













Die Einführung des Apache Hadoop Distributed File System (HDFS) hat die Speicherung, Verarbeitung und Analyse von Daten für Unternehmen revolutioniert, die Entwicklung von Big Data beschleunigt und tiefgreifende Veränderungen in der Branche hervorgerufen.
Ursprünglich waren bei Hadoop Speicher und Berechnung integriert, doch die Entstehung von Cloud Computing führte zu einer Trennung dieser Komponenten. Objektspeicher entstand als Alternative zu HDFS, hatte jedoch Einschränkungen. Um diese Einschränkungen zu ergänzen, bietet JuiceFS, eine quelloffene, leistungsstarke verteilte Dateisystem, kosteneffiziente Lösungen für datenintensive Szenarien wie Berechnung, Analyse und Training. Die Entscheidung für eine Trennung von Speicher und Berechnung hängt von Faktoren wie Skalierbarkeit, Leistung, Kosten und Kompatibilität ab.
In diesem Artikel werden wir die Hadoop-Architektur überprüfen, die Bedeutung und die Machbarkeit der Entkopplung von Speicher und Berechnung diskutieren und verfügbare Marktlösungen erkunden, wobei wir ihre jeweiligen Vor- und Nachteile hervorheben. Unser Ziel ist es, Einblicke und Inspiration für Unternehmen zu bieten, die sich einer Transformation der Architektur für die Trennung von Speicher und Berechnung unterziehen.
Hadoop-Architektur-Design-Merkmale
Hadoop als All-In-One-Framework
Im Jahr 2006 wurde Hadoop als All-In-One-Framework veröffentlicht, bestehend aus drei Komponenten:
- MapReduce für Berechnungen
- YARN für Ressourcenplanung
- HDFS für verteilten Dateispeicher
 Core components of Hadoop
Core components of HadoopVielfältige Berechnungskomponenten
Unter diesen drei Komponenten hat die Berechnungsschicht eine schnelle Entwicklung erlebt. Anfangs gab es nur MapReduce, aber die Branche bemerkte bald die Entstehung verschiedener Frameworks wie Tez und Spark für die Berechnung, Hive für den Daten-Lagerungsbau und Abfragesysteme wie Presto und Impala. In Verbindung mit diesen Komponenten gibt es zahlreiche Datentransferwerkzeuge wie Sqoop.

HDFS Dominierte das Speichersystem
Über ungefähr zehn Jahre war HDFS, das verteilte Dateisystem, das dominante Speichersystem geblieben. Es war die Standardwahl für fast alle Berechnungskomponenten. Alle oben genannten Komponenten innerhalb des Big Data Ökosystems wurden für die HDFS-API entworfen. Einige Komponenten nutzen die spezifischen Fähigkeiten von HDFS tiefgreifend. Zum Beispiel:
- HBase nutzt die geringe Schreiblatenz von HDFS für ihre Write-Ahead-Logs.
- MapReduce und Spark boten Datenplatzierungsfunktionen.
Die Designentscheidungen dieser Big Data Komponenten, basierend auf der HDFS-API, brachten potenzielle Herausforderungen für die Bereitstellung von Datenplattformen in die Cloud.
Speicher-Berechnung gekoppelte Architektur
Die folgende Abbildung zeigt einen Teil einer vereinfachten HDFS-Architektur, die Berechnung mit Speicher kombiniert.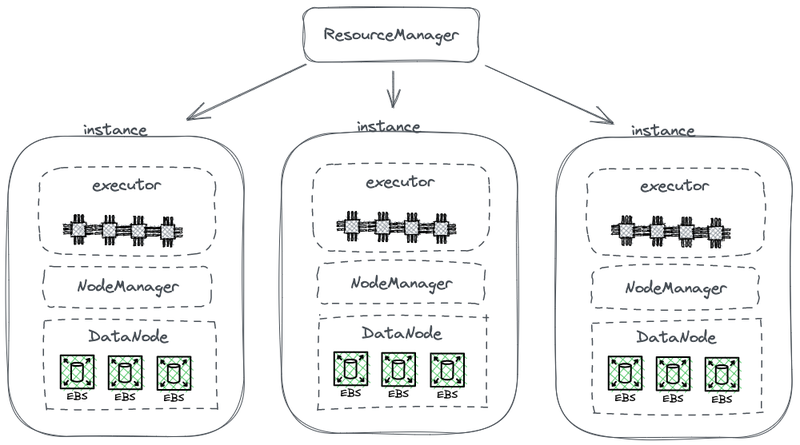
Hadoop-Architektur mit gekoppelter Speicher- und Berechnung
In dieser Abbildung dient jeder Knoten als HDFS-DataNode zum Speichern von Daten. Darüber hinaus setzt YARN auf jedem Knoten einen Node Manager-Prozess ein. Dies ermöglicht YARN, den Knoten als Teil seiner verwalteten Ressourcen für Berechnungsaufgaben zu erkennen. Diese Architektur ermöglicht es, Speicher und Berechnung auf demselben Computer zusammenzulegen, und Daten können während der Berechnung vom Speicher gelesen werden.
