













Der Autor hat den Free and Open Source Fund ausgewählt, um eine Spende im Rahmen des Write for DOnations-Programms zu erhalten.
Einführung
Die Datenbanküberwachung ist der kontinuierliche Prozess des systematischen Verfolgens verschiedener Kennzahlen, die zeigen, wie die Datenbank funktioniert. Durch die Beobachtung von Leistungsdaten können wertvolle Einblicke gewonnen und mögliche Engpässe identifiziert werden, sowie zusätzliche Möglichkeiten zur Verbesserung der Datenbankleistung gefunden werden. Solche Systeme implementieren oft Alarmierung, die Administratoren benachrichtigt, wenn etwas schief geht. Die gesammelten Statistiken können verwendet werden, um nicht nur die Konfiguration und den Arbeitsablauf der Datenbank zu verbessern, sondern auch die von Clientanwendungen.
Der Vorteil der Verwendung des Elastic Stack (ELK-Stacks) zur Überwachung Ihrer verwalteten Datenbank besteht in seiner ausgezeichneten Unterstützung für die Suche und der Fähigkeit, neue Daten sehr schnell zu erfassen. Es zeichnet sich nicht durch die Aktualisierung der Daten aus, aber dieser Kompromiss ist für Überwachungs- und Protokollzwecke akzeptabel, da vergangene Daten fast nie geändert werden. Elasticsearch bietet eine leistungsstarke Möglichkeit, auf die Daten zuzugreifen, die Sie über Kibana nutzen können, um ein besseres Verständnis dafür zu erlangen, wie die Datenbank in verschiedenen Zeiträumen abschneidet. Dies ermöglicht es Ihnen, die Datenbanklast mit realen Ereignissen in Beziehung zu setzen, um Einblicke darüber zu gewinnen, wie die Datenbank verwendet wird.
In diesem Tutorial importieren Sie Datenbankmetriken, die vom Redis INFO-Befehl generiert werden, über Logstash in Elasticsearch. Dies beinhaltet die Konfiguration von Logstash, um den Befehl regelmäßig auszuführen, seine Ausgabe zu analysieren und sie sofort danach an Elasticsearch zur Indexierung zu senden. Die importierten Daten können später in Kibana analysiert und visualisiert werden. Am Ende des Tutorials haben Sie ein automatisiertes System, das Redis-Statistiken für spätere Analysen abruft.
Voraussetzungen
- Ein Ubuntu 18.04 Server mit mindestens 8 GB RAM, Root-Privilegien und einem sekundären, nicht-root-Konto. Sie können dies einrichten, indem Sie diesem Anleitung zur Ersteinrichtung des Servers folgen. Für dieses Tutorial ist der nicht-root-Benutzer
sammy. - Java 8 auf Ihrem Server installiert. Für Installationsanweisungen besuchen Sie Wie man Java mit
aptauf Ubuntu 18.04 installiert und folgen Sie den Befehlen im ersten Schritt. Sie müssen nicht das Java Development Kit (JDK) installieren. - Nginx auf Ihrem Server installiert. Für eine Anleitung dazu sehen Sie das Wie man Nginx auf Ubuntu 18.04 installiert Tutorial.
- Elasticsearch und Kibana auf Ihrem Server installiert. Führen Sie die ersten beiden Schritte des Wie man Elasticsearch, Logstash und Kibana (Elastic Stack) auf Ubuntu 18.04 installiert Tutorials aus.
- A Redis managed database provisioned from DigitalOcean with connection information available. Make sure that your server’s IP address is on the whitelist. For a guide on creating a Redis database using the DigitalOcean Control Panel, visit the Redis Quickstart guide.
- Redli auf Ihrem Server installiert gemäß dem Wie man sich mit einer verwalteten Datenbank auf Ubuntu 18.04 verbindet Tutorial.
Schritt 1 — Installation und Konfiguration von Logstash
In diesem Abschnitt werden Sie Logstash installieren und konfigurieren, um Statistiken von Ihrem Redis-Datenbankcluster abzurufen und sie dann zur Indizierung an Elasticsearch zu senden.
