Sie „Konfigurieren“ im linken Menü.
Schritt 2
Scrollen Sie zum Abschnitt „Scan Repository Triggers“ und aktivieren Sie das Kontrollkästchen „Periodically if not otherwise run“ und wählen Sie das Zeitintervall für die periodische Ausführung des Scans (zwei Minuten in unserem Beispiel).
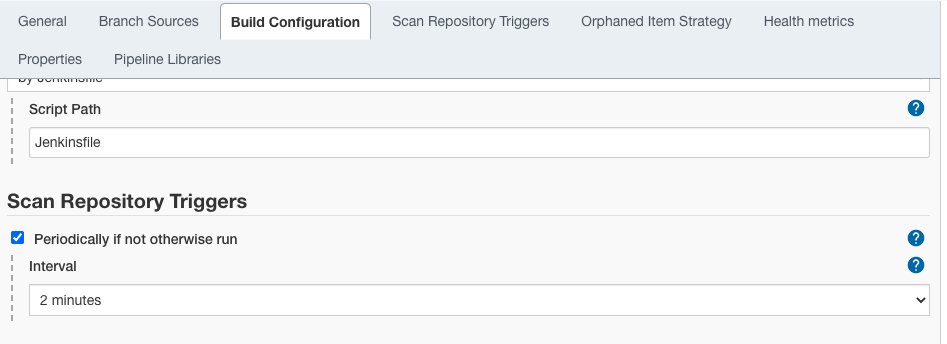
Schritt 3
Klicken Sie auf die Schaltfläche „Speichern“.
Ab sofort wird Jenkins den Repo alle zwei Minuten scannen. Wird in einer beliebigen Branch ein neuer Commit gefunden, wird Jenkins einen neuen Build-Job für diesen speziellen Branch mit Jenkinsfile ausführen.
Unten befindet sich der „Scan Repository Log“, der eindeutig zeigt, dass der Scan alle zwei Minuten ausgelöst wird.

Echtzeit-Anwendungsfälle für Jenkins Multibranch Pipeline
Nachfolgend finden Sie einige Szenarien, in denen die Jenkins Multibranch Pipeline nützlich sein kann:
- Jeder neue Commit in der master Branch muss automatisch auf dem Server bereitgestellt werden.
- Wenn ein Entwickler versucht, einen Pull Request (PR) zur Entwicklungsbranch zu erhöhen, dann:
- Das Code sollte erfolgreich ohne Kompilierungsfehler gebaut werden.
- Der Code sollte mindestens 80% Testabdeckung haben.
- Der Code sollte die SONAR Codequalitätsprüfung bestehen.
- Wenn Entwickler versuchen, Code in eine Branch zu pushen, die nicht master oder develop ist, sollte der Code erfolgreich kompiliert werden. Wenn nicht, eine Warn-E-Mail senden.
Hier ist ein Beispiel für einen Jenkinsfile, der einige der oben genannten Anwendungsfälle abdeckt:
pipeline {
agent any
tools {
maven 'MAVEN_PATH'
jdk 'jdk8'
}
stages {
stage("Tools initialization") {
steps {
sh "mvn --version"
sh "java -version"
}
}
stage("Checkout Code") {
steps {
checkout scm
}
}
stage("Check Code Health") {
when {
not {
anyOf {
branch 'master';
branch 'develop'
}
}
}
steps {
sh "mvn clean compile"
}
}
stage("Run Test cases") {
when {
branch 'develop';
}
steps {
sh "mvn clean test"
}
}
stage("Check Code coverage") {
when {
branch 'develop'
}
steps {
jacoco(
execPattern: '**/target/**.exec',
classPattern: '**/target/classes',
sourcePattern: '**/src',
inclusionPattern: 'com/iamvickyav/**',
changeBuildStatus: true,
minimumInstructionCoverage: '30',
maximumInstructionCoverage: '80')
}
}
stage("Build and Deploy Code") {
when {
branch 'master'
}
steps {
sh "mvn tomcat7:deploy"
}
}
}
}Wir haben diese neue Jenkinsfile in den Branches master und develop hinterlegt, damit sie beim nächsten Repository-Scan von Jenkins Multibranch erkannt werden kann.
Selenium Automation Testing With Jenkins Multibranch Pipeline
Angenommen, wir schreiben Automatisierungstestfälle für eine Website. Immer wenn ein neuer Testfall in einem Branch hinterlegt wird, sollen sie ausgeführt und darauf geachtet werden, dass sie wie erwartet funktionieren.
Das Ausführen automatisierter Testfälle für jede Kombination aus Browser und Betriebssystem ist eine Herausforderung für jeden Entwickler. Hier kann die leistungsfähige Automatisierungstestinfrastruktur von LambdaTest nützlich sein.