Warum Hadoop gekoppelter Speicher und Berechnung
Hadoop gekoppelter Speicher und Berechnung aufgrund der Einschränkungen von Netzwerkkommunikation und Hardware während seiner Entwurfsphase.
Im Jahr 2006 befand sich Cloud Computing noch in seiner frühen Entwicklungsphase, und Amazon hatte gerade seine erste Dienstleistung veröffentlicht. In Rechenzentren waren die vorherrschenden Netzwerkkarten hauptsächlich mit einer Geschwindigkeit von 100 Mbps betriebsbereit. Datenspeicher, die für Big-Data-Workloads verwendet wurden, erreichten eine Durchsatzrate von etwa 50 MB/s, was einer Netzwerkbandbreite von 400 Mbps entspricht.
Bei einem Knoten mit acht Festplatten, der seine maximale Kapazität auslastet, wurden mehrere Gigabit pro Sekunde an Netzwerkbandbreite für eine effiziente Datenübertragung benötigt. Leider war die maximale Kapazität der Netzwerkkarten auf 1 Gbps begrenzt. Folglich war die Netzwerkbandbreite pro Knoten nicht ausreichend, um die Fähigkeiten aller Festplatten innerhalb des Knotens voll auszuschöpfen. Infolgedessen stellte die Netzwerkbandbreite bei Rechenaufgaben, die auf einer Seite des Netzwerks lagen und die Daten auf Datenknoten auf der anderen Seite befanden, einen signifikanten Engpass dar.
Warum die Trennung von Speicher und Berechnung notwendig ist
Von 2006 bis etwa 2016 stellten Unternehmen folgende Probleme:
- Die Nachfrage nach Rechenleistung und Speicher in Anwendungen war unausgeglichen, und ihre Wachstumsraten unterschieden sich. Während Unternehmensdaten schnell wuchsen, wuchs der Bedarf an Rechenleistung nicht so schnell. Diese Aufgaben, entwickelt von Menschen, vervielfachten sich nicht exponentiell in kurzer Zeit. Die von diesen Aufgaben erzeugten Daten hingegen sammelten sich jedoch schnell an, möglicherweise in exponentiellem Maßstab. Darüber hinaus konnten einige Daten dem Unternehmen vielleicht nicht sofort nützen, würden jedoch in der Zukunft von Wert sein. Daher speicherten Unternehmen die Daten umfassend, um das potentielle Wertvolle darin zu erkunden.
- Bei der Skalierung mussten Unternehmen sowohl Rechen- als auch Speicherkapazitäten gleichzeitig erweitern, was häufig zu verschwendeten Rechenressourcen führte. Die Hardwaretopologie der Speicher-Rechen gekoppelten Architektur beeinflusste die Kapazitätserweiterung. Wenn die Speicherkapazität nicht ausreichte, mussten wir nicht nur Maschinen hinzufügen, sondern auch CPUs und Speicher aufwerten, da Datenknoten in der gekoppelten Architektur für die Berechnung zuständig waren. Daher waren Maschinen in der Regel mit einer ausgewogenen Rechenleistung und Speicherkonfiguration ausgestattet, die ausreichende Speicherkapazität zusammen mit vergleichbarer Rechenleistung boten. Die tatsächliche Nachfrage nach Rechenleistung stieg jedoch nicht so stark an, wie erwartet. Infolgedessen verursachte die erweiterte Rechenleistung für Unternehmen einen großen Verlust.