Beginnen Sie mit der Installation von Logstash mit dem folgenden Befehl:
Sobald Logstash installiert ist, aktivieren Sie den Dienst, um automatisch beim Booten zu starten:
Bevor Sie Logstash konfigurieren, um die Statistiken abzurufen, sehen wir uns an, wie die Daten selbst aussehen. Um eine Verbindung zu Ihrer Redis-Datenbank herzustellen, gehen Sie zum Managed Database Control Panel und wählen Sie im Dropdown-Menü unter dem Verbindungsdetails-Panel Flags aus:
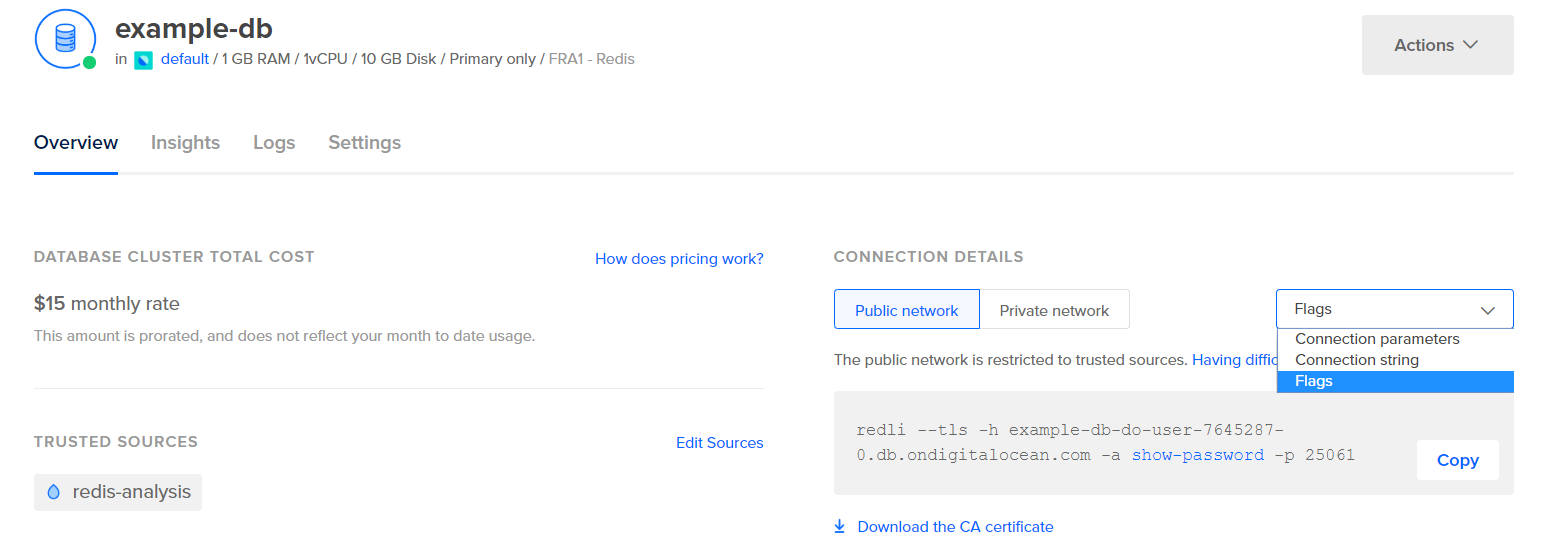
Ihnen wird ein vordefinierter Befehl für den Redli-Client angezeigt, den Sie verwenden, um eine Verbindung zu Ihrer Datenbank herzustellen. Klicken Sie auf Kopieren und führen Sie den folgenden Befehl auf Ihrem Server aus, wobei Sie redli_flags_command durch den gerade kopierten Befehl ersetzen:
Da die Ausgabe dieses Befehls lang ist, erklären wir dies in verschiedene Abschnitte unterteilt.
In der Ausgabe des Redis info-Befehls sind Abschnitte mit # markiert, was einen Kommentar kennzeichnet. Die Werte sind in Form von Schlüssel:Wert ausgefüllt, was sie relativ einfach zu analysieren macht.
Der Server-Abschnitt enthält technische Informationen zum Redis-Build, wie z.B. dessen Version und den Git-Commit, auf dem er basiert, während der Clients-Abschnitt die Anzahl der aktuell geöffneten Verbindungen angibt.
Output# Server
redis_version:6.2.6
redis_git_sha1:4f4e829a
redis_git_dirty:1
redis_build_id:5861572cb79aebf3
redis_mode:standalone
os:Linux 5.11.12-300.fc34.x86_64 x86_64
arch_bits:64
multiplexing_api:epoll
atomicvar_api:atomic-builtin
gcc_version:11.2.1
process_id:79
process_supervised:systemd
run_id:b8a0aa25d8f49a879112a04a817ac2acd92e0c75
tcp_port:25060
server_time_usec:1640878632737564
uptime_in_seconds:1679
uptime_in_days:0
hz:10
configured_hz:10
lru_clock:13488680
executable:/usr/bin/redis-server
config_file:/etc/redis.conf
io_threads_active:0
# Clients
connected_clients:4
cluster_connections:0
maxclients:10032
client_recent_max_input_buffer:24
client_recent_max_output_buffer:0
...
Memory bestätigt, wie viel RAM Redis für sich selbst allokiert hat, sowie die maximale Menge an Speicher, die es möglicherweise verwenden kann. Wenn ihm der Speicher ausgeht, werden Schlüssel mithilfe der von Ihnen im Control Panel angegebenen Strategie freigegeben (angezeigt im maxmemory_policy-Feld in dieser Ausgabe).
Output...
# Memory
used_memory:977696
used_memory_human:954.78K
used_memory_rss:9977856
used_memory_rss_human:9.52M
used_memory_peak:977696
used_memory_peak_human:954.78K
used_memory_peak_perc:100.00%
used_memory_overhead:871632
used_memory_startup:810128
used_memory_dataset:106064
used_memory_dataset_perc:63.30%
allocator_allocated:947216
allocator_active:1273856
allocator_resident:3510272
total_system_memory:1017667584
total_system_memory_human:970.52M
used_memory_lua:37888
used_memory_lua_human:37.00K
used_memory_scripts:0
used_memory_scripts_human:0B
number_of_cached_scripts:0
maxmemory:455081984
maxmemory_human:434.00M
maxmemory_policy:noeviction
allocator_frag_ratio:1.34
allocator_frag_bytes:326640
allocator_rss_ratio:2.76
allocator_rss_bytes:2236416
rss_overhead_ratio:2.84
rss_overhead_bytes:6467584
mem_fragmentation_ratio:11.43
mem_fragmentation_bytes:9104832
mem_not_counted_for_evict:0
mem_replication_backlog:0
mem_clients_slaves:0
mem_clients_normal:61504
mem_aof_buffer:0
mem_allocator:jemalloc-5.1.0
active_defrag_running:0
lazyfree_pending_objects:0
...