Mit dem LambdaTest Selenium Grid können Sie Ihre Browserabdeckung maximieren.
In diesem Abschnitt werden wir sehen, wie man die Testinfrastruktur von LambdaTest mit der Jenkins Multibranch Pipeline nutzt. Als Demonstration haben wir hier eine Beispiel-Todo-App gehostet – LambdaTest ToDo App. Automatisierte Testfälle, die mit Cucumber geschrieben wurden, sind im Beispiel-Repo hinterlegt.
Von Jenkins aus möchten wir diese Testfälle auf der LambdaTest-Plattform ausführen. Das Ausführen von Testfällen in LambdaTest erfordert Benutzername und AccessToken. Registrieren Sie sich kostenlos bei der LambdaTest-Plattform, um Ihre Zugangsdaten zu erhalten.
Einrichten von Umgebungsvariablen
Wenn der Testfall ausgeführt wird, wird er nach dem LambdaTest-Benutzernamen (LT_USERNAME) und dem Passwort (LT_ACCESS_KEY) in Umgebungsvariablen suchen. Daher müssen wir diese vorher konfigurieren.
Um sie nicht im Quellcode zu speichern, haben wir sie als Geheimnisse in Jenkins konfiguriert und Umgebungsvariablen daraus geladen:
environment {
LAMBDATEST_CRED = credentials('Lambda-Test-Credentials-For-multibranch')
LT_USERNAME = "$LAMBDATEST_CRED_USR"
LT_ACCESS_KEY = "$LAMBDATEST_CRED_PSW"
}Hier ist unsere endgültige Jenkinsfile:
pipeline {
agent any
tools {
maven 'MAVEN_PATH'
jdk 'jdk8'
}
stages {
stage("Tools initialization") {
steps {
sh "mvn --version"
sh "java -version"
}
}
stage("Checkout Code") {
steps {
checkout scm
}
}
stage("Check Code Health") {
when {
not {
anyOf {
branch 'master';
branch 'develop'
}
}
}
steps {
sh "mvn clean compile"
}
}
stage("Run Test cases in LambdaTest") {
when {
branch 'develop';
}
environment {
LAMBDATEST_CRED = credentials('Lambda-Test-Credentials-For-multibranch')
LT_USERNAME = "$LAMBDATEST_CRED_USR"
LT_ACCESS_KEY = "$LAMBDATEST_CRED_PSW"
}
steps {
sh "mvn test"
}
}
}
}Nun werden wir einen neuen „Job“ in Jenkins als Multibranch-Pipeline erstellen, indem wir die in den oben genannten Abschnitten beschriebenen Schritte befolgen. Wir verweisen auf das Beispiel-Repo.
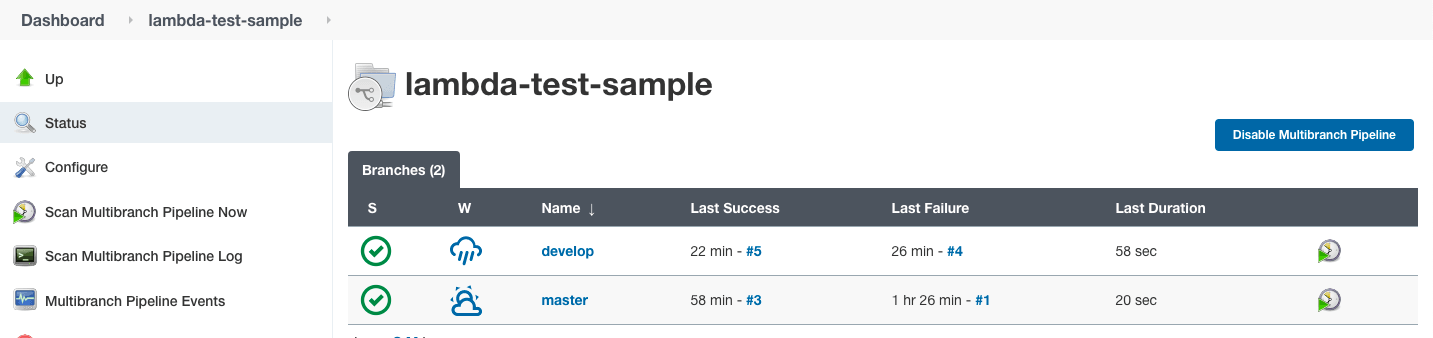
Sobald der Build erfolgreich ausgeführt wird, besuchen Sie das LambdaTest-Automatisierungs-Dashboard, um die Testprotokolle abzurufen.