- Das Ausbalancieren von Rechen- und Speicherkapazitäten und die Auswahl geeigneter Maschinen wurde zu einer Herausforderung. Die Ressourcennutzung des gesamten Clusters in Bezug auf Speicher und I/O konnte stark unausgeglichen sein, und diese Ungleichheit verschlimmerte sich mit zunehmender Clustergröße. Darüber hinaus war es schwierig, geeignete Maschinen zu beschaffen, da diese ein Gleichgewicht zwischen den Anforderungen an Rechen- und Speicherkapazitäten finden mussten.
- Da die Daten ungleichmäßig verteilt sein konnten, war es schwierig, Rechenaufgaben effektiv auf den Instanzen zu planen, auf denen die Daten lagen. Die Datenstandort-Planungsstrategie kann realen Szenarien aufgrund der Möglichkeit einer unausgeglichenen Datenverteilung nicht effektiv begegnen. Zum Beispiel könnten bestimmte Knoten zu lokalen Hotspots werden, die mehr Rechenleistung erfordern. Folglich könnte selbst wenn Aufgaben auf der Big Data Plattform auf diese Hotspot-Knoten geplant werden, die I/O-Leistung immer noch ein limitierender Faktor sein.
Warum Entkopplung von Speicher und Berechnung machbar ist
Die Machbarkeit der Trennung von Speicher und Berechnung wurde durch Fortschritte in Hardware und Software zwischen 2006 und 2016 ermöglicht. Diese Fortschritte umfassen:
Netzwerkkarten
Die Verbreitung von 10-Gb-Netzwerkkarten hat zugenommen, mit zunehmender Verfügbarkeit von höheren Kapazitäten wie 20 Gb, 40 Gb und sogar 50 Gb in Rechenzentren und Cloud-Umgebungen. In AI-Szenarien werden auch Netzwerkkarten mit einer Kapazität von 100 GB verwendet. Dies stellt eine erhebliche Steigerung des Netzwerkbandbreiten um mehr als 100-fach dar.
Festplatten
Viele Unternehmen setzen weiterhin auf festplattenbasierte Lösungen für den Speicher in großen Datenclustern. Die Durchsatzrate von Festplatten hat sich verdoppelt und stieg von 50 MB/s auf 100 MB/s. Ein mit einer 10-GB-Netzwerkkarte ausgestattetes System kann einen Spitzen-Durchsatz von etwa 12 Festplatten unterstützen. Dies ist für die meisten Unternehmen ausreichend, und somit ist die Netzwerkübertragung nicht länger ein Engpass.
Software
Die Verwendung effizienter Kompressionsalgorithmen wie Snappy, LZ4 und Zstandard sowie von Spaltenspeicherformaten wie Avro, Parquet und Orc hat den I/O-Druck weiter verringert. Der Engpass bei der Big-Data-Verarbeitung hat sich von I/O auf die CPU-Leistung verschoben.
Wie man Speicher-Berechnung-Trennung umsetzt
Erster Versuch: Unabhängige Bereitstellung von HDFS in die Cloud
Unabhängige Bereitstellung von HDFS
Seit 2013 gab es Versuche innerhalb der Branche, Speicher und Berechnungen zu trennen. Der erste Ansatz war ziemlich einfach und beinhaltete die unabhängige Bereitstellung von HDFS ohne Integration in die Rechenarbeiter. Diese Lösung führte keine neuen Komponenten in die Hadoop-Ökosystem ein.
Wie im folgenden Diagramm gezeigt, wurde der NodeManager nicht mehr auf DataNodes bereitgestellt. Dies zeigte an, dass Berechnungsaufgaben nicht mehr an DataNodes gesendet wurden. Der Speicher wurde zu einem separaten Cluster, und die für Berechnungen benötigten Daten wurden über das Netzwerk übertragen, unterstützt von End-to-End-10-Gb-Netzwerkkarten. (Beachten Sie, dass die Netzwerkübertragungslinien im Diagramm nicht markiert sind.)

Obwohl diese Lösung die Datenlokalität, das genialste Design von HDFS, aufgab, verbesserte die erhöhte Geschwindigkeit der Netzwerkkommunikation die Konfiguration des Clusters erheblich. Dies wurde durch Experimente von Davies, dem Mitgründer von Juicedata, und seinen Teamkollegen während ihrer Zeit bei Facebook im Jahr 2013 demonstriert. Die Ergebnisse bestätigten die Durchführbarkeit der unabhängigen Bereitstellung und Verwaltung von Rechenknoten.