Im Persistence-Abschnitt können Sie sehen, wann Redis zuletzt die von ihm gespeicherten Schlüssel auf die Festplatte gespeichert hat, und ob dies erfolgreich war. Der Stats-Abschnitt enthält Zahlen zu Client- und In-Cluster-Verbindungen, zur Anzahl der Male, die der angeforderte Schlüssel gefunden wurde (oder nicht), usw.
Output...
# Persistence
loading:0
current_cow_size:0
current_cow_size_age:0
current_fork_perc:0.00
current_save_keys_processed:0
current_save_keys_total:0
rdb_changes_since_last_save:0
rdb_bgsave_in_progress:0
rdb_last_save_time:1640876954
rdb_last_bgsave_status:ok
rdb_last_bgsave_time_sec:1
rdb_current_bgsave_time_sec:-1
rdb_last_cow_size:217088
aof_enabled:0
aof_rewrite_in_progress:0
aof_rewrite_scheduled:0
aof_last_rewrite_time_sec:-1
aof_current_rewrite_time_sec:-1
aof_last_bgrewrite_status:ok
aof_last_write_status:ok
aof_last_cow_size:0
module_fork_in_progress:0
module_fork_last_cow_size:0
# Stats
total_connections_received:202
total_commands_processed:2290
instantaneous_ops_per_sec:0
total_net_input_bytes:38034
total_net_output_bytes:1103968
instantaneous_input_kbps:0.01
instantaneous_output_kbps:0.00
rejected_connections:0
sync_full:0
sync_partial_ok:0
sync_partial_err:0
expired_keys:0
expired_stale_perc:0.00
expired_time_cap_reached_count:0
expire_cycle_cpu_milliseconds:29
evicted_keys:0
keyspace_hits:0
keyspace_misses:0
pubsub_channels:0
pubsub_patterns:0
latest_fork_usec:452
total_forks:1
migrate_cached_sockets:0
slave_expires_tracked_keys:0
active_defrag_hits:0
active_defrag_misses:0
active_defrag_key_hits:0
active_defrag_key_misses:0
tracking_total_keys:0
tracking_total_items:0
tracking_total_prefixes:0
unexpected_error_replies:0
total_error_replies:0
dump_payload_sanitizations:0
total_reads_processed:2489
total_writes_processed:2290
io_threaded_reads_processed:0
io_threaded_writes_processed:0
...
Indem Sie sich das role unter Replication ansehen, wissen Sie, ob Sie mit einem primären oder einem Replikat-Knoten verbunden sind. Der Rest des Abschnitts enthält die Anzahl der aktuell verbundenen Replikate und die Menge an Daten, die dem Replikat im Vergleich zum Primärknoten fehlen. Es können zusätzliche Felder vorhanden sein, wenn die Instanz, mit der Sie verbunden sind, ein Replikat ist.
Hinweis: Das Redis-Projekt verwendet in seiner Dokumentation und in verschiedenen Befehlen die Begriffe „Master“ und „Slave“. DigitalOcean bevorzugt im Allgemeinen die alternativen Begriffe „Primary“ und „Replica“. Dieser Leitfaden verwendet standardmäßig die Begriffe „Primary“ und „Replica“, wo immer möglich, aber beachten Sie, dass es einige Fälle gibt, in denen die Begriffe „Master“ und „Slave“ unvermeidlich auftauchen.
Output...
# Replication
role:master
connected_slaves:0
master_failover_state:no-failover
master_replid:f727fad3691f2a8d8e593b087c468bbb83703af3
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:0
second_repl_offset:-1
repl_backlog_active:0
repl_backlog_size:45088768
repl_backlog_first_byte_offset:0
repl_backlog_histlen:0
...
Unter CPU sehen Sie die Menge an System (used_cpu_sys) und Benutzer (used_cpu_user) CPU-Leistung, die Redis gerade verbraucht. Der Cluster-Abschnitt enthält nur ein einzigartiges Feld, cluster_enabled, das anzeigt, dass der Redis-Cluster läuft.
Output...
# CPU
used_cpu_sys:1.617986
used_cpu_user:1.248422
used_cpu_sys_children:0.000000
used_cpu_user_children:0.001459
used_cpu_sys_main_thread:1.567638
used_cpu_user_main_thread:1.218768
# Modules
# Fehlerstatistiken
# Cluster
cluster_enabled:0
# Keyspace
Logstash wird damit beauftragt, regelmäßig den info-Befehl auf Ihrer Redis-Datenbank auszuführen (ähnlich wie Sie es gerade getan haben), die Ergebnisse zu analysieren und sie an Elasticsearch zu senden. Sie können dann später von Kibana darauf zugreifen.
Sie speichern die Konfiguration zur Indizierung von Redis-Statistiken in Elasticsearch in einer Datei namens redis.conf im Verzeichnis /etc/logstash/conf.d, wo Logstash Konfigurationsdateien speichert. Wenn es als Dienst gestartet wird, werden sie automatisch im Hintergrund ausgeführt.