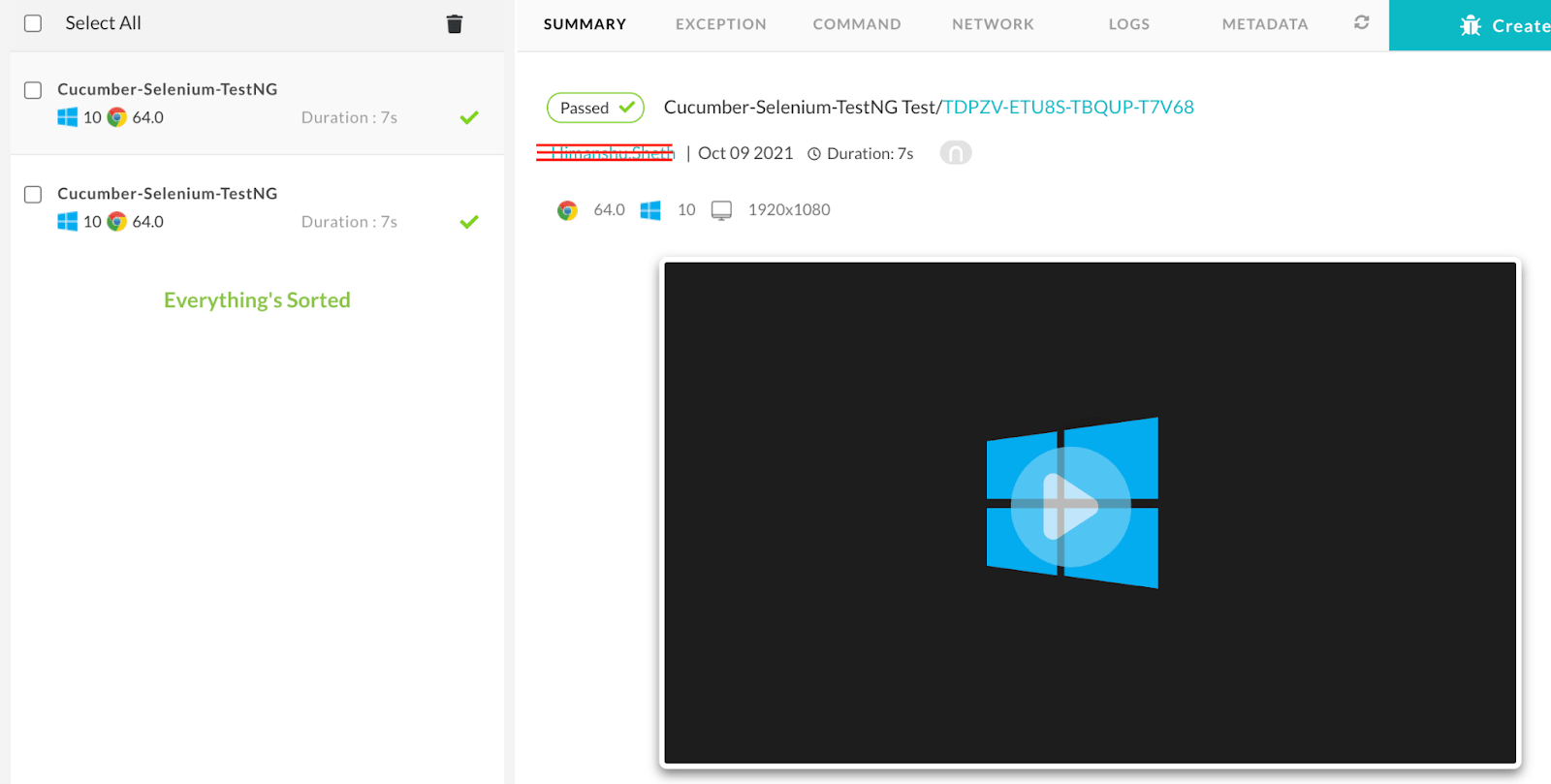
Schlussfolgerung
Damit haben wir gelernt, wie man eine Jenkins Multibranch-Pipeline erstellt, wie man einen Git-Repo darin konfiguriert, unterschiedliche Buildschritte für verschiedene Zweige, die periodische Autoscan-Funktion des Repos durch Jenkins und die Nutzung der leistungsstarken Automatisierungstestinfrastruktur von LambdaTest zur Automatisierung unserer CI/CD-Builds. Ich hoffe, dieser Artikel war für Sie nützlich. Bitte teilen Sie Ihr Feedback im Kommentarbereich.
Source:
https://dzone.com/articles/how-to-create-jenkins-multibranch-pipeline