Dieser Versuch entwickelte sich jedoch nicht weiter. Der Hauptgrund sind die Herausforderungen bei der Bereitstellung von HDFS in die Cloud.
Herausforderungen bei der Bereitstellung von HDFS in die Cloud
Die Bereitstellung von HDFS in die Cloud stellt die folgenden Probleme:
- Das HDFS-Mehrfachreplikationsmechanismus kann die Kosten von Unternehmen in der Cloud erhöhen: In der Vergangenheit haben Unternehmen HDFS-Systeme in ihren Rechenzentren mit Bare-Metal-Festplatten aufgebaut. Um das Risiko von Festplattenausfällen zu mindern, hat HDFS einen Mehrfachreplikationsmechanismus implementiert, um die Datensicherheit und Verfügbarkeit zu gewährleisten. Wenn jedoch Daten in die Cloud migriert werden, bieten Cloud-Anbieter Cloud-Festplatten, die bereits durch den Mehrfachreplikationsmechanismus geschützt sind. Folglich müssen Unternehmen die Daten innerhalb der Cloud dreifach replizieren, was zu einer erheblichen Kostenerhöhung führt.
- Begrenzte Auswahlmöglichkeiten für die Bereitstellung auf Bare-Metal-Festplatten: Obwohl Cloud-Anbieter einige Maschinentypen mit Bare-Metal-Festplatten anbieten, sind die verfügbaren Optionen begrenzt. Zum Beispiel unterstützen von 100 verfügbaren virtuellen Maschinentypen in der Cloud nur 5-10 Maschinentypen Bare-Metal-Festplatten. Diese begrenzte Auswahl kann möglicherweise nicht die spezifischen Anforderungen von Unternehmensclustern erfüllen.
- Unfähigkeit, die einzigartigen Vorteile der Cloud zu nutzen: Die Bereitstellung von HDFS in der Cloud erfordert die manuelle Erstellung von Maschinen, die Bereitstellung, Wartung, Überwachung und Betrieb ohne die Bequemlichkeit der elastischen Skalierung und des Pay-as-you-go-Modells. Dies sind die Hauptvorteile des Cloud Computings. Daher ist es nicht einfach, HDFS in der Cloud bereitstellen zu können und dabei eine Trennung von Speicher und Rechenleistung zu erreichen.
HDFS-Einschränkungen
HDFS selbst hat diese Einschränkungen:
- Begrenzte Skalierbarkeit der NameNodes: Die NameNodes in HDFS können nur vertikal skaliert werden und lassen keine verteilte Skalierung zu. Diese Einschränkung setzt eine Grenze für die Anzahl der Dateien, die innerhalb eines einzelnen HDFS-Clusters verwaltet werden können.
- Das Speichern von mehr als 500 Millionen Dateien verursacht hohe Betriebskosten: Aus unserer Erfahrung heraus ist es in der Regel einfach, HDFS mit weniger als 300 Millionen Dateien zu betreiben und zu warten. Wenn die Anzahl der Dateien die 500 Millionen überschreitet, muss die HDFS Federation-Mechanik implementiert werden. Dies führt jedoch zu hohen Betriebs- und Verwaltungskosten.
- Hoher Ressourcenverbrauch und hoher Lasten Druck auf den NameNode beeinträchtigen die Verfügbarkeit des HDFS-Clusters: Wenn ein NameNode zu viele Ressourcen mit hoher Belastung belegt, kann eine vollständige Garbage Collection (GC) ausgelöst werden. Dies beeinträchtigt die Verfügbarkeit des gesamten HDFS-Clusters. Der Systemspeicher kann eine Ausfallzeit erleiden, wodurch das Lesen von Daten unmöglich ist und es keine Möglichkeit gibt, in den GC-Prozess einzugreifen. Die Dauer des Systemstillstands kann nicht bestimmt werden. Dies ist ein anhaltendes Problem in hoch belasteten HDFS-Clustern.
Öffentlicher Cloud + Objektspeicher
Mit dem Fortschritt der Cloud-Computing-Technologie haben Unternehmen jetzt die Möglichkeit, Objektspeicher als Alternative zu HDFS zu verwenden. Objektspeicher ist speziell für die Speicherung von groß angelegten unstrukturierten Daten entwickelt worden und bietet eine Architektur für einfaches Hoch- und Herunterladen von Daten. Es bietet eine hoch skalierbare Speicherkapazität und stellt eine kosteneffiziente Lösung dar.