Erstellen Sie redis.conf mit Ihrem bevorzugten Editor (z. B. nano):
Fügen Sie die folgenden Zeilen hinzu:
input {
exec {
command => "redis_flags_command info"
interval => 10
type => "redis_info"
}
}
filter {
kv {
value_split => ":"
field_split => "\r\n"
remove_field => [ "command", "message" ]
}
ruby {
code =>
"
event.to_hash.keys.each { |k|
if event.get(k).to_i.to_s == event.get(k) # is integer?
event.set(k, event.get(k).to_i) # convert to integer
end
if event.get(k).to_f.to_s == event.get(k) # is float?
event.set(k, event.get(k).to_f) # convert to float
end
}
puts 'Ruby filter finished'
"
}
}
output {
elasticsearch {
hosts => "http://localhost:9200"
index => "%{type}"
}
}
Vergessen Sie nicht, redis_flags_command durch den Befehl zu ersetzen, der im Steuerfeld angezeigt wird, den Sie zuvor im Schritt verwendet haben.
Sie definieren eine Eingabe, die aus einer Reihe von Filtern besteht, die auf die gesammelten Daten angewendet werden, sowie eine Ausgabe, die die gefilterten Daten an Elasticsearch sendet. Die Eingabe besteht aus dem exec-Befehl, der periodisch nach einer festgelegten Zeit interval (ausgedrückt in Sekunden) einen Befehl auf dem Server ausführt. Es wird auch ein Typ-Parameter angegeben, der den Dokumenttyp definiert, wenn er in Elasticsearch indiziert wird. Der exec-Block leitet ein Objekt weiter, das zwei Felder enthält, Befehl und Nachricht-Zeichenfolge. Das Feld Befehl enthält den ausgeführten Befehl und die Nachricht enthält dessen Ausgabe.
Es gibt zwei Filter, die nacheinander auf den aus der Eingabe gesammelten Daten ausgeführt werden. Der kv-Filter steht für den Schlüssel-Wert-Filter und ist in Logstash integriert. Er wird zum Parsen von Daten im allgemeinen Format von SchlüsselWert-TrennzeichenWert verwendet und bietet Parameter zur Festlegung von Wert- und Feldtrennzeichen. Das Feldtrennzeichen bezieht sich auf Zeichenfolgen, die die im allgemeinen Format formatierten Daten voneinander trennen. Im Fall der Ausgabe des Redis INFO-Befehls ist das Feldtrennzeichen (field_split) eine neue Zeile und das Werttrennzeichen (value_split) ist :. Zeilen, die nicht dem definierten Format entsprechen, einschließlich Kommentaren, werden verworfen.
Um den kv-Filter zu konfigurieren, geben Sie : an den value_split-Parameter und \r\n (was eine neue Zeile bedeutet) an den field_split-Parameter weiter. Sie ordnen außerdem an, das command– und message-Felder aus dem aktuellen Datensatz zu entfernen, indem Sie sie als Elemente eines Arrays an remove_field übergeben, da sie Daten enthalten, die jetzt nutzlos sind.
Der kv-Filter stellt den von ihm analysierten Wert standardmäßig als String (Text) dar. Dies führt zu einem Problem, da Kibana String-Typen nicht einfach verarbeiten kann, selbst wenn es sich tatsächlich um eine Zahl handelt. Um dies zu lösen, verwenden Sie benutzerdefinierten Ruby-Code, um die nur aus Zahlen bestehenden Strings, wo möglich, in Zahlen umzuwandeln. Der zweite Filter ist ein ruby-Block, der einen code-Parameter akzeptiert, der einen String mit dem auszuführenden Code enthält.
event ist eine Variable, die Logstash Ihrem Code zur Verfügung stellt und die die aktuellen Daten im Filter-Pipeline enthält. Wie bereits erwähnt, werden Filter nacheinander ausgeführt, was bedeutet, dass der Ruby-Filter die analysierten Daten vom kv-Filter empfangen wird. Der Ruby-Code selbst wandelt das event in einen Hash um und durchläuft die Schlüssel. Dann wird überprüft, ob der mit dem Schlüssel verbundene Wert als Ganzzahl oder als Fließkommazahl (eine Zahl mit Dezimalstellen) dargestellt werden kann. Wenn ja, wird der Zeichenfolgenwert durch die geparste Zahl ersetzt. Wenn die Schleife beendet ist, wird eine Meldung (Ruby-Filter abgeschlossen) ausgegeben, um den Fortschritt zu melden.
Die Ausgabe sendet die verarbeiteten Daten zur Indizierung an Elasticsearch. Das resultierende Dokument wird im Index redis_info gespeichert, der in der Eingabe definiert und als Parameter an den Ausgabe-Block übergeben wird.
Speichern und schließen Sie die Datei.
Sie haben Logstash mit apt installiert und konfiguriert, um periodisch Statistiken von Redis anzufordern, sie zu verarbeiten und an Ihre Elasticsearch-Instanz zu senden.
Schritt 2 — Überprüfen der Logstash-Konfiguration
Jetzt werden Sie die Konfiguration testen, indem Sie Logstash ausführen, um zu überprüfen, ob es die Daten ordnungsgemäß abruft.