Vorteile des Objektspeichers als HDFS-Ersatz
Objektspeicher hat an Popularität gewonnen, beginnend mit AWS und später von anderen Cloud-Anbietern als Ersatz für HDFS übernommen. Die folgenden Vorteile sind bemerkenswert:
- Dienstorientiert und einsatzbereit: Objektspeicher benötigt keine Bereitstellung, Überwachung oder Wartungsarbeiten und bietet eine bequeme und benutzerfreundliche Erfahrung.
- Elastische Skalierung und Pay-as-you-go: Unternehmen zahlen für Objektspeicher basierend auf ihrem tatsächlichen Verbrauch, wodurch die Notwendigkeit für Kapazitätsplanung entfällt. Sie können einen Objektspeicher-Bucket erstellen und so viel Daten speichern, wie notwendig ist, ohne sich Gedanken über Speicherkapazitätsgrenzen machen zu müssen.
Nachteile des Objektspeichers
Allerdings treten bei der Verwendung von Objektspeicher zur Unterstützung komplexer Datensysteme wie Hadoop die folgenden Herausforderungen auf:
Nachteil #1: Mangelnde Leistung bei Dateilisten
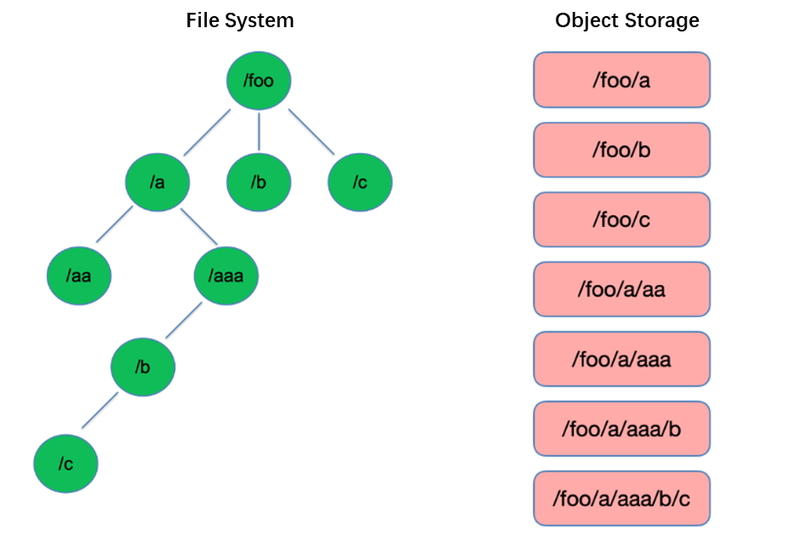
Das Auflisten ist eine der grundlegendsten Operationen im Dateisystem. Es ist leichtgewichtig und schnell in baumartigen Strukturen wie HDFS.
Im Gegensatz dazu verwendet Objektspeicher eine flache Struktur und erfordert das Indexieren mit Schlüsseln (eindeutigen Identifikatoren) für das Speichern und Abrufen von Tausenden oder sogar Milliarden von Objekten. Daher kann beim Durchführen einer List-Operation der Objektspeicher nur innerhalb dieses Indexes suchen, was zu einer deutlich schlechteren Leistung im Vergleich zu baumartigen Strukturen führt.
Nachteil #2: Fehlen der atomaren Umbenennungsfähigkeit, die die Leistung und Stabilität von Aufgaben beeinträchtigt
In Extraktions-, Transformations- und Laden-Computing-Modellen (ETL) schreibt jede Teilaufgabe ihre Ergebnisse in ein temporäres Verzeichnis. Wenn die gesamte Aufgabe abgeschlossen ist, kann das temporäre Verzeichnis in das endgültige Verzeichnis umbenannt werden.
Diese Umbenennungsoperationen sind atomar und schnell in Dateisystemen wie HDFS und garantieren Transaktionen. Da Objektspeicher jedoch keine native Verzeichnisstruktur haben, handhaben sie eine Umbenennungsoperation als simuliertes Verfahren, das einen erheblichen internen Datenkopierungsprozess beinhaltet. Dieser Prozess kann zeitaufwändig sein und keine Transaktionsgarantien bieten.
Bei der Verwendung von Objektspeicher verwenden Benutzer häufig das Pfadformat aus traditionellen Dateisystemen als Schlüssel für Objekte, wie z.B. „/order/2-22/8/10/detail“. Bei einer Umbenennungsoperation ist es notwendig, nach allen Objekten zu suchen, deren Schlüssel das Verzeichnisname enthalten, und alle Objekte mit dem neuen Verzeichnisnamen als Schlüssel zu kopieren. Dieser Prozess beinhaltet Datenkopiervorgänge, was zu einer wesentlich geringeren Leistung im Vergleich zu Dateisystemen führt, möglicherweise um ein oder zwei Größenordnungen langsamer.
Darüber hinaus besteht aufgrund der fehlenden Transaktionsgarantien das Risiko eines Fehlschlags während des Prozesses, was zu inkorrekten Daten führen kann. Diese scheinbar kleinen Unterschiede haben Auswirkungen auf die Leistung und Stabilität des gesamten Aufgabenpipelines.
Nachteil #3: Die Mechanik der eventualen Konsistenz beeinträchtigt die Datenkorrektheit und Aufgabenstabilität
Zum Beispiel, wenn mehrere Clients gleichzeitig Dateien unter einem Pfad erstellen, kann die über die List-API erhaltene Dateiliste nicht sofort alle erstellten Dateien enthalten. Es dauert Zeit, bis die internen Systeme des Objektspeichers Datenkonsistenz erreichen. Diese Art des Zugriffs wird häufig in der ETL-Datenverarbeitung verwendet, und die eventuelle Konsistenz kann die Datenkorrektheit und Aufgabenstabilität beeinflussen.
Um das Problem der mangelnden Datenkonsistenz bei Objektspeicher zu beheben, hat AWS ein Produkt namens EMRFS veröffentlicht. Dabei kommt eine zusätzliche DynamoDB-Datenbank zum Einsatz. Beispielsweise schreibt Spark bei der Erstellung einer Datei auch gleichzeitig eine Kopie der Dateiliste in DynamoDB. Anschließend wird ein Mechanismus eingerichtet, der kontinuierlich die List-API des Objektspeichers aufruft und die erhaltenen Ergebnisse mit den im Datenbank gespeicherten Ergebnissen vergleicht, bis diese übereinstimmen, woraufhin die Ergebnisse zurückgegeben werden. Allerdings ist die Stabilität dieses Mechanismus nicht ausreichend, da sie von der Belastung der Region, in der sich der Objektspeicher befindet, beeinflusst werden kann, was zu variabler Leistung führt. Daher ist dies keine ideale Lösung.
Nachteil #4: Eingeschränkte Kompatibilität mit Hadoop-Komponenten
HDFS war in den frühen Phasen des Hadoop-Ökosystems die primäre Speicherwahl, und verschiedene Komponenten wurden basierend auf der HDFS-API entwickelt. Die Einführung von Objektspeicher hat zu Veränderungen in der Datenspeicherstruktur und den APIs geführt.
Cloud-Anbieter müssen Verbindungskomponenten zwischen Komponenten und Cloud-Objektspeicher modifizieren und obere Schichtkomponenten patchen, um Kompatibilität sicherzustellen. Diese Aufgabe stellt für öffentliche Cloud-Anbieter eine erhebliche Arbeitsbelastung dar.
Infolgedessen ist die Anzahl der unterstützten Rechenkomponenten in Big-Data-Plattformen von öffentlichen Cloud-Anbietern begrenzt und umfasst in der Regel nur einige Versionen von Spark, Hive und Presto. Diese Einschränkung stellt Herausforderungen für die Migration von Big-Data-Plattformen in die Cloud oder für Benutzer mit spezifischen Anforderungen an ihre eigenen Distributionen und Komponenten dar.
Um die leistungsstarke Performance von Objektspeicher zu nutzen, während die Zuverlässigkeit von Dateisystemen erhalten bleibt, können Unternehmen Objektspeicher + JuiceFS verwenden.
Objektspeicher + JuiceFS
Wenn Benutzer komplexe Datenberechnungen, Analysen und Trainings auf Objektspeicher durchführen möchten, kann der alleinige Objektspeicher möglicherweise nicht ausreichend die Anforderungen von Unternehmen erfüllen. Dies ist ein Hauptgrund für die Entwicklung von JuiceFS durch Juicedata, die darauf abzielt, die Einschränkungen von Objektspeicher zu ergänzen.