Logstash unterstützt das Ausführen einer bestimmten Konfiguration, indem der Dateipfad mit dem -f-Parameter übergeben wird. Führen Sie den folgenden Befehl aus, um Ihre neue Konfiguration aus dem letzten Schritt zu testen:
Es kann einige Zeit dauern, bis die Ausgabe angezeigt wird, aber bald sehen Sie etwas Ähnliches wie folgt:
OutputUsing bundled JDK: /usr/share/logstash/jdk
OpenJDK 64-Bit Server VM warning: Option UseConcMarkSweepGC was deprecated in version 9.0 and will likely be removed in a future release.
WARNING: Could not find logstash.yml which is typically located in $LS_HOME/config or /etc/logstash. You can specify the path using --path.settings. Continuing using the defaults
Could not find log4j2 configuration at path /usr/share/logstash/config/log4j2.properties. Using default config which logs errors to the console
[INFO ] 2021-12-30 15:42:08.887 [main] runner - Starting Logstash {"logstash.version"=>"7.16.2", "jruby.version"=>"jruby 9.2.20.1 (2.5.8) 2021-11-30 2a2962fbd1 OpenJDK 64-Bit Server VM 11.0.13+8 on 11.0.13+8 +indy +jit [linux-x86_64]"}
[INFO ] 2021-12-30 15:42:08.932 [main] settings - Creating directory {:setting=>"path.queue", :path=>"/usr/share/logstash/data/queue"}
[INFO ] 2021-12-30 15:42:08.939 [main] settings - Creating directory {:setting=>"path.dead_letter_queue", :path=>"/usr/share/logstash/data/dead_letter_queue"}
[WARN ] 2021-12-30 15:42:09.406 [LogStash::Runner] multilocal - Ignoring the 'pipelines.yml' file because modules or command line options are specified
[INFO ] 2021-12-30 15:42:09.449 [LogStash::Runner] agent - No persistent UUID file found. Generating new UUID {:uuid=>"acc4c891-936b-4271-95de-7d41f4a41166", :path=>"/usr/share/logstash/data/uuid"}
[INFO ] 2021-12-30 15:42:10.985 [Api Webserver] agent - Successfully started Logstash API endpoint {:port=>9600, :ssl_enabled=>false}
[INFO ] 2021-12-30 15:42:11.601 [Converge PipelineAction::Create<main>] Reflections - Reflections took 77 ms to scan 1 urls, producing 119 keys and 417 values
[WARN ] 2021-12-30 15:42:12.215 [Converge PipelineAction::Create<main>] plain - Relying on default value of `pipeline.ecs_compatibility`, which may change in a future major release of Logstash. To avoid unexpected changes when upgrading Logstash, please explicitly declare your desired ECS Compatibility mode.
[WARN ] 2021-12-30 15:42:12.366 [Converge PipelineAction::Create<main>] plain - Relying on default value of `pipeline.ecs_compatibility`, which may change in a future major release of Logstash. To avoid unexpected changes when upgrading Logstash, please explicitly declare your desired ECS Compatibility mode.
[WARN ] 2021-12-30 15:42:12.431 [Converge PipelineAction::Create<main>] elasticsearch - Relying on default value of `pipeline.ecs_compatibility`, which may change in a future major release of Logstash. To avoid unexpected changes when upgrading Logstash, please explicitly declare your desired ECS Compatibility mode.
[INFO ] 2021-12-30 15:42:12.494 [[main]-pipeline-manager] elasticsearch - New Elasticsearch output {:class=>"LogStash::Outputs::ElasticSearch", :hosts=>["http://localhost:9200"]}
[INFO ] 2021-12-30 15:42:12.755 [[main]-pipeline-manager] elasticsearch - Elasticsearch pool URLs updated {:changes=>{:removed=>[], :added=>[http://localhost:9200/]}}
[WARN ] 2021-12-30 15:42:12.955 [[main]-pipeline-manager] elasticsearch - Restored connection to ES instance {:url=>"http://localhost:9200/"}
[INFO ] 2021-12-30 15:42:12.967 [[main]-pipeline-manager] elasticsearch - Elasticsearch version determined (7.16.2) {:es_version=>7}
[WARN ] 2021-12-30 15:42:12.968 [[main]-pipeline-manager] elasticsearch - Detected a 6.x and above cluster: the `type` event field won't be used to determine the document _type {:es_version=>7}
[WARN ] 2021-12-30 15:42:13.065 [[main]-pipeline-manager] kv - Relying on default value of `pipeline.ecs_compatibility`, which may change in a future major release of Logstash. To avoid unexpected changes when upgrading Logstash, please explicitly declare your desired ECS Compatibility mode.
[INFO ] 2021-12-30 15:42:13.090 [Ruby-0-Thread-10: :1] elasticsearch - Using a default mapping template {:es_version=>7, :ecs_compatibility=>:disabled}
[INFO ] 2021-12-30 15:42:13.147 [Ruby-0-Thread-10: :1] elasticsearch - Installing Elasticsearch template {:name=>"logstash"}
[INFO ] 2021-12-30 15:42:13.192 [[main]-pipeline-manager] javapipeline - Starting pipeline {:pipeline_id=>"main", "pipeline.workers"=>2, "pipeline.batch.size"=>125, "pipeline.batch.delay"=>50, "pipeline.max_inflight"=>250, "pipeline.sources"=>["/etc/logstash/conf.d/redis.conf"], :thread=>"#<Thread:0x5104e975 run>"}
[INFO ] 2021-12-30 15:42:13.973 [[main]-pipeline-manager] javapipeline - Pipeline Java execution initialization time {"seconds"=>0.78}
[INFO ] 2021-12-30 15:42:13.983 [[main]-pipeline-manager] exec - Registering Exec Input {:type=>"redis_info", :command=>"redli --tls -h db-redis-fra1-68603-do-user-1446234-0.b.db.ondigitalocean.com -a hnpJxAgoH3Om3UwM -p 25061 info", :interval=>10, :schedule=>nil}
[INFO ] 2021-12-30 15:42:13.994 [[main]-pipeline-manager] javapipeline - Pipeline started {"pipeline.id"=>"main"}
[INFO ] 2021-12-30 15:42:14.034 [Agent thread] agent - Pipelines running {:count=>1, :running_pipelines=>[:main], :non_running_pipelines=>[]}
Ruby filter finished
Ruby filter finished
Ruby filter finished
...