JuiceFS ist eine quelloffene, leistungsfähige verteilte Dateisystem, speziell für die Cloud entwickelt. Zusammen mit Objektspeicher bietet JuiceFS kosteneffiziente Lösungen für datenintensive Szenarien wie Berechnung, Analyse und Training.
Wie JuiceFS + Objektspeicher funktioniert
Das folgende Diagramm zeigt die Bereitstellung von JuiceFS in einem Hadoop-Cluster.
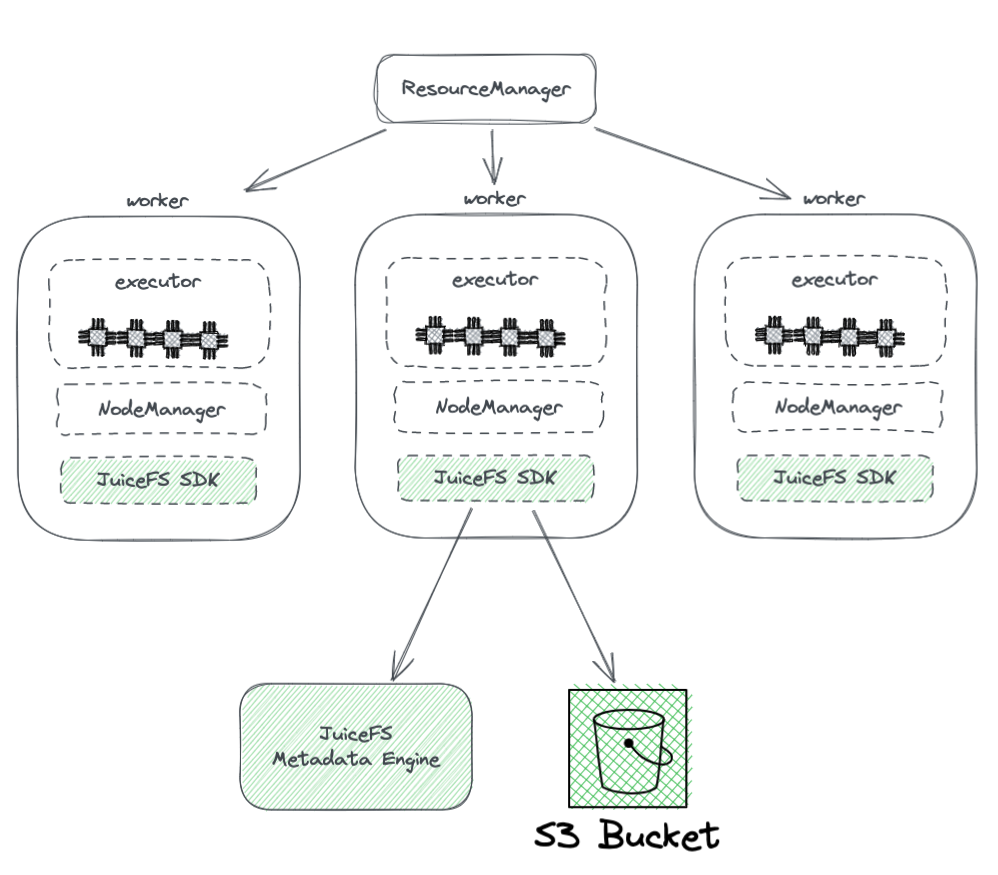
Aus dem Diagramm können wir Folgendes erkennen:
- Alle von YARN verwalteten Worker-Knoten tragen eine JuiceFS Hadoop SDK, die die vollständige Kompatibilität mit HDFS gewährleisten kann.
- Das SDK greift auf zwei Komponenten zu:
-
JuiceFS Metadata Engine: Das Metadata-Engine fungiert als Gegenstück zum HDFS‘ NameNode. Es speichert die Metadateninformationen des gesamten Dateisystems, einschließlich Verzeichniszählungen, Dateinamen, Berechtigungen und Zeitstempel, und löst Skalierbarkeits- und GC-Herausforderungen, denen das HDFS‘ NameNode gegenübersteht.
-
S3 Bucket: Die Daten werden innerhalb des S3 Buckets gespeichert, das als Analogon zum HDFS‘ DataNode betrachtet werden kann. Es kann als eine große Anzahl von Festplatten verwendet werden, die Datenspeicherungs- und Replikationsaufgaben verwalten.