Sie sehen die Nachricht Ruby-Filter abgeschlossen in regelmäßigen Abständen gedruckt (auf 10 Sekunden im vorherigen Schritt eingestellt), was bedeutet, dass die Statistiken an Elasticsearch übertragen werden.
Sie können Logstash beenden, indem Sie auf Ihrer Tastatur STRG + C drücken. Wie bereits erwähnt, führt Logstash automatisch alle Konfigurationsdateien aus, die unter /etc/logstash/conf.d gefunden wurden, im Hintergrund aus, wenn es als Dienst gestartet wird. Führen Sie den folgenden Befehl aus, um es zu starten:
Sie haben Logstash ausgeführt, um zu überprüfen, ob es eine Verbindung zu Ihrem Redis-Cluster herstellen und Daten sammeln kann. Als nächstes werden Sie einige der statistischen Daten in Kibana erkunden.
Schritt 3 – Erkunden der importierten Daten in Kibana
In diesem Abschnitt werden Sie die statistischen Daten erkunden und visualisieren, die die Leistung Ihrer Datenbank in Kibana beschreiben.
Öffnen Sie Ihren Webbrowser und navigieren Sie zu Ihrer Domain, auf der Sie Kibana gemäß den Voraussetzungen freigegeben haben. Sie sehen die Standard-Willkommensseite:
Bevor Sie die Daten erkunden, die Logstash an Elasticsearch sendet, müssen Sie zunächst den redis_info-Index zu Kibana hinzufügen. Wählen Sie dazu zunächst Selbst erkunden auf der Willkommensseite und öffnen Sie dann das Hamburger-Menü oben links. Unter Analytics klicken Sie auf Discover.
Kibana wird Sie dann auffordern, ein neues Indexmuster zu erstellen:
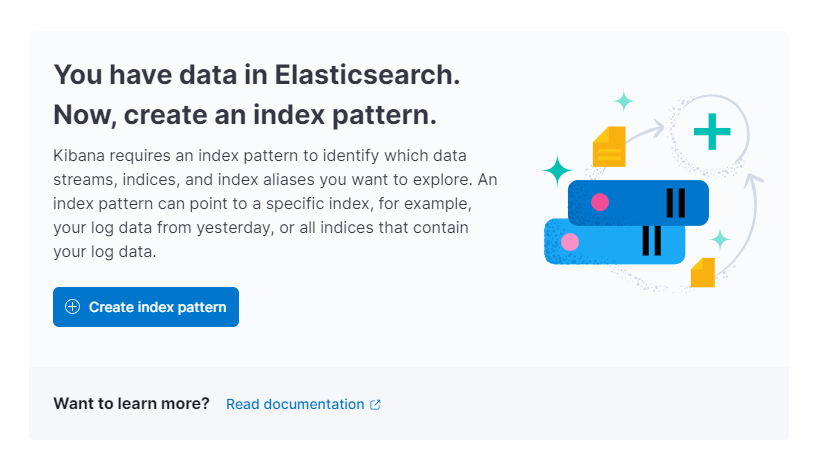
Drücken Sie auf Indexmuster erstellen. Sie sehen ein Formular zum Erstellen eines neuen Indexmusters. Indexmuster in Kibana bieten eine Möglichkeit, Daten aus mehreren Elasticsearch-Indizes gleichzeitig abzurufen und können verwendet werden, um nur einen Index zu erkunden.

Auf der rechten Seite listet Kibana alle verfügbaren Indizes auf, wie z. B. redis_info, den Sie konfiguriert haben, um Logstash zu verwenden. Geben Sie es im Name-Textfeld ein und wählen Sie @timestamp aus dem Dropdown-Menü als Zeitstempelfeld aus. Wenn Sie fertig sind, klicken Sie auf die Schaltfläche Indexmuster erstellen unten.
Um Visualisierungen zu erstellen und vorhandene anzuzeigen, öffnen Sie das Hamburger-Menü. Wählen Sie unter Analytics Dashboard. Wenn es geladen ist, klicken Sie auf Visualisierung erstellen, um eine neue zu erstellen:
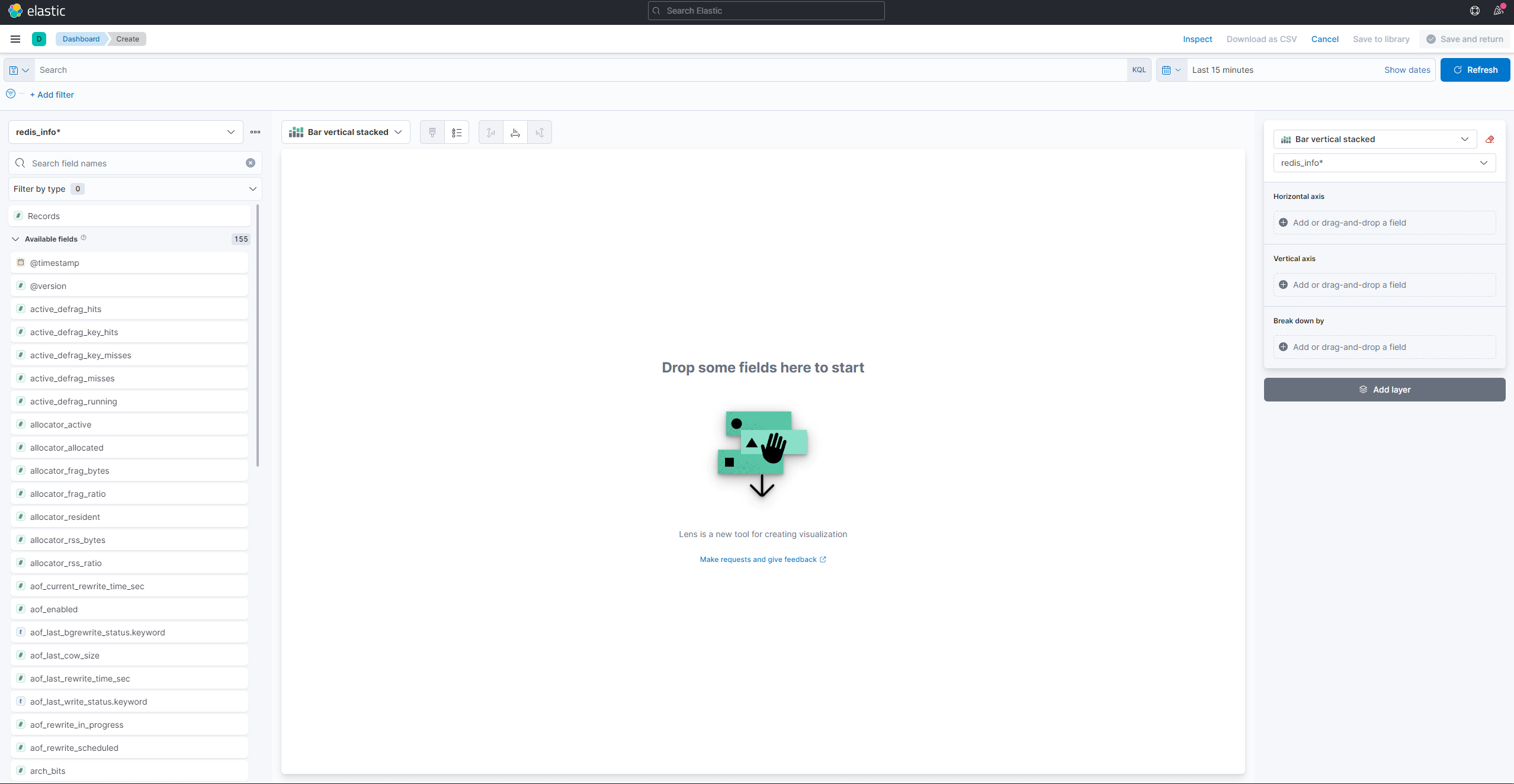
Das linke Seitenpanel bietet eine Liste von Werten, die Kibana zur Erstellung der Visualisierung verwenden kann, die im zentralen Teil des Bildschirms angezeigt wird. In der oberen rechten Ecke des Bildschirms befindet sich der Datumsbereichsauswähler. Wenn das @timestamp-Feld in der Visualisierung verwendet wird, zeigt Kibana nur die Daten an, die dem im Bereichsauswähler angegebenen Zeitintervall gehören.