-
-
JuiceFS besteht aus drei Komponenten:
- JuiceFS Hadoop SDK
- Metadata Engine
- S3 Bucket
Vorteile von JuiceFS gegenüber direkter Nutzung von Objektspeicher
JuiceFS bietet mehrere Vorteile im Vergleich zur direkten Nutzung von Objektspeicher:
- Vollständige Kompatibilität mit HDFS: Dies wird durch die ursprüngliche Konstruktion von JuiceFS erreicht, die POSIX voll unterstützt. Die POSIX-API hat eine größere Abdeckung und Komplexität als HDFS.
- Möglichkeit zur Nutzung mit vorhandenem HDFS und Objektspeicher: Dank der Konstruktion des Hadoop-Systems kann JuiceFS neben vorhandenen HDFS- und Objektspeichersystemen genutzt werden, ohne dass ein vollständiger Austausch erforderlich ist. In einem Hadoop-Cluster können mehrere Dateisysteme konfiguriert werden, wodurch JuiceFS und HDFS nebeneinander existieren und zusammenarbeiten können. Diese Architektur eliminiert die Notwendigkeit für einen vollständigen Austausch vorhandener HDFS-Cluster, der erheblichen Aufwand und Risiken mit sich bringen würde. Nutzer können JuiceFS basierend auf ihren Anwendungsanforderungen und Clusterbedingungen allmählich integrieren.
- Leistungsfähige Metadatenleistung: JuiceFS trennt die Metadaten-Engine von S3 und ist nicht mehr von der S3-Metadatenleistung abhängig. Dies stellt eine optimale Metadatenleistung sicher. Bei der Nutzung von JuiceFS werden Interaktionen mit dem zugrunde liegenden Objektspeicher auf grundlegende Operationen wie Get, Put und Delete reduziert. Diese Architektur überwindet die Leistungsgrenzen von Objektspeichermetadaten und beseitigt Probleme im Zusammenhang mit der eventuellen Konsistenz.
- Unterstützung für atomares Umbenennen: JuiceFS unterstützt atomare Umbenennungsoperationen aufgrund seines eigenständigen Metadaten-Engines. Der Cache verbessert den Zugriff auf heiße Daten und bietet die Funktion der Datenlokalität: Mit dem Cache müssen heiße Daten nicht mehr jedes Mal aus dem Objektspeicher über das Netzwerk abgerufen werden. Darüber hinaus implementiert JuiceFS die HDFS-spezifische Datenlokalitäts-API, sodass alle übergeordneten Komponenten, die die Datenlokalität unterstützen, wieder die Kenntnis der Datenaffinität erlangen können. Dies ermöglicht es YARN, Aufgaben auf Knoten mit etabliertem Caching bevorzugt zu planen, was zu einer Gesamtleistung vergleichbar mit dem speicher-rechengekoppelten HDFS führt.
- JuiceFS ist POSIX-kompatibel, was die Integration in maschinellem Lernen und AI-bezogene Anwendungen erleichtert.
Schlussfolgerung
Mit der Weiterentwicklung der Unternehmensanforderungen und den Fortschritten in der Technologie hat sich die Architektur von Speicher und Rechenleistung verändert und sich von der Kopplung zur Trennung verändert.
Es gibt verschiedene Ansätze zur Erreichung der Trennung von Speicher und Rechenleistung, von der Bereitstellung von HDFS in der Cloud bis hin zu öffentlichen Cloud-Lösungen, die mit Hadoop kompatibel sind, und sogar zu Lösungen wie Objektspeicher + JuiceFS, die für komplexe Big-Data-Berechnungen und -Speicherung in der Cloud geeignet sind.
Für Unternehmen gibt es kein Allheilmittel, und der Schlüssel besteht darin, die Architektur anhand ihrer spezifischen Bedürfnisse auszuwählen. Trotzdem ist Einfachheit immer eine sichere Wahl.
Über den Autor
Rui Su, ein Partner bei Juicedata, war seit 2017 Mitbegründer und hatte maßgeblichen Anteil an der vollständigen Entwicklung des JuiceFS-Produkts, des Marktes und der Open-Source-Community. Mit 16 Jahren branchenerfahrung hat er in Positionen wie R&D, Produktmanager und Gründer in Software, Internet und Nichtregierungsorganisationen fungiert.
Source:
https://dzone.com/articles/from-hadoop-to-cloud-why-and-how-to-decouple-stora