Wählen Sie im Dropdown-Menü im Hauptteil der Seite Linie unter dem Abschnitt Linie und Bereich aus. Finden Sie dann das Feld used_memory in der Liste links und ziehen Sie es in den zentralen Teil. Sie werden bald eine Linienvisualisierung der durchschnittlichen Menge an verwendetem Speicher im Laufe der Zeit sehen:
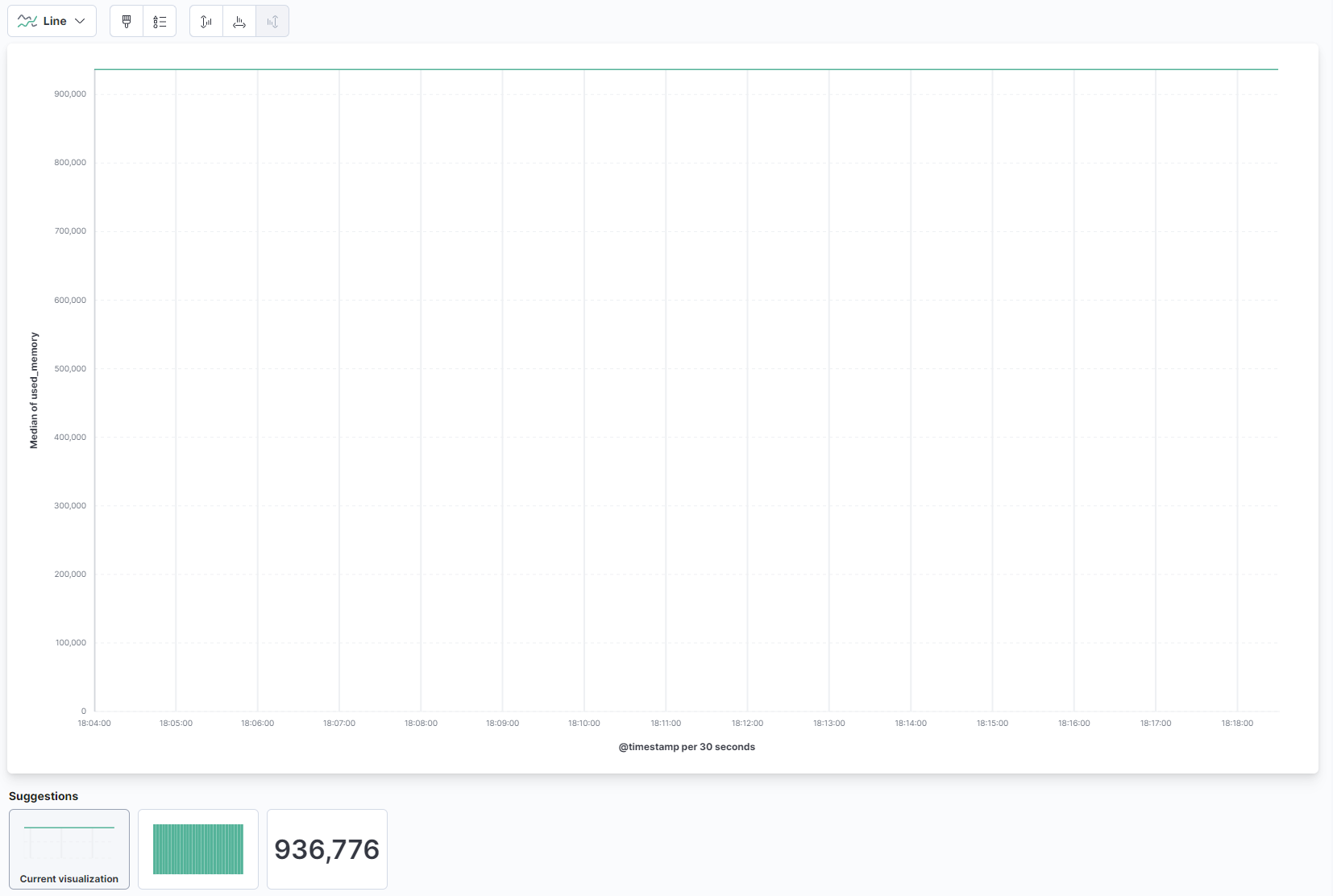
Auf der rechten Seite können Sie konfigurieren, wie die horizontalen und vertikalen Achsen verarbeitet werden. Dort können Sie die vertikale Achse so einstellen, dass sie die Durchschnittswerte anzeigt, anstelle des Medians, indem Sie auf die angezeigte Achse klicken:
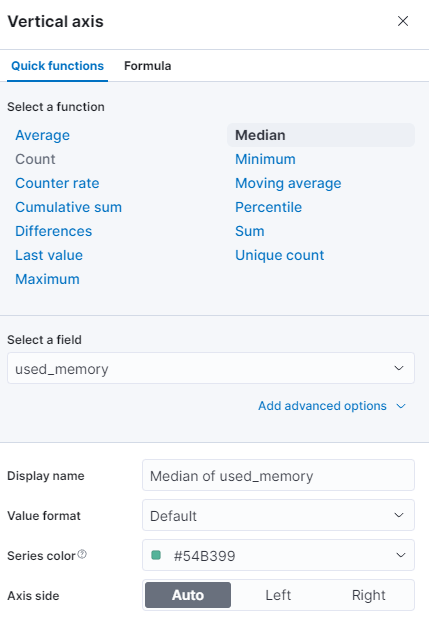
Sie können eine andere Funktion auswählen oder Ihre eigene bereitstellen:
Das Diagramm wird sofort mit den aktualisierten Werten aktualisiert.
In diesem Schritt haben Sie die Speicherauslastung Ihrer verwalteten Redis-Datenbank mithilfe von Kibana visualisiert. Dies ermöglicht es Ihnen, ein besseres Verständnis dafür zu erlangen, wie Ihre Datenbank genutzt wird, was Ihnen dabei helfen wird, Client-Anwendungen sowie Ihre Datenbank selbst zu optimieren.
Fazit
Sie haben nun den Elastic Stack auf Ihrem Server installiert und so konfiguriert, dass er regelmäßig Statistikdaten von Ihrer verwalteten Redis-Datenbank abruft. Sie können die Daten mithilfe von Kibana oder einer anderen geeigneten Software analysieren und visualisieren, was Ihnen wertvolle Einblicke und realweltliche Zusammenhänge darüber verschafft, wie Ihre Datenbank performt.
Für weitere Informationen darüber, was Sie mit Ihrer verwalteten Redis-Datenbank tun können, besuchen Sie die Produktdokumentation. Wenn Sie die Datenbankstatistiken gerne mit einem anderen Visualisierungstyp präsentieren möchten, werfen Sie einen Blick in die Kibana-Dokumentation für weitere Anweisungen.